

一文快速上手Logstash
本文同步发布在腾讯云+社区Elasticsearch专栏:https://cloud.tencent.com/developer/column/4008
Elasticsearch是当前主流的分布式大数据存储和搜索引擎,可以为用户提供强大的全文本检索能力,广泛应用于日志检索,全站搜索等领域。Logstash作为Elasicsearch常用的实时数据采集引擎,可以采集来自不同数据源的数据,并对数据进行处理后输出到多种输出源,是Elastic Stack 的重要组成部分。本文从Logstash的工作原理,使用示例,部署方式及性能调优等方面入手,为大家提供一个快速入门Logstash的方式。文章最后也给出了一些深入了解Logstash的的链接,以方便大家根据需要详细了解。
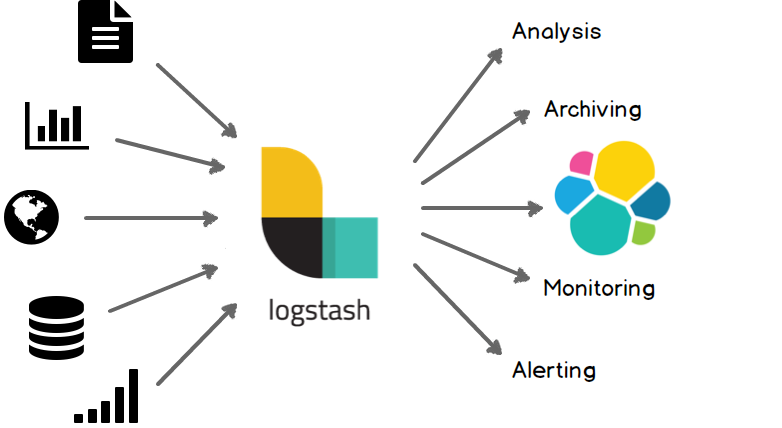
1 Logstash工作原理
1.1 处理过程
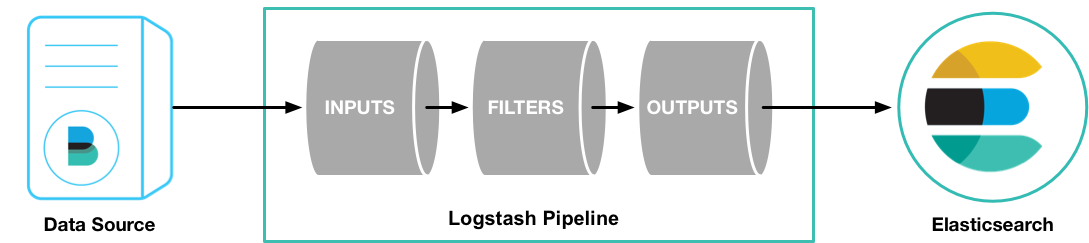
如上图,Logstash的数据处理过程主要包括:Inputs, Filters, Outputs 三部分, 另外在Inputs和Outputs中可以使用Codecs对数据格式进行处理。这四个部分均以插件形式存在,用户通过定义pipeline配置文件,设置需要使用的input,filter,output, codec插件,以实现特定的数据采集,数据处理,数据输出等功能
- (1)Inputs:用于从数据源获取数据,常见的插件如file, syslog, redis, beats 等[详细参考]
- (2)Filters:用于处理数据如格式转换,数据派生等,常见的插件如grok, mutate, drop, clone, geoip等[详细参考]
- (3)Outputs:用于数据输出,常见的插件如elastcisearch,file, graphite, statsd等[详细参考]
- (4)Codecs:Codecs不是一个单独的流程,而是在输入和输出等插件中用于数据转换的模块,用于对数据进行编码处理,常见的插件如json,multiline[详细参考]
可以点击每个模块后面的_详细参考_链接了解该模块的插件列表及对应功能
1.2 执行模型:
- (1)每个Input启动一个线程,从对应数据源获取数据
- (2)Input会将数据写入一个队列:默认为内存中的有界队列(意外停止会导致数据丢失)。为了防止数丢失Logstash提供了两个特性: Persistent Queues:通过磁盘上的queue来防止数据丢失 Dead Letter Queues:保存无法处理的event(仅支持Elasticsearch作为输出源)
- (3)Logstash会有多个pipeline worker, 每一个pipeline worker会从队列中取一批数据,然后执行filter和output(worker数目及每次处理的数据量均由配置确定)
2 Logstash使用示例
2.1 Logstash Hello world
第一个示例Logstash将采用标准输入和标准输出作为input和output,并且不指定filter
- (1)下载Logstash并解压(需要预先安装JDK8)
- (2)cd到Logstash的根目录,并执行启动命令如下:
cd logstash-6.4.0
bin/logstash -e 'input { stdin { } } output { stdout {} }'- (3)此时Logstash已经启动成功,-e表示在启动时直接指定pipeline配置,当然也可以将该配置写入一个配置文件中,然后通过指定配置文件来启动
- (4)在控制台输入:hello world,可以看到如下输出:
{
"@version" => "1",
"host" => "localhost",
"@timestamp" => 2018-09-18T12:39:38.514Z,
"message" => "hello world"
} Logstash会自动为数据添加@version, host, @timestamp等字段
在这个示例中Logstash从标准输入中获得数据,仅在数据中添加一些简单字段后将其输出到标准输出。
2.2 日志采集
这个示例将采用Filebeat input插件(Elastic Stack中的轻量级数据采集程序)采集本地日志,然后将结果输出到标准输出
filebeat.yml配置如下(paths改为日志实际位置,不同版本beats配置可能略有变化,请根据情况调整)
filebeat.prospectors:
- input\_type: log
paths:
- /path/to/file/logstash-tutorial.log
output.logstash:
hosts: "localhost:5044"启动命令:
./filebeat -e -c filebeat.yml -d "publish"- (3)配置logstash并启动
1)创建first-pipeline.conf文件内容如下(该文件为pipeline配置文件,用于指定input,filter, output等):
input {
beats {
port => "5044"
}
}
#filter {
#}
output {
stdout { codec => rubydebug }
}codec => rubydebug用于美化输出[参考]
2)验证配置(注意指定配置文件的路径):
./bin/logstash -f first-pipeline.conf --config.test_and_exit3)启动命令:
./bin/logstash -f first-pipeline.conf --config.reload.automatic--config.reload.automatic选项启用动态重载配置功能
4)预期结果:
可以在Logstash的终端显示中看到,日志文件被读取并处理为如下格式的多条数据
{
"@timestamp" => 2018-10-09T12:22:39.742Z,
"offset" => 24464,
"@version" => "1",
"input_type" => "log",
"beat" => {
"name" => "VM_136_9_centos",
"hostname" => "VM_136_9_centos",
"version" => "5.6.10"
},
"host" => "VM_136_9_centos",
"source" => "/data/home/michelmu/workspace/logstash-tutorial.log",
"message" => "86.1.76.62 - - [04/Jan/2015:05:30:37 +0000] \"GET /style2.css HTTP/1.1\" 200 4877 \"http://www.semicomplete.com/projects/xdotool/\" \"Mozilla/5.0 (X11; Linux x86_64; rv:24.0) Gecko/20140205 Firefox/24.0 Iceweasel/24.3.0\"",
"type" => "log",
"tags" => [
[0] "beats_input_codec_plain_applied"
]
}相对于示例2.1,该示例使用了filebeat input插件从日志中获取一行记录,这也是Elastic stack获取日志数据最常见的一种方式。另外该示例还采用了rubydebug codec 对输出的数据进行显示美化。
2.3 日志格式处理
可以看到虽然示例2.2使用filebeat从日志中读取数据,并将数据输出到标准输出,但是日志内容作为一个整体被存放在message字段中,这样对后续存储及查询都极为不便。可以为该pipeline指定一个grok filter来对日志格式进行处理
- (1)在first-pipeline.conf中增加filter配置如下
input {
beats {
port => "5044"
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}"}
}
}
output {
stdout { codec => rubydebug }
}- (2)到filebeat的根目录下删除之前上报的数据历史(以便重新上报数据),并重启filebeat
sudo rm data/registry
sudo ./filebeat -e -c filebeat.yml -d "publish"- (3)由于之前启动Logstash设置了自动更新配置,因此Logstash不需要重新启动,这个时候可以获取到的日志数据如下:
{
"request" => "/style2.css",
"agent" => "\"Mozilla/5.0 (X11; Linux x86_64; rv:24.0) Gecko/20140205 Firefox/24.0 Iceweasel/24.3.0\"",
"offset" => 24464,
"auth" => "-",
"ident" => "-",
"input_type" => "log",
"verb" => "GET",
"source" => "/data/home/michelmu/workspace/logstash-tutorial.log",
"message" => "86.1.76.62 - - [04/Jan/2015:05:30:37 +0000] \"GET /style2.css HTTP/1.1\" 200 4877 \"http://www.semicomplete.com/projects/xdotool/\" \"Mozilla/5.0 (X11; Linux x86_64; rv:24.0) Gecko/20140205 Firefox/24.0 Iceweasel/24.3.0\"",
"type" => "log",
"tags" => [
[0] "beats_input_codec_plain_applied"
],
"referrer" => "\"http://www.semicomplete.com/projects/xdotool/\"",
"@timestamp" => 2018-10-09T12:24:21.276Z,
"response" => "200",
"bytes" => "4877",
"clientip" => "86.1.76.62",
"@version" => "1",
"beat" => {
"name" => "VM_136_9_centos",
"hostname" => "VM_136_9_centos",
"version" => "5.6.10"
},
"host" => "VM_136_9_centos",
"httpversion" => "1.1",
"timestamp" => "04/Jan/2015:05:30:37 +0000"
}可以看到message中的数据被详细解析出来了
2.4 数据派生和增强
Logstash中的一些filter可以根据现有数据生成一些新的数据,如geoip可以根据ip生成经纬度信息
- (1)在first-pipeline.conf中增加geoip配置如下
input {
beats {
port => "5044"
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}"}
}
geoip {
source => "clientip"
}
}
output {
stdout { codec => rubydebug }
}- (2)如2.3一样清空filebeat历史数据,并重启
- (3)当然Logstash仍然不需要重启,可以看到输出变为如下:
{
"request" => "/style2.css",
"agent" => "\"Mozilla/5.0 (X11; Linux x86_64; rv:24.0) Gecko/20140205 Firefox/24.0 Iceweasel/24.3.0\"",
"geoip" => {
"timezone" => "Europe/London",
"ip" => "86.1.76.62",
"latitude" => 51.5333,
"continent_code" => "EU",
"city_name" => "Willesden",
"country_name" => "United Kingdom",
"country_code2" => "GB",
"country_code3" => "GB",
"region_name" => "Brent",
"location" => {
"lon" => -0.2333,
"lat" => 51.5333
},
"postal_code" => "NW10",
"region_code" => "BEN",
"longitude" => -0.2333
},
"offset" => 24464,
"auth" => "-",
"ident" => "-",
"input_type" => "log",
"verb" => "GET",
"source" => "/data/home/michelmu/workspace/logstash-tutorial.log",
"message" => "86.1.76.62 - - [04/Jan/2015:05:30:37 +0000] \"GET /style2.css HTTP/1.1\" 200 4877 \"http://www.semicomplete.com/projects/xdotool/\" \"Mozilla/5.0 (X11; Linux x86_64; rv:24.0) Gecko/20140205 Firefox/24.0 Iceweasel/24.3.0\"",
"type" => "log",
"tags" => [
[0] "beats_input_codec_plain_applied"
],
"referrer" => "\"http://www.semicomplete.com/projects/xdotool/\"",
"@timestamp" => 2018-10-09T12:37:46.686Z,
"response" => "200",
"bytes" => "4877",
"clientip" => "86.1.76.62",
"@version" => "1",
"beat" => {
"name" => "VM_136_9_centos",
"hostname" => "VM_136_9_centos",
"version" => "5.6.10"
},
"host" => "VM_136_9_centos",
"httpversion" => "1.1",
"timestamp" => "04/Jan/2015:05:30:37 +0000"
}可以看到根据ip派生出了许多地理位置信息数据
2.5 将数据导入Elasticsearch
Logstash作为Elastic stack的重要组成部分,其最常用的功能是将数据导入到Elasticssearch中。将Logstash中的数据导入到Elasticsearch中操作也非常的方便,只需要在pipeline配置文件中增加Elasticsearch的output即可。
