

社区日报 第454期 (2018-11-20)
http://t.cn/E20PA5a
2、GitLab 11.5 将支持 Elasticsearch 6,放弃支持5.5。
http://t.cn/E20Pq9j
3、ElasticSearch搜索之布尔和聚合。
http://t.cn/E20PxFB
编辑:叮咚光军
归档:https://elasticsearch.cn/article/6148
订阅:https://tinyletter.com/elastic-daily
http://t.cn/E20PA5a
2、GitLab 11.5 将支持 Elasticsearch 6,放弃支持5.5。
http://t.cn/E20Pq9j
3、ElasticSearch搜索之布尔和聚合。
http://t.cn/E20PxFB
编辑:叮咚光军
归档:https://elasticsearch.cn/article/6148
订阅:https://tinyletter.com/elastic-daily 收起阅读 »
腾讯云Elasticsearch团队招聘高级后台开发工程师 base深圳
Elasticsearch相关产品的新功能设计、开发、运营和维护工作;
跟进研究业界前沿技术,推动产品技术升级。
岗位要求:
编程能力扎实,熟悉Java/C++中的一种,具有良好的数据结构、算法、操作系统等计算机基本知识;
熟悉ElasticSearch/Lucene开源系统,有实际开发经验者优先;
熟悉Hadoop、HBase、InfluxDB等开源系统,有云计算相关开发经验者优先;
具有敏捷开发、完整产品生命周期开发者优先;
学习能力强,善于独立思考,思维活跃,对技术有强烈激情。
请发简历至:360608805@qq.com
Elasticsearch相关产品的新功能设计、开发、运营和维护工作;
跟进研究业界前沿技术,推动产品技术升级。
岗位要求:
编程能力扎实,熟悉Java/C++中的一种,具有良好的数据结构、算法、操作系统等计算机基本知识;
熟悉ElasticSearch/Lucene开源系统,有实际开发经验者优先;
熟悉Hadoop、HBase、InfluxDB等开源系统,有云计算相关开发经验者优先;
具有敏捷开发、完整产品生命周期开发者优先;
学习能力强,善于独立思考,思维活跃,对技术有强烈激情。
请发简历至:360608805@qq.com
收起阅读 »
社区日报 第453期 (2018-11-19)
http://t.cn/E2aQmeA
2. 如何租到靠谱的房子?Scrapy爬虫帮你一网打尽各平台租房信息!
http://t.cn/E2a8AoX
3. 理解elasticsearch的parent-child关系
http://t.cn/E2a89kd
编辑:cyberdak
归档:https://elasticsearch.cn/article/6146
订阅:https://tinyletter.com/elastic-daily
http://t.cn/E2aQmeA
2. 如何租到靠谱的房子?Scrapy爬虫帮你一网打尽各平台租房信息!
http://t.cn/E2a8AoX
3. 理解elasticsearch的parent-child关系
http://t.cn/E2a89kd
编辑:cyberdak
归档:https://elasticsearch.cn/article/6146
订阅:https://tinyletter.com/elastic-daily 收起阅读 »
海量科技股份有限公司ES中文插件
海量分词演示界面 http://www.hailiangxinxi.com/smartCenter2018/index
另外,海量提供免费API接口,文档详见http://www.hailiangxinxi.com/smartCenter2018/doc,欢迎大家试用,如有疑问,请联系nlp@hylanda.com
Analyzer: hlseg_search , hlseg_large , hlseg_normal, Tokenizer: hlseg_search , hlseg_large , hlseg_normal
github地址:https://github.com/HylandaOpen ... ME.md
海量分词演示界面 http://www.hailiangxinxi.com/smartCenter2018/index
另外,海量提供免费API接口,文档详见http://www.hailiangxinxi.com/smartCenter2018/doc,欢迎大家试用,如有疑问,请联系nlp@hylanda.com
Analyzer: hlseg_search , hlseg_large , hlseg_normal, Tokenizer: hlseg_search , hlseg_large , hlseg_normal
github地址:https://github.com/HylandaOpen ... ME.md 收起阅读 »
ET007 ElasticStack 6.5 介绍
就在 11月14日,ElasticStack 6.5.0 发布了,此次发布带来了许多激动人心的特性,我们一起来体验一下:

如果没有任何数据,kibana会提示我们导入sample数据,这边我选择Try our sample data, 然后导入全部3个样例数据,这可以让我们在没有数据的情况下快速体验新特性。
Infrastructure & Logs UI
很多用户使用 ElasticStack 收集基础架构的日志和指标,比如系统日志、安全日志、CPU指标,内存指标等等。在6.5中,kibana 侧边栏中增加了 Infrastructure 和 Logs 两个新的 tab,让用户更简单地查看自己的基础架构,和每台主机或者容器里的日志。
logs
进入logs标签页,如果当前没有数据,kibana会引导我们添加数据

我们选择 system logs

根据指示,我们安装部署好filebeat并启动,再次进入 logs 标签页便可以看到收集到的系统日志了

- 搜索过滤框:在这里可以像在 discover 里一样写query string,并且会有输入提示
- 时间选择框:可以选择需要查看的时间点,如果点了 Stream live,会持续监听尾部新输出的日志内容,类似 linux 命令中的tail -f
- 日志时间轴:高亮的部位是当前查看日志所在的时间范围,对应的区域图标识了日志量
假如我想实现 tail -f /var/log/system.log | grep google.com 一样的效果,可以打开 Stream live,并在搜索过滤框中这样输入:

很简单,很方便有木有?
Infrastructure
同样在kibana的引导下安装 Metric beat,并开启system模块,启动后进入 infrastructure 标签页:

这里可以直观地看到所有基础架构的指标状况,深色的内层代表主机,颜色代表了健康状况。浅灰色的外层代表了group,因为我只在自己的笔记本上做了部署,所以只能看到一个host。

点击主机会弹出菜单
- View logs : 跳转到 logs 标签页,并通过搜索过滤框指定host,只查看这台主机的日志。
- View metrics : 跳转到这台主机的指标详情,可以查看历史数据

APM
Java 和 Go
不负众望,继 Nodejs、Python、Ruby、Javascript 之后,Elastic APM 5.6.0 新增了对 Java 和 Golang 的支持!
Distributed Tracing
在 SOA 和 MSA 大行其道的年代,如何追踪请求在各个系统之间的流动成为了apm的关键问题。
Elastic APM 支持 OpenTracing 标准,并在各个agent里内置了 OpenTracing 兼容的bridge
以下是官网上该特性的截图:

APM Server 监控
如 ElasticStack的其他产品一般,APM也支持了监控,并可以在 Kinbana Montoring下查看监控信息:

APM Server 内存占用优化
通过新的基于NDJSON的协议,agent可以在采集信息后通过事件流立即发往APM server,这样 APM Server可以一个接一个地处理接收到的事件,而不是一次性地收到一大块(chunk),这样在很大程度上减少了APM Server的内存占用。
Elasticsearch
Cross-cluster replication
这里的副本并非我们平时常见的分片副本,而是通过在集群B配置一个副本indexB来追随集群A中的indexA,indexA中发生的任何变化都会同步到indexB中来。另外也可以配置一个pattern,当集群A出现符合pattern的索引,自动在集群B创建他的副本,这听起来很酷。值得一提的是,这将是白金版里新增的一个特性。
Minimal Snapshots
snapshot 是 es 中用来创建索引副本的特性,在之前的版本中,snapshot会把完整的 index 都保存下来,包括原始数据和索引数据等等。新的 Minimal Snapshots 提供了一种只备份 _source 内容和 index metadata,当需要恢复时,需要通过 reindex 操作来完成。最小快照最多可能帮你节省50%的磁盘占用,但是会花费更多的时间来恢复。这个特性可能并不适合所有人,但给恢复窗口比较长,且磁盘容量有限的用户多了一种选择。
SQL / ODBC
现在可以使用 支持 ODBC 的第三方工具来连接 elasticsearch 了!我想可以找时间试试用 tableau 直连 elasticsearch会是啥效果。
Java 11
Java11 是一个 LTS 版本,相信会有越来越多的用户升级到 java11
G1GC支持
经过无数的测试,Elasticsearch官方宣布了在 JDK 10+ 上支持 G1GC。G1GC 相比 CMS有诸多优势,如今可以放心地使用G1GC了。(期待对ZGC的支持!)
Authorization realm
X-Pack Security中的新特性,可以对用户认证和用户授权分别配置 realm,比如使用内置的用户体系来认证,再去ldap中获取用户的角色、权限等信息。这也是白金版新增的特性。
机器学习的新特性
- 支持在同一个机器学习任务中分析多个时间系列
- 为机器学习任务添加了新的多分桶(multi-bucket) 分析
Kibana
Canvas
Canvas ! 我在做数据分析师的同学看到之后说太酷了,像 PPT。
点击侧边栏的 canvas 标签,可以看到我们先前导入的样本数据也包含了 canvas 样例:

在 11月的 深圳开发者大会上,上海普翔 也用 canvas 对填写调查问卷的参会人员做了分析:

https://github.com/alexfrancoeur/kibana_canvas_examples 这里有很多非常不错的 canvas 样例供大家学习,把json文件直接拖到 canvas 页面就可以导入学习了!
Spaces
把 kibana 对象(比如 visualizations、dashboards)组织到独立的 space 里,并且通过 RBAC 来控制哪些用户可以访问哪些 space。这实在是太棒了,想象在一个企业里,多个部门通过kibana查询、分析数据,大家关注的dashboard肯定是不一样的,在6.5之前,我们只能通过社区插件来实现这样的需求,而大版本的升级可能直接导致插件不可用,有了 Space,我们不必再担心!

Rollups UI
Rollup 是 es6.4 中新增的一个特性,用来把一些历史数据压缩归档,用作以后的分析。6.5.0 中 kibana 增加了一个界面用来查看和管理 Rollup 任务。

Data visualizer for files
通过可视化的方式查看文件的结构,查看其中出现最频繁的内容:

Beats
Beats Central Management
Beats 终于也支持中心化配置管理了!我们只需按照往常一样安装filebeat、metricbeat,然后使用 filebeat enroll <kibana-url> <token>,便可以通过kibana来管理beats的配置、甚至给他们打上tag:

想一想,假如我们在上千台机器上部署filebeat,如果哪天需要批量变更配置文件,只需要通过脚本调用配置管理的API就可以了
Functionbeat
Functionbeat是一种新的beat类型,可以被部署为一个方法,而不需要跑在服务器环境上,比如 AWS Lambda function。
以上就是 6.5.0 版本的主要特性,更详细的内容可以查看 https://www.elastic.co/blog/elastic-stack-6-5-0-released ,希望通过我的介绍,可以让大家了解到新版本所带来的激动人心的特性。

