

社区日报 第477期 (2018-12-13)
http://t.cn/EUxkESo
2.Elasticsearch线程池分析
http://t.cn/EUxkDNg
3.Elasticsearch Pipeline Aggregations指南
http://t.cn/EUxFzZX
编辑:金桥
归档:https://elasticsearch.cn/article/6195
订阅:https://tinyletter.com/elastic-daily
http://t.cn/EUxkESo
2.Elasticsearch线程池分析
http://t.cn/EUxkDNg
3.Elasticsearch Pipeline Aggregations指南
http://t.cn/EUxFzZX
编辑:金桥
归档:https://elasticsearch.cn/article/6195
订阅:https://tinyletter.com/elastic-daily 收起阅读 »
Day 13 - Elasticsearch-Hadoop打通Elasticsearch和Hadoop
ES-Hadoop打通Elasticsearch和Hadoop
介绍
Elasticsearch作为强大的搜索引擎,Hadoop HDFS是分布式文件系统。
ES-Hadoop是一个深度集成Hadoop和ElasticSearch的项目,也是ES官方来维护的一个子项目。Elasticsearch可以将自身的Document导入到HDFS中用作备份;同时也可以将存储在HDFS上的结构化文件导入为ES中的Document,通过实现Hadoop和ES之间的输入输出,可以在Hadoop里面对ES集群的数据进行读取和写入,充分发挥Map-Reduce并行处理的优势,为Hadoop数据带来实时搜索的可能。
ES-Hadoop插件支持Map-Reduce、Cascading、Hive、Pig、Spark、Storm、yarn等组件。
ES-Hadoop整个数据流转图如下:

环境配置
- Elasticsearch 5.0.2
- Centos 7
- elasticsearch-hadoop 5.0.2
- repository-hdfs-5.0.2
Elasticsearch备份数据到HDFS
介绍
Elasticsearch副本提供了数据高可靠性,在部分节点丢失的情况下不中断服务;但是副本并不提供对灾难性故障的保护,同时在运维人员误操作情况下也不能保障数据的可恢复性。对于这种情况,我们需要对Elasticsearch集群数据的真正备份。
通过快照的方式,将Elasticsearch集群中的数据备份到HDFS上,这样数据既存在于Elasticsearch集群中,有存在于HDFS上。当ES集群出现不可恢复的故障时,可以将数据从HDFS上快速恢复。
操作步骤
-
下载插件 https://artifacts.elastic.co/downloads/elasticsearch-plugins/repository-hdfs/repository-hdfs-5.0.2.zip 保存在/usr/local下
-
安装插件
cd /usr/local/es/elasticsearch-5.0.2/bin ./elasticsearch-plugin install file:///usr/local/repository-hdfs-5.0.2.zip - 安装成功后需要重启Elasticsearch
备份与恢复
-
构建一个仓库
PUT http://192.168.10.74:9200/_snapshot/backup { "type": "hdfs", "settings": { "uri": "hdfs://192.168.10.170:9000", "path": "/es", "conf_location": "/usr/local/hadoop/etc/hadoop/hdfs-site.xml" } } -
备份快照
PUT http://192.168.10.74:9200/_snapshot/backup/snapshot_users?wait_for_completion=true { "indices": "users", //备份users的index,注意不设置这个属性,默认是备份所有index "ignore_unavailable": true, "include_global_state": false } -
恢复快照
POST http://192.168.10.74:9200/_snapshot/backup/snapshot_users/_restore { "indices": "users", //指定索引恢复,不指定就是所有 "ignore_unavailable": true, //忽略恢复时异常索引 "include_global_state": false //是否存储全局转态信息,fasle代表有一个或几个失败,不会导致整个任务失败 }
整合Spark与Elasticsearch
整体思路
- 数据首先存储在HDFS上,可以通过Spark SQL直接导入到ES中
- Spark SQL可以直接通过建立Dataframe或者临时表连接ES,达到搜索优化、减少数据量和数据筛选的目的,此时数据只在ES内存中而不再Spark SQL中
- 筛选后的数据重新导入到Spark SQL中进行查询
引入依赖
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch-hadoop</artifactId>
<version>5.0.2</version>
</dependency>具体流程
- 数据在HDFS上,数据存储在HDFS的每个DataNode的block上

-
数据加载到Spark SQL
- 数据从HDFS加载到Spark SQL中,以RDD形式存储
JavaRDD<String> textFile = spark.read().textFile("hdfs://192.168.10.170:9000/csv/user.csv")- 添加数据结构信息转换为新的RDD
JavaRDD<UserItem> dataSplits = textFile.map(line -> { String records = line.toString().trim(); String record = records.substring(0,records.length() - 1).trim(); String[] parts = record.split("\\|"); UserItem u = new UserItem(); u.setName(parts[0]); u.setAge(parts[1]); u.setHeight(parts[2]); return u; });- 根据新的RDD创建DataFrame
DataSet<Row> ds = spark.createDataFrame(dataSplits, UserItem.class);

-
由Dataset
创建索引,并写入ES
JavaEsSparkSQL.saveToEs(ds, "es_spark/users");
- 数据在ES中建立索引

-
Spark SQL通过索引对ES中的数据进行查询
SparkSession spark = SparkSession.builder().appName("es-spark").master("local").config("es.index.auto.create", true).getOrCreate(); Map<String, String> options = new HashMap<>(); options.put("pushdown", "true"); options.put("es.nodes","192.168.10.74:9200"); Dataset<Row> df = spark.read().options(options).format("org.elasticsearch.spark.sql").load("es_spark/users"); df.createOrReplaceTempView("users"); Dataset<Row> userSet = spark.sql("SELECT name FORM users WHERE age >=10 AND age <= 20"); userSet.show();
结束
ES-Hadoop无缝打通了ES和Hadoop两个非常优秀的框架,从而让ES的强大检索性能帮助我们快速分析海量数据。
ES-Hadoop打通Elasticsearch和Hadoop
介绍
Elasticsearch作为强大的搜索引擎,Hadoop HDFS是分布式文件系统。
ES-Hadoop是一个深度集成Hadoop和ElasticSearch的项目,也是ES官方来维护的一个子项目。Elasticsearch可以将自身的Document导入到HDFS中用作备份;同时也可以将存储在HDFS上的结构化文件导入为ES中的Document,通过实现Hadoop和ES之间的输入输出,可以在Hadoop里面对ES集群的数据进行读取和写入,充分发挥Map-Reduce并行处理的优势,为Hadoop数据带来实时搜索的可能。
ES-Hadoop插件支持Map-Reduce、Cascading、Hive、Pig、Spark、Storm、yarn等组件。
ES-Hadoop整个数据流转图如下:
环境配置
- Elasticsearch 5.0.2
- Centos 7
- elasticsearch-hadoop 5.0.2
- repository-hdfs-5.0.2
Elasticsearch备份数据到HDFS
介绍
Elasticsearch副本提供了数据高可靠性,在部分节点丢失的情况下不中断服务;但是副本并不提供对灾难性故障的保护,同时在运维人员误操作情况下也不能保障数据的可恢复性。对于这种情况,我们需要对Elasticsearch集群数据的真正备份。
通过快照的方式,将Elasticsearch集群中的数据备份到HDFS上,这样数据既存在于Elasticsearch集群中,有存在于HDFS上。当ES集群出现不可恢复的故障时,可以将数据从HDFS上快速恢复。
操作步骤
-
下载插件 https://artifacts.elastic.co/downloads/elasticsearch-plugins/repository-hdfs/repository-hdfs-5.0.2.zip 保存在/usr/local下
-
安装插件
cd /usr/local/es/elasticsearch-5.0.2/bin ./elasticsearch-plugin install file:///usr/local/repository-hdfs-5.0.2.zip - 安装成功后需要重启Elasticsearch
备份与恢复
-
构建一个仓库
PUT http://192.168.10.74:9200/_snapshot/backup { "type": "hdfs", "settings": { "uri": "hdfs://192.168.10.170:9000", "path": "/es", "conf_location": "/usr/local/hadoop/etc/hadoop/hdfs-site.xml" } } -
备份快照
PUT http://192.168.10.74:9200/_snapshot/backup/snapshot_users?wait_for_completion=true { "indices": "users", //备份users的index,注意不设置这个属性,默认是备份所有index "ignore_unavailable": true, "include_global_state": false } -
恢复快照
POST http://192.168.10.74:9200/_snapshot/backup/snapshot_users/_restore { "indices": "users", //指定索引恢复,不指定就是所有 "ignore_unavailable": true, //忽略恢复时异常索引 "include_global_state": false //是否存储全局转态信息,fasle代表有一个或几个失败,不会导致整个任务失败 }
整合Spark与Elasticsearch
整体思路
- 数据首先存储在HDFS上,可以通过Spark SQL直接导入到ES中
- Spark SQL可以直接通过建立Dataframe或者临时表连接ES,达到搜索优化、减少数据量和数据筛选的目的,此时数据只在ES内存中而不再Spark SQL中
- 筛选后的数据重新导入到Spark SQL中进行查询
引入依赖
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch-hadoop</artifactId>
<version>5.0.2</version>
</dependency>具体流程
- 数据在HDFS上,数据存储在HDFS的每个DataNode的block上
-
数据加载到Spark SQL
- 数据从HDFS加载到Spark SQL中,以RDD形式存储
JavaRDD<String> textFile = spark.read().textFile("hdfs://192.168.10.170:9000/csv/user.csv")- 添加数据结构信息转换为新的RDD
JavaRDD<UserItem> dataSplits = textFile.map(line -> { String records = line.toString().trim(); String record = records.substring(0,records.length() - 1).trim(); String[] parts = record.split("\\|"); UserItem u = new UserItem(); u.setName(parts[0]); u.setAge(parts[1]); u.setHeight(parts[2]); return u; });- 根据新的RDD创建DataFrame
DataSet<Row> ds = spark.createDataFrame(dataSplits, UserItem.class);
-
由Dataset
创建索引,并写入ES
JavaEsSparkSQL.saveToEs(ds, "es_spark/users");
- 数据在ES中建立索引
-
Spark SQL通过索引对ES中的数据进行查询
SparkSession spark = SparkSession.builder().appName("es-spark").master("local").config("es.index.auto.create", true).getOrCreate(); Map<String, String> options = new HashMap<>(); options.put("pushdown", "true"); options.put("es.nodes","192.168.10.74:9200"); Dataset<Row> df = spark.read().options(options).format("org.elasticsearch.spark.sql").load("es_spark/users"); df.createOrReplaceTempView("users"); Dataset<Row> userSet = spark.sql("SELECT name FORM users WHERE age >=10 AND age <= 20"); userSet.show();
结束
ES-Hadoop无缝打通了ES和Hadoop两个非常优秀的框架,从而让ES的强大检索性能帮助我们快速分析海量数据。
收起阅读 »社区日报 第476期 (2018-12-12)
http://t.cn/EUfESt7
2. 6.5.3发布了,还没升级到6的同学又多了一个新的选择!
http://t.cn/EUfEHvA
3. (自备梯子)如何不停机修改索引的 mapping?
http://t.cn/EUfErLr
编辑:rockybean
归档:https://elasticsearch.cn/article/6193
订阅:https://tinyletter.com/elastic-daily
http://t.cn/EUfESt7
2. 6.5.3发布了,还没升级到6的同学又多了一个新的选择!
http://t.cn/EUfEHvA
3. (自备梯子)如何不停机修改索引的 mapping?
http://t.cn/EUfErLr
编辑:rockybean
归档:https://elasticsearch.cn/article/6193
订阅:https://tinyletter.com/elastic-daily 收起阅读 »
logstash filter如何判断字段是够为空或者null
下面的是数据源, 并没有time字段的
{
"仓ku": "华南",
"originName": "",
"Code": "23248",
"BrandName": "",
"originCode": null,
"CategoryName": "原厂"
}下面的是数据源, 并没有time字段的
{
"仓ku": "华南",
"originName": "",
"Code": "23248",
"BrandName": "",
"originCode": null,
"CategoryName": "原厂"
}Day 12 - Elasticsearch日志场景最佳实践
1. 背景
Elasticsearch可广泛应用于日志分析、全文检索、结构化数据分析等多种场景,大幅度降低维护多套专用系统的成本,在开源社区非常受欢迎。然而Elasticsearch为满足多种不同的使用场景,底层组合使用了多种数据结构,部分数据结构对具体的用户使用场景可能是冗余的,从而导致默认情况下无法达到性能和成本最优化。 幸运的是,Elasticsearch提供非常灵活的模板配置能力,用户可以按需进行优化。多数情况下,用户结合使用场景进行优化后,Elasticsearch的性能都会有数倍的提升,成本也对应有倍数级别的下降。本文主要介绍不同日志使用场景下的调优经验。
2. 日志处理基本流程
日志处理的基本流程包含:日志采集 -> 数据清洗 -> 存储 -> 可视化分析。Elastic Stack提供完整的日志解决方案,帮助用户完成对日志处理全链路的管理,推荐大家使用。每个流程的处理如下:
- 日志采集:从业务所在的机器上,较实时的采集日志传递给下游。常用开源组件如Beats、Logstash、Fluentd等。
- 数据清洗:利用正则解析等机制,完成日志从文本数据到结构化数据的转换。用户可使用Logstash 或 Elasticsearch Ingest模块等完成数据清洗。
- 存储:使用Elasticsearch对数据进行持久存储,并提供全文搜索和分析能力。
- 可视化分析:通过图形界面,完成对日志的搜索分析,常用的开源组件如Kibana、Grafana。

使用Elastic Stack处理日志的详细过程,用户可参考官方文章Getting started with the Elastic Stack,这里不展开介绍。
3. 日志场景调优
对于Elasticsearch的通用调优,之前分享的文章Elasticsearch调优实践,详细介绍了Elasticsearch在性能、稳定性方面的调优经验。而对于日志场景,不同的场景使用方式差别较大,这里主要介绍常见使用方式下,性能和成本的优化思路。
3.1 基础场景
对于多数简单日志使用场景,用户一般只要求存储原始日志,并提供按关键字搜索日志记录的能力。对于此类场景,用户可跳过数据清洗阶段,并参考如下方式进行优化:
- 建议打开最优压缩,一般可降低40%存储。
- 设置原始日志字段(message)为text,去除keyword类型子字段,提供全文搜索能力,降低存储。
- 关闭_all索引,前面已通过message提供全文搜索能力。
- 对于其他字符串字段,统一设置为keyword类型,避免默认情况下字符串字段同时存储text、keyword两种类型的数据。
- 使用开源组件(如Beats)上报数据时会包含较多辅助信息,用户可通过修改组件配置文件进行裁剪。
这样去除message的keyword子字段、_all等冗余信息后,再加上最优压缩,可以保证数据相对精简。下面给出这类场景的常用模板,供用户参考:
{
"order": 5,
"template": "my_log_*",
"settings": {
"translog.durability": "async",
"translog.sync_interval": "5s",
"index.refresh_interval": "30s",
"index.codec": "best_compression" # 最优压缩
},
"mappings": {
"_default_": {
"_all": { # 关闭_all索引
"enabled": false
},
"dynamic_templates": [
{
"log": { # 原始日志字段,分词建立索引
"match": "message",
"mapping": {
"type": "text"
}
}
},
{
"strings": { # 其他字符串字段,统一设置为keyword类型
"match_mapping_type": "string",
"mapping": {
"type": "keyword"
}
}
}
]
}
}
}3.2 精准搜索场景
对于部分用户,普通的全文检索并不能满足需求,希望精准搜索日志中的某部分,例如每条日志中包含程序运行时多个阶段的耗时数据,对具体一个阶段的耗时进行搜索就比较麻烦。对于此类场景,用户可基于基础场景,进行如下调整:
- 清洗过程中,可仅解析出需要精准搜索的部分作为独立字段,用于精准搜索。
- 对于精准搜索字段,如果无排序/聚合需求,可以关闭doc_values;对于字符串,一般使用keyword,可按需考虑使用text。
下面给出这类场景的常用模板,供用户参考:
{
"order": 5,
"template": "my_log_*",
"settings": {
"translog.durability": "async",
"translog.sync_interval": "5s",
"index.refresh_interval": "30s",
"index.codec": "best_compression" # 最优压缩
},
"mappings": {
"_default_": {
"_all": { # 关闭_all索引
"enabled": false
},
"dynamic_templates": [
{
"log": { # 原始日志字段,分词建立索引
"match": "message",
"mapping": {
"type": "text"
}
}
},
{
"precise_fieldx": { # 精准搜索字段
"match": "fieldx",
"mapping": {
"type": "keyword",
"doc_values": false
}
}
},
{
"strings": { # 其他字符串字段,统一设置为keyword类型
"match_mapping_type": "string",
"mapping": {
"type": "keyword"
}
}
}
]
}
}
}3.3 统计分析场景
对于某些场景,日志包含的主要是程序运行时输出的统计信息,用户通常会完全解析日志进行精确查询、统计分析,而是否保存原始日志关系不大。对于此类场景,用户可进行如下调整:
- 清洗过程中,解析出所有需要的数据作为独立字段;原始日志非必要时,建议去除。
- 如果有强需求保留原始日志,可以设置该字段enabled属性为false,只存储不索引。
- 多数字段保持默认即可,会自动建立索引、打开doc_values,可用于查询、排序、聚合。
- 对部分无排序/聚合需求、开销高的字段,可以关闭doc_values。
下面给出这类场景的常用模板,供用户参考:
{
"order": 5,
"template": "my_log_*",
"settings": {
"translog.durability": "async",
"translog.sync_interval": "5s",
"index.refresh_interval": "30s",
"index.codec": "best_compression" # 最优压缩
},
"mappings": {
"_default_": {
"_all": { # 关闭_all索引
"enabled": false
},
"dynamic_templates": [
{
"log": { # 原始日志字段,关闭索引
"match": "message",
"mapping": {
"enabled": false
}
}
},
{
"index_only_fieldx": { # 仅索引的字段,无排序/聚合需求
"match": "fieldx",
"mapping": {
"type": "keyword",
"doc_values": false
}
}
},
{
"strings": { # 其他字符串字段,统一设置为keyword类型
"match_mapping_type": "string",
"mapping": {
"type": "keyword"
}
}
}
]
}
}
}ES 5.1及之后的版本,支持关键字查询时自动选择目标字段,用户没有必要再使用原始日志字段提供不指定字段进行查询的能力。
4. 小结
日志的使用方式比较灵活,本文结合常见的客户使用方式,从整体上对性能、成本进行优化。用户也可结合自身业务场景,参考文章Elasticsearch调优实践进行更细致的优化。
1. 背景
Elasticsearch可广泛应用于日志分析、全文检索、结构化数据分析等多种场景,大幅度降低维护多套专用系统的成本,在开源社区非常受欢迎。然而Elasticsearch为满足多种不同的使用场景,底层组合使用了多种数据结构,部分数据结构对具体的用户使用场景可能是冗余的,从而导致默认情况下无法达到性能和成本最优化。 幸运的是,Elasticsearch提供非常灵活的模板配置能力,用户可以按需进行优化。多数情况下,用户结合使用场景进行优化后,Elasticsearch的性能都会有数倍的提升,成本也对应有倍数级别的下降。本文主要介绍不同日志使用场景下的调优经验。
2. 日志处理基本流程
日志处理的基本流程包含:日志采集 -> 数据清洗 -> 存储 -> 可视化分析。Elastic Stack提供完整的日志解决方案,帮助用户完成对日志处理全链路的管理,推荐大家使用。每个流程的处理如下:
- 日志采集:从业务所在的机器上,较实时的采集日志传递给下游。常用开源组件如Beats、Logstash、Fluentd等。
- 数据清洗:利用正则解析等机制,完成日志从文本数据到结构化数据的转换。用户可使用Logstash 或 Elasticsearch Ingest模块等完成数据清洗。
- 存储:使用Elasticsearch对数据进行持久存储,并提供全文搜索和分析能力。
- 可视化分析:通过图形界面,完成对日志的搜索分析,常用的开源组件如Kibana、Grafana。
使用Elastic Stack处理日志的详细过程,用户可参考官方文章Getting started with the Elastic Stack,这里不展开介绍。
3. 日志场景调优
对于Elasticsearch的通用调优,之前分享的文章Elasticsearch调优实践,详细介绍了Elasticsearch在性能、稳定性方面的调优经验。而对于日志场景,不同的场景使用方式差别较大,这里主要介绍常见使用方式下,性能和成本的优化思路。
3.1 基础场景
对于多数简单日志使用场景,用户一般只要求存储原始日志,并提供按关键字搜索日志记录的能力。对于此类场景,用户可跳过数据清洗阶段,并参考如下方式进行优化:
- 建议打开最优压缩,一般可降低40%存储。
- 设置原始日志字段(message)为text,去除keyword类型子字段,提供全文搜索能力,降低存储。
- 关闭_all索引,前面已通过message提供全文搜索能力。
- 对于其他字符串字段,统一设置为keyword类型,避免默认情况下字符串字段同时存储text、keyword两种类型的数据。
- 使用开源组件(如Beats)上报数据时会包含较多辅助信息,用户可通过修改组件配置文件进行裁剪。
这样去除message的keyword子字段、_all等冗余信息后,再加上最优压缩,可以保证数据相对精简。下面给出这类场景的常用模板,供用户参考:
{
"order": 5,
"template": "my_log_*",
"settings": {
"translog.durability": "async",
"translog.sync_interval": "5s",
"index.refresh_interval": "30s",
"index.codec": "best_compression" # 最优压缩
},
"mappings": {
"_default_": {
"_all": { # 关闭_all索引
"enabled": false
},
"dynamic_templates": [
{
"log": { # 原始日志字段,分词建立索引
"match": "message",
"mapping": {
"type": "text"
}
}
},
{
"strings": { # 其他字符串字段,统一设置为keyword类型
"match_mapping_type": "string",
"mapping": {
"type": "keyword"
}
}
}
]
}
}
}3.2 精准搜索场景
对于部分用户,普通的全文检索并不能满足需求,希望精准搜索日志中的某部分,例如每条日志中包含程序运行时多个阶段的耗时数据,对具体一个阶段的耗时进行搜索就比较麻烦。对于此类场景,用户可基于基础场景,进行如下调整:
- 清洗过程中,可仅解析出需要精准搜索的部分作为独立字段,用于精准搜索。
- 对于精准搜索字段,如果无排序/聚合需求,可以关闭doc_values;对于字符串,一般使用keyword,可按需考虑使用text。
下面给出这类场景的常用模板,供用户参考:
{
"order": 5,
"template": "my_log_*",
"settings": {
"translog.durability": "async",
"translog.sync_interval": "5s",
"index.refresh_interval": "30s",
"index.codec": "best_compression" # 最优压缩
},
"mappings": {
"_default_": {
"_all": { # 关闭_all索引
"enabled": false
},
"dynamic_templates": [
{
"log": { # 原始日志字段,分词建立索引
"match": "message",
"mapping": {
"type": "text"
}
}
},
{
"precise_fieldx": { # 精准搜索字段
"match": "fieldx",
"mapping": {
"type": "keyword",
"doc_values": false
}
}
},
{
"strings": { # 其他字符串字段,统一设置为keyword类型
"match_mapping_type": "string",
"mapping": {
"type": "keyword"
}
}
}
]
}
}
}3.3 统计分析场景
对于某些场景,日志包含的主要是程序运行时输出的统计信息,用户通常会完全解析日志进行精确查询、统计分析,而是否保存原始日志关系不大。对于此类场景,用户可进行如下调整:
- 清洗过程中,解析出所有需要的数据作为独立字段;原始日志非必要时,建议去除。
- 如果有强需求保留原始日志,可以设置该字段enabled属性为false,只存储不索引。
- 多数字段保持默认即可,会自动建立索引、打开doc_values,可用于查询、排序、聚合。
- 对部分无排序/聚合需求、开销高的字段,可以关闭doc_values。
下面给出这类场景的常用模板,供用户参考:
{
"order": 5,
"template": "my_log_*",
"settings": {
"translog.durability": "async",
"translog.sync_interval": "5s",
"index.refresh_interval": "30s",
"index.codec": "best_compression" # 最优压缩
},
"mappings": {
"_default_": {
"_all": { # 关闭_all索引
"enabled": false
},
"dynamic_templates": [
{
"log": { # 原始日志字段,关闭索引
"match": "message",
"mapping": {
"enabled": false
}
}
},
{
"index_only_fieldx": { # 仅索引的字段,无排序/聚合需求
"match": "fieldx",
"mapping": {
"type": "keyword",
"doc_values": false
}
}
},
{
"strings": { # 其他字符串字段,统一设置为keyword类型
"match_mapping_type": "string",
"mapping": {
"type": "keyword"
}
}
}
]
}
}
}ES 5.1及之后的版本,支持关键字查询时自动选择目标字段,用户没有必要再使用原始日志字段提供不指定字段进行查询的能力。
4. 小结
日志的使用方式比较灵活,本文结合常见的客户使用方式,从整体上对性能、成本进行优化。用户也可结合自身业务场景,参考文章Elasticsearch调优实践进行更细致的优化。
收起阅读 »用elasitc stack监控kafka
当我们搭建elasitc stack集群时,大多数时候会在我们的架构中加入kafka作为消息缓冲区,即从beats -> kafka -> logstash -> elasticsearch这样的一个消息流。使用kafka可以给我们带来很多便利,但是也让我们需要额外多维护一套组件,elasitc stack本身已经提供了monitoring的功能,我们可以方便的从kibana上监控各个组件中各节点的可用性,吞吐和性能等各种指标,但kafka作为架构中的组件之一却游离在监控之外,相当不合理。
幸而elastic真的是迭代的相当快,在metricbeat上很早就有了对kafka的监控,但一直没有一个直观的dashboard,终于在6.5版本上,上新了kafka dashboard。我们来看一下吧。
安装和配置metricbeat
安装包下载地址,下载后,自己安装。
然后,将/etc/metricbeat/modules.d/kafka.yml.disable文件重命名为/etc/metricbeat/modules.d/kafka.yml。(即打开kafka的监控)。稍微修改一下文件内容, 注意,这里需填入所有你需要监控的kafka服务器的地址:
# Module: kafka
# Docs: https://www.elastic.co/guide/en/beats/metricbeat/6.4/metricbeat-module-kafka.html
- module: kafka
metricsets:
- partition
- consumergroup
period: 20s
hosts: ["10.*.*.*:9092","10.*.*.*:9092","10.*.*.*:9092","10.*.*.*:9092"]
#client_id: metricbeat
#retries: 3
#backoff: 250ms
# List of Topics to query metadata for. If empty, all topics will be queried.
#topics: []
# Optional SSL. By default is off.
# List of root certificates for HTTPS server verifications
#ssl.certificate_authorities: ["/etc/pki/root/ca.pem"]
# Certificate for SSL client authentication
#ssl.certificate: "/etc/pki/client/cert.pem"
# Client Certificate Key
#ssl.key: "/etc/pki/client/cert.key"
# SASL authentication
#username: ""
#password: ""运行metricbeat,这里,一定要注意enable kibana dashboard。
然后就可以在kibana里面看到:


这样,我们就可以通过sentinl等类似的插件,自动做kafka的告警等功能了
当我们搭建elasitc stack集群时,大多数时候会在我们的架构中加入kafka作为消息缓冲区,即从beats -> kafka -> logstash -> elasticsearch这样的一个消息流。使用kafka可以给我们带来很多便利,但是也让我们需要额外多维护一套组件,elasitc stack本身已经提供了monitoring的功能,我们可以方便的从kibana上监控各个组件中各节点的可用性,吞吐和性能等各种指标,但kafka作为架构中的组件之一却游离在监控之外,相当不合理。
幸而elastic真的是迭代的相当快,在metricbeat上很早就有了对kafka的监控,但一直没有一个直观的dashboard,终于在6.5版本上,上新了kafka dashboard。我们来看一下吧。
安装和配置metricbeat
安装包下载地址,下载后,自己安装。
然后,将/etc/metricbeat/modules.d/kafka.yml.disable文件重命名为/etc/metricbeat/modules.d/kafka.yml。(即打开kafka的监控)。稍微修改一下文件内容, 注意,这里需填入所有你需要监控的kafka服务器的地址:
# Module: kafka
# Docs: https://www.elastic.co/guide/en/beats/metricbeat/6.4/metricbeat-module-kafka.html
- module: kafka
metricsets:
- partition
- consumergroup
period: 20s
hosts: ["10.*.*.*:9092","10.*.*.*:9092","10.*.*.*:9092","10.*.*.*:9092"]
#client_id: metricbeat
#retries: 3
#backoff: 250ms
# List of Topics to query metadata for. If empty, all topics will be queried.
#topics: []
# Optional SSL. By default is off.
# List of root certificates for HTTPS server verifications
#ssl.certificate_authorities: ["/etc/pki/root/ca.pem"]
# Certificate for SSL client authentication
#ssl.certificate: "/etc/pki/client/cert.pem"
# Client Certificate Key
#ssl.key: "/etc/pki/client/cert.key"
# SASL authentication
#username: ""
#password: ""运行metricbeat,这里,一定要注意enable kibana dashboard。
然后就可以在kibana里面看到:
这样,我们就可以通过sentinl等类似的插件,自动做kafka的告警等功能了
收起阅读 »搭建Elasitc stack集群需要注意的日志问题
@[toc] 搭建Elasitc stack集群时,我们往往把大部分注意力放在集群的搭建,索引的优化,分片的设置上等具体的调优参数上,很少有人会去关心Elasitc stack的日志配置的问题,大概是觉得,日志应该是一个公共的问题,默认的配置应该已经为我们处理好了。但很不幸,在不同的机器配置或者不同的运营策略下,如果采用默认的配置,会给我们带来麻烦。
默认配置带来的麻烦
以下例子是默认情况下,当Elasitc stack集群运行超过3个月之后的情况:
elasticsearch
elasticsearch默认情况下会每天rolling一个文件,当到达2G的时候,才开始清除超出的部分,当一个文件只有几十K的时候,文件会一直累计下来。

logstash
一直增长的gc文件和不停增多的rolling日志文件

kibana
默认日志输出到kibana.out文件当中,这个文件会变得越来越大

kafka
这里提到kafka是因为在大部分的架构当中,我们都会用到kafka作为中间件数据缓冲区,因此不得不维护kafka集群。同样,如果不做特定的配置,也会遇到日志的问题:不停增多的rolling日志文件

原因是kafka的默认log4j配置是使用DailyRollingFileAppender每隔一个小时生成一个文件 '.'yyyy-MM-dd-HH:
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=[%d] %p %m (%c)%n
log4j.appender.kafkaAppender=org.apache.log4j.DailyRollingFileAppender
log4j.appender.kafkaAppender.DatePattern='.'yyyy-MM-dd-HH
log4j.appender.kafkaAppender.File=${kafka.logs.dir}/server.log
log4j.appender.kafkaAppender.layout=org.apache.log4j.PatternLayout
log4j.appender.kafkaAppender.layout.ConversionPattern=[%d] %p %m (%c)%n
log4j.appender.stateChangeAppender=org.apache.log4j.DailyRollingFileAppender
log4j.appender.stateChangeAppender.DatePattern='.'yyyy-MM-dd-HH
log4j.appender.stateChangeAppender.File=${kafka.logs.dir}/state-change.log
log4j.appender.stateChangeAppender.layout=org.apache.log4j.PatternLayout
log4j.appender.stateChangeAppender.layout.ConversionPattern=[%d] %p %m (%c)%n
log4j.appender.requestAppender=org.apache.log4j.DailyRollingFileAppender
log4j.appender.requestAppender.DatePattern='.'yyyy-MM-dd-HH
log4j.appender.requestAppender.File=${kafka.logs.dir}/kafka-request.log
log4j.appender.requestAppender.layout=org.apache.log4j.PatternLayout
log4j.appender.requestAppender.layout.ConversionPattern=[%d] %p %m (%c)%n
log4j.appender.cleanerAppender=org.apache.log4j.DailyRollingFileAppender
log4j.appender.cleanerAppender.DatePattern='.'yyyy-MM-dd-HH
log4j.appender.cleanerAppender.File=${kafka.logs.dir}/log-cleaner.log
log4j.appender.cleanerAppender.layout=org.apache.log4j.PatternLayout
log4j.appender.cleanerAppender.layout.ConversionPattern=[%d] %p %m (%c)%n
log4j.appender.controllerAppender=org.apache.log4j.DailyRollingFileAppender
log4j.appender.controllerAppender.DatePattern='.'yyyy-MM-dd-HH
log4j.appender.controllerAppender.File=${kafka.logs.dir}/controller.log
log4j.appender.controllerAppender.layout=org.apache.log4j.PatternLayout
log4j.appender.controllerAppender.layout.ConversionPattern=[%d] %p %m (%c)%n
log4j.appender.authorizerAppender=org.apache.log4j.DailyRollingFileAppender
log4j.appender.authorizerAppender.DatePattern='.'yyyy-MM-dd-HH
log4j.appender.authorizerAppender.File=${kafka.logs.dir}/kafka-authorizer.log
log4j.appender.authorizerAppender.layout=org.apache.log4j.PatternLayout
log4j.appender.authorizerAppender.layout.ConversionPattern=[%d] %p %m (%c)%n解决方案
因此,对于我们需要维护的这几个组件,需要配置合理的日志rotate策略。一个比较常用的策略就是时间+size,每天rotate一个日志文件或者每当日志文件大小超过256M,rotate一个新的日志文件,并且最多保留7天之内的日志文件。
elasticsearch
通过修改log4j2.properties文件来解决。该文件在/etc/elasticsesarch目录下(或者config目录)。
默认配置是:
appender.rolling.type = RollingFile
appender.rolling.name = rolling
appender.rolling.fileName = ${sys:es.logs.base_path}${sys:file.separator}${sys:es.logs.cluster_name}.log
appender.rolling.layout.type = PatternLayout
appender.rolling.layout.pattern = [%d{ISO8601}][%-5p][%-25c{1.}] [%node_name]%marker %.-10000m%n
appender.rolling.filePattern = ${sys:es.logs.base_path}${sys:file.separator}${sys:es.logs.cluster_name}-%d{yyyy-MM-dd}-%i.log.gz
appender.rolling.policies.type = Policies
appender.rolling.policies.time.type = TimeBasedTriggeringPolicy
appender.rolling.policies.time.interval = 1
appender.rolling.policies.time.modulate = true
appender.rolling.policies.size.type = SizeBasedTriggeringPolicy
appender.rolling.policies.size.size = 256MB
appender.rolling.strategy.type = DefaultRolloverStrategy
appender.rolling.strategy.fileIndex = nomax
appender.rolling.strategy.action.type = Delete
appender.rolling.strategy.action.basepath = ${sys:es.logs.base_path}
appender.rolling.strategy.action.condition.type = IfFileName
appender.rolling.strategy.action.condition.glob = ${sys:es.logs.cluster_name}-*
appender.rolling.strategy.action.condition.nested_condition.type = IfAccumulatedFileSize
appender.rolling.strategy.action.condition.nested_condition.exceeds = 2GB 以上默认配置,会保存2GB的日志,只有累计的日志大小超过2GB的时候,才会删除旧的日志文件。 建议改为如下配置,仅保留最近7天的日志
appender.rolling.strategy.type = DefaultRolloverStrategy
appender.rolling.strategy.action.type = Delete
appender.rolling.strategy.action.basepath = ${sys:es.logs.base_path}
appender.rolling.strategy.action.condition.type = IfFileName
appender.rolling.strategy.action.condition.glob = ${sys:es.logs.cluster_name}-*
appender.rolling.strategy.action.condition.nested_condition.type = IfLastModified
appender.rolling.strategy.action.condition.nested_condition.age = 7D这里必须注意,log4j2会因为末尾的空格导致无法识别配置
logstash
与elasticsearch类似,通过修改log4j2.properties文件来解决。该文件在/etc/logstash目录下(或者config目录)。
默认配置是不会删除历史日志的:
status = error
name = LogstashPropertiesConfig
appender.console.type = Console
appender.console.name = plain_console
appender.console.layout.type = PatternLayout
appender.console.layout.pattern = [%d{ISO8601}][%-5p][%-25c] %m%n
appender.json_console.type = Console
appender.json_console.name = json_console
appender.json_console.layout.type = JSONLayout
appender.json_console.layout.compact = true
appender.json_console.layout.eventEol = true
appender.rolling.type = RollingFile
appender.rolling.name = plain_rolling
appender.rolling.fileName = ${sys:ls.logs}/logstash-${sys:ls.log.format}.log
appender.rolling.filePattern = ${sys:ls.logs}/logstash-${sys:ls.log.format}-%d{yyyy-MM-dd}.log
appender.rolling.policies.type = Policies
appender.rolling.policies.time.type = TimeBasedTriggeringPolicy
appender.rolling.policies.time.interval = 1
appender.rolling.policies.time.modulate = true
appender.rolling.layout.type = PatternLayout
appender.rolling.layout.pattern = [%d{ISO8601}][%-5p][%-25c] %-.10000m%n需手动加上:
appender.rolling.strategy.type = DefaultRolloverStrategy
appender.rolling.strategy.action.type = Delete
appender.rolling.strategy.action.basepath = ${sys:ls.logs}
appender.rolling.strategy.action.condition.type = IfFileName
appender.rolling.strategy.action.condition.glob = ${sys:ls.logs}/logstash-${sys:ls.log.format}
appender.rolling.strategy.action.condition.nested_condition.type = IfLastModified
appender.rolling.strategy.action.condition.nested_condition.age = 7Dkibana
在kibana的配置文件中,只有以下几个选项:
logging.dest:
Default: stdout Enables you specify a file where Kibana stores log output.
logging.quiet:
Default: false Set the value of this setting to true to suppress all logging output other than error messages.
logging.silent:
Default: false Set the value of this setting to true to suppress all logging output.
logging.verbose:
Default: false Set the value of this setting to true to log all events, including system usage information and all requests. Supported on Elastic Cloud Enterprise.
logging.timezone
Default: UTC Set to the canonical timezone id (e.g. US/Pacific) to log events using that timezone. A list of timezones can be referenced at https://en.wikipedia.org/wiki/List_of_tz_database_time_zones.我们可以指定输出的日志文件与日志内容,但是却不可以配置日志的rotate。这时,我们需要使用logrotate,这个linux默认安装的工具。 首先,我们要在配置文件里面指定生成pid文件:
pid.file: "pid.log"然后,修改/etc/logrotate.conf:
/var/log/kibana {
missingok
notifempty
sharedscripts
daily
rotate 7
copytruncate
/bin/kill -HUP $(cat /usr/share/kibana/pid.log 2>/dev/null) 2>/dev/null
endscript
}kafka
如果不想写脚本清理过多的文件的话,需要修改config/log4j.properties文件。使用RollingFileAppender代替DailyRollingFileAppender,同时设置MaxFileSize和MaxBackupIndex。即修改为:
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=[%d] %p %m (%c)%n
log4j.appender.kafkaAppender=org.apache.log4j.RollingFileAppender
log4j.appender.kafkaAppender.File=${kafka.logs.dir}/server.log
log4j.appender.kafkaAppender.MaxFileSize=10MB
log4j.appender.kafkaAppender.MaxBackupIndex=10
log4j.appender.kafkaAppender.layout=org.apache.log4j.PatternLayout
log4j.appender.kafkaAppender.layout.ConversionPattern=[%d] %p %m (%c)%n
log4j.appender.stateChangeAppender=org.apache.log4j.RollingFileAppender
log4j.appender.stateChangeAppender.File=${kafka.logs.dir}/state-change.log
log4j.appender.stateChangeAppender.MaxFileSize=10M
log4j.appender.stateChangeAppender.MaxBackupIndex=10
log4j.appender.stateChangeAppender.layout=org.apache.log4j.PatternLayout
log4j.appender.stateChangeAppender.layout.ConversionPattern=[%d] %p %m (%c)%n
log4j.appender.requestAppender=org.apache.log4j.RollingFileAppender
log4j.appender.requestAppender.File=${kafka.logs.dir}/kafka-request.log
log4j.appender.requestAppender.MaxFileSize=10MB
log4j.appender.requestAppender.MaxBackupIndex=10
log4j.appender.requestAppender.layout=org.apache.log4j.PatternLayout
log4j.appender.requestAppender.layout.ConversionPattern=[%d] %p %m (%c)%n
log4j.appender.cleanerAppender=org.apache.log4j.RollingFileAppender
log4j.appender.cleanerAppender.File=${kafka.logs.dir}/log-cleaner.log
log4j.appender.cleanerAppender.MaxFileSize=10MB
log4j.appender.cleanerAppender.MaxBackupIndex=10
log4j.appender.cleanerAppender.layout=org.apache.log4j.PatternLayout
log4j.appender.cleanerAppender.layout.ConversionPattern=[%d] %p %m (%c)%n
log4j.appender.controllerAppender=org.apache.log4j.RollingFileAppender
log4j.appender.controllerAppender.File=${kafka.logs.dir}/controller.log
log4j.appender.controllerAppender.MaxFileSize=10MB
log4j.appender.controllerAppender.MaxBackupIndex=10
log4j.appender.controllerAppender.layout=org.apache.log4j.PatternLayout
log4j.appender.controllerAppender.layout.ConversionPattern=[%d] %p %m (%c)%n
log4j.appender.authorizerAppender=org.apache.log4j.RollingFileAppender
log4j.appender.authorizerAppender.File=${kafka.logs.dir}/kafka-authorizer.log
log4j.appender.authorizerAppender.MaxFileSize=10MB
log4j.appender.authorizerAppender.MaxBackupIndex=10
log4j.appender.authorizerAppender.layout=org.apache.log4j.PatternLayout
log4j.appender.authorizerAppender.layout.ConversionPattern=[%d] %p %m (%c)%n
# Turn on all our debugging info
#log4j.logger.kafka.producer.async.DefaultEventHandler=DEBUG, kafkaAppender
#log4j.logger.kafka.client.ClientUtils=DEBUG, kafkaAppender
#log4j.logger.kafka.perf=DEBUG, kafkaAppender
#log4j.logger.kafka.perf.ProducerPerformance$ProducerThread=DEBUG, kafkaAppender
#log4j.logger.org.I0Itec.zkclient.ZkClient=DEBUG
log4j.logger.kafka=INFO, kafkaAppender
log4j.logger.kafka.network.RequestChannel$=WARN, requestAppender
log4j.additivity.kafka.network.RequestChannel$=false
#log4j.logger.kafka.network.Processor=TRACE, requestAppender
#log4j.logger.kafka.server.KafkaApis=TRACE, requestAppender
#log4j.additivity.kafka.server.KafkaApis=false
log4j.logger.kafka.request.logger=WARN, requestAppender
log4j.additivity.kafka.request.logger=false
log4j.logger.kafka.controller=TRACE, controllerAppender
log4j.additivity.kafka.controller=false
log4j.logger.kafka.log.LogCleaner=INFO, cleanerAppender
log4j.additivity.kafka.log.LogCleaner=false
log4j.logger.state.change.logger=TRACE, stateChangeAppender
log4j.additivity.state.change.logger=false
#Change this to debug to get the actual audit log for authorizer.
log4j.logger.kafka.authorizer.logger=WARN, authorizerAppender
log4j.additivity.kafka.authorizer.logger=false@[toc] 搭建Elasitc stack集群时,我们往往把大部分注意力放在集群的搭建,索引的优化,分片的设置上等具体的调优参数上,很少有人会去关心Elasitc stack的日志配置的问题,大概是觉得,日志应该是一个公共的问题,默认的配置应该已经为我们处理好了。但很不幸,在不同的机器配置或者不同的运营策略下,如果采用默认的配置,会给我们带来麻烦。
默认配置带来的麻烦
以下例子是默认情况下,当Elasitc stack集群运行超过3个月之后的情况:
elasticsearch
elasticsearch默认情况下会每天rolling一个文件,当到达2G的时候,才开始清除超出的部分,当一个文件只有几十K的时候,文件会一直累计下来。
logstash
一直增长的gc文件和不停增多的rolling日志文件
kibana
默认日志输出到kibana.out文件当中,这个文件会变得越来越大
kafka
这里提到kafka是因为在大部分的架构当中,我们都会用到kafka作为中间件数据缓冲区,因此不得不维护kafka集群。同样,如果不做特定的配置,也会遇到日志的问题:不停增多的rolling日志文件
原因是kafka的默认log4j配置是使用DailyRollingFileAppender每隔一个小时生成一个文件 '.'yyyy-MM-dd-HH:
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=[%d] %p %m (%c)%n
log4j.appender.kafkaAppender=org.apache.log4j.DailyRollingFileAppender
log4j.appender.kafkaAppender.DatePattern='.'yyyy-MM-dd-HH
log4j.appender.kafkaAppender.File=${kafka.logs.dir}/server.log
log4j.appender.kafkaAppender.layout=org.apache.log4j.PatternLayout
log4j.appender.kafkaAppender.layout.ConversionPattern=[%d] %p %m (%c)%n
log4j.appender.stateChangeAppender=org.apache.log4j.DailyRollingFileAppender
log4j.appender.stateChangeAppender.DatePattern='.'yyyy-MM-dd-HH
log4j.appender.stateChangeAppender.File=${kafka.logs.dir}/state-change.log
log4j.appender.stateChangeAppender.layout=org.apache.log4j.PatternLayout
log4j.appender.stateChangeAppender.layout.ConversionPattern=[%d] %p %m (%c)%n
log4j.appender.requestAppender=org.apache.log4j.DailyRollingFileAppender
log4j.appender.requestAppender.DatePattern='.'yyyy-MM-dd-HH
log4j.appender.requestAppender.File=${kafka.logs.dir}/kafka-request.log
log4j.appender.requestAppender.layout=org.apache.log4j.PatternLayout
log4j.appender.requestAppender.layout.ConversionPattern=[%d] %p %m (%c)%n
log4j.appender.cleanerAppender=org.apache.log4j.DailyRollingFileAppender
log4j.appender.cleanerAppender.DatePattern='.'yyyy-MM-dd-HH
log4j.appender.cleanerAppender.File=${kafka.logs.dir}/log-cleaner.log
log4j.appender.cleanerAppender.layout=org.apache.log4j.PatternLayout
log4j.appender.cleanerAppender.layout.ConversionPattern=[%d] %p %m (%c)%n
log4j.appender.controllerAppender=org.apache.log4j.DailyRollingFileAppender
log4j.appender.controllerAppender.DatePattern='.'yyyy-MM-dd-HH
log4j.appender.controllerAppender.File=${kafka.logs.dir}/controller.log
log4j.appender.controllerAppender.layout=org.apache.log4j.PatternLayout
log4j.appender.controllerAppender.layout.ConversionPattern=[%d] %p %m (%c)%n
log4j.appender.authorizerAppender=org.apache.log4j.DailyRollingFileAppender
log4j.appender.authorizerAppender.DatePattern='.'yyyy-MM-dd-HH
log4j.appender.authorizerAppender.File=${kafka.logs.dir}/kafka-authorizer.log
log4j.appender.authorizerAppender.layout=org.apache.log4j.PatternLayout
log4j.appender.authorizerAppender.layout.ConversionPattern=[%d] %p %m (%c)%n解决方案
因此,对于我们需要维护的这几个组件,需要配置合理的日志rotate策略。一个比较常用的策略就是时间+size,每天rotate一个日志文件或者每当日志文件大小超过256M,rotate一个新的日志文件,并且最多保留7天之内的日志文件。
elasticsearch
通过修改log4j2.properties文件来解决。该文件在/etc/elasticsesarch目录下(或者config目录)。
默认配置是:
appender.rolling.type = RollingFile
appender.rolling.name = rolling
appender.rolling.fileName = ${sys:es.logs.base_path}${sys:file.separator}${sys:es.logs.cluster_name}.log
appender.rolling.layout.type = PatternLayout
appender.rolling.layout.pattern = [%d{ISO8601}][%-5p][%-25c{1.}] [%node_name]%marker %.-10000m%n
appender.rolling.filePattern = ${sys:es.logs.base_path}${sys:file.separator}${sys:es.logs.cluster_name}-%d{yyyy-MM-dd}-%i.log.gz
appender.rolling.policies.type = Policies
appender.rolling.policies.time.type = TimeBasedTriggeringPolicy
appender.rolling.policies.time.interval = 1
appender.rolling.policies.time.modulate = true
appender.rolling.policies.size.type = SizeBasedTriggeringPolicy
appender.rolling.policies.size.size = 256MB
appender.rolling.strategy.type = DefaultRolloverStrategy
appender.rolling.strategy.fileIndex = nomax
appender.rolling.strategy.action.type = Delete
appender.rolling.strategy.action.basepath = ${sys:es.logs.base_path}
appender.rolling.strategy.action.condition.type = IfFileName
appender.rolling.strategy.action.condition.glob = ${sys:es.logs.cluster_name}-*
appender.rolling.strategy.action.condition.nested_condition.type = IfAccumulatedFileSize
appender.rolling.strategy.action.condition.nested_condition.exceeds = 2GB 以上默认配置,会保存2GB的日志,只有累计的日志大小超过2GB的时候,才会删除旧的日志文件。 建议改为如下配置,仅保留最近7天的日志
appender.rolling.strategy.type = DefaultRolloverStrategy
appender.rolling.strategy.action.type = Delete
appender.rolling.strategy.action.basepath = ${sys:es.logs.base_path}
appender.rolling.strategy.action.condition.type = IfFileName
appender.rolling.strategy.action.condition.glob = ${sys:es.logs.cluster_name}-*
appender.rolling.strategy.action.condition.nested_condition.type = IfLastModified
appender.rolling.strategy.action.condition.nested_condition.age = 7D这里必须注意,log4j2会因为末尾的空格导致无法识别配置
logstash
与elasticsearch类似,通过修改log4j2.properties文件来解决。该文件在/etc/logstash目录下(或者config目录)。
默认配置是不会删除历史日志的:
status = error
name = LogstashPropertiesConfig
appender.console.type = Console
appender.console.name = plain_console
appender.console.layout.type = PatternLayout
appender.console.layout.pattern = [%d{ISO8601}][%-5p][%-25c] %m%n
appender.json_console.type = Console
appender.json_console.name = json_console
appender.json_console.layout.type = JSONLayout
appender.json_console.layout.compact = true
appender.json_console.layout.eventEol = true
appender.rolling.type = RollingFile
appender.rolling.name = plain_rolling
appender.rolling.fileName = ${sys:ls.logs}/logstash-${sys:ls.log.format}.log
appender.rolling.filePattern = ${sys:ls.logs}/logstash-${sys:ls.log.format}-%d{yyyy-MM-dd}.log
appender.rolling.policies.type = Policies
appender.rolling.policies.time.type = TimeBasedTriggeringPolicy
appender.rolling.policies.time.interval = 1
appender.rolling.policies.time.modulate = true
appender.rolling.layout.type = PatternLayout
appender.rolling.layout.pattern = [%d{ISO8601}][%-5p][%-25c] %-.10000m%n需手动加上:
appender.rolling.strategy.type = DefaultRolloverStrategy
appender.rolling.strategy.action.type = Delete
appender.rolling.strategy.action.basepath = ${sys:ls.logs}
appender.rolling.strategy.action.condition.type = IfFileName
appender.rolling.strategy.action.condition.glob = ${sys:ls.logs}/logstash-${sys:ls.log.format}
appender.rolling.strategy.action.condition.nested_condition.type = IfLastModified
appender.rolling.strategy.action.condition.nested_condition.age = 7Dkibana
在kibana的配置文件中,只有以下几个选项:
logging.dest:
Default: stdout Enables you specify a file where Kibana stores log output.
logging.quiet:
Default: false Set the value of this setting to true to suppress all logging output other than error messages.
logging.silent:
Default: false Set the value of this setting to true to suppress all logging output.
logging.verbose:
Default: false Set the value of this setting to true to log all events, including system usage information and all requests. Supported on Elastic Cloud Enterprise.
logging.timezone
Default: UTC Set to the canonical timezone id (e.g. US/Pacific) to log events using that timezone. A list of timezones can be referenced at https://en.wikipedia.org/wiki/List_of_tz_database_time_zones.我们可以指定输出的日志文件与日志内容,但是却不可以配置日志的rotate。这时,我们需要使用logrotate,这个linux默认安装的工具。 首先,我们要在配置文件里面指定生成pid文件:
pid.file: "pid.log"然后,修改/etc/logrotate.conf:
/var/log/kibana {
missingok
notifempty
sharedscripts
daily
rotate 7
copytruncate
/bin/kill -HUP $(cat /usr/share/kibana/pid.log 2>/dev/null) 2>/dev/null
endscript
}kafka
如果不想写脚本清理过多的文件的话,需要修改config/log4j.properties文件。使用RollingFileAppender代替DailyRollingFileAppender,同时设置MaxFileSize和MaxBackupIndex。即修改为:
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=[%d] %p %m (%c)%n
log4j.appender.kafkaAppender=org.apache.log4j.RollingFileAppender
log4j.appender.kafkaAppender.File=${kafka.logs.dir}/server.log
log4j.appender.kafkaAppender.MaxFileSize=10MB
log4j.appender.kafkaAppender.MaxBackupIndex=10
log4j.appender.kafkaAppender.layout=org.apache.log4j.PatternLayout
log4j.appender.kafkaAppender.layout.ConversionPattern=[%d] %p %m (%c)%n
log4j.appender.stateChangeAppender=org.apache.log4j.RollingFileAppender
log4j.appender.stateChangeAppender.File=${kafka.logs.dir}/state-change.log
log4j.appender.stateChangeAppender.MaxFileSize=10M
log4j.appender.stateChangeAppender.MaxBackupIndex=10
log4j.appender.stateChangeAppender.layout=org.apache.log4j.PatternLayout
log4j.appender.stateChangeAppender.layout.ConversionPattern=[%d] %p %m (%c)%n
log4j.appender.requestAppender=org.apache.log4j.RollingFileAppender
log4j.appender.requestAppender.File=${kafka.logs.dir}/kafka-request.log
log4j.appender.requestAppender.MaxFileSize=10MB
log4j.appender.requestAppender.MaxBackupIndex=10
log4j.appender.requestAppender.layout=org.apache.log4j.PatternLayout
log4j.appender.requestAppender.layout.ConversionPattern=[%d] %p %m (%c)%n
log4j.appender.cleanerAppender=org.apache.log4j.RollingFileAppender
log4j.appender.cleanerAppender.File=${kafka.logs.dir}/log-cleaner.log
log4j.appender.cleanerAppender.MaxFileSize=10MB
log4j.appender.cleanerAppender.MaxBackupIndex=10
log4j.appender.cleanerAppender.layout=org.apache.log4j.PatternLayout
log4j.appender.cleanerAppender.layout.ConversionPattern=[%d] %p %m (%c)%n
log4j.appender.controllerAppender=org.apache.log4j.RollingFileAppender
log4j.appender.controllerAppender.File=${kafka.logs.dir}/controller.log
log4j.appender.controllerAppender.MaxFileSize=10MB
log4j.appender.controllerAppender.MaxBackupIndex=10
log4j.appender.controllerAppender.layout=org.apache.log4j.PatternLayout
log4j.appender.controllerAppender.layout.ConversionPattern=[%d] %p %m (%c)%n
log4j.appender.authorizerAppender=org.apache.log4j.RollingFileAppender
log4j.appender.authorizerAppender.File=${kafka.logs.dir}/kafka-authorizer.log
log4j.appender.authorizerAppender.MaxFileSize=10MB
log4j.appender.authorizerAppender.MaxBackupIndex=10
log4j.appender.authorizerAppender.layout=org.apache.log4j.PatternLayout
log4j.appender.authorizerAppender.layout.ConversionPattern=[%d] %p %m (%c)%n
# Turn on all our debugging info
#log4j.logger.kafka.producer.async.DefaultEventHandler=DEBUG, kafkaAppender
#log4j.logger.kafka.client.ClientUtils=DEBUG, kafkaAppender
#log4j.logger.kafka.perf=DEBUG, kafkaAppender
#log4j.logger.kafka.perf.ProducerPerformance$ProducerThread=DEBUG, kafkaAppender
#log4j.logger.org.I0Itec.zkclient.ZkClient=DEBUG
log4j.logger.kafka=INFO, kafkaAppender
log4j.logger.kafka.network.RequestChannel$=WARN, requestAppender
log4j.additivity.kafka.network.RequestChannel$=false
#log4j.logger.kafka.network.Processor=TRACE, requestAppender
#log4j.logger.kafka.server.KafkaApis=TRACE, requestAppender
#log4j.additivity.kafka.server.KafkaApis=false
log4j.logger.kafka.request.logger=WARN, requestAppender
log4j.additivity.kafka.request.logger=false
log4j.logger.kafka.controller=TRACE, controllerAppender
log4j.additivity.kafka.controller=false
log4j.logger.kafka.log.LogCleaner=INFO, cleanerAppender
log4j.additivity.kafka.log.LogCleaner=false
log4j.logger.state.change.logger=TRACE, stateChangeAppender
log4j.additivity.state.change.logger=false
#Change this to debug to get the actual audit log for authorizer.
log4j.logger.kafka.authorizer.logger=WARN, authorizerAppender
log4j.additivity.kafka.authorizer.logger=falseKibana优化过程(Optimize)过长或无法结束的解决方案
使用过Kibana的同学应该都知道,当我们在kibana的配置文件中打开或者关闭功能,或者安装、卸载额外的插件后,重启kibana会触发一个优化的过程(optimize),如下图:

这个过程或长或短,视你电脑的性能而定。这里简单介绍一下该过程所要完成的事情。
Kibana是一个单页Web应用
首先,Kibana是一个单页的web应用。何为单页web应用?即所有的页面的读取都是在浏览器上完成,而与后台服务器无关。与后台服务器的通信只关乎数据,而非页面。所以,应用上所有的UI都被打包在一起,一次性的发送到了浏览器端,而不是通过URL到后台进行获取。所以,我们看到kibana的首页是下面这样的:
http://localhost:5601/app/kibana#/
注意这里的#后,代表#后面的内容会被浏览器提取,不往服务器端进行url的情况,而是在浏览器上进行内部重新渲染。因为所有的页面都是存储在浏览器的,所有在初次访问的时候,会加载大量的代码到浏览器端,这些代码都是被压缩过的bundle文件:

而optimize的过程,就是把这些原本可读性的源代码压缩为bundle.js的过程。因此,每当你对Kibana进行裁剪之后重启,因为前端的部分是完全由浏览器负责的,所有bundle文件需要重新生成后再发给浏览器,所以会触发optimize的过程。
Kibana在6.2.0版本之后,常规版本已经默认自带了xpack(当然,你还是可以直接下载不带xpack的开源社区版),导致Kibana的size已经到了200M左右,而且越往后的版本,功能越多,代码量越大,每次optimize的过程都会耗费更多的时间。一般来说,我们会将Kibana部署在单独的机器上,因为这仅仅是一个web后端,通常我们不会分配比较优质的资源,(2C4G都算浪费的了),这种情况下面,每次我们裁剪后重启Kibana都会耗费半个小时~1个小时的时间,更有甚者直接hang住,查看系统日志才知道OOM了。
Nodejs的内存机制
Kibana是用Nodejs编写的程序,在一般的后端语言中,基本的内存使用上基本没有什么限制,但是在nodeJs中却只能使用部分内存。在64位系统下位约为1.4G,在32位系统下约为0.7G,造成这个问题的主要原因是因为nodeJs基于V8构建,V8使用自己的方式来管理和分配内存,这一套管理方式在浏览器端使用绰绰有余,但是在nodeJs中这却限制了开发者,在应用中如果碰到了这个限制,就会造成进程退出。
Nodejs内存机制对Kibana优化的影响
因为Kibana的代码体量越来越大,将所有的代码加载到内存之后,再解析语法树,进行bundle的转换所耗费的内存已经接近1.4G的限制了,当你安装更多插件,比如sentinl的时候,系统往往已经无法为继,导致Kibana无法启动
解决方案
这种情况下,我们需要在Kibana启动的时候,指定NodeJs使用更多的内存。这个可以通过设置Node的环境变量办到。
NODE_OPTIONS="--max-old-space-size=4096"当然,我的建议是直接指定在kibana的启动脚本当中,修改/usr/share/kibana/bin/kibana文件为:
#!/bin/sh
SCRIPT=$0
# SCRIPT may be an arbitrarily deep series of symlinks. Loop until we have the concrete path.
while [ -h "$SCRIPT" ] ; do
ls=$(ls -ld "$SCRIPT")
# Drop everything prior to ->
link=$(expr "$ls" : '.*-> \(.*\)$')
if expr "$link" : '/.*' > /dev/null; then
SCRIPT="$link"
else
SCRIPT=$(dirname "$SCRIPT")/"$link"
fi
done
DIR="$(dirname "${SCRIPT}")/.."
NODE="${DIR}/node/bin/node"
test -x "$NODE" || NODE=$(which node)
if [ ! -x "$NODE" ]; then
echo "unable to find usable node.js executable."
exit 1
fi
NODE_ENV=production exec "${NODE}" $NODE_OPTIONS --max_old_space_size=3072 --no-warnings "${DIR}/src/cli" ${@}
改动在最后一句:NODE_ENV=production exec "${NODE}" $NODE_OPTIONS --max_old_space_size=3072 --no-warnings "${DIR}/src/cli" ${@}
这样,我们可以保证Kibana能顺利的完成optimize的过程
使用过Kibana的同学应该都知道,当我们在kibana的配置文件中打开或者关闭功能,或者安装、卸载额外的插件后,重启kibana会触发一个优化的过程(optimize),如下图:
这个过程或长或短,视你电脑的性能而定。这里简单介绍一下该过程所要完成的事情。
Kibana是一个单页Web应用
首先,Kibana是一个单页的web应用。何为单页web应用?即所有的页面的读取都是在浏览器上完成,而与后台服务器无关。与后台服务器的通信只关乎数据,而非页面。所以,应用上所有的UI都被打包在一起,一次性的发送到了浏览器端,而不是通过URL到后台进行获取。所以,我们看到kibana的首页是下面这样的:
http://localhost:5601/app/kibana#/
注意这里的#后,代表#后面的内容会被浏览器提取,不往服务器端进行url的情况,而是在浏览器上进行内部重新渲染。因为所有的页面都是存储在浏览器的,所有在初次访问的时候,会加载大量的代码到浏览器端,这些代码都是被压缩过的bundle文件:
而optimize的过程,就是把这些原本可读性的源代码压缩为bundle.js的过程。因此,每当你对Kibana进行裁剪之后重启,因为前端的部分是完全由浏览器负责的,所有bundle文件需要重新生成后再发给浏览器,所以会触发optimize的过程。
Kibana在6.2.0版本之后,常规版本已经默认自带了xpack(当然,你还是可以直接下载不带xpack的开源社区版),导致Kibana的size已经到了200M左右,而且越往后的版本,功能越多,代码量越大,每次optimize的过程都会耗费更多的时间。一般来说,我们会将Kibana部署在单独的机器上,因为这仅仅是一个web后端,通常我们不会分配比较优质的资源,(2C4G都算浪费的了),这种情况下面,每次我们裁剪后重启Kibana都会耗费半个小时~1个小时的时间,更有甚者直接hang住,查看系统日志才知道OOM了。
Nodejs的内存机制
Kibana是用Nodejs编写的程序,在一般的后端语言中,基本的内存使用上基本没有什么限制,但是在nodeJs中却只能使用部分内存。在64位系统下位约为1.4G,在32位系统下约为0.7G,造成这个问题的主要原因是因为nodeJs基于V8构建,V8使用自己的方式来管理和分配内存,这一套管理方式在浏览器端使用绰绰有余,但是在nodeJs中这却限制了开发者,在应用中如果碰到了这个限制,就会造成进程退出。
Nodejs内存机制对Kibana优化的影响
因为Kibana的代码体量越来越大,将所有的代码加载到内存之后,再解析语法树,进行bundle的转换所耗费的内存已经接近1.4G的限制了,当你安装更多插件,比如sentinl的时候,系统往往已经无法为继,导致Kibana无法启动
解决方案
这种情况下,我们需要在Kibana启动的时候,指定NodeJs使用更多的内存。这个可以通过设置Node的环境变量办到。
NODE_OPTIONS="--max-old-space-size=4096"当然,我的建议是直接指定在kibana的启动脚本当中,修改/usr/share/kibana/bin/kibana文件为:
#!/bin/sh
SCRIPT=$0
# SCRIPT may be an arbitrarily deep series of symlinks. Loop until we have the concrete path.
while [ -h "$SCRIPT" ] ; do
ls=$(ls -ld "$SCRIPT")
# Drop everything prior to ->
link=$(expr "$ls" : '.*-> \(.*\)$')
if expr "$link" : '/.*' > /dev/null; then
SCRIPT="$link"
else
SCRIPT=$(dirname "$SCRIPT")/"$link"
fi
done
DIR="$(dirname "${SCRIPT}")/.."
NODE="${DIR}/node/bin/node"
test -x "$NODE" || NODE=$(which node)
if [ ! -x "$NODE" ]; then
echo "unable to find usable node.js executable."
exit 1
fi
NODE_ENV=production exec "${NODE}" $NODE_OPTIONS --max_old_space_size=3072 --no-warnings "${DIR}/src/cli" ${@}
改动在最后一句:NODE_ENV=production exec "${NODE}" $NODE_OPTIONS --max_old_space_size=3072 --no-warnings "${DIR}/src/cli" ${@}
这样,我们可以保证Kibana能顺利的完成optimize的过程
收起阅读 »社区日报 第475期 (2018-12-11)
http://t.cn/EUwFsy6
2、Elasticsearch检索 — 聚合和LBS
http://t.cn/EU7qsRb
3、有赞订单管理的三生三世与 “十面埋伏”
http://t.cn/EU75ZTF
编辑:叮咚光军
归档:https://elasticsearch.cn/article/6187
订阅:https://tinyletter.com/elastic-daily
http://t.cn/EUwFsy6
2、Elasticsearch检索 — 聚合和LBS
http://t.cn/EU7qsRb
3、有赞订单管理的三生三世与 “十面埋伏”
http://t.cn/EU75ZTF
编辑:叮咚光军
归档:https://elasticsearch.cn/article/6187
订阅:https://tinyletter.com/elastic-daily 收起阅读 »
Day 11 -父子关系维护检索实战一 - Elasticsearch 5.x-父子关系维护
- 父子关系维护检索实战一 Elasticsearch 5.x 父子关系维护检索实战
- 父子关系维护检索实战二 Elasticsearch 6.x 父子关系维护检索实战
本文是其中第一篇- Elasticsearch 5.x 父子关系维护检索实战,涵盖以下部分内容:
- Elasticsearch 5.x 中父子关系mapping结构设计
- Elasticsearch 5.x 中维护父子关系数据
- Elasticsearch 5.x 中has_child和has_parent查询的基本用法
- Elasticsearch 5.x 中如何在检索中同时返回父子数据
案例说明
以一个体检记录相关的数据来介绍本文涉及的相关功能,体检数据包括客户基本信息basic和客户医疗记录medical、客户体检记录exam、客户体检结果分析记录diagnosis,它们之间的关系图如下:

我们采用Elasticsearch java客户端 bboss-elastic 来实现本文相关功能。
1.准备工作
参考文档《高性能elasticsearch ORM开发库使用介绍》导入和配置bboss客户端
2.定义mapping结构-Elasticsearch 5.x 中父子关系mapping结构设计
Elasticsearch 5.x中一个indice mapping支持多个mapping type,通过在子类型mapping中指定父类型的mapping type名字来设置父子关系,例如:
父类型
"basic": {
....
}
子类型:
"medical": {
"_parent": { "type": "basic" },
.................
}
新建dsl配置文件-esmapper/Client_Info.xml,定义完整的mapping结构:createClientIndice
<properties>
<!--
创建客户信息索引索引表
-->
<property name="createClientIndice">
<![CDATA[{
"settings": {
"number_of_shards": 6,
"index.refresh_interval": "5s"
},
"mappings": {
"basic": { ##基本信息
"properties": {
"party_id": {
"type": "keyword"
},
"sex": {
"type": "keyword"
},
"mari_sts": {
"type": "keyword"
},
"ethnic": {
"type": "text"
},
"prof": {
"type": "text"
},
"province": {
"type": "text"
},
"city": {
"type": "text"
},
"client_type": {
"type": "keyword"
},
"client_name": {
"type": "text"
},
"age": {
"type": "integer"
},
"id_type": {
"type": "keyword"
},
"idno": {
"type": "keyword"
},
"education": {
"type": "text"
},
"created_date": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd'T'HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss||epoch_millis"
},
"birth_date": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd'T'HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss||epoch_millis"
},
"last_modified_date": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd'T'HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss||epoch_millis"
},
"etl_date": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd'T'HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss||epoch_millis"
}
}
},
"diagnosis": { ##结果分析
"_parent": {
"type": "basic"
},
"properties": {
"party_id": {
"type": "keyword"
},
"provider": {
"type": "text"
},
"subject": {
"type": "text"
},
"diagnosis_type": {
"type": "text"
},
"icd10_code": {
"type": "text",
"type": "keyword"
},
"sd_disease_name": {
"type": "text",
"type": "keyword"
},
"created_date": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd'T'HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss||epoch_millis"
},
"last_modified_date": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd'T'HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss||epoch_millis"
},
"etl_date": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd'T'HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss||epoch_millis"
}
}
},
"medical": { ##医疗情况
"_parent": {
"type": "basic"
},
"properties": {
"party_id": {
"type": "keyword"
},
"hos_name_yb": {
"type": "text"
},
"eivisions_name": {
"type": "text"
},
"medical_type": {
"type": "text"
},
"medical_common_name": {
"type": "text"
},
"medical_sale_name": {
"type": "text"
},
"medical_code": {
"type": "text"
},
"specification": {
"type": "text"
},
"usage_num": {
"type": "text"
},
"unit": {
"type": "text"
},
"usage_times": {
"type": "text"
},
"created_date": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd'T'HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss||epoch_millis"
},
"last_modified_date": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd'T'HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss||epoch_millis"
},
"etl_date": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd'T'HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss||epoch_millis"
}
}
},
"exam": { ##检查结果
"_parent": {
"type": "basic"
},
"properties": {
"party_id": {
"type": "keyword"
},
"hospital": {
"type": "text"
},
"dept": {
"type": "text"
},
"is_ok": {
"type": "text"
},
"exam_result": {
"type": "text"
},
"fld1": {
"type": "text"
},
"fld2": {
"type": "text"
},
"fld3": {
"type": "text"
},
"fld4": {
"type": "text"
},
"fld5": {
"type": "text"
},
"fld901": {
"type": "text"
},
"fld6": {
"type": "text"
},
"fld902": {
"type": "text"
},
"fld14": {
"type": "text"
},
"fld20": {
"type": "text"
},
"fld21": {
"type": "text"
},
"fld23": {
"type": "text"
},
"fld24": {
"type": "text"
},
"fld65": {
"type": "text"
},
"fld66": {
"type": "text"
},
"fld67": {
"type": "text"
},
"fld68": {
"type": "text"
},
"created_date": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd'T'HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss||epoch_millis"
},
"last_modified_date": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd'T'HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss||epoch_millis"
},
"etl_date": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd'T'HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss||epoch_millis"
}
}
}
}
}]]>
</property>
</properties>这个mapping中定义了4个索引类型:basic,exam,medical,diagnosis,其中basic是其他类型的父类型。
通过bboss客户端创建名称为client_info 的索引:
public void createClientIndice(){
//定义客户端实例,加载上面建立的dsl配置文件
ClientInterface clientUtil = ElasticSearchHelper.getConfigRestClientUtil("esmapper/Client_Info.xml");
try {
//client_info存在返回true,不存在返回false
boolean exist = clientUtil.existIndice("client_info");
//如果索引表client_info已经存在先删除mapping
if(exist) {//先删除mapping client_info
clientUtil.dropIndice("client_info");
}
} catch (ElasticSearchException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
//创建mapping client_info
clientUtil.createIndiceMapping("client_info","createClientIndice");
String client_info = clientUtil.getIndice("client_info");//获取最新建立的索引表结构client_info
System.out.println("after createClientIndice clientUtil.getIndice(\"client_info\") response:"+client_info);
}3.维护父子关系数据-Elasticsearch 5.x 中维护父子关系数据
- 定义对象
首先定义四个对象,分别对应mapping中的四个索引类型,篇幅关系只列出主要属性
- Basic
- Medical
- Exam
- Diagnosis
通过注解@ESId指定基本信息文档_id
public class Basic extends ESBaseData {
/**
* 索引_id
*/
@ESId
private String party_id;
private String sex; // 性别
......
}
通过注解@ESParentId指定Medical关联的基本信息文档_id,Medical文档_id由ElasticSearch自动生成
public class Medical extends ESBaseData {
@ESParentId
private String party_id; //父id
private String hos_name_yb; //就诊医院
...
}
通过注解@ESParentId指定Exam关联的基本信息文档_id,Exam文档_id由ElasticSearch自动生成
public class Exam extends ESBaseData {
@ESParentId
private String party_id; //父id
private String hospital; // 就诊医院
....
}
通过注解@ESParentId指定Diagnosis关联的基本信息文档_id,Diagnosis文档_id由ElasticSearch自动生成
public class Diagnosis extends ESBaseData {
@ESParentId
private String party_id; //父id
private String provider; //诊断医院
private String subject; //科室
......
} - 通过api维护测试数据
对象定义好了后,通过bboss客户数据到之前建立好的索引client_info中。
/**
* 录入体检医疗信息
*/
public void importClientInfoDataFromBeans() {
ClientInterface clientUtil = ElasticSearchHelper.getRestClientUtil();
//导入基本信息,并且实时刷新,测试需要,实际环境不要带refresh
List<Basic> basics = buildBasics();
clientUtil.addDocuments("client_info","basic",basics,"refresh");
//导入医疗信息,并且实时刷新,测试需要,实际环境不要带refresh
List<Medical> medicals = buildMedicals();
clientUtil.addDocuments("client_info","medical",medicals,"refresh");
//导入体检结果数据,并且实时刷新,测试需要,实际环境不要带refresh
List<Exam> exams = buildExams();
clientUtil.addDocuments("client_info","exam",exams,"refresh");
//导入结果诊断数据,并且实时刷新,测试需要,实际环境不要带refresh
List<Diagnosis> diagnosiss = buildDiagnosiss();
clientUtil.addDocuments("client_info","diagnosis",diagnosiss,"refresh");
}
//构建基本信息集合
private List<Basic> buildBasics() {
List<Basic> basics = new ArrayList<Basic>();
Basic basic = new Basic();
basic.setParty_id("1");
basic.setAge(60);
basics.add(basic);
//继续添加其他数据
return basics;
}
//
构建医疗信息集合
private List<Medical> buildMedicals() {
List<Medical> medicals = new ArrayList<Medical>();
Medical medical = new Medical();
medical.setParty_id("1");//设置父文档id-基本信息文档_id
medical.setCreated_date(new Date());
medicals.add(medical);
//继续添加其他数据
return medicals;
}
//构建体检结果数据集合
private List<Exam> buildExams() {
List<Exam> exams = new ArrayList<Exam>();
Exam exam = new Exam();
exam.setParty_id("1");//设置父文档id-基本信息文档_id
exams.add(exam);
//继续添加其他数据
return exams;
}
//构建结果诊断数据集合
private List<Diagnosis> buildDiagnosiss() {
List<Diagnosis> diagnosiss = new ArrayList<Diagnosis>();
Diagnosis diagnosis = new Diagnosis();
diagnosis.setParty_id("1");//设置父文档id-基本信息文档_id
diagnosiss.add(diagnosis);
//继续添加其他数据
return diagnosiss;
}- 通过json报文批量导入测试数据
除了通过addDocuments录入数据,还可以通过json报文批量导入数据
在配置文件esmapper/Client_Info.xml增加以下内容:
<!--
导入基本信息:
-->
<property name="bulkImportBasicData" trim="false">
<![CDATA[
{ "index": { "_id": "1" }}
{ "party_id":"1", "sex":"男", "mari_sts":"不详", "ethnic":"蒙古族", "prof":"放牧","birth_date":"1966-2-14 00:00:00", "province":"内蒙古", "city":"赤峰市","client_type":"1", "client_name":"安", "age":52,"id_type":"1", "idno":"1", "education":"初中","created_date":"2013-04-24 00:00:00","last_modified_date":"2013-04-24 00:00:00", "etl_date":"2013-04-24 00:00:00"}
{ "index": { "_id": "2" }}
{ "party_id":"2", "sex":"女", "mari_sts":"已婚", "ethnic":"汉族", "prof":"公务员","birth_date":"1986-07-06 00:00:00", "province":"广东", "city":"深圳","client_type":"1", "client_name":"彭", "age":32,"id_type":"1", "idno":"2", "education":"本科", "created_date":"2013-05-09 15:49:47","last_modified_date":"2013-05-09 15:49:47", "etl_date":"2013-05-09 15:49:47"}
{ "index": { "_id": "3" }}
{ "party_id":"3", "sex":"男", "mari_sts":"未婚", "ethnic":"汉族", "prof":"无业","birth_date":"2000-08-15 00:00:00", "province":"广东", "city":"佛山","client_type":"1", "client_name":"浩", "age":18,"id_type":"1", "idno":"3", "education":"高中", "created_date":"2014-09-01 09:49:27","last_modified_date":"2014-09-01 09:49:27", "etl_date":"2014-09-01 09:49:27" }
{ "index": { "_id": "4" }}
{ "party_id":"4", "sex":"女", "mari_sts":"未婚", "ethnic":"满族", "prof":"工人","birth_date":"1996-03-14 00:00:00", "province":"江苏", "city":"扬州","client_type":"1", "client_name":"慧", "age":22,"id_type":"1", "idno":"4", "education":"高中", "created_date":"2014-09-16 09:30:37","last_modified_date":"2014-09-16 09:30:37", "etl_date":"2014-09-16 09:30:37" }
{ "index": { "_id": "5" }}
{ "party_id":"5", "sex":"女", "mari_sts":"已婚", "ethnic":"汉族", "prof":"教师","birth_date":"1983-08-14 00:00:00", "province":"宁夏", "city":"灵武","client_type":"1", "client_name":"英", "age":35,"id_type":"1", "idno":"5", "education":"本科", "created_date":"2015-09-16 09:30:37","last_modified_date":"2015-09-16 09:30:37", "etl_date":"2015-09-16 09:30:37" }
{ "index": { "_id": "6" }}
{ "party_id":"6", "sex":"女", "mari_sts":"已婚", "ethnic":"汉族", "prof":"工人","birth_date":"1959-07-04 00:00:00", "province":"山东", "city":"青岛","client_type":"1", "client_name":"岭", "age":59,"id_type":"1", "idno":"6", "education":"小学", "created_date":"2015-09-01 09:49:27","last_modified_date":"2015-09-01 09:49:27", "etl_date":"2015-09-01 09:49:27" }
{ "index": { "_id": "7" }}
{ "party_id":"7", "sex":"女", "mari_sts":"未婚", "ethnic":"汉族", "prof":"学生","birth_date":"1999-02-18 00:00:00", "province":"山东", "city":"青岛","client_type":"1", "client_name":"欣", "age":19,"id_type":"1", "idno":"7", "education":"高中", "created_date":"2016-12-01 09:49:27","last_modified_date":"2016-12-01 09:49:27", "etl_date":"2016-12-01 09:49:27" }
{ "index": { "_id": "8" }}
{ "party_id":"8", "sex":"女", "mari_sts":"未婚", "ethnic":"汉族", "prof":"学生","birth_date":"2007-11-18 00:00:00", "province":"山东", "city":"青岛","client_type":"1", "client_name":"梅", "age":10,"id_type":"1", "idno":"8", "education":"小学", "created_date":"2016-11-21 09:49:27","last_modified_date":"2016-11-21 09:49:27", "etl_date":"2016-11-21 09:49:27" }
{ "index": { "_id": "9" }}
{ "party_id":"9", "sex":"男", "mari_sts":"不详", "ethnic":"回族", "prof":"个体户","birth_date":"1978-03-29 00:00:00", "province":"北京", "city":"北京","client_type":"1", "client_name":"磊", "age":40,"id_type":"1", "idno":"9", "education":"高中", "created_date":"2017-09-01 09:49:27","last_modified_date":"2017-09-01 09:49:27", "etl_date":"2017-09-01 09:49:27" }
{ "index": { "_id": "10" }}
{ "party_id":"10", "sex":"男", "mari_sts":"已婚", "ethnic":"汉族", "prof":"农民","birth_date":"1970-11-14 00:00:00", "province":"浙江", "city":"台州","client_type":"1", "client_name":"强", "age":47,"id_type":"1", "idno":"10", "education":"初中", "created_date":"2018-09-01 09:49:27","last_modified_date":"2018-09-01 09:49:27", "etl_date":"2018-09-01 09:49:27" }
]]>
</property>
<!--
导入诊断信息
-->
<property name="bulkImportDiagnosisData" trim="false">
<![CDATA[
{ "index": { "parent": "1" }}
{ "party_id":"1", "provider":"内蒙古医院", "subject":"","diagnosis_type":"","icd10_code":"J31.0", "sd_disease_name":"鼻炎","created_date":"2013-07-23 20:56:44", "last_modified_date":"2013-07-23 20:56:44", "etl_date":"2013-07-23 20:56:44" }
{ "index": { "parent": "1" }}
{ "party_id":"1", "provider":"内蒙古医院", "subject":"","diagnosis_type":"","icd10_code":"M47.8", "sd_disease_name":"颈椎病","created_date":"2013-09-23 20:56:44", "last_modified_date":"2013-09-23 20:56:44", "etl_date":"2013-09-23 20:56:44" }
{ "index": { "parent": "1" }}
{ "party_id":"1", "provider":"内蒙古医院", "subject":"","diagnosis_type":"","icd10_code":"E78.1", "sd_disease_name":"甘油三脂增高","created_date":"2018-09-20 09:27:44", "last_modified_date":"2018-09-20 09:27:44", "etl_date":"2018-09-20 09:27:44" }
{ "index": { "parent": "4" }}
{ "party_id":"4", "provider":"江苏医院", "subject":"","diagnosis_type":"","icd10_code":"J00", "sd_disease_name":"感冒","created_date":"2011-05-19 15:52:55", "last_modified_date":"2011-05-19 15:52:55", "etl_date":"2011-05-19 15:52:55" }
{ "index": { "parent": "6" }}
{ "party_id":"6", "provider":"山东医院", "subject":"","diagnosis_type":"","icd10_code":"H44", "sd_disease_name":"眼疾","created_date":"2016-04-08 10:42:18", "last_modified_date":"2016-04-08 10:42:18", "etl_date":"2016-04-08 10:42:18" }
{ "index": { "parent": "6" }}
{ "party_id":"6", "provider":"山东医院", "subject":"","diagnosis_type":"","icd10_code":"M47.8", "sd_disease_name":"颈椎病","created_date":"2016-04-08 10:42:18", "last_modified_date":"2016-04-08 10:42:18", "etl_date":"2016-04-08 10:42:18" }
{ "index": { "parent": "7" }}
{ "party_id":"7", "provider":"山东医院", "subject":"","diagnosis_type":"","icd10_code":"J00", "sd_disease_name":"感冒","created_date":"2017-04-08 10:42:18", "last_modified_date":"2017-04-08 10:42:18", "etl_date":"2017-04-08 10:42:18" }
{ "index": { "parent": "8" }}
{ "party_id":"8", "provider":"山东医院", "subject":"","diagnosis_type":"","icd10_code":"J00", "sd_disease_name":"感冒","created_date":"2018-04-08 10:42:18", "last_modified_date":"2018-04-08 10:42:18", "etl_date":"2018-04-08 10:42:18" }
{ "index": { "parent": "9" }}
{ "party_id":"9", "provider":"朝阳医院", "subject":"","diagnosis_type":"","icd10_code":"A03.901", "sd_disease_name":"急性细菌性痢疾","created_date":"2015-06-08 10:42:18", "last_modified_date":"2015-06-08 10:42:18", "etl_date":"2015-06-08 10:42:18" }
]]>
</property>
<!--
导入医疗信息
-->
<property name="bulkImportMedicalData" trim="false">
<![CDATA[
{ "index": { "parent": "1" }}
{ "party_id":"1", "hos_name_yb":"内蒙古医院", "eivisions_name":"", "medical_type":"","medical_common_name":"氟化钠", "medical_sale_name":"", "medical_code":"A01AA01", "specification":"","usage_num":"", "unit":"", "usage_times":"","created_date":"2014-03-18 00:00:00", "last_modified_date":"2014-03-18 00:00:00", "etl_date":"2014-03-18 00:00:00" }
{ "index": { "parent": "1" }}
{ "party_id":"1", "hos_name_yb":"内蒙古医院", "eivisions_name":"", "medical_type":"","medical_common_name":"四环素", "medical_sale_name":"", "medical_code":"A01AB13", "specification":"","usage_num":"", "unit":"", "usage_times":"","created_date":"2016-05-31 00:00:00", "last_modified_date":"2016-05-31 00:00:00", "etl_date":"2016-05-31 00:00:00" }
{ "index": { "parent": "1" }}
{ "party_id":"1", "hos_name_yb":"内蒙古医院", "eivisions_name":"", "medical_type":"","medical_common_name":"", "medical_sale_name":"盐酸多西环素胶丸", "medical_code":"A01AB22", "specification":"","usage_num":"", "unit":"", "usage_times":"","created_date":"2016-03-18 00:00:00", "last_modified_date":"2016-03-18 00:00:00", "etl_date":"2016-03-18 00:00:00" }
{ "index": { "parent": "1" }}
{ "party_id":"1", "hos_name_yb":"内蒙古医院", "eivisions_name":"", "medical_type":"","medical_common_name":"盐酸多西环素分散片", "medical_sale_name":"", "medical_code":"A01AB22", "specification":"","usage_num":"", "unit":"", "usage_times":"","created_date":"2013-07-23 20:56:44", "last_modified_date":"2013-07-23 20:56:44", "etl_date":"2013-07-23 20:56:44" }
{ "index": { "parent": "1" }}
{ "party_id":"1", "hos_name_yb":"内蒙古医院", "eivisions_name":"", "medical_type":"","medical_common_name":"地塞米松", "medical_sale_name":"", "medical_code":"A01AC02", "specification":"","usage_num":"", "unit":"", "usage_times":"","created_date":"2013-09-23 20:56:44", "last_modified_date":"2013-09-23 20:56:44", "etl_date":"2013-09-23 20:56:44" }
{ "index": { "parent": "1" }}
{ "party_id":"1", "hos_name_yb":"内蒙古医院", "eivisions_name":"", "medical_type":"","medical_common_name":"肾上腺素", "medical_sale_name":"", "medical_code":"A01AD01", "specification":"","usage_num":"", "unit":"", "usage_times":"","created_date":"2018-09-20 09:27:44", "last_modified_date":"2018-09-20 09:27:44", "etl_date":"2018-09-20 09:27:44" }
{ "index": { "parent": "4" }}
{ "party_id":"4", "hos_name_yb":"江苏医院", "eivisions_name":"", "medical_type":"","medical_common_name":"地塞米松", "medical_sale_name":"", "medical_code":"A01AC02", "specification":"","usage_num":"", "unit":"", "usage_times":"","created_date":"2011-05-19 15:52:55", "last_modified_date":"2011-05-19 15:52:55", "etl_date":"2011-05-19 15:52:55" }
{ "index": { "parent": "4" }}
{ "party_id":"4", "hos_name_yb":"江苏医院", "eivisions_name":"", "medical_type":"","medical_common_name":"四环素", "medical_sale_name":"", "medical_code":"A01AB13", "specification":"","usage_num":"", "unit":"", "usage_times":"","created_date":"2018-04-08 10:42:18", "last_modified_date":"2018-04-08 10:42:18", "etl_date":"2018-04-08 10:42:18" }
{ "index": { "parent": "4" }}
{ "party_id":"4", "hos_name_yb":"江苏医院", "eivisions_name":"", "medical_type":"","medical_common_name":"诺氟沙星胶囊", "medical_sale_name":"", "medical_code":"A01AD01", "specification":"","usage_num":"", "unit":"", "usage_times":"","created_date":"2015-06-08 10:42:18", "last_modified_date":"2015-06-08 10:42:18", "etl_date":"2015-06-08 10:42:18" }
{ "index": { "parent": "6" }}
{ "party_id":"6", "hos_name_yb":"山东医院", "eivisions_name":"", "medical_type":"","medical_common_name":"盐酸异丙肾上腺素片", "medical_sale_name":"", "medical_code":"A01AD01", "specification":"","usage_num":"", "unit":"", "usage_times":"","created_date":"2014-01-23 20:56:44", "last_modified_date":"2014-01-23 20:56:44", "etl_date":"2014-01-23 20:56:44" }
{ "index": { "parent": "6" }}
{ "party_id":"6", "hos_name_yb":"山东医院", "eivisions_name":"", "medical_type":"","medical_common_name":"甲硝唑栓", "medical_sale_name":"", "medical_code":"A01AB17", "specification":"","usage_num":"", "unit":"", "usage_times":"","created_date":"2018-06-08 10:42:18", "last_modified_date":"2018-06-08 10:42:18", "etl_date":"2018-06-08 10:42:18" }
{ "index": { "parent": "9" }}
{ "party_id":"9", "hos_name_yb":"朝阳医院", "eivisions_name":"", "medical_type":"","medical_common_name":"复方克霉唑乳膏", "medical_sale_name":"", "medical_code":"A01AB18", "specification":"","usage_num":"", "unit":"", "usage_times":"","created_date":"2014-01-23 20:56:44", "last_modified_date":"2014-01-23 20:56:44", "etl_date":"2014-01-23 20:56:44"}
]]>
</property>
<!--
导入体检信息
-->
<property name="bulkImportExamData" trim="false">
<![CDATA[
{ "index": { "parent": "1" }}
{ "party_id":"1", "hospital":"", "dept":"", "is_ok":"N", "exam_result":"高血压","fld1":"158", "fld2":"63", "fld3":"94", "fld4":"85", "fld5":"131", "fld901":"89", "fld6":"4.9","fld902":"4.8","fld14":"78", "fld21":"78", "fld23":"", "fld24":"5.5", "fld65":"5.5", "fld66":"1.025","fld67":"", "fld68":"","created_date":"2014-03-18 00:00:00", "last_modified_date":"2014-03-18 00:00:00", "etl_date":"2014-03-18 00:00:00" }
{ "index": { "parent": "2" }}
{ "party_id":"2", "hospital":"", "dept":"", "is_ok":"Y", "exam_result":"轻度脂肪肝","fld1":"158", "fld2":"63", "fld3":"94", "fld4":"85", "fld5":"131", "fld901":"89", "fld6":"4.9","fld902":"4.8","fld14":"78", "fld21":"78", "fld23":"", "fld24":"5.5", "fld65":"5.5", "fld66":"1.025","fld67":"", "fld68":"","created_date":"2014-03-18 00:00:00", "last_modified_date":"2014-03-18 00:00:00", "etl_date":"2014-03-18 00:00:00" }
{ "index": { "parent": "3" }}
{ "party_id":"3", "hospital":"", "dept":"", "is_ok":"N", "exam_result":"急性细菌性痢疾","fld1":"158", "fld2":"63", "fld3":"94", "fld4":"85", "fld5":"131", "fld901":"89", "fld6":"4.9","fld902":"4.8","fld14":"78", "fld21":"78", "fld23":"", "fld24":"5.5", "fld65":"5.5", "fld66":"1.025","fld67":"", "fld68":"","created_date":"2014-03-18 00:00:00", "last_modified_date":"2014-03-18 00:00:00", "etl_date":"2014-03-18 00:00:00" }
{ "index": { "parent": "4" }}
{ "party_id":"4", "hospital":"", "dept":"", "is_ok":"N", "exam_result":"感冒","fld1":"158", "fld2":"63", "fld3":"94", "fld4":"85", "fld5":"131", "fld901":"89", "fld6":"4.9","fld902":"4.8","fld14":"78", "fld21":"78", "fld23":"", "fld24":"5.5", "fld65":"5.5", "fld66":"1.025","fld67":"", "fld68":"","created_date":"2014-03-18 00:00:00", "last_modified_date":"2014-03-18 00:00:00", "etl_date":"2014-03-18 00:00:00" }
{ "index": { "parent": "5" }}
{ "party_id":"5", "hospital":"", "dept":"", "is_ok":"N", "exam_result":"感冒","fld1":"158", "fld2":"63", "fld3":"94", "fld4":"85", "fld5":"131", "fld901":"89", "fld6":"4.9","fld902":"4.8","fld14":"78", "fld21":"78", "fld23":"", "fld24":"5.5", "fld65":"5.5", "fld66":"1.025","fld67":"", "fld68":"","created_date":"2014-03-18 00:00:00", "last_modified_date":"2014-03-18 00:00:00", "etl_date":"2014-03-18 00:00:00" }
{ "index": { "parent": "6" }}
{ "party_id":"6", "hospital":"", "dept":"", "is_ok":"N", "exam_result":"感冒","fld1":"158", "fld2":"63", "fld3":"94", "fld4":"85", "fld5":"131", "fld901":"89", "fld6":"4.9","fld902":"4.8","fld14":"78", "fld21":"78", "fld23":"", "fld24":"5.5", "fld65":"5.5", "fld66":"1.025","fld67":"", "fld68":"","created_date":"2014-03-18 00:00:00", "last_modified_date":"2014-03-18 00:00:00", "etl_date":"2014-03-18 00:00:00" }
{ "index": { "parent": "7" }}
{ "party_id":"7", "hospital":"", "dept":"", "is_ok":"N", "exam_result":"颈椎病","fld1":"158", "fld2":"63", "fld3":"94", "fld4":"85", "fld5":"131", "fld901":"89", "fld6":"4.9","fld902":"4.8","fld14":"78", "fld21":"78", "fld23":"", "fld24":"5.5", "fld65":"5.5", "fld66":"1.025","fld67":"", "fld68":"","created_date":"2014-03-18 00:00:00", "last_modified_date":"2014-03-18 00:00:00", "etl_date":"2014-03-18 00:00:00" }
{ "index": { "parent": "8" }}
{ "party_id":"1", "hospital":"", "dept":"", "is_ok":"N", "exam_result":"颈椎病","fld1":"158", "fld2":"63", "fld3":"94", "fld4":"85", "fld5":"131", "fld901":"89", "fld6":"4.9","fld902":"4.8","fld14":"78", "fld21":"78", "fld23":"", "fld24":"5.5", "fld65":"5.5", "fld66":"1.025","fld67":"", "fld68":"","created_date":"2014-03-18 00:00:00", "last_modified_date":"2014-03-18 00:00:00", "etl_date":"2014-03-18 00:00:00" }
{ "index": { "parent": "9" }}
{ "party_id":"9", "hospital":"", "dept":"", "is_ok":"N", "exam_result":"颈椎病","fld1":"158", "fld2":"63", "fld3":"94", "fld4":"85", "fld5":"131", "fld901":"89", "fld6":"4.9","fld902":"4.8","fld14":"78", "fld21":"78", "fld23":"", "fld24":"5.5", "fld65":"5.5", "fld66":"1.025","fld67":"", "fld68":"","created_date":"2014-03-18 00:00:00", "last_modified_date":"2014-03-18 00:00:00", "etl_date":"2014-03-18 00:00:00" }
{ "index": { "parent": "10" }}
{ "party_id":"10", "hospital":"", "dept":"", "is_ok":"N", "exam_result":"颈椎病","fld1":"158", "fld2":"63", "fld3":"94", "fld4":"85", "fld5":"131", "fld901":"89", "fld6":"4.9","fld902":"4.8","fld14":"78", "fld21":"78", "fld23":"", "fld24":"5.5", "fld65":"5.5", "fld66":"1.025","fld67":"", "fld68":"","created_date":"2014-03-18 00:00:00", "last_modified_date":"2014-03-18 00:00:00", "etl_date":"2014-03-18 00:00:00" }
]]>
</property>
/**
* 通过读取配置文件中的dsl json数据导入医疗数据
*/
public void importClientInfoFromJsonData(){
ClientInterface clientUtil = ElasticSearchHelper.getConfigRestClientUtil("esmapper/Client_Info.xml");
clientUtil.executeHttp("client_info/basic/_bulk?refresh","bulkImportBasicData",ClientUtil.HTTP_POST);
clientUtil.executeHttp("client_info/diagnosis/_bulk?refresh","bulkImportDiagnosisData",ClientUtil.HTTP_POST);
clientUtil.executeHttp("client_info/medical/_bulk?refresh","bulkImportMedicalData",ClientUtil.HTTP_POST);
clientUtil.executeHttp("client_info/exam/_bulk?refresh","bulkImportExamData",ClientUtil.HTTP_POST);
long basiccount = clientUtil.countAll("client_info/basic");
System.out.println(basiccount);
long medicalcount = clientUtil.countAll("client_info/medical");
System.out.println(medicalcount);
long examcount = clientUtil.countAll("client_info/exam");
System.out.println(examcount);
long diagnosiscount = clientUtil.countAll("client_info/diagnosis");
System.out.println(diagnosiscount);
}- 根据父查子-通过客户名称信息查询客户端体检结果
在配置文件esmapper/Client_Info.xml增加dsl语句:queryExamSearchByClientName
<!--根据客户名称查询客户体检报告-->
<property name="queryExamSearchByClientName">
<![CDATA[
{
"query": {
## 最多返回size变量对应的记录条数
"size":#[size],
"has_parent": {
"type": "basic",
"query": {
"match": {
"client_name": #[clientName] ## 通过变量clientName设置客户名称
}
}
}
}
}
]]>
</property>执行查询,通过bboss的searchList 方法获取符合条件的体检报告以及总记录数据,返回size对应的1000条数据
/**
* 根据客户名称查询客户体检报告
*/
public void queryExamSearchByClientName(){
ClientInterface clientUtil = ElasticSearchHelper.getConfigRestClientUtil("esmapper/Client_info.xml");
Map<String,Object> params = new HashMap<String,Object>();
params.put("clientName","张三");
params.put("size",1000);
ESDatas<Exam> exams = clientUtil.searchList("client_info/exam/_search","queryExamSearchByClientName",params,Exam.class);
List<Exam> examList = exams.getDatas();//获取符合条件的体检数据
long totalSize = exams.getTotalSize();//符合条件的总记录数据
}- 根据子查父数据-通过医疗信息编码查找客户基本数据
在配置文件esmapper/Client_Info.xml增加查询dsl语句:queryClientInfoByMedicalName
<!--通过医疗信息编码查找客户基本数据-->
<property name="queryClientInfoByMedicalName">
<![CDATA[
{
"query": {
## 最多返回size变量对应的记录条数
"size":#[size],
"has_child": {
"type": "medical",
"score_mode": "max",
"query": {
"match": {
"medical_code": #[medicalCode] ## 通过变量medicalCode设置医疗编码
}
}
}
}
}
]]>
</property> /**
* 通过医疗信息编码查找客户基本数据
*/
public void queryClientInfoByMedicalName(){
ClientInterface clientUtil = ElasticSearchHelper.getConfigRestClientUtil("esmapper/Client_info.xml");
Map<String,Object> params = new HashMap<String,Object>();
params.put("medicalCode","A01AA01"); //通过变量medicalCode设置医疗编码
params.put("size",1000); //最多返回size变量对应的记录条数
ESDatas<Basic> bascis = clientUtil.searchList("client_info/basic/_search","queryClientInfoByMedicalName",params,Basic.class);
List<Basic> bascisList = bascis.getDatas();//获取符合条件的客户信息
long totalSize = bascis.getTotalSize();
}这一节中我们介绍同时返回父子数据的玩法 :inner_hits的妙用
- 根据父条件查询所有子数据集合并返回父数据,根据客户名称查询所有体检数据,同时返回客户信息
在配置文件esmapper/Client_Info.xml增加检索dsl-queryDiagnosisByClientName
<!--根据客户名称获取客户体检诊断数据,并返回客户信息-->
<property name="queryDiagnosisByClientName">
<![CDATA[
{
"query": {
## 最多返回size变量对应的记录条数
"size":#[size],
"has_parent": {
"type": "basic",
"query": {
"match": {
"client_name": #[clientName] ## 通过变量clientName设置客户名称
}
},
"inner_hits": {} ## 通过变量inner_hits表示要返回对应的客户信息
}
}
}
]]>
</property> /**
* 根据客户名称获取客户体检诊断数据,并返回客户数据
*/
public void queryDiagnosisByClientName(){
ClientInterface clientUtil = ElasticSearchHelper.getConfigRestClientUtil("esmapper/Client_info.xml");
Map<String,Object> params = new HashMap<String,Object>();
params.put("clientName","张三");
params.put("size",1000);
try {
ESInnerHitSerialThreadLocal.setESInnerTypeReferences(Basic.class);//指定inner查询结果对应的客户基本信息类型,Basic只有一个文档类型,索引不需要显示指定basic对应的mapping type名称
ESDatas<Diagnosis> diagnosiss = clientUtil.searchList("client_info/diagnosis/_search",
"queryDiagnosisByClientName",params,Diagnosis.class);
List<Diagnosis> diagnosisList = diagnosiss.getDatas();//获取符合条件的体检报告数据
long totalSize = diagnosiss.getTotalSize();
//遍历诊断报告信息,并查看报告对应的客户基本信息
for(int i = 0; diagnosisList != null && i < diagnosisList.size(); i ++) {
Diagnosis diagnosis = diagnosisList.get(i);
List<Basic> basics = ResultUtil.getInnerHits(diagnosis.getInnerHits(), "basic");
if(basics != null) {
System.out.println(basics.size());
}
}
}
finally{
ESInnerHitSerialThreadLocal.clean();//清空inner查询结果对应的客户基本信息类型
}
}- 根据子条件查询父数据并返回符合条件的父的子数据集合,查询客户信息,同时返回客户对应的所有体检报告、医疗记录、诊断记录
在配置文件esmapper/Client_Info.xml增加检索dsl-queryClientAndAllSons
<!--查询客户信息,同时返回客户对应的所有体检报告、医疗记录、诊断记录-->
<property name="queryClientAndAllSons">
<![CDATA[
{
"query": {
"bool": {
"should": [
{
"match_all":{}
}
]
,"must": [
{
"has_child": {
"score_mode": "none",
"type": "diagnosis"
,"query": {
"bool": {
"must": [
{
"term": {
"icd10_code": {
"value": "J00"
}
}
}
]
}
},"inner_hits":{}
}
}
]
,"should": [
{
"has_child": {
"score_mode": "none",
"type": "medical"
,"query": {
"match_all": {}
},"inner_hits":{}
}
}
]
,"should": [
{
"has_child": {
"type": "exam",
"query": {
"match_all": {}
},"inner_hits":{}
}
}
]
}
}
}
]]>
</property> /**
* 查询客户信息,同时返回客户对应的所有体检报告、医疗记录、诊断记录
*/
public void queryClientAndAllSons(){
ClientInterface clientUtil = ElasticSearchHelper.getConfigRestClientUtil("esmapper/Client_Info.xml");
Map<String,Object> params = null;//没有检索条件,构造一个空的参数对象
try {
//设置子文档的类型和对象映射关系
ESInnerHitSerialThreadLocal.setESInnerTypeReferences("exam",Exam.class);//指定inner查询结果对于exam类型和对应的对象类型Exam
ESInnerHitSerialThreadLocal.setESInnerTypeReferences("diagnosis",Diagnosis.class);//指定inner查询结果对于diagnosis类型和对应的对象类型Diagnosis
ESInnerHitSerialThreadLocal.setESInnerTypeReferences("medical",Medical.class);//指定inner查询结果对于medical类型和对应的对象类型Medical
ESDatas<Basic> escompanys = clientUtil.searchList("client_info/basic/_search",
"queryClientAndAllSons",params,Basic.class);
//String response = clientUtil.executeRequest("client_info/basic/_search","queryClientAndAllSons",params);直接获取原始的json报文
// escompanys = clientUtil.searchAll("client_info",Basic.class);
long totalSize = escompanys.getTotalSize();
List<Basic> clientInfos = escompanys.getDatas();//获取符合条件的数据
//查看公司下面的雇员信息(符合检索条件的雇员信息)
for (int i = 0; clientInfos != null && i < clientInfos.size(); i++) {
Basic clientInfo = clientInfos.get(i);
List<Exam> exams = ResultUtil.getInnerHits(clientInfo.getInnerHits(), "exam");
if(exams != null)
System.out.println(exams.size());
List<Diagnosis> diagnosiss = ResultUtil.getInnerHits(clientInfo.getInnerHits(), "diagnosis");
if(diagnosiss != null)
System.out.println(diagnosiss.size());
List<Medical> medicals = ResultUtil.getInnerHits(clientInfo.getInnerHits(), "medical");
if(medicals != null)
System.out.println(medicals.size());
}
}
finally{
ESInnerHitSerialThreadLocal.clean();//清空inner查询结果对于各种类型信息
}
} @Test
public void testMutil(){
this.createClientIndice();//创建indice client_info
// this.importClientInfoDataFromBeans(); //通过api添加测试数据
this.importClientInfoFromJsonData();//导入测试数据
this.queryExamSearchByClientName(); //根据客户端名称查询提交报告
this.queryClientInfoByMedicalName();//通过医疗信息编码查找客户基本数据
this.queryDiagnosisByClientName();//根据客户名称获取客户体检诊断数据,并返回客户数据
this.queryClientAndAllSons();//查询客户信息,同时返回客户对应的所有体检报告、医疗记录、诊断记录
}到此Elasticsearch 5.x 父子关系维护检索实战介绍完毕,谢谢大家!
相关资料
完整demo工程 https://github.com/bbossgroups/eshelloword-booter
对应的类文件和配置文件
org.bboss.elasticsearchtest.parentchild.ParentChildTest
esmapper/Client_Info.xml
开发交流
bboss交流群 166471282
bboss公众号