- (1)首先要有一个已经部署好的Logstash,当然可以使用腾讯云快速创建一个Elasticsearch创建地址
- (2)在first-pipeline.conf中增加Elasticsearch的配置,如下
input {
beats {
port => "5044"
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}"}
}
geoip {
source => "clientip"
}
}
output {
elasticsearch {
hosts => [ "localhost:9200" ]
}
}- (3)清理filebeat历史数据,并重启
- (4)查询Elasticsearch确认数据是否正常上传(注意替换查询语句中的日期)
curl -XGET 'http://172.16.16.17:9200/logstash-2018.10.09/_search?pretty&q=response=200'- (5)如果Elasticsearch关联了Kibana也可以使用kibana查看数据是否正常上报
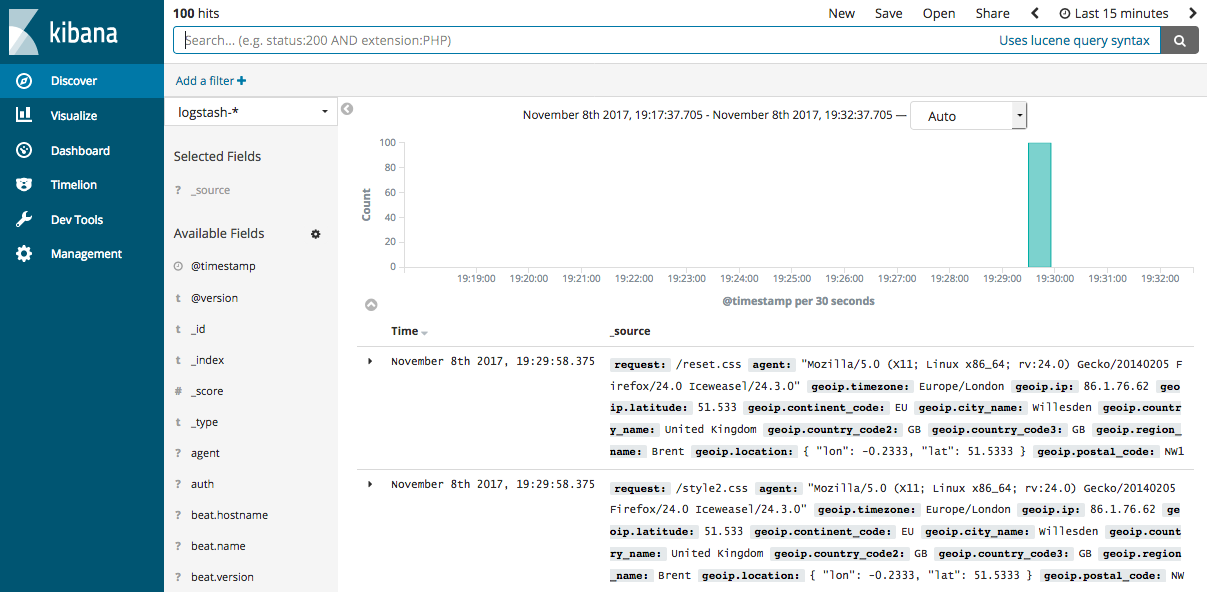
Logstash提供了大量的Input, filter, output, codec的插件,用户可以根据自己的需要,使用一个或多个组件实现自己的功能,当然用户也可以自定义插件以实现更为定制化的功能。自定义插件可以参考[logstash input插件开发]
3 部署Logstash
演示过如何快速使用Logstash后,现在详细讲述一下Logstash的部署方式。
3.1 安装
- 安装JDK:Logstash采用JRuby编写,运行需要JDK环境,因此安装Logstash前需要先安装JDK。(当前6.4仅支持JDK8)
- 安装Logstash:可以采用直接下载压缩包方式安装,也通过APT或YUM安装,另外Logstash支持安装到Docker中。[Logstash安装参考]
- 安装X-PACK:在6.3及之后版本X-PACK会随Logstash安装,在此之前需要手动安装[参考链接]
3.2 目录结构
logstash的目录主要包括:根目录、bin目录、配置目录、日志目录、插件目录、数据目录
不同安装方式各目录的默认位置参考[此处]
3.3 配置文件
- Pipeline配置文件,名称可以自定义,在启动Logstash时显式指定,编写方式可以参考前面示例,对于具体插件的配置方式参见具体插件的说明(使用Logstash时必须配置): 用于定义一个pipeline,数据处理方式和输出源
- Settings配置文件(可以使用默认配置): 在使用Logstash时可以不用设置,用于性能调优,日志记录等
- 为了保证敏感配置的安全性,logstash提供了配置加密功能[参考链接]
3.4 启动关闭方式
3.4.1 启动
- 命令行启动
- 在debian和rpm上以服务形式启动
- 在docker中启动3.4.2 关闭
- 关闭Logstash
- Logstash的关闭时会先关闭input停止输入,然后处理完所有进行中的事件,然后才完全停止,以防止数据丢失,但这也导致停止过程出现延迟或失败的情况。
3.5 扩展Logstash
当单个Logstash无法满足性能需求时,可以采用横向扩展的方式来提高Logstash的处理能力。横向扩展的多个Logstash相互独立,采用相同的pipeline配置,另外可以在这多个Logstash前增加一个LoadBalance,以实现多个Logstash的负载均衡。
4 性能调优
[详细调优参考]
- (1)Inputs和Outputs的性能:当输入输出源的性能已经达到上限,那么性能瓶颈不在Logstash,应优先对输入输出源的性能进行调优。
- (2)系统性能指标:
- CPU:确定CPU使用率是否过高,如果CPU过高则先查看JVM堆空间使用率部分,确认是否为GC频繁导致,如果GC正常,则可以通过调节Logstash worker相关配置来解决。
- 内存:由于Logstash运行在JVM上,因此注意调整JVM堆空间上限,以便其有足够的运行空间。另外注意Logstash所在机器上是否有其他应用占用了大量内存,导致Logstash内存磁盘交换频繁。
- I/O使用率: 1)磁盘IO: 磁盘IO饱和可能是因为使用了会导致磁盘IO饱和的创建(如file output),另外Logstash中出现错误产生大量错误日志时也会导致磁盘IO饱和。Linux下可以通过iostat, dstat等查看磁盘IO情况 2)网络IO: 网络IO饱和一般发生在使用有大量网络操作的插件时。linux下可以使用dstat或iftop等查看网络IO情况
- (3)JVM堆检查:
- 如果JVM堆大小设置过小会导致GC频繁,从而导致CPU使用率过高
- 快速验证这个问题的方法是double堆大小,看性能是否有提升。注意要给系统至少预留1GB的空间。
- 为了精确查找问题可以使用jmap或VisualVM。[参考]
- 设置Xms和Xmx为相同值,防止堆大小在运行时调整,这个过程非常消耗性能。
- (4)Logstash worker设置:
worker相关配置在logstash.yml中,主要包括如下三个:
- pipeline.workers: 该参数用以指定Logstash中执行filter和output的线程数,当如果发现CPU使用率尚未达到上限,可以通过调整该参数,为Logstash提供更高的性能。建议将Worker数设置适当超过CPU核数可以减少IO等待时间对处理过程的影响。实际调优中可以先通过-w指定该参数,当确定好数值后再写入配置文件中。
- pipeline.batch.size: 该指标用于指定单个worker线程一次性执行flilter和output的event批量数。增大该值可以减少IO次数,提高处理速度,但是也以为这增加内存等资源的消耗。当与Elasticsearch联用时,该值可以用于指定Elasticsearch一次bluck操作的大小。
- pipeline.batch.delay: 该指标用于指定worker等待时间的超时时间,如果worker在该时间内没有等到pipeline.batch.size个事件,那么将直接开始执行filter和output而不再等待。
结束语
Logstash作为Elastic Stack的重要组成部分,在Elasticsearch数据采集和处理过程中扮演着重要的角色。本文通过简单示例的演示和Logstash基础知识的铺陈,希望可以帮助初次接触Logstash的用户对Logstash有一个整体认识,并能较为快速上手。对于Logstash的高阶使用,仍需要用户在使用过程中结合实际情况查阅相关资源深入研究。当然也欢迎大家积极交流,并对文中的错误提出宝贵意见。
MORE:
本文同步发布在腾讯云+社区Elasticsearch专栏:https://cloud.tencent.com/developer/column/4008
Elasticsearch是当前主流的分布式大数据存储和搜索引擎,可以为用户提供强大的全文本检索能力,广泛应用于日志检索,全站搜索等领域。Logstash作为Elasicsearch常用的实时数据采集引擎,可以采集来自不同数据源的数据,并对数据进行处理后输出到多种输出源,是Elastic Stack 的重要组成部分。本文从Logstash的工作原理,使用示例,部署方式及性能调优等方面入手,为大家提供一个快速入门Logstash的方式。文章最后也给出了一些深入了解Logstash的的链接,以方便大家根据需要详细了解。
1 Logstash工作原理
1.1 处理过程
如上图,Logstash的数据处理过程主要包括:Inputs, Filters, Outputs 三部分, 另外在Inputs和Outputs中可以使用Codecs对数据格式进行处理。这四个部分均以插件形式存在,用户通过定义pipeline配置文件,设置需要使用的input,filter,output, codec插件,以实现特定的数据采集,数据处理,数据输出等功能
- (1)Inputs:用于从数据源获取数据,常见的插件如file, syslog, redis, beats 等[详细参考]
- (2)Filters:用于处理数据如格式转换,数据派生等,常见的插件如grok, mutate, drop, clone, geoip等[详细参考]
- (3)Outputs:用于数据输出,常见的插件如elastcisearch,file, graphite, statsd等[详细参考]
- (4)Codecs:Codecs不是一个单独的流程,而是在输入和输出等插件中用于数据转换的模块,用于对数据进行编码处理,常见的插件如json,multiline[详细参考]
可以点击每个模块后面的_详细参考_链接了解该模块的插件列表及对应功能
1.2 执行模型:
- (1)每个Input启动一个线程,从对应数据源获取数据
- (2)Input会将数据写入一个队列:默认为内存中的有界队列(意外停止会导致数据丢失)。为了防止数丢失Logstash提供了两个特性: Persistent Queues:通过磁盘上的queue来防止数据丢失 Dead Letter Queues:保存无法处理的event(仅支持Elasticsearch作为输出源)
- (3)Logstash会有多个pipeline worker, 每一个pipeline worker会从队列中取一批数据,然后执行filter和output(worker数目及每次处理的数据量均由配置确定)
2 Logstash使用示例
2.1 Logstash Hello world
第一个示例Logstash将采用标准输入和标准输出作为input和output,并且不指定filter
- (1)下载Logstash并解压(需要预先安装JDK8)
- (2)cd到Logstash的根目录,并执行启动命令如下:
cd logstash-6.4.0
bin/logstash -e 'input { stdin { } } output { stdout {} }'- (3)此时Logstash已经启动成功,-e表示在启动时直接指定pipeline配置,当然也可以将该配置写入一个配置文件中,然后通过指定配置文件来启动
- (4)在控制台输入:hello world,可以看到如下输出:
{
"@version" => "1",
"host" => "localhost",
"@timestamp" => 2018-09-18T12:39:38.514Z,
"message" => "hello world"
} Logstash会自动为数据添加@version, host, @timestamp等字段
在这个示例中Logstash从标准输入中获得数据,仅在数据中添加一些简单字段后将其输出到标准输出。
2.2 日志采集
这个示例将采用Filebeat input插件(Elastic Stack中的轻量级数据采集程序)采集本地日志,然后将结果输出到标准输出
filebeat.yml配置如下(paths改为日志实际位置,不同版本beats配置可能略有变化,请根据情况调整)
filebeat.prospectors:
- input\_type: log
paths:
- /path/to/file/logstash-tutorial.log
output.logstash:
hosts: "localhost:5044"启动命令:
./filebeat -e -c filebeat.yml -d "publish"- (3)配置logstash并启动
1)创建first-pipeline.conf文件内容如下(该文件为pipeline配置文件,用于指定input,filter, output等):
input {
beats {
port => "5044"
}
}
#filter {
#}
output {
stdout { codec => rubydebug }
}codec => rubydebug用于美化输出[参考]
2)验证配置(注意指定配置文件的路径):
./bin/logstash -f first-pipeline.conf --config.test_and_exit3)启动命令:
./bin/logstash -f first-pipeline.conf --config.reload.automatic--config.reload.automatic选项启用动态重载配置功能
4)预期结果:
可以在Logstash的终端显示中看到,日志文件被读取并处理为如下格式的多条数据
{
"@timestamp" => 2018-10-09T12:22:39.742Z,
"offset" => 24464,
"@version" => "1",
"input_type" => "log",
"beat" => {
"name" => "VM_136_9_centos",
"hostname" => "VM_136_9_centos",
"version" => "5.6.10"
},
"host" => "VM_136_9_centos",
"source" => "/data/home/michelmu/workspace/logstash-tutorial.log",
"message" => "86.1.76.62 - - [04/Jan/2015:05:30:37 +0000] \"GET /style2.css HTTP/1.1\" 200 4877 \"http://www.semicomplete.com/projects/xdotool/\" \"Mozilla/5.0 (X11; Linux x86_64; rv:24.0) Gecko/20140205 Firefox/24.0 Iceweasel/24.3.0\"",
"type" => "log",
"tags" => [
[0] "beats_input_codec_plain_applied"
]
}相对于示例2.1,该示例使用了filebeat input插件从日志中获取一行记录,这也是Elastic stack获取日志数据最常见的一种方式。另外该示例还采用了rubydebug codec 对输出的数据进行显示美化。
2.3 日志格式处理
可以看到虽然示例2.2使用filebeat从日志中读取数据,并将数据输出到标准输出,但是日志内容作为一个整体被存放在message字段中,这样对后续存储及查询都极为不便。可以为该pipeline指定一个grok filter来对日志格式进行处理
- (1)在first-pipeline.conf中增加filter配置如下
input {
beats {
port => "5044"
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}"}
}
}
output {
stdout { codec => rubydebug }
}- (2)到filebeat的根目录下删除之前上报的数据历史(以便重新上报数据),并重启filebeat
sudo rm data/registry
