

Elasitcsearch中国开发者报告调研 | 获奖名单公布
为了深入了解 Elasticsearch 开发者群体的现状,2019年11月,Elastic社区、阿里云Elasticsearch技术团队和阿里云开发者社区三方联合发起了Elasticsearch开发者研活动。
在调研过程中,1186位开发者完成了调研问卷,18位技术专家完成了专题访问。参与调研的开发者们从不同角度,分享了个人特征、社会属性、技术能力、从业经历等信息;在Elasticsearch技术的应用、行业实践、职业发展等方面,真实的提供了反馈。
作为首次国内发起的针对 Elasticsearch 开发者群体的行业性调研报告,我们希望能给更多从业者提供关于自身职业、行业以及技术应用的参照,也希望有更多的开发者关注并进入到这一特定技术领域,共同推动 Elastic Stack 相关技术持续向前发展。
以下为本次参与调研的60位幸运者名单,礼品获取信息请关注**短信通知**。

报告获取时间:2019年12月07日
钉钉扫码,加入《Elasticsearch中文技术交流群》
在2019年12月07日免费获取“Elasticsearch开发者报告”

为了深入了解 Elasticsearch 开发者群体的现状,2019年11月,Elastic社区、阿里云Elasticsearch技术团队和阿里云开发者社区三方联合发起了Elasticsearch开发者研活动。
在调研过程中,1186位开发者完成了调研问卷,18位技术专家完成了专题访问。参与调研的开发者们从不同角度,分享了个人特征、社会属性、技术能力、从业经历等信息;在Elasticsearch技术的应用、行业实践、职业发展等方面,真实的提供了反馈。
作为首次国内发起的针对 Elasticsearch 开发者群体的行业性调研报告,我们希望能给更多从业者提供关于自身职业、行业以及技术应用的参照,也希望有更多的开发者关注并进入到这一特定技术领域,共同推动 Elastic Stack 相关技术持续向前发展。
以下为本次参与调研的60位幸运者名单,礼品获取信息请关注**短信通知**。
报告获取时间:2019年12月07日
钉钉扫码,加入《Elasticsearch中文技术交流群》
在2019年12月07日免费获取“Elasticsearch开发者报告”
社区日报 第802期 (2019-12-04)
http://t.cn/AiePIiEj
2、几十亿数据查询3秒返回 Elasticsearch性能优化实战
http://t.cn/AiePIeuT
3、Spring Boot2.0 整合 ElasticSearch框架 实现高性能搜索引擎
http://t.cn/Aig6yJS8
Elastic 开发者大会参会指南
http://t.cn/AiePMrwH
编辑:江水
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup

http://t.cn/AiePIiEj
2、几十亿数据查询3秒返回 Elasticsearch性能优化实战
http://t.cn/AiePIeuT
3、Spring Boot2.0 整合 ElasticSearch框架 实现高性能搜索引擎
http://t.cn/Aig6yJS8
Elastic 开发者大会参会指南
http://t.cn/AiePMrwH
编辑:江水
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
收起阅读 »
社区日报 第801期 (2019-12-03)
http://t.cn/Aig1UdJQ
2、从12亿条社交信息泄漏看Elasticsearch安全的重要性。
http://t.cn/Aig1UDq3
3、360 私有云平台 Elasticsearch 服务初探。
http://t.cn/Aig1UFsV
编辑:叮咚光军
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub

http://t.cn/Aig1UdJQ
2、从12亿条社交信息泄漏看Elasticsearch安全的重要性。
http://t.cn/Aig1UDq3
3、360 私有云平台 Elasticsearch 服务初探。
http://t.cn/Aig1UFsV
编辑:叮咚光军
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
收起阅读 »
社区日报 第800期 (2019-12-02)
http://t.cn/AigWPmpk
2、Elasticsearch 集群协调迎来新时代
https://www.elastic.co/cn/blog ... earch
3、7.x 版本的乐观锁使用方式
https://www.elastic.co/guide/e ... .html
编辑:cyberdak
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup

http://t.cn/AigWPmpk
2、Elasticsearch 集群协调迎来新时代
https://www.elastic.co/cn/blog ... earch
3、7.x 版本的乐观锁使用方式
https://www.elastic.co/guide/e ... .html
编辑:cyberdak
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
收起阅读 »
玩转Elasticsearch routing功能
Elasticsearch是一个搭建在Lucene搜索引擎库基础之上的搜索服务平台。它在单机的Lucene搜索引擎库基础之上增加了分布式设计,translog等特性,增强了搜索引擎的性能,高可用性,高可扩性等。
Elasticsearch分布式设计的基本思想是Elasticsearch集群由多个服务器节点组成,集群中的一个索引分为多个分片,每个分片可以分配在不同的节点上。其中每个分片都是一个单独的功能完成的Lucene实例,可以独立地进行写入和查询服务,ES中存储的数据分布在集群分片的一个或多个上,其结构简单描述为下图。
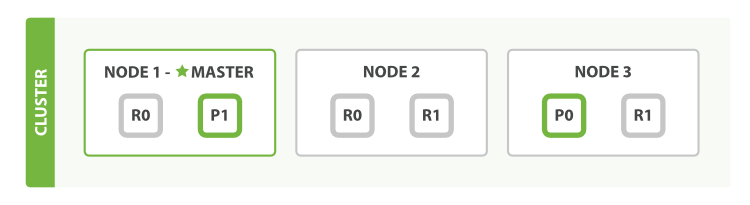
在上面的架构图中,集群由三个节点组成,每个节点上有两个分片,想要读写文档就必须知道文档被分配在哪个分片上,这也正是本文要讲的routing功能的作用。
1. 工作原理
1.1 routing参数
routing参数是一个可选参数,默认使用文档的_id值,可以用在INDEX, UPDATE,GET, SEARCH, DELETE等各种操作中。在写入(包括更新)时,用于计算文档所属分片,在查询(GET请求或指定了routing的查询)中用于限制查询范围,提高查询速度。
1.2 计算方法
ES中shardId的计算公式如下:
shardId = hash(_routing) % num_primary_shards通过该公式可以保证使用相同routing的文档被分配到同一个shard上,当然在默认情况下使用_id作为routing起到将文档均匀分布到多个分片上防止数据倾斜的作用。
1.3 routing_partition_size参数
使用了routing参数可以让routing值相同的文档分配到同一个分片上,从而减少查询时需要查询的shard数,提高查询效率。但是使用该参数容易导致数据倾斜。为此,ES还提供了一个index.routing_partition_size参数(仅当使用routing参数时可用),用于将routing相同的文档映射到集群分片的一个子集上,这样一方面可以减少查询的分片数,另一方面又可以在一定程度上防止数据倾斜。引入该参数后计算公式如下
shard_num = (hash(_routing) + hash(_id) % routing_partition_size) % num_primary_shards1.4 源码解读
如下为计算文档归属分片的源码,从源码中我们可以看到ES的哈希算法使用的是Murmur3,取模使用的是java的floorMod
version: 6.5
path: org\elasticsearch\cluster\routing\OperationRouting.java
public static int generateShardId(IndexMetaData indexMetaData, @Nullable String id, @Nullable String routing) {
final String effectiveRouting;
final int partitionOffset;
if (routing == null) {
assert(indexMetaData.isRoutingPartitionedIndex() == false) : "A routing value is required for gets from a partitioned index";
effectiveRouting = id; //默认使用id
} else {
effectiveRouting = routing;
}
if (indexMetaData.isRoutingPartitionedIndex()) {//使用了routing_partition_size参数
partitionOffset = Math.floorMod(Murmur3HashFunction.hash(id), indexMetaData.getRoutingPartitionSize());
} else {
// we would have still got 0 above but this check just saves us an unnecessary hash calculation
partitionOffset = 0;
}
return calculateScaledShardId(indexMetaData, effectiveRouting, partitionOffset);
}
private static int calculateScaledShardId(IndexMetaData indexMetaData, String effectiveRouting, int partitionOffset) {
final int hash = Murmur3HashFunction.hash(effectiveRouting) + partitionOffset;
// we don't use IMD#getNumberOfShards since the index might have been shrunk such that we need to use the size
// of original index to hash documents
return Math.floorMod(hash, indexMetaData.getRoutingNumShards()) / indexMetaData.getRoutingFactor();
}2. 存在的问题及解决方案
2.1 数据倾斜
如前面所述,用户使用自定义routing可以控制文档的分配位置,从而达到将相似文档放在同一个或同一批分片的目的,减少查询时的分片个数,提高查询速度。然而,这也意味着数据无法像默认情况那么均匀的分配到各分片和各节点上,从而会导致各节点存储和读写压力分布不均,影响系统的性能和稳定性。对此可以从以下两个方面进行优化
- 使用
routing_partition_size参数
如前面所述,该参数可以使routing相同的文档分配到一批分片(集群分片的子集)而不是一个分片上,从而可以从一定程度上减轻数据倾斜的问题。该参数的效果与其值设置的大小有关,当该值等于number_of_shard时,routing将退化为与未指定一样。当然该方法只能减轻数据倾斜,并不能彻底解决。 - 合理划分数据和设置routing值
从前面的分析,我们可以得到文档分片计算的公式,公式中的hash算法和取模算法也已经通过源码获取。因此用户在划分数据时,可以首先明确数据要划分为几类,每一类数据准备划分到哪部分分片上,再结合分片计算公式计算出合理的routing值,当然也可以在routing参数设置之前设置一个自定义hash函数来实现,从而实现数据的均衡分配。 - routing前使用自定义hash函数
很多情况下,用户并不能提前确定数据的分类值,为此可以在分类值和routing值之间设置一个hash函数,保证分类值散列后的值更均匀,使用该值作为routing,从而防止数据倾斜。
2.2 异常行为
ES的id去重是在分片维度进行的,之所以这样做是ES因为默认情况下使用_id作为routing值,这样id相同的文档会被分配到相同的分片上,因此只需要在分片维度做id去重即可保证id的唯一性。
然而当使用了自定义routing后,id相同的文档如果指定了不同的routing是可能被分配到不同的分片上的,从而导致同一个索引中出现两个id一样的文档,这里之所以说“可能”是因为如果不同的routing经过计算后仍然被映射到同一个分片上,去重还是可以生效的。因此这里会出现一个不稳定的情况,即当对id相同routing不同的文档进行写入操作时,有的时候被更新,有的时候会生成两个id相同的文档,具体可以使用下面的操作复现