敬请关注:父子关系维护检索实战二 Elasticsearch 6.x 父子关系维护检
- 父子关系维护检索实战一 Elasticsearch 5.x 父子关系维护检索实战
- 父子关系维护检索实战二 Elasticsearch 6.x 父子关系维护检索实战
本文是其中第一篇- Elasticsearch 5.x 父子关系维护检索实战,涵盖以下部分内容:
- Elasticsearch 5.x 中父子关系mapping结构设计
- Elasticsearch 5.x 中维护父子关系数据
- Elasticsearch 5.x 中has_child和has_parent查询的基本用法
- Elasticsearch 5.x 中如何在检索中同时返回父子数据
案例说明
以一个体检记录相关的数据来介绍本文涉及的相关功能,体检数据包括客户基本信息basic和客户医疗记录medical、客户体检记录exam、客户体检结果分析记录diagnosis,它们之间的关系图如下:
我们采用Elasticsearch java客户端 bboss-elastic 来实现本文相关功能。
1.准备工作
参考文档《高性能elasticsearch ORM开发库使用介绍》导入和配置bboss客户端
2.定义mapping结构-Elasticsearch 5.x 中父子关系mapping结构设计
Elasticsearch 5.x中一个indice mapping支持多个mapping type,通过在子类型mapping中指定父类型的mapping type名字来设置父子关系,例如:
父类型
"basic": {
....
}
子类型:
"medical": {
"_parent": { "type": "basic" },
.................
}
新建dsl配置文件-esmapper/Client_Info.xml,定义完整的mapping结构:createClientIndice
<properties>
<!--
创建客户信息索引索引表
-->
<property name="createClientIndice">
<![CDATA[{
"settings": {
"number_of_shards": 6,
"index.refresh_interval": "5s"
},
"mappings": {
"basic": { ##基本信息
"properties": {
"party_id": {
"type": "keyword"
},
"sex": {
"type": "keyword"
},
"mari_sts": {
"type": "keyword"
},
"ethnic": {
"type": "text"
},
"prof": {
"type": "text"
},
"province": {
"type": "text"
},
"city": {
"type": "text"
},
"client_type": {
"type": "keyword"
},
"client_name": {
"type": "text"
},
"age": {
"type": "integer"
},
"id_type": {
"type": "keyword"
},
"idno": {
"type": "keyword"
},
"education": {
"type": "text"
},
"created_date": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd'T'HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss||epoch_millis"
},
"birth_date": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd'T'HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss||epoch_millis"
},
"last_modified_date": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd'T'HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss||epoch_millis"
},
"etl_date": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd'T'HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss||epoch_millis"
}
}
},
"diagnosis": { ##结果分析
"_parent": {
"type": "basic"
},
"properties": {
"party_id": {
"type": "keyword"
},
"provider": {
"type": "text"
},
"subject": {
"type": "text"
},
"diagnosis_type": {
"type": "text"
},
"icd10_code": {
"type": "text",
"type": "keyword"
},
"sd_disease_name": {
"type": "text",
"type": "keyword"
},
"created_date": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd'T'HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss||epoch_millis"
},
"last_modified_date": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd'T'HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss||epoch_millis"
},
"etl_date": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd'T'HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss||epoch_millis"
}
}
},
"medical": { ##医疗情况
"_parent": {
"type": "basic"
},
"properties": {
"party_id": {
"type": "keyword"
},
"hos_name_yb": {
"type": "text"
},
"eivisions_name": {
"type": "text"
},
"medical_type": {
"type": "text"
},
"medical_common_name": {
"type": "text"
},
"medical_sale_name": {
"type": "text"
},
"medical_code": {
"type": "text"
},
"specification": {
"type": "text"
},
"usage_num": {
"type": "text"
},
"unit": {
"type": "text"
},
"usage_times": {
"type": "text"
},
"created_date": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd'T'HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss||epoch_millis"
},
"last_modified_date": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd'T'HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss||epoch_millis"
},
"etl_date": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd'T'HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss||epoch_millis"
}
}
},
"exam": { ##检查结果
"_parent": {
"type": "basic"
},
"properties": {
"party_id": {
"type": "keyword"
},
"hospital": {
"type": "text"
},
"dept": {
"type": "text"
},
"is_ok": {
"type": "text"
},
"exam_result": {
"type": "text"
},
"fld1": {
"type": "text"
},
"fld2": {
"type": "text"
},
"fld3": {
"type": "text"
},
"fld4": {
"type": "text"
},
"fld5": {
"type": "text"
},
"fld901": {
"type": "text"
},
"fld6": {
"type": "text"
},
"fld902": {
"type": "text"
},
"fld14": {
"type": "text"
},
"fld20": {
"type": "text"
},
"fld21": {
"type": "text"
},
"fld23": {
"type": "text"
},
"fld24": {
"type": "text"
},
"fld65": {
"type": "text"
},
"fld66": {
"type": "text"
},
"fld67": {
"type": "text"
},
"fld68": {
"type": "text"
},
"created_date": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd'T'HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss||epoch_millis"
},
"last_modified_date": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd'T'HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss||epoch_millis"
},
"etl_date": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd'T'HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss||epoch_millis"
}
}
}
}
}]]>
</property>
</properties>这个mapping中定义了4个索引类型:basic,exam,medical,diagnosis,其中basic是其他类型的父类型。
通过bboss客户端创建名称为client_info 的索引:
public void createClientIndice(){
//定义客户端实例,加载上面建立的dsl配置文件
ClientInterface clientUtil = ElasticSearchHelper.getConfigRestClientUtil("esmapper/Client_Info.xml");
try {
//client_info存在返回true,不存在返回false
boolean exist = clientUtil.existIndice("client_info");
//如果索引表client_info已经存在先删除mapping
if(exist) {//先删除mapping client_info
clientUtil.dropIndice("client_info");
}
} catch (ElasticSearchException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
//创建mapping client_info
clientUtil.createIndiceMapping("client_info","createClientIndice");
String client_info = clientUtil.getIndice("client_info");//获取最新建立的索引表结构client_info
System.out.println("after createClientIndice clientUtil.getIndice(\"client_info\") response:"+client_info);
}3.维护父子关系数据-Elasticsearch 5.x 中维护父子关系数据
- 定义对象
首先定义四个对象,分别对应mapping中的四个索引类型,篇幅关系只列出主要属性
- Basic
- Medical
- Exam
- Diagnosis
通过注解@ESId指定基本信息文档_id
public class Basic extends ESBaseData {
/**
* 索引_id
*/
@ESId
private String party_id;
private String sex; // 性别
......
}
通过注解@ESParentId指定Medical关联的基本信息文档_id,Medical文档_id由ElasticSearch自动生成
public class Medical extends ESBaseData {
@ESParentId
private String party_id; //父id
private String hos_name_yb; //就诊医院
...
}
通过注解@ESParentId指定Exam关联的基本信息文档_id,Exam文档_id由ElasticSearch自动生成
public class Exam extends ESBaseData {
@ESParentId
private String party_id; //父id
private String hospital; // 就诊医院
....
}
通过注解@ESParentId指定Diagnosis关联的基本信息文档_id,Diagnosis文档_id由ElasticSearch自动生成
public class Diagnosis extends ESBaseData {
@ESParentId
private String party_id; //父id
private String provider; //诊断医院
private String subject; //科室
......
} - 通过api维护测试数据
对象定义好了后,通过bboss客户数据到之前建立好的索引client_info中。
/**
* 录入体检医疗信息
*/
public void importClientInfoDataFromBeans() {
ClientInterface clientUtil = ElasticSearchHelper.getRestClientUtil();
//导入基本信息,并且实时刷新,测试需要,实际环境不要带refresh
List<Basic> basics = buildBasics();
clientUtil.addDocuments("client_info","basic",basics,"refresh");
//导入医疗信息,并且实时刷新,测试需要,实际环境不要带refresh
List<Medical> medicals = buildMedicals();
clientUtil.addDocuments("client_info","medical",medicals,"refresh");
//导入体检结果数据,并且实时刷新,测试需要,实际环境不要带refresh
List<Exam> exams = buildExams();
clientUtil.addDocuments("client_info","exam",exams,"refresh");
//导入结果诊断数据,并且实时刷新,测试需要,实际环境不要带refresh
List<Diagnosis> diagnosiss = buildDiagnosiss();
clientUtil.addDocuments("client_info","diagnosis",diagnosiss,"refresh");
}
//构建基本信息集合
private List<Basic> buildBasics() {
List<Basic> basics = new ArrayList<Basic>();
Basic basic = new Basic();
basic.setParty_id("1");
basic.setAge(60);
basics.add(basic);
//继续添加其他数据
return basics;
}
//
构建医疗信息集合
private List<Medical> buildMedicals() {
List<Medical> medicals = new ArrayList<Medical>();
Medical medical = new Medical();
medical.setParty_id("1");//设置父文档id-基本信息文档_id
medical.setCreated_date(new Date());
medicals.add(medical);
//继续添加其他数据
return medicals;
}
//构建体检结果数据集合
private List<Exam> buildExams() {
List<Exam> exams = new ArrayList<Exam>();
Exam exam = new Exam();
exam.setParty_id("1");//设置父文档id-基本信息文档_id
exams.add(exam);
//继续添加其他数据
return exams;
}
//构建结果诊断数据集合
private List<Diagnosis> buildDiagnosiss() {
List<Diagnosis> diagnosiss = new ArrayList<Diagnosis>();
Diagnosis diagnosis = new Diagnosis();
diagnosis.setParty_id("1");//设置父文档id-基本信息文档_id
diagnosiss.add(diagnosis);
//继续添加其他数据
return diagnosiss;
}- 通过json报文批量导入测试数据
除了通过addDocuments录入数据,还可以通过json报文批量导入数据
在配置文件esmapper/Client_Info.xml增加以下内容:
<!--
导入基本信息:
-->
<property name="bulkImportBasicData" trim="false">
<![CDATA[
{ "index": { "_id": "1" }}
{ "party_id":"1", "sex":"男", "mari_sts":"不详", "ethnic":"蒙古族", "prof":"放牧","birth_date":"1966-2-14 00:00:00", "province":"内蒙古", "city":"赤峰市","client_type":"1", "client_name":"安", "age":52,"id_type":"1", "idno":"1", "education":"初中","created_date":"2013-04-24 00:00:00","last_modified_date":"2013-04-24 00:00:00", "etl_date":"2013-04-24 00:00:00"}
{ "index": { "_id": "2" }}
{ "party_id":"2", "sex":"女", "mari_sts":"已婚", "ethnic":"汉族", "prof":"公务员","birth_date":"1986-07-06 00:00:00", "province":"广东", "city":"深圳","client_type":"1", "client_name":"彭", "age":32,"id_type":"1", "idno":"2", "education":"本科", "created_date":"2013-05-09 15:49:47","last_modified_date":"2013-05-09 15:49:47", "etl_date":"2013-05-09 15:49:47"}
{ "index": { "_id": "3" }}
{ "party_id":"3", "sex":"男", "mari_sts":"未婚", "ethnic":"汉族", "prof":"无业","birth_date":"2000-08-15 00:00:00", "province":"广东", "city":"佛山","client_type":"1", "client_name":"浩", "age":18,"id_type":"1", "idno":"3", "education":"高中", "created_date":"2014-09-01 09:49:27","last_modified_date":"2014-09-01 09:49:27", "etl_date":"2014-09-01 09:49:27" }
{ "index": { "_id": "4" }}
{ "party_id":"4", "sex":"女", "mari_sts":"未婚", "ethnic":"满族", "prof":"工人","birth_date":"1996-03-14 00:00:00", "province":"江苏", "city":"扬州","client_type":"1", "client_name":"慧", "age":22,"id_type":"1", "idno":"4", "education":"高中", "created_date":"2014-09-16 09:30:37","last_modified_date":"2014-09-16 09:30:37", "etl_date":"2014-09-16 09:30:37" }
{ "index": { "_id": "5" }}
{ "party_id":"5", "sex":"女", "mari_sts":"已婚", "ethnic":"汉族", "prof":"教师","birth_date":"1983-08-14 00:00:00", "province":"宁夏", "city":"灵武","client_type":"1", "client_name":"英", "age":35,"id_type":"1", "idno":"5", "education":"本科", "created_date":"2015-09-16 09:30:37","last_modified_date":"2015-09-16 09:30:37", "etl_date":"2015-09-16 09:30:37" }
{ "index": { "_id": "6" }}
{ "party_id":"6", "sex":"女", "mari_sts":"已婚", "ethnic":"汉族", "prof":"工人","birth_date":"1959-07-04 00:00:00", "province":"山东", "city":"青岛","client_type":"1", "client_name":"岭", "age":59,"id_type":"1", "idno":"6", "education":"小学", "created_date":"2015-09-01 09:49:27","last_modified_date":"2015-09-01 09:49:27", "etl_date":"2015-09-01 09:49:27" }
{ "index": { "_id": "7" }}
{ "party_id":"7", "sex":"女", "mari_sts":"未婚", "ethnic":"汉族", "prof":"学生","birth_date":"1999-02-18 00:00:00", "province":"山东", "city":"青岛","client_type":"1", "client_name":"欣", "age":19,"id_type":"1", "idno":"7", "education":"高中", "created_date":"2016-12-01 09:49:27","last_modified_date":"2016-12-01 09:49:27", "etl_date":"2016-12-01 09:49:27" }
{ "index": { "_id": "8" }}
{ "party_id":"8", "sex":"女", "mari_sts":"未婚", "ethnic":"汉族", "prof":"学生","birth_date":"2007-11-18 00:00:00", "province":"山东", "city":"青岛","client_type":"1", "client_name":"梅", "age":10,"id_type":"1", "idno":"8", "education":"小学", "created_date":"2016-11-21 09:49:27","last_modified_date":"2016-11-21 09:49:27", "etl_date":"2016-11-21 09:49:27" }
{ "index": { "_id": "9" }}
{ "party_id":"9", "sex":"男", "mari_sts":"不详", "ethnic":"回族", "prof":"个体户","birth_date":"1978-03-29 00:00:00", "province":"北京", "city":"北京","client_type":"1", "client_name":"磊", "age":40,"id_type":"1", "idno":"9", "education":"高中", "created_date":"2017-09-01 09:49:27","last_modified_date":"2017-09-01 09:49:27", "etl_date":"2017-09-01 09:49:27" }
{ "index": { "_id": "10" }}
{ "party_id":"10", "sex":"男", "mari_sts":"已婚", "ethnic":"汉族", "prof":"农民","birth_date":"1970-11-14 00:00:00", "province":"浙江", "city":"台州","client_type":"1", "client_name":"强", "age":47,"id_type":"1", "idno":"10", "education":"初中", "created_date":"2018-09-01 09:49:27","last_modified_date":"2018-09-01 09:49:27", "etl_date":"2018-09-01 09:49:27" }
]]>
</property>
<!--
导入诊断信息
-->
<property name="bulkImportDiagnosisData" trim="false">
<![CDATA[
{ "index": { "parent": "1" }}
{ "party_id":"1", "provider":"内蒙古医院", "subject":"","diagnosis_type":"","icd10_code":"J31.0", "sd_disease_name":"鼻炎","created_date":"2013-07-23 20:56:44", "last_modified_date":"2013-07-23 20:56:44", "etl_date":"2013-07-23 20:56:44" }
{ "index": { "parent": "1" }}
{ "party_id":"1", "provider":"内蒙古医院", "subject":"","diagnosis_type":"","icd10_code":"M47.8", "sd_disease_name":"颈椎病","created_date":"2013-09-23 20:56:44", "last_modified_date":"2013-09-23 20:56:44", "etl_date":"2013-09-23 20:56:44" }
{ "index": { "parent": "1" }}
{ "party_id":"1", "provider":"内蒙古医院", "subject":"","diagnosis_type":"","icd10_code":"E78.1", "sd_disease_name":"甘油三脂增高","created_date":"2018-09-20 09:27:44", "last_modified_date":"2018-09-20 09:27:44", "etl_date":"2018-09-20 09:27:44" }
{ "index": { "parent": "4" }}
{ "party_id":"4", "provider":"江苏医院", "subject":"","diagnosis_type":"","icd10_code":"J00", "sd_disease_name":"感冒","created_date":"2011-05-19 15:52:55", "last_modified_date":"2011-05-19 15:52:55", "etl_date":"2011-05-19 15:52:55" }
{ "index": { "parent": "6" }}
{ "party_id":"6", "provider":"山东医院", "subject":"","diagnosis_type":"","icd10_code":"H44", "sd_disease_name":"眼疾","created_date":"2016-04-08 10:42:18", "last_modified_date":"2016-04-08 10:42:18", "etl_date":"2016-04-08 10:42:18" }
{ "index": { "parent": "6" }}
{ "party_id":"6", "provider":"山东医院", "subject":"","diagnosis_type":"","icd10_code":"M47.8", "sd_disease_name":"颈椎病","created_date":"2016-04-08 10:42:18", "last_modified_date":"2016-04-08 10:42:18", "etl_date":"2016-04-08 10:42:18" }
{ "index": { "parent": "7" }}
{ "party_id":"7", "provider":"山东医院", "subject":"","diagnosis_type":"","icd10_code":"J00", "sd_disease_name":"感冒","created_date":"2017-04-08 10:42:18", "last_modified_date":"2017-04-08 10:42:18", "etl_date":"2017-04-08 10:42:18" }
{ "index": { "parent": "8" }}
{ "party_id":"8", "provider":"山东医院", "subject":"","diagnosis_type":"","icd10_code":"J00", "sd_disease_name":"感冒","created_date":"2018-04-08 10:42:18", "last_modified_date":"2018-04-08 10:42:18", "etl_date":"2018-04-08 10:42:18" }
{ "index": { "parent": "9" }}
{ "party_id":"9", "provider":"朝阳医院", "subject":"","diagnosis_type":"","icd10_code":"A03.901", "sd_disease_name":"急性细菌性痢疾","created_date":"2015-06-08 10:42:18", "last_modified_date":"2015-06-08 10:42:18", "etl_date":"2015-06-08 10:42:18" }
]]>
</property>
<!--
导入医疗信息
-->
<property name="bulkImportMedicalData" trim="false">
<![CDATA[
{ "index": { "parent": "1" }}
{ "party_id":"1", "hos_name_yb":"内蒙古医院", "eivisions_name":"", "medical_type":"","medical_common_name":"氟化钠", "medical_sale_name":"", "medical_code":"A01AA01", "specification":"","usage_num":"", "unit":"", "usage_times":"","created_date":"2014-03-18 00:00:00", "last_modified_date":"2014-03-18 00:00:00", "etl_date":"2014-03-18 00:00:00" }
{ "index": { "parent": "1" }}
{ "party_id":"1", "hos_name_yb":"内蒙古医院", "eivisions_name":"", "medical_type":"","medical_common_name":"四环素", "medical_sale_name":"", "medical_code":"A01AB13", "specification":"","usage_num":"", "unit":"", "usage_times":"","created_date":"2016-05-31 00:00:00", "last_modified_date":"2016-05-31 00:00:00", "etl_date":"2016-05-31 00:00:00" }
{ "index": { "parent": "1" }}
{ "party_id":"1", "hos_name_yb":"内蒙古医院", "eivisions_name":"", "medical_type":"","medical_common_name":"", "medical_sale_name":"盐酸多西环素胶丸", "medical_code":"A01AB22", "specification":"","usage_num":"", "unit":"", "usage_times":"","created_date":"2016-03-18 00:00:00", "last_modified_date":"2016-03-18 00:00:00", "etl_date":"2016-03-18 00:00:00" }
{ "index": { "parent": "1" }}
{ "party_id":"1", "hos_name_yb":"内蒙古医院", "eivisions_name":"", "medical_type":"","medical_common_name":"盐酸多西环素分散片", "medical_sale_name":"", "medical_code":"A01AB22", "specification":"","usage_num":"", "unit":"", "usage_times":"","created_date":"2013-07-23 20:56:44", "last_modified_date":"2013-07-23 20:56:44", "etl_date":"2013-07-23 20:56:44" }
{ "index": { "parent": "1" }}
{ "party_id":"1", "hos_name_yb":"内蒙古医院", "eivisions_name":"", "medical_type":"","medical_common_name":"地塞米松", "medical_sale_name":"", "medical_code":"A01AC02", "specification":"","usage_num":"", "unit":"", "usage_times":"","created_date":"2013-09-23 20:56:44", "last_modified_date":"2013-09-23 20:56:44", "etl_date":"2013-09-23 20:56:44" }
{ "index": { "parent": "1" }}
{ "party_id":"1", "hos_name_yb":"内蒙古医院", "eivisions_name":"", "medical_type":"","medical_common_name":"肾上腺素", "medical_sale_name":"", "medical_code":"A01AD01", "specification":"","usage_num":"", "unit":"", "usage_times":"","created_date":"2018-09-20 09:27:44", "last_modified_date":"2018-09-20 09:27:44", "etl_date":"2018-09-20 09:27:44" }
{ "index": { "parent": "4" }}
{ "party_id":"4", "hos_name_yb":"江苏医院", "eivisions_name":"", "medical_type":"","medical_common_name":"地塞米松", "medical_sale_name":"", "medical_code":"A01AC02", "specification":"","usage_num":"", "unit":"", "usage_times":"","created_date":"2011-05-19 15:52:55", "last_modified_date":"2011-05-19 15:52:55", "etl_date":"2011-05-19 15:52:55" }
{ "index": { "parent": "4" }}
{ "party_id":"4", "hos_name_yb":"江苏医院", "eivisions_name":"", "medical_type":"","medical_common_name":"四环素", "medical_sale_name":"", "medical_code":"A01AB13", "specification":"","usage_num":"", "unit":"", "usage_times":"","created_date":"2018-04-08 10:42:18", "last_modified_date":"2018-04-08 10:42:18", "etl_date":"2018-04-08 10:42:18" }
{ "index": { "parent": "4" }}