就在 11月14日,ElasticStack 6.5.0 发布了,此次发布带来了许多激动人心的特性,我们一起来体验一下:
如果没有任何数据,kibana会提示我们导入sample数据,这边我选择Try our sample data, 然后导入全部3个样例数据,这可以让我们在没有数据的情况下快速体验新特性。
Infrastructure & Logs UI
很多用户使用 ElasticStack 收集基础架构的日志和指标,比如系统日志、安全日志、CPU指标,内存指标等等。在6.5中,kibana 侧边栏中增加了 Infrastructure 和 Logs 两个新的 tab,让用户更简单地查看自己的基础架构,和每台主机或者容器里的日志。
logs
进入logs标签页,如果当前没有数据,kibana会引导我们添加数据
我们选择 system logs
根据指示,我们安装部署好filebeat并启动,再次进入 logs 标签页便可以看到收集到的系统日志了
- 搜索过滤框:在这里可以像在 discover 里一样写query string,并且会有输入提示
- 时间选择框:可以选择需要查看的时间点,如果点了 Stream live,会持续监听尾部新输出的日志内容,类似 linux 命令中的tail -f
- 日志时间轴:高亮的部位是当前查看日志所在的时间范围,对应的区域图标识了日志量
假如我想实现 tail -f /var/log/system.log | grep google.com 一样的效果,可以打开 Stream live,并在搜索过滤框中这样输入:
很简单,很方便有木有?
Infrastructure
同样在kibana的引导下安装 Metric beat,并开启system模块,启动后进入 infrastructure 标签页:
这里可以直观地看到所有基础架构的指标状况,深色的内层代表主机,颜色代表了健康状况。浅灰色的外层代表了group,因为我只在自己的笔记本上做了部署,所以只能看到一个host。
点击主机会弹出菜单
- View logs : 跳转到 logs 标签页,并通过搜索过滤框指定host,只查看这台主机的日志。
- View metrics : 跳转到这台主机的指标详情,可以查看历史数据
APM
Java 和 Go
不负众望,继 Nodejs、Python、Ruby、Javascript 之后,Elastic APM 5.6.0 新增了对 Java 和 Golang 的支持!
Distributed Tracing
在 SOA 和 MSA 大行其道的年代,如何追踪请求在各个系统之间的流动成为了apm的关键问题。
Elastic APM 支持 OpenTracing 标准,并在各个agent里内置了 OpenTracing 兼容的bridge
以下是官网上该特性的截图:
APM Server 监控
如 ElasticStack的其他产品一般,APM也支持了监控,并可以在 Kinbana Montoring下查看监控信息:
APM Server 内存占用优化
通过新的基于NDJSON的协议,agent可以在采集信息后通过事件流立即发往APM server,这样 APM Server可以一个接一个地处理接收到的事件,而不是一次性地收到一大块(chunk),这样在很大程度上减少了APM Server的内存占用。
Elasticsearch
Cross-cluster replication
这里的副本并非我们平时常见的分片副本,而是通过在集群B配置一个副本indexB来追随集群A中的indexA,indexA中发生的任何变化都会同步到indexB中来。另外也可以配置一个pattern,当集群A出现符合pattern的索引,自动在集群B创建他的副本,这听起来很酷。值得一提的是,这将是白金版里新增的一个特性。
Minimal Snapshots
snapshot 是 es 中用来创建索引副本的特性,在之前的版本中,snapshot会把完整的 index 都保存下来,包括原始数据和索引数据等等。新的 Minimal Snapshots 提供了一种只备份 _source 内容和 index metadata,当需要恢复时,需要通过 reindex 操作来完成。最小快照最多可能帮你节省50%的磁盘占用,但是会花费更多的时间来恢复。这个特性可能并不适合所有人,但给恢复窗口比较长,且磁盘容量有限的用户多了一种选择。
SQL / ODBC
现在可以使用 支持 ODBC 的第三方工具来连接 elasticsearch 了!我想可以找时间试试用 tableau 直连 elasticsearch会是啥效果。
Java 11
Java11 是一个 LTS 版本,相信会有越来越多的用户升级到 java11
G1GC支持
经过无数的测试,Elasticsearch官方宣布了在 JDK 10+ 上支持 G1GC。G1GC 相比 CMS有诸多优势,如今可以放心地使用G1GC了。(期待对ZGC的支持!)
Authorization realm
X-Pack Security中的新特性,可以对用户认证和用户授权分别配置 realm,比如使用内置的用户体系来认证,再去ldap中获取用户的角色、权限等信息。这也是白金版新增的特性。
机器学习的新特性
- 支持在同一个机器学习任务中分析多个时间系列
- 为机器学习任务添加了新的多分桶(multi-bucket) 分析
Kibana
Canvas
Canvas ! 我在做数据分析师的同学看到之后说太酷了,像 PPT。
点击侧边栏的 canvas 标签,可以看到我们先前导入的样本数据也包含了 canvas 样例:
在 11月的 深圳开发者大会上,上海普翔 也用 canvas 对填写调查问卷的参会人员做了分析:
https://github.com/alexfrancoeur/kibana_canvas_examples 这里有很多非常不错的 canvas 样例供大家学习,把json文件直接拖到 canvas 页面就可以导入学习了!
Spaces
把 kibana 对象(比如 visualizations、dashboards)组织到独立的 space 里,并且通过 RBAC 来控制哪些用户可以访问哪些 space。这实在是太棒了,想象在一个企业里,多个部门通过kibana查询、分析数据,大家关注的dashboard肯定是不一样的,在6.5之前,我们只能通过社区插件来实现这样的需求,而大版本的升级可能直接导致插件不可用,有了 Space,我们不必再担心!
Rollups UI
Rollup 是 es6.4 中新增的一个特性,用来把一些历史数据压缩归档,用作以后的分析。6.5.0 中 kibana 增加了一个界面用来查看和管理 Rollup 任务。
Data visualizer for files
通过可视化的方式查看文件的结构,查看其中出现最频繁的内容:
Beats
Beats Central Management
Beats 终于也支持中心化配置管理了!我们只需按照往常一样安装filebeat、metricbeat,然后使用 filebeat enroll <kibana-url> <token>,便可以通过kibana来管理beats的配置、甚至给他们打上tag:
想一想,假如我们在上千台机器上部署filebeat,如果哪天需要批量变更配置文件,只需要通过脚本调用配置管理的API就可以了
Functionbeat
Functionbeat是一种新的beat类型,可以被部署为一个方法,而不需要跑在服务器环境上,比如 AWS Lambda function。
以上就是 6.5.0 版本的主要特性,更详细的内容可以查看 https://www.elastic.co/blog/elastic-stack-6-5-0-released ,希望通过我的介绍,可以让大家了解到新版本所带来的激动人心的特性。
社区日报 第452期 (2018-11-18)
http://t.cn/E2tAGhG
2.Spark ElasticSearch Hadoop更新和Upsert示例和说明。
http://t.cn/E2t2yg2
3.(自备梯子)我的数据科学恐怖故事。
http://t.cn/E2t2FrI
编辑:至尊宝
归档:https://elasticsearch.cn/article/6143
订阅:https://tinyletter.com/elastic-daily
http://t.cn/E2tAGhG
2.Spark ElasticSearch Hadoop更新和Upsert示例和说明。
http://t.cn/E2t2yg2
3.(自备梯子)我的数据科学恐怖故事。
http://t.cn/E2t2FrI
编辑:至尊宝
归档:https://elasticsearch.cn/article/6143
订阅:https://tinyletter.com/elastic-daily 收起阅读 »
ELK 使用小技巧(第 2 期)
ELK Tips 主要介绍一些 ELK 使用过程中的小技巧,内容主要来源为 Elastic 中文社区。
一、Logstash
1、Filebeat :Non-zero metrics in the last 30s
- 问题表现:Filebeat 无法向 Elasticsearch 发送日志数据;
- 错误信息:
INFO [monitoring] 1og/log.go:124 Non-zero metrics in the last 30s; - 社区反馈:在 input 和 output 下面添加属性 enabled:true。
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/*.log
output.elasticsearch:
hosts: ["https://localhost:9200"]
username: "filebeat_internal"
password: "YOUR_PASSWORD"
enabled: trueinput 和 output 下 enabled 属性默认值为 true,因此怀疑另有其因。
2、Logstash 按月生成索引
output {
if [type] == "typeA"{
elasticsearch {
hosts => "127.0.0.1:9200"
index => "log_%{+YYYY_MM}"
}
}
}按照日的原理类似:%{+YYYY.MM.dd}
3、Filebeat 通过配置删除特定字段
Filebeat 实现了类似 Logstash 中 filter 的功能,叫做处理器(processors),processors 种类不多,尽可能在保持 Filebeat 轻量化的基础上提供更多常用的功能。
下面列几种常用的 processors:
add_cloud_metadata:添加云服务器的 meta 信息;add_locale:添加本地时区;decode_json_fields:解析并处理包含 Json 字符串的字段;drop_event:丢弃符合条件的消息事件;drop_fields:删除符合条件的字段;include_fields:选择符合条件的字段;rename:字段重命名;add_kubernetes_metadata:添加 k8s 的 meta 信息;add_docker_metadata:添加容器的 meta 信息;add_host_metadata:添加操作系统的 meta 信息;dissect:类似与 gork 的正则匹配字段的功能;dns:配置 filebeat 独立的 dns 解析方式;add_process_metadata:添加进程的元信息。
processors 的使用方式:
- type: <input_type>
processors:
- <processor_name>:
when:
<condition>
<parameters>
...4、LogStash 采集 FTP 日志文件
exec {
codec => plain { }
command => "curl ftp://server/logs.log"
interval => 3000}
}5、Logstash docker-compose 启动失败(Permission denied)
在 docker-compose 中使用 user 选项设置使用 root 用户启动 docker,能解决权限问题。
$ cat docker-compose.yml
version: '2'
services:
logstash:
image: docker.elastic.co/logstash/logstash:6.4.2
user: root
command: id6、Metricize filter plugin
将一条消息拆分为多条消息。
# 原始信息
{
type => "type A"
metric1 => "value1"
metric2 => "value2"
}
# 配置信息
filter {
metricize {
metrics => [ "metric1", "metric2" ]
}
}
# 最终输出
{ {
type => "type A" type => "type A"
metric => "metric1" metric => "metric2"
value => "value1" value => "value2"
} }二、Elasticsearch
1、ES 倒排索引内部结构
Lucene 的倒排索引都是按照字段(field)来存储对应的文档信息的,如果 docName 和 docContent 中有“苹果”这个 term,就会有这两个索引链,如下所示:
docName:
"苹果" -> "doc1, doc2, doc3..."
docContent:
"苹果" -> "doc2, doc4, doc6..."2、Jest 和 RestHighLevelClient 哪个好用点
RestHighLevelClient 是官方组件,会一直得到官方的支持,且会与 ES 保持同步更新,推荐使用官方的高阶 API。
Jest 由于是社区维护,所以更新会有一定延迟,目前最新版对接 ES6.3.1,近一个月只有四个 issue,说明整体活跃度较低,因此不推荐使用。
此外推荐一份 TransportClient 的中文使用手册,翻译的很不错:https://github.com/jackiehff/elasticsearch-client-java-api-cn。
3、ES 单分片使用 From/Size 分页遇到重复数据
常规情况下 ES 单分片使用 From/Size 是不会遇到数据重复的,数据重复的可能原因有:
- 没有添加排序;
- 添加了按得分排序,但是查询语句全部为 filter 过滤条件(此时得分都一致);
- 添加了排序,但是有索引中文档的新增、修改、删除等操作。
对于多分片,推荐添加 preference 参数来实现分页结果的一致性。
4、The number of object passed must be even but was [1]
ES 在调用 setSource 的时候传入 Json 对象后会报错:The number of object passed must be even but was [1],此时可以推荐将 Json 对象转为 Map 集合,或者把 Json 对象转为 json 字符串,不过传入字符串的时候需要设置类型。
IndexRequest indexRequest = new IndexRequest("index", "type", "id");
JSONObject doc = new JSONObject();
//indexRequest.source(jsonObject); 错误的使用方法
//转为 Map 对象
indexRequest.source(JSONObject.parseObject((String) doc.get("json"), Map.class));
//转为 Json 字符串(声明字符串类型)
indexRequest.source(JSON.toJSONString(doc), XContentType.JSON);5、跨集群搜索
ES 6.X 原生支持跨集群搜索,具体配置请参考:https://www.elastic.co/guide/en/kibana/current/management-cross-cluster-search.html
PUT _cluster/settings
{
"persistent": {
"cluster": {
"remote": {
"cluster_one": {
"seeds": [
"127.0.0.1:9300"
]
},
"cluster_two": {
"seeds": [
"127.0.0.1:9301"
]
},
"cluster_three": {
"seeds": [
"127.0.0.1:9302"
]
}
}
}
}
}ES 6.5 推出了新功能,跨集群同步(Cross-cluster replication),感兴趣的可以自行了解。
6、ES 排序时设置空值排序位置
GET /_search
{
"sort" : [
{ "price" : {"missing" : "_last"} }
],
"query" : {
"term" : { "product" : "chocolate" }
}
}7、ES 冷归档数据如何处理
使用相对低配的大磁盘机器配置为 ES 的 Warm Nodes,可以通过 index.routing.allocation.require.box_type 来设置索引是冷数据或者热数据。如果索引极少使用,可以 close 索引,然后在需要搜索的时候 open 即可。
8、ES 相似文章检测
对于大文本的去重,可以参考 SimHash 算法,通过 SimHash 可以提取到文档指纹(64位),两篇文章通过 SimHash 计算海明距离即可判断是否重复。海明距离计算,可以通过插件实现:https://github.com/joway/elasticsearch-hamming-plugin
9、Terms 聚合查询优化
- 如果只需要聚合后前 N 条记录,推荐在 Terms 聚合时添加上
"collect_mode": "breadth_first"; - 此外可以通过设置
"min_doc_count": 10来限制最小匹配文档数; - 如果对返回的 Term 有所要求,可以通过设置
include和exclude来过滤 Term; - 如果想获取全部 Term 聚合结果,但是聚合结果又很多,可以考虑将聚合分成多个批次分别取回(Filtering Values with partitions)。
10、Tomcat 字符集造成的 ES 查询无结果
两个系统连接同一个 ES 服务,配置和代码完全一致,同一个搜索条件,一个能够搜索出来东西,一个什么都搜索不出来,排查结果是因为其中一个系统的 tomcat 配置有问题,导致请求的时候乱码了,所以搜不到数据。
11、ES 索引设置默认分词器
默认情况下,如果字段不指定分词器,ES 或使用 standard 分词器进行分词;可以通过下面的设置更改默认的分词器。
2.X 支持设置默认的索引分词器(default_index)和默认的查询分词器(default_search),6.X 已经不再支持。
PUT /index
{
"settings": {
"analysis": {
"analyzer": {
"default": {
"type": "ik_max_word",
"tokenizer": "ik_max_word"
}
}
}
}
}12、ES 中的魔法参数
- 索引名:_index
- 类型名:_type
- 文档Id:_id
- 得分:_score
- 索引排序:_doc
如果你对排序没有特别的需求,推荐使用 _doc 进行排序,例如执行 Scroll 操作时。
13、ES 延迟执行数据上卷(Rollup )
Rollup job 有个 delay 参数控制 job 执行的延迟时间,默认情况下不延迟执行,这样如果某个 interval 的数据已经聚合好了,该 interval 迟到的数据是不会处理的。
好在 rollup api 可以支持同时搜索裸索引和 rollup 过的索引,所以如果数据经常有延迟的话,可以考虑设置一个合适的 delay,比如 1h、6h 甚至 24h,这样 rollup 的索引产生会有延迟,但是能确保迟到的数据被处理。
从应用场景上看,rollup 一般是为了对历史数据做聚合存放,减少存储空间,所以延迟几个小时,甚至几天都是合理的。搜索的时候,同时搜索最近的裸索引和历史的 rollup 索引,就能将两者的数据组合起来,在给出正确的聚合结果的情况下,又兼顾了性能。
Rollup 是实验性功能,不过非常有用,特别是使用 ES 做数据仓库的场景。
14、ES6.x 获取所有的聚合结果
ES2.x 版本中,在聚合查询时,通过设置 setSize(0) 就可以获取所有的聚合结果,在ES6.x 中直接设置 setSize(Integer.MAX_VALUE) 等效于 2.x 中设置为 0。
15、ES Jar 包冲突问题
经常会遇到 ES 与业务集成时出现 Jar 包冲突问题,推荐的解决方法是使用 maven-shade-plugin 插件,该插件通过将冲突的 Jar 包更换一个命名空间的方式来解决 Jar 包的冲突问题,具体使用可以参考文章:https://www.jianshu.com/p/d9fb7afa634d。
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.1</version>
<configuration>
<createDependencyReducedPom>false</createDependencyReducedPom>
</configuration>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<relocations>
<relocation>
<pattern>com.google.guava</pattern>
<shadedPattern>net.luculent.elasticsearch.guava</shadedPattern>
</relocation>
<relocation>
<pattern>com.fasterxml.jackson</pattern>
<shadedPattern>net.luculent.elasticsearch.jackson</shadedPattern>
</relocation>
<relocation>
<pattern>org.joda</pattern>
<shadedPattern>net.luculent.elasticsearch.joda</shadedPattern>
</relocation>
<relocation>
<pattern>com.google.common</pattern>
<shadedPattern>net.luculent.elasticsearch.common</shadedPattern>
</relocation>
<relocation>
<pattern>com.google.thirdparty</pattern>
<shadedPattern>net.luculent.elasticsearch.thirdparty</shadedPattern>
</relocation>
</relocations>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer" />
<transformer implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"/>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>16、ES 如何选择 Shard 存储文档?
ES 采用 djb2 哈希算法对要索引文档的指定(或者默认随机生成的)_id 进行哈希,得到哈希结果后对索引 shard 数目 n 取模,公式如下:hash(_id) % n;根据取模结果决定存储到哪一个 shard 。
三、Kibana
1、在 Kiabana 的 Discovery 界面显示自定义字段
Kibana 的 Discovery 界面默认只显示 time 和 _source 两个字段,这个界面的左半部分,在 Popular 下面展示了很多,你只需要在你需要展示的字段后面点击 add 即可将自定义的字段添加到 discovery 界面。

