

【深圳ES Meetup】字节跳动黄杨锋:从0到1构建 ES 服务平台的挑战
分享嘉宾 黄杨锋 高级工程师 @字节跳动
目前在头条深圳负责ES服务平台相关的研发工作;此前曾就职于华为、YY、腾讯等企业,在腾讯基于ES做微信支付数据的检索。
Q1、从0到1构建 ES 服务平台的过程中有哪些痛点?分别是如何解决的?
A:(1)需要隔离,远离大集群,是通过 k8s来解决。
(2)性能分析方面相对还比较薄弱 ,打算增加metric和trace日志来看看具体耗时。
Q2、在 ES 服务平台方面未来还有什么样的规划?
A:相关规划详见下图

Q3、结合您的实践经历,对 ES 目前的生态发展、应用以及未来有什么样的看法?
A: ES 发展很快,周边生态也越来越丰富,希望 ES 在快速发展的过程中,更加注重查询性能的优化提升,以及集群的稳定性。
Q4、您对本次技术沙龙活动的主题分享有什么期待?
A:期望看到性能优化、机器学习相关的最新进展。
Q5、您对 Elastic 中文社区发展有什么意见或建议呢?
A:(1)ES 在中国程序员中的影响力感觉可以加强,希望可以做到像 Google/Amazon 在中国程序员群体上那样有很大的影响力;
(2)希望官方出一些内核相关的书籍或文章;
(3)希望价钱可以再调低点。
11月16日 Elastic 中文社区深圳 Meetup 火热报名中
主题分享:《基于K8S的ES服务平台在头条的实践介绍》黄杨锋
主题摘要:ES 服务平台自上线以来,已经接入了头条、抖音等众多业务。本次分享将介绍 ES 服务平台从 0 到 1 的创建过程中所做的一些工作,包括 K8S 碰到的一些难点、ES 功能的增强、跨机房容灾、全栈监控告警、自动化部署等功能。

分享嘉宾 黄杨锋 高级工程师 @字节跳动
目前在头条深圳负责ES服务平台相关的研发工作;此前曾就职于华为、YY、腾讯等企业,在腾讯基于ES做微信支付数据的检索。
Q1、从0到1构建 ES 服务平台的过程中有哪些痛点?分别是如何解决的?
A:(1)需要隔离,远离大集群,是通过 k8s来解决。
(2)性能分析方面相对还比较薄弱 ,打算增加metric和trace日志来看看具体耗时。
Q2、在 ES 服务平台方面未来还有什么样的规划?
A:相关规划详见下图
Q3、结合您的实践经历,对 ES 目前的生态发展、应用以及未来有什么样的看法?
A: ES 发展很快,周边生态也越来越丰富,希望 ES 在快速发展的过程中,更加注重查询性能的优化提升,以及集群的稳定性。
Q4、您对本次技术沙龙活动的主题分享有什么期待?
A:期望看到性能优化、机器学习相关的最新进展。
Q5、您对 Elastic 中文社区发展有什么意见或建议呢?
A:(1)ES 在中国程序员中的影响力感觉可以加强,希望可以做到像 Google/Amazon 在中国程序员群体上那样有很大的影响力;
(2)希望官方出一些内核相关的书籍或文章;
(3)希望价钱可以再调低点。
11月16日 Elastic 中文社区深圳 Meetup 火热报名中
主题分享:《基于K8S的ES服务平台在头条的实践介绍》黄杨锋
主题摘要:ES 服务平台自上线以来,已经接入了头条、抖音等众多业务。本次分享将介绍 ES 服务平台从 0 到 1 的创建过程中所做的一些工作,包括 K8S 碰到的一些难点、ES 功能的增强、跨机房容灾、全栈监控告警、自动化部署等功能。
社区日报 第780期 (2019-11-12)
http://t.cn/AirIlimU
2、每秒5000万的存储能力,我们是如何做到的。
http://t.cn/Ai1s3aVT
3、MySQL 慢查询日志导入 Elasticsearch 可视化查询分析。
http://t.cn/AirIl9cm
编辑:叮咚光军
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
http://t.cn/AirIlimU
2、每秒5000万的存储能力,我们是如何做到的。
http://t.cn/Ai1s3aVT
3、MySQL 慢查询日志导入 Elasticsearch 可视化查询分析。
http://t.cn/AirIl9cm
编辑:叮咚光军
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub 收起阅读 »
社区日报 第779期 (2019-11-11)
http://t.cn/AirbIiTh
2、 剖析ElasticSearch核心概念,NRT,索引,分片,副本等
http://t.cn/Air4o9fn
3、为什么Elasticsearch查询速度比B-tree块
http://t.cn/Air49zm1
编辑:cyberdak
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
http://t.cn/AirbIiTh
2、 剖析ElasticSearch核心概念,NRT,索引,分片,副本等
http://t.cn/Air4o9fn
3、为什么Elasticsearch查询速度比B-tree块
http://t.cn/Air49zm1
编辑:cyberdak
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup 收起阅读 »
社区日报 第778期 (2019-11-10)
http://t.cn/EMBiRNp
2.(自备梯子)AWS Elasticsearch入门。
http://t.cn/AirhxMeL
3.(自备梯子)Apple试图杀死基于Web的App?