# 出现两个id一样的情况
POST _bulk
{"index":{"_index":"routing_test","_id":"123","routing":"abc"}}
{"name":"zhangsan","age":18}
{"index":{"_index":"routing_test","_id":"123","routing":"xyz"}}
{"name":"lisi","age":22}
GET routing_test/_search
# 相同id被更新的情况
POST _bulk
{"index":{"_index":"routing_test_2","_id":"123","routing":"123"}}
{"name":"zhangsan","age":18}
{"index":{"_index":"routing_test_2","_id":"123","routing":"123456"}}
{"name":"lisi","age":22}
GET routing_test_2/_search以上测试场景在5.6.4, 6.4.3, 6.8.2集群上均验证会出现,在7.2.1集群上没有出现(可能是id去重逻辑发生了变化,这个后续研究一下后更新)。
对于这种场景,虽然在响应行为不一致,但是由于属于未按正常使用方式使用(id相同的文档应该使用相同的routing),也属于可以理解的情况,官方文档上也有对应描述, 参考地址
3. 常规用法
3.1 文档划分及routing指定
- 明确文档划分
使用routing是为了让查询时有可能出现在相同结果集的文档被分配到一个或一批分片上。因此首先要先明确哪些文档应该被分配在一起,对于这些文档使用相同的routing值,常规的一些自带分类信息的文档,如学生的班级属性,产品的分类等都可以作为文档划分的依据。 - 确定各类别的目标分片
当然这一步不是必须的,但是合理设置各类数据的目标分片,让他们尽量均匀分配,可以防止数据倾斜。因此建议在使用前就明确哪一类数据准备分配在哪一个或一批分片上,然后通过计算给出这类文档的合理routing值 - routing分布均匀
在很多场景下分类有哪些值不确定,因此无法明确划分各类数据的分片归属并计算出routing值,对于这种情况,建议可以在routing之前增加一个hash函数,让不同文档分类的值通过哈希尽量散列得更均匀一些,从而保证数据分布平衡。
3.2 routing的使用
- 写入操作
文档的PUT, POST, BULK操作均支持routing参数,在请求中带上routing=xxx即可。使用了routing值即可保证使用相同routing值的文档被分配到一个或一批分片上。 - GET操作
对于使用了routing写入的文档,在GET时必须指定routing,否则可能导致404,这与GET的实现机制有关,GET请求会先根据routing找到对应的分片再获取文档,如果对写入使用routing的文档GET时没有指定routing,那么会默认使用id进行routing从而大概率无法获得文档。 - 查询操作
查询操作可以在body中指定_routing参数(可以指定多个)来进行查询。当然不指定_routing也是可以查询出结果的,不过是遍历所有的分片,指定了_routing后,查询仅会对routing对应的一个或一批索引进行检索,从而提高查询效率,这也是很多用户使用routing的主要目的,查询操作示例如下:GET my_index/_search { "query": { "terms": { "_routing": [ "user1" ] } } } - UPDATE或DELETE操作
UPDATE或DELETE操作与GET操作类似,也是先根据routing确定分片,再进行更新或删除操作,因此对于写入使用了routing的文档,必须指定routing,否则会报404响应。
3.3 设置routing为必选参数
从3.2的分析可以看出对于使用routing写入的文档,在进行GET,UPDATE或DELETE操作时如果不指定routing参数会出现异常。为此ES提供了一个索引mapping级别的设置,_routing.required, 来强制用户在INDEX,GET, DELETE,UPDATA一个文档时必须使用routing参数。当然查询时不受该参数的限制的。该参数的设置方式如下:
PUT my_index
{
"mappings": {
"_doc": {
"_routing": {
"required": true
}
}
}
}3.4 routing结合别名使用
别名功能支持设置routing, 如下:
POST /_aliases
{
"actions" : [
{
"add" : {
"index" : "test",
"alias" : "alias1",
"routing" : "1"
}
}
]
}还支持查询和写入使用不同的routing,[详情参考] 将routing和别名结合,可以对使用者屏蔽读写时使用routing的细节,降低误操作的风险,提高操作的效率。
routing是ES中相对高阶一些的用法,在用户了解业务数据分布和查询需求的基础之上,可以对查询性能进行优化,然而使用不当会导致数据倾斜,重复ID等问题。本文介绍了routing的原理,问题及使用技巧,希望对大家有帮助,欢迎评论讨论
欢迎关注公众号Elastic慕容,和我一起进入Elastic的奇妙世界吧
Elasticsearch是一个搭建在Lucene搜索引擎库基础之上的搜索服务平台。它在单机的Lucene搜索引擎库基础之上增加了分布式设计,translog等特性,增强了搜索引擎的性能,高可用性,高可扩性等。
Elasticsearch分布式设计的基本思想是Elasticsearch集群由多个服务器节点组成,集群中的一个索引分为多个分片,每个分片可以分配在不同的节点上。其中每个分片都是一个单独的功能完成的Lucene实例,可以独立地进行写入和查询服务,ES中存储的数据分布在集群分片的一个或多个上,其结构简单描述为下图。
在上面的架构图中,集群由三个节点组成,每个节点上有两个分片,想要读写文档就必须知道文档被分配在哪个分片上,这也正是本文要讲的routing功能的作用。
1. 工作原理
1.1 routing参数
routing参数是一个可选参数,默认使用文档的_id值,可以用在INDEX, UPDATE,GET, SEARCH, DELETE等各种操作中。在写入(包括更新)时,用于计算文档所属分片,在查询(GET请求或指定了routing的查询)中用于限制查询范围,提高查询速度。
1.2 计算方法
ES中shardId的计算公式如下:
shardId = hash(_routing) % num_primary_shards通过该公式可以保证使用相同routing的文档被分配到同一个shard上,当然在默认情况下使用_id作为routing起到将文档均匀分布到多个分片上防止数据倾斜的作用。
1.3 routing_partition_size参数
使用了routing参数可以让routing值相同的文档分配到同一个分片上,从而减少查询时需要查询的shard数,提高查询效率。但是使用该参数容易导致数据倾斜。为此,ES还提供了一个index.routing_partition_size参数(仅当使用routing参数时可用),用于将routing相同的文档映射到集群分片的一个子集上,这样一方面可以减少查询的分片数,另一方面又可以在一定程度上防止数据倾斜。引入该参数后计算公式如下
shard_num = (hash(_routing) + hash(_id) % routing_partition_size) % num_primary_shards1.4 源码解读
如下为计算文档归属分片的源码,从源码中我们可以看到ES的哈希算法使用的是Murmur3,取模使用的是java的floorMod
version: 6.5
path: org\elasticsearch\cluster\routing\OperationRouting.java
public static int generateShardId(IndexMetaData indexMetaData, @Nullable String id, @Nullable String routing) {
final String effectiveRouting;
final int partitionOffset;
if (routing == null) {
assert(indexMetaData.isRoutingPartitionedIndex() == false) : "A routing value is required for gets from a partitioned index";
effectiveRouting = id; //默认使用id
} else {
effectiveRouting = routing;
}
if (indexMetaData.isRoutingPartitionedIndex()) {//使用了routing_partition_size参数
partitionOffset = Math.floorMod(Murmur3HashFunction.hash(id), indexMetaData.getRoutingPartitionSize());
} else {
// we would have still got 0 above but this check just saves us an unnecessary hash calculation
partitionOffset = 0;
}
return calculateScaledShardId(indexMetaData, effectiveRouting, partitionOffset);
}
private static int calculateScaledShardId(IndexMetaData indexMetaData, String effectiveRouting, int partitionOffset) {
final int hash = Murmur3HashFunction.hash(effectiveRouting) + partitionOffset;
// we don't use IMD#getNumberOfShards since the index might have been shrunk such that we need to use the size
// of original index to hash documents
return Math.floorMod(hash, indexMetaData.getRoutingNumShards()) / indexMetaData.getRoutingFactor();
}2. 存在的问题及解决方案
2.1 数据倾斜
如前面所述,用户使用自定义routing可以控制文档的分配位置,从而达到将相似文档放在同一个或同一批分片的目的,减少查询时的分片个数,提高查询速度。然而,这也意味着数据无法像默认情况那么均匀的分配到各分片和各节点上,从而会导致各节点存储和读写压力分布不均,影响系统的性能和稳定性。对此可以从以下两个方面进行优化
- 使用
routing_partition_size参数
如前面所述,该参数可以使routing相同的文档分配到一批分片(集群分片的子集)而不是一个分片上,从而可以从一定程度上减轻数据倾斜的问题。该参数的效果与其值设置的大小有关,当该值等于number_of_shard时,routing将退化为与未指定一样。当然该方法只能减轻数据倾斜,并不能彻底解决。 - 合理划分数据和设置routing值
从前面的分析,我们可以得到文档分片计算的公式,公式中的hash算法和取模算法也已经通过源码获取。因此用户在划分数据时,可以首先明确数据要划分为几类,每一类数据准备划分到哪部分分片上,再结合分片计算公式计算出合理的routing值,当然也可以在routing参数设置之前设置一个自定义hash函数来实现,从而实现数据的均衡分配。 - routing前使用自定义hash函数
很多情况下,用户并不能提前确定数据的分类值,为此可以在分类值和routing值之间设置一个hash函数,保证分类值散列后的值更均匀,使用该值作为routing,从而防止数据倾斜。
2.2 异常行为
ES的id去重是在分片维度进行的,之所以这样做是ES因为默认情况下使用_id作为routing值,这样id相同的文档会被分配到相同的分片上,因此只需要在分片维度做id去重即可保证id的唯一性。
然而当使用了自定义routing后,id相同的文档如果指定了不同的routing是可能被分配到不同的分片上的,从而导致同一个索引中出现两个id一样的文档,这里之所以说“可能”是因为如果不同的routing经过计算后仍然被映射到同一个分片上,去重还是可以生效的。因此这里会出现一个不稳定的情况,即当对id相同routing不同的文档进行写入操作时,有的时候被更新,有的时候会生成两个id相同的文档,具体可以使用下面的操作复现
