笔者于2019年10月参加并通过了Elastic Certified Engineer Exam, 在准备考试的三四个月的时间内,对考试的要求,考试的准备,考试的流程等有一些了解,因此总结这篇文章,希望对后续参加考试的朋友有一定的帮助。
1. 考试简介
Elastic Certified Engineer Exam是Elastic官方推出的Elasticsearch使用能力认证考试,通过该考试表明考生具备了通过执行一些列操作构建完整Elasticsearch解决方案的能力,这些操作包括包括集群安装,配置,管理,数据索引,查询,分析等。
详细介绍可以参考[Elastic Certified Engineer]
2. 考察点
认证考试介绍页面中有对考察点有明确的说明,可以参考[Exam Objectives], 考察点主要是Elasticsearch的使用(不考察Elastic stack其他组件如kibana, beat, logstash等的使用),不考察Elasticsearch的实现原理,考察点主要包括:
- 集群的安装和配置:基本安装,配置,安全配置,角色和用户管理等
- 索引数据:索引和文档的各种操作
- 查询:各种查询场景
- 聚合:各种聚合查询,如指标聚合,分桶聚合,嵌套聚合,pipeline聚合等
- Mapping和Analzysis: 索引mapping和分词相关操作
- 集群管理: shard分配,集群健康诊断,备份与恢复,冷热分离,跨集群检索等。
上述只是简单列举,详情以Exam Objectives为准
3. 考试准备
建议参加[Official Elastic Training], 该培训对Elasticsearch的使用会有详细的讲解,并有配套的lab,学习完课程,并认真完成各lab基本就具备了通过考试的能力。
另外要对Elasticsearch官方文档的结构有较为清晰的了解,能快速的查找到相关文档,当然如果能熟练使用kibana文档跳转和文档的搜索功能也可以。
另外还有一些考试通过者的一些经验:
