

中文分词
IK 字段级别词典的升级之路
Easysearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 3143 次浏览 • 2025-07-29 13:01
背景知识:词库的作用
IK 分词器是一款基于词典匹配的中文分词器,其准确性和召回率与 IK 使用的词库也有不小的关系。
这里我们先了解一下词典匹配法的作用流程:
- 预先准备一个大规模的词典,用算法在文本中寻找词典里的最长匹配项。这种方法实现简单且速度快。
- 但面临歧义切分和未登录词挑战:同一序列可能有不同切分方式(例如“北京大学生”可以切成“北京大学/生”或“北京/大学生”),需要规则或算法消除歧义;
- 而词典中没有的新词(如网络流行语、人名等)无法正确切分。
可以看到词库是词元产生的比对基础,一个完善的中文词库能大大提高分词器的准确性和召回率。
IK 使用的词库是中文中常见词汇的合集,完善且丰富,ik_smart 和 ik_max_word 也能满足大部分中文分词的场景需求。但是针对一些专业的场景,比如医药这样的行业词库、电商搜索词、新闻热点词等,IK 是很难覆盖到的。这时候就需要使用者自己去维护自定义的词库了。
IK 的自定义词库加载方式
IK 本身也支持自定义词库的加载和更新的,但是只支持一个集群使用一个词库。
这里主要的制约因素是,词库对象与 ik 的中文分词器执行对象是一一对应的关系。
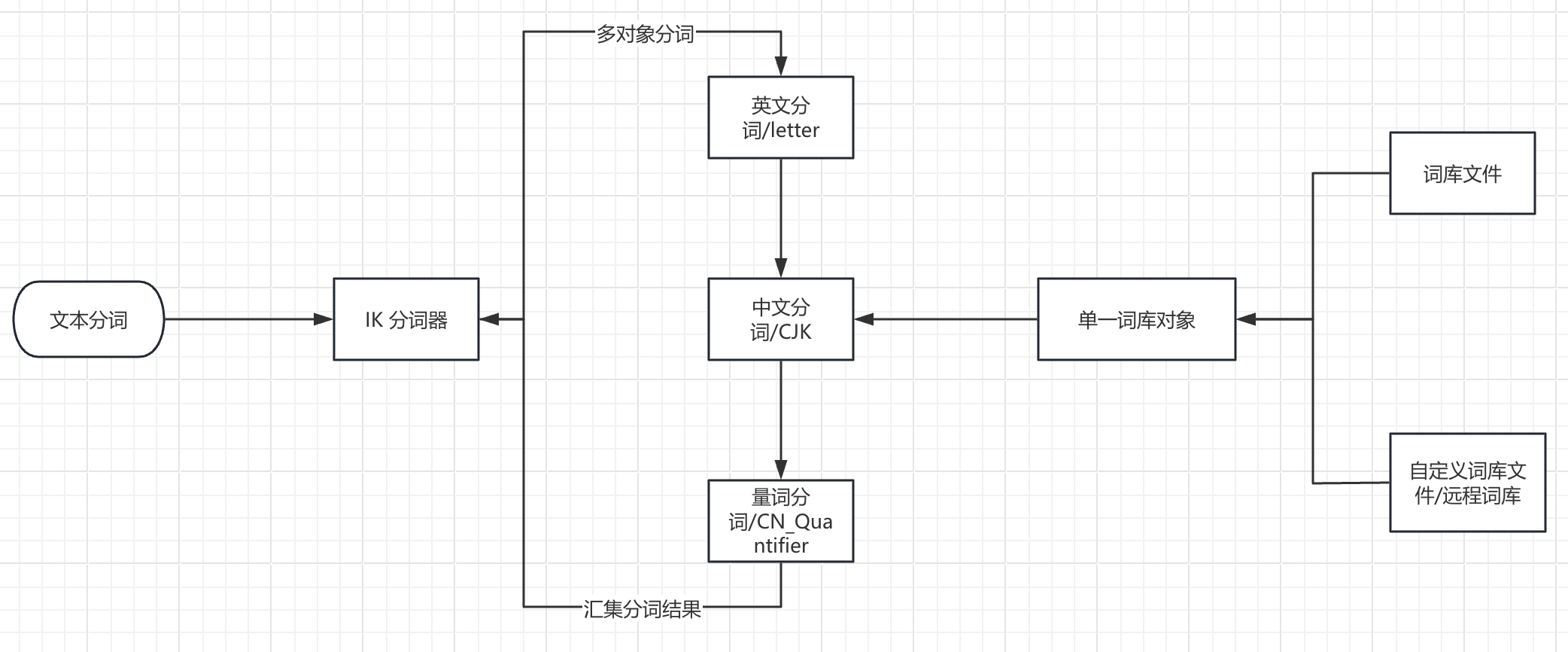
这导致了 IK 的词库面对不同中文分词场景时较低的灵活性,使用者并不能做到字段级别的词库加载。并且基于文件或者 http 协议的词库加载方式也需要不小的维护成本。
字段级别词库的加载
鉴于上述的背景问题,INFINI lab 加强了 IK 的词库加载逻辑,做到了字段级别的词库加载。同时将自定义词库的加载方式由外部文件/远程访问改成了内部索引查询。
主要逻辑如图:
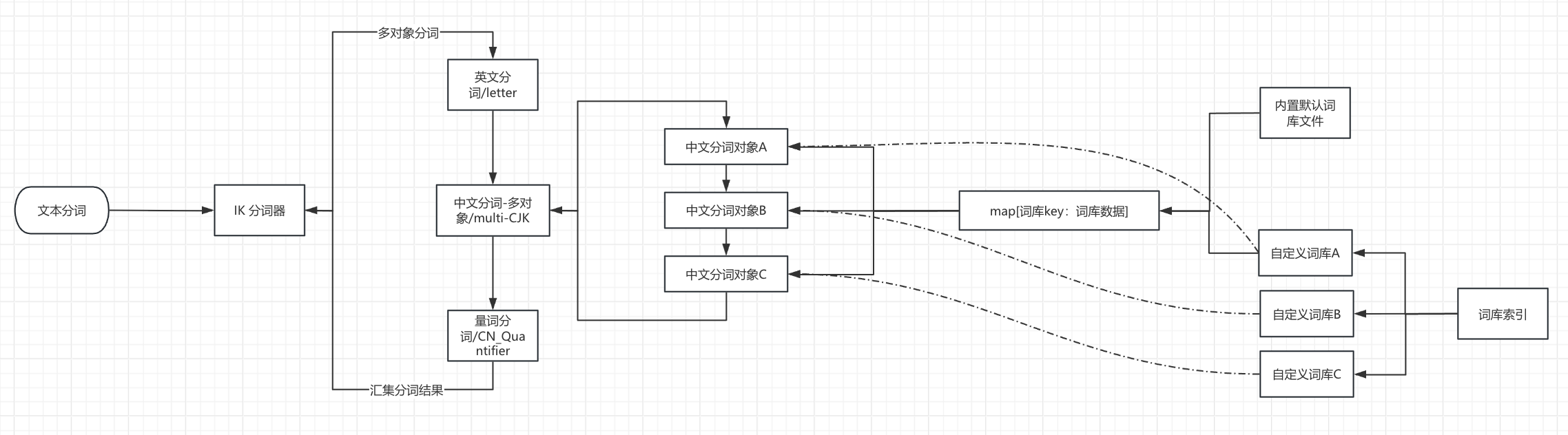
这里 IK 多中文词库的加载优化主要基于 IK 可以加载多词类对象(即下面这段代码)的灵活性,将原来遍历一个 CJK 词类对象修改成遍历多个 CJK 词类对象,各个自定义词库可以附着在 CJK 词库对象上实现不同词库的分词。
do{
//遍历子分词器
for(ISegmenter segmenter : segmenters){
segmenter.analyze(context);
}
//字符缓冲区接近读完,需要读入新的字符
if(context.needRefillBuffer()){
break;
}
}对默认词库的新增支持
对于默认词库的修改,新版 IK 也可以通过写入词库索引方式支持,只要将 dict_key 设置为 default 即可。
POST .analysis_ik/_doc
{
"dict_key": "default",
"dict_type": "main_dicts",
"dict_content":"杨树林"
}效率测试
测试方案 1:单条测试
测试方法:写入一条数据到默认 ik_max_word 和自定义词库,查看是否有明显的效率差距
- 创建测试索引,自定义一个包括默认词库的 IK 分词器
PUT my-index-000001
{
"settings": {
"number_of_shards": 3,
