

【搜索客社区日报】第2134期 (2025-10-27)
https://elasticstack.blog.csdn ... 74404
2、Elasticsearch:隔离环境中的高级向量搜索
https://elasticstack.blog.csdn ... 74013
3、在 Elastic Observability 中,启用 TSDS 集成可节省高达 70% 的指标存储
https://elasticstack.blog.csdn ... 15817
4、Agent下半场!比Prompt更重要的是「上下文工程」,Anthropic首次系统阐述
https://mp.weixin.qq.com/s/pFo4hGAAgmYEQUJcC6otkw
5、一文读懂传统RAG、多模态RAG、Agentic RAG与GraphRAG
https://mp.weixin.qq.com/s/pNUymIuRACOy2QG9Et4v0Q
编辑:Muse
更多资讯:http://news.searchkit.cn
https://elasticstack.blog.csdn ... 74404
2、Elasticsearch:隔离环境中的高级向量搜索
https://elasticstack.blog.csdn ... 74013
3、在 Elastic Observability 中,启用 TSDS 集成可节省高达 70% 的指标存储
https://elasticstack.blog.csdn ... 15817
4、Agent下半场!比Prompt更重要的是「上下文工程」,Anthropic首次系统阐述
https://mp.weixin.qq.com/s/pFo4hGAAgmYEQUJcC6otkw
5、一文读懂传统RAG、多模态RAG、Agentic RAG与GraphRAG
https://mp.weixin.qq.com/s/pNUymIuRACOy2QG9Et4v0Q
编辑:Muse
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2133期 (2025-10-23)
https://mp.weixin.qq.com/s/ki5Tq-kTnzadfTbiqEItOg
2.蚂蚁的 SGLang 高效实践:DeepSeek R1 on H20
https://mp.weixin.qq.com/s/LBQ1YMyOjlNo4w0dGxwtJA
3.英伟达携手LMCache:用 Dynamo解锁KV缓存性能新突破
https://mp.weixin.qq.com/s/UzArWDs_TAiW4CiDEL9IyQ
编辑:Se7en
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/ki5Tq-kTnzadfTbiqEItOg
2.蚂蚁的 SGLang 高效实践:DeepSeek R1 on H20
https://mp.weixin.qq.com/s/LBQ1YMyOjlNo4w0dGxwtJA
3.英伟达携手LMCache:用 Dynamo解锁KV缓存性能新突破
https://mp.weixin.qq.com/s/UzArWDs_TAiW4CiDEL9IyQ
编辑:Se7en
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2132期 (2025-10-22)
https://medium.com/data-scienc ... 54a63
2.从零到智能代理的实战指南(搭梯)
http://medium.com/data-science ... dd099
3.50 个 LLMs 面试问题终极列表(搭梯)
https://medium.com/data-scienc ... 756ee
编辑:kin122
更多资讯:http://news.searchkit.cn
https://medium.com/data-scienc ... 54a63
2.从零到智能代理的实战指南(搭梯)
http://medium.com/data-science ... dd099
3.50 个 LLMs 面试问题终极列表(搭梯)
https://medium.com/data-scienc ... 756ee
编辑:kin122
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2131期 (2025-10-21)
https://marius-ciclistu.medium ... 1777e
2. 怎么在Ubuntu里搭存储体系(需要梯子)
https://medium.com/%40yogeshwa ... 51d0b
3. 用ES深入挖掘集群行为和内存堆栈信息(需要梯子)
https://manish-dixit.medium.co ... 9e84c
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
https://marius-ciclistu.medium ... 1777e
2. 怎么在Ubuntu里搭存储体系(需要梯子)
https://medium.com/%40yogeshwa ... 51d0b
3. 用ES深入挖掘集群行为和内存堆栈信息(需要梯子)
https://manish-dixit.medium.co ... 9e84c
编辑:斯蒂文
更多资讯:http://news.searchkit.cn 收起阅读 »
搜索百科(5):Easysearch — 自主可控的国产分布式搜索引擎
大家好,我是 INFINI Labs 的石阳。
欢迎关注 《搜索百科》 专栏!每天 5 分钟,带你速览一款搜索相关的技术或产品,同时还会带你探索它们背后的技术原理、发展故事及上手体验等。
在上一篇我们介绍了 OpenSearch —— 那个因协议争议而诞生的开源搜索分支。今天,我们把目光转向国内,聊聊极限科技研发的一款轻量级搜索引擎:Easysearch。
引言
在搜索技术的世界里,从 Lucene 的出现到 Solr、Elasticsearch 的崛起,搜索引擎技术已经发展了二十余年。然而,随着开源协议的变更与国际形势的变化,国产自主搜索引擎的需求愈发迫切。在这样的背景下,Easysearch 作为一款自主可控、轻量高效、兼容 Elasticsearch 的分布式搜索引擎应运而生,为国内企业带来了全新的选择。

Easysearch 概述
Easysearch 是一款分布式搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析、AI 集成等。Easysearch 衍生自开源协议 Apache 2.0 的 Elasticsearch 7.10 版本,并不断往前迭代更新,紧跟 Lucene 最新版本的更新。Easysearch 可以替代 Elasticsearch,同时添加和完善多项企业级功能。
- 首次发布:2023 年 4 月
- 最新版本:1.15.4(截止 2025 年 10 月)
- 主导企业:极限科技 (INFINI Labs)
- 官方网址:https://easysearch.cn
诞生背景:为什么要有 Easysearch?
Easysearch 由极限科技(INFINI Labs)团队推出。项目的起点源于团队长期在搜索引擎和大数据领域的深厚实践积累,团队深刻认识到国内企业在使用 Elasticsearch 时普遍面临以下痛点:
- 开源协议变化带来的商业风险 —— Elastic 于 2021 年将许可更改为 SSPL,导致社区分裂,增加了企业在合规和商用上的不确定性;
- 高并发与高可靠性场景下对稳定可控方案的需求 —— 企业级应用亟需一个性能可靠、可深度优化的搜索基础设施;
- 技术栈自主可控的迫切需求 —— 随着国产化进程加快,国内生态中缺乏轻量化、易部署、且完全可控的搜索引擎产品;
- 本地化服务与快速响应能力的缺口 —— 国内企业更需要本地团队提供高效的技术支持与服务,对本土化、个性化功能需求能得到及时响应与反馈。
基于这些考虑,Easysearch 在设计之初就明确了目标:构建一款兼容 Elasticsearch API、简洁易用、性能出众且完全自主可控的国产搜索引擎。
核心特性
- 轻量级:安装包大小不到 60 MB,安装部署简洁,资源占用低,开箱即用;
- 跨平台:支持主流操作系统和 CPU 架构,支持国产信创运行环境;
- 高性能:针对不同场景进行的极致优化,可用更少硬件成本获得更高服务性能,降本增效。
- 稳定可靠:修复大量内核问题,解决内存泄露,集群卡顿、查询缓慢等问题,久经严苛业务环境考验。
- 安全增强:默认就提供完整的企业级安全功能,支持 LDAP/AD 集成,支持索引、文档、字段粒度细权管控。
- 兼容性强:兼容 Elasticsearch 7.x 的 REST API 和数据格式,迁移成本低;
- 可视化运维:无需 Kibana 即可通过内置 Web UI 插件界面管理索引、节点与监控指标等。
对比优势
| 对比维度 | Easysearch | Elasticsearch | OpenSearch |
|---|---|---|---|
| 用户协议 | 社区免费+商业授权 | SSPL/AGPL v3 | Apache 2.0 |
| API 兼容性 | 高度兼容 ES | 原生 | 高度兼容 ES |
| 最小安装体积 | 57MB | 482MB | 682MB |
| 部署复杂度 | 简单 | 中等 | 相对复杂 |
| 信创环境支持 | 全面兼容 | 无 | 无 |
| 可视化管理 | 开箱即用管理后台 | 需独立部署 Kibana | 需独立部署 OpenSearch Dashboards |
| 本地化与中文支持 | 强 | 弱 | 弱 |
| AI 插件支持 | 较弱 | 强 | 较强 |
| 社区与生态 | 快速成长中 | 成熟广泛 | 活跃增长 |
快速开始:5 分钟体验 Easysearch
1. 使用 Docker 启动
# 直接运行镜像使用随机密码(数据及配置未持久化)
docker run --name easysearch \
--ulimit memlock=-1:-1 \
-p 9200:9200 \
infinilabs/easysearch:1.15.42. 验证集群状态
curl -ku "username:password" -X GET "https://localhost:9200/"返回结果示例:
{
"name": "easysearch-node",
"cluster_name": "easysearch-6yhwn91v80gf",
"cluster_uuid": "Gfu_fuF1QViJfeUWVbiFCA",
"version": {
"distribution": "easysearch",
"number": "1.15.4",
"distributor": "INFINI Labs",
"build_hash": "9110128946b0af3de639966cfa74b5498346949d",
"build_date": "2025-10-14T03:30:41.948590Z",
"build_snapshot": false,
"lucene_version": "8.11.4",
"minimum_wire_lucene_version": "7.7.0",
"minimum_lucene_index_compatibility_version": "7.7.0"
},
"tagline": "You Know, For Easy Search!"