# 出现两个id一样的情况
POST _bulk
{"index":{"_index":"routing_test","_id":"123","routing":"abc"}}
{"name":"zhangsan","age":18}
{"index":{"_index":"routing_test","_id":"123","routing":"xyz"}}
{"name":"lisi","age":22}
GET routing_test/_search
# 相同id被更新的情况
POST _bulk
{"index":{"_index":"routing_test_2","_id":"123","routing":"123"}}
{"name":"zhangsan","age":18}
{"index":{"_index":"routing_test_2","_id":"123","routing":"123456"}}
{"name":"lisi","age":22}
GET routing_test_2/_search以上测试场景在5.6.4, 6.4.3, 6.8.2集群上均验证会出现,在7.2.1集群上没有出现(可能是id去重逻辑发生了变化,这个后续研究一下后更新)。
对于这种场景,虽然在响应行为不一致,但是由于属于未按正常使用方式使用(id相同的文档应该使用相同的routing),也属于可以理解的情况,官方文档上也有对应描述, 参考地址
3. 常规用法
3.1 文档划分及routing指定
- 明确文档划分
使用routing是为了让查询时有可能出现在相同结果集的文档被分配到一个或一批分片上。因此首先要先明确哪些文档应该被分配在一起,对于这些文档使用相同的routing值,常规的一些自带分类信息的文档,如学生的班级属性,产品的分类等都可以作为文档划分的依据。 - 确定各类别的目标分片
当然这一步不是必须的,但是合理设置各类数据的目标分片,让他们尽量均匀分配,可以防止数据倾斜。因此建议在使用前就明确哪一类数据准备分配在哪一个或一批分片上,然后通过计算给出这类文档的合理routing值 - routing分布均匀
在很多场景下分类有哪些值不确定,因此无法明确划分各类数据的分片归属并计算出routing值,对于这种情况,建议可以在routing之前增加一个hash函数,让不同文档分类的值通过哈希尽量散列得更均匀一些,从而保证数据分布平衡。
3.2 routing的使用
- 写入操作
文档的PUT, POST, BULK操作均支持routing参数,在请求中带上routing=xxx即可。使用了routing值即可保证使用相同routing值的文档被分配到一个或一批分片上。 - GET操作
对于使用了routing写入的文档,在GET时必须指定routing,否则可能导致404,这与GET的实现机制有关,GET请求会先根据routing找到对应的分片再获取文档,如果对写入使用routing的文档GET时没有指定routing,那么会默认使用id进行routing从而大概率无法获得文档。 - 查询操作
查询操作可以在body中指定_routing参数(可以指定多个)来进行查询。当然不指定_routing也是可以查询出结果的,不过是遍历所有的分片,指定了_routing后,查询仅会对routing对应的一个或一批索引进行检索,从而提高查询效率,这也是很多用户使用routing的主要目的,查询操作示例如下:GET my_index/_search { "query": { "terms": { "_routing": [ "user1" ] } } } - UPDATE或DELETE操作
UPDATE或DELETE操作与GET操作类似,也是先根据routing确定分片,再进行更新或删除操作,因此对于写入使用了routing的文档,必须指定routing,否则会报404响应。
3.3 设置routing为必选参数
从3.2的分析可以看出对于使用routing写入的文档,在进行GET,UPDATE或DELETE操作时如果不指定routing参数会出现异常。为此ES提供了一个索引mapping级别的设置,_routing.required, 来强制用户在INDEX,GET, DELETE,UPDATA一个文档时必须使用routing参数。当然查询时不受该参数的限制的。该参数的设置方式如下:
PUT my_index
{
"mappings": {
"_doc": {
"_routing": {
"required": true
}
}
}
}3.4 routing结合别名使用
别名功能支持设置routing, 如下:
POST /_aliases
{
"actions" : [
{
"add" : {
"index" : "test",
"alias" : "alias1",
"routing" : "1"
}
}
]
}还支持查询和写入使用不同的routing,[详情参考] 将routing和别名结合,可以对使用者屏蔽读写时使用routing的细节,降低误操作的风险,提高操作的效率。
routing是ES中相对高阶一些的用法,在用户了解业务数据分布和查询需求的基础之上,可以对查询性能进行优化,然而使用不当会导致数据倾斜,重复ID等问题。本文介绍了routing的原理,问题及使用技巧,希望对大家有帮助,欢迎评论讨论
欢迎关注公众号Elastic慕容,和我一起进入Elastic的奇妙世界吧
社区日报 第799期 (2019-12-01)
http://t.cn/AigjZN3Z
2.使用Beats,logstash和Search Guard记录日志。
http://t.cn/AigjAhvi
3.(自备梯子)如果您关闭所有Google跟踪功能,Android基本上将无法使用。
http://t.cn/AigjLLx7
编辑:至尊宝
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
http://t.cn/AigjZN3Z
2.使用Beats,logstash和Search Guard记录日志。
http://t.cn/AigjAhvi
3.(自备梯子)如果您关闭所有Google跟踪功能,Android基本上将无法使用。
http://t.cn/AigjLLx7
编辑:至尊宝
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup 收起阅读 »
社区日报 第798期 (2019-11-30)
社区日报 第797期 (2019-11-29)
http://t.cn/Aig6ZMLc
2、400+节点的 Elasticsearch 集群运维之道
http://t.cn/Aig6ZK5x
3、Elasticsearch 数据建模注意事项
http://t.cn/Aig6Zppe
编辑:铭毅天下
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
http://t.cn/Aig6ZMLc
2、400+节点的 Elasticsearch 集群运维之道
http://t.cn/Aig6ZK5x
3、Elasticsearch 数据建模注意事项
http://t.cn/Aig6Zppe
编辑:铭毅天下
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup 收起阅读 »
社区日报 第796期 (2019-11-28)
http://t.cn/AidNmls5
2.Elasticsearch为什么无法支持document partially update
http://t.cn/AigVEta2
3.Elasticsearch分布式架构机制讲解
http://t.cn/AidY4W5k
4.High cardinality下对持续写入的Elasticsearch索引进行聚合查询的性能优化
http://t.cn/AigVEaUf
编辑:金桥
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
http://t.cn/AidNmls5
2.Elasticsearch为什么无法支持document partially update
http://t.cn/AigVEta2
3.Elasticsearch分布式架构机制讲解
http://t.cn/AidY4W5k
4.High cardinality下对持续写入的Elasticsearch索引进行聚合查询的性能优化
http://t.cn/AigVEaUf
编辑:金桥
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup 收起阅读 »
社区日报 第795期 (2019-11-27)
http://t.cn/AigbGqcg
2、Elasticsearch 容量规划最新官方视频介绍
http://t.cn/AigbcyqA
3、来学习下 Elastic 的 Leadership
http://t.cn/AigbcsIG
编辑:rockybean
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
http://t.cn/AigbGqcg
2、Elasticsearch 容量规划最新官方视频介绍
http://t.cn/AigbcyqA
3、来学习下 Elastic 的 Leadership
http://t.cn/AigbcsIG
编辑:rockybean
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup 收起阅读 »
Elasticsearch冷热分离原理和实践
性能与容量之间的矛盾由来已久,计算机的多级存储体系就是其中一个经典的例子,同样的问题在Elasticsearch中也存在。为了保证Elasticsearch的读写性能,官方建议磁盘使用SSD固态硬盘。然而Elasticsearch要解决的是海量数据的存储和检索问题,海量的数据就意味需要大量的存储空间,如果都使用SSD固态硬盘成本将成为一个很大的问题,这也是制约许多企业和个人使用Elasticsearch的因素之一。为了解决这个问题,Elasticsearch冷热分离架构应运而生。
1. 实现原理
1.1 节点异构
传统的Elasticsearch集群中所有节点均采用相同的配置,然而Elasticsearch并没有对节点的规格一致性做要求,换而言之就是每个节点可以是任意规格,当然这样做会导致集群各节点性能不一致,影响集群稳定性。但是如果有规则的将集群的节点分成不同类型,部分是高性能的节点用于存储热点数据,部分是性能相对差些的大容量节点用于存储冷数据,却可以一方面保证热数据的性能,另一方面保证冷数据的存储,降低存储成本,这也是Elasticsearch冷热分离架构的基本思想,如下图为一个3热节点,2冷节点的冷热分离Elasticsearch集群:
其中热节点为16核64GB 1TB SSD盘,用于满足对热数据对读写性能的要求,冷节点为8C32GB 5TB HDD在保证一定读写性能的基础之上提供了成本较低的大存储HDD盘来满足冷节点对数据存储的需求。
1.2 数据分布
集群节点异构后接着要考虑的是数据分布问题,即用户如何对冷热数据进行标识,并将冷数据移动到冷节点,热数据移动到热节点。
节点指定冷热属性
仅仅将不同的节点设置为不同的规格还不够,为了能明确区分出哪些节点是热节点,哪些节点是冷节点,需要为对应节点打标签
Elasticsearch支持给节点打标签,具体方式是在elasticsearch.yml文件中增加
node.attr.{attribute}: {value}配置。其中attribute为用户自定义的任意标签名,value为该节点对应的该标签的值,例如对于冷热分离,可以使用如下设置
node.attr.temperature: hot //热节点
node.attr.temperature: warm //冷节点ps:中文通常叫冷热,英文叫hot/warm
索引指定冷热属性
节点有了冷热属性后,接下来就是指定数据的冷热属性,来设置和调整数据分布。冷热分离方案中数据冷热分布的基本单位是索引,即指定某个索引为热索引,另一个索引为冷索引。通过索引的分布来实现控制数据分布的目的。 Elasticsearch提供了index shard filtering功能(2.x开始),该功能在索引配置中提供了如下几个配置
index.routing.allocation.include.{attribute}
Assign the index to a node whose {attribute} has at least one of the comma-separated values.
index.routing.allocation.require.{attribute}
Assign the index to a node whose {attribute} has all of the comma-separated values.