{ "party_id":"4", "hos_name_yb":"江苏医院", "eivisions_name":"", "medical_type":"","medical_common_name":"诺氟沙星胶囊", "medical_sale_name":"", "medical_code":"A01AD01", "specification":"","usage_num":"", "unit":"", "usage_times":"","created_date":"2015-06-08 10:42:18", "last_modified_date":"2015-06-08 10:42:18", "etl_date":"2015-06-08 10:42:18" }
{ "index": { "parent": "6" }}
{ "party_id":"6", "hos_name_yb":"山东医院", "eivisions_name":"", "medical_type":"","medical_common_name":"盐酸异丙肾上腺素片", "medical_sale_name":"", "medical_code":"A01AD01", "specification":"","usage_num":"", "unit":"", "usage_times":"","created_date":"2014-01-23 20:56:44", "last_modified_date":"2014-01-23 20:56:44", "etl_date":"2014-01-23 20:56:44" }
{ "index": { "parent": "6" }}
{ "party_id":"6", "hos_name_yb":"山东医院", "eivisions_name":"", "medical_type":"","medical_common_name":"甲硝唑栓", "medical_sale_name":"", "medical_code":"A01AB17", "specification":"","usage_num":"", "unit":"", "usage_times":"","created_date":"2018-06-08 10:42:18", "last_modified_date":"2018-06-08 10:42:18", "etl_date":"2018-06-08 10:42:18" }
{ "index": { "parent": "9" }}
{ "party_id":"9", "hos_name_yb":"朝阳医院", "eivisions_name":"", "medical_type":"","medical_common_name":"复方克霉唑乳膏", "medical_sale_name":"", "medical_code":"A01AB18", "specification":"","usage_num":"", "unit":"", "usage_times":"","created_date":"2014-01-23 20:56:44", "last_modified_date":"2014-01-23 20:56:44", "etl_date":"2014-01-23 20:56:44"}
]]>
</property>
<!--
导入体检信息
-->
<property name="bulkImportExamData" trim="false">
<![CDATA[
{ "index": { "parent": "1" }}
{ "party_id":"1", "hospital":"", "dept":"", "is_ok":"N", "exam_result":"高血压","fld1":"158", "fld2":"63", "fld3":"94", "fld4":"85", "fld5":"131", "fld901":"89", "fld6":"4.9","fld902":"4.8","fld14":"78", "fld21":"78", "fld23":"", "fld24":"5.5", "fld65":"5.5", "fld66":"1.025","fld67":"", "fld68":"","created_date":"2014-03-18 00:00:00", "last_modified_date":"2014-03-18 00:00:00", "etl_date":"2014-03-18 00:00:00" }
{ "index": { "parent": "2" }}
{ "party_id":"2", "hospital":"", "dept":"", "is_ok":"Y", "exam_result":"轻度脂肪肝","fld1":"158", "fld2":"63", "fld3":"94", "fld4":"85", "fld5":"131", "fld901":"89", "fld6":"4.9","fld902":"4.8","fld14":"78", "fld21":"78", "fld23":"", "fld24":"5.5", "fld65":"5.5", "fld66":"1.025","fld67":"", "fld68":"","created_date":"2014-03-18 00:00:00", "last_modified_date":"2014-03-18 00:00:00", "etl_date":"2014-03-18 00:00:00" }
{ "index": { "parent": "3" }}
{ "party_id":"3", "hospital":"", "dept":"", "is_ok":"N", "exam_result":"急性细菌性痢疾","fld1":"158", "fld2":"63", "fld3":"94", "fld4":"85", "fld5":"131", "fld901":"89", "fld6":"4.9","fld902":"4.8","fld14":"78", "fld21":"78", "fld23":"", "fld24":"5.5", "fld65":"5.5", "fld66":"1.025","fld67":"", "fld68":"","created_date":"2014-03-18 00:00:00", "last_modified_date":"2014-03-18 00:00:00", "etl_date":"2014-03-18 00:00:00" }
{ "index": { "parent": "4" }}
{ "party_id":"4", "hospital":"", "dept":"", "is_ok":"N", "exam_result":"感冒","fld1":"158", "fld2":"63", "fld3":"94", "fld4":"85", "fld5":"131", "fld901":"89", "fld6":"4.9","fld902":"4.8","fld14":"78", "fld21":"78", "fld23":"", "fld24":"5.5", "fld65":"5.5", "fld66":"1.025","fld67":"", "fld68":"","created_date":"2014-03-18 00:00:00", "last_modified_date":"2014-03-18 00:00:00", "etl_date":"2014-03-18 00:00:00" }
{ "index": { "parent": "5" }}
{ "party_id":"5", "hospital":"", "dept":"", "is_ok":"N", "exam_result":"感冒","fld1":"158", "fld2":"63", "fld3":"94", "fld4":"85", "fld5":"131", "fld901":"89", "fld6":"4.9","fld902":"4.8","fld14":"78", "fld21":"78", "fld23":"", "fld24":"5.5", "fld65":"5.5", "fld66":"1.025","fld67":"", "fld68":"","created_date":"2014-03-18 00:00:00", "last_modified_date":"2014-03-18 00:00:00", "etl_date":"2014-03-18 00:00:00" }
{ "index": { "parent": "6" }}
{ "party_id":"6", "hospital":"", "dept":"", "is_ok":"N", "exam_result":"感冒","fld1":"158", "fld2":"63", "fld3":"94", "fld4":"85", "fld5":"131", "fld901":"89", "fld6":"4.9","fld902":"4.8","fld14":"78", "fld21":"78", "fld23":"", "fld24":"5.5", "fld65":"5.5", "fld66":"1.025","fld67":"", "fld68":"","created_date":"2014-03-18 00:00:00", "last_modified_date":"2014-03-18 00:00:00", "etl_date":"2014-03-18 00:00:00" }
{ "index": { "parent": "7" }}
{ "party_id":"7", "hospital":"", "dept":"", "is_ok":"N", "exam_result":"颈椎病","fld1":"158", "fld2":"63", "fld3":"94", "fld4":"85", "fld5":"131", "fld901":"89", "fld6":"4.9","fld902":"4.8","fld14":"78", "fld21":"78", "fld23":"", "fld24":"5.5", "fld65":"5.5", "fld66":"1.025","fld67":"", "fld68":"","created_date":"2014-03-18 00:00:00", "last_modified_date":"2014-03-18 00:00:00", "etl_date":"2014-03-18 00:00:00" }
{ "index": { "parent": "8" }}
{ "party_id":"1", "hospital":"", "dept":"", "is_ok":"N", "exam_result":"颈椎病","fld1":"158", "fld2":"63", "fld3":"94", "fld4":"85", "fld5":"131", "fld901":"89", "fld6":"4.9","fld902":"4.8","fld14":"78", "fld21":"78", "fld23":"", "fld24":"5.5", "fld65":"5.5", "fld66":"1.025","fld67":"", "fld68":"","created_date":"2014-03-18 00:00:00", "last_modified_date":"2014-03-18 00:00:00", "etl_date":"2014-03-18 00:00:00" }
{ "index": { "parent": "9" }}
{ "party_id":"9", "hospital":"", "dept":"", "is_ok":"N", "exam_result":"颈椎病","fld1":"158", "fld2":"63", "fld3":"94", "fld4":"85", "fld5":"131", "fld901":"89", "fld6":"4.9","fld902":"4.8","fld14":"78", "fld21":"78", "fld23":"", "fld24":"5.5", "fld65":"5.5", "fld66":"1.025","fld67":"", "fld68":"","created_date":"2014-03-18 00:00:00", "last_modified_date":"2014-03-18 00:00:00", "etl_date":"2014-03-18 00:00:00" }
{ "index": { "parent": "10" }}
{ "party_id":"10", "hospital":"", "dept":"", "is_ok":"N", "exam_result":"颈椎病","fld1":"158", "fld2":"63", "fld3":"94", "fld4":"85", "fld5":"131", "fld901":"89", "fld6":"4.9","fld902":"4.8","fld14":"78", "fld21":"78", "fld23":"", "fld24":"5.5", "fld65":"5.5", "fld66":"1.025","fld67":"", "fld68":"","created_date":"2014-03-18 00:00:00", "last_modified_date":"2014-03-18 00:00:00", "etl_date":"2014-03-18 00:00:00" }
]]>
</property>
/**
* 通过读取配置文件中的dsl json数据导入医疗数据
*/
public void importClientInfoFromJsonData(){
ClientInterface clientUtil = ElasticSearchHelper.getConfigRestClientUtil("esmapper/Client_Info.xml");
clientUtil.executeHttp("client_info/basic/_bulk?refresh","bulkImportBasicData",ClientUtil.HTTP_POST);
clientUtil.executeHttp("client_info/diagnosis/_bulk?refresh","bulkImportDiagnosisData",ClientUtil.HTTP_POST);
clientUtil.executeHttp("client_info/medical/_bulk?refresh","bulkImportMedicalData",ClientUtil.HTTP_POST);
clientUtil.executeHttp("client_info/exam/_bulk?refresh","bulkImportExamData",ClientUtil.HTTP_POST);
long basiccount = clientUtil.countAll("client_info/basic");
System.out.println(basiccount);
long medicalcount = clientUtil.countAll("client_info/medical");
System.out.println(medicalcount);
long examcount = clientUtil.countAll("client_info/exam");
System.out.println(examcount);
long diagnosiscount = clientUtil.countAll("client_info/diagnosis");
System.out.println(diagnosiscount);
}- 根据父查子-通过客户名称信息查询客户端体检结果
在配置文件esmapper/Client_Info.xml增加dsl语句:queryExamSearchByClientName
<!--根据客户名称查询客户体检报告-->
<property name="queryExamSearchByClientName">
<![CDATA[
{
"query": {
## 最多返回size变量对应的记录条数
"size":#[size],
"has_parent": {
"type": "basic",
"query": {
"match": {
"client_name": #[clientName] ## 通过变量clientName设置客户名称
}
}
}
}
}
]]>
</property>执行查询,通过bboss的searchList 方法获取符合条件的体检报告以及总记录数据,返回size对应的1000条数据
/**
* 根据客户名称查询客户体检报告
*/
public void queryExamSearchByClientName(){
ClientInterface clientUtil = ElasticSearchHelper.getConfigRestClientUtil("esmapper/Client_info.xml");
Map<String,Object> params = new HashMap<String,Object>();
params.put("clientName","张三");
params.put("size",1000);
ESDatas<Exam> exams = clientUtil.searchList("client_info/exam/_search","queryExamSearchByClientName",params,Exam.class);
List<Exam> examList = exams.getDatas();//获取符合条件的体检数据
long totalSize = exams.getTotalSize();//符合条件的总记录数据
}- 根据子查父数据-通过医疗信息编码查找客户基本数据
在配置文件esmapper/Client_Info.xml增加查询dsl语句:queryClientInfoByMedicalName
<!--通过医疗信息编码查找客户基本数据-->
<property name="queryClientInfoByMedicalName">
<![CDATA[
{
"query": {
## 最多返回size变量对应的记录条数
"size":#[size],
"has_child": {
"type": "medical",
"score_mode": "max",
"query": {
"match": {
"medical_code": #[medicalCode] ## 通过变量medicalCode设置医疗编码
}
}
}
}
}
]]>
</property> /**
* 通过医疗信息编码查找客户基本数据
*/
public void queryClientInfoByMedicalName(){
ClientInterface clientUtil = ElasticSearchHelper.getConfigRestClientUtil("esmapper/Client_info.xml");
Map<String,Object> params = new HashMap<String,Object>();
params.put("medicalCode","A01AA01"); //通过变量medicalCode设置医疗编码
params.put("size",1000); //最多返回size变量对应的记录条数
ESDatas<Basic> bascis = clientUtil.searchList("client_info/basic/_search","queryClientInfoByMedicalName",params,Basic.class);
List<Basic> bascisList = bascis.getDatas();//获取符合条件的客户信息
long totalSize = bascis.getTotalSize();
}这一节中我们介绍同时返回父子数据的玩法 :inner_hits的妙用
- 根据父条件查询所有子数据集合并返回父数据,根据客户名称查询所有体检数据,同时返回客户信息
在配置文件esmapper/Client_Info.xml增加检索dsl-queryDiagnosisByClientName
<!--根据客户名称获取客户体检诊断数据,并返回客户信息-->
<property name="queryDiagnosisByClientName">
<![CDATA[
{
"query": {
## 最多返回size变量对应的记录条数
"size":#[size],
"has_parent": {
"type": "basic",
"query": {
"match": {
"client_name": #[clientName] ## 通过变量clientName设置客户名称
}
},
"inner_hits": {} ## 通过变量inner_hits表示要返回对应的客户信息
}
}
}
]]>
</property> /**
* 根据客户名称获取客户体检诊断数据,并返回客户数据
*/
public void queryDiagnosisByClientName(){
ClientInterface clientUtil = ElasticSearchHelper.getConfigRestClientUtil("esmapper/Client_info.xml");
Map<String,Object> params = new HashMap<String,Object>();
params.put("clientName","张三");
params.put("size",1000);
try {
ESInnerHitSerialThreadLocal.setESInnerTypeReferences(Basic.class);//指定inner查询结果对应的客户基本信息类型,Basic只有一个文档类型,索引不需要显示指定basic对应的mapping type名称
ESDatas<Diagnosis> diagnosiss = clientUtil.searchList("client_info/diagnosis/_search",
"queryDiagnosisByClientName",params,Diagnosis.class);
List<Diagnosis> diagnosisList = diagnosiss.getDatas();//获取符合条件的体检报告数据
long totalSize = diagnosiss.getTotalSize();
//遍历诊断报告信息,并查看报告对应的客户基本信息
for(int i = 0; diagnosisList != null && i < diagnosisList.size(); i ++) {
Diagnosis diagnosis = diagnosisList.get(i);
List<Basic> basics = ResultUtil.getInnerHits(diagnosis.getInnerHits(), "basic");
if(basics != null) {
System.out.println(basics.size());
}
}
}
finally{
ESInnerHitSerialThreadLocal.clean();//清空inner查询结果对应的客户基本信息类型
}
}- 根据子条件查询父数据并返回符合条件的父的子数据集合,查询客户信息,同时返回客户对应的所有体检报告、医疗记录、诊断记录
在配置文件esmapper/Client_Info.xml增加检索dsl-queryClientAndAllSons
<!--查询客户信息,同时返回客户对应的所有体检报告、医疗记录、诊断记录-->
<property name="queryClientAndAllSons">
<![CDATA[
{
"query": {
"bool": {
"should": [
{
"match_all":{}
}
]
,"must": [
{
"has_child": {
"score_mode": "none",
"type": "diagnosis"
,"query": {
"bool": {
"must": [
{
"term": {
"icd10_code": {
"value": "J00"
}
}
}
]
}
},"inner_hits":{}
}
}
]
,"should": [
{
"has_child": {
"score_mode": "none",
"type": "medical"
,"query": {
"match_all": {}
},"inner_hits":{}
}
}
]
,"should": [
{
"has_child": {
"type": "exam",
"query": {
"match_all": {}
},"inner_hits":{}
}
}
]
}
}
}
]]>
</property> /**
* 查询客户信息,同时返回客户对应的所有体检报告、医疗记录、诊断记录
*/
public void queryClientAndAllSons(){
ClientInterface clientUtil = ElasticSearchHelper.getConfigRestClientUtil("esmapper/Client_Info.xml");
Map<String,Object> params = null;//没有检索条件,构造一个空的参数对象
try {
//设置子文档的类型和对象映射关系
ESInnerHitSerialThreadLocal.setESInnerTypeReferences("exam",Exam.class);//指定inner查询结果对于exam类型和对应的对象类型Exam
ESInnerHitSerialThreadLocal.setESInnerTypeReferences("diagnosis",Diagnosis.class);//指定inner查询结果对于diagnosis类型和对应的对象类型Diagnosis
ESInnerHitSerialThreadLocal.setESInnerTypeReferences("medical",Medical.class);//指定inner查询结果对于medical类型和对应的对象类型Medical
ESDatas<Basic> escompanys = clientUtil.searchList("client_info/basic/_search",
"queryClientAndAllSons",params,Basic.class);
//String response = clientUtil.executeRequest("client_info/basic/_search","queryClientAndAllSons",params);直接获取原始的json报文
// escompanys = clientUtil.searchAll("client_info",Basic.class);
long totalSize = escompanys.getTotalSize();
List<Basic> clientInfos = escompanys.getDatas();//获取符合条件的数据
//查看公司下面的雇员信息(符合检索条件的雇员信息)
for (int i = 0; clientInfos != null && i < clientInfos.size(); i++) {
Basic clientInfo = clientInfos.get(i);
List<Exam> exams = ResultUtil.getInnerHits(clientInfo.getInnerHits(), "exam");
if(exams != null)
System.out.println(exams.size());
List<Diagnosis> diagnosiss = ResultUtil.getInnerHits(clientInfo.getInnerHits(), "diagnosis");
if(diagnosiss != null)
System.out.println(diagnosiss.size());
List<Medical> medicals = ResultUtil.getInnerHits(clientInfo.getInnerHits(), "medical");
if(medicals != null)
System.out.println(medicals.size());
}
}
finally{
ESInnerHitSerialThreadLocal.clean();//清空inner查询结果对于各种类型信息
}
} @Test
public void testMutil(){
this.createClientIndice();//创建indice client_info
// this.importClientInfoDataFromBeans(); //通过api添加测试数据
this.importClientInfoFromJsonData();//导入测试数据
this.queryExamSearchByClientName(); //根据客户端名称查询提交报告
this.queryClientInfoByMedicalName();//通过医疗信息编码查找客户基本数据
this.queryDiagnosisByClientName();//根据客户名称获取客户体检诊断数据,并返回客户数据
this.queryClientAndAllSons();//查询客户信息,同时返回客户对应的所有体检报告、医疗记录、诊断记录
}到此Elasticsearch 5.x 父子关系维护检索实战介绍完毕,谢谢大家!
相关资料
完整demo工程 https://github.com/bbossgroups/eshelloword-booter
对应的类文件和配置文件
org.bboss.elasticsearchtest.parentchild.ParentChildTest
esmapper/Client_Info.xml
开发交流
bboss交流群 166471282
bboss公众号
敬请关注:父子关系维护检索实战二 Elasticsearch 6.x 父子关系维护检 收起阅读 »
logstash input插件开发
logstash作为一个数据管道中间件,支持对各种类型数据的采集与转换,并将数据发送到各种类型的存储库,比如实现消费kafka数据并且写入到Elasticsearch, 日志文件同步到对象存储S3等,mysql数据同步到Elasticsearch等。
logstash内部主要包含三个模块:
* input: 从数据源获取数据
* filter: 过滤、转换数据
* output: 输出数据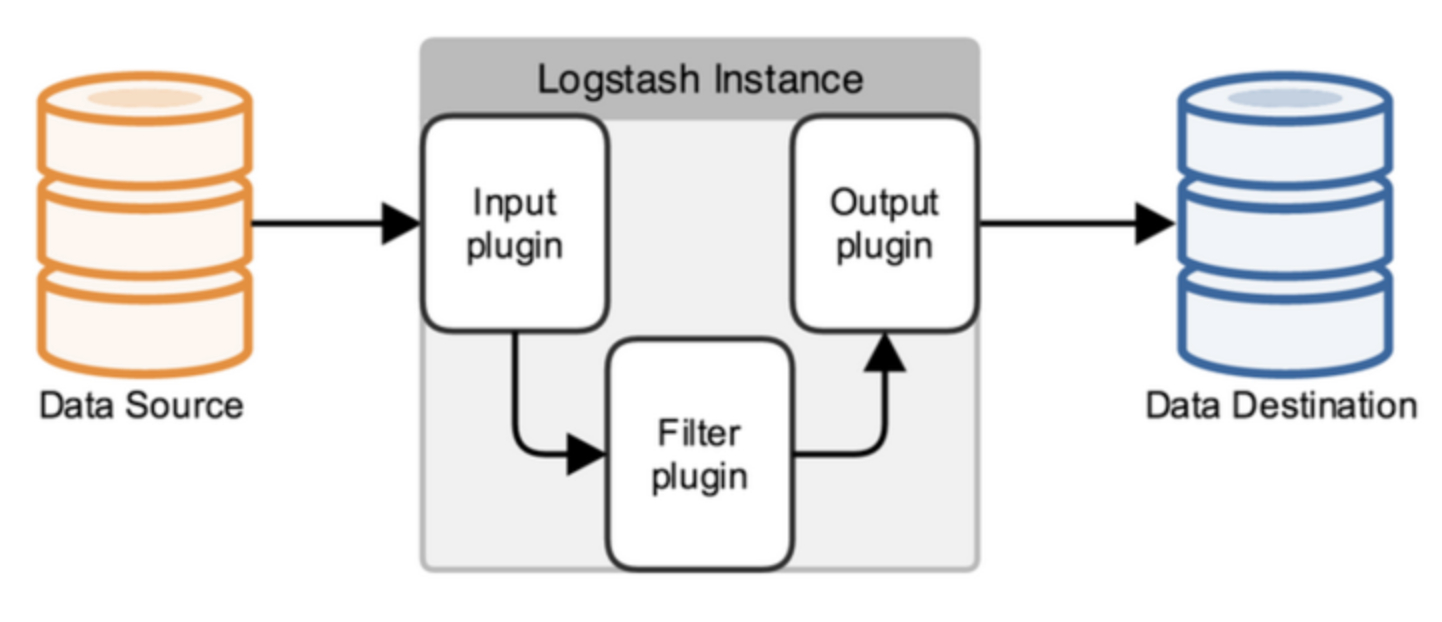
不同类型的数据都可以通过对应的input-plugin, output-plugin完成数据的输入与输出。如需要消费kafka中的数据并写入到Elasticsearch中,则需要使用logstash的kafka-input-plugin完成数据输入,logstash-output-elasticsearch完成数据输出。如果需要对输入数据进行过滤或者转换,比如根据关键词过滤掉不需要的内容,或者时间字段的格式转换,就需要又filter-plugin完成了。
logstash的input插件目前已经有几十种了,支持大多数比较通用或开源的数据源的输入。但如果公司内部开发的数据库或其它存储类的服务不能和开源产品在接口协议上兼容,比如腾讯自研的消息队列服务CMQ不依赖于其它的开源消息队列产品,所以不能直接使用logstash的logstash-input-kafka或logstash-input-rabbitmq同步CMQ中的数据;腾讯云对象存储服务COS, 在鉴权方式上和AWS的S3存在差异,也不能直接使用logstash-input-s3插件从COS中读取数据,对于这种情况,就需要自己开发logstash的input插件了。
本文以开发logstash的cos input插件为例,介绍如何开发logstash的input插件。
logstash官方提供了有个简单的input plugin example可供参考: https://github.com/logstash-plugins/logstash-input-example/
环境准备
logstash使用jruby开发,首先要配置jruby环境:
-
安装rvm:
rvm是一个ruby管理器,可以安装并管理ruby环境,也可以通过命令行切换到不同的ruby版本。
gpg --keyserver hkp://keys.gnupg.net --recv-keys 409B6B1796C275462A1703113804BB82D39DC0E3 7D2BAF1CF37B13E2069D6956105BD0E739499BDB\curl -sSL https://get.rvm.io | bash -s stablesource /etc/profile.d/rvm.sh -
安装jruby
rvm install jrubyrvm use jruby -
安装包管理工具bundle和测试工具rspec
gem install bundle gem install rspec
从example开始
-
clone logstash-input-example
git clone https://github.com/logstash-plugins/logstash-input-example.git -
将clone出来的logstash-input-example源码copy到logstash-input-cos目录,并删除.git文件夹,目的是以logstash-input-example的源码为参考进行开发,同时把需要改动名称的地方修改一下:
mv logstash-input-example.gemspec logstash-input-cos.gemspec mv lib/logstash/inputs/example.rb lib/logstash/inputs/cos.rb mv spec/inputs/example_spec.rb spec/inputs/cos_spec.rb - 建立的源码目录结构如图所示:
其中,重要文件的作用说明如下:
- cos.rb: 主文件,在该文件中编写logstash配置文件的读写与源数据获取的代码,需要继承LogStash::Inputs::Base基类
- cos_spec.rb: 单元测试文件,通过rspec可以对cos.rb中的代码进行测试
- logstash-input-cos.gemspec: 类似于maven中的pom.xml文件,配置工程的版本、名称、licene,包依赖等,通过bundle命令可以下载依赖包
配置并下载依赖
因为腾讯云COS服务没有ruby sdk, 因为只能依赖其Java sdk进行开发,首先添加对cos java sdk的依赖。在logstash-input-cos.gemspec中Gem dependencies配置栏中增加以下内容:
# Gem dependencies
s.requirements << "jar 'com.qcloud:cos_api', '5.4.4'"
s.add_runtime_dependency "logstash-core-plugin-api", ">= 1.60", "<= 2.99"
s.add_runtime_dependency 'logstash-codec-plain'
s.add_runtime_dependency 'stud', '>= 0.0.22'
s.add_runtime_dependency 'jar-dependencies'
s.add_development_dependency 'logstash-devutils', '1.3.6'相比logstash-input-example.gemspec,增加了对com.qcloud:cos_api包以及jar-dependencies包的依赖,jar-dependencies用于在ruby环境中管理jar包,并且可以跟踪jar包的加载状态。
然后,在logstash-input-cos.gemspec中增加配置:
s.platform = 'java'这样可以成功下载java依赖包,并且可以在ruby代码中直接调用java代码。
最后,执行以下命令下载依赖:
bundle install编写代码
logstash-input-cos的代码逻辑其实比较简单,主要是通过执行定时任务,调用cos java sdk中的listObjects方法,获取到指定bucket里的数据,并在每次定时任务执行结束后设置marker保存在本地,再次执行时从marker位置获取数据,以实现数据的增量同步。
jar包的引用
因为要调用cos java sdk中的代码,先引用该jar包:
require 'cos_api-5.4.4.jar'
java_import com.qcloud.cos.COSClient;
java_import com.qcloud.cos.ClientConfig;
java_import com.qcloud.cos.auth.BasicCOSCredentials;
java_import com.qcloud.cos.auth.COSCredentials;
java_import com.qcloud.cos.exception.CosClientException;
java_import com.qcloud.cos.exception.CosServiceException;
java_import com.qcloud.cos.model.COSObjectSummary;
java_import com.qcloud.cos.model.ListObjectsRequest;
java_import com.qcloud.cos.model.ObjectListing;
java_import com.qcloud.cos.region.Region;读取配置文件
logstash配置文件读取的代码如图所示:
config_name为cos,其它的配置项读取代码按照ruby的代码规范编写,添加类型校验与默认值,就可以从以下配置文件中读取配置项:
input {
cos {
"endpoint" => "cos.ap-guangzhou.myqcloud.com"
"access_key_id" => "*****"
"access_key_secret" => "****"
"bucket" => "******"
"region" => "ap-guangzhou"
"appId" => "**********"
"interval" => 60
}
}
output {
stdout {
codec=>rubydebug
}
}实现register方法
logstash input插件必须实现另个方法:register 和run
register方法类似于初始化方法,在该方法中可以直接使用从配置文件读取并赋值的变量,完成cos client的初始化,代码如下:
# 1 初始化用户身份信息(appid, secretId, secretKey)
cred = com.qcloud.cos.auth.BasicCOSCredentials.new(@access_key_id, @access_key_secret)
# 2 设置bucket的区域, COS地域的简称请参照 https://www.qcloud.com/document/product/436/6224
clientConfig = com.qcloud.cos.ClientConfig.new(com.qcloud.cos.region.Region.new(@region))
# 3 生成cos客户端
@cosclient = com.qcloud.cos.COSClient.new(cred, clientConfig)
# bucket名称, 需包含appid
bucketName = @bucket + "-"+ @appId
@bucketName = bucketName
@listObjectsRequest = com.qcloud.cos.model.ListObjectsRequest.new()
# 设置bucket名称
@listObjectsRequest.setBucketName(bucketName)
# prefix表示列出的object的key以prefix开始
@listObjectsRequest.setPrefix(@prefix)
# 设置最大遍历出多少个对象, 一次listobject最大支持1000
@listObjectsRequest.setMaxKeys(1000)