4. 考试报名
- 考试购买
- 考试预约
- 按照邮件指引注册examlocal
这是一个第三方考试网站,注意注册时使用和注册training网站相同的邮箱
- 在schedule an Exam页面搜索Elastic Certificate Exam
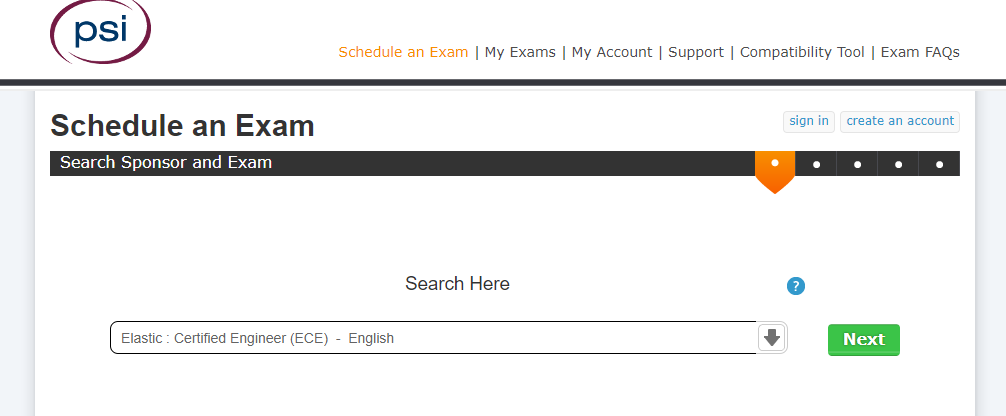
- 选择合适的考试时间,注意时区的选择
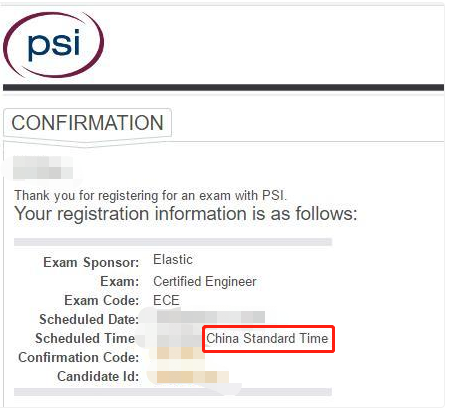
- 最后校验会有一个checklist,检测你当前机器是否符合要求
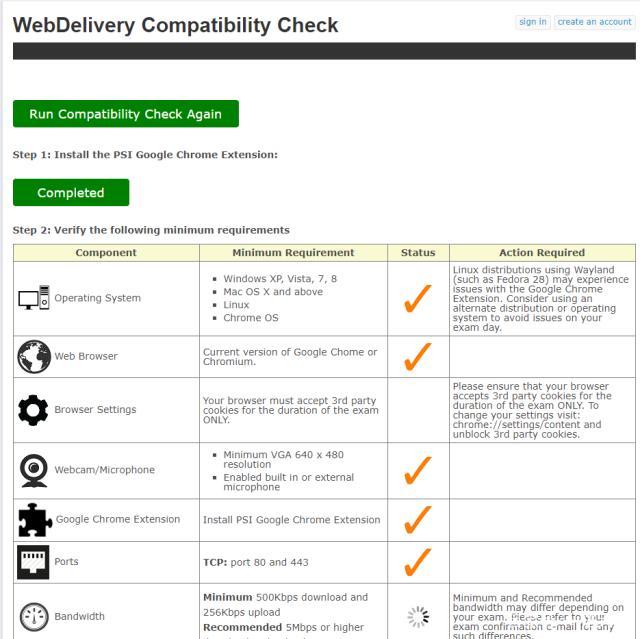 这里要注意
这里要注意
- 要按照指引为浏览器安装插件
- 准备VPN,以保证考试时网络没有问题
- 考试时后台不能有任何进程,如果机器上有默认无法禁用的程序要注意
- 电脑要带摄像头和麦克风
5. 考试环境和流程
- 考试环境
考试环境是一个通过浏览器连接的远程centos系统,通过terminal连接考试的各集群服务器,通过系统内浏览器来查看官方文档和作答考卷。关于环境的讲解可以查看官方讲解视频,考试环境和讲解中完全一致
- 考试流程
考试开始前15分钟,考生通过考试网站指引进入考试系统,此时考官便可以通过摄像头和麦克风看到听到你,但是你是看不到听不到考官的,考官会通过一个聊天窗口与你打字沟通。
考官会要求你先出示你的证件,注意这里一定要使用护照等带有拼音的证件,毕竟外国人不认识中文,如果没有此类证件,想要使用身份证,需要提前写邮件给Elasitc申请。
接着考官会要求你抱着电脑环视周围,查看桌面上是否有任何物品,如果有物品如护照等,会被要求拿走放到其他地方。
接着考官会要求你打开你电脑的任务管理器,查看是否有除去浏览器的其他进程。
上述检查均通过后,便可以开始考试,考试时间是3个小时,考题也都是常规的一些集群使用相关的知识点,没有偏题怪题。考前看其他人的经验大概90分钟完成,我也基本在这个时间点完成。