sudo ./filebeat -e -c filebeat.yml -d "publish"- (3)由于之前启动Logstash设置了自动更新配置,因此Logstash不需要重新启动,这个时候可以获取到的日志数据如下:
{
"request" => "/style2.css",
"agent" => "\"Mozilla/5.0 (X11; Linux x86_64; rv:24.0) Gecko/20140205 Firefox/24.0 Iceweasel/24.3.0\"",
"offset" => 24464,
"auth" => "-",
"ident" => "-",
"input_type" => "log",
"verb" => "GET",
"source" => "/data/home/michelmu/workspace/logstash-tutorial.log",
"message" => "86.1.76.62 - - [04/Jan/2015:05:30:37 +0000] \"GET /style2.css HTTP/1.1\" 200 4877 \"http://www.semicomplete.com/projects/xdotool/\" \"Mozilla/5.0 (X11; Linux x86_64; rv:24.0) Gecko/20140205 Firefox/24.0 Iceweasel/24.3.0\"",
"type" => "log",
"tags" => [
[0] "beats_input_codec_plain_applied"
],
"referrer" => "\"http://www.semicomplete.com/projects/xdotool/\"",
"@timestamp" => 2018-10-09T12:24:21.276Z,
"response" => "200",
"bytes" => "4877",
"clientip" => "86.1.76.62",
"@version" => "1",
"beat" => {
"name" => "VM_136_9_centos",
"hostname" => "VM_136_9_centos",
"version" => "5.6.10"
},
"host" => "VM_136_9_centos",
"httpversion" => "1.1",
"timestamp" => "04/Jan/2015:05:30:37 +0000"
}可以看到message中的数据被详细解析出来了
2.4 数据派生和增强
Logstash中的一些filter可以根据现有数据生成一些新的数据,如geoip可以根据ip生成经纬度信息
- (1)在first-pipeline.conf中增加geoip配置如下
input {
beats {
port => "5044"
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}"}
}
geoip {
source => "clientip"
}
}
output {
stdout { codec => rubydebug }
}- (2)如2.3一样清空filebeat历史数据,并重启
- (3)当然Logstash仍然不需要重启,可以看到输出变为如下:
{
"request" => "/style2.css",
"agent" => "\"Mozilla/5.0 (X11; Linux x86_64; rv:24.0) Gecko/20140205 Firefox/24.0 Iceweasel/24.3.0\"",
"geoip" => {
"timezone" => "Europe/London",
"ip" => "86.1.76.62",
"latitude" => 51.5333,
"continent_code" => "EU",
"city_name" => "Willesden",
"country_name" => "United Kingdom",
"country_code2" => "GB",
"country_code3" => "GB",
"region_name" => "Brent",
"location" => {
"lon" => -0.2333,
"lat" => 51.5333
},
"postal_code" => "NW10",
"region_code" => "BEN",
"longitude" => -0.2333
},
"offset" => 24464,
"auth" => "-",
"ident" => "-",
"input_type" => "log",
"verb" => "GET",
"source" => "/data/home/michelmu/workspace/logstash-tutorial.log",
"message" => "86.1.76.62 - - [04/Jan/2015:05:30:37 +0000] \"GET /style2.css HTTP/1.1\" 200 4877 \"http://www.semicomplete.com/projects/xdotool/\" \"Mozilla/5.0 (X11; Linux x86_64; rv:24.0) Gecko/20140205 Firefox/24.0 Iceweasel/24.3.0\"",
"type" => "log",
"tags" => [
[0] "beats_input_codec_plain_applied"
],
"referrer" => "\"http://www.semicomplete.com/projects/xdotool/\"",
"@timestamp" => 2018-10-09T12:37:46.686Z,
"response" => "200",
"bytes" => "4877",
"clientip" => "86.1.76.62",
"@version" => "1",
"beat" => {
"name" => "VM_136_9_centos",
"hostname" => "VM_136_9_centos",
"version" => "5.6.10"
},
"host" => "VM_136_9_centos",
"httpversion" => "1.1",
"timestamp" => "04/Jan/2015:05:30:37 +0000"
}可以看到根据ip派生出了许多地理位置信息数据
2.5 将数据导入Elasticsearch
Logstash作为Elastic stack的重要组成部分,其最常用的功能是将数据导入到Elasticssearch中。将Logstash中的数据导入到Elasticsearch中操作也非常的方便,只需要在pipeline配置文件中增加Elasticsearch的output即可。
- (1)首先要有一个已经部署好的Logstash,当然可以使用腾讯云快速创建一个Elasticsearch创建地址
- (2)在first-pipeline.conf中增加Elasticsearch的配置,如下
input {
beats {
port => "5044"
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}"}
}
geoip {
source => "clientip"
}
}
output {
elasticsearch {
hosts => [ "localhost:9200" ]
}
}- (3)清理filebeat历史数据,并重启
- (4)查询Elasticsearch确认数据是否正常上传(注意替换查询语句中的日期)
curl -XGET 'http://172.16.16.17:9200/logstash-2018.10.09/_search?pretty&q=response=200'- (5)如果Elasticsearch关联了Kibana也可以使用kibana查看数据是否正常上报
Logstash提供了大量的Input, filter, output, codec的插件,用户可以根据自己的需要,使用一个或多个组件实现自己的功能,当然用户也可以自定义插件以实现更为定制化的功能。自定义插件可以参考[logstash input插件开发]
3 部署Logstash
演示过如何快速使用Logstash后,现在详细讲述一下Logstash的部署方式。
3.1 安装
- 安装JDK:Logstash采用JRuby编写,运行需要JDK环境,因此安装Logstash前需要先安装JDK。(当前6.4仅支持JDK8)
- 安装Logstash:可以采用直接下载压缩包方式安装,也通过APT或YUM安装,另外Logstash支持安装到Docker中。[Logstash安装参考]
- 安装X-PACK:在6.3及之后版本X-PACK会随Logstash安装,在此之前需要手动安装[参考链接]
3.2 目录结构
logstash的目录主要包括:根目录、bin目录、配置目录、日志目录、插件目录、数据目录
不同安装方式各目录的默认位置参考[此处]
3.3 配置文件
- Pipeline配置文件,名称可以自定义,在启动Logstash时显式指定,编写方式可以参考前面示例,对于具体插件的配置方式参见具体插件的说明(使用Logstash时必须配置): 用于定义一个pipeline,数据处理方式和输出源
- Settings配置文件(可以使用默认配置): 在使用Logstash时可以不用设置,用于性能调优,日志记录等
- 为了保证敏感配置的安全性,logstash提供了配置加密功能[参考链接]
3.4 启动关闭方式
3.4.1 启动
- 命令行启动
- 在debian和rpm上以服务形式启动
- 在docker中启动3.4.2 关闭
- 关闭Logstash
- Logstash的关闭时会先关闭input停止输入,然后处理完所有进行中的事件,然后才完全停止,以防止数据丢失,但这也导致停止过程出现延迟或失败的情况。
3.5 扩展Logstash
当单个Logstash无法满足性能需求时,可以采用横向扩展的方式来提高Logstash的处理能力。横向扩展的多个Logstash相互独立,采用相同的pipeline配置,另外可以在这多个Logstash前增加一个LoadBalance,以实现多个Logstash的负载均衡。
4 性能调优
[详细调优参考]
- (1)Inputs和Outputs的性能:当输入输出源的性能已经达到上限,那么性能瓶颈不在Logstash,应优先对输入输出源的性能进行调优。
- (2)系统性能指标:
- CPU:确定CPU使用率是否过高,如果CPU过高则先查看JVM堆空间使用率部分,确认是否为GC频繁导致,如果GC正常,则可以通过调节Logstash worker相关配置来解决。
- 内存:由于Logstash运行在JVM上,因此注意调整JVM堆空间上限,以便其有足够的运行空间。另外注意Logstash所在机器上是否有其他应用占用了大量内存,导致Logstash内存磁盘交换频繁。
- I/O使用率: 1)磁盘IO: 磁盘IO饱和可能是因为使用了会导致磁盘IO饱和的创建(如file output),另外Logstash中出现错误产生大量错误日志时也会导致磁盘IO饱和。Linux下可以通过iostat, dstat等查看磁盘IO情况 2)网络IO: 网络IO饱和一般发生在使用有大量网络操作的插件时。linux下可以使用dstat或iftop等查看网络IO情况
- (3)JVM堆检查:
- 如果JVM堆大小设置过小会导致GC频繁,从而导致CPU使用率过高
- 快速验证这个问题的方法是double堆大小,看性能是否有提升。注意要给系统至少预留1GB的空间。
- 为了精确查找问题可以使用jmap或VisualVM。[参考]
- 设置Xms和Xmx为相同值,防止堆大小在运行时调整,这个过程非常消耗性能。
- (4)Logstash worker设置:
worker相关配置在logstash.yml中,主要包括如下三个:
- pipeline.workers: 该参数用以指定Logstash中执行filter和output的线程数,当如果发现CPU使用率尚未达到上限,可以通过调整该参数,为Logstash提供更高的性能。建议将Worker数设置适当超过CPU核数可以减少IO等待时间对处理过程的影响。实际调优中可以先通过-w指定该参数,当确定好数值后再写入配置文件中。
- pipeline.batch.size: 该指标用于指定单个worker线程一次性执行flilter和output的event批量数。增大该值可以减少IO次数,提高处理速度,但是也以为这增加内存等资源的消耗。当与Elasticsearch联用时,该值可以用于指定Elasticsearch一次bluck操作的大小。
- pipeline.batch.delay: 该指标用于指定worker等待时间的超时时间,如果worker在该时间内没有等到pipeline.batch.size个事件,那么将直接开始执行filter和output而不再等待。
结束语
Logstash作为Elastic Stack的重要组成部分,在Elasticsearch数据采集和处理过程中扮演着重要的角色。本文通过简单示例的演示和Logstash基础知识的铺陈,希望可以帮助初次接触Logstash的用户对Logstash有一个整体认识,并能较为快速上手。对于Logstash的高阶使用,仍需要用户在使用过程中结合实际情况查阅相关资源深入研究。当然也欢迎大家积极交流,并对文中的错误提出宝贵意见。
MORE:
收起阅读 »当Elasticsearch遇见Kafka--Kafka Connect
本文同步发布在腾讯云+社区Elasticsearch专栏中:https://cloud.tencent.com/developer/column/4008
在“当Elasticsearch遇见Kafka--Logstash kafka input插件”一文中,我对Logstash的Kafka input插件进行了简单的介绍,并通过实际操作的方式,为大家呈现了使用该方式实现Kafka与Elastisearch整合的基本过程。可以看出使用Logstash input插件的方式,具有配置简单,数据处理方便等优点。然而使用Logstash Kafka插件并不是Kafka与Elsticsearch整合的唯一方案,另一种比较常见的方案是使用Kafka的开源组件Kafka Connect。

1 Kafka Connect简介
Kafka Connect是Kafka的开源组件Confluent提供的功能,用于实现Kafka与外部系统的连接。Kafka Connect同时支持分布式模式和单机模式,另外提供了一套完整的REST接口,用于查看和管理Kafka Connectors,还具有offset自动管理,可扩展等优点。
Kafka connect分为企业版和开源版,企业版在开源版的基础之上提供了监控,负载均衡,副本等功能,实际生产环境中建议使用企业版。(本测试使用开源版)
Kafka connect workers有两种工作模式,单机模式和分布式模式。在开发和适合使用单机模式的场景下,可以使用standalone模式, 在实际生产环境下由于单个worker的数据压力会比较大,distributed模式对负载均和和扩展性方面会有很大帮助。(本测试使用standalone模式)