index.routing.allocation.exclude.{attribute}
Assign the index to a node whose {attribute} has none of the comma-separated values.用户可以在创建索引,或后续的任意时刻设置这些配置来控制索引在不同标签节点上的分配动作。
index.routing.allocation.include.{attribute}表示索引可以分配在包含多个值中其中一个的节点上。
index.routing.allocation.require.{attribute}表示索引要分配在包含索引指定值的节点上(通常一般设置一个值)。
index.routing.allocation.exclude.{attribute}表示索引只能分配在不包含所有指定值的节点上。
数据分布控制
Elasticsearch的索引分片分配由ShardAllocator决定,ShardAllocator通过在索引分片创建或rebalance时对每个节点调用一系列AllocationDecider来决定是否将节点分配到指定节点上,其中一个AllocationDecider是FilterAllocationDecider,该decider用于应用集群,节点的一些基于attr的分配规则,涉及到节点级别配置的核心代码如下
private Decision shouldIndexFilter(IndexMetaData indexMd, RoutingNode node, RoutingAllocation allocation) {
if (indexMd.requireFilters() != null) {
if (indexMd.requireFilters().match(node.node()) == false) {
return allocation.decision(Decision.NO, NAME, "node does not match index setting [%s] filters [%s]",
IndexMetaData.INDEX_ROUTING_REQUIRE_GROUP_PREFIX, indexMd.requireFilters());
}
}
if (indexMd.includeFilters() != null) {
if (indexMd.includeFilters().match(node.node()) == false) {
return allocation.decision(Decision.NO, NAME, "node does not match index setting [%s] filters [%s]",
IndexMetaData.INDEX_ROUTING_INCLUDE_GROUP_PREFIX, indexMd.includeFilters());
}
}
if (indexMd.excludeFilters() != null) {
if (indexMd.excludeFilters().match(node.node())) {
return allocation.decision(Decision.NO, NAME, "node matches index setting [%s] filters [%s]",
IndexMetaData.INDEX_ROUTING_EXCLUDE_GROUP_SETTING.getKey(), indexMd.excludeFilters());
}
}
return null;
}2 冷热集群搭建及使用实践
2.1 集群规格选型
根据业务数据量及读写性能要求选择合适的冷热节点规格
- 存储量计算:根据冷热数据各自数据量及要求保留时间,计算出冷热数据源数据量,然后使用如下公式计算出冷热节点各自的磁盘需求量
实际空间 = 源数据 * (1 + 副本数量) * (1 + 数据膨胀) / (1 - 内部任务开销) / (1 - 操作系统预留) ≈ 源数据 * (1 + 副本数量) * 1.45 ES建议存储容量 = 源数据 * (1 + 副本数量) * 1.45 * (1 + 预留空间) ≈ 源数据 * (1 + 副本数量) * 2.2 - 副本数量:副本有利于增加数据的可靠性,但同时会增加存储成本。默认和建议的副本数量为1,对于部分可以承受异常情况导致数据丢失的场景,可考虑设置副本数量为0。
- 数据膨胀:除原始数据外,ES 需要存储索引、列存数据等,在应用编码压缩等技术后,一般膨胀10%。
- 内部任务开销:ES 占用约20%的磁盘空间,用于 segment 合并、ES Translog、日志等。
- 操作系统预留:Linux 操作系统默认为 root 用户预留5%的磁盘空间,用于关键流程处理、系统恢复、防止磁盘碎片化问题等。
- 预留空间:为保证集群的正常运行建议预留50%的存储空间
- 计算资源预估:
ES 的计算资源主要消耗在写入和查询过程,而不同业务场景在写入和查询方面的复杂度不同、比重不同,导致计算资源相比存储资源较难评估- 日志场景:日志属于典型的写多读少类场景,计算资源主要消耗在写入过程中。我们在日志场景的经验是:2核8GB内存的资源最大可支持0.5w/s的写入能力,但注意不同业务场景可能有偏差。由于实例性能基本随计算资源总量呈线性扩容,您可以按实例资源总量估算写入能力。例如6核24GB内存的资源可支持1.5w/s的写入能力,40核160GB内存的资源可支持10w/s的写入能力。
- Metric 及 APM 等结构化数据场景:这也是写多读少类场景,但相比日志场景计算资源消耗较小,2核8GB内存的资源一般可支持1w/s的写入能力,您可参照日志场景线性扩展的方式,评估不同规格实例的实际写入能力。
- 站内搜索及应用搜索等搜索场景:此类为读多写少类场景,计算资源主要消耗在查询过程,由于查询复杂度在不同使用场景差别非常大,计算资源也最难评估,建议您结合存储资源初步选择计算资源,然后在测试过程中验证、调整。
2.2 搭建集群
- 自建
按照选定冷热节点规格部署服务器,搭建集群,热节点使用SSD盘,冷节点使用HDD盘,对热节点elasticsearcy.yml增加如下配置
node.attr.temperature: hot 对冷节点增加如下配置
node.attr.temperature: warm启动集群,冷热分离的Elasticsearch集群即搭建完成
- 购买云ES服务
腾讯云预计于12月中旬上线冷热分离集群,用户只需要在创建页面上根据需要即可分钟级拉起一个冷热分离架构的ES集群,方便快速,扩展性好,运维成本低
- 验证
使用如下命令可以验证节点冷热属性
GET _cat/nodeattrs?v&h=node,attr,value&s=attr:desc node attr value node1 temperature hot node2 temperature hot node3 temperature warm node4 temperature hot node5 temperature warm ...可以看到该集群为三热二冷的冷热分离集群(当然要注意如果其中有专用主节点或专用协调节点这类无法分配shard的节点,即使设置了冷热属性也不会有分片可以分配到其上)
3. 为索引设置冷热属性
业务方可以根据实际情况决定索引的冷热属性
- 对于热数据,索引设置如下
PUT hot_data_index/_settings { "index.routing.allocation.require.temperature": "hot" } - 对于冷数据,索引设置
PUT hot_data_index/_settings { "index.routing.allocation.require.temperature": "warm" } - 验证
创建索引PUT hot_warm_test_index { "settings": { "number_of_replicas": 1, "number_of_shards": 3 } }查看分片分配,可以看到分片均匀分配在五个节点上
GET _cat/shards/hot_warm_test_index?v&h=index,shard,prirep,node&s=node index shard prirep node hot_data_index 1 p node1 hot_data_index 0 r node1 hot_data_index 2 r node2 hot_data_index 2 p node3 hot_data_index 1 r node4 hot_data_index 0 p node5设置索引为热索引
PUT hot_warm_test_index/_settings { "index.routing.allocation.require.temperature": "hot" }查看分片分配,发现分片均分配在热节点上
GET _cat/shards/hot_warm_test_index?v&h=index,shard,prirep,node&s=node index shard prirep node hot_data_index 1 p node1 hot_data_index 0 r node1 hot_data_index 0 p node2 hot_data_index 2 r node2 hot_data_index 2 p node4 hot_data_index 1 r node4设置索引为冷索引
PUT hot_warm_test_index/_settings { "index.routing.allocation.require.temperature": "warm" }查看分片分配,发现分片均分配到冷节点上
GET _cat/shards/hot_warm_test_index?v&h=index,shard,prirep,node&s=node index shard prirep node hot_data_index 1 p node3 hot_data_index 0 r node3 hot_data_index 2 r node3 hot_data_index 0 p node5 hot_data_index 2 p node5 hot_data_index 1 r node5
4. 索引生命周期管理
从ES6.6开始,Elasticsearch提供索引生命周期管理功能,索引生命周期管理可以通过API或者kibana界面配置,详情参考[index-lifecycle-management], 本文仅通过kibana界面演示如何使用索引生命周期管理结合冷热分离架构实现索引数据的动态管理。
kibana中的索引生命周期管理位置如下图(版本6.8.2):
点击创建create policy,进入配置界面,可以看到索引的生命周期被分为:
Hot phrase,Warm phase, Cold phase,Delete phrase四个阶段
- Hot phrase: 该阶段可以根据索引的文档数,大小,时长决定是否调用rollover API来滚动索引,详情可以参考[indices-rollover-index],因与本文关系不大不再详细赘述。
- Warm phrase: 当一个索引在Hot phrase被roll over后便会进入Warm phrase,进入该阶段的索引会被设置为read-only, 用户可以为这个索引设置要使用的attribute, 如对于冷热分离策略,这里可以选择temperature: warm属性。另外还可以对索引进行forceMerge, shrink等操作,这两个操作具体可以参考官方文档。
- Cold phrase: 可以设置当索引rollover一段时间后进入cold阶段,这个阶段也可以设置一个属性。从冷热分离架构可以看出冷热属性是具备扩展性的,不仅可以指定hot, warm, 也可以扩展增加hot, warm, cold, freeze等多个冷热属性。如果想使用三层的冷热分离的话这里可以指定为temperature: cold, 此处还支持对索引的freeze操作,详情参考官方文档。
- Delete phrase: 可以设置索引rollover一段时间后进入delete阶段,进入该阶段的索引会自动被删除。
冷热分离架构是Elasticsearch的经典架构之一,使用该架构用户可以在保证热数据良好读写性能的同时,仍可以存储海量的数据,极大地丰富了ES的应用场景,解决了用户的成本问题。再结合ES在6.6推出的索引生命周期管理,使得ES集群在使用性和自动化方面表现出色,真正地解决了用户在性能,存储成本,自动化数据管理等方面的问题。
欢迎关注公众号Elastic慕容,和我一起进入Elastic的奇妙世界吧
性能与容量之间的矛盾由来已久,计算机的多级存储体系就是其中一个经典的例子,同样的问题在Elasticsearch中也存在。为了保证Elasticsearch的读写性能,官方建议磁盘使用SSD固态硬盘。然而Elasticsearch要解决的是海量数据的存储和检索问题,海量的数据就意味需要大量的存储空间,如果都使用SSD固态硬盘成本将成为一个很大的问题,这也是制约许多企业和个人使用Elasticsearch的因素之一。为了解决这个问题,Elasticsearch冷热分离架构应运而生。
1. 实现原理
1.1 节点异构
传统的Elasticsearch集群中所有节点均采用相同的配置,然而Elasticsearch并没有对节点的规格一致性做要求,换而言之就是每个节点可以是任意规格,当然这样做会导致集群各节点性能不一致,影响集群稳定性。但是如果有规则的将集群的节点分成不同类型,部分是高性能的节点用于存储热点数据,部分是性能相对差些的大容量节点用于存储冷数据,却可以一方面保证热数据的性能,另一方面保证冷数据的存储,降低存储成本,这也是Elasticsearch冷热分离架构的基本思想,如下图为一个3热节点,2冷节点的冷热分离Elasticsearch集群:
其中热节点为16核64GB 1TB SSD盘,用于满足对热数据对读写性能的要求,冷节点为8C32GB 5TB HDD在保证一定读写性能的基础之上提供了成本较低的大存储HDD盘来满足冷节点对数据存储的需求。
1.2 数据分布
集群节点异构后接着要考虑的是数据分布问题,即用户如何对冷热数据进行标识,并将冷数据移动到冷节点,热数据移动到热节点。
节点指定冷热属性
仅仅将不同的节点设置为不同的规格还不够,为了能明确区分出哪些节点是热节点,哪些节点是冷节点,需要为对应节点打标签
Elasticsearch支持给节点打标签,具体方式是在elasticsearch.yml文件中增加
node.attr.{attribute}: {value}配置。其中attribute为用户自定义的任意标签名,value为该节点对应的该标签的值,例如对于冷热分离,可以使用如下设置
node.attr.temperature: hot //热节点
node.attr.temperature: warm //冷节点ps:中文通常叫冷热,英文叫hot/warm
索引指定冷热属性
节点有了冷热属性后,接下来就是指定数据的冷热属性,来设置和调整数据分布。冷热分离方案中数据冷热分布的基本单位是索引,即指定某个索引为热索引,另一个索引为冷索引。通过索引的分布来实现控制数据分布的目的。 Elasticsearch提供了index shard filtering功能(2.x开始),该功能在索引配置中提供了如下几个配置
index.routing.allocation.include.{attribute}
Assign the index to a node whose {attribute} has at least one of the comma-separated values.
index.routing.allocation.require.{attribute}
Assign the index to a node whose {attribute} has all of the comma-separated values.