}3. 索引与搜索示例
# 写入文档
curl -ku "username:password" -X POST "https://localhost:9200/my_index/_doc" -H 'Content-Type: application/json' -d'
{
"title": "Easysearch 入门",
"content": "这是一个轻量级搜索引擎的示例文档。",
"tags": ["搜索", "国产", "轻量级"]
}'
# 搜索文档
curl -ku "username:password" -X GET "https://localhost:9200/my_index/_search" -H 'Content-Type: application/json' -d'
{
"query": {
"match": {
"content": "搜索引擎"
}
}
}'4. 使用 Easysearch UI
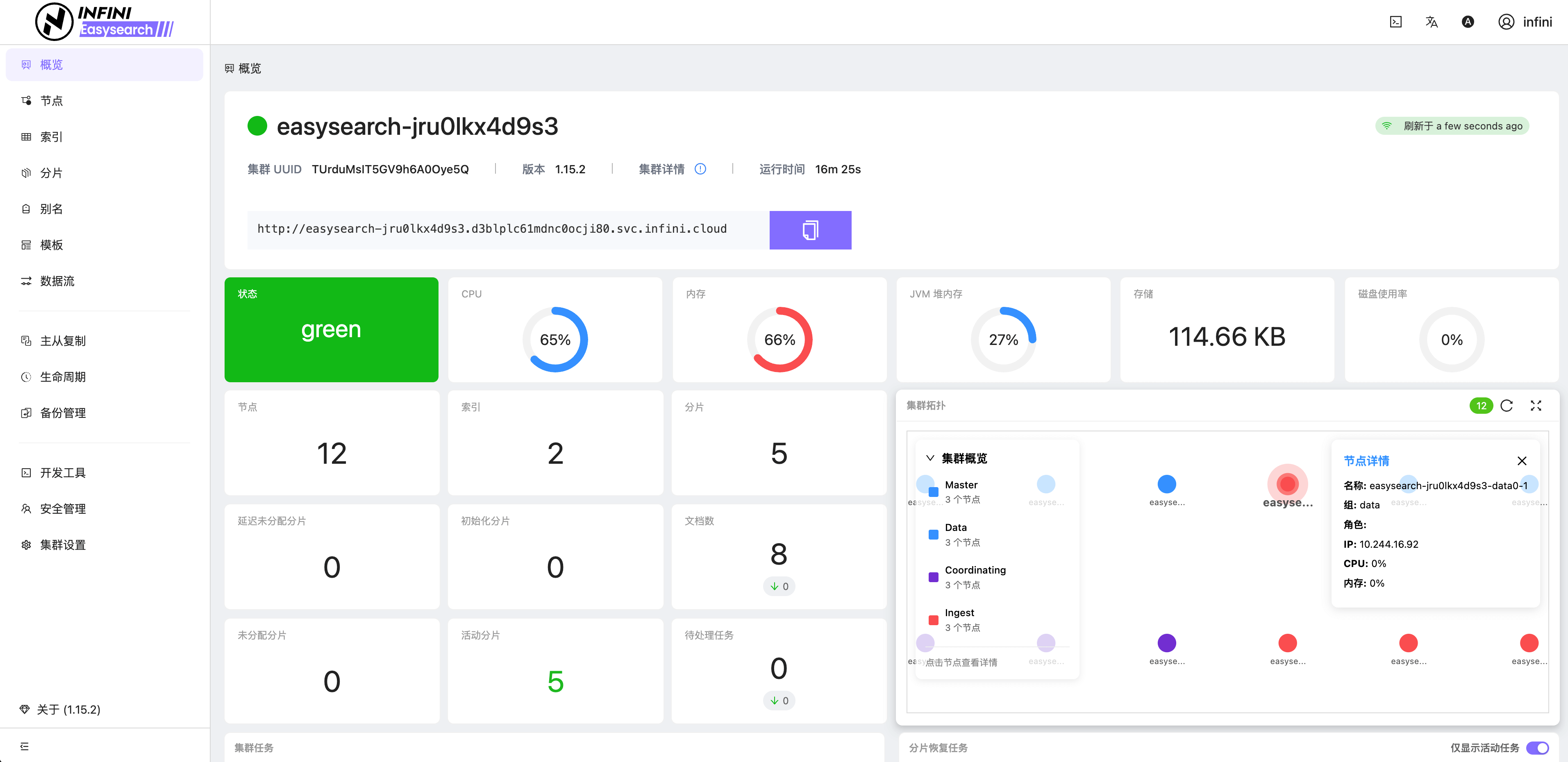
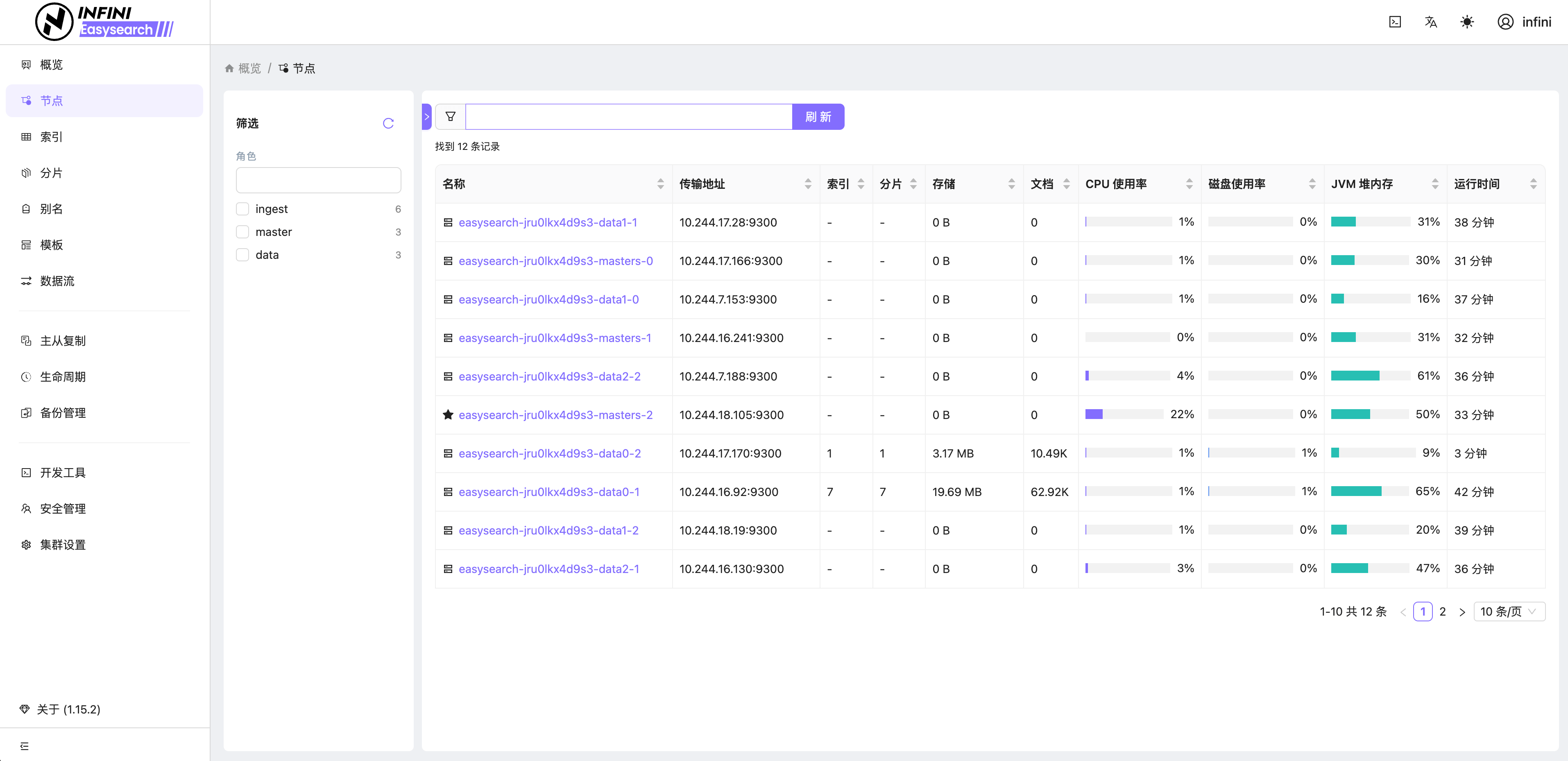
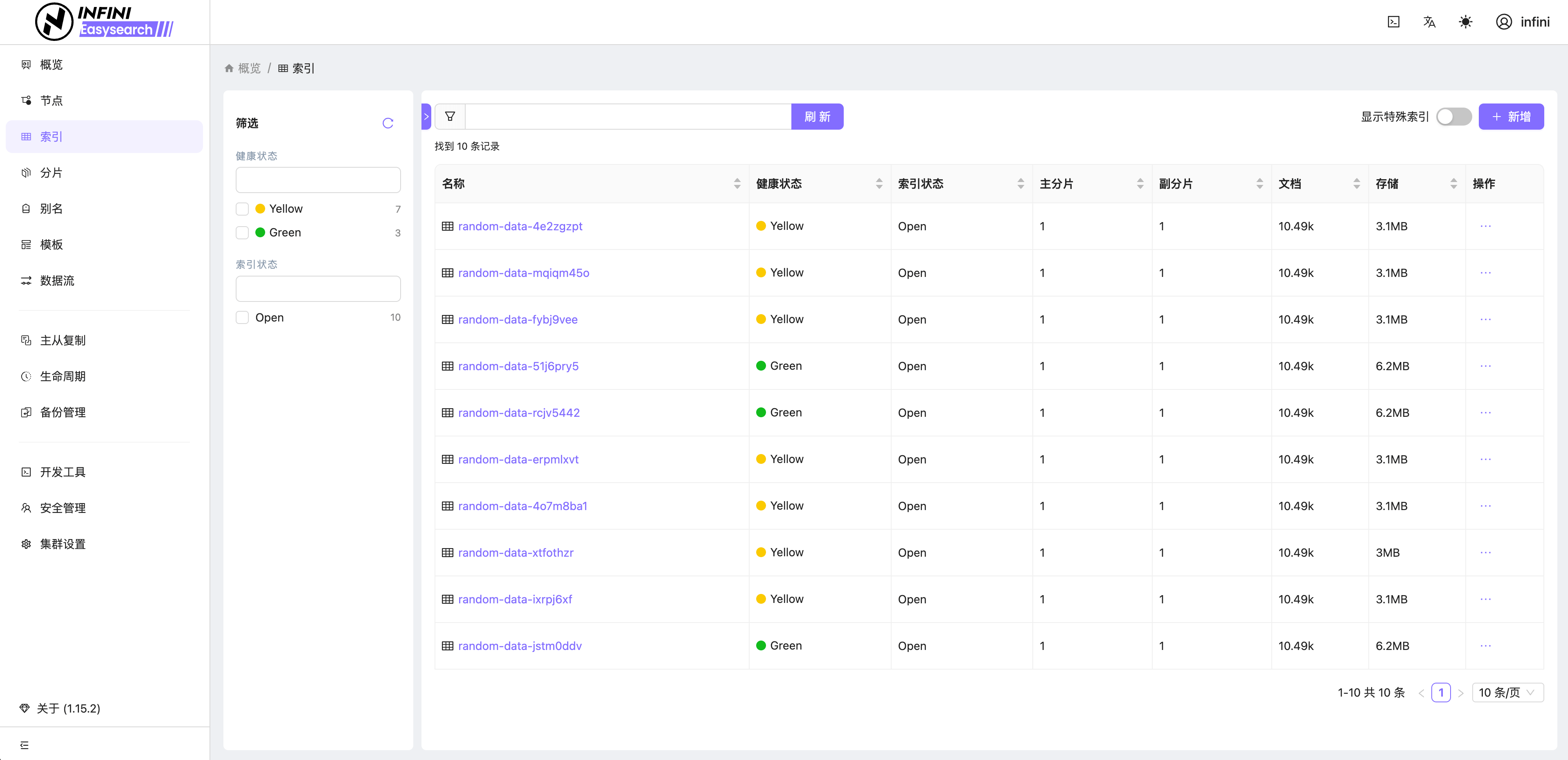
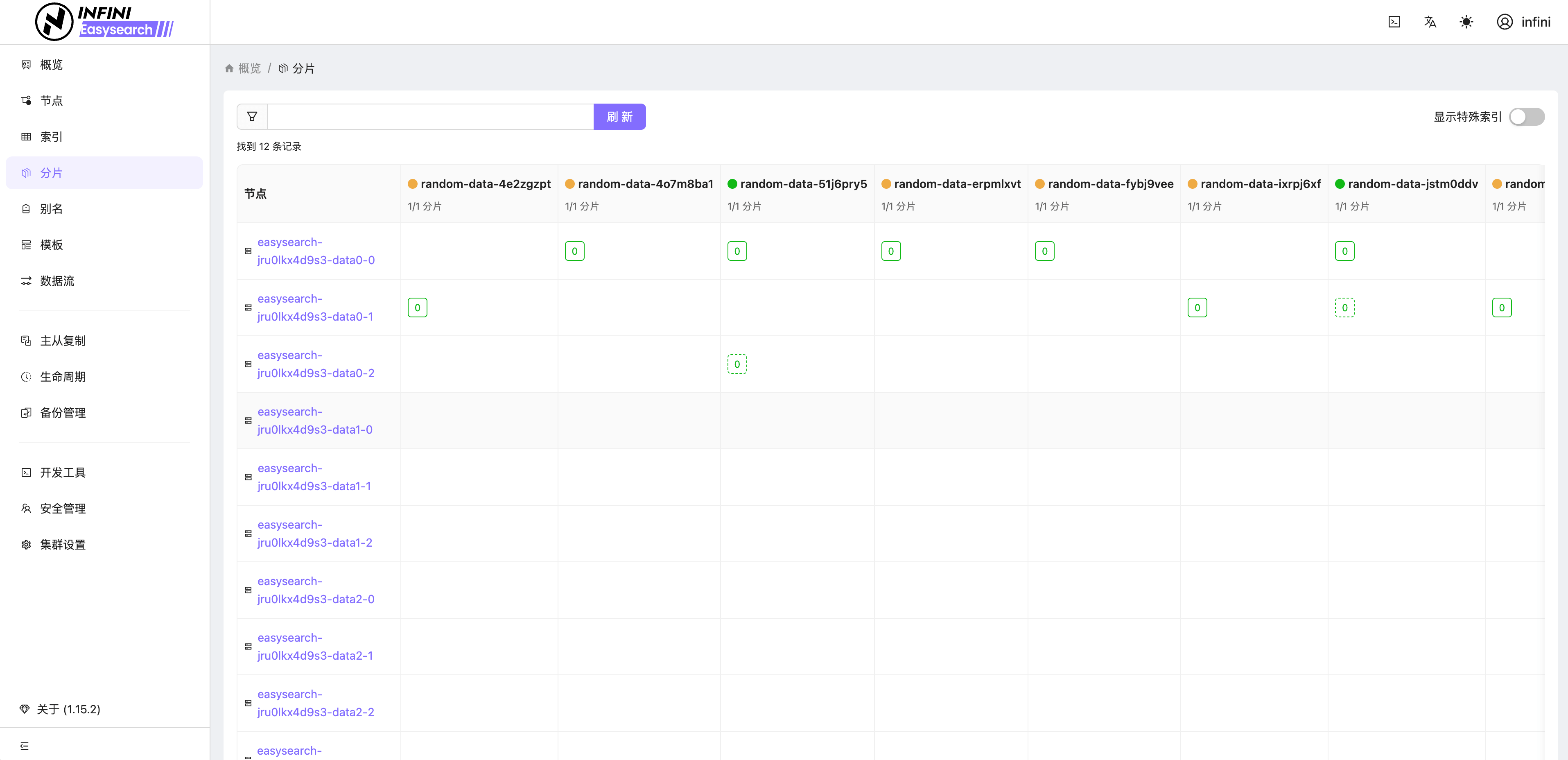
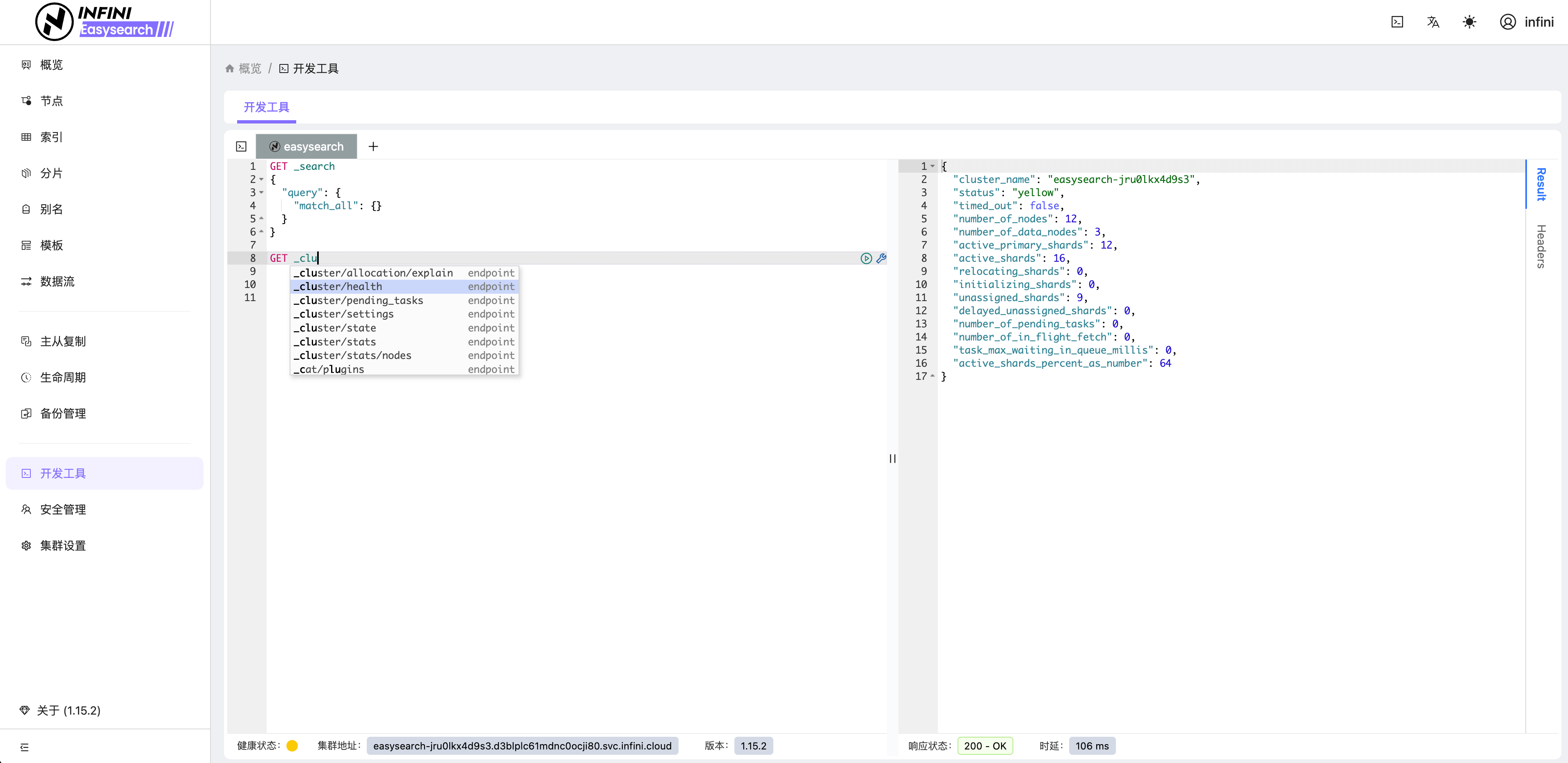
Easysearch 提供了轻量级界面化管理功能,不再依赖第三方组件即可对集群进行管理,真正做到开箱即用。如果你安装了 Easysearch UI 插件或者下载捆绑包,可通过 https://localhost:9200/\_ui/ 访问,进行节点、索引、分片、查询调试和监控查看等管理。
图 1:系统登录
图 2:集群概览
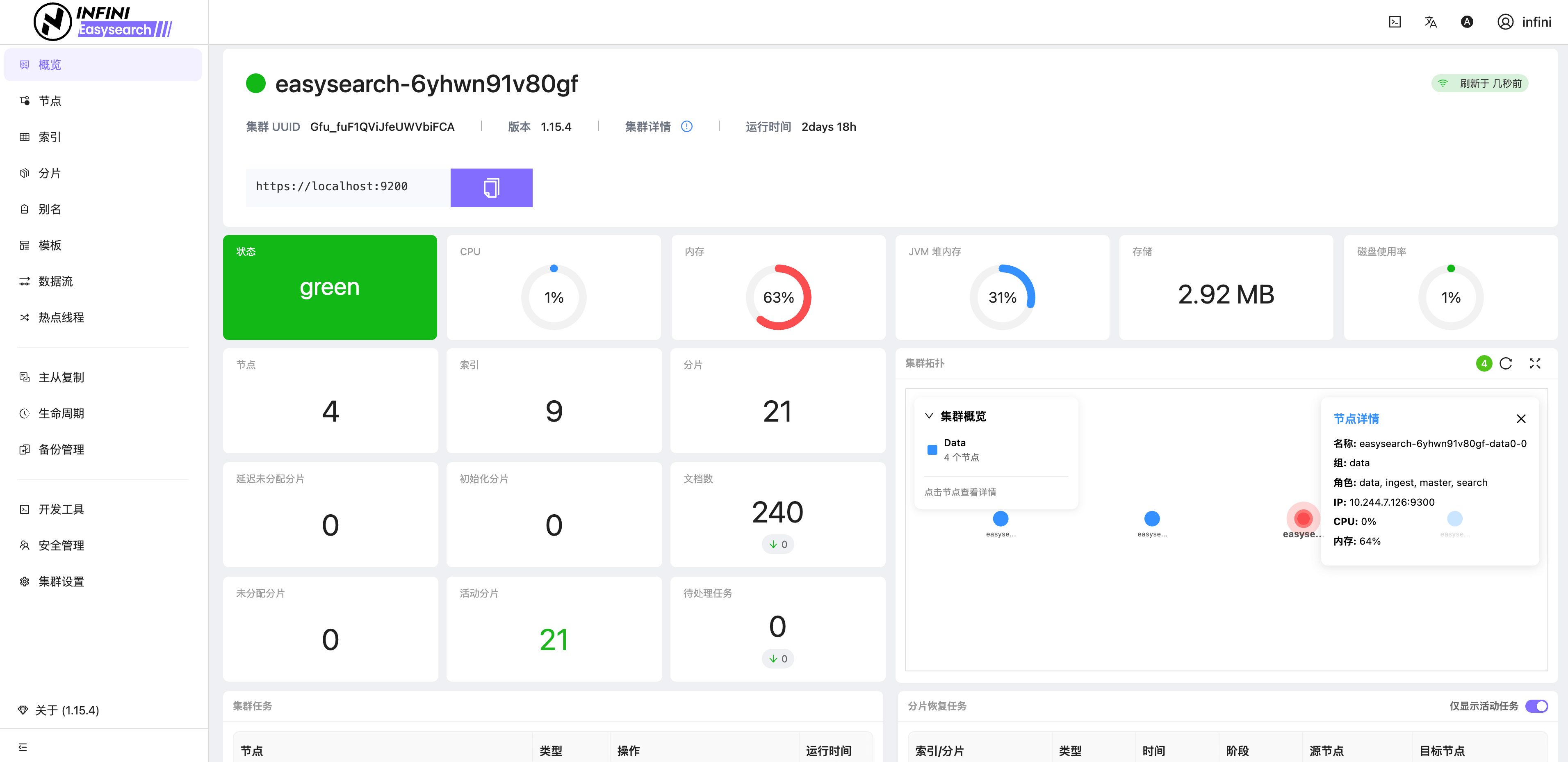
图 3:节点列表
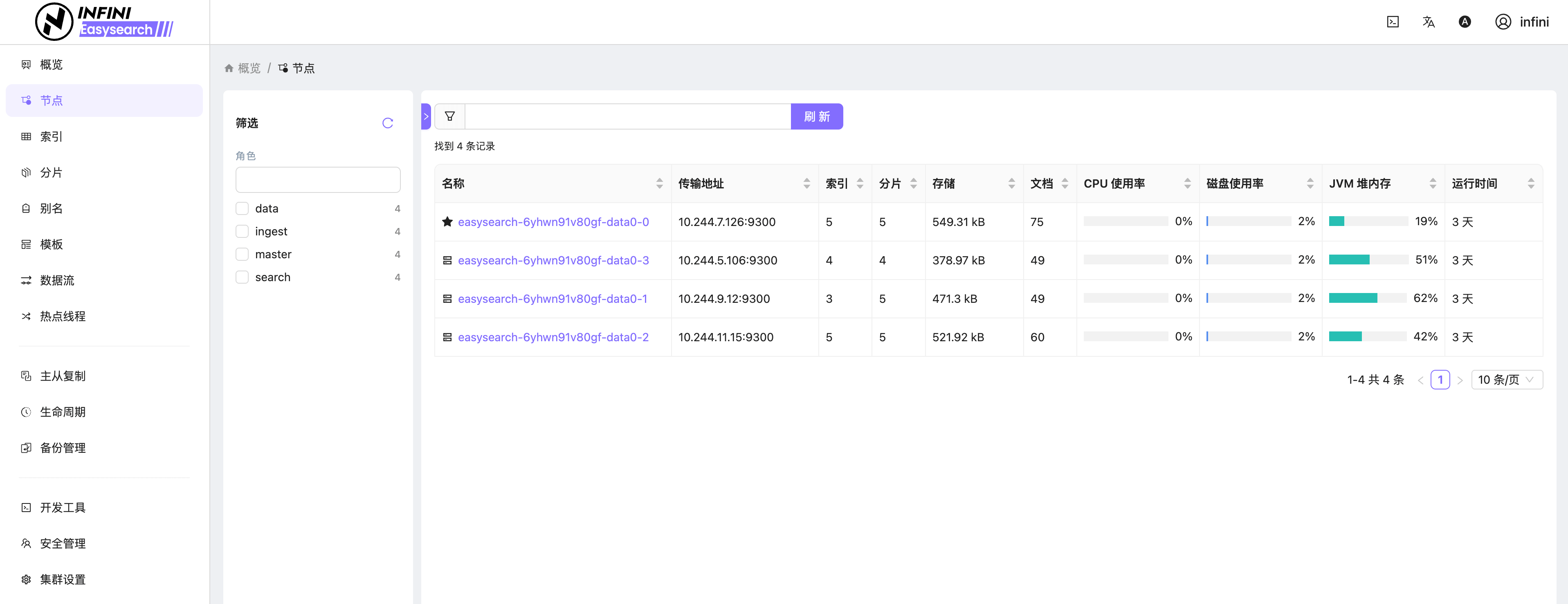
图 4:节点概览
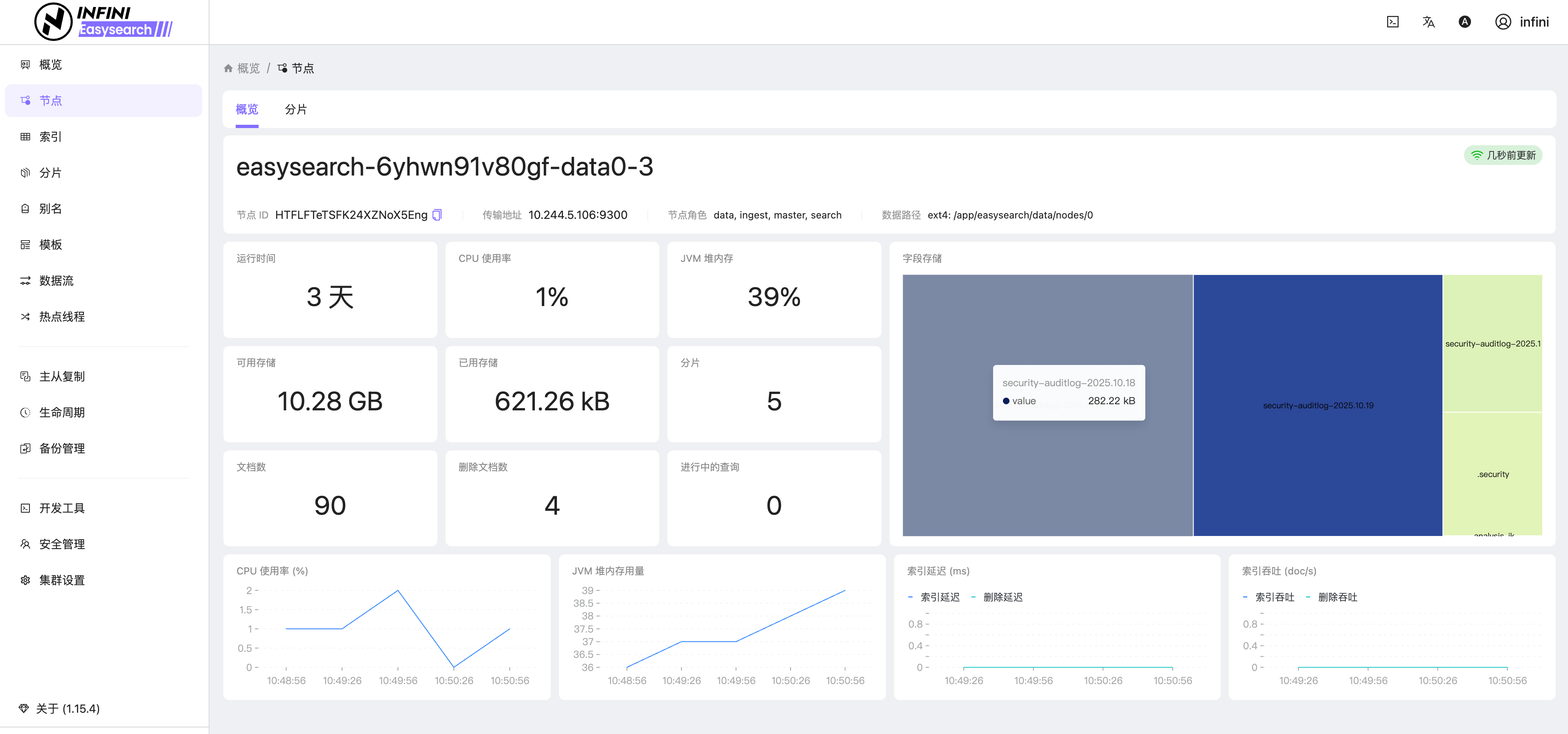
图 5:索引列表
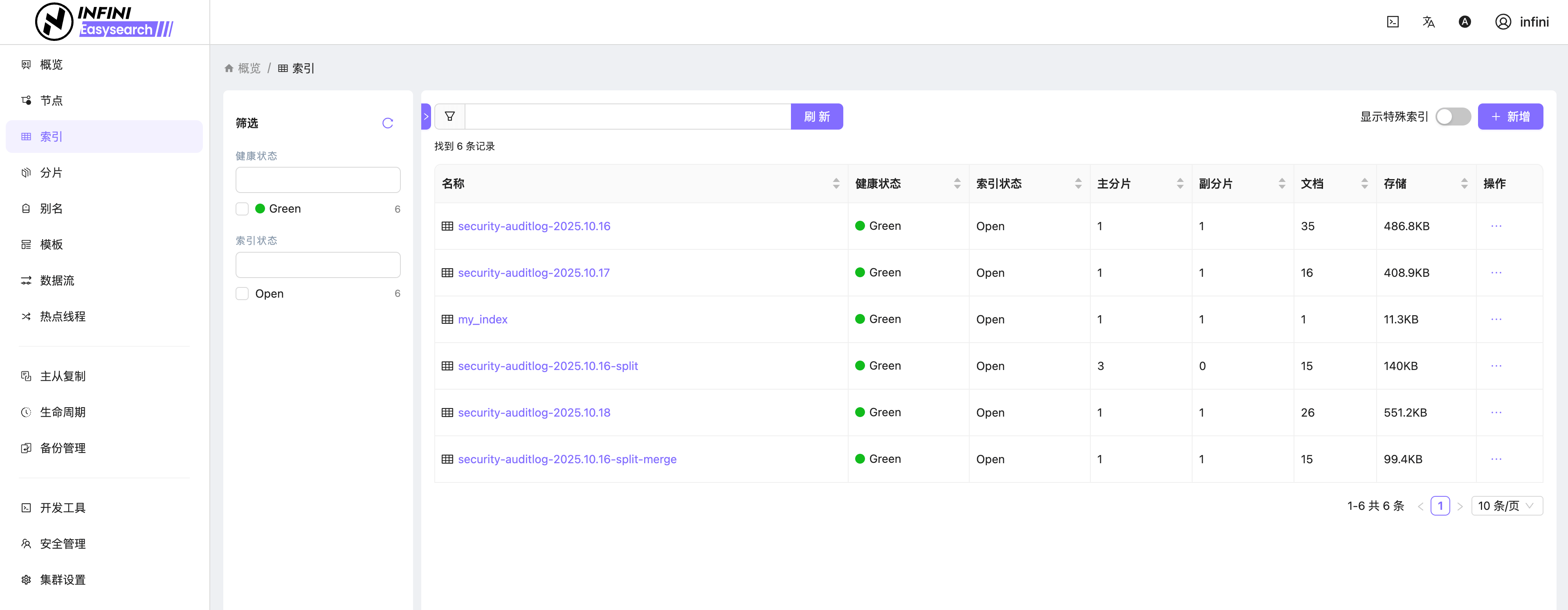
图 6:索引概览
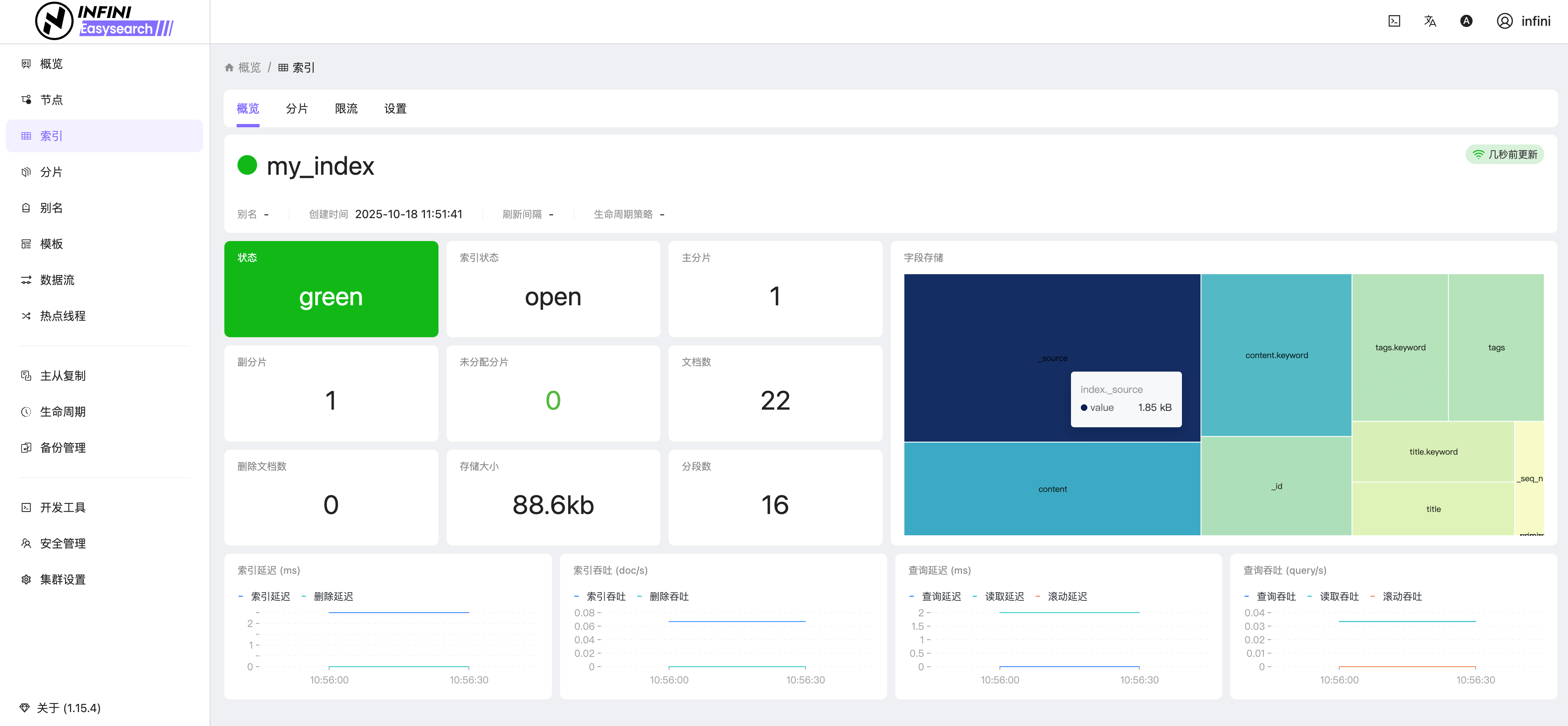
图 7:分片管理
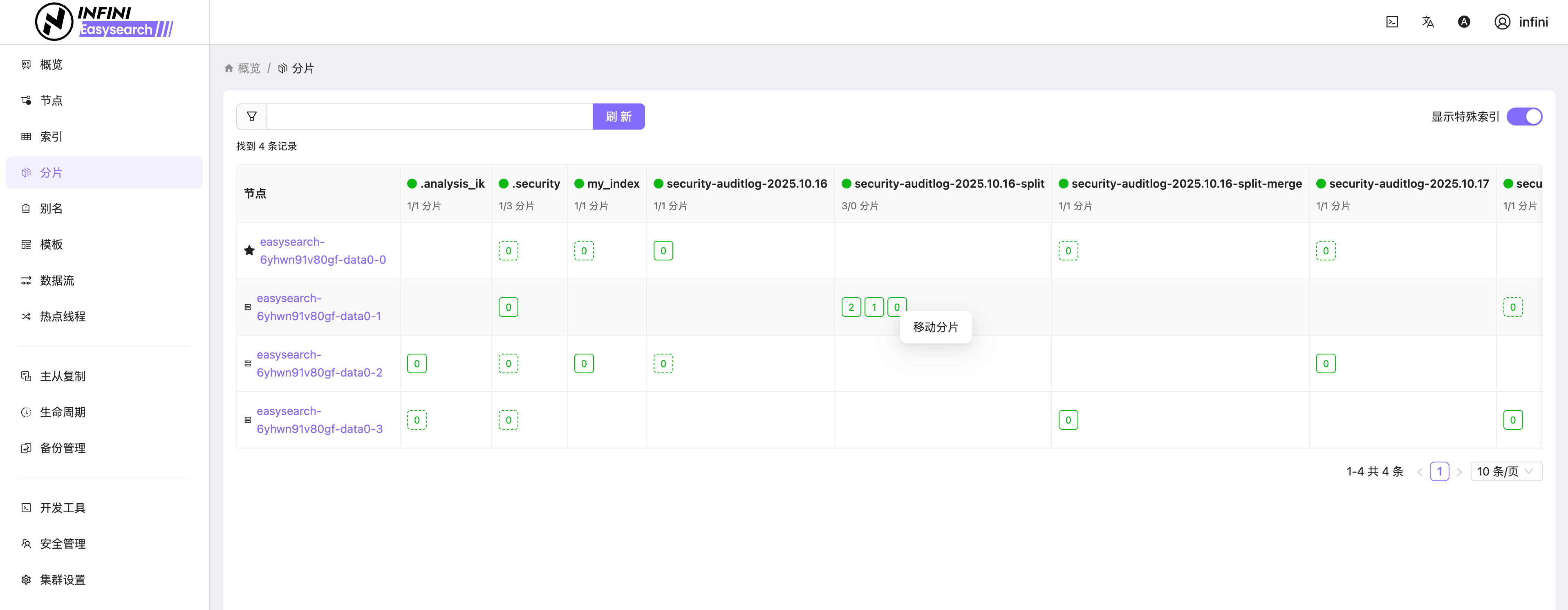
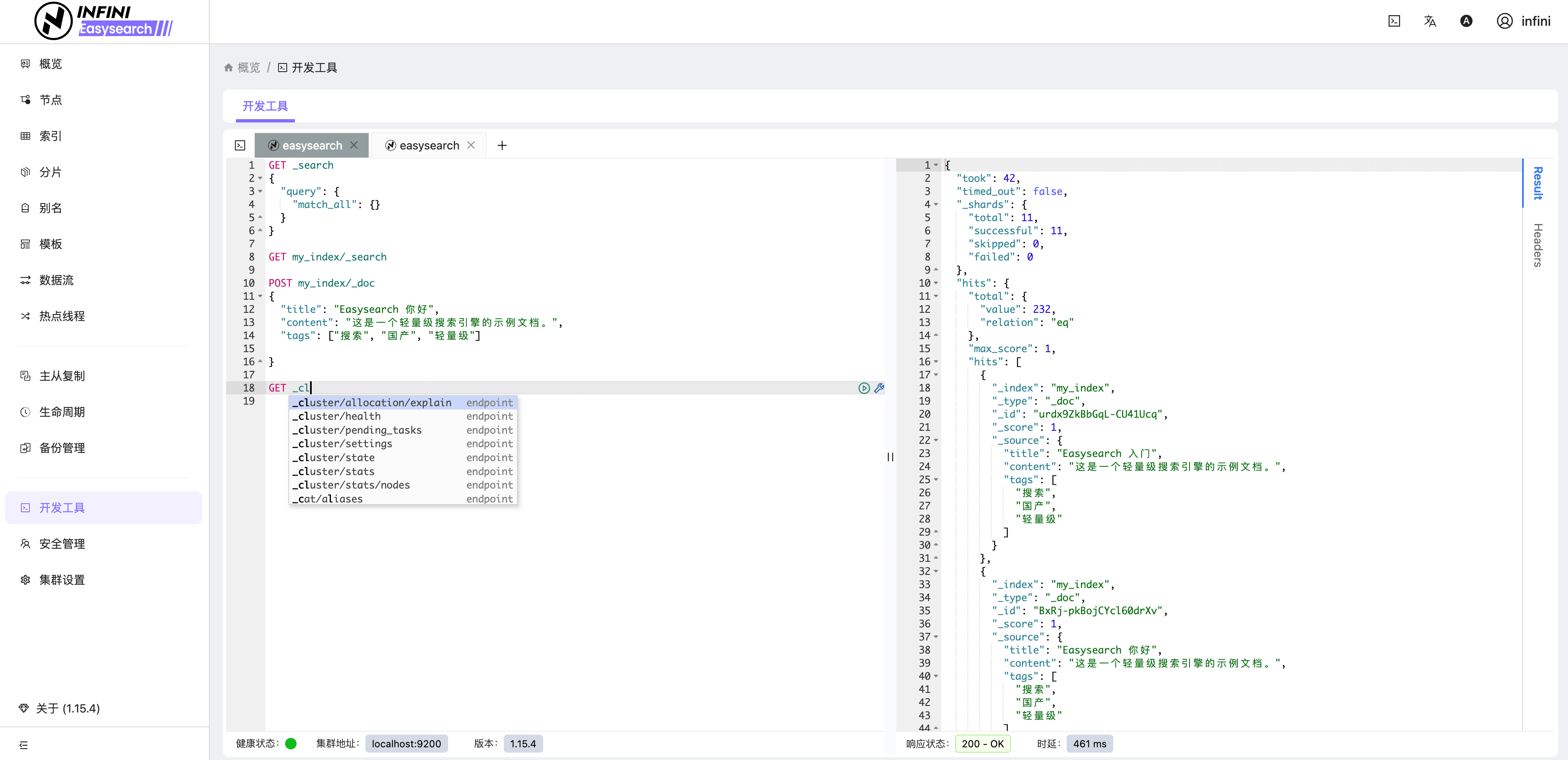