2、filebeat 的 monitor 指标的说明
- Total:'All events newly created in the publishing pipeline'
- Emitted: 'Events processed by the output (including retries)'
- Acknowledged:'Events acknowledged by the output (includes events dropped by the output)'
- Queued:'Events added to the event pipeline queue'
四、社区文章精选
- Elastic认证考试心得
- 一文快速上手Logstash
- 当Elasticsearch遇见Kafka--Kafka Connect
- elasticsearch冷热数据读写分离
- elasticsearch优秀实践
- ELK 使用小技巧(第 1 期)
Any Code,Code Any!
扫码关注『AnyCode』,编程路上,一起前行。

ELK Tips 主要介绍一些 ELK 使用过程中的小技巧,内容主要来源为 Elastic 中文社区。
一、Logstash
1、Filebeat :Non-zero metrics in the last 30s
- 问题表现:Filebeat 无法向 Elasticsearch 发送日志数据;
- 错误信息:
INFO [monitoring] 1og/log.go:124 Non-zero metrics in the last 30s; - 社区反馈:在 input 和 output 下面添加属性 enabled:true。
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/*.log
output.elasticsearch:
hosts: ["https://localhost:9200"]
username: "filebeat_internal"
password: "YOUR_PASSWORD"
enabled: trueinput 和 output 下 enabled 属性默认值为 true,因此怀疑另有其因。
2、Logstash 按月生成索引
output {
if [type] == "typeA"{
elasticsearch {
hosts => "127.0.0.1:9200"
index => "log_%{+YYYY_MM}"
}
}
}按照日的原理类似:%{+YYYY.MM.dd}
3、Filebeat 通过配置删除特定字段
Filebeat 实现了类似 Logstash 中 filter 的功能,叫做处理器(processors),processors 种类不多,尽可能在保持 Filebeat 轻量化的基础上提供更多常用的功能。
下面列几种常用的 processors:
add_cloud_metadata:添加云服务器的 meta 信息;add_locale:添加本地时区;decode_json_fields:解析并处理包含 Json 字符串的字段;drop_event:丢弃符合条件的消息事件;drop_fields:删除符合条件的字段;include_fields:选择符合条件的字段;rename:字段重命名;add_kubernetes_metadata:添加 k8s 的 meta 信息;add_docker_metadata:添加容器的 meta 信息;add_host_metadata:添加操作系统的 meta 信息;dissect:类似与 gork 的正则匹配字段的功能;dns:配置 filebeat 独立的 dns 解析方式;add_process_metadata:添加进程的元信息。
processors 的使用方式:
- type: <input_type>
processors:
- <processor_name>:
when:
<condition>
<parameters>
...4、LogStash 采集 FTP 日志文件
exec {
codec => plain { }
command => "curl ftp://server/logs.log"
interval => 3000}
}5、Logstash docker-compose 启动失败(Permission denied)
在 docker-compose 中使用 user 选项设置使用 root 用户启动 docker,能解决权限问题。
$ cat docker-compose.yml
version: '2'
services:
logstash:
image: docker.elastic.co/logstash/logstash:6.4.2
user: root
command: id6、Metricize filter plugin
将一条消息拆分为多条消息。
# 原始信息
{
type => "type A"
metric1 => "value1"
metric2 => "value2"
}
# 配置信息
filter {
metricize {
metrics => [ "metric1", "metric2" ]
}
}
# 最终输出
{ {
type => "type A" type => "type A"
metric => "metric1" metric => "metric2"
value => "value1" value => "value2"
} }二、Elasticsearch
1、ES 倒排索引内部结构
Lucene 的倒排索引都是按照字段(field)来存储对应的文档信息的,如果 docName 和 docContent 中有“苹果”这个 term,就会有这两个索引链,如下所示:
docName:
"苹果" -> "doc1, doc2, doc3..."
docContent:
"苹果" -> "doc2, doc4, doc6..."2、Jest 和 RestHighLevelClient 哪个好用点
RestHighLevelClient 是官方组件,会一直得到官方的支持,且会与 ES 保持同步更新,推荐使用官方的高阶 API。
Jest 由于是社区维护,所以更新会有一定延迟,目前最新版对接 ES6.3.1,近一个月只有四个 issue,说明整体活跃度较低,因此不推荐使用。
此外推荐一份 TransportClient 的中文使用手册,翻译的很不错:https://github.com/jackiehff/elasticsearch-client-java-api-cn。
3、ES 单分片使用 From/Size 分页遇到重复数据
常规情况下 ES 单分片使用 From/Size 是不会遇到数据重复的,数据重复的可能原因有:
- 没有添加排序;
- 添加了按得分排序,但是查询语句全部为 filter 过滤条件(此时得分都一致);
- 添加了排序,但是有索引中文档的新增、修改、删除等操作。
对于多分片,推荐添加 preference 参数来实现分页结果的一致性。
4、The number of object passed must be even but was [1]
ES 在调用 setSource 的时候传入 Json 对象后会报错:The number of object passed must be even but was [1],此时可以推荐将 Json 对象转为 Map 集合,或者把 Json 对象转为 json 字符串,不过传入字符串的时候需要设置类型。
IndexRequest indexRequest = new IndexRequest("index", "type", "id");
JSONObject doc = new JSONObject();
//indexRequest.source(jsonObject); 错误的使用方法
//转为 Map 对象
indexRequest.source(JSONObject.parseObject((String) doc.get("json"), Map.class));
//转为 Json 字符串(声明字符串类型)
indexRequest.source(JSON.toJSONString(doc), XContentType.JSON);5、跨集群搜索
ES 6.X 原生支持跨集群搜索,具体配置请参考:https://www.elastic.co/guide/en/kibana/current/management-cross-cluster-search.html
PUT _cluster/settings
{
"persistent": {
"cluster": {
"remote": {
"cluster_one": {
"seeds": [
"127.0.0.1:9300"
]
},
"cluster_two": {
"seeds": [
"127.0.0.1:9301"
]
},
"cluster_three": {
"seeds": [
"127.0.0.1:9302"
]
}
}
}
}
}ES 6.5 推出了新功能,跨集群同步(Cross-cluster replication),感兴趣的可以自行了解。
6、ES 排序时设置空值排序位置
GET /_search
{
"sort" : [
{ "price" : {"missing" : "_last"} }
],
"query" : {
"term" : { "product" : "chocolate" }
}
}7、ES 冷归档数据如何处理
使用相对低配的大磁盘机器配置为 ES 的 Warm Nodes,可以通过 index.routing.allocation.require.box_type 来设置索引是冷数据或者热数据。如果索引极少使用,可以 close 索引,然后在需要搜索的时候 open 即可。
8、ES 相似文章检测
对于大文本的去重,可以参考 SimHash 算法,通过 SimHash 可以提取到文档指纹(64位),两篇文章通过 SimHash 计算海明距离即可判断是否重复。海明距离计算,可以通过插件实现:https://github.com/joway/elasticsearch-hamming-plugin
9、Terms 聚合查询优化
- 如果只需要聚合后前 N 条记录,推荐在 Terms 聚合时添加上
"collect_mode": "breadth_first"; - 此外可以通过设置
"min_doc_count": 10来限制最小匹配文档数; - 如果对返回的 Term 有所要求,可以通过设置
include和exclude来过滤 Term; - 如果想获取全部 Term 聚合结果,但是聚合结果又很多,可以考虑将聚合分成多个批次分别取回(Filtering Values with partitions)。
10、Tomcat 字符集造成的 ES 查询无结果
两个系统连接同一个 ES 服务,配置和代码完全一致,同一个搜索条件,一个能够搜索出来东西,一个什么都搜索不出来,排查结果是因为其中一个系统的 tomcat 配置有问题,导致请求的时候乱码了,所以搜不到数据。
11、ES 索引设置默认分词器
默认情况下,如果字段不指定分词器,ES 或使用 standard 分词器进行分词;可以通过下面的设置更改默认的分词器。
2.X 支持设置默认的索引分词器(default_index)和默认的查询分词器(default_search),6.X 已经不再支持。
PUT /index
{
"settings": {
"analysis": {
"analyzer": {
"default": {
"type": "ik_max_word",
"tokenizer": "ik_max_word"
}
}
}
}
}12、ES 中的魔法参数
- 索引名:_index
- 类型名:_type
- 文档Id:_id
- 得分:_score
- 索引排序:_doc
如果你对排序没有特别的需求,推荐使用 _doc 进行排序,例如执行 Scroll 操作时。
13、ES 延迟执行数据上卷(Rollup )
Rollup job 有个 delay 参数控制 job 执行的延迟时间,默认情况下不延迟执行,这样如果某个 interval 的数据已经聚合好了,该 interval 迟到的数据是不会处理的。
好在 rollup api 可以支持同时搜索裸索引和 rollup 过的索引,所以如果数据经常有延迟的话,可以考虑设置一个合适的 delay,比如 1h、6h 甚至 24h,这样 rollup 的索引产生会有延迟,但是能确保迟到的数据被处理。
从应用场景上看,rollup 一般是为了对历史数据做聚合存放,减少存储空间,所以延迟几个小时,甚至几天都是合理的。搜索的时候,同时搜索最近的裸索引和历史的 rollup 索引,就能将两者的数据组合起来,在给出正确的聚合结果的情况下,又兼顾了性能。
Rollup 是实验性功能,不过非常有用,特别是使用 ES 做数据仓库的场景。
14、ES6.x 获取所有的聚合结果
ES2.x 版本中,在聚合查询时,通过设置 setSize(0) 就可以获取所有的聚合结果,在ES6.x 中直接设置 setSize(Integer.MAX_VALUE) 等效于 2.x 中设置为 0。
15、ES Jar 包冲突问题
经常会遇到 ES 与业务集成时出现 Jar 包冲突问题,推荐的解决方法是使用 maven-shade-plugin 插件,该插件通过将冲突的 Jar 包更换一个命名空间的方式来解决 Jar 包的冲突问题,具体使用可以参考文章:https://www.jianshu.com/p/d9fb7afa634d。
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.1</version>
<configuration>
<createDependencyReducedPom>false</createDependencyReducedPom>
</configuration>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<relocations>
<relocation>
<pattern>com.google.guava</pattern>
<shadedPattern>net.luculent.elasticsearch.guava</shadedPattern>
</relocation>
<relocation>
<pattern>com.fasterxml.jackson</pattern>
<shadedPattern>net.luculent.elasticsearch.jackson</shadedPattern>
</relocation>
<relocation>
<pattern>org.joda</pattern>
<shadedPattern>net.luculent.elasticsearch.joda</shadedPattern>
</relocation>
<relocation>
<pattern>com.google.common</pattern>
<shadedPattern>net.luculent.elasticsearch.common</shadedPattern>
</relocation>
<relocation>
<pattern>com.google.thirdparty</pattern>
<shadedPattern>net.luculent.elasticsearch.thirdparty</shadedPattern>
</relocation>