@listObjectsRequest.setMarker(@markerConfig.getMarker)示例代码中设置了@cosclient和@listObjectRequest为全局变量, 因为在run方法中会用到这两个变量。
注意在ruby中调用java代码的方式:没有变量描述符;不能直接new Object(),而只能Object.new().
实现run方法
run方法获取数据并将数据流转换成event事件
最简单的run方法为:
def run(queue)
Stud.interval(@interval) do
event = LogStash::Event.new("message" => @message, "host" => @host)
decorate(event)
queue << event
end # loop
end # def run代码说明:
- 通过Stud ruby模块执行定时任务,interval可自定义,从配置文件中读取
- 生成event, 示例代码生成了一个包含两个字段数据的event
- 调用decorate()方法, 给该event打上tag,如果配置的话
- queue<<event, 将event插入到数据管道中,发送给filter处理
logstash-input-cos的run方法实现为:
def run(queue)
@current_thread = Thread.current
Stud.interval(@interval) do
process(queue)
end
end
def process(queue)
@logger.info('Marker from: ' + @markerConfig.getMarker)
objectListing = @cosclient.listObjects(@listObjectsRequest)
nextMarker = objectListing.getNextMarker()
cosObjectSummaries = objectListing.getObjectSummaries()
cosObjectSummaries.each do |obj|
# 文件的路径key
key = obj.getKey()
if stop?
@logger.info("stop while attempting to read log file")
break
end
# 根据key获取内容
getObject(key) { |log|
# 发送消息
@codec.decode(log) do |event|
decorate(event)
queue << event
end
}
#记录 marker
@markerConfig.setMarker(key)
@logger.info('Marker end: ' + @markerConfig.getMarker)
end
end
# 获取下载输入流
def getObject(key, &block)
getObjectRequest = com.qcloud.cos.model.GetObjectRequest.new(@bucketName, key)
cosObject = @cosclient.getObject(getObjectRequest)
cosObjectInput = cosObject.getObjectContent()
buffered =BufferedReader.new(InputStreamReader.new(cosObjectInput))
while (line = buffered.readLine())
block.call(line)
end
end测试代码
在spec/inputs/cos_spec.rb中增加如下测试代码:
# encoding: utf-8
require "logstash/devutils/rspec/spec_helper"
require "logstash/inputs/cos"
describe LogStash::Inputs::Cos do
it_behaves_like "an interruptible input plugin" do
let(:config) { {
"endpoint" => 'cos.ap-guangzhou.myqcloud.com',
"access_key_id" => '*',
"access_key_secret" => '*',
"bucket" => '*',
"region" => 'ap-guangzhou',
"appId" => '*',
"interval" => 60 } }
end
end
rspec是一个ruby测试库,通过bundle命令执行rspec:
bundle exec rspec如果cos.rb中的代码没有语法或运行时错误,则会出现如果信息表明测试成功:
Finished in 0.8022 seconds (files took 3.45 seconds to load)
1 example, 0 failures构建并测试input-plugin-cos
build
使用gem对input-plugin-cos插件源码进行build:
gem build logstash-input-cos.gemspec构建完成后会生成一个名为logstash-input-cos-0.0.1-java.gem的文件
test
在logstash的解压目录下,执行一下命令安装logstash-input-cos plugin:
./bin/logstash-plugin install /usr/local/githome/logstash-input-cos/logstash-input-cos-0.0.1-java.gem执行结果为:
Validating /usr/local/githome/logstash-input-cos/logstash-input-cos-0.0.1-java.gem
Installing logstash-input-cos
Installation successful另外,可以通过./bin/logstash-plugin list命令查看logstash已经安装的所有input/output/filter/codec插件。
生成配置文件cos.logstash.conf,内容为:
input {
cos {
"endpoint" => "cos.ap-guangzhou.myqcloud.com"
"access_key_id" => "*****"
"access_key_secret" => "****"
"bucket" => "******"
"region" => "ap-guangzhou"
"appId" => "**********"
"interval" => 60
}
}
output {
stdout {
codec=>rubydebug
}
}该配置文件使用腾讯云官网账号的secret_id和secret_key进行权限验证,拉取指定bucket里的数据,为了测试,将output设置为标准输出。
执行logstash:
./bin/logstash -f cos.logstash.conf输出结果为:
Sending Logstash's logs to /root/logstash-5.6.4/logs which is now configured via log4j2.properties
[2018-07-30T19:26:17,039][WARN ][logstash.runner ] --config.debug was specified, but log.level was not set to 'debug'! No config info will be logged.
[2018-07-30T19:26:17,048][INFO ][logstash.modules.scaffold] Initializing module {:module_name=>"netflow", :directory=>"/root/logstash-5.6.4/modules/netflow/configuration"}
[2018-07-30T19:26:17,049][INFO ][logstash.modules.scaffold] Initializing module {:module_name=>"fb_apache", :directory=>"/root/logstash-5.6.4/modules/fb_apache/configuration"}
[2018-07-30T19:26:17,252][INFO ][logstash.inputs.cos ] Using version 0.1.x input plugin 'cos'. This plugin isn't well supported by the community and likely has no maintainer.
[2018-07-30T19:26:17,341][INFO ][logstash.pipeline ] Starting pipeline {"id"=>"main", "pipeline.workers"=>4, "pipeline.batch.size"=>125, "pipeline.batch.delay"=>5, "pipeline.max_inflight"=>500}
[2018-07-30T19:26:17,362][INFO ][logstash.inputs.cos ] Registering cos input {:bucket=>"bellengao", :region=>"ap-guangzhou"}
[2018-07-30T19:26:17,528][INFO ][logstash.pipeline ] Pipeline main started
[2018-07-30T19:26:17,530][INFO ][logstash.inputs.cos ] Marker from:
log4j:WARN No appenders could be found for logger (org.apache.http.client.protocol.RequestAddCookies).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
[2018-07-30T19:26:17,574][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}
[2018-07-30T19:26:17,714][INFO ][logstash.inputs.cos ] Marker end: access.log
{
"message" => "77.179.66.156 - - [25/Oct/2016:14:49:33 +0200] \"GET / HTTP/1.1\" 200 612 \"-\" \"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.59 Safari/537.36\"",
"@version" => "1",
"@timestamp" => 2018-07-30T11:26:17.710Z
}
{
"message" => "77.179.66.156 - - [25/Oct/2016:14:49:34 +0200] \"GET /favicon.ico HTTP/1.1\" 404 571 \"http://localhost:8080/\" \"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.59 Safari/537.36\"",
"@version" => "1",
"@timestamp" => 2018-07-30T11:26:17.711Z
}在cos中的bucket里上传了名为access.log的nginx日志,上述输出结果中最后打印出来的每个json结构体构成一个event, 其中message消息即为access.log中每一条日志。
logstash作为一个数据管道中间件,支持对各种类型数据的采集与转换,并将数据发送到各种类型的存储库,比如实现消费kafka数据并且写入到Elasticsearch, 日志文件同步到对象存储S3等,mysql数据同步到Elasticsearch等。
logstash内部主要包含三个模块:
* input: 从数据源获取数据
* filter: 过滤、转换数据
* output: 输出数据
不同类型的数据都可以通过对应的input-plugin, output-plugin完成数据的输入与输出。如需要消费kafka中的数据并写入到Elasticsearch中,则需要使用logstash的kafka-input-plugin完成数据输入,logstash-output-elasticsearch完成数据输出。如果需要对输入数据进行过滤或者转换,比如根据关键词过滤掉不需要的内容,或者时间字段的格式转换,就需要又filter-plugin完成了。
logstash的input插件目前已经有几十种了,支持大多数比较通用或开源的数据源的输入。但如果公司内部开发的数据库或其它存储类的服务不能和开源产品在接口协议上兼容,比如腾讯自研的消息队列服务CMQ不依赖于其它的开源消息队列产品,所以不能直接使用logstash的logstash-input-kafka或logstash-input-rabbitmq同步CMQ中的数据;腾讯云对象存储服务COS, 在鉴权方式上和AWS的S3存在差异,也不能直接使用logstash-input-s3插件从COS中读取数据,对于这种情况,就需要自己开发logstash的input插件了。
本文以开发logstash的cos input插件为例,介绍如何开发logstash的input插件。
logstash官方提供了有个简单的input plugin example可供参考: https://github.com/logstash-plugins/logstash-input-example/
环境准备
logstash使用jruby开发,首先要配置jruby环境:
-
安装rvm:
rvm是一个ruby管理器,可以安装并管理ruby环境,也可以通过命令行切换到不同的ruby版本。
gpg --keyserver hkp://keys.gnupg.net --recv-keys 409B6B1796C275462A1703113804BB82D39DC0E3 7D2BAF1CF37B13E2069D6956105BD0E739499BDB\curl -sSL https://get.rvm.io | bash -s stablesource /etc/profile.d/rvm.sh -
安装jruby
rvm install jrubyrvm use jruby -
安装包管理工具bundle和测试工具rspec
gem install bundle gem install rspec
从example开始
-
clone logstash-input-example
git clone https://github.com/logstash-plugins/logstash-input-example.git -
将clone出来的logstash-input-example源码copy到logstash-input-cos目录,并删除.git文件夹,目的是以logstash-input-example的源码为参考进行开发,同时把需要改动名称的地方修改一下:
mv logstash-input-example.gemspec logstash-input-cos.gemspec mv lib/logstash/inputs/example.rb lib/logstash/inputs/cos.rb mv spec/inputs/example_spec.rb spec/inputs/cos_spec.rb - 建立的源码目录结构如图所示:
其中,重要文件的作用说明如下:
- cos.rb: 主文件,在该文件中编写logstash配置文件的读写与源数据获取的代码,需要继承LogStash::Inputs::Base基类
- cos_spec.rb: 单元测试文件,通过rspec可以对cos.rb中的代码进行测试
- logstash-input-cos.gemspec: 类似于maven中的pom.xml文件,配置工程的版本、名称、licene,包依赖等,通过bundle命令可以下载依赖包
配置并下载依赖
因为腾讯云COS服务没有ruby sdk, 因为只能依赖其Java sdk进行开发,首先添加对cos java sdk的依赖。在logstash-input-cos.gemspec中Gem dependencies配置栏中增加以下内容:
# Gem dependencies
s.requirements << "jar 'com.qcloud:cos_api', '5.4.4'"
s.add_runtime_dependency "logstash-core-plugin-api", ">= 1.60", "<= 2.99"
s.add_runtime_dependency 'logstash-codec-plain'
s.add_runtime_dependency 'stud', '>= 0.0.22'
s.add_runtime_dependency 'jar-dependencies'
s.add_development_dependency 'logstash-devutils', '1.3.6'相比logstash-input-example.gemspec,增加了对com.qcloud:cos_api包以及jar-dependencies包的依赖,jar-dependencies用于在ruby环境中管理jar包,并且可以跟踪jar包的加载状态。
然后,在logstash-input-cos.gemspec中增加配置:
s.platform = 'java'这样可以成功下载java依赖包,并且可以在ruby代码中直接调用java代码。
最后,执行以下命令下载依赖:
bundle install编写代码
logstash-input-cos的代码逻辑其实比较简单,主要是通过执行定时任务,调用cos java sdk中的listObjects方法,获取到指定bucket里的数据,并在每次定时任务执行结束后设置marker保存在本地,再次执行时从marker位置获取数据,以实现数据的增量同步。
jar包的引用
因为要调用cos java sdk中的代码,先引用该jar包:
require 'cos_api-5.4.4.jar'
java_import com.qcloud.cos.COSClient;
java_import com.qcloud.cos.ClientConfig;
java_import com.qcloud.cos.auth.BasicCOSCredentials;
java_import com.qcloud.cos.auth.COSCredentials;
java_import com.qcloud.cos.exception.CosClientException;
java_import com.qcloud.cos.exception.CosServiceException;
java_import com.qcloud.cos.model.COSObjectSummary;
java_import com.qcloud.cos.model.ListObjectsRequest;
java_import com.qcloud.cos.model.ObjectListing;
java_import com.qcloud.cos.region.Region;读取配置文件
logstash配置文件读取的代码如图所示:
config_name为cos,其它的配置项读取代码按照ruby的代码规范编写,添加类型校验与默认值,就可以从以下配置文件中读取配置项:
input {
cos {
"endpoint" => "cos.ap-guangzhou.myqcloud.com"
"access_key_id" => "*****"
"access_key_secret" => "****"
"bucket" => "******"
"region" => "ap-guangzhou"
"appId" => "**********"
"interval" => 60
}
}
output {
stdout {
codec=>rubydebug
}
}实现register方法
logstash input插件必须实现另个方法:register 和run
register方法类似于初始化方法,在该方法中可以直接使用从配置文件读取并赋值的变量,完成cos client的初始化,代码如下:
# 1 初始化用户身份信息(appid, secretId, secretKey)
cred = com.qcloud.cos.auth.BasicCOSCredentials.new(@access_key_id, @access_key_secret)
# 2 设置bucket的区域, COS地域的简称请参照 https://www.qcloud.com/document/product/436/6224
clientConfig = com.qcloud.cos.ClientConfig.new(com.qcloud.cos.region.Region.new(@region))
# 3 生成cos客户端
@cosclient = com.qcloud.cos.COSClient.new(cred, clientConfig)
# bucket名称, 需包含appid
bucketName = @bucket + "-"+ @appId
@bucketName = bucketName
@listObjectsRequest = com.qcloud.cos.model.ListObjectsRequest.new()
# 设置bucket名称
@listObjectsRequest.setBucketName(bucketName)
# prefix表示列出的object的key以prefix开始
@listObjectsRequest.setPrefix(@prefix)
# 设置最大遍历出多少个对象, 一次listobject最大支持1000
@listObjectsRequest.setMaxKeys(1000)
@listObjectsRequest.setMarker(@markerConfig.getMarker)示例代码中设置了@cosclient和@listObjectRequest为全局变量, 因为在run方法中会用到这两个变量。
注意在ruby中调用java代码的方式:没有变量描述符;不能直接new Object(),而只能Object.new().
实现run方法
run方法获取数据并将数据流转换成event事件
最简单的run方法为:
def run(queue)
Stud.interval(@interval) do
event = LogStash::Event.new("message" => @message, "host" => @host)
decorate(event)
queue << event
end # loop
end # def run代码说明:
- 通过Stud ruby模块执行定时任务,interval可自定义,从配置文件中读取
- 生成event, 示例代码生成了一个包含两个字段数据的event
- 调用decorate()方法, 给该event打上tag,如果配置的话
- queue<<event, 将event插入到数据管道中,发送给filter处理
logstash-input-cos的run方法实现为:
def run(queue)
@current_thread = Thread.current
Stud.interval(@interval) do
process(queue)
end
end
def process(queue)
@logger.info('Marker from: ' + @markerConfig.getMarker)
objectListing = @cosclient.listObjects(@listObjectsRequest)
nextMarker = objectListing.getNextMarker()
cosObjectSummaries = objectListing.getObjectSummaries()
cosObjectSummaries.each do |obj|
# 文件的路径key
key = obj.getKey()
if stop?
@logger.info("stop while attempting to read log file")
break
end
# 根据key获取内容
getObject(key) { |log|
# 发送消息
@codec.decode(log) do |event|
decorate(event)
queue << event
end
}
#记录 marker
@markerConfig.setMarker(key)
@logger.info('Marker end: ' + @markerConfig.getMarker)
end
end
# 获取下载输入流
def getObject(key, &block)
getObjectRequest = com.qcloud.cos.model.GetObjectRequest.new(@bucketName, key)
cosObject = @cosclient.getObject(getObjectRequest)
cosObjectInput = cosObject.getObjectContent()
buffered =BufferedReader.new(InputStreamReader.new(cosObjectInput))
while (line = buffered.readLine())
block.call(line)
end
end测试代码
在spec/inputs/cos_spec.rb中增加如下测试代码:
# encoding: utf-8
require "logstash/devutils/rspec/spec_helper"
require "logstash/inputs/cos"
describe LogStash::Inputs::Cos do
it_behaves_like "an interruptible input plugin" do
let(:config) { {
"endpoint" => 'cos.ap-guangzhou.myqcloud.com',
"access_key_id" => '*',
"access_key_secret" => '*',
"bucket" => '*',
"region" => 'ap-guangzhou',
"appId" => '*',
"interval" => 60 } }
end
end
rspec是一个ruby测试库,通过bundle命令执行rspec:
bundle exec rspec如果cos.rb中的代码没有语法或运行时错误,则会出现如果信息表明测试成功:
Finished in 0.8022 seconds (files took 3.45 seconds to load)
1 example, 0 failures构建并测试input-plugin-cos
build
使用gem对input-plugin-cos插件源码进行build:
gem build logstash-input-cos.gemspec构建完成后会生成一个名为logstash-input-cos-0.0.1-java.gem的文件
test
在logstash的解压目录下,执行一下命令安装logstash-input-cos plugin:
./bin/logstash-plugin install /usr/local/githome/logstash-input-cos/logstash-input-cos-0.0.1-java.gem执行结果为:
Validating /usr/local/githome/logstash-input-cos/logstash-input-cos-0.0.1-java.gem
Installing logstash-input-cos
Installation successful另外,可以通过./bin/logstash-plugin list命令查看logstash已经安装的所有input/output/filter/codec插件。
生成配置文件cos.logstash.conf,内容为:
input {
cos {
"endpoint" => "cos.ap-guangzhou.myqcloud.com"
"access_key_id" => "*****"
"access_key_secret" => "****"
"bucket" => "******"
"region" => "ap-guangzhou"
"appId" => "**********"
"interval" => 60
}
}
output {
stdout {
codec=>rubydebug
}
}该配置文件使用腾讯云官网账号的secret_id和secret_key进行权限验证,拉取指定bucket里的数据,为了测试,将output设置为标准输出。
执行logstash:
./bin/logstash -f cos.logstash.conf输出结果为:
Sending Logstash's logs to /root/logstash-5.6.4/logs which is now configured via log4j2.properties
[2018-07-30T19:26:17,039][WARN ][logstash.runner ] --config.debug was specified, but log.level was not set to 'debug'! No config info will be logged.
[2018-07-30T19:26:17,048][INFO ][logstash.modules.scaffold] Initializing module {:module_name=>"netflow", :directory=>"/root/logstash-5.6.4/modules/netflow/configuration"}
[2018-07-30T19:26:17,049][INFO ][logstash.modules.scaffold] Initializing module {:module_name=>"fb_apache", :directory=>"/root/logstash-5.6.4/modules/fb_apache/configuration"}
[2018-07-30T19:26:17,252][INFO ][logstash.inputs.cos ] Using version 0.1.x input plugin 'cos'. This plugin isn't well supported by the community and likely has no maintainer.
[2018-07-30T19:26:17,341][INFO ][logstash.pipeline ] Starting pipeline {"id"=>"main", "pipeline.workers"=>4, "pipeline.batch.size"=>125, "pipeline.batch.delay"=>5, "pipeline.max_inflight"=>500}
[2018-07-30T19:26:17,362][INFO ][logstash.inputs.cos ] Registering cos input {:bucket=>"bellengao", :region=>"ap-guangzhou"}
[2018-07-30T19:26:17,528][INFO ][logstash.pipeline ] Pipeline main started
[2018-07-30T19:26:17,530][INFO ][logstash.inputs.cos ] Marker from:
log4j:WARN No appenders could be found for logger (org.apache.http.client.protocol.RequestAddCookies).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
[2018-07-30T19:26:17,574][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}
[2018-07-30T19:26:17,714][INFO ][logstash.inputs.cos ] Marker end: access.log
{
"message" => "77.179.66.156 - - [25/Oct/2016:14:49:33 +0200] \"GET / HTTP/1.1\" 200 612 \"-\" \"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.59 Safari/537.36\"",
"@version" => "1",
"@timestamp" => 2018-07-30T11:26:17.710Z
}
{
"message" => "77.179.66.156 - - [25/Oct/2016:14:49:34 +0200] \"GET /favicon.ico HTTP/1.1\" 404 571 \"http://localhost:8080/\" \"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.59 Safari/537.36\"",
"@version" => "1",
"@timestamp" => 2018-07-30T11:26:17.711Z
}在cos中的bucket里上传了名为access.log的nginx日志,上述输出结果中最后打印出来的每个json结构体构成一个event, 其中message消息即为access.log中每一条日志。
收起阅读 »Day 10 - Elasticsearch 分片恢复并发数过大引发的bug分析
大家好,今天为大家分享一次 ES 的填坑经验。主要是关于集群恢复过程中,分片恢复并发数调整过大导致集群 hang 死的问题。
场景描述
废话不多说,先来描述场景。某日,腾讯云线上某 ES 集群,15个节点,2700+ 索引,15000+ 分片,数十 TB 数据。由于机器故障,某个节点被重启,此时集群有大量的 unassigned 分片,集群处于 yellow 状态。为了加快集群恢复的速度,手动调整分片恢复并发数,原本想将默认值为2的 node_concurrent_recoveries 调整为10,结果手一抖多加了一个0,设定了如下参数:
curl -X PUT "localhost:9200/_cluster/settings" -H 'Content-Type: application/json' -d'
{
"persistent": {
"cluster.routing.allocation.node_concurrent_recoveries": 100,
"indices.recovery.max_bytes_per_sec": "40mb"
}
}
'设定之后,观察集群 unassigned 分片,一开始下降的速度很快。大约几分钟后,数量维持在一个固定值不变了,然后,然后就没有然后了,集群所有节点 generic 线程池卡死,虽然已存在的索引读写没问题,但是新建索引以及所有涉及 generic 线程池的操作全部卡住。立马修改分片恢复并发数到10,通过管控平台一把重启了全部节点,约15分钟后集群恢复正常。接下来会先介绍一些基本的概念,然后再重现这个问题并做详细分析。
基本概念
ES 线程池(thread pool)
ES 中每个节点有多种线程池,各有用途。重要的有:
- generic :通用线程池,后台的 node discovery,上述的分片恢复(node recovery)等等一些通用后台的操作都会用到该线程池。该线程池线程数量默认为配置的处理器数量(processors)* 4,最小128,最大512。
- index :index/delete 等索引操作会用到该线程池,包括自动创建索引等。默认线程数量为配置的处理器数量,默认队列大小:200.
- search :查询请求处理线程池。默认线程数量:int((# of available_processors * 3) / 2) + 1,默认队列大小:1000.
- get :get 请求处理线程池。默认线程数量为配置的处理器数量,默认队列大小:1000.
- write :单个文档的 index/delete/update 以及 bulk 请求处理线程。默认线程数量为配置的处理器数量,默认队列大小:200,在写多的日志场景我们一般会将队列调大。 还有其它线程池,例如备份回档(snapshot)、analyze、refresh 等,这里就不一一介绍了。详细可参考官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-threadpool.html
集群恢复之分片恢复
我们知道 ES 集群状态分为三种,green、yellow、red。green 状态表示所有分片包括主副本均正常被分配;yellow 状态表示所有主分片已分配,但是有部分副本分片未分配;red 表示有部分主分片未分配。 一般当集群中某个节点因故障失联或者重启之后,如果集群索引有副本的场景,集群将进入分片恢复阶段(recovery)。此时一般是 master 节点发起更新集群元数据任务,分片的分配策略由 master 决定,具体分配策略可以参考腾讯云+社区的这篇文章了解细节:https://cloud.tencent.com/developer/article/1334743 。各节点收到集群元数据更新请求,检查分片状态并触发分片恢复流程,根据分片数据所在的位置,有多种恢复的方式,主要有以下几种:
- EXISTING_STORE : 数据在节点本地存在,从本地节点恢复。
- PEER :本地数据不可用或不存在,从远端节点(源分片,一般是主分片)恢复。
- SNAPSHOT : 数据从备份仓库恢复。
- LOCAL_SHARDS : 分片合并(shrink)场景,从本地别的分片恢复。
PEER 场景分片恢复并发数主要由如下参数控制:
- cluster.routing.allocation.node_concurrent_incoming_recoveries:节点上最大接受的分片恢复并发数。一般指分片从其它节点恢复至本节点。
- cluster.routing.allocation.node_concurrent_outgoing_recoveries :节点上最大发送的分片恢复并发数。一般指分片从本节点恢复至其它节点。
- cluster.routing.allocation.node_concurrent_recoveries :该参数同时设置上述接受发送分片恢复并发数为相同的值。 详细参数可参考官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/shards-allocation.html
集群卡住的主要原因就是从远端节点恢复(PEER Recovery)的并发数过多,导致 generic 线程池被用完。涉及目标节点(target)和源节点(source)的恢复交互流程,后面分析问题时我们再来详细讨论。
问题复现与剖析
为了便于描述,我用 ES 6.4.3版本重新搭建了一个三节点的集群。单节点 1 core,2GB memory。新建了300个 index, 单个 index 5个分片一个副本,共 3000 个 shard。每个 index 插入大约100条数据。 先设定分片恢复并发数,为了夸张一点,我直接调整到200,如下所示:
curl -X PUT "localhost:9200/_cluster/settings" -H 'Content-Type: application/json' -d'
{
"persistent": {
"cluster.routing.allocation.node_concurrent_recoveries": 200 // 设定分片恢复并发数
}
}
'接下来停掉某节点,模拟机器挂掉场景。几分钟后,观察集群分片恢复数量,卡在固定数值不再变化:

通过 allocation explain 查看分片分配状态,未分配的原因是受到最大恢复并发数的限制:


此时查询或写入已有索引不受影响,但是新建索引这种涉及到 generic 线程池的操作都会卡住。 通过堆栈分析,128 个 generic 线程全部卡在 PEER recovery 阶段。

当集群中有分片的状态发生变更时,master 节点会发起集群元数据更新(cluster state update)请求给所有节点。其它节点收到该请求后,感知到分片状态的变更,启动分片恢复流程。部分分片需要从其它节点恢复,代码层面,涉及分片分配的目标节点(target)和源节点(source)的交互流程如下:

6.x 版本之后引入了 seqNo,恢复会涉及到 seqNo+translog,这也是6.x提升恢复速度的一大改进。我们重点关注流程中第 2、4、5、7、10、12 步骤中的远程调用,他们的作用分别是:
- 第2步:分片分配的目标节点向源节点(一般是主分片)发起分片恢复请求,携带起始 seqNo 和 syncId。
- 第4步:发送数据文件信息,告知目标节点待接收的文件清单。
- 第5步:发送 diff 数据文件给目标节点。
- 第7步:源节点发送 prepare translog 请求给目标节点,等目标节点打开 shard level 引擎,准备接受 translog。
- 第10步:源节点发送指定范围的 translog 快照给目标节点。
- 第12步:结束恢复流程。
我们可以看到除第5步发送数据文件外,多次远程交互 submitRequest 都会调用 txGet,这个调用底层用的是基于 AQS 改造过的 sync 对象,是一个同步调用。 如果一端 generic 线程池被这些请求打满,发出的请求等待对端返回,而发出的这些请求由于对端 generic 线程池同样的原因被打满,只能 pending 在队列中,这样两边的线程池都满了而且相互等待对端队列中的线程返回,就出现了分布式死锁现象。
问题处理
为了避免改动太大带来不确定的 side effect,针对腾讯云 ES 集群我们目前先在 rest 层拒掉了并发数超过一定值的参数设定请求并提醒用户。与此同时,我们向官方提交了 issue:https://github.com/elastic/elasticsearch/issues/36195 进行跟踪。
总结
本文旨在描述集群恢复过程出现的集群卡死场景,避免更多的 ES 用户踩坑,没有对整体分片恢复做详细的分析,大家想了解详细的分片恢复流程可以参考腾讯云+社区 Elasticsearch 专栏相关的文章:https://cloud.tencent.com/developer/column/2428
完结,谢谢!
大家好,今天为大家分享一次 ES 的填坑经验。主要是关于集群恢复过程中,分片恢复并发数调整过大导致集群 hang 死的问题。
场景描述
废话不多说,先来描述场景。某日,腾讯云线上某 ES 集群,15个节点,2700+ 索引,15000+ 分片,数十 TB 数据。由于机器故障,某个节点被重启,此时集群有大量的 unassigned 分片,集群处于 yellow 状态。为了加快集群恢复的速度,手动调整分片恢复并发数,原本想将默认值为2的 node_concurrent_recoveries 调整为10,结果手一抖多加了一个0,设定了如下参数:
curl -X PUT "localhost:9200/_cluster/settings" -H 'Content-Type: application/json' -d'
{
"persistent": {
"cluster.routing.allocation.node_concurrent_recoveries": 100,
"indices.recovery.max_bytes_per_sec": "40mb"
}
}
'设定之后,观察集群 unassigned 分片,一开始下降的速度很快。大约几分钟后,数量维持在一个固定值不变了,然后,然后就没有然后了,集群所有节点 generic 线程池卡死,虽然已存在的索引读写没问题,但是新建索引以及所有涉及 generic 线程池的操作全部卡住。立马修改分片恢复并发数到10,通过管控平台一把重启了全部节点,约15分钟后集群恢复正常。接下来会先介绍一些基本的概念,然后再重现这个问题并做详细分析。
基本概念
ES 线程池(thread pool)
ES 中每个节点有多种线程池,各有用途。重要的有:
- generic :通用线程池,后台的 node discovery,上述的分片恢复(node recovery)等等一些通用后台的操作都会用到该线程池。该线程池线程数量默认为配置的处理器数量(processors)* 4,最小128,最大512。
- index :index/delete 等索引操作会用到该线程池,包括自动创建索引等。默认线程数量为配置的处理器数量,默认队列大小:200.
- search :查询请求处理线程池。默认线程数量:int((# of available_processors * 3) / 2) + 1,默认队列大小:1000.
- get :get 请求处理线程池。默认线程数量为配置的处理器数量,默认队列大小:1000.
- write :单个文档的 index/delete/update 以及 bulk 请求处理线程。默认线程数量为配置的处理器数量,默认队列大小:200,在写多的日志场景我们一般会将队列调大。 还有其它线程池,例如备份回档(snapshot)、analyze、refresh 等,这里就不一一介绍了。详细可参考官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-threadpool.html
集群恢复之分片恢复
我们知道 ES 集群状态分为三种,green、yellow、red。green 状态表示所有分片包括主副本均正常被分配;yellow 状态表示所有主分片已分配,但是有部分副本分片未分配;red 表示有部分主分片未分配。 一般当集群中某个节点因故障失联或者重启之后,如果集群索引有副本的场景,集群将进入分片恢复阶段(recovery)。此时一般是 master 节点发起更新集群元数据任务,分片的分配策略由 master 决定,具体分配策略可以参考腾讯云+社区的这篇文章了解细节:https://cloud.tencent.com/developer/article/1334743 。各节点收到集群元数据更新请求,检查分片状态并触发分片恢复流程,根据分片数据所在的位置,有多种恢复的方式,主要有以下几种:
- EXISTING_STORE : 数据在节点本地存在,从本地节点恢复。
- PEER :本地数据不可用或不存在,从远端节点(源分片,一般是主分片)恢复。
- SNAPSHOT : 数据从备份仓库恢复。
- LOCAL_SHARDS : 分片合并(shrink)场景,从本地别的分片恢复。
PEER 场景分片恢复并发数主要由如下参数控制:
- cluster.routing.allocation.node_concurrent_incoming_recoveries:节点上最大接受的分片恢复并发数。一般指分片从其它节点恢复至本节点。
- cluster.routing.allocation.node_concurrent_outgoing_recoveries :节点上最大发送的分片恢复并发数。一般指分片从本节点恢复至其它节点。
- cluster.routing.allocation.node_concurrent_recoveries :该参数同时设置上述接受发送分片恢复并发数为相同的值。 详细参数可参考官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/shards-allocation.html
集群卡住的主要原因就是从远端节点恢复(PEER Recovery)的并发数过多,导致 generic 线程池被用完。涉及目标节点(target)和源节点(source)的恢复交互流程,后面分析问题时我们再来详细讨论。
问题复现与剖析
为了便于描述,我用 ES 6.4.3版本重新搭建了一个三节点的集群。单节点 1 core,2GB memory。新建了300个 index, 单个 index 5个分片一个副本,共 3000 个 shard。每个 index 插入大约100条数据。 先设定分片恢复并发数,为了夸张一点,我直接调整到200,如下所示:
curl -X PUT "localhost:9200/_cluster/settings" -H 'Content-Type: application/json' -d'
{
"persistent": {
"cluster.routing.allocation.node_concurrent_recoveries": 200 // 设定分片恢复并发数
}
}
'接下来停掉某节点,模拟机器挂掉场景。几分钟后,观察集群分片恢复数量,卡在固定数值不再变化:
通过 allocation explain 查看分片分配状态,未分配的原因是受到最大恢复并发数的限制:
此时查询或写入已有索引不受影响,但是新建索引这种涉及到 generic 线程池的操作都会卡住。 通过堆栈分析,128 个 generic 线程全部卡在 PEER recovery 阶段。
当集群中有分片的状态发生变更时,master 节点会发起集群元数据更新(cluster state update)请求给所有节点。其它节点收到该请求后,感知到分片状态的变更,启动分片恢复流程。部分分片需要从其它节点恢复,代码层面,涉及分片分配的目标节点(target)和源节点(source)的交互流程如下:
6.x 版本之后引入了 seqNo,恢复会涉及到 seqNo+translog,这也是6.x提升恢复速度的一大改进。我们重点关注流程中第 2、4、5、7、10、12 步骤中的远程调用,他们的作用分别是:
- 第2步:分片分配的目标节点向源节点(一般是主分片)发起分片恢复请求,携带起始 seqNo 和 syncId。
- 第4步:发送数据文件信息,告知目标节点待接收的文件清单。
- 第5步:发送 diff 数据文件给目标节点。
- 第7步:源节点发送 prepare translog 请求给目标节点,等目标节点打开 shard level 引擎,准备接受 translog。
- 第10步:源节点发送指定范围的 translog 快照给目标节点。
- 第12步:结束恢复流程。
我们可以看到除第5步发送数据文件外,多次远程交互 submitRequest 都会调用 txGet,这个调用底层用的是基于 AQS 改造过的 sync 对象,是一个同步调用。 如果一端 generic 线程池被这些请求打满,发出的请求等待对端返回,而发出的这些请求由于对端 generic 线程池同样的原因被打满,只能 pending 在队列中,这样两边的线程池都满了而且相互等待对端队列中的线程返回,就出现了分布式死锁现象。
问题处理
为了避免改动太大带来不确定的 side effect,针对腾讯云 ES 集群我们目前先在 rest 层拒掉了并发数超过一定值的参数设定请求并提醒用户。与此同时,我们向官方提交了 issue:https://github.com/elastic/elasticsearch/issues/36195 进行跟踪。
总结
本文旨在描述集群恢复过程出现的集群卡死场景,避免更多的 ES 用户踩坑,没有对整体分片恢复做详细的分析,大家想了解详细的分片恢复流程可以参考腾讯云+社区 Elasticsearch 专栏相关的文章:https://cloud.tencent.com/developer/column/2428
完结,谢谢!
收起阅读 »社区日报 第474期 (2018-12-10)
http://t.cn/Ey1omYc
2. Es 另外一款web管理UI,包含导入,查看,编辑等功能
http://t.cn/Ey1dKAj
3. 使用elasticseach 搜索emoji表情
http://t.cn/Rf5r848
编辑:cyberdak
归档:https://elasticsearch.cn/article/6183
订阅:https://tinyletter.com/elastic-daily
http://t.cn/Ey1omYc
2. Es 另外一款web管理UI,包含导入,查看,编辑等功能
http://t.cn/Ey1dKAj
3. 使用elasticseach 搜索emoji表情
http://t.cn/Rf5r848
编辑:cyberdak
归档:https://elasticsearch.cn/article/6183
订阅:https://tinyletter.com/elastic-daily 收起阅读 »
Day 9 - 动手实现一个自定义beat
参考
https://elasticsearch.cn/article/113
https://www.elastic.co/blog/build-your-own-beat
介绍
公司内部有统一的log收集系统,并且实现了定制的filebeat进行log收集。为了实现实时报警和监控,自定义的beat并没有直接把输出发给elasticsearch后端,而是中间会经过storm或者durid进行实时分析,然后落入es或者hdfs。同时由于是统一log收集,所以目前还没有针对具体的不同应用进行log的内容的切分,导致所有的log都是以一行为单位落入后端存储。于是需要针对不同的业务部门定制不同的beat。 本文初步尝试定制一个可以在beat端解析hdfs audit log的beat,限于篇幅,只实现了基本的文件解析功能。下面会从环境配置,代码实现,运行测试三个方面进行讲解。
环境配置
go version go1.9.4 linux/amd64
python version: 2.7.9
不得不吐槽下python的安装,各种坑。因为系统默认的python版本是2.7.5,而cookiecutter建议使用2.7.9
下面的工具会提供python本身需要依赖的一些native包
yum install openssl -y
yum install openssl-devel -y
yum install zlib-devel -y
yum install zlib -y安装python
wget https://www.python.org/ftp/python/2.7.9/Python-2.7.9.tgz
tar -zxvf Python-2.7.9.tgz
cd ~/python/Python-2.7.9
./configure --prefix=/usr/local/python-2.7.9
make
make install
rm -f /bin/python
ln -s /usr/local/python-2.7.9/bin/python /bin/python安装工具包 distribute, setuptools, pip
cd ~/python/setuptools-19.6 && python setup.py install
cd ~/python/pip-1.5.4 && python setup.py install
cd ~/python/distribute-0.7.3 && python setup.py install安装cookiecutter
pip install --user cookiecutter安装cookiecutter所依赖的工具
pip install backports.functools-lru-cache
pip install six
pip install virtualenv*** virtualenv 安装好了之后,所在目录是在python的目录里面 (/usr/local/python-2.7.9/bin/virtualenv),需要配置好PATH,这个工具稍后会被beat的Makefile用到
代码实现
需要实现的功能比较简单,目标是打开hdfs-audit.log文件,然后逐行读取,同时解析出必要的信息,组装成event,然后发送出去,如果对接的es的话,需要同时支持自动在es端创建正确的mapping
使用官方提供的beat模板创建自己的beat
- 需要设置好环境变量$GOPATH,本例子中GOPATH=/root/go
$ go get github.com/elastic/beats
$ cd $GOPATH/src/github.com/elastic/beats
$ git checkout 5.1
[root@minikube-2830379 suxingfate]# cookiecutter /root/go/src/github.com/elastic/beats/generate/beat
project_name [Examplebeat]: hdfsauditbeat
github_name [your-github-name]: suxingfate
beat [hdfsauditbeat]:
beat_path [github.com/suxingfate]:
full_name [Firstname Lastname]: xinglong
make setup到这里,模板就生成了,然后就是定制需要的东西。
- 1 _meta/beat.yml # 配置模板文件,定义我们的beat会接受哪些配置项
- 2 config/config.go #使用go的struct定义整个config对象,包含所有的配置项
- 3 beater/hdfsauditbeat.go # 核心逻辑代码
- 4 _meta/fields.yml #这里是跟es对接的时候给es定义的mapping
1 _meta/beat.yml
这里增加了path,为后面配置hdfs-audit.log文件的位置留好坑
[root@minikube-2830379 hdfsauditbeat]# cat _meta/beat.yml
################### Hdfsauditbeat Configuration Example #########################
############################# Hdfsauditbeat ######################################
hdfsauditbeat:
# Defines how often an event is sent to the output
period: 1s
path: "."2 config/config.go
这里把path定义到struct里面,后面核心代码就可以从config对象获得path了
[root@minikube-2830379 hdfsauditbeat]# cat config/config.go
// Config is put into a different package to prevent cyclic imports in case
// it is needed in several locations
package config
import "time"
type Config struct {
Period time.Duration `config:"period"`
Path string `config:"path"`
}
var DefaultConfig = Config{
Period: 1 * time.Second,
Path: ".",
}3 beater/hdfsauditbeat.go
这里需要改动的地方是: 3.1 定义了一个catAudit函数来解析目标文件的每一行,同时生成自定义的event,然后发送出去 3.2 Run函数调用自定义的catAudit函数,从而把我们的功能嵌入
[root@minikube-2830379 hdfsauditbeat]# cat beater/hdfsauditbeat.go
package beater
import (
"fmt"
"time"
"os"
"io"
"bufio"
"strings"
"github.com/elastic/beats/libbeat/beat"
"github.com/elastic/beats/libbeat/common"
"github.com/elastic/beats/libbeat/logp"
"github.com/elastic/beats/libbeat/publisher"
"github.com/suxingfate/hdfsauditbeat/config"
)
type Hdfsauditbeat struct {
done chan struct{}
config config.Config
client publisher.Client
}
// Creates beater
func New(b *beat.Beat, cfg *common.Config) (beat.Beater, error) {
config := config.DefaultConfig
if err := cfg.Unpack(&config); err != nil {
return nil, fmt.Errorf("Error reading config file: %v", err)
}
bt := &Hdfsauditbeat{
done: make(chan struct{}),
config: config,
}
return bt, nil
}
func (bt *Hdfsauditbeat) Run(b *beat.Beat) error {
logp.Info("hdfsauditbeat is running! Hit CTRL-C to stop it.")
bt.client = b.Publisher.Connect()
ticker := time.NewTicker(bt.config.Period)
counter := 1
for {
select {
case <-bt.done:
return nil
case <-ticker.C:
}
bt.catAudit(bt.config.Path)
logp.Info("Event sent")
counter++
}
}
func (bt *Hdfsauditbeat) Stop() {
bt.client.Close()
close(bt.done)
}
func (bt *Hdfsauditbeat) catAudit(auditFile string) {
file, err := os.OpenFile(auditFile, os.O_RDWR, 0666)
if err != nil {
//fmt.Println("Open file error!", err)
return
}
defer file.Close()
buf := bufio.NewReader(file)
for {
line, err := buf.ReadString('\n')
line = strings.TrimSpace(line)
if line == "" {
return
}
timeEnd := strings.Index(line, ",")
timeString := line[0 :timeEnd]
tm, _ := time.Parse("2006-01-02 03:04:05", timeString)
ugiStart := strings.Index(line, "ugi=") + 4
ugiEnd := strings.Index(line, " (auth")
ugi := line[ugiStart :ugiEnd]
cmdStart := strings.Index(line, "cmd=") + 4
line = line[cmdStart:len(line)]
cmdEnd := strings.Index(line, " ")
cmd := line[0 : cmdEnd]
srcStart := strings.Index(line, "src=") + 4
line = line[srcStart:len(line)]
srcEnd := strings.Index(line, " ")
src := line[0:srcEnd]
dstStart := strings.Index(line, "dst=") + 4
line = line[dstStart:len(line)]
dstEnd := strings.Index(line, " ")
dst := line[0:dstEnd]
event := common.MapStr{
"@timestamp": common.Time(time.Unix(tm.Unix(), 0)),
"ugi": ugi,
"cmd": cmd,
"src": src,
"dst": dst,
}
bt.client.PublishEvent(event)
if err != nil {
if err == io.EOF {
//fmt.Println("File read ok!")
break
} else {
//fmt.Println("Read file error!", err)
return
}
}
}
}
4 _meat/fields.yml
[root@minikube-2830379 hdfsauditbeat]# less _meta/fields.yml
- key: hdfsauditbeat
title: hdfsauditbeat
description:
fields:
- name: counter
type: long
required: true
description: >
PLEASE UPDATE DOCUMENTATION
#new fiels added hdfsaudit
- name: entrytime
type: date
- name: ugi
type: keyword
- name: cmd
type: keyword
- name: src
type: keyword
- name: dst
type: keyword测试
首先编译好项目
make update
make然后会发现生成了一个hdfsauditbeat文件,这个就是二进制的可执行文件。下面进行测试,这里偷了个懒,没有发给es,而是吐到console进行观察。 修改了一下配置文件,需要指定正确的需要消费的audit log文件的路径,另外就是修改了output为console
[root@minikube-2830379 hdfsauditbeat]# cat hdfsauditbeat.yml
################### Hdfsauditbeat Configuration Example #########################
############################# Hdfsauditbeat ######################################
hdfsauditbeat:
# Defines how often an event is sent to the output
period: 1s
path: "/root/go/hdfs-audit.log"
#================================ General =====================================
# The name of the shipper that publishes the network data. It can be used to group
# all the transactions sent by a single shipper in the web interface.
#name:
# The tags of the shipper are included in their own field with each
# transaction published.
#tags: ["service-X", "web-tier"]
# Optional fields that you can specify to add additional information to the
# output.
#fields:
# env: staging
#================================ Outputs =====================================
# Configure what outputs to use when sending the data collected by the beat.
# Multiple outputs may be used.
#-------------------------- Elasticsearch output ------------------------------
#output.elasticsearch:
# Array of hosts to connect to.
# hosts: ["localhost:9200"]
# Optional protocol and basic auth credentials.
#protocol: "https"
#username: "elastic"
#password: "changeme"
#----------------------------- Logstash output --------------------------------
#output.logstash:
# The Logstash hosts
#hosts: ["localhost:5044"]
# Optional SSL. By default is off.
# List of root certificates for HTTPS server verifications
#ssl.certificate_authorities: ["/etc/pki/root/ca.pem"]
# Certificate for SSL client authentication
#ssl.certificate: "/etc/pki/client/cert.pem"
# Client Certificate Key
#ssl.key: "/etc/pki/client/cert.key"
output.console:
pretty: true
#================================ Logging =====================================
# Sets log level. The default log level is info.
# Available log levels are: critical, error, warning, info, debug
#logging.level: debug
# At debug level, you can selectively enable logging only for some components.
# To enable all selectors use ["*"]. Examples of other selectors are "beat",
# "publish", "service".
#logging.selectors: ["*"]开始执行
[root@minikube-2830379 hdfsauditbeat]# ./hdfsauditbeat
{
"@timestamp": "2018-12-09T03:00:00.000Z",
"beat": {
"hostname": "minikube-2830379.lvs02.dev.abc.com",
"name": "minikube-2830379.lvs02.dev.abc.com",
"version": "5.1.3"
},
"cmd": "create",
"dst": "null",
"src": "/app-logs/app/logs/application_1540949675029_717305/lvsdpehdc25dn0444.stratus.lvs.abc.com_8042.tmp",
"ugi": "appmon@APD.ABC.COM"
}
{
"@timestamp": "2018-12-09T03:00:00.000Z",
"beat": {
"hostname": "minikube-2830379.lvs02.dev.abc.com",
"name": "minikube-2830379.lvs02.dev.abc.com",
"version": "5.1.3"
},
"cmd": "create",
"dst": "null",
"src": "/app-logs/appmon/logs/application_1540949675029_717305/lvsdpehdc25dn0444.stratus.lvs.abc.com_8042.tmp",
"ugi": "appmon@APD.ABC.COM"
}结束
使用自定义beat给我们提供了很大的灵活性,虽然pipline或者logstash也可以做到,但是使用场景还是有很大差别的。如果是调用特殊的命令获得输出,或者是本文的场景都更适合定制化beat。
参考
https://elasticsearch.cn/article/113
https://www.elastic.co/blog/build-your-own-beat
介绍
公司内部有统一的log收集系统,并且实现了定制的filebeat进行log收集。为了实现实时报警和监控,自定义的beat并没有直接把输出发给elasticsearch后端,而是中间会经过storm或者durid进行实时分析,然后落入es或者hdfs。同时由于是统一log收集,所以目前还没有针对具体的不同应用进行log的内容的切分,导致所有的log都是以一行为单位落入后端存储。于是需要针对不同的业务部门定制不同的beat。 本文初步尝试定制一个可以在beat端解析hdfs audit log的beat,限于篇幅,只实现了基本的文件解析功能。下面会从环境配置,代码实现,运行测试三个方面进行讲解。
环境配置
go version go1.9.4 linux/amd64
python version: 2.7.9
不得不吐槽下python的安装,各种坑。因为系统默认的python版本是2.7.5,而cookiecutter建议使用2.7.9
下面的工具会提供python本身需要依赖的一些native包
yum install openssl -y
yum install openssl-devel -y
yum install zlib-devel -y
yum install zlib -y安装python
wget https://www.python.org/ftp/python/2.7.9/Python-2.7.9.tgz
tar -zxvf Python-2.7.9.tgz
cd ~/python/Python-2.7.9
./configure --prefix=/usr/local/python-2.7.9
make
make install
rm -f /bin/python
ln -s /usr/local/python-2.7.9/bin/python /bin/python安装工具包 distribute, setuptools, pip
cd ~/python/setuptools-19.6 && python setup.py install
cd ~/python/pip-1.5.4 && python setup.py install
cd ~/python/distribute-0.7.3 && python setup.py install安装cookiecutter
pip install --user cookiecutter安装cookiecutter所依赖的工具
pip install backports.functools-lru-cache
pip install six
pip install virtualenv*** virtualenv 安装好了之后,所在目录是在python的目录里面 (/usr/local/python-2.7.9/bin/virtualenv),需要配置好PATH,这个工具稍后会被beat的Makefile用到
代码实现
需要实现的功能比较简单,目标是打开hdfs-audit.log文件,然后逐行读取,同时解析出必要的信息,组装成event,然后发送出去,如果对接的es的话,需要同时支持自动在es端创建正确的mapping
使用官方提供的beat模板创建自己的beat
- 需要设置好环境变量$GOPATH,本例子中GOPATH=/root/go
$ go get github.com/elastic/beats
$ cd $GOPATH/src/github.com/elastic/beats
$ git checkout 5.1
[root@minikube-2830379 suxingfate]# cookiecutter /root/go/src/github.com/elastic/beats/generate/beat
project_name [Examplebeat]: hdfsauditbeat
github_name [your-github-name]: suxingfate
beat [hdfsauditbeat]:
beat_path [github.com/suxingfate]:
full_name [Firstname Lastname]: xinglong
make setup到这里,模板就生成了,然后就是定制需要的东西。
- 1 _meta/beat.yml # 配置模板文件,定义我们的beat会接受哪些配置项
- 2 config/config.go #使用go的struct定义整个config对象,包含所有的配置项
- 3 beater/hdfsauditbeat.go # 核心逻辑代码
- 4 _meta/fields.yml #这里是跟es对接的时候给es定义的mapping
1 _meta/beat.yml
这里增加了path,为后面配置hdfs-audit.log文件的位置留好坑
[root@minikube-2830379 hdfsauditbeat]# cat _meta/beat.yml
################### Hdfsauditbeat Configuration Example #########################
############################# Hdfsauditbeat ######################################
hdfsauditbeat:
# Defines how often an event is sent to the output
period: 1s
path: "."2 config/config.go
这里把path定义到struct里面,后面核心代码就可以从config对象获得path了
[root@minikube-2830379 hdfsauditbeat]# cat config/config.go
// Config is put into a different package to prevent cyclic imports in case
// it is needed in several locations
package config
import "time"
type Config struct {
Period time.Duration `config:"period"`
Path string `config:"path"`
}
var DefaultConfig = Config{
Period: 1 * time.Second,
Path: ".",
}3 beater/hdfsauditbeat.go
这里需要改动的地方是: 3.1 定义了一个catAudit函数来解析目标文件的每一行,同时生成自定义的event,然后发送出去 3.2 Run函数调用自定义的catAudit函数,从而把我们的功能嵌入
[root@minikube-2830379 hdfsauditbeat]# cat beater/hdfsauditbeat.go
package beater
import (
"fmt"
"time"
"os"
"io"
"bufio"
"strings"
"github.com/elastic/beats/libbeat/beat"
"github.com/elastic/beats/libbeat/common"
"github.com/elastic/beats/libbeat/logp"
"github.com/elastic/beats/libbeat/publisher"
"github.com/suxingfate/hdfsauditbeat/config"
)
type Hdfsauditbeat struct {
done chan struct{}
config config.Config
client publisher.Client
}
// Creates beater
func New(b *beat.Beat, cfg *common.Config) (beat.Beater, error) {
config := config.DefaultConfig
if err := cfg.Unpack(&config); err != nil {
return nil, fmt.Errorf("Error reading config file: %v", err)
}
bt := &Hdfsauditbeat{
done: make(chan struct{}),
config: config,
}
return bt, nil
}
func (bt *Hdfsauditbeat) Run(b *beat.Beat) error {
logp.Info("hdfsauditbeat is running! Hit CTRL-C to stop it.")
bt.client = b.Publisher.Connect()
ticker := time.NewTicker(bt.config.Period)
counter := 1
for {
select {
case <-bt.done:
return nil
case <-ticker.C:
}
bt.catAudit(bt.config.Path)
logp.Info("Event sent")
counter++
}
}
func (bt *Hdfsauditbeat) Stop() {
bt.client.Close()
close(bt.done)
}
func (bt *Hdfsauditbeat) catAudit(auditFile string) {
file, err := os.OpenFile(auditFile, os.O_RDWR, 0666)
if err != nil {
//fmt.Println("Open file error!", err)
return
}
defer file.Close()
buf := bufio.NewReader(file)
for {
line, err := buf.ReadString('\n')
line = strings.TrimSpace(line)
if line == "" {
return
}
timeEnd := strings.Index(line, ",")
timeString := line[0 :timeEnd]
tm, _ := time.Parse("2006-01-02 03:04:05", timeString)
ugiStart := strings.Index(line, "ugi=") + 4
ugiEnd := strings.Index(line, " (auth")
ugi := line[ugiStart :ugiEnd]
cmdStart := strings.Index(line, "cmd=") + 4
line = line[cmdStart:len(line)]
cmdEnd := strings.Index(line, " ")
cmd := line[0 : cmdEnd]
srcStart := strings.Index(line, "src=") + 4
line = line[srcStart:len(line)]
srcEnd := strings.Index(line, " ")
src := line[0:srcEnd]
dstStart := strings.Index(line, "dst=") + 4
line = line[dstStart:len(line)]
dstEnd := strings.Index(line, " ")
dst := line[0:dstEnd]
event := common.MapStr{
"@timestamp": common.Time(time.Unix(tm.Unix(), 0)),
"ugi": ugi,
"cmd": cmd,
"src": src,
"dst": dst,
}
bt.client.PublishEvent(event)
if err != nil {
if err == io.EOF {
//fmt.Println("File read ok!")
break
} else {
//fmt.Println("Read file error!", err)
return
}
}
}
}
4 _meat/fields.yml
[root@minikube-2830379 hdfsauditbeat]# less _meta/fields.yml
- key: hdfsauditbeat
title: hdfsauditbeat
description:
fields:
- name: counter
type: long
required: true
description: >
PLEASE UPDATE DOCUMENTATION
#new fiels added hdfsaudit
- name: entrytime
type: date
- name: ugi
type: keyword
- name: cmd
type: keyword
- name: src
type: keyword
- name: dst
type: keyword测试
首先编译好项目
make update
make然后会发现生成了一个hdfsauditbeat文件,这个就是二进制的可执行文件。下面进行测试,这里偷了个懒,没有发给es,而是吐到console进行观察。 修改了一下配置文件,需要指定正确的需要消费的audit log文件的路径,另外就是修改了output为console
[root@minikube-2830379 hdfsauditbeat]# cat hdfsauditbeat.yml
################### Hdfsauditbeat Configuration Example #########################
############################# Hdfsauditbeat ######################################
hdfsauditbeat:
# Defines how often an event is sent to the output
period: 1s
path: "/root/go/hdfs-audit.log"
#================================ General =====================================
# The name of the shipper that publishes the network data. It can be used to group
# all the transactions sent by a single shipper in the web interface.
#name:
# The tags of the shipper are included in their own field with each
# transaction published.
#tags: ["service-X", "web-tier"]
# Optional fields that you can specify to add additional information to the
# output.
#fields:
# env: staging
#================================ Outputs =====================================
# Configure what outputs to use when sending the data collected by the beat.
# Multiple outputs may be used.
#-------------------------- Elasticsearch output ------------------------------
#output.elasticsearch:
# Array of hosts to connect to.
# hosts: ["localhost:9200"]
# Optional protocol and basic auth credentials.
#protocol: "https"
#username: "elastic"
#password: "changeme"
#----------------------------- Logstash output --------------------------------
#output.logstash:
# The Logstash hosts
#hosts: ["localhost:5044"]
# Optional SSL. By default is off.
# List of root certificates for HTTPS server verifications
#ssl.certificate_authorities: ["/etc/pki/root/ca.pem"]
# Certificate for SSL client authentication
#ssl.certificate: "/etc/pki/client/cert.pem"
# Client Certificate Key
#ssl.key: "/etc/pki/client/cert.key"
output.console:
pretty: true
#================================ Logging =====================================
# Sets log level. The default log level is info.
# Available log levels are: critical, error, warning, info, debug
#logging.level: debug
# At debug level, you can selectively enable logging only for some components.
# To enable all selectors use ["*"]. Examples of other selectors are "beat",
# "publish", "service".
#logging.selectors: ["*"]开始执行
[root@minikube-2830379 hdfsauditbeat]# ./hdfsauditbeat
{
"@timestamp": "2018-12-09T03:00:00.000Z",
"beat": {
"hostname": "minikube-2830379.lvs02.dev.abc.com",
"name": "minikube-2830379.lvs02.dev.abc.com",
"version": "5.1.3"
},
"cmd": "create",
"dst": "null",
"src": "/app-logs/app/logs/application_1540949675029_717305/lvsdpehdc25dn0444.stratus.lvs.abc.com_8042.tmp",
"ugi": "appmon@APD.ABC.COM"
}
{
"@timestamp": "2018-12-09T03:00:00.000Z",
"beat": {
"hostname": "minikube-2830379.lvs02.dev.abc.com",
"name": "minikube-2830379.lvs02.dev.abc.com",
"version": "5.1.3"
},
"cmd": "create",
"dst": "null",
"src": "/app-logs/appmon/logs/application_1540949675029_717305/lvsdpehdc25dn0444.stratus.lvs.abc.com_8042.tmp",
"ugi": "appmon@APD.ABC.COM"
}结束
使用自定义beat给我们提供了很大的灵活性,虽然pipline或者logstash也可以做到,但是使用场景还是有很大差别的。如果是调用特殊的命令获得输出,或者是本文的场景都更适合定制化beat。
收起阅读 »社区日报 第473期 (2018-12-09)
http://t.cn/EyEJZGO
2.(自备梯子)将full-scale ELK栈部署到Kubernetes。
http://t.cn/EyEiOtk
3.(自备梯子)Facebook建立在不平等的基础之上。
http://t.cn/EyE6quM
编辑:至尊宝
归档:https://elasticsearch.cn/article/6181
订阅:https://tinyletter.com/elastic-daily
http://t.cn/EyEJZGO
2.(自备梯子)将full-scale ELK栈部署到Kubernetes。
http://t.cn/EyEiOtk
3.(自备梯子)Facebook建立在不平等的基础之上。
http://t.cn/EyE6quM
编辑:至尊宝
归档:https://elasticsearch.cn/article/6181
订阅:https://tinyletter.com/elastic-daily 收起阅读 »