图 8:开发工具
以上仅列出了一些基本功能,其他如安全管理、主从复制、备份管理、生命周期管理等更多高级功能由于篇幅限制不一一展示,有兴趣的朋友可自行部署探索。
结语
Easysearch 的诞生,不仅填补了国产搜索引擎在分布式与轻量化领域的空白,也让更多企业在面对开源协议变动与外部技术依赖时,拥有了更加安全、灵活、可控的选择。
它既是国产替代方案的有力代表,更是新一代搜索技术生态的积极探索者,为企业级实时搜索与分析带来新的可能。
🚀 下期预告
下一篇我们将介绍 一款 AI 驱动的现代搜索引擎 - Meilisearch,基于 Rust 构建的开源搜索引擎,性能高、部署简单。号称比 Elasticsearch 快 10 倍,真的这么牛吗?
💬 三连互动
- 你是否在使用或考虑国产搜索替代方案?
- 在实际项目中,你最看重搜索引擎的哪些特性?(性能、兼容性、运维、成本)
- 对 Easysearch 有什么功能上的期待?
对搜索技术感兴趣的朋友,也欢迎加我微信(ID:lsy965145175)备注“搜索百科”,拉你进 搜索技术交流群,一起探讨与学习!
✨ 推荐阅读
- 搜索百科(4):OpenSearch — 开源搜索的新选择
- 搜索百科(3):Elasticsearch — 搜索界的"流量明星"
- 搜索百科(2):Apache Solr — 企业级搜索的开源先锋
- 搜索百科(1):Lucene — 打开现代搜索世界的第一扇门
🔗 参考资源
原文:https://infinilabs.cn/blog/2025/search-wiki-5-easysearch/
大家好,我是 INFINI Labs 的石阳。
欢迎关注 《搜索百科》 专栏!每天 5 分钟,带你速览一款搜索相关的技术或产品,同时还会带你探索它们背后的技术原理、发展故事及上手体验等。
在上一篇我们介绍了 OpenSearch —— 那个因协议争议而诞生的开源搜索分支。今天,我们把目光转向国内,聊聊极限科技研发的一款轻量级搜索引擎:Easysearch。
引言
在搜索技术的世界里,从 Lucene 的出现到 Solr、Elasticsearch 的崛起,搜索引擎技术已经发展了二十余年。然而,随着开源协议的变更与国际形势的变化,国产自主搜索引擎的需求愈发迫切。在这样的背景下,Easysearch 作为一款自主可控、轻量高效、兼容 Elasticsearch 的分布式搜索引擎应运而生,为国内企业带来了全新的选择。
Easysearch 概述