关于Kafka Connect的详细情况可以参考[Kafka Connect]
2 使用Kafka Connect连接Kafka和Elasticsearch
2.1 测试环境准备
本文与使用Logstash Kafka input插件环境一样[传送门],组件列表如下
| 服务 | ip | port |
|---|---|---|
| Elasticsearch service | 192.168.0.8 | 9200 |
| Ckafka | 192.168.13.10 | 9092 |
| CVM | 192.168.0.13 | - |
kafka topic也复用原来了的kafka_es_test
2.2 Kafka Connect 安装
本文下载的为开源版本confluent-oss-5.0.1-2.11.tar.gz,下载后解压
2.3 Worker配置
1) 配置参考
如前文所说,worker分为Standalone和Distributed两种模式,针对两种模式的配置,参考如下
[通用配置]
此处需要注意的是Kafka Connect默认使用AvroConverter,使用该AvroConverter时需要注意必须启动Schema Registry服务
2) 实际操作
本测试使用standalone模式,因此修改/root/confluent-5.0.1/etc/schema-registry/connect-avro-standalone.properties
bootstrap.servers=192.168.13.10:90922.4 Elasticsearch Connector配置
1) 配置参考
[Elasticsearch Configuration Options]
2) 实际操作
修改/root/confluent-5.0.1/etc/kafka-connect-elasticsearch/quickstart-elasticsearch.properties
name=elasticsearch-sink
connector.class=io.confluent.connect.elasticsearch.ElasticsearchSinkConnector
tasks.max=1
topics=kafka_es_test
key.ignore=true
connection.url=http://192.168.0.8:9200
type.name=kafka-connect注意: 其中topics不仅对应Kafka的topic名称,同时也是Elasticsearch的索引名,当然也可以通过topic.index.map来设置从topic名到Elasticsearch索引名的映射
2.5 启动connector
1 注意事项
1) 由于配置文件中jar包位置均采用的相对路径,因此建议在confluent根目录下执行命令和启动程序,以避免不必要的问题
2) 如果前面没有修改converter,仍采用AvroConverter, 注意需要在启动connertor前启动Schema Registry服务
2 启动Schema Registry服务
正如前文所说,由于在配置worker时指定使用了AvroConverter,因此需要启动Schema Registry服务。而该服务需要指定一个zookeeper地址或Kafka地址,以存储schema数据。由于CKafka不支持用户通过接口形式创建topic,因此需要在本机起一个kafka以创建名为_schema的topic。
1) 启动Zookeeper
./bin/zookeeper-server-start -daemon etc/kafka/zookeeper.properties2) 启动kafka
./bin/kafka-server-start -daemon etc/kafka/server.properties3) 启动schema Registry
./bin/schema-registry-start -daemon etc/schema-registry/schema-registry.properties4) 使用netstat -natpl 查看各服务端口是否正常启动
zookeeper 2181
kafka 9092
schema registry 8081
3 启动Connector
./bin/connect-standalone -daemon etc/schema-registry/connect-avro-standalone.properties etc/kafka-connect-elasticsearch/quickstart-elasticsearch.propertiesps:以上启动各服务均可在logs目录下找到对应日志
2.6 启动Kafka Producer
由于我们采用的是AvroConverter,因此不能采用Kafka工具包中的producer。Kafka Connector bin目录下提供了Avro Producer
1) 启动Producer
./bin/kafka-avro-console-producer --broker-list 192.168.13.10:9092 --topic kafka_es_test --property value.schema='{"type":"record","name":"person","fields":[{"name":"nickname","type":"string"}]}'2) 输入如下数据
{"nickname":"michel"}
{"nickname":"mushao"}2.7 Kibana验证结果
1) 查看索引
在kibana Dev Tools的Console中输入
GET _cat/indices结果
green open kafka_es_test 36QtDP6vQOG7ubOa161wGQ 5 1 1 0 7.9kb 3.9kb
green open .kibana QUw45tN0SHqeHbF9-QVU6A 1 1 1 0 5.5kb 2.7kb可以看到名为kafka_es_test的索引被成功创建
2) 查看数据
{
"took": 0,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 1,
"hits": [
{
"_index": "kafka_es_test",
"_type": "kafka-connect",
"_id": "kafka_es_test+0+0",
"_score": 1,
"_source": {
"nickname": "michel"
}
},
{
"_index": "kafka_es_test",
"_type": "kafka-connect",
"_id": "kafka_es_test+0+1",
"_score": 1,
"_source": {
"nickname": "mushao"
}
}
]
}
}可以看到数据已经被成功写入
3 Confluent CLI
3.1 简介
查阅资料时发现很多文章都是使用Confluent CLI启动Kafka Connect,然而官方文档已经明确说明了该CLI只是适用于开发阶段,不能用于生产环境。
它可以一键启动包括zookeeper,kafka,schema registry, kafka rest, connect等在内的多个服务。但是这些服务对于Kafka Connect都不是必须的,如果不使用AvroConverter,则只需要启动Connect即可。即使使用了AvroConverter, 也只需要启动schema registry,将schema保存在远端的kafka中。Kafka Connect REST API也只是为用户提供一个管理connector的接口,也不是必选的。
另外使用CLI启动默认配置为启动Distributed的Connector,需要通过环境变量来修改配置
3.2 使用Confluent CLI
confluent CLI提供了丰富的命令,包括服务启动,服务停止,状态查询,日志查看等,详情参考如下简介视频 [Introducing the Confluent CLI | Screencast]
1) 启动
./bin/confluent start2) 检查confluent运行状态
./bin/confluent status当得到如下结果则说明confluent启动成功
ksql-server is [UP]
connect is [UP]
kafka-rest is [UP]
schema-registry is [UP]
kafka is [UP]
zookeeper is [UP]3) 问题定位
如果第二步出现问题,可以使用log命令查看,如connect未启动成功则
./bin/confluent log connect4) 加载Elasticsearch Connector
a) 查看connector
./bin/confluent list connectors结果
Bundled Predefined Connectors (edit configuration under etc/):
elasticsearch-sink
file-source
file-sink
jdbc-source
jdbc-sink
hdfs-sink
s3-sinkb) 加载Elasticsearch connector
./bin/confluent load elasticsearch-sink结果
{
"name": "elasticsearch-sink",
"config": {
"connector.class": "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector",
"tasks.max": "1",
"topics": "kafka_es_test",
"key.ignore": "true",
"connection.url": "http://192.168.0.8:9200",
"type.name": "kafka-connect",
"name": "elasticsearch-sink"
},
"tasks": [],
"type": null
}5) 使用producer生产数据,并使用kibana验证是否写入成功
4 Kafka Connect Rest API
Kafka Connect提供了一套完成的管理Connector的接口,详情参考[Kafka Connect REST Interface]。该接口可以实现对Connector的创建,销毁,修改,查询等操作
1) GET connectors 获取运行中的connector列表
2) POST connectors 使用指定的名称和配置创建connector
3) GET connectors/(string:name) 获取connector的详细信息
4) GET connectors/(string:name)/config 获取connector的配置
5) PUT connectors/(string:name)/config 设置connector的配置
6) GET connectors/(string:name)/status 获取connector状态
7) POST connectors/(stirng:name)/restart 重启connector
8) PUT connectors/(string:name)/pause 暂停connector
9) PUT connectors/(string:name)/resume 恢复connector
10) DELETE connectors/(string:name)/ 删除connector
11) GET connectors/(string:name)/tasks 获取connectors任务列表
12) GET /connectors/(string: name)/tasks/(int: taskid)/status 获取任务状态
13) POST /connectors/(string: name)/tasks/(int: taskid)/restart 重启任务
14) GET /connector-plugins/ 获取已安装插件列表
15) PUT /connector-plugins/(string: name)/config/validate 验证配置
5 总结
Kafka Connect是Kafka一个功能强大的组件,为kafka提供了与外部系统连接的一套完整方案,包括数据传输,连接管理,监控,多副本等。相对于Logstash Kafka插件,功能更为全面,但配置也相对为复杂些。有文章提到其性能也优于Logstash Kafka Input插件,如果对写入性能比较敏感的场景,可以在实际压测的基础上进行选择。另外由于直接将数据从Kafka写入Elasticsearch, 如果需要对文档进行处理时,选择Logstash可能更为方便。
本文同步发布在腾讯云+社区Elasticsearch专栏中:https://cloud.tencent.com/developer/column/4008
在“当Elasticsearch遇见Kafka--Logstash kafka input插件”一文中,我对Logstash的Kafka input插件进行了简单的介绍,并通过实际操作的方式,为大家呈现了使用该方式实现Kafka与Elastisearch整合的基本过程。可以看出使用Logstash input插件的方式,具有配置简单,数据处理方便等优点。然而使用Logstash Kafka插件并不是Kafka与Elsticsearch整合的唯一方案,另一种比较常见的方案是使用Kafka的开源组件Kafka Connect。
1 Kafka Connect简介
Kafka Connect是Kafka的开源组件Confluent提供的功能,用于实现Kafka与外部系统的连接。Kafka Connect同时支持分布式模式和单机模式,另外提供了一套完整的REST接口,用于查看和管理Kafka Connectors,还具有offset自动管理,可扩展等优点。
Kafka connect分为企业版和开源版,企业版在开源版的基础之上提供了监控,负载均衡,副本等功能,实际生产环境中建议使用企业版。(本测试使用开源版)
Kafka connect workers有两种工作模式,单机模式和分布式模式。在开发和适合使用单机模式的场景下,可以使用standalone模式, 在实际生产环境下由于单个worker的数据压力会比较大,distributed模式对负载均和和扩展性方面会有很大帮助。(本测试使用standalone模式)
关于Kafka Connect的详细情况可以参考[Kafka Connect]
2 使用Kafka Connect连接Kafka和Elasticsearch
2.1 测试环境准备
本文与使用Logstash Kafka input插件环境一样[传送门],组件列表如下
| 服务 | ip | port |
|---|---|---|
| Elasticsearch service | 192.168.0.8 | 9200 |
| Ckafka | 192.168.13.10 | 9092 |
| CVM | 192.168.0.13 | - |