考试过程中可以向考官申请中途休息和喝水,考官会暂停考试。建议做完第一遍后进行检查,可能会发现一些细节问题,如单节点集群考试创建的索引默认一副本会导致集群yellow等。
6. 考题回顾
正式进入考题前会有一个考题作答讲解和集群情况描述,我的环境是三个集群,第一个是三节点,另外两个都是一节点,每个集群都带有一个kibana。
我的考题共10道,我这里只对考题考点做简单描述:
- 冷热分离架构配置
- update_by_query + script按照要求更新索引
- 自定义分词插件,让king's和kings有相同的评分
- nested类型和nested query
- dynamic mapping
- multi-match, boost, most_fields
- date-histogram, sub-aggregation
- 开启security
- 集群备份snapshot
- match_phrase, hightlighting, sort
7. 考试结果
考试成绩会在三个工作日内公布,但实际一般一个工作日就会出结果。如果通过考试会收到一封考试通过的邮件,如下
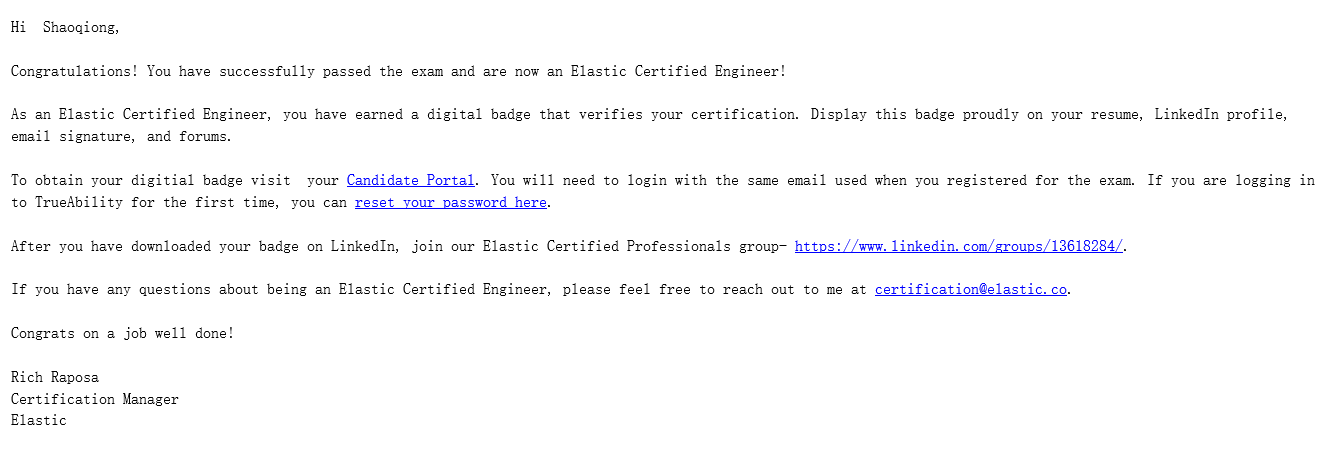 按照邮件指引便可以得到一个电子证书,如下图
按照邮件指引便可以得到一个电子证书,如下图

最后分享一下从大洋彼岸寄过来的纪念币

最后祝大家考试顺利(●'◡'●)
欢迎关注公众号Elastic慕容,和我一起进入Elastic的奇妙世界吧



 按照指示步骤进行操作购买支付即可,考试费用是$400美元,可以使用visa或master信用卡支付
按照指示步骤进行操作购买支付即可,考试费用是$400美元,可以使用visa或master信用卡支付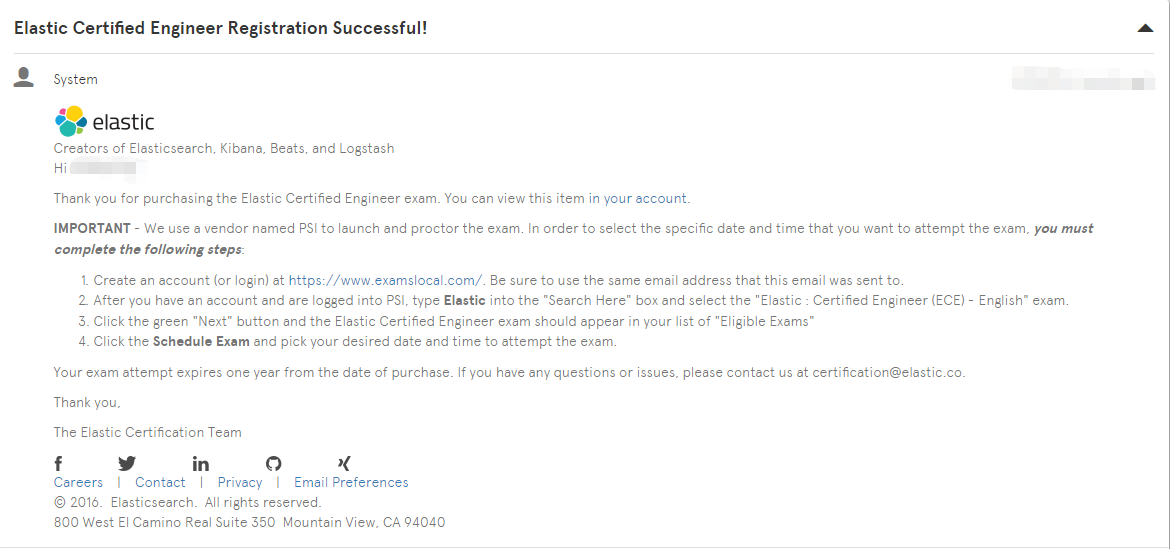 购买成功后考试有一年的有效期,可以在购买后的一年时间内的任意时间预约考试
购买成功后考试有一年的有效期,可以在购买后的一年时间内的任意时间预约考试