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "my_tokenizer"
}
},
"tokenizer": {
"my_tokenizer": {
"type": "ik_max_word",
"custom_dict_enable": true,
"load_default_dicts":true,
"lowcase_enable": true,
"dict_key": "test_dic"
}
}
}
},
"mappings": {
"properties": {
"test_ik": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
}
}- 将该词库重复默认词库的内容
POST .analysis_ik/_doc
{
"dict_key": "test_dic",
"dict_type": "main_dicts",
"dict_content":"""xxxx #词库内容
"""
}
# debug 日志
[2025-07-09T16:37:43,112][INFO ][o.w.a.d.Dictionary ] [ik-1] Loaded 275909 words from main_dicts dictionary for dict_key: test_dic- 测试默认词库和自定义词库的分词效率
GET my-index-000001/_analyze
{
"analyzer": "my_custom_analyzer",
"text":"自强不息,杨树林"
}
GET my-index-000001/_analyze
{
"analyzer": "ik_max_word",
"text":"自强不息,杨树林"
}
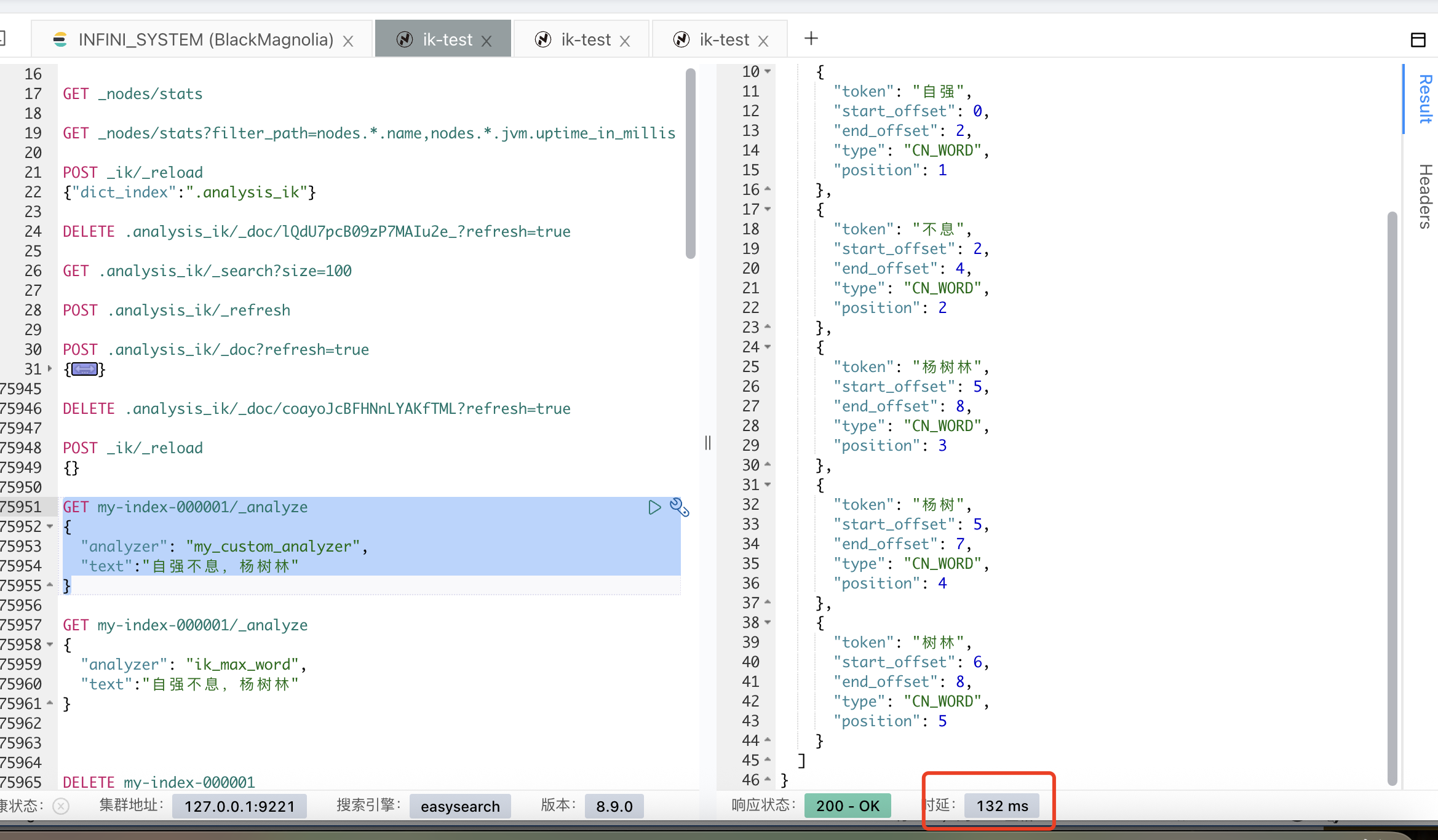
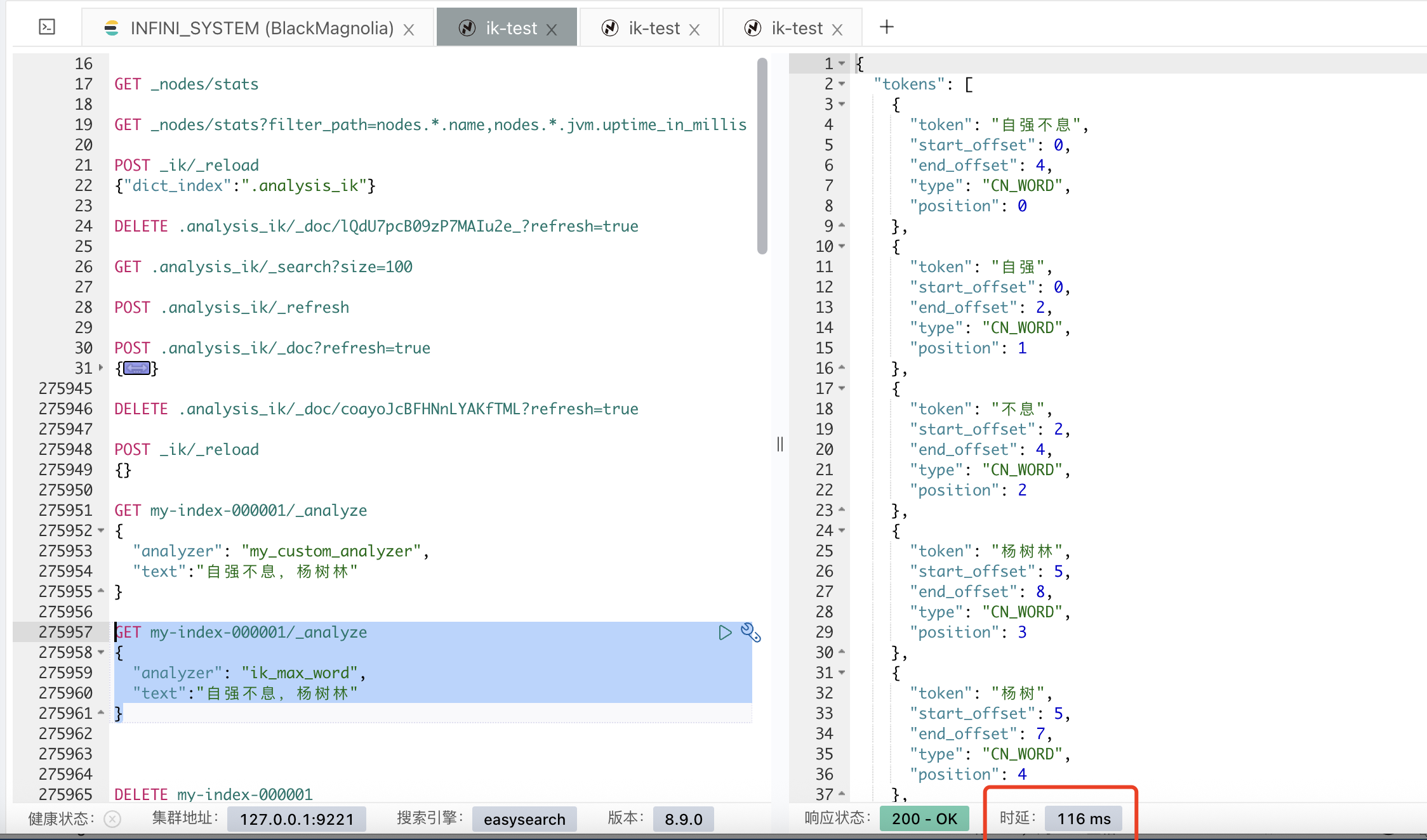
打开 debug 日志,可以看到自定义分词器在不同的词库找到了 2 次“自强不息”
...
[2025-07-09T16:52:22,937][INFO ][o.w.a.c.CN_QuantifierSegmenter] [ik-1] 当前扫描词元[息]不需要启动量词扫描
[2025-07-09T16:52:22,937][INFO ][o.w.a.c.CJKSegmenter ] [ik-1] >>> WORD FOUND [自强不息] from dict [default]
[2025-07-09T16:52:22,937][INFO ][o.w.a.c.CJKSegmenter ] [ik-1] >>> WORD FOUND [不息] from dict [default]
[2025-07-09T16:52:22,937][INFO ][o.w.a.c.CJKSegmenter ] [ik-1] >>> WORD FOUND [自强不息] from dict [test_dic]
[2025-07-09T16:52:22,937][INFO ][o.w.a.c.CJKSegmenter ] [ik-1] >>> WORD FOUND [不息] from dict [test_dic]
[2025-07-09T16:52:22,937][INFO ][o.w.a.c.CN_QuantifierSegmenter] [ik-1] 当前扫描词元[,]不需要启动量词扫描
...而默认词库只有一次
...