kafka topic也复用原来了的kafka_es_test
2.2 Kafka Connect 安装
本文下载的为开源版本confluent-oss-5.0.1-2.11.tar.gz,下载后解压
2.3 Worker配置
1) 配置参考
如前文所说,worker分为Standalone和Distributed两种模式,针对两种模式的配置,参考如下
[通用配置]
此处需要注意的是Kafka Connect默认使用AvroConverter,使用该AvroConverter时需要注意必须启动Schema Registry服务
2) 实际操作
本测试使用standalone模式,因此修改/root/confluent-5.0.1/etc/schema-registry/connect-avro-standalone.properties
bootstrap.servers=192.168.13.10:90922.4 Elasticsearch Connector配置
1) 配置参考
[Elasticsearch Configuration Options]
2) 实际操作
修改/root/confluent-5.0.1/etc/kafka-connect-elasticsearch/quickstart-elasticsearch.properties
name=elasticsearch-sink
connector.class=io.confluent.connect.elasticsearch.ElasticsearchSinkConnector
tasks.max=1
topics=kafka_es_test
key.ignore=true
connection.url=http://192.168.0.8:9200
type.name=kafka-connect注意: 其中topics不仅对应Kafka的topic名称,同时也是Elasticsearch的索引名,当然也可以通过topic.index.map来设置从topic名到Elasticsearch索引名的映射
2.5 启动connector
1 注意事项
1) 由于配置文件中jar包位置均采用的相对路径,因此建议在confluent根目录下执行命令和启动程序,以避免不必要的问题
2) 如果前面没有修改converter,仍采用AvroConverter, 注意需要在启动connertor前启动Schema Registry服务
2 启动Schema Registry服务
正如前文所说,由于在配置worker时指定使用了AvroConverter,因此需要启动Schema Registry服务。而该服务需要指定一个zookeeper地址或Kafka地址,以存储schema数据。由于CKafka不支持用户通过接口形式创建topic,因此需要在本机起一个kafka以创建名为_schema的topic。
1) 启动Zookeeper
./bin/zookeeper-server-start -daemon etc/kafka/zookeeper.properties2) 启动kafka
./bin/kafka-server-start -daemon etc/kafka/server.properties3) 启动schema Registry
./bin/schema-registry-start -daemon etc/schema-registry/schema-registry.properties4) 使用netstat -natpl 查看各服务端口是否正常启动
zookeeper 2181
kafka 9092
schema registry 8081
3 启动Connector
./bin/connect-standalone -daemon etc/schema-registry/connect-avro-standalone.properties etc/kafka-connect-elasticsearch/quickstart-elasticsearch.propertiesps:以上启动各服务均可在logs目录下找到对应日志
2.6 启动Kafka Producer
由于我们采用的是AvroConverter,因此不能采用Kafka工具包中的producer。Kafka Connector bin目录下提供了Avro Producer
1) 启动Producer
./bin/kafka-avro-console-producer --broker-list 192.168.13.10:9092 --topic kafka_es_test --property value.schema='{"type":"record","name":"person","fields":[{"name":"nickname","type":"string"}]}'2) 输入如下数据
{"nickname":"michel"}
{"nickname":"mushao"}2.7 Kibana验证结果
1) 查看索引
在kibana Dev Tools的Console中输入
GET _cat/indices结果
green open kafka_es_test 36QtDP6vQOG7ubOa161wGQ 5 1 1 0 7.9kb 3.9kb
green open .kibana QUw45tN0SHqeHbF9-QVU6A 1 1 1 0 5.5kb 2.7kb可以看到名为kafka_es_test的索引被成功创建
2) 查看数据
{
"took": 0,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 1,
"hits": [
{
"_index": "kafka_es_test",
"_type": "kafka-connect",
"_id": "kafka_es_test+0+0",
"_score": 1,
"_source": {
"nickname": "michel"
}
},
{
"_index": "kafka_es_test",
"_type": "kafka-connect",
"_id": "kafka_es_test+0+1",
"_score": 1,
"_source": {
"nickname": "mushao"
}
}
]
}
}可以看到数据已经被成功写入
3 Confluent CLI
3.1 简介
查阅资料时发现很多文章都是使用Confluent CLI启动Kafka Connect,然而官方文档已经明确说明了该CLI只是适用于开发阶段,不能用于生产环境。
它可以一键启动包括zookeeper,kafka,schema registry, kafka rest, connect等在内的多个服务。但是这些服务对于Kafka Connect都不是必须的,如果不使用AvroConverter,则只需要启动Connect即可。即使使用了AvroConverter, 也只需要启动schema registry,将schema保存在远端的kafka中。Kafka Connect REST API也只是为用户提供一个管理connector的接口,也不是必选的。
另外使用CLI启动默认配置为启动Distributed的Connector,需要通过环境变量来修改配置
3.2 使用Confluent CLI
confluent CLI提供了丰富的命令,包括服务启动,服务停止,状态查询,日志查看等,详情参考如下简介视频 [Introducing the Confluent CLI | Screencast]
1) 启动
./bin/confluent start2) 检查confluent运行状态
./bin/confluent status当得到如下结果则说明confluent启动成功
ksql-server is [UP]
connect is [UP]
kafka-rest is [UP]
schema-registry is [UP]
kafka is [UP]
zookeeper is [UP]3) 问题定位
如果第二步出现问题,可以使用log命令查看,如connect未启动成功则
./bin/confluent log connect4) 加载Elasticsearch Connector
a) 查看connector
./bin/confluent list connectors结果
Bundled Predefined Connectors (edit configuration under etc/):
elasticsearch-sink
file-source
file-sink
jdbc-source
jdbc-sink
hdfs-sink
s3-sinkb) 加载Elasticsearch connector
./bin/confluent load elasticsearch-sink结果
{
"name": "elasticsearch-sink",
"config": {
"connector.class": "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector",
"tasks.max": "1",
"topics": "kafka_es_test",
"key.ignore": "true",
"connection.url": "http://192.168.0.8:9200",
"type.name": "kafka-connect",
"name": "elasticsearch-sink"
},
"tasks": [],
"type": null
}5) 使用producer生产数据,并使用kibana验证是否写入成功
4 Kafka Connect Rest API
Kafka Connect提供了一套完成的管理Connector的接口,详情参考[Kafka Connect REST Interface]。该接口可以实现对Connector的创建,销毁,修改,查询等操作
1) GET connectors 获取运行中的connector列表
2) POST connectors 使用指定的名称和配置创建connector
3) GET connectors/(string:name) 获取connector的详细信息
4) GET connectors/(string:name)/config 获取connector的配置
5) PUT connectors/(string:name)/config 设置connector的配置
6) GET connectors/(string:name)/status 获取connector状态
7) POST connectors/(stirng:name)/restart 重启connector
8) PUT connectors/(string:name)/pause 暂停connector
9) PUT connectors/(string:name)/resume 恢复connector
10) DELETE connectors/(string:name)/ 删除connector
11) GET connectors/(string:name)/tasks 获取connectors任务列表
12) GET /connectors/(string: name)/tasks/(int: taskid)/status 获取任务状态
13) POST /connectors/(string: name)/tasks/(int: taskid)/restart 重启任务
14) GET /connector-plugins/ 获取已安装插件列表
15) PUT /connector-plugins/(string: name)/config/validate 验证配置
5 总结
Kafka Connect是Kafka一个功能强大的组件,为kafka提供了与外部系统连接的一套完整方案,包括数据传输,连接管理,监控,多副本等。相对于Logstash Kafka插件,功能更为全面,但配置也相对为复杂些。有文章提到其性能也优于Logstash Kafka Input插件,如果对写入性能比较敏感的场景,可以在实际压测的基础上进行选择。另外由于直接将数据从Kafka写入Elasticsearch, 如果需要对文档进行处理时,选择Logstash可能更为方便。
收起阅读 »社区日报 第451期 (2018-11-17)
-
如何迁移到kibana空间 http://t.cn/E2yMhZi
-
利用kibana空间优化管理权限。 http://t.cn/E2yJq1b
- Elasitcsearch索引优化。 http://t.cn/E2y6afZ
-
如何迁移到kibana空间 http://t.cn/E2yMhZi
-
利用kibana空间优化管理权限。 http://t.cn/E2yJq1b
- Elasitcsearch索引优化。 http://t.cn/E2y6afZ
社区日报 第450期 (2018-11-16)
http://t.cn/E2PPJH2
2、Elastic开启了大数据应用新时代
http://t.cn/E2PPCmn
3、图解elasticsearch原理
http://t.cn/E2PPThd
编辑:铭毅天下
归档:https://elasticsearch.cn/article/6138
订阅:https://tinyletter.com/elastic-daily
http://t.cn/E2PPJH2
2、Elastic开启了大数据应用新时代
http://t.cn/E2PPCmn
3、图解elasticsearch原理
http://t.cn/E2PPThd
编辑:铭毅天下
归档:https://elasticsearch.cn/article/6138
订阅:https://tinyletter.com/elastic-daily 收起阅读 »
社区日报 第449期 (2018-11-15)
http://t.cn/EwZO5to
2.一个让elastalert报警更简单的UI
http://t.cn/EAgg8WQ
3.Filebeat优化实践
http://t.cn/EAge74i
编辑:金桥
归档:https://elasticsearch.cn/article/6137
订阅:https://tinyletter.com/elastic-daily
http://t.cn/EwZO5to
2.一个让elastalert报警更简单的UI
http://t.cn/EAgg8WQ
3.Filebeat优化实践
http://t.cn/EAge74i
编辑:金桥
归档:https://elasticsearch.cn/article/6137
订阅:https://tinyletter.com/elastic-daily 收起阅读 »
ES 6.4.3 X-PACK 启用安装配置
我基于最新的版本整理了下启用X-PACK功能。坑比较多,给我的感觉与searchguard 搞得越来越像了……
比较坑的是 transport(9300) 必须要用SSL…… 大家注意下。 6比5复杂多了……
Configure each node to:
Required: Enable TLS on the transport layer.