http://t.cn/Airhidlj
编辑:至尊宝
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
http://t.cn/EMBiRNp
2.(自备梯子)AWS Elasticsearch入门。
http://t.cn/AirhxMeL
3.(自备梯子)Apple试图杀死基于Web的App?
http://t.cn/Airhidlj
编辑:至尊宝
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup 收起阅读 »
【深圳ES Meetup】李猛:DB与ES结合,是业务系统实践值得探讨的事
李猛 架构师/Elastic认证工程师
Elastic Stack产品深度用户,2012/2013年接触Elasticsearch,对Elastic Stack开发、架构、运维等方面有深入体验,实践过多种ES项目,最暴力的大数据分析应用,最复杂的业务系统应用等。
Q1、作为深度用户,当初是基于什么样的动机和考量选择使用 ES 产品并持续深入探索的?
A:易用性与功能强大,个人平常比较爱好算法研究,选择任何数据产品本质上都是选择算法,算法的本质决定了产品的强大。
架构是个宏观问题,ES的设计是标准的分布式,架构的优秀设计带来的是易用性;
算法是个微观问题,ES集成了很多优秀的算法,这样在很多业务场景下都可满足,而不用更换不同的数据产品,这样也会带来产品运维方面的便利性,保障应用的技术栈不至于过多复杂。
Q2、在探索 DB 与 ES 的互通方面,有遇到什么难题吗?最后是如何解决的呢?
A:数据一致性与实时性问题。应用架构思维变化,业务调整变化与技术方案变化。
Q3、结合您的实践经历,对 ES 目前的生态发展、应用以及未来有什么样的看法?
A:ES目前主要应用是在单索引条件下查询,附带有简单的聚合分析能力。复杂的分析能力不具备,ES未来会增强复杂的分析能力,比如有条件的支持2个索引的关联分析。
Q4、您对本次技术沙龙活动的主题分享有什么期待?
A:期望更多人参加探讨更多的业务应用场景,比如传统应用方面、大数据方面、机器学习方面;帮助大家以后项目实战有更多的案例参考。
Q5、您对 Elastic 中文社区发展有什么意见或建议呢?
A:ES目前在国内的热度几乎超过任何数据库,几乎大大小小的公司,都在使用;从开始入门到成熟运用多多少少都会遇到很多问题, 希望社区活动更加多一点,业余的交流更多一点。比如可以办一些,走进某些企业的活动。
11月16日 Elastic 中文社区深圳 Meetup 火热报名中
分享主题:《DB到ES数据实时同步之路》 李猛
主题摘要:关系型数据库天然具备最严格的事务特性,有效的保证数据库一致性,但在高效查询方面显得很无力;Elasticsearch天然具备高效的查询算法,但在数据一致性方面却是先天缺陷;如何将DB与ES的优点结合,是任何一个企业公司业务系统实践都值得探讨的事。

李猛 架构师/Elastic认证工程师
Elastic Stack产品深度用户,2012/2013年接触Elasticsearch,对Elastic Stack开发、架构、运维等方面有深入体验,实践过多种ES项目,最暴力的大数据分析应用,最复杂的业务系统应用等。
Q1、作为深度用户,当初是基于什么样的动机和考量选择使用 ES 产品并持续深入探索的?
A:易用性与功能强大,个人平常比较爱好算法研究,选择任何数据产品本质上都是选择算法,算法的本质决定了产品的强大。
架构是个宏观问题,ES的设计是标准的分布式,架构的优秀设计带来的是易用性;
算法是个微观问题,ES集成了很多优秀的算法,这样在很多业务场景下都可满足,而不用更换不同的数据产品,这样也会带来产品运维方面的便利性,保障应用的技术栈不至于过多复杂。
Q2、在探索 DB 与 ES 的互通方面,有遇到什么难题吗?最后是如何解决的呢?
A:数据一致性与实时性问题。应用架构思维变化,业务调整变化与技术方案变化。
Q3、结合您的实践经历,对 ES 目前的生态发展、应用以及未来有什么样的看法?
A:ES目前主要应用是在单索引条件下查询,附带有简单的聚合分析能力。复杂的分析能力不具备,ES未来会增强复杂的分析能力,比如有条件的支持2个索引的关联分析。
Q4、您对本次技术沙龙活动的主题分享有什么期待?
A:期望更多人参加探讨更多的业务应用场景,比如传统应用方面、大数据方面、机器学习方面;帮助大家以后项目实战有更多的案例参考。
Q5、您对 Elastic 中文社区发展有什么意见或建议呢?