[2025-07-09T16:54:22,618][INFO ][o.w.a.c.CN_QuantifierSegmenter] [ik-1] 当前扫描词元[息]不需要启动量词扫描
[2025-07-09T16:54:22,618][INFO ][o.w.a.c.CJKSegmenter ] [ik-1] >>> WORD FOUND [自强不息] from dict [default]
[2025-07-09T16:54:22,618][INFO ][o.w.a.c.CJKSegmenter ] [ik-1] >>> WORD FOUND [不息] from dict [default]
[2025-07-09T16:54:22,618][INFO ][o.w.a.c.CN_QuantifierSegmenter] [ik-1] 当前扫描词元[,]不需要启动量词扫描
...测试方案 2:持续写入测试
测试方法:在 ik_max_word 和自定义词库的索引里,分别持续 bulk 写入,查看总体写入延迟。
测试索引:
# ik_max_word索引
PUT ik_max_test
{
"mappings": {
"properties": {
"chapter": {
"type": "keyword"
},
"content": {
"type": "text",
"analyzer": "ik_max_word"
},
"paragraph_id": {
"type": "keyword"
},
"random_field": {
"type": "text"
},
"timestamp": {
"type": "keyword"
},
"word_count": {
"type": "integer"
}
}
},
"settings": {
"index": {
"number_of_shards": "1",
"number_of_replicas": "0"
}
}
}
# 自定义词库索引
PUT ik_custom_test
{
"mappings": {
"properties": {
"chapter": {
"type": "keyword"
},
"content": {
"type": "text",
"analyzer": "my_custom_analyzer"
},
"paragraph_id": {
"type": "keyword"
},
"random_field": {
"type": "text"
},
"timestamp": {
"type": "keyword"
},
"word_count": {
"type": "integer"
}
}
},
"settings": {
"index": {
"number_of_shards": "1",
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "my_tokenizer"
}
},
"tokenizer": {
"my_tokenizer": {
"load_default_dicts": "true",
"type": "ik_max_word",
"dict_key": "test_dic",
"lowcase_enable": "true",
"custom_dict_enable": "true"
}
}
},
"number_of_replicas": "0"
}
}
}
这里利用脚本循环写入了一段《四世同堂》的文本,比较相同次数下,两次写入的总体延迟。
测试脚本内容如下:
#!/usr/bin/env python3
# -_- coding: utf-8 -_-
"""
四世同堂中文内容随机循环写入 Elasticsearch 脚本
目标:生成指定 bulk 次数的索引内容
"""
import random
import time
import json
from datetime import datetime
import requests
import logging
import os
import argparse
import urllib3
# 配置日志
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(**name**)
class ESDataGenerator:
def **init**(self, es_host='localhost', es_port=9200, index_name='sisitontang_content',
target_bulk_count=10000, batch_size=1000, use_https=False, username=None, password=None, verify_ssl=True):
"""
初始化 ES 连接和配置
"""
protocol = 'https' if use_https else 'http'
self.es_url = f'{protocol}://{es_host}:{es_port}'
self.index_name = index_name
self.target_bulk_count = target_bulk_count # 目标 bulk 次数
self.batch_size = batch_size
self.check_interval = 1000 # 每 1000 次 bulk 检查一次进度
# 设置认证信息
self.auth = None
if username and password:
self.auth = (username, password)
logger.info(f"使用用户名认证: {username}")
# 设置请求会话
self.session = requests.Session()
if self.auth:
self.session.auth = self.auth
# 处理HTTPS和SSL证书验证
if use_https:
self.session.verify = False # 始终禁用SSL验证以避免证书问题
logger.info("警告:已禁用SSL证书验证(适合开发测试环境)")
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
# 设置SSL适配器以处理连接问题
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
# 配置重试策略
retry_strategy = Retry(
total=3,
backoff_factor=1,
status_forcelist=[429, 500, 502, 503, 504],
)
adapter = HTTPAdapter(max_retries=retry_strategy)
self.session.mount("https://", adapter)
# 设置更宽松的SSL上下文
self.session.verify = False
logger.info(f"ES连接地址: {self.es_url}")
# 创建索引映射
self.create_index()
def create_index(self):
"""创建索引和映射"""
mapping = {
"mappings": {
"properties": {
"chapter": {"type": "keyword"},
"content": {"type": "text", "analyzer": "ik_max_word"},
"timestamp": {"type": "date"},
"word_count": {"type": "integer"},
"paragraph_id": {"type": "keyword"},
"random_field": {"type": "text"}
}
}
}
try:
# 检查索引是否存在
response = self.session.head(f"{self.es_url}/{self.index_name}")
if response.status_code == 200:
logger.info(f"索引 {self.index_name} 已存在")
else:
# 创建索引
response = self.session.put(
f"{self.es_url}/{self.index_name}",
headers={'Content-Type': 'application/json'},
json=mapping
)
if response.status_code in [200, 201]:
logger.info(f"创建索引 {self.index_name} 成功")
else:
logger.error(f"创建索引失败: {response.status_code} - {response.text}")
except Exception as e:
logger.error(f"创建索引失败: {e}")
def load_text_content(self, file_path='sisitontang.txt'):
"""
从文件加载《四世同堂》的完整文本内容
如果文件不存在,则返回扩展的示例内容
"""
if os.path.exists(file_path):
try:
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
logger.info(f"从文件 {file_path} 加载了 {len(content)} 个字符的文本内容")
return content
except Exception as e:
logger.error(f"读取文件失败: {e}")
# 如果文件不存在,返回扩展的示例内容
logger.info("使用内置的扩展示例内容")
return self.get_extended_sample_content()
def get_extended_sample_content(self):
"""
获取扩展的《四世同堂》示例内容
"""
content = """
小羊圈胡同是北平城里的一个小胡同。它不宽,可是很长,从东到西有一里多路。在这条胡同里,从东边数起,有个小茶馆,几个小门脸,和一群小房屋。小茶馆的斜对面是个较大的四合院,院子里有几棵大槐树。这个院子就是祁家的住所,四世同堂的大家庭就在这里度过了最困难的岁月。
祁老人是个善良的老头儿,虽然年纪大了,可是还很有精神。他的一生见证了太多的变迁,从清朝的衰落到民国的建立,再到现在的战乱,他都以一种达观的态度面对着。他的儿子祁天佑是个教书先生,为人正直,在胡同里很有威望。祁家的儿媳妇韵梅是个贤惠的女人,把家里打理得井井有条,即使在最困难的时候,也要维持着家庭的尊严。
钱默吟先生是个有学问的人,他的诗写得很好,可是性格有些古怪。他住在胡同深处的一个小院子里,平时很少出门,只是偶尔到祁家坐坐,和祁天佑聊聊古今。他对时局有着自己独特的见解,但更多的时候,他选择在自己的小天地里寻找精神的慰藉。战争的残酷现实让这个文人感到深深的无力,但他依然坚持着自己的文人气节。
小顺子是个活泼的孩子,他每天都在胡同里跑来跑去,和其他的孩子们一起玩耍。他的笑声总是能感染到周围的人,让这个古老的胡同充满了生机。即使在战争的阴霾下,孩子们依然保持着他们的天真和快乐,这或许就是生活的希望所在。小顺子不懂得大人们的烦恼,他只是简单地享受着童年的快乐。
李四大爷是个老实人,他在胡同里开了个小杂货铺。虽然生意不大,但是童叟无欺,街坊邻居们都愿意到他这里买东西。他的妻子是个能干的女人,把小铺子管理得很好。在那个物资匮乏的年代,能够维持一个小铺子的经营已经很不容易了。李四大爷经常帮助邻居们,即使自己的生活也不宽裕。
胡同里的生活是平静的,每天清晨,人们就开始忙碌起来。有的人挑着水桶去井边打水,有的人牵着羊去街上卖奶,有的人挑着菜担子去菜市场。这种平静的生活在战争来临之前是那么的珍贵,人们都珍惜着这样的日子。邻里之间相互照顾,孩子们在院子里玩耍,老人们在门口晒太阳聊天。
冠晓荷是个复杂的人物,他有文化,也有野心。在日本人占领北平的时候,他选择了与敌人合作,这让胡同里的人们都看不起他。但是他的妻子还是个好人,只是被丈夫连累了。冠晓荷的选择代表了那个时代一部分知识分子的软弱和妥协,他们在民族大义和个人利益之间选择了后者。
春天来了,胡同里的槐树发芽了,小鸟们在枝头歌唱。孩子们在院子里玩耍,老人们在门口晒太阳。这样的日子让人感到温暖和希望。即使在最黑暗的时期,生活依然要继续,人们依然要保持对美好未来的希望。春天的到来总是能够给人们带来新的希望和力量。
战争的阴云笼罩着整个城市,胡同里的人们也感受到了压力。有的人选择了抗争,有的人选择了妥协,有的人选择了逃避。每个人都在用自己的方式应对这个艰难的时代。祁瑞宣面临着痛苦的选择,他既不愿意与日本人合作,也不敢公开反抗,这种内心的煎熬让他备受折磨。
老舍先生用他细腻的笔触描绘了胡同里的众生相,每个人物都有自己的特点和命运。他们的喜怒哀乐构成了这部伟大作品的丰富内涵。从祁老爷子的达观,到祁瑞宣的痛苦,从韵梅的坚强,到冠晓荷的堕落,每个人物都是那个时代的缩影。
在那个动荡的年代,普通人的生活是不容易的。他们要面对战争的威胁,要面对生活的困难,要面对道德的选择。但是他们依然坚强地活着,为了家人,为了希望。即使在最困难的时候,人们依然保持着对美好生活的向往。
胡同里的邻里关系是复杂的,有友好的,也有矛盾的。但是在大的困难面前,大家还是会相互帮助。这种邻里之间的温情是中华民族传统文化的重要组成部分。在那个特殊的年代,这种人与人之间的温情显得更加珍贵。
祁瑞宣是个有理想的青年,他受过良好的教育,有自己的抱负。但是在日本人占领期间,他的理想和现实之间产生了尖锐的矛盾。他不愿意做汉奸,但是也不能完全抵抗。这种内心的矛盾和痛苦是那个时代很多知识分子的真实写照。