Easysearch 是一款分布式搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析、AI 集成等。Easysearch 衍生自开源协议 Apache 2.0 的 Elasticsearch 7.10 版本,并不断往前迭代更新,紧跟 Lucene 最新版本的更新。Easysearch 可以替代 Elasticsearch,同时添加和完善多项企业级功能。
- 首次发布:2023 年 4 月
- 最新版本:1.15.4(截止 2025 年 10 月)
- 主导企业:极限科技 (INFINI Labs)
- 官方网址:https://easysearch.cn
诞生背景:为什么要有 Easysearch?
Easysearch 由极限科技(INFINI Labs)团队推出。项目的起点源于团队长期在搜索引擎和大数据领域的深厚实践积累,团队深刻认识到国内企业在使用 Elasticsearch 时普遍面临以下痛点:
- 开源协议变化带来的商业风险 —— Elastic 于 2021 年将许可更改为 SSPL,导致社区分裂,增加了企业在合规和商用上的不确定性;
- 高并发与高可靠性场景下对稳定可控方案的需求 —— 企业级应用亟需一个性能可靠、可深度优化的搜索基础设施;
- 技术栈自主可控的迫切需求 —— 随着国产化进程加快,国内生态中缺乏轻量化、易部署、且完全可控的搜索引擎产品;
- 本地化服务与快速响应能力的缺口 —— 国内企业更需要本地团队提供高效的技术支持与服务,对本土化、个性化功能需求能得到及时响应与反馈。
基于这些考虑,Easysearch 在设计之初就明确了目标:构建一款兼容 Elasticsearch API、简洁易用、性能出众且完全自主可控的国产搜索引擎。
核心特性
- 轻量级:安装包大小不到 60 MB,安装部署简洁,资源占用低,开箱即用;
- 跨平台:支持主流操作系统和 CPU 架构,支持国产信创运行环境;
- 高性能:针对不同场景进行的极致优化,可用更少硬件成本获得更高服务性能,降本增效。
- 稳定可靠:修复大量内核问题,解决内存泄露,集群卡顿、查询缓慢等问题,久经严苛业务环境考验。
- 安全增强:默认就提供完整的企业级安全功能,支持 LDAP/AD 集成,支持索引、文档、字段粒度细权管控。
- 兼容性强:兼容 Elasticsearch 7.x 的 REST API 和数据格式,迁移成本低;
- 可视化运维:无需 Kibana 即可通过内置 Web UI 插件界面管理索引、节点与监控指标等。
对比优势
| 对比维度 | Easysearch | Elasticsearch | OpenSearch |