A:ES目前在国内的热度几乎超过任何数据库,几乎大大小小的公司,都在使用;从开始入门到成熟运用多多少少都会遇到很多问题, 希望社区活动更加多一点,业余的交流更多一点。比如可以办一些,走进某些企业的活动。
11月16日 Elastic 中文社区深圳 Meetup 火热报名中
分享主题:《DB到ES数据实时同步之路》 李猛
主题摘要:关系型数据库天然具备最严格的事务特性,有效的保证数据库一致性,但在高效查询方面显得很无力;Elasticsearch天然具备高效的查询算法,但在数据一致性方面却是先天缺陷;如何将DB与ES的优点结合,是任何一个企业公司业务系统实践都值得探讨的事。
收起阅读 »
社区日报 第777期 (2019-11-09)
1.从Elasticsearch到ElasticStack的技术演进之路 http://t.cn/AiBeonIc
2.利用dense_vector类型实现词向量搜索 http://t.cn/AiBekFwz
3.文本检索课程笔记系列: http://t.cn/AiBekFwh http://t.cn/AiBekFwP http://t.cn/AiBekFw7
1.从Elasticsearch到ElasticStack的技术演进之路 http://t.cn/AiBeonIc
2.利用dense_vector类型实现词向量搜索 http://t.cn/AiBekFwz
3.文本检索课程笔记系列: http://t.cn/AiBekFwh http://t.cn/AiBekFwP http://t.cn/AiBekFw7
收起阅读 »社区日报 第776期 (2019-11-08)
http://1t.click/aYvT
2、 一文带您快速入门可视化分析平台 Kibana
http://1t.click/aYvV
3、分布式搜索引擎面试题
(一)https://dwz.cn/Dcya8QQB
(二)https://dwz.cn/bMMIjkMJ
编辑:江水
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
http://1t.click/aYvT
2、 一文带您快速入门可视化分析平台 Kibana
http://1t.click/aYvV
3、分布式搜索引擎面试题
(一)https://dwz.cn/Dcya8QQB
(二)https://dwz.cn/bMMIjkMJ
编辑:江水
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
收起阅读 »
社区日报 第775期 (2019-11-07)
http://t.cn/AiBR3PuQ
2、(自备梯子)使用 ELK 导出 CouchDB 的数据
http://t.cn/AiBRBlFN
3、(自备梯子)引入 BERT,在 es 上实现语义搜索
http://t.cn/AiBRg9JP
编辑:rockybean
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
http://t.cn/AiBR3PuQ
2、(自备梯子)使用 ELK 导出 CouchDB 的数据
http://t.cn/AiBRBlFN
3、(自备梯子)引入 BERT,在 es 上实现语义搜索
http://t.cn/AiBRg9JP
编辑:rockybean
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup 收起阅读 »
社区日报 第774期 (2019-11-06)
http://t.cn/AiBlrpMC
2、Elastic:应用程序性能监控/管理(APM)实践
http://t.cn/Ai1saCNR
3、Flink 实时写入数据到 ElasticSearch 性能调优
http://t.cn/AiujKITJ
编辑:铭毅天下
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
http://t.cn/AiBlrpMC
2、Elastic:应用程序性能监控/管理(APM)实践
http://t.cn/Ai1saCNR
3、Flink 实时写入数据到 ElasticSearch 性能调优
http://t.cn/AiujKITJ
编辑:铭毅天下
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup 收起阅读 »
社区日报 第773期 (2019-11-05)
http://t.cn/RmQhDoR
2、Elasticsearch在日志分析领域应用和运维实践。
http://t.cn/AiBocweP
3、go操作ElasticSearch实战。
http://t.cn/AiBocyxj
编辑:叮咚光军
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
http://t.cn/RmQhDoR
2、Elasticsearch在日志分析领域应用和运维实践。
http://t.cn/AiBocweP
3、go操作ElasticSearch实战。
http://t.cn/AiBocyxj
编辑:叮咚光军
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup 收起阅读 »
深圳 ES Meetup 来啦! 11月16日 阿里中心
.png")
活动链接: https://meetup.elasticsearch.c ... .html
议程
13:00-13:30 签到
13:30-13:40 活动介绍
13:40-14:20 分享主题:基于K8S的ES服务平台在头条的实践介绍
分享嘉宾:黄杨锋 @字节跳动