</relocations>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer" />
<transformer implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"/>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>16、ES 如何选择 Shard 存储文档?
ES 采用 djb2 哈希算法对要索引文档的指定(或者默认随机生成的)_id 进行哈希,得到哈希结果后对索引 shard 数目 n 取模,公式如下:hash(_id) % n;根据取模结果决定存储到哪一个 shard 。
三、Kibana
1、在 Kiabana 的 Discovery 界面显示自定义字段
Kibana 的 Discovery 界面默认只显示 time 和 _source 两个字段,这个界面的左半部分,在 Popular 下面展示了很多,你只需要在你需要展示的字段后面点击 add 即可将自定义的字段添加到 discovery 界面。
2、filebeat 的 monitor 指标的说明
- Total:'All events newly created in the publishing pipeline'
- Emitted: 'Events processed by the output (including retries)'
- Acknowledged:'Events acknowledged by the output (includes events dropped by the output)'
- Queued:'Events added to the event pipeline queue'
四、社区文章精选
- Elastic认证考试心得
- 一文快速上手Logstash
- 当Elasticsearch遇见Kafka--Kafka Connect
- elasticsearch冷热数据读写分离
- elasticsearch优秀实践
- ELK 使用小技巧(第 1 期)
Any Code,Code Any!
扫码关注『AnyCode』,编程路上,一起前行。
一文快速上手Logstash
本文同步发布在腾讯云+社区Elasticsearch专栏:https://cloud.tencent.com/developer/column/4008
Elasticsearch是当前主流的分布式大数据存储和搜索引擎,可以为用户提供强大的全文本检索能力,广泛应用于日志检索,全站搜索等领域。Logstash作为Elasicsearch常用的实时数据采集引擎,可以采集来自不同数据源的数据,并对数据进行处理后输出到多种输出源,是Elastic Stack 的重要组成部分。本文从Logstash的工作原理,使用示例,部署方式及性能调优等方面入手,为大家提供一个快速入门Logstash的方式。文章最后也给出了一些深入了解Logstash的的链接,以方便大家根据需要详细了解。
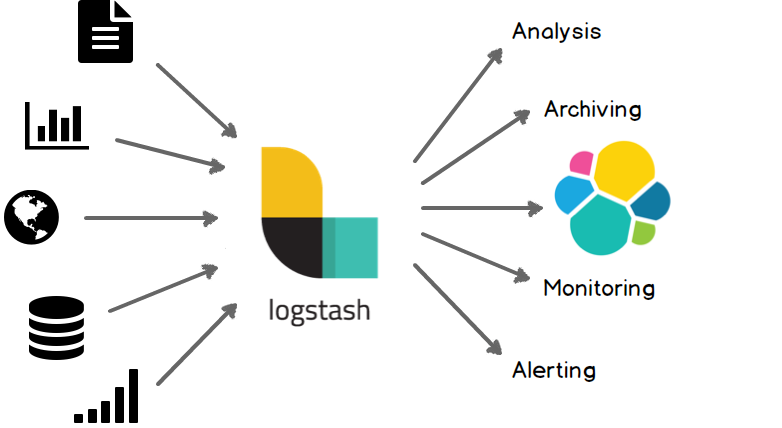
1 Logstash工作原理
1.1 处理过程
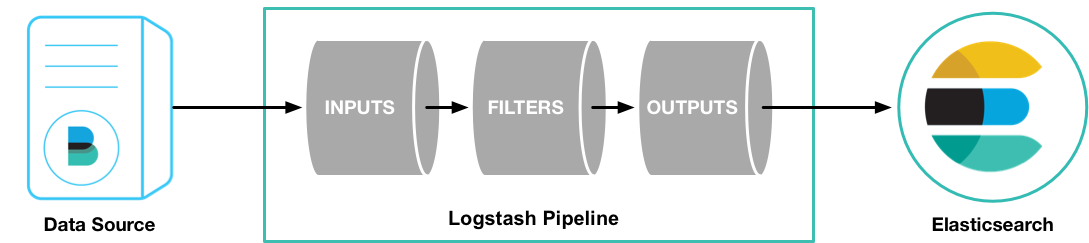
如上图,Logstash的数据处理过程主要包括:Inputs, Filters, Outputs 三部分, 另外在Inputs和Outputs中可以使用Codecs对数据格式进行处理。这四个部分均以插件形式存在,用户通过定义pipeline配置文件,设置需要使用的input,filter,output, codec插件,以实现特定的数据采集,数据处理,数据输出等功能
- (1)Inputs:用于从数据源获取数据,常见的插件如file, syslog, redis, beats 等[详细参考]
- (2)Filters:用于处理数据如格式转换,数据派生等,常见的插件如grok, mutate, drop, clone, geoip等[详细参考]
- (3)Outputs:用于数据输出,常见的插件如elastcisearch,file, graphite, statsd等[详细参考]
- (4)Codecs:Codecs不是一个单独的流程,而是在输入和输出等插件中用于数据转换的模块,用于对数据进行编码处理,常见的插件如json,multiline[详细参考]
可以点击每个模块后面的_详细参考_链接了解该模块的插件列表及对应功能
1.2 执行模型:
- (1)每个Input启动一个线程,从对应数据源获取数据
- (2)Input会将数据写入一个队列:默认为内存中的有界队列(意外停止会导致数据丢失)。为了防止数丢失Logstash提供了两个特性: Persistent Queues:通过磁盘上的queue来防止数据丢失 Dead Letter Queues:保存无法处理的event(仅支持Elasticsearch作为输出源)
- (3)Logstash会有多个pipeline worker, 每一个pipeline worker会从队列中取一批数据,然后执行filter和output(worker数目及每次处理的数据量均由配置确定)
2 Logstash使用示例
2.1 Logstash Hello world
第一个示例Logstash将采用标准输入和标准输出作为input和output,并且不指定filter
- (1)下载Logstash并解压(需要预先安装JDK8)
- (2)cd到Logstash的根目录,并执行启动命令如下:
cd logstash-6.4.0
bin/logstash -e 'input { stdin { } } output { stdout {} }'- (3)此时Logstash已经启动成功,-e表示在启动时直接指定pipeline配置,当然也可以将该配置写入一个配置文件中,然后通过指定配置文件来启动
- (4)在控制台输入:hello world,可以看到如下输出:
{
"@version" => "1",
"host" => "localhost",
"@timestamp" => 2018-09-18T12:39:38.514Z,
"message" => "hello world"
} Logstash会自动为数据添加@version, host, @timestamp等字段
在这个示例中Logstash从标准输入中获得数据,仅在数据中添加一些简单字段后将其输出到标准输出。
2.2 日志采集
这个示例将采用Filebeat input插件(Elastic Stack中的轻量级数据采集程序)采集本地日志,然后将结果输出到标准输出
filebeat.yml配置如下(paths改为日志实际位置,不同版本beats配置可能略有变化,请根据情况调整)
filebeat.prospectors:
- input\_type: log
paths:
- /path/to/file/logstash-tutorial.log
output.logstash:
hosts: "localhost:5044"启动命令:
./filebeat -e -c filebeat.yml -d "publish"- (3)配置logstash并启动
1)创建first-pipeline.conf文件内容如下(该文件为pipeline配置文件,用于指定input,filter, output等):
input {
beats {
port => "5044"
}
}
#filter {
#}
output {
stdout { codec => rubydebug }
}codec => rubydebug用于美化输出[参考]
2)验证配置(注意指定配置文件的路径):
./bin/logstash -f first-pipeline.conf --config.test_and_exit3)启动命令:
./bin/logstash -f first-pipeline.conf --config.reload.automatic--config.reload.automatic选项启用动态重载配置功能
4)预期结果:
可以在Logstash的终端显示中看到,日志文件被读取并处理为如下格式的多条数据
{
"@timestamp" => 2018-10-09T12:22:39.742Z,
"offset" => 24464,
"@version" => "1",
"input_type" => "log",
"beat" => {
"name" => "VM_136_9_centos",
"hostname" => "VM_136_9_centos",
"version" => "5.6.10"
},
"host" => "VM_136_9_centos",
"source" => "/data/home/michelmu/workspace/logstash-tutorial.log",
"message" => "86.1.76.62 - - [04/Jan/2015:05:30:37 +0000] \"GET /style2.css HTTP/1.1\" 200 4877 \"http://www.semicomplete.com/projects/xdotool/\" \"Mozilla/5.0 (X11; Linux x86_64; rv:24.0) Gecko/20140205 Firefox/24.0 Iceweasel/24.3.0\"",
"type" => "log",
"tags" => [
[0] "beats_input_codec_plain_applied"
]
}相对于示例2.1,该示例使用了filebeat input插件从日志中获取一行记录,这也是Elastic stack获取日志数据最常见的一种方式。另外该示例还采用了rubydebug codec 对输出的数据进行显示美化。
2.3 日志格式处理
可以看到虽然示例2.2使用filebeat从日志中读取数据,并将数据输出到标准输出,但是日志内容作为一个整体被存放在message字段中,这样对后续存储及查询都极为不便。可以为该pipeline指定一个grok filter来对日志格式进行处理
- (1)在first-pipeline.conf中增加filter配置如下
input {
beats {
port => "5044"
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}"}
}
}
output {
stdout { codec => rubydebug }
}- (2)到filebeat的根目录下删除之前上报的数据历史(以便重新上报数据),并重启filebeat
sudo rm data/registry
sudo ./filebeat -e -c filebeat.yml -d "publish"- (3)由于之前启动Logstash设置了自动更新配置,因此Logstash不需要重新启动,这个时候可以获取到的日志数据如下:
{
"request" => "/style2.css",
"agent" => "\"Mozilla/5.0 (X11; Linux x86_64; rv:24.0) Gecko/20140205 Firefox/24.0 Iceweasel/24.3.0\"",
"offset" => 24464,
"auth" => "-",
"ident" => "-",
"input_type" => "log",
"verb" => "GET",
"source" => "/data/home/michelmu/workspace/logstash-tutorial.log",
"message" => "86.1.76.62 - - [04/Jan/2015:05:30:37 +0000] \"GET /style2.css HTTP/1.1\" 200 4877 \"http://www.semicomplete.com/projects/xdotool/\" \"Mozilla/5.0 (X11; Linux x86_64; rv:24.0) Gecko/20140205 Firefox/24.0 Iceweasel/24.3.0\"",
"type" => "log",
"tags" => [
[0] "beats_input_codec_plain_applied"
],
"referrer" => "\"http://www.semicomplete.com/projects/xdotool/\"",
"@timestamp" => 2018-10-09T12:24:21.276Z,
"response" => "200",
"bytes" => "4877",
"clientip" => "86.1.76.62",
"@version" => "1",
"beat" => {
"name" => "VM_136_9_centos",
"hostname" => "VM_136_9_centos",
"version" => "5.6.10"
},
"host" => "VM_136_9_centos",
"httpversion" => "1.1",
"timestamp" => "04/Jan/2015:05:30:37 +0000"
}可以看到message中的数据被详细解析出来了
2.4 数据派生和增强
Logstash中的一些filter可以根据现有数据生成一些新的数据,如geoip可以根据ip生成经纬度信息
- (1)在first-pipeline.conf中增加geoip配置如下
input {
beats {
port => "5044"
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}"}
}
geoip {
source => "clientip"
}
}
output {
stdout { codec => rubydebug }
}- (2)如2.3一样清空filebeat历史数据,并重启
- (3)当然Logstash仍然不需要重启,可以看到输出变为如下:
{
"request" => "/style2.css",
"agent" => "\"Mozilla/5.0 (X11; Linux x86_64; rv:24.0) Gecko/20140205 Firefox/24.0 Iceweasel/24.3.0\"",
"geoip" => {
"timezone" => "Europe/London",
"ip" => "86.1.76.62",
"latitude" => 51.5333,
"continent_code" => "EU",
"city_name" => "Willesden",
"country_name" => "United Kingdom",
"country_code2" => "GB",
"country_code3" => "GB",
"region_name" => "Brent",
"location" => {
"lon" => -0.2333,
"lat" => 51.5333
},
"postal_code" => "NW10",
"region_code" => "BEN",
"longitude" => -0.2333
},
"offset" => 24464,
"auth" => "-",
"ident" => "-",
"input_type" => "log",
"verb" => "GET",
"source" => "/data/home/michelmu/workspace/logstash-tutorial.log",