|---|---|---|---|
| 用户协议 | 社区免费+商业授权 | SSPL/AGPL v3 | Apache 2.0 |
| API 兼容性 | 高度兼容 ES | 原生 | 高度兼容 ES |
| 最小安装体积 | 57MB | 482MB | 682MB |
| 部署复杂度 | 简单 | 中等 | 相对复杂 |
| 信创环境支持 | 全面兼容 | 无 | 无 |
| 可视化管理 | 开箱即用管理后台 | 需独立部署 Kibana | 需独立部署 OpenSearch Dashboards |
| 本地化与中文支持 | 强 | 弱 | 弱 |
| AI 插件支持 | 较弱 | 强 | 较强 |
| 社区与生态 | 快速成长中 | 成熟广泛 | 活跃增长 |
快速开始:5 分钟体验 Easysearch
1. 使用 Docker 启动
# 直接运行镜像使用随机密码(数据及配置未持久化)
docker run --name easysearch \
--ulimit memlock=-1:-1 \
-p 9200:9200 \
infinilabs/easysearch:1.15.42. 验证集群状态
curl -ku "username:password" -X GET "https://localhost:9200/"返回结果示例:
{
"name": "easysearch-node",
"cluster_name": "easysearch-6yhwn91v80gf",
"cluster_uuid": "Gfu_fuF1QViJfeUWVbiFCA",
"version": {
"distribution": "easysearch",
"number": "1.15.4",
"distributor": "INFINI Labs",
"build_hash": "9110128946b0af3de639966cfa74b5498346949d",
"build_date": "2025-10-14T03:30:41.948590Z",
"build_snapshot": false,
"lucene_version": "8.11.4",
"minimum_wire_lucene_version": "7.7.0",
"minimum_lucene_index_compatibility_version": "7.7.0"
},
"tagline": "You Know, For Easy Search!"