index.routing.allocation.exclude.{attribute}
Assign the index to a node whose {attribute} has none of the comma-separated values.用户可以在创建索引,或后续的任意时刻设置这些配置来控制索引在不同标签节点上的分配动作。
index.routing.allocation.include.{attribute}表示索引可以分配在包含多个值中其中一个的节点上。
index.routing.allocation.require.{attribute}表示索引要分配在包含索引指定值的节点上(通常一般设置一个值)。
index.routing.allocation.exclude.{attribute}表示索引只能分配在不包含所有指定值的节点上。
数据分布控制
Elasticsearch的索引分片分配由ShardAllocator决定,ShardAllocator通过在索引分片创建或rebalance时对每个节点调用一系列AllocationDecider来决定是否将节点分配到指定节点上,其中一个AllocationDecider是FilterAllocationDecider,该decider用于应用集群,节点的一些基于attr的分配规则,涉及到节点级别配置的核心代码如下
private Decision shouldIndexFilter(IndexMetaData indexMd, RoutingNode node, RoutingAllocation allocation) {
if (indexMd.requireFilters() != null) {
if (indexMd.requireFilters().match(node.node()) == false) {
return allocation.decision(Decision.NO, NAME, "node does not match index setting [%s] filters [%s]",
IndexMetaData.INDEX_ROUTING_REQUIRE_GROUP_PREFIX, indexMd.requireFilters());
}
}
if (indexMd.includeFilters() != null) {
if (indexMd.includeFilters().match(node.node()) == false) {
return allocation.decision(Decision.NO, NAME, "node does not match index setting [%s] filters [%s]",
IndexMetaData.INDEX_ROUTING_INCLUDE_GROUP_PREFIX, indexMd.includeFilters());
}
}
if (indexMd.excludeFilters() != null) {
if (indexMd.excludeFilters().match(node.node())) {
return allocation.decision(Decision.NO, NAME, "node matches index setting [%s] filters [%s]",
IndexMetaData.INDEX_ROUTING_EXCLUDE_GROUP_SETTING.getKey(), indexMd.excludeFilters());
}
}
return null;
}2 冷热集群搭建及使用实践
2.1 集群规格选型
根据业务数据量及读写性能要求选择合适的冷热节点规格
- 存储量计算:根据冷热数据各自数据量及要求保留时间,计算出冷热数据源数据量,然后使用如下公式计算出冷热节点各自的磁盘需求量
实际空间 = 源数据 * (1 + 副本数量) * (1 + 数据膨胀) / (1 - 内部任务开销) / (1 - 操作系统预留) ≈ 源数据 * (1 + 副本数量) * 1.45 ES建议存储容量 = 源数据 * (1 + 副本数量) * 1.45 * (1 + 预留空间) ≈ 源数据 * (1 + 副本数量) * 2.2 - 副本数量:副本有利于增加数据的可靠性,但同时会增加存储成本。默认和建议的副本数量为1,对于部分可以承受异常情况导致数据丢失的场景,可考虑设置副本数量为0。
- 数据膨胀:除原始数据外,ES 需要存储索引、列存数据等,在应用编码压缩等技术后,一般膨胀10%。
- 内部任务开销:ES 占用约20%的磁盘空间,用于 segment 合并、ES Translog、日志等。
- 操作系统预留:Linux 操作系统默认为 root 用户预留5%的磁盘空间,用于关键流程处理、系统恢复、防止磁盘碎片化问题等。
- 预留空间:为保证集群的正常运行建议预留50%的存储空间
- 计算资源预估:
ES 的计算资源主要消耗在写入和查询过程,而不同业务场景在写入和查询方面的复杂度不同、比重不同,导致计算资源相比存储资源较难评估- 日志场景:日志属于典型的写多读少类场景,计算资源主要消耗在写入过程中。我们在日志场景的经验是:2核8GB内存的资源最大可支持0.5w/s的写入能力,但注意不同业务场景可能有偏差。由于实例性能基本随计算资源总量呈线性扩容,您可以按实例资源总量估算写入能力。例如6核24GB内存的资源可支持1.5w/s的写入能力,40核160GB内存的资源可支持10w/s的写入能力。
- Metric 及 APM 等结构化数据场景:这也是写多读少类场景,但相比日志场景计算资源消耗较小,2核8GB内存的资源一般可支持1w/s的写入能力,您可参照日志场景线性扩展的方式,评估不同规格实例的实际写入能力。
- 站内搜索及应用搜索等搜索场景:此类为读多写少类场景,计算资源主要消耗在查询过程,由于查询复杂度在不同使用场景差别非常大,计算资源也最难评估,建议您结合存储资源初步选择计算资源,然后在测试过程中验证、调整。
2.2 搭建集群
- 自建
按照选定冷热节点规格部署服务器,搭建集群,热节点使用SSD盘,冷节点使用HDD盘,对热节点elasticsearcy.yml增加如下配置
node.attr.temperature: hot 对冷节点增加如下配置
node.attr.temperature: warm启动集群,冷热分离的Elasticsearch集群即搭建完成
- 购买云ES服务
腾讯云预计于12月中旬上线冷热分离集群,用户只需要在创建页面上根据需要即可分钟级拉起一个冷热分离架构的ES集群,方便快速,扩展性好,运维成本低
- 验证
使用如下命令可以验证节点冷热属性
GET _cat/nodeattrs?v&h=node,attr,value&s=attr:desc node attr value node1 temperature hot node2 temperature hot node3 temperature warm node4 temperature hot node5 temperature warm ...可以看到该集群为三热二冷的冷热分离集群(当然要注意如果其中有专用主节点或专用协调节点这类无法分配shard的节点,即使设置了冷热属性也不会有分片可以分配到其上)
3. 为索引设置冷热属性
业务方可以根据实际情况决定索引的冷热属性
- 对于热数据,索引设置如下
PUT hot_data_index/_settings { "index.routing.allocation.require.temperature": "hot" } - 对于冷数据,索引设置
PUT hot_data_index/_settings { "index.routing.allocation.require.temperature": "warm" } - 验证
创建索引PUT hot_warm_test_index { "settings": { "number_of_replicas": 1, "number_of_shards": 3 } }查看分片分配,可以看到分片均匀分配在五个节点上
GET _cat/shards/hot_warm_test_index?v&h=index,shard,prirep,node&s=node index shard prirep node hot_data_index 1 p node1 hot_data_index 0 r node1 hot_data_index 2 r node2 hot_data_index 2 p node3 hot_data_index 1 r node4 hot_data_index 0 p node5设置索引为热索引
PUT hot_warm_test_index/_settings { "index.routing.allocation.require.temperature": "hot" }查看分片分配,发现分片均分配在热节点上
GET _cat/shards/hot_warm_test_index?v&h=index,shard,prirep,node&s=node index shard prirep node hot_data_index 1 p node1 hot_data_index 0 r node1 hot_data_index 0 p node2 hot_data_index 2 r node2 hot_data_index 2 p node4 hot_data_index 1 r node4设置索引为冷索引
PUT hot_warm_test_index/_settings { "index.routing.allocation.require.temperature": "warm" }查看分片分配,发现分片均分配到冷节点上
GET _cat/shards/hot_warm_test_index?v&h=index,shard,prirep,node&s=node index shard prirep node hot_data_index 1 p node3 hot_data_index 0 r node3 hot_data_index 2 r node3 hot_data_index 0 p node5 hot_data_index 2 p node5 hot_data_index 1 r node5
4. 索引生命周期管理
从ES6.6开始,Elasticsearch提供索引生命周期管理功能,索引生命周期管理可以通过API或者kibana界面配置,详情参考[index-lifecycle-management], 本文仅通过kibana界面演示如何使用索引生命周期管理结合冷热分离架构实现索引数据的动态管理。
kibana中的索引生命周期管理位置如下图(版本6.8.2):
点击创建create policy,进入配置界面,可以看到索引的生命周期被分为:
Hot phrase,Warm phase, Cold phase,Delete phrase四个阶段
- Hot phrase: 该阶段可以根据索引的文档数,大小,时长决定是否调用rollover API来滚动索引,详情可以参考[indices-rollover-index],因与本文关系不大不再详细赘述。
- Warm phrase: 当一个索引在Hot phrase被roll over后便会进入Warm phrase,进入该阶段的索引会被设置为read-only, 用户可以为这个索引设置要使用的attribute, 如对于冷热分离策略,这里可以选择temperature: warm属性。另外还可以对索引进行forceMerge, shrink等操作,这两个操作具体可以参考官方文档。
- Cold phrase: 可以设置当索引rollover一段时间后进入cold阶段,这个阶段也可以设置一个属性。从冷热分离架构可以看出冷热属性是具备扩展性的,不仅可以指定hot, warm, 也可以扩展增加hot, warm, cold, freeze等多个冷热属性。如果想使用三层的冷热分离的话这里可以指定为temperature: cold, 此处还支持对索引的freeze操作,详情参考官方文档。
- Delete phrase: 可以设置索引rollover一段时间后进入delete阶段,进入该阶段的索引会自动被删除。
冷热分离架构是Elasticsearch的经典架构之一,使用该架构用户可以在保证热数据良好读写性能的同时,仍可以存储海量的数据,极大地丰富了ES的应用场景,解决了用户的成本问题。再结合ES在6.6推出的索引生命周期管理,使得ES集群在使用性和自动化方面表现出色,真正地解决了用户在性能,存储成本,自动化数据管理等方面的问题。
欢迎关注公众号Elastic慕容,和我一起进入Elastic的奇妙世界吧
社区日报 第793期 (2019-11-25)
http://t.cn/Ex5GjNQ
2、解决es以及kibana的时区展示问题
http://t.cn/Aid199Ur
3、再一次了解Elasticsearch的机器学习功能
http://t.cn/EKQCgbL
编辑:cyberdak
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
http://t.cn/Ex5GjNQ
2、解决es以及kibana的时区展示问题
http://t.cn/Aid199Ur
3、再一次了解Elasticsearch的机器学习功能
http://t.cn/EKQCgbL
编辑:cyberdak
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup 收起阅读 »
You know, for search--带你认识Elasticsearch
Elasticsearch作为当前流行的分布式搜索引擎,被广泛应用于日志检索,指标采集,APM,安全分析等领域。本文将对Elastic Stack的发展历程,基本原理,产品生态,主要功能和应用场景进行总结,以帮助大家对Elastic生态的前世今生能有一个清晰的了解。
1. 发展历程
1.1 美好的事物总有一个浪漫的开始
许多年前,一个叫Shay Banon的年轻人想为正在学习厨艺的新婚妻子编写一款菜谱搜索软件。在开发过程中,他发现搜索引擎库Lucene不仅使用门槛高,还有会有许多重复性工作。因此他决定在lucene基础之上封装一个简单易用的搜索应用库,并命名为Compress。Elasticsearch的前身就在这样浪漫的机缘下诞生了。
1.2 分布式为其注入了新的活力
之后shay找到了一份工作,工作内容涉及到大量的高并发分布式场景,于是他决定重写Compress,引入了分布式架构,并更名为Elasticsearch。Elasticsearch的第一个版本发布于2010年5月,发布后公众反响强烈。
1.3 开源力量助其腾飞
Elasticsearch在github上发布后,使用量骤增,并很快有了自己的社区。很快,社区中的 Steven Schuurman、Uri Boness 和 Simon Willnauer 与Shay Banon 一起成立了一家搜索公司Elasticsearch Inc.。
在Elasticsearch Inc.公司成立前后,另外两个开源项目也正在快速发展。一个是Jordan Sissel的开源可插拔数据采集工具Logstash, 另一个是Rashid Khan的开源数据可视化UI Kibana。由于作者间对彼此产品比较熟悉,因此决定合作发展,最终形成了Elastic Stack的经典技术栈ELK: Elasticsearch, Logstash, Kibana。
1.4 快速成长
| 之后Elasticsearch迅速发展,增加了许多新功能和特性 版本 | 发布日志 | 重要特性 |
|---|---|---|
| 0.7.0 | 2010.5.14 | github上第一个版本 |
| 1.0.0 | 2014.2.14 | 备份恢复,聚合,熔断器,docvalues等 |
| 2.0.0 | 2015.10.28 | 组件版本统一,推出Elastic Cloud等 |
| 5.0.0 | 2016.10.26 | 商业组件整合为x-pack;使用Lucene6.0引入BKD树,稀疏数据优化等; beat引入module概念; 增加machine learning功能; shrink API; ingest node; painless 脚本等 |
| 6.0.0 | 2017.8.31 | 稀疏性docvalues支持,index sorting, sequence num, 滚动升级等 |
| 7.0.0 | 2019.4.10 | 引入新的集群协调层zen2; real内存熔断器等 |
2018年美东时间10月5日上午 9:30 整,纽约证券交易所的铃声响起,Elastic 成功上市。
2. 基本原理
2.1 最初的想法
Elasticsearch是一个分布式搜索引擎,底层使用Lucene来实现其核心搜索功能。虽然当前Elasticsearch拥有的众多的功能和解决方案,但是其核心仍然是全文检索。
- 什么是全文检索?