"message" => "86.1.76.62 - - [04/Jan/2015:05:30:37 +0000] \"GET /style2.css HTTP/1.1\" 200 4877 \"http://www.semicomplete.com/projects/xdotool/\" \"Mozilla/5.0 (X11; Linux x86_64; rv:24.0) Gecko/20140205 Firefox/24.0 Iceweasel/24.3.0\"",
"type" => "log",
"tags" => [
[0] "beats_input_codec_plain_applied"
],
"referrer" => "\"http://www.semicomplete.com/projects/xdotool/\"",
"@timestamp" => 2018-10-09T12:37:46.686Z,
"response" => "200",
"bytes" => "4877",
"clientip" => "86.1.76.62",
"@version" => "1",
"beat" => {
"name" => "VM_136_9_centos",
"hostname" => "VM_136_9_centos",
"version" => "5.6.10"
},
"host" => "VM_136_9_centos",
"httpversion" => "1.1",
"timestamp" => "04/Jan/2015:05:30:37 +0000"
}可以看到根据ip派生出了许多地理位置信息数据
2.5 将数据导入Elasticsearch
Logstash作为Elastic stack的重要组成部分,其最常用的功能是将数据导入到Elasticssearch中。将Logstash中的数据导入到Elasticsearch中操作也非常的方便,只需要在pipeline配置文件中增加Elasticsearch的output即可。
- (1)首先要有一个已经部署好的Logstash,当然可以使用腾讯云快速创建一个Elasticsearch创建地址
- (2)在first-pipeline.conf中增加Elasticsearch的配置,如下
input {
beats {
port => "5044"
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}"}
}
geoip {
source => "clientip"
}
}
output {
elasticsearch {
hosts => [ "localhost:9200" ]
}
}- (3)清理filebeat历史数据,并重启
- (4)查询Elasticsearch确认数据是否正常上传(注意替换查询语句中的日期)
curl -XGET 'http://172.16.16.17:9200/logstash-2018.10.09/_search?pretty&q=response=200'- (5)如果Elasticsearch关联了Kibana也可以使用kibana查看数据是否正常上报
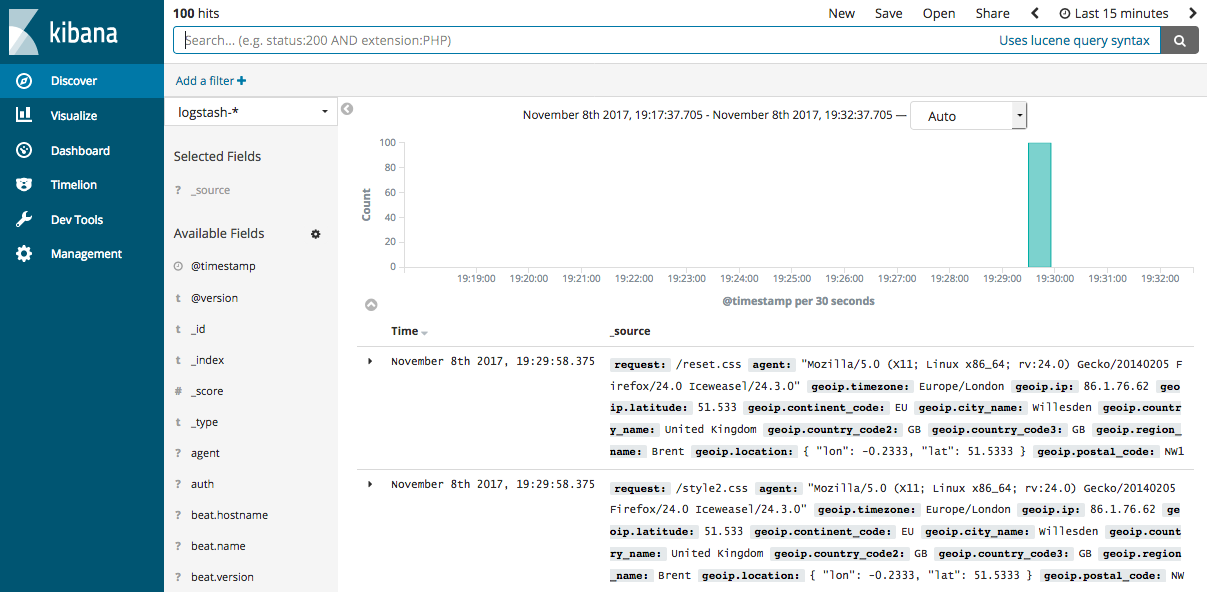
Logstash提供了大量的Input, filter, output, codec的插件,用户可以根据自己的需要,使用一个或多个组件实现自己的功能,当然用户也可以自定义插件以实现更为定制化的功能。自定义插件可以参考[logstash input插件开发]
3 部署Logstash
演示过如何快速使用Logstash后,现在详细讲述一下Logstash的部署方式。
3.1 安装
- 安装JDK:Logstash采用JRuby编写,运行需要JDK环境,因此安装Logstash前需要先安装JDK。(当前6.4仅支持JDK8)
- 安装Logstash:可以采用直接下载压缩包方式安装,也通过APT或YUM安装,另外Logstash支持安装到Docker中。[Logstash安装参考]
- 安装X-PACK:在6.3及之后版本X-PACK会随Logstash安装,在此之前需要手动安装[参考链接]
3.2 目录结构
logstash的目录主要包括:根目录、bin目录、配置目录、日志目录、插件目录、数据目录
不同安装方式各目录的默认位置参考[此处]
3.3 配置文件
- Pipeline配置文件,名称可以自定义,在启动Logstash时显式指定,编写方式可以参考前面示例,对于具体插件的配置方式参见具体插件的说明(使用Logstash时必须配置): 用于定义一个pipeline,数据处理方式和输出源
- Settings配置文件(可以使用默认配置): 在使用Logstash时可以不用设置,用于性能调优,日志记录等
- 为了保证敏感配置的安全性,logstash提供了配置加密功能[参考链接]
3.4 启动关闭方式
3.4.1 启动
- 命令行启动
- 在debian和rpm上以服务形式启动
- 在docker中启动3.4.2 关闭
- 关闭Logstash
- Logstash的关闭时会先关闭input停止输入,然后处理完所有进行中的事件,然后才完全停止,以防止数据丢失,但这也导致停止过程出现延迟或失败的情况。
3.5 扩展Logstash
当单个Logstash无法满足性能需求时,可以采用横向扩展的方式来提高Logstash的处理能力。横向扩展的多个Logstash相互独立,采用相同的pipeline配置,另外可以在这多个Logstash前增加一个LoadBalance,以实现多个Logstash的负载均衡。
4 性能调优
[详细调优参考]
- (1)Inputs和Outputs的性能:当输入输出源的性能已经达到上限,那么性能瓶颈不在Logstash,应优先对输入输出源的性能进行调优。
- (2)系统性能指标:
- CPU:确定CPU使用率是否过高,如果CPU过高则先查看JVM堆空间使用率部分,确认是否为GC频繁导致,如果GC正常,则可以通过调节Logstash worker相关配置来解决。
- 内存:由于Logstash运行在JVM上,因此注意调整JVM堆空间上限,以便其有足够的运行空间。另外注意Logstash所在机器上是否有其他应用占用了大量内存,导致Logstash内存磁盘交换频繁。
- I/O使用率: 1)磁盘IO: 磁盘IO饱和可能是因为使用了会导致磁盘IO饱和的创建(如file output),另外Logstash中出现错误产生大量错误日志时也会导致磁盘IO饱和。Linux下可以通过iostat, dstat等查看磁盘IO情况 2)网络IO: 网络IO饱和一般发生在使用有大量网络操作的插件时。linux下可以使用dstat或iftop等查看网络IO情况
- (3)JVM堆检查:
- 如果JVM堆大小设置过小会导致GC频繁,从而导致CPU使用率过高
- 快速验证这个问题的方法是double堆大小,看性能是否有提升。注意要给系统至少预留1GB的空间。
- 为了精确查找问题可以使用jmap或VisualVM。[参考]
- 设置Xms和Xmx为相同值,防止堆大小在运行时调整,这个过程非常消耗性能。
- (4)Logstash worker设置:
worker相关配置在logstash.yml中,主要包括如下三个:
- pipeline.workers: 该参数用以指定Logstash中执行filter和output的线程数,当如果发现CPU使用率尚未达到上限,可以通过调整该参数,为Logstash提供更高的性能。建议将Worker数设置适当超过CPU核数可以减少IO等待时间对处理过程的影响。实际调优中可以先通过-w指定该参数,当确定好数值后再写入配置文件中。
- pipeline.batch.size: 该指标用于指定单个worker线程一次性执行flilter和output的event批量数。增大该值可以减少IO次数,提高处理速度,但是也以为这增加内存等资源的消耗。当与Elasticsearch联用时,该值可以用于指定Elasticsearch一次bluck操作的大小。
- pipeline.batch.delay: 该指标用于指定worker等待时间的超时时间,如果worker在该时间内没有等到pipeline.batch.size个事件,那么将直接开始执行filter和output而不再等待。
结束语
Logstash作为Elastic Stack的重要组成部分,在Elasticsearch数据采集和处理过程中扮演着重要的角色。本文通过简单示例的演示和Logstash基础知识的铺陈,希望可以帮助初次接触Logstash的用户对Logstash有一个整体认识,并能较为快速上手。对于Logstash的高阶使用,仍需要用户在使用过程中结合实际情况查阅相关资源深入研究。当然也欢迎大家积极交流,并对文中的错误提出宝贵意见。
MORE:
本文同步发布在腾讯云+社区Elasticsearch专栏:https://cloud.tencent.com/developer/column/4008
Elasticsearch是当前主流的分布式大数据存储和搜索引擎,可以为用户提供强大的全文本检索能力,广泛应用于日志检索,全站搜索等领域。Logstash作为Elasicsearch常用的实时数据采集引擎,可以采集来自不同数据源的数据,并对数据进行处理后输出到多种输出源,是Elastic Stack 的重要组成部分。本文从Logstash的工作原理,使用示例,部署方式及性能调优等方面入手,为大家提供一个快速入门Logstash的方式。文章最后也给出了一些深入了解Logstash的的链接,以方便大家根据需要详细了解。
1 Logstash工作原理
1.1 处理过程
如上图,Logstash的数据处理过程主要包括:Inputs, Filters, Outputs 三部分, 另外在Inputs和Outputs中可以使用Codecs对数据格式进行处理。这四个部分均以插件形式存在,用户通过定义pipeline配置文件,设置需要使用的input,filter,output, codec插件,以实现特定的数据采集,数据处理,数据输出等功能
- (1)Inputs:用于从数据源获取数据,常见的插件如file, syslog, redis, beats 等[详细参考]
- (2)Filters:用于处理数据如格式转换,数据派生等,常见的插件如grok, mutate, drop, clone, geoip等[详细参考]
- (3)Outputs:用于数据输出,常见的插件如elastcisearch,file, graphite, statsd等[详细参考]
- (4)Codecs:Codecs不是一个单独的流程,而是在输入和输出等插件中用于数据转换的模块,用于对数据进行编码处理,常见的插件如json,multiline[详细参考]
可以点击每个模块后面的_详细参考_链接了解该模块的插件列表及对应功能
1.2 执行模型:
- (1)每个Input启动一个线程,从对应数据源获取数据
- (2)Input会将数据写入一个队列:默认为内存中的有界队列(意外停止会导致数据丢失)。为了防止数丢失Logstash提供了两个特性: Persistent Queues:通过磁盘上的queue来防止数据丢失 Dead Letter Queues:保存无法处理的event(仅支持Elasticsearch作为输出源)
- (3)Logstash会有多个pipeline worker, 每一个pipeline worker会从队列中取一批数据,然后执行filter和output(worker数目及每次处理的数据量均由配置确定)
2 Logstash使用示例
2.1 Logstash Hello world
第一个示例Logstash将采用标准输入和标准输出作为input和output,并且不指定filter
- (1)下载Logstash并解压(需要预先安装JDK8)
- (2)cd到Logstash的根目录,并执行启动命令如下:
cd logstash-6.4.0
bin/logstash -e 'input { stdin { } } output { stdout {} }'- (3)此时Logstash已经启动成功,-e表示在启动时直接指定pipeline配置,当然也可以将该配置写入一个配置文件中,然后通过指定配置文件来启动
- (4)在控制台输入:hello world,可以看到如下输出:
{
"@version" => "1",
"host" => "localhost",
"@timestamp" => 2018-09-18T12:39:38.514Z,
"message" => "hello world"
} Logstash会自动为数据添加@version, host, @timestamp等字段
在这个示例中Logstash从标准输入中获得数据,仅在数据中添加一些简单字段后将其输出到标准输出。
2.2 日志采集
这个示例将采用Filebeat input插件(Elastic Stack中的轻量级数据采集程序)采集本地日志,然后将结果输出到标准输出
filebeat.yml配置如下(paths改为日志实际位置,不同版本beats配置可能略有变化,请根据情况调整)
filebeat.prospectors:
- input\_type: log
paths:
- /path/to/file/logstash-tutorial.log
output.logstash:
hosts: "localhost:5044"启动命令:
./filebeat -e -c filebeat.yml -d "publish"- (3)配置logstash并启动
1)创建first-pipeline.conf文件内容如下(该文件为pipeline配置文件,用于指定input,filter, output等):
input {
beats {
port => "5044"
}
}
#filter {
#}
output {
stdout { codec => rubydebug }
}codec => rubydebug用于美化输出[参考]
2)验证配置(注意指定配置文件的路径):
./bin/logstash -f first-pipeline.conf --config.test_and_exit3)启动命令:
./bin/logstash -f first-pipeline.conf --config.reload.automatic--config.reload.automatic选项启用动态重载配置功能
4)预期结果:
可以在Logstash的终端显示中看到,日志文件被读取并处理为如下格式的多条数据
{
"@timestamp" => 2018-10-09T12:22:39.742Z,
"offset" => 24464,
"@version" => "1",
"input_type" => "log",
"beat" => {
"name" => "VM_136_9_centos",
"hostname" => "VM_136_9_centos",
"version" => "5.6.10"
},
"host" => "VM_136_9_centos",
"source" => "/data/home/michelmu/workspace/logstash-tutorial.log",
"message" => "86.1.76.62 - - [04/Jan/2015:05:30:37 +0000] \"GET /style2.css HTTP/1.1\" 200 4877 \"http://www.semicomplete.com/projects/xdotool/\" \"Mozilla/5.0 (X11; Linux x86_64; rv:24.0) Gecko/20140205 Firefox/24.0 Iceweasel/24.3.0\"",
"type" => "log",
"tags" => [