Recommended: Enable TLS on the HTTP layer.
参考:
https://www.elastic.co/guide/e ... .html
- ES 设置
- 配置 TLS/SSL
- 配置ES(x-pack认证)
- 启动ES
- 配置密码
- 配置kibana
1 Elasticsearch.yml 文件添加内容
xpack.security.enabled: true
2 .1生成CA证书
./elasticsearch-certutil ca
2.2 生成客户端证书
./elasticsearch-certutil cert --ca
2.3ES启用SSL配置文件
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.keystore.path: xxx.p12
xpack.security.transport.ssl.truststore.path: xxx.p12
2.4 keystore 添加内容
./elasticsearch-keystore add xpack.security.transport.ssl.keystore.secure_password
3启用相关功能
xpack.monitoring.enabled: true
xpack.graph.enabled: true
xpack.ml.enabled: true
xpack.security.enabled: true
xpack.watcher.enabled: true
xpack.security.authc.accept_default_password: false
xpack.security.transport.ssl.enabled: true
xpack.monitoring.collection.cluster.stats.timeout: 30m
xpack.monitoring.collection.index.stats.timeout: 30m
xpack.monitoring.collection.index.recovery.active_only: true
xpack.monitoring.collection.index.recovery.timeout: 30m
xpack.monitoring.history.duration: 3650d
4 启动ES
./elasticsearch -d 每台
5配置密码
./elasticsearch-setup-passwords
6汉化kibana 这玩意我还没有整理完,5差不多搞完了。
7开始浪
6版本

5版本



我基于最新的版本整理了下启用X-PACK功能。坑比较多,给我的感觉与searchguard 搞得越来越像了……
比较坑的是 transport(9300) 必须要用SSL…… 大家注意下。 6比5复杂多了……
Configure each node to:
Required: Enable TLS on the transport layer.
Recommended: Enable TLS on the HTTP layer.
参考:
https://www.elastic.co/guide/e ... .html
- ES 设置
- 配置 TLS/SSL
- 配置ES(x-pack认证)
- 启动ES
- 配置密码
- 配置kibana
1 Elasticsearch.yml 文件添加内容
xpack.security.enabled: true
2 .1生成CA证书
./elasticsearch-certutil ca
2.2 生成客户端证书
./elasticsearch-certutil cert --ca
2.3ES启用SSL配置文件
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.keystore.path: xxx.p12
xpack.security.transport.ssl.truststore.path: xxx.p12
2.4 keystore 添加内容
./elasticsearch-keystore add xpack.security.transport.ssl.keystore.secure_password
3启用相关功能
xpack.monitoring.enabled: true
xpack.graph.enabled: true
xpack.ml.enabled: true
xpack.security.enabled: true
xpack.watcher.enabled: true
xpack.security.authc.accept_default_password: false
xpack.security.transport.ssl.enabled: true
xpack.monitoring.collection.cluster.stats.timeout: 30m
xpack.monitoring.collection.index.stats.timeout: 30m
xpack.monitoring.collection.index.recovery.active_only: true
xpack.monitoring.collection.index.recovery.timeout: 30m
xpack.monitoring.history.duration: 3650d
4 启动ES
./elasticsearch -d 每台
5配置密码
./elasticsearch-setup-passwords
6汉化kibana 这玩意我还没有整理完,5差不多搞完了。
7开始浪
6版本
5版本
【 报名已结束】2018 Elastic & 东方航空大数据技术沙龙
上海米哈游高薪诚聘运维开发工程师,待遇15k-30k
工作职责:
负责网络游戏业务的部署、发布、变更;
负责新游戏的接入、架构评估、痛点挖掘优化;
负责监控网络游戏业务的运行状况,及时处理游戏运行中出现的故障,保障网络游戏服务的正常提供;
负责与游戏运营项目组的日常沟通交流,接受并处理项目组提出的运维需求;
针对各系统编写并维护自动化运维脚本;
负责项目组相关运营支撑工具的开发(Python);
负责日常运维工作的自动化、工具化建设;
参与游戏大数据挖掘与分析;
工作要求:
本科以上学历,计算机类或相关专业;
3年以上互联网行业经验、2年以上的批量服务器维护经验;
有开发经验,掌握Python、Bash、Sed、Awk等编程语言;
有较强的抗压能力、沟通能力、推动能力和较好的服务意识;
善于团队协作、项目管理、主动思考、自我驱动强;
优先(满足之一即可):
熟悉云技术应用阿里云,腾讯云,AWS者优先;
有知名游戏维护经验者优先,有数据挖掘经验者优先;
具有开源精神,能阅读源码,有DEVOPS/大数据平台运维管理经验者优先;
熟悉ELK等实时日志处理相关工作经验优先;
熟悉Docker、K8S原理,有Docker实际应用经验者优先;
联系方式:chen.yang@mihoyo.com
工作职责:
负责网络游戏业务的部署、发布、变更;
负责新游戏的接入、架构评估、痛点挖掘优化;
负责监控网络游戏业务的运行状况,及时处理游戏运行中出现的故障,保障网络游戏服务的正常提供;
负责与游戏运营项目组的日常沟通交流,接受并处理项目组提出的运维需求;
针对各系统编写并维护自动化运维脚本;
负责项目组相关运营支撑工具的开发(Python);
负责日常运维工作的自动化、工具化建设;
参与游戏大数据挖掘与分析;
工作要求:
本科以上学历,计算机类或相关专业;
3年以上互联网行业经验、2年以上的批量服务器维护经验;
有开发经验,掌握Python、Bash、Sed、Awk等编程语言;
有较强的抗压能力、沟通能力、推动能力和较好的服务意识;
善于团队协作、项目管理、主动思考、自我驱动强;
优先(满足之一即可):
熟悉云技术应用阿里云,腾讯云,AWS者优先;
有知名游戏维护经验者优先,有数据挖掘经验者优先;
具有开源精神,能阅读源码,有DEVOPS/大数据平台运维管理经验者优先;
熟悉ELK等实时日志处理相关工作经验优先;
熟悉Docker、K8S原理,有Docker实际应用经验者优先;
联系方式:chen.yang@mihoyo.com
收起阅读 »
Elastic认证考试心得
2018 Elastic中国开发者大会前一天,我参加了Elastic认证工程师考试,隔天在大会的闪电演讲部分做了一个快速的分享。 昨天考试结果下来了,比较遗憾,没能通过。 不过这次参考心得颇多,值得专门写一篇文总结一下,帮助准备考认证的同学少走一点弯路。
考试内容
官方有一个考试要求达到的目标提纲Objectives, 其中涵盖的知识点还是比较广的,建议每个点都要根据文档操作演练一下。 我考前几天大致扫了一下提纲,感觉基本上都熟悉,没有仔细一一演练。 到了考试的时候,才发现有几个知识点只是浮于表面的了解,细节并不熟悉,临时去读文档时间又不够。
考试环境
用自己的电脑,登陆到考试网站,有一个远程桌面连接到考试虚拟机。虚拟机上原装了5个ES集群,结点数量各异。 桌面提供有一个浏览器,可以访问kibana和官方文档站点,还有一个终端,可以ssh到集群各个结点。 考试所有操作基本都是在kibana的sense和这个终端里完成, 期间只允许访问官方文档,不允许通过Google查找解决方案。 我们是现场考试,人工监考。 常规的考试是通过摄像头远程监考的,并且需要安装一个插件,检查后台进程。 按照规定,自己的机器只能开浏览器,不允许开evernotes等其他辅助工具。 远程桌面的速度不是很快,在浏览器里翻看文档会感觉有些卡顿,所以要求对文档非常熟悉,一查即准,否则来回翻页都会消耗不少时间。最好用鼠标,翻页会容易得多,我没带鼠标,用MAC的触摸板翻页,非常痛苦。 另外用Mac的同学,要适应一下拷贝粘贴快捷键,考试机器拷贝粘贴用的是ctrl-c / ctrl-v ,用惯了Mac的快捷键会有些不适应。
考试时长
3个小时,期间可以上厕所,但是建议考前少喝水,上好厕所,时间宝贵。
考题形式
12道考题全部是上机题,每道题描述一个场景,要求解决问题或者达到某个目标。 每道题都会涉及到考试提纲里2-3个知识点,所以对各个知识点细节的了解非常重要, 只要一个知识点理解的模糊,就容易卡住。 做题顺序可以自己控制,最好先把自己熟悉,马上能搞定的先做了,耗时超过10分钟还没把握的,先放一放最后再做把。这12道题我只完成了其中的9个,有3个在现场卡了比较长时间,因为时间不够放弃, 接下来的部分会做更细节的分析。
亲历考题类型总结
-
给一个状态是red的集群,要求不损失数据的前提下,让集群变green。
该题我遇到3个要解决的问题:- 有一个结点挂了,找到挂掉的结点,ssh上去,手动起来;
- 此时集群变成yellow,还是有shard不能分配,检查发现有一个索引的routings设置里,routing ->include里rack1写成了rakc1,故意写错的,修正好即可
- 集群依然还有shard是unassinged状态,继续检查发现有一个索引的routings里,include的rack数量不够,导致有些 replica分配不了。 更新一下routing,让他include更多的rack就解决了。集群状态变green。
此题考查的知识点包括,如何查看集群状态,如果查看结点列表,如何使用allocation explain api, 如何通过索引的allocation routing控制shard的分布。因为平常工作中解决集群问题比较多,所以此题完成比较轻松。
-
有一个文档,内容类似
dog & cat, 要求索引这条文档,并且使用match_phrasequery,查询dog & cat或者dog and cat都能match。此题我现场没搞出来,当时第一反应是标准tokenizer已经将
&剥离掉了,那么只要用stop words filter将and剥离掉,不就可以了吗? 结果配置后,发现match不上。 仔细一想,match_phase需要匹配位置的,&是tokenize阶段剥离的,and是token filter阶段剥离的,这样位置就不对了。 用analyzer api分析一下,位置的确不对。然后想到应该用synonym token filter来处理,结果配置还是一直有问题。 这时候耗时已经太多,直接放弃了。回来后又演练了一下这道题,才发现用synonym token filter是没问题的,但是tokenizer应该改成whitespace,否则&被剥离了。 总结起来还是平常这块用得少,不熟练,所以考试的时候时间一紧,脑子没转过来。 -
有index_a包含一些文档, 要求创建索引index_b,通过reindex api将index_a的文档索引到index_b。 要求增加一个整形字段,value是index_a的field_x的字符长度; 再增加一个数组类型的字段,value是field_y的词集合。(field_y是空格分割的一组词,比方
"foo bar",索引到index_b后,要求变成["foo", "bar"]。此题没什么技巧,就是考察reindex api的使用+ painless script。 但是我平常不怎么用painless,虽然原理上知道需要对一个字段求size,一个需要做split,但具体的语法不熟悉,也是来不及翻看文档,直接放弃。
-
按照要求创建一个index template,并且通过bulk api索引一些文档,达到自动创建索引的效果。 创建的索引的settings和mappings应该符合要求。
此题比较简单,熟悉index template语法,常用的settings, mappings设置就OK了。
-
按要求写一个查询, 其中一个条件是某个关键词必须包含在4个字段中至少2个。
此题也没什么技巧,考查bool query和minimum_should_match,熟悉就能写出来
-
按照要求写一个search template
熟悉search template的mustache模版语言即可轻松写出,但是很遗憾,平常没用过search template,虽然知道个大概,但是当时写的时候,不知道哪里语法有问题,PUT template总是不成功。猜想可能是哪个位置的字符没有转译产生非法json字符,或者哪一层嵌套有问题。 总之就是调试不成功,又浪费了很多时间。
-
多层嵌套聚合,其中还包括bucket过滤
没技巧,熟悉聚合,聚合嵌套,buckets过滤即可。
-
给定一个json文档,要求创建一个索引,定义一个nested field,将json文档索引成嵌套类型,同时完成指定的嵌套查询和排序。
比较简单,熟悉nested type和nested query即可完成。
-
给定两个集群,都包含有某个索引。 要求配置cross cluster search,能够从其中一个集群执行跨集群搜索,写出搜索的url和query body。
中间设置了一个陷阱,有一个集群有结点挂掉了,不能访问。 所以先要解决结点挂掉的问题,然后在要执行查询的集群配置cross cluster。 确认链接没问题以后,写出查询即可。
-
有一个3结点集群,还有一个kibana。 es集群没有安装x-pack,但是安装包已经放在了机器上,kibana有安装x-pack,并且启用了security,所以此时还连接不到集群。 要求给3个结点配置security,给内置的几个用户分别设定指定的密码。 之后添加指定的新用户,指定的role,并给用户赋予role a, role b。
此题熟悉x-pack security即可。 先分别ssh到3个结点,安装x-pack后启动结点。 等结点链接成功以后,用初始化内置用户密码的脚本,按要求分别设置密码。 之后就可以用elastic这个内置的管理员账号登陆kibana了。 然后通过kibana的用户和角色管理界面,分别添加对应的用户和角色。
还有2题是什么不太记得了,应该都是要求根据要求创建索引,reindex数据,然后执行某种类型的查询,或者聚合,比较简单吧。
总结下来,本次考试就是考察的知识点比较多,虽然只有12道考题,但是每道考题都是对多个知识点的综合考察,对ES的理解只停留在理论上是不够的,要求比较强的实际动手能力。 能考过的同学,一定是有过比较丰富的实际操作经验,该认证的含金量我感觉还是非常非常的高!