生活中的数据可以分为结构化数据和非结构化数据。结构化数据是指格式和长度固定的数据,如一个人的年龄,姓名等。非结构化数据是指格式和长度不固定的数据,如一个文章的内容等。
对于结构化数据,可以存储在DB中通过精确匹配找到。但是对于非结构化数据,一般查询时只能提供查询的局部信息或模糊信息,传统数据库无法根据这些信息进行查询(或者说效率很差)。 - 如何解决全文检索-倒排索引
倒排索引时相对于正排索引而言的,如下图是正排索引和倒排索引的对比
正排索引可以通过id查找到对应的文章,但是无法通过给的部分内容如love,找出含有该关键字的文档。 倒排索引会先对文档进行分析将其拆分成单个Term, 并存储包含该Term的文档id,这样便可以实现通过内容查找对应文档,如包含love的文档为文档1的第二个位置和文档2的第二个位置。倒排索引的逻辑结构如下图:
当然这样的倒排索引建立起来会导致索引的大小迅速膨胀,lucene对此引入了一个特殊的数据结构叫FST,用于解决这个问题。感兴趣的朋友可以查询资料了解,公众号里后续也会专门介绍该数据结构。
2.2 Elasticsearch的改进
使用倒排索引实现全文检索都是Lucene已经具备的能力,Elasticsearch只是将这个能力封装起来提供给用户使用。那么Elasticsearch在lucene之上做了哪些改进和优化呢? 首先我们先了解一下Lucene中的几个基本概念
- Index(索引):一类业务数据的集合,类似于传统数据库DB的概念。
- Document(文档):一条完整的数据记录,json格式,是数据存储和检索的基本单位,类似于传统数据库的一条记录。
- Field(字段):文档的具体一个属性,类似于传统数据库的列。
- Term(分词):全文检索特有词汇,在存储文档字段或检索时会先对传入的值进行拆分,使用拆分后的词进行存储和检索。
2.2.1 分布式设计:
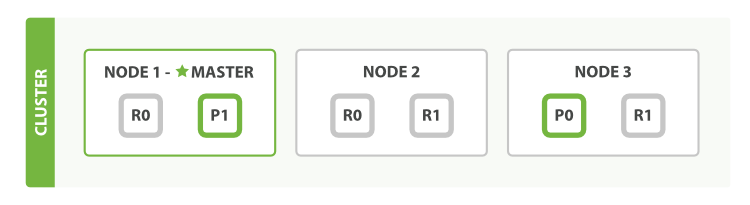
为了支持对海量数据的存储和查询,Elasticsearch引入分片的概念,一个索引被分成多个分片,每个分片可以有一个主分片和多个副本分片,每个分片副本都是一个具有完整功能的lucene实例,可以独立进行存储和搜索。分片可以分配在不同的节点上,同一个分片的不同副本不能分配在相同的节点上。 在进行读写操作时,ES会根据传入的_routing参数(或mapping中设置的_routing, 如果参数和设置中都没有则默认使用_id), 按照公式
shard_num = hash(\routing) % num_primary_shards,计算出文档要所在或要分配到的分片,再从集群元数据中找出对应主分片的位置,将请求路由到该分片进行读写操作。
2.2.2 近实时性-refresh操作
当一个文档写入Lucene后是不能被立即查询到的,Elasticsearch提供了一个refresh操作,会定时地调用lucene的reopen(新版本为openIfChanged)为内存中新写入的数据生成一个新的segment,此时被处理的文档均可以被检索到。refresh操作的时间间隔由refresh_interval参数控制,默认为1s, 当然还可以在写入请求中带上refresh表示写入后立即refresh,另外还可以调用refresh API显式refresh。
2.2.3 数据存储可靠性
- 引入translog
当一个文档写入Lucence后是存储在内存中的,即使执行了refresh操作仍然是在文件系统缓存中,如果此时服务器宕机,那么这部分数据将会丢失。为此ES增加了translog, 当进行文档写操作时会先将文档写入Lucene,然后写入一份到translog,写入translog是落盘的(如果对可靠性要求不是很高,也可以设置异步落盘,可以提高性能,由配置
index.translog.durability和index.translog.sync_interval控制),这样就可以防止服务器宕机后数据的丢失。与传统的分布式系统不同,这里是先写入Lucene再写入translog,原因是写入Lucene可能会失败,为了减少写入失败回滚的复杂度,因此先写入Lucene. - flush操作
另外每30分钟或当translog达到一定大小(由
index.translog.flush_threshold_size控制,默认512mb), ES会触发一次flush操作,此时ES会先执行refresh操作将buffer中的数据生成segment,然后调用lucene的commit方法将所有内存中的segment fsync到磁盘。此时lucene中的数据就完成了持久化,会清空translog中的数据(6.x版本为了实现sequenceIDs,不删除translog)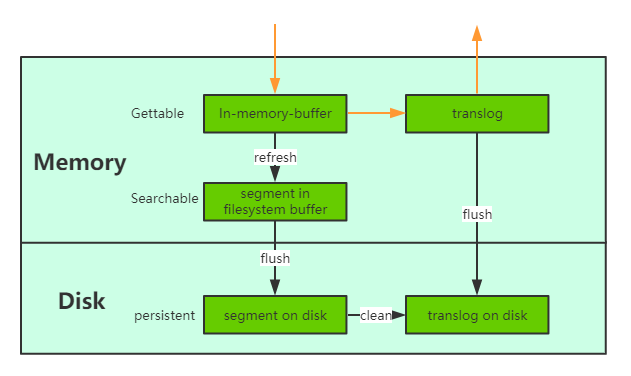
- merge操作 由于refresh默认间隔为1s中,因此会产生大量的小segment,为此ES会运行一个任务检测当前磁盘中的segment,对符合条件的segment进行合并操作,减少lucene中的segment个数,提高查询速度,降低负载。不仅如此,merge过程也是文档删除和更新操作后,旧的doc真正被删除的时候。用户还可以手动调用_forcemerge API来主动触发merge,以减少集群的segment个数和清理已删除或更新的文档。
- 多副本机制 另外ES有多副本机制,一个分片的主副分片不能分片在同一个节点上,进一步保证数据的可靠性。
2.2.4 部分更新
lucene支持对文档的整体更新,ES为了支持局部更新,在Lucene的Store索引中存储了一个_source字段,该字段的key值是文档ID, 内容是文档的原文。当进行更新操作时先从_source中获取原文,与更新部分合并后,再调用lucene API进行全量更新, 对于写入了ES但是还没有refresh的文档,可以从translog中获取。另外为了防止读取文档过程后执行更新前有其他线程修改了文档,ES增加了版本机制,当执行更新操作时发现当前文档的版本与预期不符,则会重新获取文档再更新。
3 Elastic Stack生态
Elasticsearch相对于其他的搜索引擎最大的优势之一就是完整的产品矩阵和活跃的社区,下图是Elastic Stack的产品矩阵
3.1 Elastic大数据平台
产品矩阵中最核心的部分是Elastic大数据平台,也就是大家所熟知的ELK(现在应该叫ELKB)。其中
- Elasticsearch是其中的搜索引擎,是整个Elastic Stack的核心所在,它底层使用Lucene,对外提供分布式的高可用,易扩展,近实时的数据存储和检索服务。
- Logstash是一个数据采集工具。在早期的Elastic Stack中起到数据采集,处理的作用,在新的架构中,数据采集工作交给了更轻量级的beat来完成,Logstash则更多地用在数据汇聚,处理场景下。Logstash提供了200+的插件来支持各种各样的数据采集和数据场景,极大地提高了Elastic stack在各种应用场景下的应用能力。
- Beats是一个轻量级的数据采集agent,部署在数据采集端,所有的beat底层都基于libbeat,并在其基础之上针对各种应用场景实现数据的采集和传输功能。目前除了官方提供的Filebeat,MetricBeat,PacketB eat等之外,还有大量社区贡献的beat,可以适应各种数据采集场景的需要。
- Kibana是ELK中的数据可视化工具,提供了如Discover(搜索),DashBoard(仪表盘),DevTools(开发工具),Monitoring(监控),MachineLearning(机器学习), SIEM(安全分析),Management(管理)等多种功能,极大地降低了Elasticsearch用户的使用门槛和操作复杂度。
3.2 X-PACK工具包
从5.x开始,Elastic stack将ES的商业功能特性整合到了X-PACK中, 该工具包提供了包括机器学习,规格告警,高级安全特性等在内的众多特性,为使用方提供了更为丰富和专业的功能。
3.3 解决方案
Elastic Stack完善的产品矩阵和活跃的社区,使用ES被广泛应用于各种领域,如搜索,日志,指标,APM,安全,企业搜索等。用户的使用场景和经验反馈,进而促使了Elastic stack在大数据分析平台的基础之上构建一些更完整的,易于上手的解决方案。