主题摘要:ES服务平台自上线以来,已经接入了头条、抖音等众多业务。本次分享将介绍ES服务平台从0到1的创建过程中所做的一些工作,包括K8S碰到的一些难点、ES功能的增强、跨机房容灾、全栈监控告警、自动化部署等功能。
14:20-15:00 分享主题:DB到ES数据实时同步之路
分享嘉宾:李猛
主题摘要:关系型数据库天然具备最严格的事务特性,有效的保证数据库一致性,但在高效查询方面显得很无力;Elasticsearch天然具备高效的查询算法,但在数据一致性方面却是先天缺陷; 如何将DB与ES的优点结合,是任何一个企业公司业务系统实践都值得探讨的事。
15:20-16:00 分享主题:Elasticsearch在腾讯的优化实践
分享嘉宾:陈曦 @腾讯云
主题摘要:Elasticsearch在腾讯得到了大规模应用,支撑了后台海量日志分析、腾讯云监控系统、腾讯文档搜索服务等。在服务公司内外部用户的过程中,腾讯ES团队碰到了很多痛点,对ES内核做了大量优化,使其在高性能、高可用性、低成本等方面有了大幅度的提升。本次分享将着重介绍腾讯ES团队对ES的优化实践。
16:00-16:40 分享主题:阿里云Elasticsearch内核优化与应用实践
分享嘉宾:欧阳楚才 @阿里巴巴
主题摘要: Elasticsearch在阿里云上服务了大量的客户,同时也面临着巨大的业务挑战。阿里云ES在内核引擎、中文分词、向量检索、容器化部署等方面做了一系列开发工作,应用于文档、日志、图像、视频的检索与分析。
16:40-17:20 分享主题:码云Gitee的Elasticsearch检索优化实战
分享嘉宾:陈鑫 @码云
主题摘要: 码云(Gitee.com)的Elasticsearch应用实战,以代码仓库搜索为例,讲解Elasticsearch在分词、信息检索模型、排序模型的自定义、重写和优化经验。
17:20-18:00 抽奖 & 交流
活动链接: https://meetup.elasticsearch.c ... .html
议程
13:00-13:30 签到
13:30-13:40 活动介绍
13:40-14:20 分享主题:基于K8S的ES服务平台在头条的实践介绍
分享嘉宾:黄杨锋 @字节跳动
主题摘要:ES服务平台自上线以来,已经接入了头条、抖音等众多业务。本次分享将介绍ES服务平台从0到1的创建过程中所做的一些工作,包括K8S碰到的一些难点、ES功能的增强、跨机房容灾、全栈监控告警、自动化部署等功能。
14:20-15:00 分享主题:DB到ES数据实时同步之路
分享嘉宾:李猛
主题摘要:关系型数据库天然具备最严格的事务特性,有效的保证数据库一致性,但在高效查询方面显得很无力;Elasticsearch天然具备高效的查询算法,但在数据一致性方面却是先天缺陷; 如何将DB与ES的优点结合,是任何一个企业公司业务系统实践都值得探讨的事。
15:20-16:00 分享主题:Elasticsearch在腾讯的优化实践
分享嘉宾:陈曦 @腾讯云
主题摘要:Elasticsearch在腾讯得到了大规模应用,支撑了后台海量日志分析、腾讯云监控系统、腾讯文档搜索服务等。在服务公司内外部用户的过程中,腾讯ES团队碰到了很多痛点,对ES内核做了大量优化,使其在高性能、高可用性、低成本等方面有了大幅度的提升。本次分享将着重介绍腾讯ES团队对ES的优化实践。
16:00-16:40 分享主题:阿里云Elasticsearch内核优化与应用实践
分享嘉宾:欧阳楚才 @阿里巴巴
主题摘要: Elasticsearch在阿里云上服务了大量的客户,同时也面临着巨大的业务挑战。阿里云ES在内核引擎、中文分词、向量检索、容器化部署等方面做了一系列开发工作,应用于文档、日志、图像、视频的检索与分析。
16:40-17:20 分享主题:码云Gitee的Elasticsearch检索优化实战
分享嘉宾:陈鑫 @码云
主题摘要: 码云(Gitee.com)的Elasticsearch应用实战,以代码仓库搜索为例,讲解Elasticsearch在分词、信息检索模型、排序模型的自定义、重写和优化经验。
17:20-18:00 抽奖 & 交流
收起阅读 »
社区日报 第772期 (2019-11-04)
http://t.cn/AiBIEfga
2、避免OOM的利器:ElasticSeach 7.x 实际内存断路器
https://www.elastic.co/cn/blog ... eaker
3、了解es 7.x使用的最新jdk12特性,避免运维踩坑
http://t.cn/ExjQUV7
编辑:cyberdak
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
http://t.cn/AiBIEfga
2、避免OOM的利器:ElasticSeach 7.x 实际内存断路器
https://www.elastic.co/cn/blog ... eaker
3、了解es 7.x使用的最新jdk12特性,避免运维踩坑
http://t.cn/ExjQUV7
编辑:cyberdak
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup 收起阅读 »
社区日报 第771期 (2019-11-03)
http://t.cn/AiByJuok
2.(自备梯子)Docker部署Elasticsearch。
http://t.cn/AiByxZxu
3.(自备梯子)什么时候需要区块链?
http://t.cn/EX7OY1A
编辑:至尊宝
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
http://t.cn/AiByJuok
2.(自备梯子)Docker部署Elasticsearch。
http://t.cn/AiByxZxu
3.(自备梯子)什么时候需要区块链?