[0] "beats_input_codec_plain_applied"
]
}相对于示例2.1,该示例使用了filebeat input插件从日志中获取一行记录,这也是Elastic stack获取日志数据最常见的一种方式。另外该示例还采用了rubydebug codec 对输出的数据进行显示美化。
2.3 日志格式处理
可以看到虽然示例2.2使用filebeat从日志中读取数据,并将数据输出到标准输出,但是日志内容作为一个整体被存放在message字段中,这样对后续存储及查询都极为不便。可以为该pipeline指定一个grok filter来对日志格式进行处理
- (1)在first-pipeline.conf中增加filter配置如下
input {
beats {
port => "5044"
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}"}
}
}
output {
stdout { codec => rubydebug }
}- (2)到filebeat的根目录下删除之前上报的数据历史(以便重新上报数据),并重启filebeat
sudo rm data/registry
sudo ./filebeat -e -c filebeat.yml -d "publish"- (3)由于之前启动Logstash设置了自动更新配置,因此Logstash不需要重新启动,这个时候可以获取到的日志数据如下:
{
"request" => "/style2.css",
"agent" => "\"Mozilla/5.0 (X11; Linux x86_64; rv:24.0) Gecko/20140205 Firefox/24.0 Iceweasel/24.3.0\"",
"offset" => 24464,
"auth" => "-",
"ident" => "-",
"input_type" => "log",
"verb" => "GET",
"source" => "/data/home/michelmu/workspace/logstash-tutorial.log",
"message" => "86.1.76.62 - - [04/Jan/2015:05:30:37 +0000] \"GET /style2.css HTTP/1.1\" 200 4877 \"http://www.semicomplete.com/projects/xdotool/\" \"Mozilla/5.0 (X11; Linux x86_64; rv:24.0) Gecko/20140205 Firefox/24.0 Iceweasel/24.3.0\"",
"type" => "log",
"tags" => [
[0] "beats_input_codec_plain_applied"
],
"referrer" => "\"http://www.semicomplete.com/projects/xdotool/\"",
"@timestamp" => 2018-10-09T12:24:21.276Z,
"response" => "200",
"bytes" => "4877",
"clientip" => "86.1.76.62",
"@version" => "1",
"beat" => {
"name" => "VM_136_9_centos",
"hostname" => "VM_136_9_centos",
"version" => "5.6.10"
},
"host" => "VM_136_9_centos",
"httpversion" => "1.1",
"timestamp" => "04/Jan/2015:05:30:37 +0000"
}可以看到message中的数据被详细解析出来了
2.4 数据派生和增强
Logstash中的一些filter可以根据现有数据生成一些新的数据,如geoip可以根据ip生成经纬度信息
- (1)在first-pipeline.conf中增加geoip配置如下
input {
beats {
port => "5044"
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}"}
}
geoip {
source => "clientip"
}
}
output {
stdout { codec => rubydebug }
}- (2)如2.3一样清空filebeat历史数据,并重启
- (3)当然Logstash仍然不需要重启,可以看到输出变为如下:
{
"request" => "/style2.css",
"agent" => "\"Mozilla/5.0 (X11; Linux x86_64; rv:24.0) Gecko/20140205 Firefox/24.0 Iceweasel/24.3.0\"",
"geoip" => {
"timezone" => "Europe/London",
"ip" => "86.1.76.62",
"latitude" => 51.5333,
"continent_code" => "EU",
"city_name" => "Willesden",
"country_name" => "United Kingdom",
"country_code2" => "GB",
"country_code3" => "GB",
"region_name" => "Brent",
"location" => {
"lon" => -0.2333,
"lat" => 51.5333
},
"postal_code" => "NW10",
"region_code" => "BEN",
"longitude" => -0.2333
},
"offset" => 24464,
"auth" => "-",
"ident" => "-",
"input_type" => "log",
"verb" => "GET",
"source" => "/data/home/michelmu/workspace/logstash-tutorial.log",
"message" => "86.1.76.62 - - [04/Jan/2015:05:30:37 +0000] \"GET /style2.css HTTP/1.1\" 200 4877 \"http://www.semicomplete.com/projects/xdotool/\" \"Mozilla/5.0 (X11; Linux x86_64; rv:24.0) Gecko/20140205 Firefox/24.0 Iceweasel/24.3.0\"",
"type" => "log",
"tags" => [
[0] "beats_input_codec_plain_applied"
],
"referrer" => "\"http://www.semicomplete.com/projects/xdotool/\"",
"@timestamp" => 2018-10-09T12:37:46.686Z,
"response" => "200",
"bytes" => "4877",
"clientip" => "86.1.76.62",
"@version" => "1",
"beat" => {
"name" => "VM_136_9_centos",
"hostname" => "VM_136_9_centos",
"version" => "5.6.10"
},
"host" => "VM_136_9_centos",
"httpversion" => "1.1",
"timestamp" => "04/Jan/2015:05:30:37 +0000"
}可以看到根据ip派生出了许多地理位置信息数据
2.5 将数据导入Elasticsearch
Logstash作为Elastic stack的重要组成部分,其最常用的功能是将数据导入到Elasticssearch中。将Logstash中的数据导入到Elasticsearch中操作也非常的方便,只需要在pipeline配置文件中增加Elasticsearch的output即可。
- (1)首先要有一个已经部署好的Logstash,当然可以使用腾讯云快速创建一个Elasticsearch创建地址
- (2)在first-pipeline.conf中增加Elasticsearch的配置,如下
input {
beats {
port => "5044"
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}"}
}
geoip {
source => "clientip"
}
}
output {
elasticsearch {
hosts => [ "localhost:9200" ]
}
}- (3)清理filebeat历史数据,并重启
- (4)查询Elasticsearch确认数据是否正常上传(注意替换查询语句中的日期)
curl -XGET 'http://172.16.16.17:9200/logstash-2018.10.09/_search?pretty&q=response=200'- (5)如果Elasticsearch关联了Kibana也可以使用kibana查看数据是否正常上报
Logstash提供了大量的Input, filter, output, codec的插件,用户可以根据自己的需要,使用一个或多个组件实现自己的功能,当然用户也可以自定义插件以实现更为定制化的功能。自定义插件可以参考[logstash input插件开发]
3 部署Logstash
演示过如何快速使用Logstash后,现在详细讲述一下Logstash的部署方式。
3.1 安装
- 安装JDK:Logstash采用JRuby编写,运行需要JDK环境,因此安装Logstash前需要先安装JDK。(当前6.4仅支持JDK8)
- 安装Logstash:可以采用直接下载压缩包方式安装,也通过APT或YUM安装,另外Logstash支持安装到Docker中。[Logstash安装参考]
- 安装X-PACK:在6.3及之后版本X-PACK会随Logstash安装,在此之前需要手动安装[参考链接]
3.2 目录结构
logstash的目录主要包括:根目录、bin目录、配置目录、日志目录、插件目录、数据目录
不同安装方式各目录的默认位置参考[此处]
3.3 配置文件
- Pipeline配置文件,名称可以自定义,在启动Logstash时显式指定,编写方式可以参考前面示例,对于具体插件的配置方式参见具体插件的说明(使用Logstash时必须配置): 用于定义一个pipeline,数据处理方式和输出源
- Settings配置文件(可以使用默认配置): 在使用Logstash时可以不用设置,用于性能调优,日志记录等
- 为了保证敏感配置的安全性,logstash提供了配置加密功能[参考链接]
3.4 启动关闭方式
3.4.1 启动
- 命令行启动
- 在debian和rpm上以服务形式启动
- 在docker中启动3.4.2 关闭
- 关闭Logstash
- Logstash的关闭时会先关闭input停止输入,然后处理完所有进行中的事件,然后才完全停止,以防止数据丢失,但这也导致停止过程出现延迟或失败的情况。
3.5 扩展Logstash
当单个Logstash无法满足性能需求时,可以采用横向扩展的方式来提高Logstash的处理能力。横向扩展的多个Logstash相互独立,采用相同的pipeline配置,另外可以在这多个Logstash前增加一个LoadBalance,以实现多个Logstash的负载均衡。
4 性能调优
[详细调优参考]
- (1)Inputs和Outputs的性能:当输入输出源的性能已经达到上限,那么性能瓶颈不在Logstash,应优先对输入输出源的性能进行调优。
- (2)系统性能指标:
- CPU:确定CPU使用率是否过高,如果CPU过高则先查看JVM堆空间使用率部分,确认是否为GC频繁导致,如果GC正常,则可以通过调节Logstash worker相关配置来解决。
- 内存:由于Logstash运行在JVM上,因此注意调整JVM堆空间上限,以便其有足够的运行空间。另外注意Logstash所在机器上是否有其他应用占用了大量内存,导致Logstash内存磁盘交换频繁。
- I/O使用率: 1)磁盘IO: 磁盘IO饱和可能是因为使用了会导致磁盘IO饱和的创建(如file output),另外Logstash中出现错误产生大量错误日志时也会导致磁盘IO饱和。Linux下可以通过iostat, dstat等查看磁盘IO情况 2)网络IO: 网络IO饱和一般发生在使用有大量网络操作的插件时。linux下可以使用dstat或iftop等查看网络IO情况
- (3)JVM堆检查:
- 如果JVM堆大小设置过小会导致GC频繁,从而导致CPU使用率过高
- 快速验证这个问题的方法是double堆大小,看性能是否有提升。注意要给系统至少预留1GB的空间。
- 为了精确查找问题可以使用jmap或VisualVM。[参考]
- 设置Xms和Xmx为相同值,防止堆大小在运行时调整,这个过程非常消耗性能。
- (4)Logstash worker设置:
worker相关配置在logstash.yml中,主要包括如下三个:
- pipeline.workers: 该参数用以指定Logstash中执行filter和output的线程数,当如果发现CPU使用率尚未达到上限,可以通过调整该参数,为Logstash提供更高的性能。建议将Worker数设置适当超过CPU核数可以减少IO等待时间对处理过程的影响。实际调优中可以先通过-w指定该参数,当确定好数值后再写入配置文件中。
- pipeline.batch.size: 该指标用于指定单个worker线程一次性执行flilter和output的event批量数。增大该值可以减少IO次数,提高处理速度,但是也以为这增加内存等资源的消耗。当与Elasticsearch联用时,该值可以用于指定Elasticsearch一次bluck操作的大小。
- pipeline.batch.delay: 该指标用于指定worker等待时间的超时时间,如果worker在该时间内没有等到pipeline.batch.size个事件,那么将直接开始执行filter和output而不再等待。
结束语
Logstash作为Elastic Stack的重要组成部分,在Elasticsearch数据采集和处理过程中扮演着重要的角色。本文通过简单示例的演示和Logstash基础知识的铺陈,希望可以帮助初次接触Logstash的用户对Logstash有一个整体认识,并能较为快速上手。对于Logstash的高阶使用,仍需要用户在使用过程中结合实际情况查阅相关资源深入研究。当然也欢迎大家积极交流,并对文中的错误提出宝贵意见。
MORE:
收起阅读 »当Elasticsearch遇见Kafka--Kafka Connect
本文同步发布在腾讯云+社区Elasticsearch专栏中:https://cloud.tencent.com/developer/column/4008
在“当Elasticsearch遇见Kafka--Logstash kafka input插件”一文中,我对Logstash的Kafka input插件进行了简单的介绍,并通过实际操作的方式,为大家呈现了使用该方式实现Kafka与Elastisearch整合的基本过程。可以看出使用Logstash input插件的方式,具有配置简单,数据处理方便等优点。然而使用Logstash Kafka插件并不是Kafka与Elsticsearch整合的唯一方案,另一种比较常见的方案是使用Kafka的开源组件Kafka Connect。