如各种beat moudle,用户只需要简单的配置就可以快速地搭建日志或指标采集方案和对应的分析视图。
如APM server和agent,用户只需要根据指引,配置对应server和agent即可快速搭建APM服务。
如SIEM,集成了安全分析的许多功能模块,极大地满足了安全分析的需要。
3.4 Elastic云服务
为了能让用户更方便地使用Elastic Stack的功能,Elastic还提供了托管式云服务。用户只需要通过简单地配置即可快速搭建起Elastic Stack服务,极大地简化了用户的搭建流程。
在国内,Elastic还与腾讯云,阿里云等云厂商合作,提供了Elastic云服务,使得国内用户也能快捷方便地搭建起Elastic服务。
4. 主要功能
Elastic Stack发展至今已拥有丰富的功能
4.1 强大的查询能力
Elasticsearch是一个搜索引擎,而判断一个搜索引擎的优劣,就是看其对查询的支持能力。如下图为Elasticsearch支持的查询功能
基础查询能力上Elasticseach支持精确查询,全文查询,地理位置查询和一些高级查询。
Elasticsearch还支持对这些基础查询进行组合查询,并且可以调整各子查询的权重等
Elasticsearch在聚合层面也提供了强大的支持,不仅支持简单的像SUM, MAX这样的指标查询,还支持分桶查询。另外还支持对其他聚合结果的聚合Pipeline查询。
4.2 丰富的存储类型
Elasticsearch支持包括String(text/keyword), Numeric(long, integer, short ...), Date, Boolean, Binary, Range等多种数据类型,还支持如Nested, join, object, Geo-shape, Sparse vectord等多种数据类型,针对每种数据类型进行了特定的存储和检索优化,以应对不同场景的使用需要
4.3 强大的数据采集和管理能力
- 数据采集和处理:Elastic Stack的beats和Logstash不仅提供了大量的官方插件,还有大量的社区贡献,可以满足各种场景的数据采集和处理需求。另外Elastic的ingest node 也提供了丰富的数据预处理能力。
- 快照备份和恢复:支持将部分或全部数据备份到指定数据源,并支持插件开发
- 索引声明周期管理:用户可以通过配置,使集群可以自动对数据进行roll over, 降冷,关闭或或删除等操作,提高了数据的持续管理能力。
4.4 安全性
Elasticsearch提供了加密通信,基于角色的访问控制,基于属性的访问控制,LDAP,令牌服务等多种安全功能,可以满足用户在安全方面的各种需求。
4.5 监控和告警
Elasticseasrch提供了对Elastic Stack组件的监控及告警能力,极大地方便了用户对Elastic Stack运行状态的了解和对问题的定位修复。
Elasitc提供了Altering功能,用户可以根据业务需要配置规则,实现满足业务需要的规则告警
4.6 机器学习
Elasticsearch当前提供了非监督机器学习功能,该功能当前主要用在异常检测方面。在日志检索,指标,APM,安全分析等领域均有使用。
由于功能太多这里就不一一列举了,详情可以参考:[Elastic Subscription]
5 应用场景
Elasticsearch有着广泛的应用场景,借助其强大的检索能力,其当前主要应用在搜索,日志分析,指标,APM,安全分析等领域。
5.1 搜索
Elasticsearch作为搜索引擎,其对绝大多数类型的搜索功能提供了支持。由于其具有可扩展性好,安全性高,近实时,功能全面等优点,其广泛应用在各种应用搜索,站内搜,企业搜索,代码搜索等场景。
5.2 日志分析
日志分析是Elasticsearch应用最广泛的领域,由于其ELK架构可以实现快速搭建和使用,再加上其强大的检索能力,使得其深受广大运维同学喜爱。
5.3 指标
Elasticsearch5.x开始使用lucene6.0,该版本引入了BKD 树,并对稀疏数据进行了优化,使得数值数据的存储和查询性能得到了很大提升。Elasticsearch也因此得以可以广泛应用于指标监控。
5.4 APM
Elastic Stack提供APM serverh和APM anget,用于帮助用户实现APM功能。APM功能来源于之前的Opbeat。Opbeat是由一个丹麦初创团队研发,该团队主打产品就是APM运维软件。
5.5 安全分析
随着互联网技术的蓬勃发展,安全分析领域开始面临海量数据存储和查询分析问题,Elastic为安全领域提供了从数据采集,数据格式处理,异常检测,可视化分析等一整套解决方案,极大地方便了安全分析在海量数据场景下的进行。在7.x版本的Kibana中甚至直接增加了一个SIEM应用,用于向安全分析领域提供完整的解决方案。
本文对Elasticsearch的发展历程,基本原理,主要功能和应用场景进行了简单总结,希望能帮助大家对Elasticsearch有一个条理清晰的了解。
欢迎关注公众号Elastic慕容,和我一起进入Elastic的奇妙世界吧
Elasticsearch作为当前流行的分布式搜索引擎,被广泛应用于日志检索,指标采集,APM,安全分析等领域。本文将对Elastic Stack的发展历程,基本原理,产品生态,主要功能和应用场景进行总结,以帮助大家对Elastic生态的前世今生能有一个清晰的了解。
1. 发展历程
1.1 美好的事物总有一个浪漫的开始
许多年前,一个叫Shay Banon的年轻人想为正在学习厨艺的新婚妻子编写一款菜谱搜索软件。在开发过程中,他发现搜索引擎库Lucene不仅使用门槛高,还有会有许多重复性工作。因此他决定在lucene基础之上封装一个简单易用的搜索应用库,并命名为Compress。Elasticsearch的前身就在这样浪漫的机缘下诞生了。
1.2 分布式为其注入了新的活力
之后shay找到了一份工作,工作内容涉及到大量的高并发分布式场景,于是他决定重写Compress,引入了分布式架构,并更名为Elasticsearch。Elasticsearch的第一个版本发布于2010年5月,发布后公众反响强烈。
1.3 开源力量助其腾飞
Elasticsearch在github上发布后,使用量骤增,并很快有了自己的社区。很快,社区中的 Steven Schuurman、Uri Boness 和 Simon Willnauer 与Shay Banon 一起成立了一家搜索公司Elasticsearch Inc.。
在Elasticsearch Inc.公司成立前后,另外两个开源项目也正在快速发展。一个是Jordan Sissel的开源可插拔数据采集工具Logstash, 另一个是Rashid Khan的开源数据可视化UI Kibana。由于作者间对彼此产品比较熟悉,因此决定合作发展,最终形成了Elastic Stack的经典技术栈ELK: Elasticsearch, Logstash, Kibana。
1.4 快速成长
| 之后Elasticsearch迅速发展,增加了许多新功能和特性 版本 | 发布日志 | 重要特性 |
|---|---|---|
| 0.7.0 | 2010.5.14 | github上第一个版本 |
| 1.0.0 | 2014.2.14 | 备份恢复,聚合,熔断器,docvalues等 |
| 2.0.0 | 2015.10.28 | 组件版本统一,推出Elastic Cloud等 |
| 5.0.0 | 2016.10.26 | 商业组件整合为x-pack;使用Lucene6.0引入BKD树,稀疏数据优化等; beat引入module概念; 增加machine learning功能; shrink API; ingest node; painless 脚本等 |
| 6.0.0 | 2017.8.31 | 稀疏性docvalues支持,index sorting, sequence num, 滚动升级等 |
| 7.0.0 | 2019.4.10 | 引入新的集群协调层zen2; real内存熔断器等 |
2018年美东时间10月5日上午 9:30 整,纽约证券交易所的铃声响起,Elastic 成功上市。
2. 基本原理
2.1 最初的想法
Elasticsearch是一个分布式搜索引擎,底层使用Lucene来实现其核心搜索功能。虽然当前Elasticsearch拥有的众多的功能和解决方案,但是其核心仍然是全文检索。
- 什么是全文检索?