小妞子是个可爱的孩子,她的天真无邪给这个沉重的故事增添了一丝亮色。她不懂得大人们的复杂心理,只是简单地生活着,快乐着。孩子们的天真和快乐在那个黑暗的年代显得格外珍贵,它们代表着生活的希望和未来。
程长顺是个朴实的人,他没有什么文化,但是有自己的原则和底线。他不愿意向日本人低头,宁愿过艰苦的生活也要保持自己的尊严。他的坚持代表了中国人民不屈不挠的精神,即使在最困难的时候也不愿意妥协。
胡同里的生活节奏是缓慢的,人们有时间去观察周围的变化,去思考生活的意义。这种慢节奏的生活在今天看来是珍贵的,它让人们有机会去体验生活的细节。在那个年代,即使生活艰难,人们依然能够从平凡的日常中找到乐趣。
老二是个有个性的人,他不愿意受约束,喜欢自由自在的生活。但是在战争年代,这种个性给他带来了麻烦,也给家人带来了担忧。他的反叛精神在某种程度上代表着年轻一代对传统束缚的反抗,但在那个特殊的时代,这种反抗往往会带来意想不到的后果。
胡同里的四合院是北京传统建筑的代表,它们见证了一代又一代人的生活。每个院子里都有自己的故事,每个房间里都有自己的记忆。这些古老的建筑承载着深厚的历史文化底蕴,即使在战争的破坏下,依然坚强地屹立着。
在《四世同堂》这部作品中,老舍先生不仅描绘了个人的命运,也反映了整个民族的命运。小胡同里的故事其实就是大中国的缩影。每个人物的遭遇都代表着那个时代某一类人的命运,他们的选择和结局反映了整个民族在那个特殊历史时期的精神状态。
战争结束了,但是人们心中的创伤需要时间来愈合。胡同里的人们重新开始了正常的生活,但是那段艰难的经历永远不会被忘记。历史的教训提醒着人们珍惜和平,珍惜现在的美好生活。四世同堂的故事将永远流传下去,成为后人了解那个时代的重要窗口。
"""
return content.strip()
def split_text_randomly(self, text, min_length=100, max_length=200):
"""
将文本按100-200字的随机长度进行分割
"""
# 清理文本,移除多余的空白字符
text = ''.join(text.split())
segments = []
start = 0
while start < len(text):
# 随机选择段落长度
segment_length = random.randint(min_length, max_length)
end = min(start + segment_length, len(text))
segment = text[start:end]
if segment.strip(): # 确保段落不为空
segments.append(segment.strip())
start = end
return segments
def generate_random_content(self, base_content):
"""
基于基础内容生成随机变化的内容
"""
# 随机选择一个基础段落
base_paragraph = random.choice(base_content)
# 随机添加一些变化
variations = [
"在那个年代,",
"据说,",
"人们常常说,",
"老一辈人总是提到,",
"历史记录显示,",
"根据回忆,",
"有人说,",
"大家都知道,",
"传说中,",
"众所周知,"
]
endings = [
"这就是当时的情况。",
"这样的事情在那个年代很常见。",
"这个故事至今还在流传。",
"这是一个值得回忆的故事。",
"这样的经历让人难以忘怀。",
"这就是老北京的生活。",
"这种精神值得我们学习。",
"这个时代已经过去了。",
"这样的生活现在已经很难看到了。",
"这是历史的见证。"
]
# 随机组合内容
if random.random() < 0.3:
content = random.choice(variations) + base_paragraph
else:
content = base_paragraph
if random.random() < 0.3:
content += random.choice(endings)
return content
def generate_document(self, text_segments, doc_id):
"""基于文本段落生成一个文档"""
# 随机选择一个文本段落
content = random.choice(text_segments)
# 生成随机的额外字段以增加文档大小
random_field = ''.join(random.choices('abcdefghijklmnopqrstuvwxyz0123456789', k=random.randint(100, 500)))
doc = {
"chapter": f"第{random.randint(1, 100)}章",
"content": content,
"timestamp": datetime.now(),
"word_count": len(content),
"paragraph_id": f"para_{doc_id}",
"random_field": random_field
}
return doc
def get_index_size_gb(self):
"""获取索引大小(GB)"""
try:
response = self.session.get(f"{self.es_url}/_cat/indices/{self.index_name}?bytes=b&h=store.size&format=json")
if response.status_code == 200:
data = response.json()
if data and len(data) > 0:
size_bytes = int(data[0]['store.size'])
size_gb = size_bytes / (1024 * 1024 * 1024)
return size_gb
return 0
except Exception as e:
logger.error(f"获取索引大小失败: {e}")
return 0
def bulk_insert(self, documents):
"""批量插入文档使用HTTP bulk API"""
# 构建bulk请求体
bulk_data = []
for doc in documents:
# 添加action行
action = {"index": {"_index": self.index_name}}
bulk_data.append(json.dumps(action))
# 添加文档行
bulk_data.append(json.dumps(doc, ensure_ascii=False, default=str))
# 每行以换行符结束,最后也要有换行符
bulk_body = '\n'.join(bulk_data) + '\n'
try:
response = self.session.post(
f"{self.es_url}/_bulk",
headers={'Content-Type': 'application/x-ndjson'},
data=bulk_body.encode('utf-8'),
timeout=30 # 添加超时设置
)
if response.status_code == 200:
result = response.json()
# 检查是否有错误
if result.get('errors'):
error_count = 0
error_details = []
for item in result['items']:
if 'error' in item.get('index', {}):
error_count += 1
error_info = item['index']['error']
error_details.append(f"类型: {error_info.get('type')}, 原因: {error_info.get('reason')}")
if error_count > 0:
logger.warning(f"批量插入有 {error_count} 个错误")
# 打印前5个错误的详细信息
for i, error in enumerate(error_details[:5]):
logger.error(f"错误 {i+1}: {error}")
if len(error_details) > 5:
logger.error(f"... 还有 {len(error_details)-5} 个类似错误")
return True
else:
logger.error(f"批量插入失败: HTTP {response.status_code} - {response.text}")
return False
except requests.exceptions.SSLError as e:
logger.error(f"SSL连接错误: {e}")
logger.error("建议检查ES集群的SSL配置或使用 --no-verify-ssl 参数")
return False
except requests.exceptions.ConnectionError as e:
logger.error(f"连接错误: {e}")
logger.error("请检查ES集群地址和端口是否正确")
return False
except requests.exceptions.Timeout as e:
logger.error(f"请求超时: {e}")
logger.error("ES集群响应超时,可能负载过高")
return False
except Exception as e:
logger.error(f"批量插入失败: {e}")
logger.error(f"错误类型: {type(e).__name__}")
return False
def run(self):
"""运行数据生成器"""
start_time = time.time()
start_datetime = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
logger.info(f"开始生成数据,开始时间: {start_datetime},目标bulk次数: {self.target_bulk_count}")
# 加载文本内容
text_content = self.load_text_content()
# 将文本分割成100-200字的段落
text_segments = self.split_text_randomly(text_content, min_length=100, max_length=200)
logger.info(f"分割出 {len(text_segments)} 个文本段落")
doc_count = 0
bulk_count = 0
bulk_times = [] # 记录每次bulk的耗时
while bulk_count < self.target_bulk_count:
# 生成批量文档
documents = []
for i in range(self.batch_size):
doc = self.generate_document(text_segments, doc_count + i)
documents.append(doc)
# 记录单次bulk开始时间
bulk_start = time.time()
# 批量插入
if self.bulk_insert(documents):
bulk_end = time.time()
bulk_duration = bulk_end - bulk_start
bulk_times.append(bulk_duration)
doc_count += self.batch_size
bulk_count += 1
# 定期检查和报告进度
if bulk_count % self.check_interval == 0:
current_size = self.get_index_size_gb()
avg_bulk_time = sum(bulk_times[-self.check_interval:]) / len(bulk_times[-self.check_interval:])
logger.info(f"已完成 {bulk_count} 次bulk操作,插入 {doc_count} 条文档,当前索引大小: {current_size:.2f}GB,最近{self.check_interval}次bulk平均耗时: {avg_bulk_time:.3f}秒")
# 避免过于频繁的插入
#time.sleep(0.01) # 减少延迟,提高测试速度
end_time = time.time()
end_datetime = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
total_duration = end_time - start_time
# 计算统计信息
final_size = self.get_index_size_gb()
avg_bulk_time = sum(bulk_times) / len(bulk_times) if bulk_times else 0
total_docs_per_sec = doc_count / total_duration if total_duration > 0 else 0
bulk_per_sec = bulk_count / total_duration if total_duration > 0 else 0
logger.info(f"数据生成完成!")