1 Kafka Connect简介
Kafka Connect是Kafka的开源组件Confluent提供的功能,用于实现Kafka与外部系统的连接。Kafka Connect同时支持分布式模式和单机模式,另外提供了一套完整的REST接口,用于查看和管理Kafka Connectors,还具有offset自动管理,可扩展等优点。
Kafka connect分为企业版和开源版,企业版在开源版的基础之上提供了监控,负载均衡,副本等功能,实际生产环境中建议使用企业版。(本测试使用开源版)
Kafka connect workers有两种工作模式,单机模式和分布式模式。在开发和适合使用单机模式的场景下,可以使用standalone模式, 在实际生产环境下由于单个worker的数据压力会比较大,distributed模式对负载均和和扩展性方面会有很大帮助。(本测试使用standalone模式)
关于Kafka Connect的详细情况可以参考[Kafka Connect]
2 使用Kafka Connect连接Kafka和Elasticsearch
2.1 测试环境准备
本文与使用Logstash Kafka input插件环境一样[传送门],组件列表如下
| 服务 | ip | port |
|---|---|---|
| Elasticsearch service | 192.168.0.8 | 9200 |
| Ckafka | 192.168.13.10 | 9092 |
| CVM | 192.168.0.13 | - |
kafka topic也复用原来了的kafka_es_test
2.2 Kafka Connect 安装
本文下载的为开源版本confluent-oss-5.0.1-2.11.tar.gz,下载后解压
2.3 Worker配置
1) 配置参考
如前文所说,worker分为Standalone和Distributed两种模式,针对两种模式的配置,参考如下
[通用配置]
此处需要注意的是Kafka Connect默认使用AvroConverter,使用该AvroConverter时需要注意必须启动Schema Registry服务
2) 实际操作
本测试使用standalone模式,因此修改/root/confluent-5.0.1/etc/schema-registry/connect-avro-standalone.properties
bootstrap.servers=192.168.13.10:90922.4 Elasticsearch Connector配置
1) 配置参考
[Elasticsearch Configuration Options]
2) 实际操作
修改/root/confluent-5.0.1/etc/kafka-connect-elasticsearch/quickstart-elasticsearch.properties
name=elasticsearch-sink
connector.class=io.confluent.connect.elasticsearch.ElasticsearchSinkConnector
tasks.max=1
topics=kafka_es_test
key.ignore=true
connection.url=http://192.168.0.8:9200
type.name=kafka-connect注意: 其中topics不仅对应Kafka的topic名称,同时也是Elasticsearch的索引名,当然也可以通过topic.index.map来设置从topic名到Elasticsearch索引名的映射
2.5 启动connector
1 注意事项
1) 由于配置文件中jar包位置均采用的相对路径,因此建议在confluent根目录下执行命令和启动程序,以避免不必要的问题
2) 如果前面没有修改converter,仍采用AvroConverter, 注意需要在启动connertor前启动Schema Registry服务
2 启动Schema Registry服务
正如前文所说,由于在配置worker时指定使用了AvroConverter,因此需要启动Schema Registry服务。而该服务需要指定一个zookeeper地址或Kafka地址,以存储schema数据。由于CKafka不支持用户通过接口形式创建topic,因此需要在本机起一个kafka以创建名为_schema的topic。
1) 启动Zookeeper
./bin/zookeeper-server-start -daemon etc/kafka/zookeeper.properties2) 启动kafka
./bin/kafka-server-start -daemon etc/kafka/server.properties3) 启动schema Registry
./bin/schema-registry-start -daemon etc/schema-registry/schema-registry.properties4) 使用netstat -natpl 查看各服务端口是否正常启动
zookeeper 2181
kafka 9092
schema registry 8081
3 启动Connector
./bin/connect-standalone -daemon etc/schema-registry/connect-avro-standalone.properties etc/kafka-connect-elasticsearch/quickstart-elasticsearch.propertiesps:以上启动各服务均可在logs目录下找到对应日志
2.6 启动Kafka Producer
由于我们采用的是AvroConverter,因此不能采用Kafka工具包中的producer。Kafka Connector bin目录下提供了Avro Producer
1) 启动Producer
./bin/kafka-avro-console-producer --broker-list 192.168.13.10:9092 --topic kafka_es_test --property value.schema='{"type":"record","name":"person","fields":[{"name":"nickname","type":"string"}]}'2) 输入如下数据
{"nickname":"michel"}
{"nickname":"mushao"}2.7 Kibana验证结果
1) 查看索引
在kibana Dev Tools的Console中输入
GET _cat/indices结果
green open kafka_es_test 36QtDP6vQOG7ubOa161wGQ 5 1 1 0 7.9kb 3.9kb
green open .kibana QUw45tN0SHqeHbF9-QVU6A 1 1 1 0 5.5kb 2.7kb可以看到名为kafka_es_test的索引被成功创建
2) 查看数据
{
"took": 0,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 1,
"hits": [
{
"_index": "kafka_es_test",
"_type": "kafka-connect",
"_id": "kafka_es_test+0+0",
"_score": 1,
"_source": {
"nickname": "michel"
}
},
{
"_index": "kafka_es_test",
"_type": "kafka-connect",
"_id": "kafka_es_test+0+1",
"_score": 1,
"_source": {
"nickname": "mushao"
}
}
]
}
}可以看到数据已经被成功写入
3 Confluent CLI
3.1 简介
查阅资料时发现很多文章都是使用Confluent CLI启动Kafka Connect,然而官方文档已经明确说明了该CLI只是适用于开发阶段,不能用于生产环境。
它可以一键启动包括zookeeper,kafka,schema registry, kafka rest, connect等在内的多个服务。但是这些服务对于Kafka Connect都不是必须的,如果不使用AvroConverter,则只需要启动Connect即可。即使使用了AvroConverter, 也只需要启动schema registry,将schema保存在远端的kafka中。Kafka Connect REST API也只是为用户提供一个管理connector的接口,也不是必选的。
另外使用CLI启动默认配置为启动Distributed的Connector,需要通过环境变量来修改配置
3.2 使用Confluent CLI
confluent CLI提供了丰富的命令,包括服务启动,服务停止,状态查询,日志查看等,详情参考如下简介视频 [Introducing the Confluent CLI | Screencast]
1) 启动
./bin/confluent start2) 检查confluent运行状态
./bin/confluent status当得到如下结果则说明confluent启动成功
ksql-server is [UP]
connect is [UP]
kafka-rest is [UP]
schema-registry is [UP]
kafka is [UP]
zookeeper is [UP]3) 问题定位
如果第二步出现问题,可以使用log命令查看,如connect未启动成功则
./bin/confluent log connect4) 加载Elasticsearch Connector
a) 查看connector
./bin/confluent list connectors结果
Bundled Predefined Connectors (edit configuration under etc/):
elasticsearch-sink
file-source
file-sink
jdbc-source
jdbc-sink
hdfs-sink
s3-sinkb) 加载Elasticsearch connector
./bin/confluent load elasticsearch-sink结果
{
"name": "elasticsearch-sink",
"config": {
"connector.class": "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector",
"tasks.max": "1",
"topics": "kafka_es_test",
"key.ignore": "true",
"connection.url": "http://192.168.0.8:9200",
"type.name": "kafka-connect",
"name": "elasticsearch-sink"
},
"tasks": [],
"type": null
}5) 使用producer生产数据,并使用kibana验证是否写入成功
4 Kafka Connect Rest API
Kafka Connect提供了一套完成的管理Connector的接口,详情参考[Kafka Connect REST Interface]。该接口可以实现对Connector的创建,销毁,修改,查询等操作
1) GET connectors 获取运行中的connector列表
2) POST connectors 使用指定的名称和配置创建connector
3) GET connectors/(string:name) 获取connector的详细信息
4) GET connectors/(string:name)/config 获取connector的配置
5) PUT connectors/(string:name)/config 设置connector的配置
6) GET connectors/(string:name)/status 获取connector状态
7) POST connectors/(stirng:name)/restart 重启connector
8) PUT connectors/(string:name)/pause 暂停connector
9) PUT connectors/(string:name)/resume 恢复connector
10) DELETE connectors/(string:name)/ 删除connector
11) GET connectors/(string:name)/tasks 获取connectors任务列表
12) GET /connectors/(string: name)/tasks/(int: taskid)/status 获取任务状态
13) POST /connectors/(string: name)/tasks/(int: taskid)/restart 重启任务
14) GET /connector-plugins/ 获取已安装插件列表
15) PUT /connector-plugins/(string: name)/config/validate 验证配置
5 总结
Kafka Connect是Kafka一个功能强大的组件,为kafka提供了与外部系统连接的一套完整方案,包括数据传输,连接管理,监控,多副本等。相对于Logstash Kafka插件,功能更为全面,但配置也相对为复杂些。有文章提到其性能也优于Logstash Kafka Input插件,如果对写入性能比较敏感的场景,可以在实际压测的基础上进行选择。另外由于直接将数据从Kafka写入Elasticsearch, 如果需要对文档进行处理时,选择Logstash可能更为方便。
本文同步发布在腾讯云+社区Elasticsearch专栏中:https://cloud.tencent.com/developer/column/4008
在“当Elasticsearch遇见Kafka--Logstash kafka input插件”一文中,我对Logstash的Kafka input插件进行了简单的介绍,并通过实际操作的方式,为大家呈现了使用该方式实现Kafka与Elastisearch整合的基本过程。可以看出使用Logstash input插件的方式,具有配置简单,数据处理方便等优点。然而使用Logstash Kafka插件并不是Kafka与Elsticsearch整合的唯一方案,另一种比较常见的方案是使用Kafka的开源组件Kafka Connect。
1 Kafka Connect简介
Kafka Connect是Kafka的开源组件Confluent提供的功能,用于实现Kafka与外部系统的连接。Kafka Connect同时支持分布式模式和单机模式,另外提供了一套完整的REST接口,用于查看和管理Kafka Connectors,还具有offset自动管理,可扩展等优点。
Kafka connect分为企业版和开源版,企业版在开源版的基础之上提供了监控,负载均衡,副本等功能,实际生产环境中建议使用企业版。(本测试使用开源版)
Kafka connect workers有两种工作模式,单机模式和分布式模式。在开发和适合使用单机模式的场景下,可以使用standalone模式, 在实际生产环境下由于单个worker的数据压力会比较大,distributed模式对负载均和和扩展性方面会有很大帮助。(本测试使用standalone模式)
关于Kafka Connect的详细情况可以参考[Kafka Connect]
2 使用Kafka Connect连接Kafka和Elasticsearch
2.1 测试环境准备
本文与使用Logstash Kafka input插件环境一样[传送门],组件列表如下
| 服务 | ip | port |
|---|---|---|
| Elasticsearch service | 192.168.0.8 | 9200 |
| Ckafka | 192.168.13.10 | 9092 |
| CVM | 192.168.0.13 | - |
kafka topic也复用原来了的kafka_es_test
2.2 Kafka Connect 安装
本文下载的为开源版本confluent-oss-5.0.1-2.11.tar.gz,下载后解压
2.3 Worker配置
1) 配置参考
如前文所说,worker分为Standalone和Distributed两种模式,针对两种模式的配置,参考如下
[通用配置]
此处需要注意的是Kafka Connect默认使用AvroConverter,使用该AvroConverter时需要注意必须启动Schema Registry服务
2) 实际操作
本测试使用standalone模式,因此修改/root/confluent-5.0.1/etc/schema-registry/connect-avro-standalone.properties
bootstrap.servers=192.168.13.10:90922.4 Elasticsearch Connector配置
1) 配置参考
[Elasticsearch Configuration Options]
2) 实际操作
修改/root/confluent-5.0.1/etc/kafka-connect-elasticsearch/quickstart-elasticsearch.properties
name=elasticsearch-sink
connector.class=io.confluent.connect.elasticsearch.ElasticsearchSinkConnector
tasks.max=1
topics=kafka_es_test
key.ignore=true
connection.url=http://192.168.0.8:9200
type.name=kafka-connect注意: 其中topics不仅对应Kafka的topic名称,同时也是Elasticsearch的索引名,当然也可以通过topic.index.map来设置从topic名到Elasticsearch索引名的映射
2.5 启动connector
1 注意事项
1) 由于配置文件中jar包位置均采用的相对路径,因此建议在confluent根目录下执行命令和启动程序,以避免不必要的问题
2) 如果前面没有修改converter,仍采用AvroConverter, 注意需要在启动connertor前启动Schema Registry服务
2 启动Schema Registry服务
正如前文所说,由于在配置worker时指定使用了AvroConverter,因此需要启动Schema Registry服务。而该服务需要指定一个zookeeper地址或Kafka地址,以存储schema数据。由于CKafka不支持用户通过接口形式创建topic,因此需要在本机起一个kafka以创建名为_schema的topic。
1) 启动Zookeeper
./bin/zookeeper-server-start -daemon etc/kafka/zookeeper.properties2) 启动kafka
./bin/kafka-server-start -daemon etc/kafka/server.properties3) 启动schema Registry
./bin/schema-registry-start -daemon etc/schema-registry/schema-registry.properties4) 使用netstat -natpl 查看各服务端口是否正常启动
zookeeper 2181
kafka 9092
schema registry 8081
3 启动Connector
./bin/connect-standalone -daemon etc/schema-registry/connect-avro-standalone.properties etc/kafka-connect-elasticsearch/quickstart-elasticsearch.propertiesps:以上启动各服务均可在logs目录下找到对应日志
2.6 启动Kafka Producer
由于我们采用的是AvroConverter,因此不能采用Kafka工具包中的producer。Kafka Connector bin目录下提供了Avro Producer
1) 启动Producer
./bin/kafka-avro-console-producer --broker-list 192.168.13.10:9092 --topic kafka_es_test --property value.schema='{"type":"record","name":"person","fields":[{"name":"nickname","type":"string"}]}'2) 输入如下数据
{"nickname":"michel"}
{"nickname":"mushao"}2.7 Kibana验证结果
1) 查看索引
在kibana Dev Tools的Console中输入
GET _cat/indices结果
green open kafka_es_test 36QtDP6vQOG7ubOa161wGQ 5 1 1 0 7.9kb 3.9kb
green open .kibana QUw45tN0SHqeHbF9-QVU6A 1 1 1 0 5.5kb 2.7kb可以看到名为kafka_es_test的索引被成功创建
2) 查看数据
{
"took": 0,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 1,
"hits": [
{
"_index": "kafka_es_test",
"_type": "kafka-connect",
"_id": "kafka_es_test+0+0",
"_score": 1,
"_source": {
"nickname": "michel"
}
},
{
"_index": "kafka_es_test",
"_type": "kafka-connect",
"_id": "kafka_es_test+0+1",
"_score": 1,
"_source": {
"nickname": "mushao"
}
}
]
}
}可以看到数据已经被成功写入
3 Confluent CLI
3.1 简介
查阅资料时发现很多文章都是使用Confluent CLI启动Kafka Connect,然而官方文档已经明确说明了该CLI只是适用于开发阶段,不能用于生产环境。
它可以一键启动包括zookeeper,kafka,schema registry, kafka rest, connect等在内的多个服务。但是这些服务对于Kafka Connect都不是必须的,如果不使用AvroConverter,则只需要启动Connect即可。即使使用了AvroConverter, 也只需要启动schema registry,将schema保存在远端的kafka中。Kafka Connect REST API也只是为用户提供一个管理connector的接口,也不是必选的。
另外使用CLI启动默认配置为启动Distributed的Connector,需要通过环境变量来修改配置
3.2 使用Confluent CLI
confluent CLI提供了丰富的命令,包括服务启动,服务停止,状态查询,日志查看等,详情参考如下简介视频 [Introducing the Confluent CLI | Screencast]
1) 启动
./bin/confluent start2) 检查confluent运行状态
./bin/confluent status当得到如下结果则说明confluent启动成功
ksql-server is [UP]
connect is [UP]
kafka-rest is [UP]
schema-registry is [UP]
kafka is [UP]
zookeeper is [UP]3) 问题定位
如果第二步出现问题,可以使用log命令查看,如connect未启动成功则
./bin/confluent log connect4) 加载Elasticsearch Connector
a) 查看connector
./bin/confluent list connectors结果
Bundled Predefined Connectors (edit configuration under etc/):
elasticsearch-sink
file-source
file-sink
jdbc-source
jdbc-sink
hdfs-sink
s3-sinkb) 加载Elasticsearch connector
./bin/confluent load elasticsearch-sink结果
{
"name": "elasticsearch-sink",
"config": {
"connector.class": "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector",
"tasks.max": "1",
"topics": "kafka_es_test",
"key.ignore": "true",
"connection.url": "http://192.168.0.8:9200",
"type.name": "kafka-connect",
"name": "elasticsearch-sink"
},
"tasks": [],
"type": null
}5) 使用producer生产数据,并使用kibana验证是否写入成功
4 Kafka Connect Rest API
Kafka Connect提供了一套完成的管理Connector的接口,详情参考[Kafka Connect REST Interface]。该接口可以实现对Connector的创建,销毁,修改,查询等操作
1) GET connectors 获取运行中的connector列表
2) POST connectors 使用指定的名称和配置创建connector
3) GET connectors/(string:name) 获取connector的详细信息
4) GET connectors/(string:name)/config 获取connector的配置
5) PUT connectors/(string:name)/config 设置connector的配置
6) GET connectors/(string:name)/status 获取connector状态
7) POST connectors/(stirng:name)/restart 重启connector
8) PUT connectors/(string:name)/pause 暂停connector
9) PUT connectors/(string:name)/resume 恢复connector
10) DELETE connectors/(string:name)/ 删除connector
11) GET connectors/(string:name)/tasks 获取connectors任务列表
12) GET /connectors/(string: name)/tasks/(int: taskid)/status 获取任务状态
13) POST /connectors/(string: name)/tasks/(int: taskid)/restart 重启任务
14) GET /connector-plugins/ 获取已安装插件列表
15) PUT /connector-plugins/(string: name)/config/validate 验证配置
5 总结
Kafka Connect是Kafka一个功能强大的组件,为kafka提供了与外部系统连接的一套完整方案,包括数据传输,连接管理,监控,多副本等。相对于Logstash Kafka插件,功能更为全面,但配置也相对为复杂些。有文章提到其性能也优于Logstash Kafka Input插件,如果对写入性能比较敏感的场景,可以在实际压测的基础上进行选择。另外由于直接将数据从Kafka写入Elasticsearch, 如果需要对文档进行处理时,选择Logstash可能更为方便。
收起阅读 »社区日报 第451期 (2018-11-17)
-
如何迁移到kibana空间 http://t.cn/E2yMhZi
-
利用kibana空间优化管理权限。 http://t.cn/E2yJq1b
- Elasitcsearch索引优化。 http://t.cn/E2y6afZ
-
如何迁移到kibana空间 http://t.cn/E2yMhZi
-
利用kibana空间优化管理权限。 http://t.cn/E2yJq1b
- Elasitcsearch索引优化。 http://t.cn/E2y6afZ
社区日报 第450期 (2018-11-16)
http://t.cn/E2PPJH2
2、Elastic开启了大数据应用新时代
http://t.cn/E2PPCmn
3、图解elasticsearch原理
http://t.cn/E2PPThd
编辑:铭毅天下
归档:https://elasticsearch.cn/article/6138
订阅:https://tinyletter.com/elastic-daily
http://t.cn/E2PPJH2
2、Elastic开启了大数据应用新时代
http://t.cn/E2PPCmn
3、图解elasticsearch原理
http://t.cn/E2PPThd
编辑:铭毅天下
归档:https://elasticsearch.cn/article/6138
订阅:https://tinyletter.com/elastic-daily 收起阅读 »
社区日报 第449期 (2018-11-15)
http://t.cn/EwZO5to
2.一个让elastalert报警更简单的UI
http://t.cn/EAgg8WQ
3.Filebeat优化实践
http://t.cn/EAge74i
编辑:金桥
归档:https://elasticsearch.cn/article/6137
订阅:https://tinyletter.com/elastic-daily
http://t.cn/EwZO5to
2.一个让elastalert报警更简单的UI
http://t.cn/EAgg8WQ
3.Filebeat优化实践
http://t.cn/EAge74i
编辑:金桥
归档:https://elasticsearch.cn/article/6137
订阅:https://tinyletter.com/elastic-daily 收起阅读 »
ES 6.4.3 X-PACK 启用安装配置
我基于最新的版本整理了下启用X-PACK功能。坑比较多,给我的感觉与searchguard 搞得越来越像了……
比较坑的是 transport(9300) 必须要用SSL…… 大家注意下。 6比5复杂多了……
Configure each node to:
Required: Enable TLS on the transport layer.
Recommended: Enable TLS on the HTTP layer.
参考:
https://www.elastic.co/guide/e ... .html
- ES 设置
- 配置 TLS/SSL
- 配置ES(x-pack认证)
- 启动ES
- 配置密码
- 配置kibana
1 Elasticsearch.yml 文件添加内容
xpack.security.enabled: true
2 .1生成CA证书
./elasticsearch-certutil ca
2.2 生成客户端证书
./elasticsearch-certutil cert --ca
2.3ES启用SSL配置文件
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.keystore.path: xxx.p12
xpack.security.transport.ssl.truststore.path: xxx.p12
2.4 keystore 添加内容
./elasticsearch-keystore add xpack.security.transport.ssl.keystore.secure_password
3启用相关功能
xpack.monitoring.enabled: true
xpack.graph.enabled: true
xpack.ml.enabled: true
xpack.security.enabled: true
xpack.watcher.enabled: true
xpack.security.authc.accept_default_password: false
xpack.security.transport.ssl.enabled: true
xpack.monitoring.collection.cluster.stats.timeout: 30m
xpack.monitoring.collection.index.stats.timeout: 30m
xpack.monitoring.collection.index.recovery.active_only: true
xpack.monitoring.collection.index.recovery.timeout: 30m
xpack.monitoring.history.duration: 3650d
4 启动ES
./elasticsearch -d 每台
5配置密码
./elasticsearch-setup-passwords
6汉化kibana 这玩意我还没有整理完,5差不多搞完了。
7开始浪
6版本