}3. 索引与搜索示例
# 写入文档
curl -ku "username:password" -X POST "https://localhost:9200/my_index/_doc" -H 'Content-Type: application/json' -d'
{
"title": "Easysearch 入门",
"content": "这是一个轻量级搜索引擎的示例文档。",
"tags": ["搜索", "国产", "轻量级"]
}'
# 搜索文档
curl -ku "username:password" -X GET "https://localhost:9200/my_index/_search" -H 'Content-Type: application/json' -d'
{
"query": {
"match": {
"content": "搜索引擎"
}
}
}'4. 使用 Easysearch UI
Easysearch 提供了轻量级界面化管理功能,不再依赖第三方组件即可对集群进行管理,真正做到开箱即用。如果你安装了 Easysearch UI 插件或者下载捆绑包,可通过 https://localhost:9200/\_ui/ 访问,进行节点、索引、分片、查询调试和监控查看等管理。
图 1:系统登录
图 2:集群概览
图 3:节点列表
图 4:节点概览
图 5:索引列表
图 6:索引概览
图 7:分片管理
图 8:开发工具
以上仅列出了一些基本功能,其他如安全管理、主从复制、备份管理、生命周期管理等更多高级功能由于篇幅限制不一一展示,有兴趣的朋友可自行部署探索。
结语
Easysearch 的诞生,不仅填补了国产搜索引擎在分布式与轻量化领域的空白,也让更多企业在面对开源协议变动与外部技术依赖时,拥有了更加安全、灵活、可控的选择。
它既是国产替代方案的有力代表,更是新一代搜索技术生态的积极探索者,为企业级实时搜索与分析带来新的可能。
🚀 下期预告
下一篇我们将介绍 一款 AI 驱动的现代搜索引擎 - Meilisearch,基于 Rust 构建的开源搜索引擎,性能高、部署简单。号称比 Elasticsearch 快 10 倍,真的这么牛吗?
💬 三连互动
- 你是否在使用或考虑国产搜索替代方案?
- 在实际项目中,你最看重搜索引擎的哪些特性?(性能、兼容性、运维、成本)
- 对 Easysearch 有什么功能上的期待?
对搜索技术感兴趣的朋友,也欢迎加我微信(ID:lsy965145175)备注“搜索百科”,拉你进 搜索技术交流群,一起探讨与学习!
✨ 推荐阅读
- 搜索百科(4):OpenSearch — 开源搜索的新选择
- 搜索百科(3):Elasticsearch — 搜索界的"流量明星"
- 搜索百科(2):Apache Solr — 企业级搜索的开源先锋
- 搜索百科(1):Lucene — 打开现代搜索世界的第一扇门
🔗 参考资源
收起阅读 »原文:https://infinilabs.cn/blog/2025/search-wiki-5-easysearch/
【搜索客社区日报】第2130期 (2025-10-20)
https://elasticstack.blog.csdn ... 73147
2、如何使用 Synonyms UI 上传和管理 Elasticsearch 同义词 - 9.1
https://elasticstack.blog.csdn ... 10683
3、Simple MCP Client - 连接到 Elasticsearch MCP 并进行自然语言搜索
https://elasticstack.blog.csdn ... 10379
4、使用 n8n 和 MCP 创建 AI 代理
https://elasticstack.blog.csdn ... 30621
5、通过 A2A 协议将 Elastic Agent 连接到 Gemini Enterprise
https://elasticstack.blog.csdn ... 84944
编辑:Muse
更多资讯:http://news.searchkit.cn
https://elasticstack.blog.csdn ... 73147
2、如何使用 Synonyms UI 上传和管理 Elasticsearch 同义词 - 9.1
https://elasticstack.blog.csdn ... 10683
3、Simple MCP Client - 连接到 Elasticsearch MCP 并进行自然语言搜索
https://elasticstack.blog.csdn ... 10379
4、使用 n8n 和 MCP 创建 AI 代理
https://elasticstack.blog.csdn ... 30621
5、通过 A2A 协议将 Elastic Agent 连接到 Gemini Enterprise
https://elasticstack.blog.csdn ... 84944
编辑:Muse
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2129期 (2025-10-17)
https://www.51cto.com/article/827405.html
2、Elasticsearch 备份:方案篇
https://infinilabs.cn/blog/2025/es-backup-plans/
3、Elasticsearch 备份:snapshot 镜像使用篇
https://infinilabs.cn/blog/202 ... shot/
4、Easysearch 的写入流程(一):refresh
https://mp.weixin.qq.com/s/8SGHZK0_SV9m17Skbd1ymg
5、快手提出端到端生成式搜索框架 OneSearch,让搜索“一步到位”!
https://blog.csdn.net/kuaishou ... 60200
编辑:Fred
更多资讯:http://news.searchkit.cn
https://www.51cto.com/article/827405.html
2、Elasticsearch 备份:方案篇
https://infinilabs.cn/blog/2025/es-backup-plans/
3、Elasticsearch 备份:snapshot 镜像使用篇
https://infinilabs.cn/blog/202 ... shot/
4、Easysearch 的写入流程(一):refresh
https://mp.weixin.qq.com/s/8SGHZK0_SV9m17Skbd1ymg
5、快手提出端到端生成式搜索框架 OneSearch,让搜索“一步到位”!
https://blog.csdn.net/kuaishou ... 60200
编辑:Fred
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2128期 (2025-10-16)
https://mp.weixin.qq.com/s/MfGEaxVvTpS2puzUcU0cQA
2.推理速度 10 倍提升,蚂蚁集团开源业内首个高性能扩散语言模型推理框架 dInfer
https://mp.weixin.qq.com/s/B9ZE0uJb3CmeNLRbj41dgA
3.智能体设计模式:Agentic Design Patterns 中文版电子书分享
https://mp.weixin.qq.com/s/ayWxq_2IYNwMPk3NeXIcyA
编辑:Se7en
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/MfGEaxVvTpS2puzUcU0cQA
2.推理速度 10 倍提升,蚂蚁集团开源业内首个高性能扩散语言模型推理框架 dInfer
https://mp.weixin.qq.com/s/B9ZE0uJb3CmeNLRbj41dgA
3.智能体设计模式:Agentic Design Patterns 中文版电子书分享
https://mp.weixin.qq.com/s/ayWxq_2IYNwMPk3NeXIcyA
编辑:Se7en
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2127期 (2025-10-15)
https://blog.csdn.net/UbuntuTo ... 76443
2.Elasticsearch:使用推理端点及语义搜索演示
https://blog.csdn.net/UbuntuTo ... 97172
3.GPU 嗡嗡作响! Elastic 推理服务( EIS ):为 Elasticsearch 提供 GPU 加速推理
https://blog.csdn.net/UbuntuTo ... 87255
4.HNSW图:如何提升Elasticsearch性能原创
https://cloud.tencent.com/deve ... 74993
5.Easysearch 字段'隐身'之谜:source_reuse 与 ignore_above 的陷阱解析
https://infinilabs.cn/blog/202 ... ield/
编辑:kin122
更多资讯:http://news.searchkit.cn
https://blog.csdn.net/UbuntuTo ... 76443
2.Elasticsearch:使用推理端点及语义搜索演示
https://blog.csdn.net/UbuntuTo ... 97172
3.GPU 嗡嗡作响! Elastic 推理服务( EIS ):为 Elasticsearch 提供 GPU 加速推理
https://blog.csdn.net/UbuntuTo ... 87255
4.HNSW图:如何提升Elasticsearch性能原创
https://cloud.tencent.com/deve ... 74993
5.Easysearch 字段'隐身'之谜:source_reuse 与 ignore_above 的陷阱解析
https://infinilabs.cn/blog/202 ... ield/
编辑:kin122
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2126期 (2025-10-14)
https://medium.com/%40rserit/b ... 504b1
2. 给StarRocks配上ES,芜湖起飞(需要梯子)
https://medium.com/fresha-data ... 3a2e7
3. OpenSearch/ClickHouse 我做出了一个艰难的决定(需要梯子)
https://medium.com/%40prnvindc ... 658de
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
https://medium.com/%40rserit/b ... 504b1
2. 给StarRocks配上ES,芜湖起飞(需要梯子)
https://medium.com/fresha-data ... 3a2e7
3. OpenSearch/ClickHouse 我做出了一个艰难的决定(需要梯子)
https://medium.com/%40prnvindc ... 658de
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
收起阅读 »
【搜索客社区日报】第2125期 (2025-10-13)
https://elasticstack.blog.csdn ... 56582