生活中的数据可以分为结构化数据和非结构化数据。结构化数据是指格式和长度固定的数据,如一个人的年龄,姓名等。非结构化数据是指格式和长度不固定的数据,如一个文章的内容等。
对于结构化数据,可以存储在DB中通过精确匹配找到。但是对于非结构化数据,一般查询时只能提供查询的局部信息或模糊信息,传统数据库无法根据这些信息进行查询(或者说效率很差)。 - 如何解决全文检索-倒排索引
倒排索引时相对于正排索引而言的,如下图是正排索引和倒排索引的对比
正排索引可以通过id查找到对应的文章,但是无法通过给的部分内容如love,找出含有该关键字的文档。 倒排索引会先对文档进行分析将其拆分成单个Term, 并存储包含该Term的文档id,这样便可以实现通过内容查找对应文档,如包含love的文档为文档1的第二个位置和文档2的第二个位置。倒排索引的逻辑结构如下图:
当然这样的倒排索引建立起来会导致索引的大小迅速膨胀,lucene对此引入了一个特殊的数据结构叫FST,用于解决这个问题。感兴趣的朋友可以查询资料了解,公众号里后续也会专门介绍该数据结构。
2.2 Elasticsearch的改进
使用倒排索引实现全文检索都是Lucene已经具备的能力,Elasticsearch只是将这个能力封装起来提供给用户使用。那么Elasticsearch在lucene之上做了哪些改进和优化呢? 首先我们先了解一下Lucene中的几个基本概念
- Index(索引):一类业务数据的集合,类似于传统数据库DB的概念。
- Document(文档):一条完整的数据记录,json格式,是数据存储和检索的基本单位,类似于传统数据库的一条记录。
- Field(字段):文档的具体一个属性,类似于传统数据库的列。
- Term(分词):全文检索特有词汇,在存储文档字段或检索时会先对传入的值进行拆分,使用拆分后的词进行存储和检索。
2.2.1 分布式设计:
为了支持对海量数据的存储和查询,Elasticsearch引入分片的概念,一个索引被分成多个分片,每个分片可以有一个主分片和多个副本分片,每个分片副本都是一个具有完整功能的lucene实例,可以独立进行存储和搜索。分片可以分配在不同的节点上,同一个分片的不同副本不能分配在相同的节点上。 在进行读写操作时,ES会根据传入的_routing参数(或mapping中设置的_routing, 如果参数和设置中都没有则默认使用_id), 按照公式
shard_num = hash(\routing) % num_primary_shards,计算出文档要所在或要分配到的分片,再从集群元数据中找出对应主分片的位置,将请求路由到该分片进行读写操作。
2.2.2 近实时性-refresh操作
当一个文档写入Lucene后是不能被立即查询到的,Elasticsearch提供了一个refresh操作,会定时地调用lucene的reopen(新版本为openIfChanged)为内存中新写入的数据生成一个新的segment,此时被处理的文档均可以被检索到。refresh操作的时间间隔由refresh_interval参数控制,默认为1s, 当然还可以在写入请求中带上refresh表示写入后立即refresh,另外还可以调用refresh API显式refresh。
2.2.3 数据存储可靠性
- 引入translog
当一个文档写入Lucence后是存储在内存中的,即使执行了refresh操作仍然是在文件系统缓存中,如果此时服务器宕机,那么这部分数据将会丢失。为此ES增加了translog, 当进行文档写操作时会先将文档写入Lucene,然后写入一份到translog,写入translog是落盘的(如果对可靠性要求不是很高,也可以设置异步落盘,可以提高性能,由配置
index.translog.durability和index.translog.sync_interval控制),这样就可以防止服务器宕机后数据的丢失。与传统的分布式系统不同,这里是先写入Lucene再写入translog,原因是写入Lucene可能会失败,为了减少写入失败回滚的复杂度,因此先写入Lucene. - flush操作
另外每30分钟或当translog达到一定大小(由
index.translog.flush_threshold_size控制,默认512mb), ES会触发一次flush操作,此时ES会先执行refresh操作将buffer中的数据生成segment,然后调用lucene的commit方法将所有内存中的segment fsync到磁盘。此时lucene中的数据就完成了持久化,会清空translog中的数据(6.x版本为了实现sequenceIDs,不删除translog) - merge操作 由于refresh默认间隔为1s中,因此会产生大量的小segment,为此ES会运行一个任务检测当前磁盘中的segment,对符合条件的segment进行合并操作,减少lucene中的segment个数,提高查询速度,降低负载。不仅如此,merge过程也是文档删除和更新操作后,旧的doc真正被删除的时候。用户还可以手动调用_forcemerge API来主动触发merge,以减少集群的segment个数和清理已删除或更新的文档。
- 多副本机制 另外ES有多副本机制,一个分片的主副分片不能分片在同一个节点上,进一步保证数据的可靠性。
2.2.4 部分更新
lucene支持对文档的整体更新,ES为了支持局部更新,在Lucene的Store索引中存储了一个_source字段,该字段的key值是文档ID, 内容是文档的原文。当进行更新操作时先从_source中获取原文,与更新部分合并后,再调用lucene API进行全量更新, 对于写入了ES但是还没有refresh的文档,可以从translog中获取。另外为了防止读取文档过程后执行更新前有其他线程修改了文档,ES增加了版本机制,当执行更新操作时发现当前文档的版本与预期不符,则会重新获取文档再更新。
3 Elastic Stack生态
Elasticsearch相对于其他的搜索引擎最大的优势之一就是完整的产品矩阵和活跃的社区,下图是Elastic Stack的产品矩阵
3.1 Elastic大数据平台
产品矩阵中最核心的部分是Elastic大数据平台,也就是大家所熟知的ELK(现在应该叫ELKB)。其中
- Elasticsearch是其中的搜索引擎,是整个Elastic Stack的核心所在,它底层使用Lucene,对外提供分布式的高可用,易扩展,近实时的数据存储和检索服务。
- Logstash是一个数据采集工具。在早期的Elastic Stack中起到数据采集,处理的作用,在新的架构中,数据采集工作交给了更轻量级的beat来完成,Logstash则更多地用在数据汇聚,处理场景下。Logstash提供了200+的插件来支持各种各样的数据采集和数据场景,极大地提高了Elastic stack在各种应用场景下的应用能力。
- Beats是一个轻量级的数据采集agent,部署在数据采集端,所有的beat底层都基于libbeat,并在其基础之上针对各种应用场景实现数据的采集和传输功能。目前除了官方提供的Filebeat,MetricBeat,PacketB eat等之外,还有大量社区贡献的beat,可以适应各种数据采集场景的需要。
- Kibana是ELK中的数据可视化工具,提供了如Discover(搜索),DashBoard(仪表盘),DevTools(开发工具),Monitoring(监控),MachineLearning(机器学习), SIEM(安全分析),Management(管理)等多种功能,极大地降低了Elasticsearch用户的使用门槛和操作复杂度。
3.2 X-PACK工具包
从5.x开始,Elastic stack将ES的商业功能特性整合到了X-PACK中, 该工具包提供了包括机器学习,规格告警,高级安全特性等在内的众多特性,为使用方提供了更为丰富和专业的功能。
3.3 解决方案
Elastic Stack完善的产品矩阵和活跃的社区,使用ES被广泛应用于各种领域,如搜索,日志,指标,APM,安全,企业搜索等。用户的使用场景和经验反馈,进而促使了Elastic stack在大数据分析平台的基础之上构建一些更完整的,易于上手的解决方案。
如各种beat moudle,用户只需要简单的配置就可以快速地搭建日志或指标采集方案和对应的分析视图。
如APM server和agent,用户只需要根据指引,配置对应server和agent即可快速搭建APM服务。
如SIEM,集成了安全分析的许多功能模块,极大地满足了安全分析的需要。
3.4 Elastic云服务
为了能让用户更方便地使用Elastic Stack的功能,Elastic还提供了托管式云服务。用户只需要通过简单地配置即可快速搭建起Elastic Stack服务,极大地简化了用户的搭建流程。
在国内,Elastic还与腾讯云,阿里云等云厂商合作,提供了Elastic云服务,使得国内用户也能快捷方便地搭建起Elastic服务。
4. 主要功能
Elastic Stack发展至今已拥有丰富的功能
4.1 强大的查询能力
Elasticsearch是一个搜索引擎,而判断一个搜索引擎的优劣,就是看其对查询的支持能力。如下图为Elasticsearch支持的查询功能
基础查询能力上Elasticseach支持精确查询,全文查询,地理位置查询和一些高级查询。
Elasticsearch还支持对这些基础查询进行组合查询,并且可以调整各子查询的权重等
Elasticsearch在聚合层面也提供了强大的支持,不仅支持简单的像SUM, MAX这样的指标查询,还支持分桶查询。另外还支持对其他聚合结果的聚合Pipeline查询。
4.2 丰富的存储类型
Elasticsearch支持包括String(text/keyword), Numeric(long, integer, short ...), Date, Boolean, Binary, Range等多种数据类型,还支持如Nested, join, object, Geo-shape, Sparse vectord等多种数据类型,针对每种数据类型进行了特定的存储和检索优化,以应对不同场景的使用需要
4.3 强大的数据采集和管理能力
- 数据采集和处理:Elastic Stack的beats和Logstash不仅提供了大量的官方插件,还有大量的社区贡献,可以满足各种场景的数据采集和处理需求。另外Elastic的ingest node 也提供了丰富的数据预处理能力。
- 快照备份和恢复:支持将部分或全部数据备份到指定数据源,并支持插件开发
- 索引声明周期管理:用户可以通过配置,使集群可以自动对数据进行roll over, 降冷,关闭或或删除等操作,提高了数据的持续管理能力。
4.4 安全性
Elasticsearch提供了加密通信,基于角色的访问控制,基于属性的访问控制,LDAP,令牌服务等多种安全功能,可以满足用户在安全方面的各种需求。
4.5 监控和告警
Elasticseasrch提供了对Elastic Stack组件的监控及告警能力,极大地方便了用户对Elastic Stack运行状态的了解和对问题的定位修复。
Elasitc提供了Altering功能,用户可以根据业务需要配置规则,实现满足业务需要的规则告警
4.6 机器学习
Elasticsearch当前提供了非监督机器学习功能,该功能当前主要用在异常检测方面。在日志检索,指标,APM,安全分析等领域均有使用。
由于功能太多这里就不一一列举了,详情可以参考:[Elastic Subscription]
5 应用场景
Elasticsearch有着广泛的应用场景,借助其强大的检索能力,其当前主要应用在搜索,日志分析,指标,APM,安全分析等领域。
5.1 搜索
Elasticsearch作为搜索引擎,其对绝大多数类型的搜索功能提供了支持。由于其具有可扩展性好,安全性高,近实时,功能全面等优点,其广泛应用在各种应用搜索,站内搜,企业搜索,代码搜索等场景。
5.2 日志分析
日志分析是Elasticsearch应用最广泛的领域,由于其ELK架构可以实现快速搭建和使用,再加上其强大的检索能力,使得其深受广大运维同学喜爱。
5.3 指标
Elasticsearch5.x开始使用lucene6.0,该版本引入了BKD 树,并对稀疏数据进行了优化,使得数值数据的存储和查询性能得到了很大提升。Elasticsearch也因此得以可以广泛应用于指标监控。
5.4 APM
Elastic Stack提供APM serverh和APM anget,用于帮助用户实现APM功能。APM功能来源于之前的Opbeat。Opbeat是由一个丹麦初创团队研发,该团队主打产品就是APM运维软件。
5.5 安全分析
随着互联网技术的蓬勃发展,安全分析领域开始面临海量数据存储和查询分析问题,Elastic为安全领域提供了从数据采集,数据格式处理,异常检测,可视化分析等一整套解决方案,极大地方便了安全分析在海量数据场景下的进行。在7.x版本的Kibana中甚至直接增加了一个SIEM应用,用于向安全分析领域提供完整的解决方案。
本文对Elasticsearch的发展历程,基本原理,主要功能和应用场景进行了简单总结,希望能帮助大家对Elasticsearch有一个条理清晰的了解。
欢迎关注公众号Elastic慕容,和我一起进入Elastic的奇妙世界吧
社区日报 第792期 (2019-11-24)
http://t.cn/AidnCeBi
2.防止Amazon上Elasticsearch数据暴露。
http://t.cn/AidnZJ9T
3.(自备梯子)为什么特斯拉的Cybertruck可能会失败?
http://t.cn/AidnZOKM
编辑:至尊宝
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup
http://t.cn/AidnCeBi
2.防止Amazon上Elasticsearch数据暴露。
http://t.cn/AidnZJ9T
3.(自备梯子)为什么特斯拉的Cybertruck可能会失败?
http://t.cn/AidnZOKM
编辑:至尊宝
归档:https://ela.st/cn-daily-all
订阅:https://ela.st/cn-daily-sub
沙龙:https://ela.st/cn-meetup 收起阅读 »