http://t.cn/EX7OY1A
编辑:至尊宝
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup 收起阅读 »
深入理解Elasticsearch写入过程
Elasticsearch 是当前主流的搜索引擎,其具有扩展性好,查询速度快,查询结果近实时等优点,本文将对Elasticsearch的写操作进行分析。
1. lucene的写操作及其问题
Elasticsearch底层使用Lucene来实现doc的读写操作,Lucene通过
public long addDocument(...);
public long deleteDocuments(...);
public long updateDocument(...);三个方法来实现文档的写入,更新和删除操作。但是存在如下问题
- 没有并发设计
lucene只是一个搜索引擎库,并没有涉及到分布式相关的设计,因此要想使用Lucene来处理海量数据,并利用分布式的能力,就必须在其之上进行分布式的相关设计。 - 非实时
将文件写入lucence后并不能立即被检索,需要等待lucene生成一个完整的segment才能被检索 - 数据存储不可靠
写入lucene的数据不会立即被持久化到磁盘,如果服务器宕机,那存储在内存中的数据将会丢失 - 不支持部分更新
lucene中提供的updateDocuments仅支持对文档的全量更新,对部分更新不支持
2. Elasticsearch的写入方案
针对Lucene的问题,ES做了如下设计
2.1 分布式设计:
为了支持对海量数据的存储和查询,Elasticsearch引入分片的概念,一个索引被分成多个分片,每个分片可以有一个主分片和多个副本分片,每个分片副本都是一个具有完整功能的lucene实例。分片可以分配在不同的服务器上,同一个分片的不同副本不能分配在相同的服务器上。
在进行写操作时,ES会根据传入的_routing参数(或mapping中设置的_routing, 如果参数和设置中都没有则默认使用_id), 按照公式shard_num = hash(\routing) % num_primary_shards,计算出文档要分配到的分片,在从集群元数据中找出对应主分片的位置,将请求路由到该分片进行文档写操作。
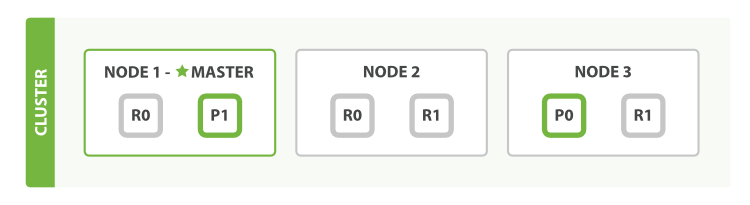
2.2 近实时性-refresh操作
当一个文档写入Lucene后是不能被立即查询到的,Elasticsearch提供了一个refresh操作,会定时地调用lucene的reopen(新版本为openIfChanged)为内存中新写入的数据生成一个新的segment,此时被处理的文档均可以被检索到。refresh操作的时间间隔由refresh_interval参数控制,默认为1s, 当然还可以在写入请求中带上refresh表示写入后立即refresh,另外还可以调用refresh API显式refresh。
2.3 数据存储可靠性
- 引入translog
当一个文档写入Lucence后是存储在内存中的,即使执行了refresh操作仍然是在文件系统缓存中,如果此时服务器宕机,那么这部分数据将会丢失。为此ES增加了translog, 当进行文档写操作时会先将文档写入Lucene,然后写入一份到translog,写入translog是落盘的(如果对可靠性要求不是很高,也可以设置异步落盘,可以提高性能,由配置index.translog.durability和index.translog.sync_interval控制),这样就可以防止服务器宕机后数据的丢失。由于translog是追加写入,因此性能比较好。与传统的分布式系统不同,这里是先写入Lucene再写入translog,原因是写入Lucene可能会失败,为了减少写入失败回滚的复杂度,因此先写入Lucene. - flush操作
另外每30分钟或当translog达到一定大小(由index.translog.flush_threshold_size控制,默认512mb), ES会触发一次flush操作,此时ES会先执行refresh操作将buffer中的数据生成segment,然后调用lucene的commit方法将所有内存中的segment fsync到磁盘。此时lucene中的数据就完成了持久化,会清空translog中的数据(6.x版本为了实现sequenceIDs,不删除translog)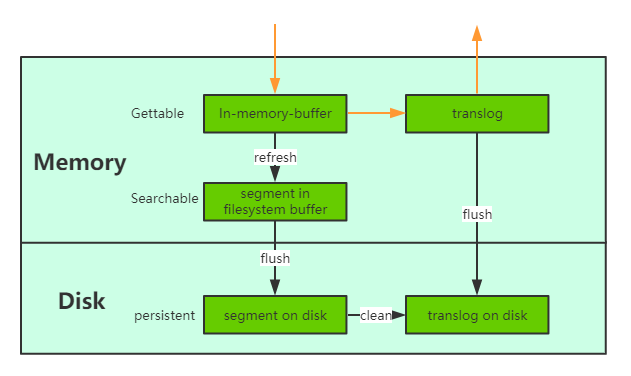
- merge操作
由于refresh默认间隔为1s中,因此会产生大量的小segment,为此ES会运行一个任务检测当前磁盘中的segment,对符合条件的segment进行合并操作,减少lucene中的segment个数,提高查询速度,降低负载。不仅如此,merge过程也是文档删除和更新操作后,旧的doc真正被删除的时候。用户还可以手动调用_forcemerge API来主动触发merge,以减少集群的segment个数和清理已删除或更新的文档。 - 多副本机制
另外ES有多副本机制,一个分片的主副分片不能分片在同一个节点上,进一步保证数据的可靠性。2.4 部分更新
lucene支持对文档的整体更新,ES为了支持局部更新,在Lucene的Store索引中存储了一个_source字段,该字段的key值是文档ID, 内容是文档的原文。当进行更新操作时先从_source中获取原文,与更新部分合并后,再调用lucene API进行全量更新, 对于写入了ES但是还没有refresh的文档,可以从translog中获取。另外为了防止读取文档过程后执行更新前有其他线程修改了文档,ES增加了版本机制,当执行更新操作时发现当前文档的版本与预期不符,则会重新获取文档再更新。
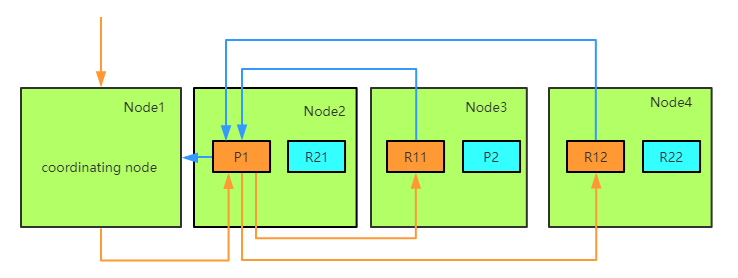
3. ES的写入流程
ES的任意节点都可以作为协调节点(coordinating node)接受请求,当协调节点接受到请求后进行一系列处理,然后通过_routing字段找到对应的primary shard,并将请求转发给primary shard, primary shard完成写入后,将写入并发发送给各replica, raplica执行写入操作后返回给primary shard, primary shard再将请求返回给协调节点。大致流程如下图:
3.1 coordinating节点
ES中接收并转发请求的节点称为coordinating节点,ES中所有节点都可以接受并转发请求。当一个节点接受到写请求或更新请求后,会执行如下操作:
- ingest pipeline
查看该请求是否符合某个ingest pipeline的pattern, 如果符合则执行pipeline中的逻辑,一般是对文档进行各种预处理,如格式调整,增加字段等。如果当前节点没有ingest角色,则需要将请求转发给有ingest角色的节点执行。 - 自动创建索引
判断索引是否存在,如果开启了自动创建则自动创建,否则报错 - 设置routing
获取请求URL或mapping中的_routing,如果没有则使用_id, 如果没有指定_id则ES会自动生成一个全局唯一ID。该_routing字段用于决定文档分配在索引的哪个shard上。 - 构建BulkShardRequest
由于Bulk Request中包含多种(Index/Update/Delete)请求,这些请求分别需要到不同的shard上执行,因此协调节点,会将请求按照shard分开,同一个shard上的请求聚合到一起,构建BulkShardRequest - 将请求发送给primary shard
因为当前执行的是写操作,因此只能在primary上完成,所以需要把请求路由到primary shard所在节点 - 等待primary shard返回
3.2 primary shard
Primary请求的入口是PrimaryOperationTransportHandler的MessageReceived, 当接收到请求时,执行的逻辑如下
- 判断操作类型
遍历bulk请求中的各子请求,根据不同的操作类型跳转到不同的处理逻辑 - 将update操作转换为Index和Delete操作
获取文档的当前内容,与update内容合并生成新文档,然后将update请求转换成index请求,此处文档设置一个version v1 - Parse Doc
解析文档的各字段,并添加如_uid等ES相关的一些系统字段 - 更新mapping
对于新增字段会根据dynamic mapping或dynamic template生成对应的mapping,如果mapping中有dynamic mapping相关设置则按设置处理,如忽略或抛出异常 - 获取sequence Id和Version
从SequcenceNumberService获取一个sequenceID和Version。SequcenID用于初始化LocalCheckPoint, verion是根据当前Versoin+1用于防止并发写导致数据不一致。 - 写入lucene
这一步开始会对文档uid加锁,然后判断uid对应的version v2和之前update转换时的versoin v1是否一致,不一致则返回第二步重新执行。 如果version一致,如果同id的doc已经存在,则调用lucene的updateDocument接口,如果是新文档则调用lucene的addDoucument. 这里有个问题,如何保证Delete-Then-Add的原子性,ES是通过在Delete之前会加上已refresh锁,禁止被refresh,只有等待Add完成后释放了Refresh Lock, 这样就保证了这个操作的原子性。 - 写入translog
写入Lucene的Segment后,会以key value的形式写Translog, Key是Id, Value是Doc的内容。当查询的时候,如果请求的是GetDocById则可以直接根据_id从translog中获取。满足nosql场景的实时性。 - 重构bulk request
因为primary shard已经将update操作转换为index操作或delete操作,因此要对之前的bulkrequest进行调整,只包含index或delete操作,不需要再进行update的处理操作。 - flush translog
默认情况下,translog要在此处落盘完成,如果对可靠性要求不高,可以设置translog异步,那么translog的fsync将会异步执行,但是落盘前的数据有丢失风险。 - 发送请求给replicas
将构造好的bulkrequest并发发送给各replicas,等待replica返回,这里需要等待所有的replicas返回,响应请求给协调节点。如果某个shard执行失败,则primary会给master发请求remove该shard。这里会同时把sequenceID, primaryTerm, GlobalCheckPoint等传递给replica。 - 等待replica响应
当所有的replica返回请求时,更细primary shard的LocalCheckPoint。
3.3 replica shard
Replica 请求的入口是在ReplicaOperationTransportHandler的messageReceived,当replica shard接收到请求时执行如下流程:
- 判断操作类型
replica收到的写如请求只会有add和delete,因update在primary shard上已经转换为add或delete了。根据不同的操作类型执行对应的操作 - Parse Doc
- 更新mapping
- 获取sequenceId和Version 直接使用primary shard发送过来的请求中的内容即可
- 写如lucene
- write Translog
- Flush translog
4 总结与分析
Elasticsearch建立在Lucene基础之上,底层采用lucene来实现文件的读写操作,实现了文档的存储和高效查询。然后lucene作为一个搜索库在应对海量数据的存储上仍有一些不足之处。
Elasticsearch通过引入分片概念,成功地将lucene部署到分布式系统中,增强了系统的可靠性和扩展性。
Elasticsearch通过定期refresh lucene in-momory-buffer中的数据,使得ES具有了近实时的写入和查询能力。
Elasticsearch通过引入translog,多副本,以及定期执行flush,merge等操作保证了数据可靠性和较高的存储性能。
Elasticsearch通过存储_source字段结合verison字段实现了文档的局部更新,使得ES的使用方式更加灵活多样。