2018 Elastic中国开发者大会前一天,我参加了Elastic认证工程师考试,隔天在大会的闪电演讲部分做了一个快速的分享。 昨天考试结果下来了,比较遗憾,没能通过。 不过这次参考心得颇多,值得专门写一篇文总结一下,帮助准备考认证的同学少走一点弯路。
考试内容
官方有一个考试要求达到的目标提纲Objectives, 其中涵盖的知识点还是比较广的,建议每个点都要根据文档操作演练一下。 我考前几天大致扫了一下提纲,感觉基本上都熟悉,没有仔细一一演练。 到了考试的时候,才发现有几个知识点只是浮于表面的了解,细节并不熟悉,临时去读文档时间又不够。
考试环境
用自己的电脑,登陆到考试网站,有一个远程桌面连接到考试虚拟机。虚拟机上原装了5个ES集群,结点数量各异。 桌面提供有一个浏览器,可以访问kibana和官方文档站点,还有一个终端,可以ssh到集群各个结点。 考试所有操作基本都是在kibana的sense和这个终端里完成, 期间只允许访问官方文档,不允许通过Google查找解决方案。 我们是现场考试,人工监考。 常规的考试是通过摄像头远程监考的,并且需要安装一个插件,检查后台进程。 按照规定,自己的机器只能开浏览器,不允许开evernotes等其他辅助工具。 远程桌面的速度不是很快,在浏览器里翻看文档会感觉有些卡顿,所以要求对文档非常熟悉,一查即准,否则来回翻页都会消耗不少时间。最好用鼠标,翻页会容易得多,我没带鼠标,用MAC的触摸板翻页,非常痛苦。 另外用Mac的同学,要适应一下拷贝粘贴快捷键,考试机器拷贝粘贴用的是ctrl-c / ctrl-v ,用惯了Mac的快捷键会有些不适应。
考试时长
3个小时,期间可以上厕所,但是建议考前少喝水,上好厕所,时间宝贵。
考题形式
12道考题全部是上机题,每道题描述一个场景,要求解决问题或者达到某个目标。 每道题都会涉及到考试提纲里2-3个知识点,所以对各个知识点细节的了解非常重要, 只要一个知识点理解的模糊,就容易卡住。 做题顺序可以自己控制,最好先把自己熟悉,马上能搞定的先做了,耗时超过10分钟还没把握的,先放一放最后再做把。这12道题我只完成了其中的9个,有3个在现场卡了比较长时间,因为时间不够放弃, 接下来的部分会做更细节的分析。
亲历考题类型总结
-
给一个状态是red的集群,要求不损失数据的前提下,让集群变green。
该题我遇到3个要解决的问题:- 有一个结点挂了,找到挂掉的结点,ssh上去,手动起来;
- 此时集群变成yellow,还是有shard不能分配,检查发现有一个索引的routings设置里,routing ->include里rack1写成了rakc1,故意写错的,修正好即可
- 集群依然还有shard是unassinged状态,继续检查发现有一个索引的routings里,include的rack数量不够,导致有些 replica分配不了。 更新一下routing,让他include更多的rack就解决了。集群状态变green。
此题考查的知识点包括,如何查看集群状态,如果查看结点列表,如何使用allocation explain api, 如何通过索引的allocation routing控制shard的分布。因为平常工作中解决集群问题比较多,所以此题完成比较轻松。
-
有一个文档,内容类似
dog & cat, 要求索引这条文档,并且使用match_phrasequery,查询dog & cat或者dog and cat都能match。此题我现场没搞出来,当时第一反应是标准tokenizer已经将
&剥离掉了,那么只要用stop words filter将and剥离掉,不就可以了吗? 结果配置后,发现match不上。 仔细一想,match_phase需要匹配位置的,&是tokenize阶段剥离的,and是token filter阶段剥离的,这样位置就不对了。 用analyzer api分析一下,位置的确不对。然后想到应该用synonym token filter来处理,结果配置还是一直有问题。 这时候耗时已经太多,直接放弃了。回来后又演练了一下这道题,才发现用synonym token filter是没问题的,但是tokenizer应该改成whitespace,否则&被剥离了。 总结起来还是平常这块用得少,不熟练,所以考试的时候时间一紧,脑子没转过来。 -
有index_a包含一些文档, 要求创建索引index_b,通过reindex api将index_a的文档索引到index_b。 要求增加一个整形字段,value是index_a的field_x的字符长度; 再增加一个数组类型的字段,value是field_y的词集合。(field_y是空格分割的一组词,比方
"foo bar",索引到index_b后,要求变成["foo", "bar"]。此题没什么技巧,就是考察reindex api的使用+ painless script。 但是我平常不怎么用painless,虽然原理上知道需要对一个字段求size,一个需要做split,但具体的语法不熟悉,也是来不及翻看文档,直接放弃。
-
按照要求创建一个index template,并且通过bulk api索引一些文档,达到自动创建索引的效果。 创建的索引的settings和mappings应该符合要求。
此题比较简单,熟悉index template语法,常用的settings, mappings设置就OK了。
-
按要求写一个查询, 其中一个条件是某个关键词必须包含在4个字段中至少2个。
此题也没什么技巧,考查bool query和minimum_should_match,熟悉就能写出来
-
按照要求写一个search template
熟悉search template的mustache模版语言即可轻松写出,但是很遗憾,平常没用过search template,虽然知道个大概,但是当时写的时候,不知道哪里语法有问题,PUT template总是不成功。猜想可能是哪个位置的字符没有转译产生非法json字符,或者哪一层嵌套有问题。 总之就是调试不成功,又浪费了很多时间。
-
多层嵌套聚合,其中还包括bucket过滤
没技巧,熟悉聚合,聚合嵌套,buckets过滤即可。
-
给定一个json文档,要求创建一个索引,定义一个nested field,将json文档索引成嵌套类型,同时完成指定的嵌套查询和排序。
比较简单,熟悉nested type和nested query即可完成。
-
给定两个集群,都包含有某个索引。 要求配置cross cluster search,能够从其中一个集群执行跨集群搜索,写出搜索的url和query body。
中间设置了一个陷阱,有一个集群有结点挂掉了,不能访问。 所以先要解决结点挂掉的问题,然后在要执行查询的集群配置cross cluster。 确认链接没问题以后,写出查询即可。
-
有一个3结点集群,还有一个kibana。 es集群没有安装x-pack,但是安装包已经放在了机器上,kibana有安装x-pack,并且启用了security,所以此时还连接不到集群。 要求给3个结点配置security,给内置的几个用户分别设定指定的密码。 之后添加指定的新用户,指定的role,并给用户赋予role a, role b。
此题熟悉x-pack security即可。 先分别ssh到3个结点,安装x-pack后启动结点。 等结点链接成功以后,用初始化内置用户密码的脚本,按要求分别设置密码。 之后就可以用elastic这个内置的管理员账号登陆kibana了。 然后通过kibana的用户和角色管理界面,分别添加对应的用户和角色。
还有2题是什么不太记得了,应该都是要求根据要求创建索引,reindex数据,然后执行某种类型的查询,或者聚合,比较简单吧。
总结下来,本次考试就是考察的知识点比较多,虽然只有12道考题,但是每道考题都是对多个知识点的综合考察,对ES的理解只停留在理论上是不够的,要求比较强的实际动手能力。 能考过的同学,一定是有过比较丰富的实际操作经验,该认证的含金量我感觉还是非常非常的高!