5版本



我基于最新的版本整理了下启用X-PACK功能。坑比较多,给我的感觉与searchguard 搞得越来越像了……
比较坑的是 transport(9300) 必须要用SSL…… 大家注意下。 6比5复杂多了……
Configure each node to:
Required: Enable TLS on the transport layer.
Recommended: Enable TLS on the HTTP layer.
参考:
https://www.elastic.co/guide/e ... .html
- ES 设置
- 配置 TLS/SSL
- 配置ES(x-pack认证)
- 启动ES
- 配置密码
- 配置kibana
1 Elasticsearch.yml 文件添加内容
xpack.security.enabled: true
2 .1生成CA证书
./elasticsearch-certutil ca
2.2 生成客户端证书
./elasticsearch-certutil cert --ca
2.3ES启用SSL配置文件
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.keystore.path: xxx.p12
xpack.security.transport.ssl.truststore.path: xxx.p12
2.4 keystore 添加内容
./elasticsearch-keystore add xpack.security.transport.ssl.keystore.secure_password
3启用相关功能
xpack.monitoring.enabled: true
xpack.graph.enabled: true
xpack.ml.enabled: true
xpack.security.enabled: true
xpack.watcher.enabled: true
xpack.security.authc.accept_default_password: false
xpack.security.transport.ssl.enabled: true
xpack.monitoring.collection.cluster.stats.timeout: 30m
xpack.monitoring.collection.index.stats.timeout: 30m
xpack.monitoring.collection.index.recovery.active_only: true
xpack.monitoring.collection.index.recovery.timeout: 30m
xpack.monitoring.history.duration: 3650d
4 启动ES
./elasticsearch -d 每台
5配置密码
./elasticsearch-setup-passwords
6汉化kibana 这玩意我还没有整理完,5差不多搞完了。
7开始浪
6版本
5版本
【 报名已结束】2018 Elastic & 东方航空大数据技术沙龙
上海米哈游高薪诚聘运维开发工程师,待遇15k-30k
工作职责:
负责网络游戏业务的部署、发布、变更;
负责新游戏的接入、架构评估、痛点挖掘优化;
负责监控网络游戏业务的运行状况,及时处理游戏运行中出现的故障,保障网络游戏服务的正常提供;
负责与游戏运营项目组的日常沟通交流,接受并处理项目组提出的运维需求;
针对各系统编写并维护自动化运维脚本;
负责项目组相关运营支撑工具的开发(Python);
负责日常运维工作的自动化、工具化建设;
参与游戏大数据挖掘与分析;
工作要求:
本科以上学历,计算机类或相关专业;
3年以上互联网行业经验、2年以上的批量服务器维护经验;
有开发经验,掌握Python、Bash、Sed、Awk等编程语言;
有较强的抗压能力、沟通能力、推动能力和较好的服务意识;
善于团队协作、项目管理、主动思考、自我驱动强;
优先(满足之一即可):
熟悉云技术应用阿里云,腾讯云,AWS者优先;
有知名游戏维护经验者优先,有数据挖掘经验者优先;
具有开源精神,能阅读源码,有DEVOPS/大数据平台运维管理经验者优先;
熟悉ELK等实时日志处理相关工作经验优先;
熟悉Docker、K8S原理,有Docker实际应用经验者优先;
联系方式:chen.yang@mihoyo.com
工作职责:
负责网络游戏业务的部署、发布、变更;
负责新游戏的接入、架构评估、痛点挖掘优化;
负责监控网络游戏业务的运行状况,及时处理游戏运行中出现的故障,保障网络游戏服务的正常提供;
负责与游戏运营项目组的日常沟通交流,接受并处理项目组提出的运维需求;
针对各系统编写并维护自动化运维脚本;
负责项目组相关运营支撑工具的开发(Python);
负责日常运维工作的自动化、工具化建设;
参与游戏大数据挖掘与分析;
工作要求:
本科以上学历,计算机类或相关专业;
3年以上互联网行业经验、2年以上的批量服务器维护经验;
有开发经验,掌握Python、Bash、Sed、Awk等编程语言;
有较强的抗压能力、沟通能力、推动能力和较好的服务意识;
善于团队协作、项目管理、主动思考、自我驱动强;
优先(满足之一即可):
熟悉云技术应用阿里云,腾讯云,AWS者优先;
有知名游戏维护经验者优先,有数据挖掘经验者优先;
具有开源精神,能阅读源码,有DEVOPS/大数据平台运维管理经验者优先;
熟悉ELK等实时日志处理相关工作经验优先;
熟悉Docker、K8S原理,有Docker实际应用经验者优先;
联系方式:chen.yang@mihoyo.com
收起阅读 »