logger.info(f"开始时间: {start_datetime}")
logger.info(f"结束时间: {end_datetime}")
logger.info(f"总耗时: {total_duration:.2f}秒 ({total_duration/60:.2f}分钟)")
logger.info(f"总计完成: {bulk_count} 次bulk操作")
logger.info(f"总计插入: {doc_count} 条文档")
logger.info(f"最终索引大小: {final_size:.2f}GB")
logger.info(f"平均每次bulk耗时: {avg_bulk_time:.3f}秒")
logger.info(f"平均bulk速率: {bulk_per_sec:.2f}次/秒")
logger.info(f"平均文档写入速率: {total_docs_per_sec:.0f}条/秒")
def main():
"""主函数"""
parser = argparse.ArgumentParser(description='四世同堂中文内容写入 Elasticsearch 脚本')
parser.add_argument('--host', default='localhost', help='ES 主机地址 (默认: localhost)')
parser.add_argument('--port', type=int, default=9200, help='ES 端口 (默认: 9200)')
parser.add_argument('--index', required=True, help='索引名称 (必填)')
parser.add_argument('--bulk-count', type=int, default=1000, help='目标 bulk 次数 (默认: 10000)')
parser.add_argument('--batch-size', type=int, default=1000, help='每次 bulk 的文档数量 (默认: 1000)')
parser.add_argument('--https', action='store_true', help='使用 HTTPS 协议')
parser.add_argument('--username', help='ES 用户名')
parser.add_argument('--password', help='ES 密码')
parser.add_argument('--no-verify-ssl', action='store_true', help='禁用 SSL 证书验证(默认已禁用)')
args = parser.parse_args()
protocol = "HTTPS" if args.https else "HTTP"
auth_info = f"认证: {args.username}" if args.username else "无认证"
ssl_info = "禁用SSL验证" if args.https else ""
logger.info(f"开始运行脚本,参数: {protocol}://{args.host}:{args.port}, 索引={args.index}, bulk次数={args.bulk_count}, {auth_info} {ssl_info}")
try:
generator = ESDataGenerator(
args.host,
args.port,
args.index,
args.bulk_count,
args.batch_size,
args.https,
args.username,
args.password,
not args.no_verify_ssl # 传入verify_ssl参数,但实际上总是False
)
generator.run()
except KeyboardInterrupt:
logger.info("用户中断了程序")
except Exception as e:
logger.error(f"程序运行出错: {e}")
logger.error(f"错误类型: {type(e).__name__}")
if **name** == "**main**":
main()
根据脚本中的测试文本添加的词库如下:
POST .analysis_ik/\_doc
{
"dict_type": "main_dicts",
"dict_key": "test_dic",
"dict_content": """祁老人
祁天佑
韵梅
祁瑞宣
老二
钱默吟
小顺子
李四大爷
冠晓荷
小妞子
程长顺
老舍
李四大爷
小羊圈胡同
北平城
胡同
小茶馆
小门脸
小房屋
四合院
院子
祁家
小院子
杂货铺
小铺子
井边
街上
菜市场
门口
枝头
城市
房间
北京
清朝
民国
战乱
战争
日本人
抗战
大槐树
槐树
小鸟
羊
门脸
房屋
水桶
菜担子
铺子
老头儿
儿子
教书先生
儿媳妇
女人
大家庭
孩子
孩子们
街坊邻居
妻子
老人
文人
知识分子
青年
汉奸
岁月
一生
变迁
衰落
建立
态度
威望
尊严
学问
诗
性格
时局
见解
小天地
精神
慰藉
现实
无力
气节
笑声
生机
阴霾
天真
快乐
希望
烦恼
童年
生意
生活
物资
年代
经营
日子
邻里
文化
野心
敌人
选择
软弱
妥协
民族大义
个人利益
温暖
时期
未来
力量
压力
抗争
逃避
方式
时代
煎熬
折磨
笔触
众生相
人物
特点
命运
喜怒哀乐
内涵
达观
痛苦
坚强
堕落
缩影
威胁
困难
道德
家人
向往
关系
矛盾
温情
传统文化
组成部分
理想
教育
抱负
占领
写照
亮色
心理
原则
底线
节奏
意义
细节
乐趣
个性
约束
麻烦
担忧
反叛精神
束缚
反抗
后果
建筑
代表
故事
记忆
历史文化底蕴
破坏
作品
创伤
经历
教训
和平
窗口
清晨
春天
内心
玩耍
聊天
晒太阳
歌唱
合作
打水
卖奶
帮助
"""
}进行 2 次集中写入的记录如下:
# ik_max_test
2025-07-13 20:15:33,294 - INFO - 开始时间: 2025-07-13 19:45:07
2025-07-13 20:15:33,294 - INFO - 结束时间: 2025-07-13 20:15:33
2025-07-13 20:15:33,294 - INFO - 总耗时: 1825.31秒 (30.42分钟)
2025-07-13 20:15:33,294 - INFO - 总计完成: 1000 次bulk操作
2025-07-13 20:15:33,294 - INFO - 总计插入: 1000000 条文档
2025-07-13 20:15:33,294 - INFO - 最终索引大小: 0.92GB
2025-07-13 20:15:33,294 - INFO - 平均每次bulk耗时: 1.790秒
2025-07-13 20:15:33,294 - INFO - 平均bulk速率: 0.55次/秒
2025-07-13 20:15:33,294 - INFO - 平均文档写入速率: 548条/秒
# ik_custom_test
2025-07-13 21:17:47,309 - INFO - 开始时间: 2025-07-13 20:44:03
2025-07-13 21:17:47,309 - INFO - 结束时间: 2025-07-13 21:17:47
2025-07-13 21:17:47,309 - INFO - 总耗时: 2023.53秒 (33.73分钟)
2025-07-13 21:17:47,309 - INFO - 总计完成: 1000 次bulk操作
2025-07-13 21:17:47,309 - INFO - 总计插入: 1000000 条文档
2025-07-13 21:17:47,309 - INFO - 最终索引大小: 0.92GB
2025-07-13 21:17:47,309 - INFO - 平均每次bulk耗时: 1.986秒
2025-07-13 21:17:47,309 - INFO - 平均bulk速率: 0.49次/秒
2025-07-13 21:17:47,309 - INFO - 平均文档写入速率: 494条/秒可以看到,有一定损耗,自定义词库词典的效率是之前的 90%。
相关阅读
关于 IK Analysis

IK Analysis 插件集成了 Lucene IK 分析器,并支持自定义词典。它支持 Easysearch\Elasticsearch\OpenSearch 的主要版本。由 INFINI Labs 维护并提供支持。
该插件包含分析器:ik_smart 和 ik_max_word,以及分词器:ik_smart 和 ik_max_word
开源地址:https://github.com/infinilabs/analysis-ik
作者:金多安,极限科技(INFINI Labs)搜索运维专家,Elastic 认证专家,搜索客社区日报责任编辑。一直从事与搜索运维相关的工作,日常会去挖掘 ES / Lucene 方向的搜索技术原理,保持搜索相关技术发展的关注。
原文:https://infinilabs.cn/blog/2025/ik-field-level-dictionarys-3/

自己写了一个elasticsearch中文分词插件
Elasticsearch • BKing 回复了问题 • 4 人关注 • 2 个回复 • 3163 次浏览 • 2020-11-23 04:55
海量科技股份有限公司ES中文插件
Elasticsearch • novia 发表了文章 • 6 个评论 • 4057 次浏览 • 2018-11-19 11:31

中文分词的特殊符号问题
Elasticsearch • laoyang360 回复了问题 • 2 人关注 • 1 个回复 • 5495 次浏览 • 2018-05-03 18:58

关于IK分词,自己的扩展字典的问题

Elasticsearch • xiao 回复了问题 • 5 人关注 • 4 个回复 • 6631 次浏览 • 2017-12-25 11:55
求教elasticsearch拼音,容错,模糊搜索的问题

Elasticsearch • xiaohu3311 回复了问题 • 7 人关注 • 2 个回复 • 12443 次浏览 • 2017-11-09 19:55

中文分词analysis-ik:远程扩展字典有更新(非常关键),怎样对已经索引的文档重新分词最快
自然语言处理 • medcl 回复了问题 • 5 人关注 • 1 个回复 • 7731 次浏览 • 2017-03-25 10:44
es2.4.4+ik1.10.4 mvn compile失败
回复Elasticsearch • redhat 发起了问题 • 1 人关注 • 0 个回复 • 4467 次浏览 • 2017-03-21 19:29

搜索中文精确问题
Elasticsearch • martindu 回复了问题 • 2 人关注 • 1 个回复 • 3205 次浏览 • 2016-09-21 16:24
简繁体转换插件更新:elasticsearch-analysis-stconvert 升级支持2.0
资讯动态 • medcl 发表了文章 • 4 个评论 • 12808 次浏览 • 2015-12-24 11:45

elasticsearch 默认支持中文分词吗
Elasticsearch • anythink 回复了问题 • 2 人关注 • 1 个回复 • 8816 次浏览 • 2015-11-26 19:04
自己写了一个elasticsearch中文分词插件
回复Elasticsearch • BKing 回复了问题 • 4 人关注 • 2 个回复 • 3163 次浏览 • 2020-11-23 04:55
求教elasticsearch拼音,容错,模糊搜索的问题
回复Elasticsearch • xiaohu3311 回复了问题 • 7 人关注 • 2 个回复 • 12443 次浏览 • 2017-11-09 19:55
中文分词analysis-ik:远程扩展字典有更新(非常关键),怎样对已经索引的文档重新分词最快
回复自然语言处理 • medcl 回复了问题 • 5 人关注 • 1 个回复 • 7731 次浏览 • 2017-03-25 10:44
es2.4.4+ik1.10.4 mvn compile失败
回复Elasticsearch • redhat 发起了问题 • 1 人关注 • 0 个回复 • 4467 次浏览 • 2017-03-21 19:29
elasticsearch 默认支持中文分词吗
回复Elasticsearch • anythink 回复了问题 • 2 人关注 • 1 个回复 • 8816 次浏览 • 2015-11-26 19:04
IK 字段级别词典的升级之路
Easysearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 3143 次浏览 • 2025-07-29 13:01
背景知识:词库的作用
IK 分词器是一款基于词典匹配的中文分词器,其准确性和召回率与 IK 使用的词库也有不小的关系。
这里我们先了解一下词典匹配法的作用流程:
- 预先准备一个大规模的词典,用算法在文本中寻找词典里的最长匹配项。这种方法实现简单且速度快。
- 但面临歧义切分和未登录词挑战:同一序列可能有不同切分方式(例如“北京大学生”可以切成“北京大学/生”或“北京/大学生”),需要规则或算法消除歧义;
- 而词典中没有的新词(如网络流行语、人名等)无法正确切分。
可以看到词库是词元产生的比对基础,一个完善的中文词库能大大提高分词器的准确性和召回率。
IK 使用的词库是中文中常见词汇的合集,完善且丰富,ik_smart 和 ik_max_word 也能满足大部分中文分词的场景需求。但是针对一些专业的场景,比如医药这样的行业词库、电商搜索词、新闻热点词等,IK 是很难覆盖到的。这时候就需要使用者自己去维护自定义的词库了。
IK 的自定义词库加载方式
IK 本身也支持自定义词库的加载和更新的,但是只支持一个集群使用一个词库。
这里主要的制约因素是,词库对象与 ik 的中文分词器执行对象是一一对应的关系。
这导致了 IK 的词库面对不同中文分词场景时较低的灵活性,使用者并不能做到字段级别的词库加载。并且基于文件或者 http 协议的词库加载方式也需要不小的维护成本。
字段级别词库的加载
鉴于上述的背景问题,INFINI lab 加强了 IK 的词库加载逻辑,做到了字段级别的词库加载。同时将自定义词库的加载方式由外部文件/远程访问改成了内部索引查询。
主要逻辑如图:
这里 IK 多中文词库的加载优化主要基于 IK 可以加载多词类对象(即下面这段代码)的灵活性,将原来遍历一个 CJK 词类对象修改成遍历多个 CJK 词类对象,各个自定义词库可以附着在 CJK 词库对象上实现不同词库的分词。
do{
//遍历子分词器
for(ISegmenter segmenter : segmenters){
segmenter.analyze(context);
}
//字符缓冲区接近读完,需要读入新的字符
if(context.needRefillBuffer()){
break;
}
}对默认词库的新增支持
对于默认词库的修改,新版 IK 也可以通过写入词库索引方式支持,只要将 dict_key 设置为 default 即可。
POST .analysis_ik/_doc
{
"dict_key": "default",
"dict_type": "main_dicts",
"dict_content":"杨树林"
}效率测试
测试方案 1:单条测试
测试方法:写入一条数据到默认 ik_max_word 和自定义词库,查看是否有明显的效率差距
- 创建测试索引,自定义一个包括默认词库的 IK 分词器
PUT my-index-000001
{
"settings": {
"number_of_shards": 3,
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "my_tokenizer"
}
},
"tokenizer": {
"my_tokenizer": {
"type": "ik_max_word",
"custom_dict_enable": true,
"load_default_dicts":true,
"lowcase_enable": true,
"dict_key": "test_dic"
}
}
}
},
"mappings": {
"properties": {
"test_ik": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
}
}- 将该词库重复默认词库的内容
POST .analysis_ik/_doc
{
"dict_key": "test_dic",
"dict_type": "main_dicts",
"dict_content":"""xxxx #词库内容
"""
}
# debug 日志
[2025-07-09T16:37:43,112][INFO ][o.w.a.d.Dictionary ] [ik-1] Loaded 275909 words from main_dicts dictionary for dict_key: test_dic- 测试默认词库和自定义词库的分词效率
GET my-index-000001/_analyze
{
"analyzer": "my_custom_analyzer",
"text":"自强不息,杨树林"
}
GET my-index-000001/_analyze
{
"analyzer": "ik_max_word",
"text":"自强不息,杨树林"
}
打开 debug 日志,可以看到自定义分词器在不同的词库找到了 2 次“自强不息”
...