2. Elasticsearch MCP 服务器:与你的 Index 聊天
https://elasticstack.blog.csdn ... 08020
3. 介绍一种新的向量存储格式:DiskBBQ
https://elasticstack.blog.csdn ... 38794
4. AutoOps:简化自管理 Elasticsearch 的旅程
https://elasticstack.blog.csdn ... 39878
5. AutoOps:简单的 Elasticsearch 集群监控与管理现已支持本地部署
https://elasticstack.blog.csdn ... 40560
编辑:Muse
更多资讯:http://news.searchkit.cn
https://elasticstack.blog.csdn ... 56582
2. Elasticsearch MCP 服务器:与你的 Index 聊天
https://elasticstack.blog.csdn ... 08020
3. 介绍一种新的向量存储格式:DiskBBQ
https://elasticstack.blog.csdn ... 38794
4. AutoOps:简化自管理 Elasticsearch 的旅程
https://elasticstack.blog.csdn ... 39878
5. AutoOps:简单的 Elasticsearch 集群监控与管理现已支持本地部署
https://elasticstack.blog.csdn ... 40560
编辑:Muse
更多资讯:http://news.searchkit.cn 收起阅读 »
Easysearch 冷热架构实战
在之前的文章中,我们介绍了如何使用索引生命周期策略来管理索引。如果要求索引根据其生命周期阶段自动在不同的节点之间迁移,还需要用到冷热架构。我们来看看具体如何实现。
冷热架构
冷热架构其实就是在 Easyearch 集群中定义不同属性的节点,这些节点共同组成冷热架构。比如给所有热节点一个 hot 属性,给所有冷节点一个 cold 属性。在 Easyearch 中分配节点属性是通过配置文件(easysearch.yml)来实现的,比如我要定义一个热节点和一个冷节点,我可以在对应节点的配置文件中添加如下行:
# 热节点添加下面的行
node.attr.temp: hot
# 冷节点添加下面的行
node.attr.temp: cold有了这些属性,我们就可以指定索引分片在分配时,是落在 hot 节点还是 cold 节点。
查看节点属性
测试环境是个 2 节点的 Easysearch 集群。

比如我创建新索引 test-index,希望它被分配到 hot 节点上。
PUT test-index
{
"settings": {
"number_of_replicas": 0,
"index.routing.allocation.require.temp": "hot"
}
}
可以看到 test-index 索引的分片分配到 hot 节点 node-1 上。我们修改索引分配节点的属性,让其移动到 cold 节点 node-2 上。
PUT test-index/_settings
{
"settings": {
"index.routing.allocation.require.temp": "cold"
}
}
生命周期与冷热架构
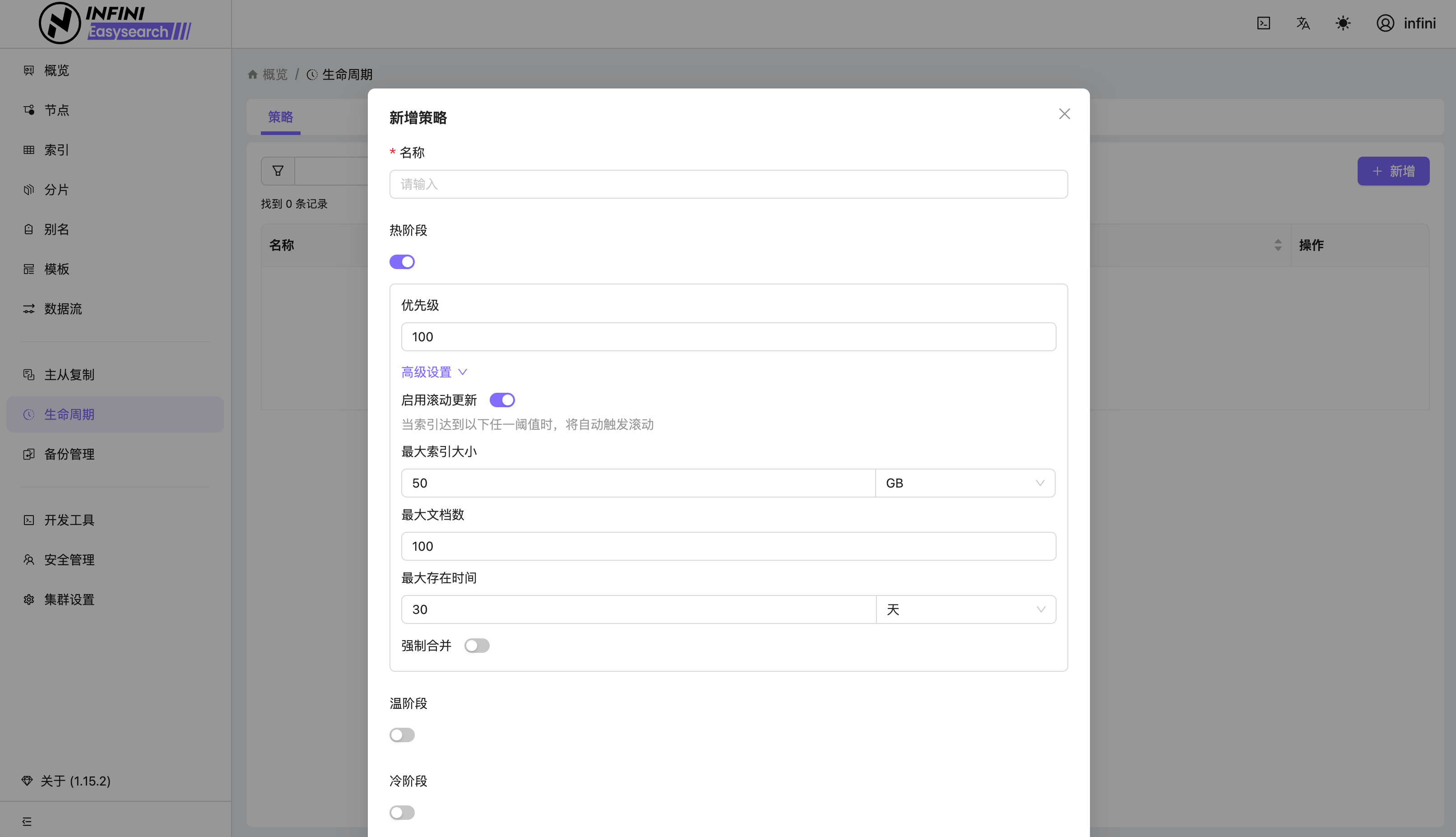
在上面的例子中,我们通过索引分配节点属性对索引“坐落”的节点进行了控制。在索引生命周期策略中也支持对该属性进行修改,实现索引根据生命周期阶段自动在不同的节点之间移动的目的。
比如我们定义一个简单的索引策略:
- 索引创建后进入 hot 阶段,此阶段的索引被分配到 hot 节点
- 创建索引 3 分钟后,索引进入 cold 阶段,此阶段索引分片移动到 cold 节点
创建策略
PUT _ilm/policy/ilm_test
{
"policy": {
"phases": {
"hot": {
"min_age": "0m",
},
"cold": {
"min_age": "3m",
"actions": {
"allocate" : {
"require" : {
"temp": "cold"
}
}
}
}
}
}
}生命周期策略后台是定期触发的任务,为了更快的观测到效果,可以修改任务触发周期为每分钟 1 次。
PUT _cluster/settings
{
"transient": {
"index_lifecycle_management.job_interval":"1"
}
}创建索引模板
创建完索引生命周期策略,还需要索引模板把索引和生命周期策略关联起来。我们创建一个模板把所有 ilm_test 开头的索引与 ilm_test 生命周期策略关联,为了便于观察,指定索引没有副本分片。
PUT _template/ilm_test
{
"order" : 100000,
"index_patterns" : [
"ilm_test*"
],
"settings" : {
"index" : {
"lifecycle" : {
"name" : "ilm_test"
},
"number_of_replicas" : "0",
"routing.allocation.require.temp": "hot"
}
}
}创建索引
创建一个 ilm_test 开头的索引,应用上一步创建的索引模板。
POST ilm_test_1/_doc
{
"test":"test"
}查看索引分片分配情况。

目前索引存储在 node-1 节点,按计划 3 分钟后将会移动到 node-2 上。


至此我们已通过索引生命周期策略实现了索引分片的移动,其实支持的操作还有很多,比如: rollover、close、snapshot 等,详情请参阅官方文档。
有任何问题,欢迎加我微信沟通。

关于 Easysearch
INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。
在之前的文章中,我们介绍了如何使用索引生命周期策略来管理索引。如果要求索引根据其生命周期阶段自动在不同的节点之间迁移,还需要用到冷热架构。我们来看看具体如何实现。
冷热架构
冷热架构其实就是在 Easyearch 集群中定义不同属性的节点,这些节点共同组成冷热架构。比如给所有热节点一个 hot 属性,给所有冷节点一个 cold 属性。在 Easyearch 中分配节点属性是通过配置文件(easysearch.yml)来实现的,比如我要定义一个热节点和一个冷节点,我可以在对应节点的配置文件中添加如下行:
# 热节点添加下面的行
node.attr.temp: hot
# 冷节点添加下面的行
node.attr.temp: cold有了这些属性,我们就可以指定索引分片在分配时,是落在 hot 节点还是 cold 节点。
查看节点属性
测试环境是个 2 节点的 Easysearch 集群。
比如我创建新索引 test-index,希望它被分配到 hot 节点上。
PUT test-index
{
"settings": {
"number_of_replicas": 0,
"index.routing.allocation.require.temp": "hot"
}
}
可以看到 test-index 索引的分片分配到 hot 节点 node-1 上。我们修改索引分配节点的属性,让其移动到 cold 节点 node-2 上。
PUT test-index/_settings
{
"settings": {
"index.routing.allocation.require.temp": "cold"
}
}
生命周期与冷热架构
在上面的例子中,我们通过索引分配节点属性对索引“坐落”的节点进行了控制。在索引生命周期策略中也支持对该属性进行修改,实现索引根据生命周期阶段自动在不同的节点之间移动的目的。
比如我们定义一个简单的索引策略:
- 索引创建后进入 hot 阶段,此阶段的索引被分配到 hot 节点
- 创建索引 3 分钟后,索引进入 cold 阶段,此阶段索引分片移动到 cold 节点
创建策略
PUT _ilm/policy/ilm_test
{
"policy": {
"phases": {
"hot": {
"min_age": "0m",
},
"cold": {
"min_age": "3m",
"actions": {
"allocate" : {
"require" : {
"temp": "cold"
}
}
}
}
}
}
}生命周期策略后台是定期触发的任务,为了更快的观测到效果,可以修改任务触发周期为每分钟 1 次。
PUT _cluster/settings
{
"transient": {
"index_lifecycle_management.job_interval":"1"
}
}创建索引模板
创建完索引生命周期策略,还需要索引模板把索引和生命周期策略关联起来。我们创建一个模板把所有 ilm_test 开头的索引与 ilm_test 生命周期策略关联,为了便于观察,指定索引没有副本分片。
PUT _template/ilm_test
{
"order" : 100000,
"index_patterns" : [
"ilm_test*"
],
"settings" : {
"index" : {
"lifecycle" : {
"name" : "ilm_test"
},
"number_of_replicas" : "0",
"routing.allocation.require.temp": "hot"
}
}
}创建索引
创建一个 ilm_test 开头的索引,应用上一步创建的索引模板。
POST ilm_test_1/_doc
{
"test":"test"
}查看索引分片分配情况。
目前索引存储在 node-1 节点,按计划 3 分钟后将会移动到 node-2 上。
至此我们已通过索引生命周期策略实现了索引分片的移动,其实支持的操作还有很多,比如: rollover、close、snapshot 等,详情请参阅官方文档。
有任何问题,欢迎加我微信沟通。
关于 Easysearch
INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。
官网文档:https://docs.infinilabs.com/easysearch
收起阅读 »Easysearch 字段'隐身'之谜:source_reuse 与 ignore_above 的陷阱解析
背景问题
前阵子,社区有小伙伴在使用 Easysearch 的数据压缩功能时发现,在开启 source_reuse 和 ZSTD 后,一个字段的内容看不到了。
索引的设置如下:
{
......
"settings": {
"index": {
"codec": "ZSTD",
"source_reuse": "true"
}
},
"mappings": {
"dynamic_templates": [
{
"message_field": {
"path_match": "message",
"mapping": {
"norms": false,
"type": "text"
},
"match_mapping_type": "string"
}
},
{
"string_fields": {
"mapping": {
"norms": false,
"type": "text",
"fields": {
"keyword": {
"ignore_above": 256,
"type": "keyword"
}
}
},
"match_mapping_type": "string",
"match": "*"
}
}
]
......