收起阅读 »社区日报 第448期 (2018-11-14)
http://t.cn/EAd7TEb
2. 搜索引擎从0到1
http://t.cn/EAVZqan
3. CentOS7 上搭建多节点 Elasticsearch集群
http://t.cn/EAdzxTP
编辑:江水
归档:https://elasticsearch.cn/article/6132
订阅:https://tinyletter.com/elastic-daily
http://t.cn/EAd7TEb
2. 搜索引擎从0到1
http://t.cn/EAVZqan
3. CentOS7 上搭建多节点 Elasticsearch集群
http://t.cn/EAdzxTP
编辑:江水
归档:https://elasticsearch.cn/article/6132
订阅:https://tinyletter.com/elastic-daily 收起阅读 »
社区日报 第447期 (2018-11-13)
http://t.cn/EAE6hvv
2、从平台到中台 | Elasticsearch 在蚂蚁金服的实践经验。
http://t.cn/EATs2iu
3、一文介绍Spring Data Elasticsearch。
http://t.cn/EAE698A
编辑:叮咚光军
归档:https://elasticsearch.cn/article/6131
订阅:https://tinyletter.com/elastic-daily
http://t.cn/EAE6hvv
2、从平台到中台 | Elasticsearch 在蚂蚁金服的实践经验。
http://t.cn/EATs2iu
3、一文介绍Spring Data Elasticsearch。
http://t.cn/EAE698A
编辑:叮咚光军
归档:https://elasticsearch.cn/article/6131
订阅:https://tinyletter.com/elastic-daily 收起阅读 »
社区日报 第446期 (2018-11-12)
2.剖析Elasticsearch的IndexSorting:一种查询性能优化利器
http://t.cn/EAlDnwc
3.记一次ElasticSearch集群灾难恢复。
http://t.cn/EAlk7Et
编辑:cyberdak
归档:https://elasticsearch.cn/article/6130
订阅:https://tinyletter.com/elastic-daily
2.剖析Elasticsearch的IndexSorting:一种查询性能优化利器
http://t.cn/EAlDnwc
3.记一次ElasticSearch集群灾难恢复。
http://t.cn/EAlk7Et
编辑:cyberdak
归档:https://elasticsearch.cn/article/6130
订阅:https://tinyletter.com/elastic-daily
收起阅读 »
社区日报 第445期 (2018-11-11)
http://t.cn/EAKdvJf
2.使用ELASTICSEARCH,LOGSTASH和KIBANA可视化数据。
http://t.cn/EA9zCvV
3.使用Golang的Elasticsearch查询示例。
http://t.cn/RRmNcop
编辑:至尊宝
归档:https://elasticsearch.cn/article/6129
订阅:https://tinyletter.com/elastic-daily
http://t.cn/EAKdvJf
2.使用ELASTICSEARCH,LOGSTASH和KIBANA可视化数据。
http://t.cn/EA9zCvV
3.使用Golang的Elasticsearch查询示例。
http://t.cn/RRmNcop
编辑:至尊宝
归档:https://elasticsearch.cn/article/6129
订阅:https://tinyletter.com/elastic-daily 收起阅读 »
Elastic日报 第444期 (2018-11-10)
http://t.cn/R5iirZ2
2、PB级Elasticsearch集群的分片分配策略
http://t.cn/EAfPVjT
3、使用Elasticsearch在地图上查找特定元素的方法
http://t.cn/EAfP8Bi
编辑: bsll
归档:https://elasticsearch.cn/article/6128
订阅:https://tinyletter.com/elastic-daily
http://t.cn/R5iirZ2
2、PB级Elasticsearch集群的分片分配策略
http://t.cn/EAfPVjT
3、使用Elasticsearch在地图上查找特定元素的方法
http://t.cn/EAfP8Bi
编辑: bsll
归档:https://elasticsearch.cn/article/6128
订阅:https://tinyletter.com/elastic-daily 收起阅读 »
elasticsearch冷热数据读写分离
Elasticsearch5.5冷热数据读写分离
前言
冷数据索引:查询频率低,基本无写入,一般为当天或最近2天以前的数据索引
热数据索引:查询频率高,写入压力大,一般为当天数据索引
当前系统日志每日写入量约为6T左右,日志数据供全线业务系统查询使用。
查询问题:
高峰时段写入及查询频率都较高,集群压力较大,查询ES时,常出现查询缓慢问题。
写入问题:
索引峰值写入量约为12w/s,且无副本。加上副本将导致索引写入速度减半、磁盘使用量加倍;不使用副本,若一个节点宕掉,整个集群无法写入,后果严重。
一、冷热数据分离
ES集群的索引写入及查询速度主要依赖于磁盘的IO速度,冷热数据分离的关键为使用SSD磁盘存储数据。
若全部使用SSD,成本过高,且存放冷数据较为浪费,因而使用普通SATA磁盘与SSD磁盘混搭,可做到资源充分利用,性能大幅提升的目标。
几个ES关键配置解读:
-
节点属性(后续索引及集群路由分布策略均依据此属性)
node.attr.box_type node.attr.zone ...elasticsearch.yml中可增加自定义配置,配置前缀为node.attr,后续属性及值可自定义,如:box_type、zone,即为当前es节点增加标签,亦可在启动命令时设置:bin/elasticsearch -d -Enode.attr.box_type=hot
-
索引路由分布策略
"index.routing.allocation.require.box_type": "hot"可在索引模板setting中设置,也可通过rest api动态更新。意义为索引依据哪个属性标签,对分片、副本进行路由分布。
如我们对使用SSD作为存储介质的ES节点增加属性标签node.attr.box_type: hot,对其他SATA类ES节点增加属性标签node.attr.box_type: cool,将使当前索引的分片数据都落在SSD上。

后续对其索引配置更新为
"index.routing.allocation.require.box_type": "cool"将使索引分片从SSD磁盘上路由至SATA磁盘上,达到冷热数据分离的效果。

-
集群路由分布策略(此策略比索引级路由策略权重高)
目的:不将鸡蛋放进一个篮子中。
"cluster.routing.allocation.awareness.attributes": "box_type"如上配置,新建索引时,索引分片及副本只会分配到含有node.attr.box_type属性的节点上。(该值可以为多个,如"box_type,zone")
若集群中的节点box_type值只有一个,如只有hot,索引分片及副本会落在hot标签的节点上;若box_type值包括hot、cool,则同一个分片与其副本将尽可能不在相同的box_type节点上。
此种场景使用于:同一个物理机含有多个ES节点,若这多个节点标签相同,使用此路由分布策略将尽可能保证相同物理机上不会存放同一个分片及其副本。
"cluster.routing.allocation.awareness.force.box_type.values": "hot,cool"强制使分片与副本分离。若只有hot标签的节点,索引只有分片可以写入,副本无法分配;若有hot、cool两种标签节点,相同分片与其副本绝不在相同标签节点上。

二、数据读写分离
几点结论:
- 若使当天索引及副本都写在SSD磁盘上,SSD磁盘使用量需20T以上,代价可能过高。(读写效率最高,但由于SSD节点肯定较少,读写都在相同节点上,节点压力会非常大)
- 现有的方式,只使用普通的SATA磁盘存储,代价最低。(读写效率最低,即为当前运行状况)
- 使用集群路由分配策略,SSD与SATA各存放1份数据,SSD磁盘需分配10T以上。(读写效率折中,均有较大提升)
若使用折中方案,另一个问题考虑:
SSD节点即有读操作,也有写操作,节点较少,压力还是较大,怎么实现mysql的主从模式,达到读写分离的效果?
目标:使主分片分配在SSD磁盘上,副本落在SATA磁盘上,读取时优先从副本中查询数据,SSD节点只负责写入数据。
实现步骤:
-
修改集群路由分配策略配置
增加集群路由配置
"allocation.awareness.attributes": "box_type", "allocation.awareness.force.box_type.values": "hot,cool" -
提前创建索引
提前创建下一天的索引,索引配置如下(可写入模板中):
PUT log4x_trace_2018_08_11 { "settings": { "index.routing.allocation.require.box_type": "hot", "number_of_replicas": 0 } }此操作可使索引所有分片都分配在SSD磁盘中。
-
修改索引路由分配策略配置
索引创建好后,动态修改索引配置
PUT log4x_trace_2018_08_11/_settings { "index.routing.allocation.require.box_type": null, "number_of_replicas": 1 }

-
转为冷数据
动态修改索引配置,并取消副本数
PUT log4x_trace_2018_08_11/_settings { "index.routing.allocation.require.box_type": "cool", "number_of_replicas": 0 }

Elasticsearch5.5冷热数据读写分离
前言
冷数据索引:查询频率低,基本无写入,一般为当天或最近2天以前的数据索引
热数据索引:查询频率高,写入压力大,一般为当天数据索引
当前系统日志每日写入量约为6T左右,日志数据供全线业务系统查询使用。
查询问题:
高峰时段写入及查询频率都较高,集群压力较大,查询ES时,常出现查询缓慢问题。
写入问题:
索引峰值写入量约为12w/s,且无副本。加上副本将导致索引写入速度减半、磁盘使用量加倍;不使用副本,若一个节点宕掉,整个集群无法写入,后果严重。
一、冷热数据分离
ES集群的索引写入及查询速度主要依赖于磁盘的IO速度,冷热数据分离的关键为使用SSD磁盘存储数据。
若全部使用SSD,成本过高,且存放冷数据较为浪费,因而使用普通SATA磁盘与SSD磁盘混搭,可做到资源充分利用,性能大幅提升的目标。
几个ES关键配置解读:
-
节点属性(后续索引及集群路由分布策略均依据此属性)
node.attr.box_type node.attr.zone ...elasticsearch.yml中可增加自定义配置,配置前缀为node.attr,后续属性及值可自定义,如:box_type、zone,即为当前es节点增加标签,亦可在启动命令时设置:bin/elasticsearch -d -Enode.attr.box_type=hot
-
索引路由分布策略
"index.routing.allocation.require.box_type": "hot"可在索引模板setting中设置,也可通过rest api动态更新。意义为索引依据哪个属性标签,对分片、副本进行路由分布。
如我们对使用SSD作为存储介质的ES节点增加属性标签node.attr.box_type: hot,对其他SATA类ES节点增加属性标签node.attr.box_type: cool,将使当前索引的分片数据都落在SSD上。
后续对其索引配置更新为
"index.routing.allocation.require.box_type": "cool"将使索引分片从SSD磁盘上路由至SATA磁盘上,达到冷热数据分离的效果。
-
集群路由分布策略(此策略比索引级路由策略权重高)
目的:不将鸡蛋放进一个篮子中。
"cluster.routing.allocation.awareness.attributes": "box_type"如上配置,新建索引时,索引分片及副本只会分配到含有node.attr.box_type属性的节点上。(该值可以为多个,如"box_type,zone")
若集群中的节点box_type值只有一个,如只有hot,索引分片及副本会落在hot标签的节点上;若box_type值包括hot、cool,则同一个分片与其副本将尽可能不在相同的box_type节点上。
此种场景使用于:同一个物理机含有多个ES节点,若这多个节点标签相同,使用此路由分布策略将尽可能保证相同物理机上不会存放同一个分片及其副本。
"cluster.routing.allocation.awareness.force.box_type.values": "hot,cool"强制使分片与副本分离。若只有hot标签的节点,索引只有分片可以写入,副本无法分配;若有hot、cool两种标签节点,相同分片与其副本绝不在相同标签节点上。
二、数据读写分离
几点结论:
- 若使当天索引及副本都写在SSD磁盘上,SSD磁盘使用量需20T以上,代价可能过高。(读写效率最高,但由于SSD节点肯定较少,读写都在相同节点上,节点压力会非常大)
- 现有的方式,只使用普通的SATA磁盘存储,代价最低。(读写效率最低,即为当前运行状况)
- 使用集群路由分配策略,SSD与SATA各存放1份数据,SSD磁盘需分配10T以上。(读写效率折中,均有较大提升)
若使用折中方案,另一个问题考虑:
SSD节点即有读操作,也有写操作,节点较少,压力还是较大,怎么实现mysql的主从模式,达到读写分离的效果?
目标:使主分片分配在SSD磁盘上,副本落在SATA磁盘上,读取时优先从副本中查询数据,SSD节点只负责写入数据。
实现步骤:
-
修改集群路由分配策略配置
增加集群路由配置
"allocation.awareness.attributes": "box_type", "allocation.awareness.force.box_type.values": "hot,cool" -
提前创建索引
提前创建下一天的索引,索引配置如下(可写入模板中):
PUT log4x_trace_2018_08_11 { "settings": { "index.routing.allocation.require.box_type": "hot", "number_of_replicas": 0 } }此操作可使索引所有分片都分配在SSD磁盘中。
-
修改索引路由分配策略配置
索引创建好后,动态修改索引配置
PUT log4x_trace_2018_08_11/_settings { "index.routing.allocation.require.box_type": null, "number_of_replicas": 1 }
-
转为冷数据
动态修改索引配置,并取消副本数
PUT log4x_trace_2018_08_11/_settings { "index.routing.allocation.require.box_type": "cool", "number_of_replicas": 0 }