[2025-07-09T16:52:22,937][INFO ][o.w.a.c.CN_QuantifierSegmenter] [ik-1] 当前扫描词元[息]不需要启动量词扫描
[2025-07-09T16:52:22,937][INFO ][o.w.a.c.CJKSegmenter ] [ik-1] >>> WORD FOUND [自强不息] from dict [default]
[2025-07-09T16:52:22,937][INFO ][o.w.a.c.CJKSegmenter ] [ik-1] >>> WORD FOUND [不息] from dict [default]
[2025-07-09T16:52:22,937][INFO ][o.w.a.c.CJKSegmenter ] [ik-1] >>> WORD FOUND [自强不息] from dict [test_dic]
[2025-07-09T16:52:22,937][INFO ][o.w.a.c.CJKSegmenter ] [ik-1] >>> WORD FOUND [不息] from dict [test_dic]
[2025-07-09T16:52:22,937][INFO ][o.w.a.c.CN_QuantifierSegmenter] [ik-1] 当前扫描词元[,]不需要启动量词扫描
...而默认词库只有一次
...
[2025-07-09T16:54:22,618][INFO ][o.w.a.c.CN_QuantifierSegmenter] [ik-1] 当前扫描词元[息]不需要启动量词扫描
[2025-07-09T16:54:22,618][INFO ][o.w.a.c.CJKSegmenter ] [ik-1] >>> WORD FOUND [自强不息] from dict [default]
[2025-07-09T16:54:22,618][INFO ][o.w.a.c.CJKSegmenter ] [ik-1] >>> WORD FOUND [不息] from dict [default]
[2025-07-09T16:54:22,618][INFO ][o.w.a.c.CN_QuantifierSegmenter] [ik-1] 当前扫描词元[,]不需要启动量词扫描
...测试方案 2:持续写入测试
测试方法:在 ik_max_word 和自定义词库的索引里,分别持续 bulk 写入,查看总体写入延迟。
测试索引:
# ik_max_word索引
PUT ik_max_test
{
"mappings": {
"properties": {
"chapter": {
"type": "keyword"
},
"content": {
"type": "text",
"analyzer": "ik_max_word"
},
"paragraph_id": {
"type": "keyword"
},
"random_field": {
"type": "text"
},
"timestamp": {
"type": "keyword"
},
"word_count": {
"type": "integer"
}
}
},
"settings": {
"index": {
"number_of_shards": "1",
"number_of_replicas": "0"
}
}
}
# 自定义词库索引
PUT ik_custom_test
{
"mappings": {
"properties": {
"chapter": {
"type": "keyword"
},
"content": {
"type": "text",
"analyzer": "my_custom_analyzer"
},
"paragraph_id": {
"type": "keyword"
},
"random_field": {
"type": "text"
},
"timestamp": {
"type": "keyword"
},
"word_count": {
"type": "integer"
}
}
},
"settings": {
"index": {
"number_of_shards": "1",
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "my_tokenizer"
}
},
"tokenizer": {
"my_tokenizer": {
"load_default_dicts": "true",
"type": "ik_max_word",
"dict_key": "test_dic",
"lowcase_enable": "true",
"custom_dict_enable": "true"
}
}
},
"number_of_replicas": "0"
}
}
}
这里利用脚本循环写入了一段《四世同堂》的文本,比较相同次数下,两次写入的总体延迟。
测试脚本内容如下:
#!/usr/bin/env python3
# -_- coding: utf-8 -_-
"""
四世同堂中文内容随机循环写入 Elasticsearch 脚本
目标:生成指定 bulk 次数的索引内容
"""
import random
import time
import json
from datetime import datetime
import requests
import logging
import os
import argparse
import urllib3
# 配置日志
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(**name**)
class ESDataGenerator:
def **init**(self, es_host='localhost', es_port=9200, index_name='sisitontang_content',
target_bulk_count=10000, batch_size=1000, use_https=False, username=None, password=None, verify_ssl=True):
"""
初始化 ES 连接和配置
"""
protocol = 'https' if use_https else 'http'
self.es_url = f'{protocol}://{es_host}:{es_port}'
self.index_name = index_name
self.target_bulk_count = target_bulk_count # 目标 bulk 次数
self.batch_size = batch_size
self.check_interval = 1000 # 每 1000 次 bulk 检查一次进度
# 设置认证信息
self.auth = None
if username and password:
self.auth = (username, password)
logger.info(f"使用用户名认证: {username}")
# 设置请求会话
self.session = requests.Session()
if self.auth:
self.session.auth = self.auth
# 处理HTTPS和SSL证书验证
if use_https:
self.session.verify = False # 始终禁用SSL验证以避免证书问题
logger.info("警告:已禁用SSL证书验证(适合开发测试环境)")
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
# 设置SSL适配器以处理连接问题
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
# 配置重试策略
retry_strategy = Retry(
total=3,
backoff_factor=1,
status_forcelist=[429, 500, 502, 503, 504],
)
adapter = HTTPAdapter(max_retries=retry_strategy)
self.session.mount("https://", adapter)
# 设置更宽松的SSL上下文
self.session.verify = False
logger.info(f"ES连接地址: {self.es_url}")
# 创建索引映射
self.create_index()
def create_index(self):
"""创建索引和映射"""
mapping = {
"mappings": {
"properties": {
"chapter": {"type": "keyword"},
"content": {"type": "text", "analyzer": "ik_max_word"},
"timestamp": {"type": "date"},
"word_count": {"type": "integer"},
"paragraph_id": {"type": "keyword"},
"random_field": {"type": "text"}
}
}
}
try:
# 检查索引是否存在
response = self.session.head(f"{self.es_url}/{self.index_name}")
if response.status_code == 200:
logger.info(f"索引 {self.index_name} 已存在")
else:
# 创建索引
response = self.session.put(
f"{self.es_url}/{self.index_name}",
headers={'Content-Type': 'application/json'},
json=mapping
)
if response.status_code in [200, 201]:
logger.info(f"创建索引 {self.index_name} 成功")
else:
logger.error(f"创建索引失败: {response.status_code} - {response.text}")
except Exception as e:
logger.error(f"创建索引失败: {e}")
def load_text_content(self, file_path='sisitontang.txt'):
"""
从文件加载《四世同堂》的完整文本内容
如果文件不存在,则返回扩展的示例内容
"""
if os.path.exists(file_path):
try:
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
logger.info(f"从文件 {file_path} 加载了 {len(content)} 个字符的文本内容")
return content
except Exception as e:
logger.error(f"读取文件失败: {e}")
# 如果文件不存在,返回扩展的示例内容
logger.info("使用内置的扩展示例内容")
return self.get_extended_sample_content()
def get_extended_sample_content(self):
"""
获取扩展的《四世同堂》示例内容
"""
content = """
小羊圈胡同是北平城里的一个小胡同。它不宽,可是很长,从东到西有一里多路。在这条胡同里,从东边数起,有个小茶馆,几个小门脸,和一群小房屋。小茶馆的斜对面是个较大的四合院,院子里有几棵大槐树。这个院子就是祁家的住所,四世同堂的大家庭就在这里度过了最困难的岁月。
祁老人是个善良的老头儿,虽然年纪大了,可是还很有精神。他的一生见证了太多的变迁,从清朝的衰落到民国的建立,再到现在的战乱,他都以一种达观的态度面对着。他的儿子祁天佑是个教书先生,为人正直,在胡同里很有威望。祁家的儿媳妇韵梅是个贤惠的女人,把家里打理得井井有条,即使在最困难的时候,也要维持着家庭的尊严。
钱默吟先生是个有学问的人,他的诗写得很好,可是性格有些古怪。他住在胡同深处的一个小院子里,平时很少出门,只是偶尔到祁家坐坐,和祁天佑聊聊古今。他对时局有着自己独特的见解,但更多的时候,他选择在自己的小天地里寻找精神的慰藉。战争的残酷现实让这个文人感到深深的无力,但他依然坚持着自己的文人气节。
小顺子是个活泼的孩子,他每天都在胡同里跑来跑去,和其他的孩子们一起玩耍。他的笑声总是能感染到周围的人,让这个古老的胡同充满了生机。即使在战争的阴霾下,孩子们依然保持着他们的天真和快乐,这或许就是生活的希望所在。小顺子不懂得大人们的烦恼,他只是简单地享受着童年的快乐。
李四大爷是个老实人,他在胡同里开了个小杂货铺。虽然生意不大,但是童叟无欺,街坊邻居们都愿意到他这里买东西。他的妻子是个能干的女人,把小铺子管理得很好。在那个物资匮乏的年代,能够维持一个小铺子的经营已经很不容易了。李四大爷经常帮助邻居们,即使自己的生活也不宽裕。
胡同里的生活是平静的,每天清晨,人们就开始忙碌起来。有的人挑着水桶去井边打水,有的人牵着羊去街上卖奶,有的人挑着菜担子去菜市场。这种平静的生活在战争来临之前是那么的珍贵,人们都珍惜着这样的日子。邻里之间相互照顾,孩子们在院子里玩耍,老人们在门口晒太阳聊天。
冠晓荷是个复杂的人物,他有文化,也有野心。在日本人占领北平的时候,他选择了与敌人合作,这让胡同里的人们都看不起他。但是他的妻子还是个好人,只是被丈夫连累了。冠晓荷的选择代表了那个时代一部分知识分子的软弱和妥协,他们在民族大义和个人利益之间选择了后者。
春天来了,胡同里的槐树发芽了,小鸟们在枝头歌唱。孩子们在院子里玩耍,老人们在门口晒太阳。这样的日子让人感到温暖和希望。即使在最黑暗的时期,生活依然要继续,人们依然要保持对美好未来的希望。春天的到来总是能够给人们带来新的希望和力量。
战争的阴云笼罩着整个城市,胡同里的人们也感受到了压力。有的人选择了抗争,有的人选择了妥协,有的人选择了逃避。每个人都在用自己的方式应对这个艰难的时代。祁瑞宣面临着痛苦的选择,他既不愿意与日本人合作,也不敢公开反抗,这种内心的煎熬让他备受折磨。
老舍先生用他细腻的笔触描绘了胡同里的众生相,每个人物都有自己的特点和命运。他们的喜怒哀乐构成了这部伟大作品的丰富内涵。从祁老爷子的达观,到祁瑞宣的痛苦,从韵梅的坚强,到冠晓荷的堕落,每个人物都是那个时代的缩影。