Elasticsearch基于lucene,又不简单地只是lucene,它完美地将lucene与分布式系统结合,既利用了lucene的检索能力,又具有了分布式系统的众多优点。
本文参考
欢迎关注公众号Elastic慕容,和我一起进入Elastic的奇妙世界吧

Elasticsearch 是当前主流的搜索引擎,其具有扩展性好,查询速度快,查询结果近实时等优点,本文将对Elasticsearch的写操作进行分析。
1. lucene的写操作及其问题
Elasticsearch底层使用Lucene来实现doc的读写操作,Lucene通过
public long addDocument(...);
public long deleteDocuments(...);
public long updateDocument(...);三个方法来实现文档的写入,更新和删除操作。但是存在如下问题
- 没有并发设计
lucene只是一个搜索引擎库,并没有涉及到分布式相关的设计,因此要想使用Lucene来处理海量数据,并利用分布式的能力,就必须在其之上进行分布式的相关设计。 - 非实时
将文件写入lucence后并不能立即被检索,需要等待lucene生成一个完整的segment才能被检索 - 数据存储不可靠
写入lucene的数据不会立即被持久化到磁盘,如果服务器宕机,那存储在内存中的数据将会丢失 - 不支持部分更新
lucene中提供的updateDocuments仅支持对文档的全量更新,对部分更新不支持
2. Elasticsearch的写入方案
针对Lucene的问题,ES做了如下设计
2.1 分布式设计:
为了支持对海量数据的存储和查询,Elasticsearch引入分片的概念,一个索引被分成多个分片,每个分片可以有一个主分片和多个副本分片,每个分片副本都是一个具有完整功能的lucene实例。分片可以分配在不同的服务器上,同一个分片的不同副本不能分配在相同的服务器上。
在进行写操作时,ES会根据传入的_routing参数(或mapping中设置的_routing, 如果参数和设置中都没有则默认使用_id), 按照公式shard_num = hash(\routing) % num_primary_shards,计算出文档要分配到的分片,在从集群元数据中找出对应主分片的位置,将请求路由到该分片进行文档写操作。
2.2 近实时性-refresh操作
当一个文档写入Lucene后是不能被立即查询到的,Elasticsearch提供了一个refresh操作,会定时地调用lucene的reopen(新版本为openIfChanged)为内存中新写入的数据生成一个新的segment,此时被处理的文档均可以被检索到。refresh操作的时间间隔由refresh_interval参数控制,默认为1s, 当然还可以在写入请求中带上refresh表示写入后立即refresh,另外还可以调用refresh API显式refresh。
2.3 数据存储可靠性
- 引入translog
当一个文档写入Lucence后是存储在内存中的,即使执行了refresh操作仍然是在文件系统缓存中,如果此时服务器宕机,那么这部分数据将会丢失。为此ES增加了translog, 当进行文档写操作时会先将文档写入Lucene,然后写入一份到translog,写入translog是落盘的(如果对可靠性要求不是很高,也可以设置异步落盘,可以提高性能,由配置index.translog.durability和index.translog.sync_interval控制),这样就可以防止服务器宕机后数据的丢失。由于translog是追加写入,因此性能比较好。与传统的分布式系统不同,这里是先写入Lucene再写入translog,原因是写入Lucene可能会失败,为了减少写入失败回滚的复杂度,因此先写入Lucene. - flush操作
另外每30分钟或当translog达到一定大小(由index.translog.flush_threshold_size控制,默认512mb), ES会触发一次flush操作,此时ES会先执行refresh操作将buffer中的数据生成segment,然后调用lucene的commit方法将所有内存中的segment fsync到磁盘。此时lucene中的数据就完成了持久化,会清空translog中的数据(6.x版本为了实现sequenceIDs,不删除translog) - merge操作
由于refresh默认间隔为1s中,因此会产生大量的小segment,为此ES会运行一个任务检测当前磁盘中的segment,对符合条件的segment进行合并操作,减少lucene中的segment个数,提高查询速度,降低负载。不仅如此,merge过程也是文档删除和更新操作后,旧的doc真正被删除的时候。用户还可以手动调用_forcemerge API来主动触发merge,以减少集群的segment个数和清理已删除或更新的文档。 - 多副本机制
另外ES有多副本机制,一个分片的主副分片不能分片在同一个节点上,进一步保证数据的可靠性。2.4 部分更新
lucene支持对文档的整体更新,ES为了支持局部更新,在Lucene的Store索引中存储了一个_source字段,该字段的key值是文档ID, 内容是文档的原文。当进行更新操作时先从_source中获取原文,与更新部分合并后,再调用lucene API进行全量更新, 对于写入了ES但是还没有refresh的文档,可以从translog中获取。另外为了防止读取文档过程后执行更新前有其他线程修改了文档,ES增加了版本机制,当执行更新操作时发现当前文档的版本与预期不符,则会重新获取文档再更新。
3. ES的写入流程
ES的任意节点都可以作为协调节点(coordinating node)接受请求,当协调节点接受到请求后进行一系列处理,然后通过_routing字段找到对应的primary shard,并将请求转发给primary shard, primary shard完成写入后,将写入并发发送给各replica, raplica执行写入操作后返回给primary shard, primary shard再将请求返回给协调节点。大致流程如下图:
3.1 coordinating节点
ES中接收并转发请求的节点称为coordinating节点,ES中所有节点都可以接受并转发请求。当一个节点接受到写请求或更新请求后,会执行如下操作:
- ingest pipeline