在那个动荡的年代,普通人的生活是不容易的。他们要面对战争的威胁,要面对生活的困难,要面对道德的选择。但是他们依然坚强地活着,为了家人,为了希望。即使在最困难的时候,人们依然保持着对美好生活的向往。
胡同里的邻里关系是复杂的,有友好的,也有矛盾的。但是在大的困难面前,大家还是会相互帮助。这种邻里之间的温情是中华民族传统文化的重要组成部分。在那个特殊的年代,这种人与人之间的温情显得更加珍贵。
祁瑞宣是个有理想的青年,他受过良好的教育,有自己的抱负。但是在日本人占领期间,他的理想和现实之间产生了尖锐的矛盾。他不愿意做汉奸,但是也不能完全抵抗。这种内心的矛盾和痛苦是那个时代很多知识分子的真实写照。
小妞子是个可爱的孩子,她的天真无邪给这个沉重的故事增添了一丝亮色。她不懂得大人们的复杂心理,只是简单地生活着,快乐着。孩子们的天真和快乐在那个黑暗的年代显得格外珍贵,它们代表着生活的希望和未来。
程长顺是个朴实的人,他没有什么文化,但是有自己的原则和底线。他不愿意向日本人低头,宁愿过艰苦的生活也要保持自己的尊严。他的坚持代表了中国人民不屈不挠的精神,即使在最困难的时候也不愿意妥协。
胡同里的生活节奏是缓慢的,人们有时间去观察周围的变化,去思考生活的意义。这种慢节奏的生活在今天看来是珍贵的,它让人们有机会去体验生活的细节。在那个年代,即使生活艰难,人们依然能够从平凡的日常中找到乐趣。
老二是个有个性的人,他不愿意受约束,喜欢自由自在的生活。但是在战争年代,这种个性给他带来了麻烦,也给家人带来了担忧。他的反叛精神在某种程度上代表着年轻一代对传统束缚的反抗,但在那个特殊的时代,这种反抗往往会带来意想不到的后果。
胡同里的四合院是北京传统建筑的代表,它们见证了一代又一代人的生活。每个院子里都有自己的故事,每个房间里都有自己的记忆。这些古老的建筑承载着深厚的历史文化底蕴,即使在战争的破坏下,依然坚强地屹立着。
在《四世同堂》这部作品中,老舍先生不仅描绘了个人的命运,也反映了整个民族的命运。小胡同里的故事其实就是大中国的缩影。每个人物的遭遇都代表着那个时代某一类人的命运,他们的选择和结局反映了整个民族在那个特殊历史时期的精神状态。
战争结束了,但是人们心中的创伤需要时间来愈合。胡同里的人们重新开始了正常的生活,但是那段艰难的经历永远不会被忘记。历史的教训提醒着人们珍惜和平,珍惜现在的美好生活。四世同堂的故事将永远流传下去,成为后人了解那个时代的重要窗口。
"""
return content.strip()
def split_text_randomly(self, text, min_length=100, max_length=200):
"""
将文本按100-200字的随机长度进行分割
"""
# 清理文本,移除多余的空白字符
text = ''.join(text.split())
segments = []
start = 0
while start < len(text):
# 随机选择段落长度
segment_length = random.randint(min_length, max_length)
end = min(start + segment_length, len(text))
segment = text[start:end]
if segment.strip(): # 确保段落不为空
segments.append(segment.strip())
start = end
return segments
def generate_random_content(self, base_content):
"""
基于基础内容生成随机变化的内容
"""
# 随机选择一个基础段落
base_paragraph = random.choice(base_content)
# 随机添加一些变化
variations = [
"在那个年代,",
"据说,",
"人们常常说,",
"老一辈人总是提到,",
"历史记录显示,",
"根据回忆,",
"有人说,",
"大家都知道,",
"传说中,",
"众所周知,"
]
endings = [
"这就是当时的情况。",
"这样的事情在那个年代很常见。",
"这个故事至今还在流传。",
"这是一个值得回忆的故事。",
"这样的经历让人难以忘怀。",
"这就是老北京的生活。",
"这种精神值得我们学习。",
"这个时代已经过去了。",
"这样的生活现在已经很难看到了。",
"这是历史的见证。"
]
# 随机组合内容
if random.random() < 0.3:
content = random.choice(variations) + base_paragraph
else:
content = base_paragraph
if random.random() < 0.3:
content += random.choice(endings)
return content
def generate_document(self, text_segments, doc_id):
"""基于文本段落生成一个文档"""
# 随机选择一个文本段落
content = random.choice(text_segments)
# 生成随机的额外字段以增加文档大小
random_field = ''.join(random.choices('abcdefghijklmnopqrstuvwxyz0123456789', k=random.randint(100, 500)))
doc = {
"chapter": f"第{random.randint(1, 100)}章",
"content": content,
"timestamp": datetime.now(),
"word_count": len(content),
"paragraph_id": f"para_{doc_id}",
"random_field": random_field
}
return doc
def get_index_size_gb(self):
"""获取索引大小(GB)"""
try:
response = self.session.get(f"{self.es_url}/_cat/indices/{self.index_name}?bytes=b&h=store.size&format=json")
if response.status_code == 200:
data = response.json()
if data and len(data) > 0:
size_bytes = int(data[0]['store.size'])
size_gb = size_bytes / (1024 * 1024 * 1024)
return size_gb
return 0
except Exception as e:
logger.error(f"获取索引大小失败: {e}")
return 0
def bulk_insert(self, documents):
"""批量插入文档使用HTTP bulk API"""
# 构建bulk请求体
bulk_data = []
for doc in documents:
# 添加action行
action = {"index": {"_index": self.index_name}}
bulk_data.append(json.dumps(action))
# 添加文档行
bulk_data.append(json.dumps(doc, ensure_ascii=False, default=str))
# 每行以换行符结束,最后也要有换行符
bulk_body = '\n'.join(bulk_data) + '\n'
try:
response = self.session.post(
f"{self.es_url}/_bulk",
headers={'Content-Type': 'application/x-ndjson'},
data=bulk_body.encode('utf-8'),
timeout=30 # 添加超时设置
)
if response.status_code == 200:
result = response.json()
# 检查是否有错误
if result.get('errors'):
error_count = 0
error_details = []
for item in result['items']:
if 'error' in item.get('index', {}):
error_count += 1
error_info = item['index']['error']
error_details.append(f"类型: {error_info.get('type')}, 原因: {error_info.get('reason')}")
if error_count > 0:
logger.warning(f"批量插入有 {error_count} 个错误")
# 打印前5个错误的详细信息
for i, error in enumerate(error_details[:5]):
logger.error(f"错误 {i+1}: {error}")
if len(error_details) > 5:
logger.error(f"... 还有 {len(error_details)-5} 个类似错误")
return True
else:
logger.error(f"批量插入失败: HTTP {response.status_code} - {response.text}")
return False
except requests.exceptions.SSLError as e:
logger.error(f"SSL连接错误: {e}")
logger.error("建议检查ES集群的SSL配置或使用 --no-verify-ssl 参数")
return False
except requests.exceptions.ConnectionError as e:
logger.error(f"连接错误: {e}")
logger.error("请检查ES集群地址和端口是否正确")
return False
except requests.exceptions.Timeout as e:
logger.error(f"请求超时: {e}")
logger.error("ES集群响应超时,可能负载过高")
return False
except Exception as e:
logger.error(f"批量插入失败: {e}")
logger.error(f"错误类型: {type(e).__name__}")
return False
def run(self):
"""运行数据生成器"""
start_time = time.time()
start_datetime = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
logger.info(f"开始生成数据,开始时间: {start_datetime},目标bulk次数: {self.target_bulk_count}")
# 加载文本内容
text_content = self.load_text_content()
# 将文本分割成100-200字的段落
text_segments = self.split_text_randomly(text_content, min_length=100, max_length=200)
logger.info(f"分割出 {len(text_segments)} 个文本段落")
doc_count = 0
bulk_count = 0
bulk_times = [] # 记录每次bulk的耗时
while bulk_count < self.target_bulk_count:
# 生成批量文档
documents = []
for i in range(self.batch_size):
doc = self.generate_document(text_segments, doc_count + i)
documents.append(doc)
# 记录单次bulk开始时间
bulk_start = time.time()
# 批量插入
if self.bulk_insert(documents):
bulk_end = time.time()
bulk_duration = bulk_end - bulk_start
bulk_times.append(bulk_duration)
doc_count += self.batch_size
bulk_count += 1
# 定期检查和报告进度
if bulk_count % self.check_interval == 0:
current_size = self.get_index_size_gb()
avg_bulk_time = sum(bulk_times[-self.check_interval:]) / len(bulk_times[-self.check_interval:])
logger.info(f"已完成 {bulk_count} 次bulk操作,插入 {doc_count} 条文档,当前索引大小: {current_size:.2f}GB,最近{self.check_interval}次bulk平均耗时: {avg_bulk_time:.3f}秒")
# 避免过于频繁的插入
#time.sleep(0.01) # 减少延迟,提高测试速度
end_time = time.time()
end_datetime = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
total_duration = end_time - start_time
# 计算统计信息
final_size = self.get_index_size_gb()
avg_bulk_time = sum(bulk_times) / len(bulk_times) if bulk_times else 0
total_docs_per_sec = doc_count / total_duration if total_duration > 0 else 0
bulk_per_sec = bulk_count / total_duration if total_duration > 0 else 0
logger.info(f"数据生成完成!")