查看该请求是否符合某个ingest pipeline的pattern, 如果符合则执行pipeline中的逻辑,一般是对文档进行各种预处理,如格式调整,增加字段等。如果当前节点没有ingest角色,则需要将请求转发给有ingest角色的节点执行。 - 自动创建索引
判断索引是否存在,如果开启了自动创建则自动创建,否则报错 - 设置routing
获取请求URL或mapping中的_routing,如果没有则使用_id, 如果没有指定_id则ES会自动生成一个全局唯一ID。该_routing字段用于决定文档分配在索引的哪个shard上。 - 构建BulkShardRequest
由于Bulk Request中包含多种(Index/Update/Delete)请求,这些请求分别需要到不同的shard上执行,因此协调节点,会将请求按照shard分开,同一个shard上的请求聚合到一起,构建BulkShardRequest - 将请求发送给primary shard
因为当前执行的是写操作,因此只能在primary上完成,所以需要把请求路由到primary shard所在节点 - 等待primary shard返回
3.2 primary shard
Primary请求的入口是PrimaryOperationTransportHandler的MessageReceived, 当接收到请求时,执行的逻辑如下
- 判断操作类型
遍历bulk请求中的各子请求,根据不同的操作类型跳转到不同的处理逻辑 - 将update操作转换为Index和Delete操作
获取文档的当前内容,与update内容合并生成新文档,然后将update请求转换成index请求,此处文档设置一个version v1 - Parse Doc
解析文档的各字段,并添加如_uid等ES相关的一些系统字段 - 更新mapping
对于新增字段会根据dynamic mapping或dynamic template生成对应的mapping,如果mapping中有dynamic mapping相关设置则按设置处理,如忽略或抛出异常 - 获取sequence Id和Version
从SequcenceNumberService获取一个sequenceID和Version。SequcenID用于初始化LocalCheckPoint, verion是根据当前Versoin+1用于防止并发写导致数据不一致。 - 写入lucene
这一步开始会对文档uid加锁,然后判断uid对应的version v2和之前update转换时的versoin v1是否一致,不一致则返回第二步重新执行。 如果version一致,如果同id的doc已经存在,则调用lucene的updateDocument接口,如果是新文档则调用lucene的addDoucument. 这里有个问题,如何保证Delete-Then-Add的原子性,ES是通过在Delete之前会加上已refresh锁,禁止被refresh,只有等待Add完成后释放了Refresh Lock, 这样就保证了这个操作的原子性。 - 写入translog
写入Lucene的Segment后,会以key value的形式写Translog, Key是Id, Value是Doc的内容。当查询的时候,如果请求的是GetDocById则可以直接根据_id从translog中获取。满足nosql场景的实时性。 - 重构bulk request
因为primary shard已经将update操作转换为index操作或delete操作,因此要对之前的bulkrequest进行调整,只包含index或delete操作,不需要再进行update的处理操作。 - flush translog
默认情况下,translog要在此处落盘完成,如果对可靠性要求不高,可以设置translog异步,那么translog的fsync将会异步执行,但是落盘前的数据有丢失风险。 - 发送请求给replicas
将构造好的bulkrequest并发发送给各replicas,等待replica返回,这里需要等待所有的replicas返回,响应请求给协调节点。如果某个shard执行失败,则primary会给master发请求remove该shard。这里会同时把sequenceID, primaryTerm, GlobalCheckPoint等传递给replica。 - 等待replica响应
当所有的replica返回请求时,更细primary shard的LocalCheckPoint。
3.3 replica shard
Replica 请求的入口是在ReplicaOperationTransportHandler的messageReceived,当replica shard接收到请求时执行如下流程:
- 判断操作类型
replica收到的写如请求只会有add和delete,因update在primary shard上已经转换为add或delete了。根据不同的操作类型执行对应的操作 - Parse Doc
- 更新mapping
- 获取sequenceId和Version 直接使用primary shard发送过来的请求中的内容即可
- 写如lucene
- write Translog
- Flush translog
4 总结与分析
Elasticsearch建立在Lucene基础之上,底层采用lucene来实现文件的读写操作,实现了文档的存储和高效查询。然后lucene作为一个搜索库在应对海量数据的存储上仍有一些不足之处。
Elasticsearch通过引入分片概念,成功地将lucene部署到分布式系统中,增强了系统的可靠性和扩展性。
Elasticsearch通过定期refresh lucene in-momory-buffer中的数据,使得ES具有了近实时的写入和查询能力。
Elasticsearch通过引入translog,多副本,以及定期执行flush,merge等操作保证了数据可靠性和较高的存储性能。
Elasticsearch通过存储_source字段结合verison字段实现了文档的局部更新,使得ES的使用方式更加灵活多样。
Elasticsearch基于lucene,又不简单地只是lucene,它完美地将lucene与分布式系统结合,既利用了lucene的检索能力,又具有了分布式系统的众多优点。
本文参考
欢迎关注公众号Elastic慕容,和我一起进入Elastic的奇妙世界吧