logger.info(f"开始时间: {start_datetime}")
logger.info(f"结束时间: {end_datetime}")
logger.info(f"总耗时: {total_duration:.2f}秒 ({total_duration/60:.2f}分钟)")
logger.info(f"总计完成: {bulk_count} 次bulk操作")
logger.info(f"总计插入: {doc_count} 条文档")
logger.info(f"最终索引大小: {final_size:.2f}GB")
logger.info(f"平均每次bulk耗时: {avg_bulk_time:.3f}秒")
logger.info(f"平均bulk速率: {bulk_per_sec:.2f}次/秒")
logger.info(f"平均文档写入速率: {total_docs_per_sec:.0f}条/秒")
def main():
"""主函数"""
parser = argparse.ArgumentParser(description='四世同堂中文内容写入 Elasticsearch 脚本')
parser.add_argument('--host', default='localhost', help='ES 主机地址 (默认: localhost)')
parser.add_argument('--port', type=int, default=9200, help='ES 端口 (默认: 9200)')
parser.add_argument('--index', required=True, help='索引名称 (必填)')
parser.add_argument('--bulk-count', type=int, default=1000, help='目标 bulk 次数 (默认: 10000)')
parser.add_argument('--batch-size', type=int, default=1000, help='每次 bulk 的文档数量 (默认: 1000)')
parser.add_argument('--https', action='store_true', help='使用 HTTPS 协议')
parser.add_argument('--username', help='ES 用户名')
parser.add_argument('--password', help='ES 密码')
parser.add_argument('--no-verify-ssl', action='store_true', help='禁用 SSL 证书验证(默认已禁用)')
args = parser.parse_args()
protocol = "HTTPS" if args.https else "HTTP"
auth_info = f"认证: {args.username}" if args.username else "无认证"
ssl_info = "禁用SSL验证" if args.https else ""
logger.info(f"开始运行脚本,参数: {protocol}://{args.host}:{args.port}, 索引={args.index}, bulk次数={args.bulk_count}, {auth_info} {ssl_info}")
try:
generator = ESDataGenerator(
args.host,
args.port,
args.index,
args.bulk_count,
args.batch_size,
args.https,
args.username,
args.password,
not args.no_verify_ssl # 传入verify_ssl参数,但实际上总是False
)
generator.run()
except KeyboardInterrupt:
logger.info("用户中断了程序")
except Exception as e:
logger.error(f"程序运行出错: {e}")
logger.error(f"错误类型: {type(e).__name__}")
if **name** == "**main**":
main()
根据脚本中的测试文本添加的词库如下:
POST .analysis_ik/\_doc
{
"dict_type": "main_dicts",
"dict_key": "test_dic",
"dict_content": """祁老人
祁天佑
韵梅
祁瑞宣
老二
钱默吟
小顺子
李四大爷
冠晓荷
小妞子
程长顺
老舍
李四大爷
小羊圈胡同
北平城
胡同
小茶馆
小门脸
小房屋
四合院
院子
祁家
小院子
杂货铺
小铺子
井边
街上
菜市场
门口
枝头
城市
房间
北京
清朝
民国
战乱
战争
日本人
抗战
大槐树
槐树
小鸟
羊
门脸
房屋
水桶
菜担子
铺子
老头儿
儿子
教书先生
儿媳妇
女人
大家庭
孩子
孩子们
街坊邻居
妻子
老人
文人
知识分子
青年
汉奸
岁月
一生
变迁
衰落
建立
态度
威望
尊严
学问
诗
性格
时局
见解
小天地
精神
慰藉
现实
无力
气节
笑声
生机
阴霾
天真
快乐
希望
烦恼
童年
生意
生活
物资
年代
经营
日子
邻里
文化
野心
敌人
选择
软弱
妥协
民族大义
个人利益
温暖
时期
未来
力量
压力
抗争
逃避
方式
时代
煎熬
折磨
笔触
众生相
人物
特点
命运
喜怒哀乐
内涵
达观
痛苦
坚强
堕落
缩影
威胁
困难
道德
家人
向往
关系
矛盾
温情
传统文化
组成部分
理想
教育
抱负
占领
写照
亮色
心理
原则
底线
节奏
意义
细节
乐趣
个性
约束
麻烦
担忧
反叛精神
束缚
反抗
后果
建筑
代表
故事
记忆
历史文化底蕴
破坏
作品
创伤
经历
教训
和平
窗口
清晨
春天
内心
玩耍
聊天
晒太阳
歌唱
合作
打水
卖奶
帮助
"""
}进行 2 次集中写入的记录如下:
# ik_max_test
2025-07-13 20:15:33,294 - INFO - 开始时间: 2025-07-13 19:45:07
2025-07-13 20:15:33,294 - INFO - 结束时间: 2025-07-13 20:15:33
2025-07-13 20:15:33,294 - INFO - 总耗时: 1825.31秒 (30.42分钟)
2025-07-13 20:15:33,294 - INFO - 总计完成: 1000 次bulk操作
2025-07-13 20:15:33,294 - INFO - 总计插入: 1000000 条文档
2025-07-13 20:15:33,294 - INFO - 最终索引大小: 0.92GB
2025-07-13 20:15:33,294 - INFO - 平均每次bulk耗时: 1.790秒
2025-07-13 20:15:33,294 - INFO - 平均bulk速率: 0.55次/秒
2025-07-13 20:15:33,294 - INFO - 平均文档写入速率: 548条/秒
# ik_custom_test
2025-07-13 21:17:47,309 - INFO - 开始时间: 2025-07-13 20:44:03
2025-07-13 21:17:47,309 - INFO - 结束时间: 2025-07-13 21:17:47
2025-07-13 21:17:47,309 - INFO - 总耗时: 2023.53秒 (33.73分钟)
2025-07-13 21:17:47,309 - INFO - 总计完成: 1000 次bulk操作
2025-07-13 21:17:47,309 - INFO - 总计插入: 1000000 条文档
2025-07-13 21:17:47,309 - INFO - 最终索引大小: 0.92GB
2025-07-13 21:17:47,309 - INFO - 平均每次bulk耗时: 1.986秒
2025-07-13 21:17:47,309 - INFO - 平均bulk速率: 0.49次/秒
2025-07-13 21:17:47,309 - INFO - 平均文档写入速率: 494条/秒可以看到,有一定损耗,自定义词库词典的效率是之前的 90%。
相关阅读
关于 IK Analysis
IK Analysis 插件集成了 Lucene IK 分析器,并支持自定义词典。它支持 Easysearch\Elasticsearch\OpenSearch 的主要版本。由 INFINI Labs 维护并提供支持。
该插件包含分析器:ik_smart 和 ik_max_word,以及分词器:ik_smart 和 ik_max_word
开源地址:https://github.com/infinilabs/analysis-ik
作者:金多安,极限科技(INFINI Labs)搜索运维专家,Elastic 认证专家,搜索客社区日报责任编辑。一直从事与搜索运维相关的工作,日常会去挖掘 ES / Lucene 方向的搜索技术原理,保持搜索相关技术发展的关注。
原文:https://infinilabs.cn/blog/2025/ik-field-level-dictionarys-3/
海量科技股份有限公司ES中文插件
Elasticsearch • novia 发表了文章 • 6 个评论 • 4057 次浏览 • 2018-11-19 11:31
简繁体转换插件更新:elasticsearch-analysis-stconvert 升级支持2.0
资讯动态 • medcl 发表了文章 • 4 个评论 • 12808 次浏览 • 2015-12-24 11:45