}然后产生的一个多字段内容能被搜索到,但是不可见。
类似于下面的这个情况:
原因分析
我们先来看看整个字段展示经历的环节:
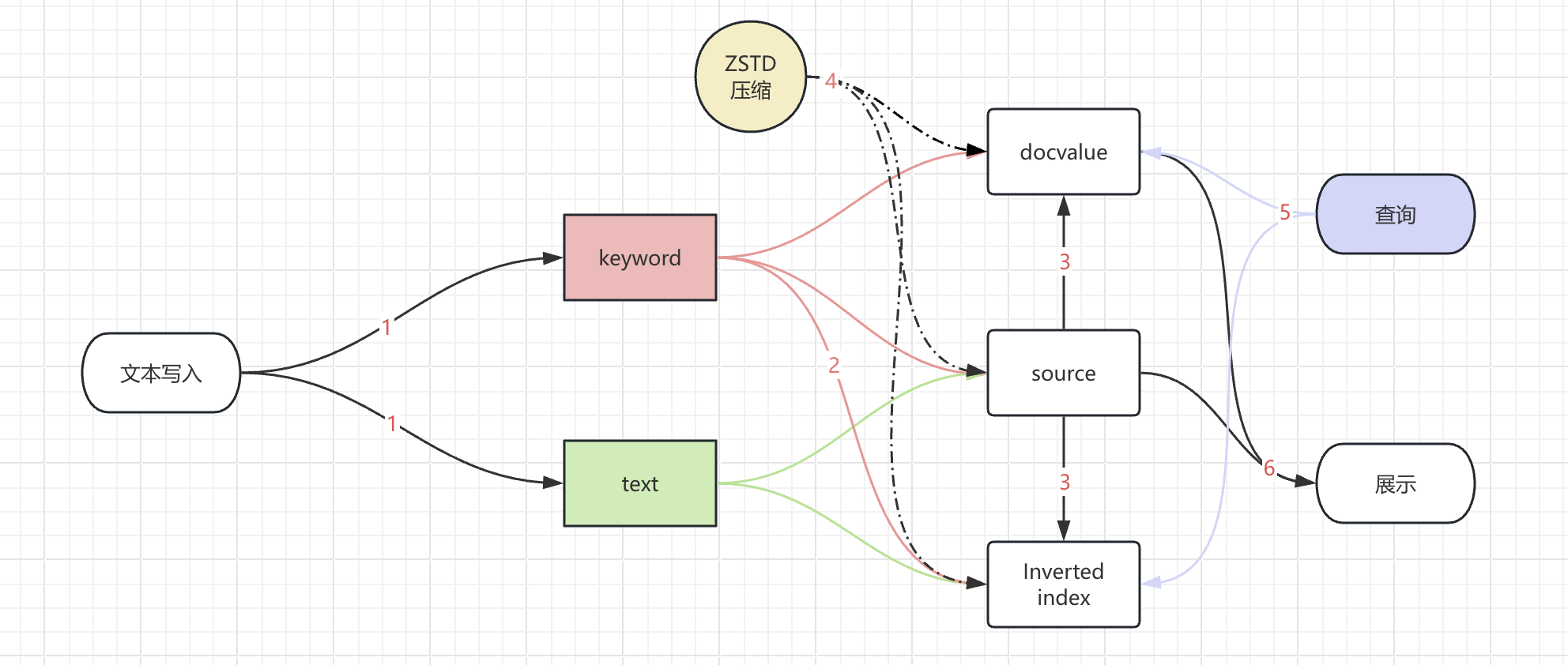
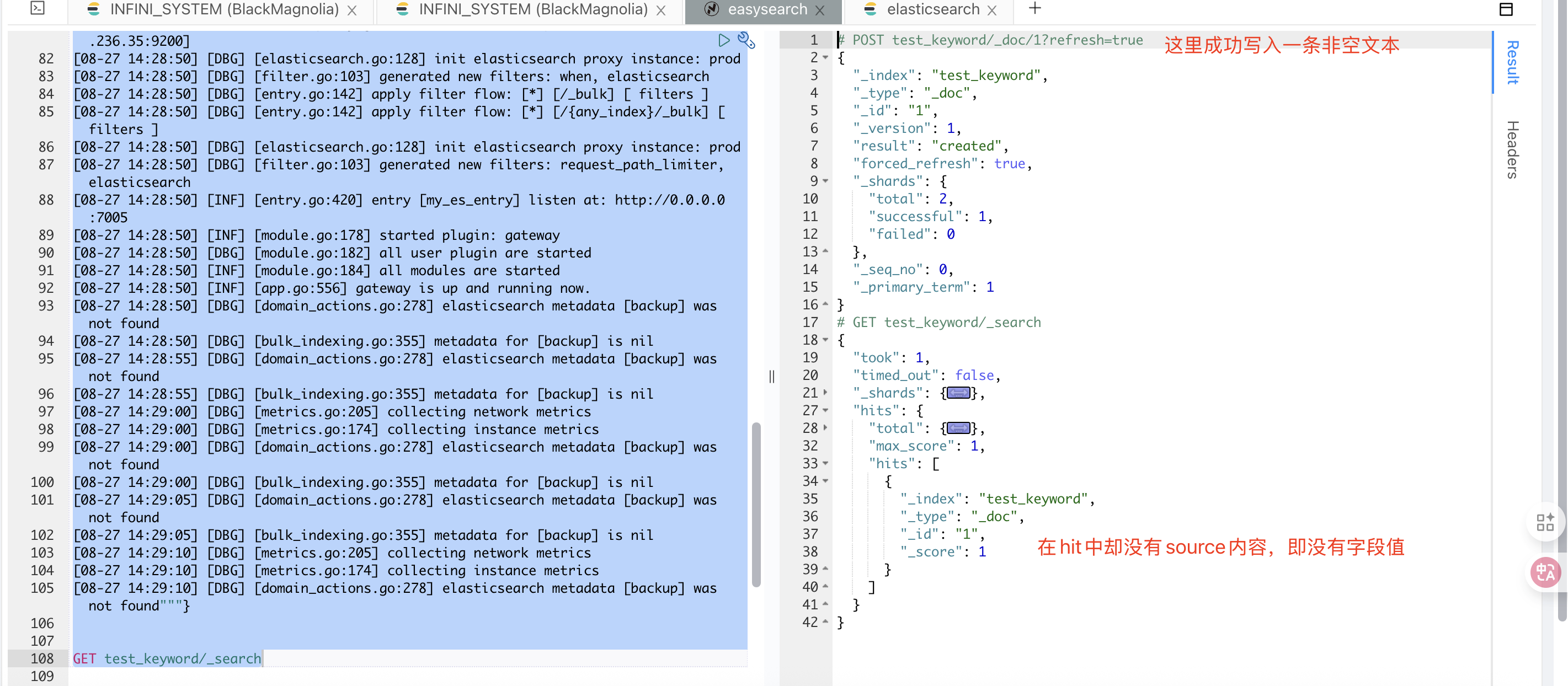
- 字段写入索引的时候,不仅写了 text 字段也写了 keyword 字段。
- keyword 字段产生倒排索引的时候,会忽略掉长度超过 ignore_above 的内容。
- 因为开启了 source_reuse,_source 字段中与 doc_values 或倒排索引重复的部分会被去除。
- 产生的数据文件进行了 ZSTD 压缩,进一步提高了数据的压缩效率。
- 索引进行倒排或者 docvalue 的查询,检索到这个文档进行展示。
- 展示的时候通过文档 id 获取
_source或者docvalues_fields的内容来展示文本,但是文本内容是空的。
其中步骤 4 中的 ZSTD 压缩,是作用于数据文件的,并不对数据内容进行修改。因此,我们来专注于其他环节。
问题复现
首先,这个字段索引的配置也是一个 es 常见的设置,并不会带来内容显示缺失的问题。
"mapping": {
"type": "text",
"fields": {
"keyword": {
"ignore_above": 256,
"type": "keyword"
}
}
},那么,source_reuse 就成了我们可以重点排查的环节。
source 发生了什么
source_reuse 的作用描述如下:
source_reuse: 启用 source_reuse 配置项能够去除 _source 字段中与 doc_values 或倒排索引重复的部分,从而有效减小索引总体大小,这个功能对日志类索引效果尤其明显。
source_reuse 支持对以下数据类型进行压缩:keyword,integer,long,short,boolean,float,half_float,double,geo_point,ip, 如果是 text 类型,需要默认启用 keyword 类型的 multi-field 映射。 以上类型必须启用 doc_values 映射(默认启用)才能压缩。这是一个对 _source 字段进行产品化的功能实现。为了减少索引的存储体量,简单粗暴的操作是直接将_source字段进行关闭,利用其他数据格式去存储,在查询的时候对应的利用 docvalue 或者 indexed 去展示文本内容。
那么 _source关闭后,会不会也有这样的问题呢?
测试的步骤如下:
# 1. 创建不带source的双字段索引
PUT test_source
{
"mappings": {
"_source": {
"enabled": false
},
"properties": {
"msg": {
"type": "text",
"fields": {
"keyword": {
"ignore_above": 256,
"type": "keyword"
}
}
}
}
}
}
# 2. 写入测试数据
POST test_source/_doc/1
{"msg":"""[08-27 14:28:45] [DBG] [config.go:273] config contain variables, try to parse with environments
[08-27 14:28:45] [DBG] [config.go:214] load config files: []
[08-27 14:28:45] [INF] [pipeline.go:419] creating pipeline: pipeline_logging_merge
[08-27 14:28:45] [INF] [pipeline.go:419] creating pipeline: ingest_pipeline_logging
[08-27 14:28:45] [INF] [pipeline.go:419] creating pipeline: async_messages_merge
[08-27 14:28:45] [INF] [pipeline.go:419] creating pipeline: metrics_merge
[08-27 14:28:45] [INF] [pipeline.go:419] creating pipeline: request_logging_merge
[08-27 14:28:45] [INF] [pipeline.go:419] creating pipeline: ingest_merged_requests
[08-27 14:28:45] [INF] [pipeline.go:419] creating pipeline: async_ingest_bulk_requests
[08-27 14:28:45] [INF] [module.go:159] started module: pipeline
[08-27 14:28:45] [DBG] [module.go:163] all system module are started
[08-27 14:28:45] [DBG] [floating_ip.go:348] setup floating_ip, root privilege are required
[08-27 14:28:45] [DBG] [queue_config.go:121] init new queue config:e60457c6eae50a4eabbb62fc1001dccc,bulk_requests
[08-27 14:28:45] [DBG] [queue_config.go:121] init new queue config:e60457c6eae50a4eabbb62fc1001dccc,bulk_requests
[08-27 14:28:45] [DBG] [queue_config.go:121] init new queue config:e60457c6eae50a4eabbb62fc1001dccc,bulk_requests
[08-27 14:28:45] [DBG] [processor.go:139] generated new processors: indexing_merge
[08-27 14:28:45] [DBG] [pipeline.go:466] processing pipeline_v2: metrics_merge
[08-27 14:28:45] [DBG] [processor.go:139] generated new processors: when
[08-27 14:28:45] [DBG] [pipeline.go:466] processing pipeline_v2: ingest_merged_requests
[08-27 14:28:45] [DBG] [processor.go:139] generated new processors: indexing_merge
[08-27 14:28:45] [DBG] [pipeline.go:466] processing pipeline_v2: request_logging_merge
[08-27 14:28:45] [DBG] [processor.go:139] generated new processors: indexing_merge
[08-27 14:28:45] [DBG] [pipeline.go:466] processing pipeline_v2: async_messages_merge
[08-27 14:28:45] [DBG] [processor.go:139] generated new processors: bulk_indexing
[08-27 14:28:45] [DBG] [pipeline.go:466] processing pipeline_v2: ingest_pipeline_logging
[08-27 14:28:45] [DBG] [queue_config.go:121] init new queue config:1216c96eb876eee5b177d45436d0a362,gateway-pipeline-logs
[08-27 14:28:45] [DBG] [processor.go:139] generated new processors: bulk_indexing
[08-27 14:28:45] [DBG] [processor.go:139] generated new processors: indexing_merge
[08-27 14:28:45] [DBG] [pipeline.go:466] processing pipeline_v2: pipeline_logging_merge
[08-27 14:28:45] [DBG] [pipeline.go:466] processing pipeline_v2: async_ingest_bulk_requests
[08-27 14:28:45] [DBG] [badger.go:110] init badger database [queue_consumer_commit_offset]
[08-27 14:28:45] [INF] [floating_ip.go:290] floating_ip entering standby mode
[08-27 14:28:45] [DBG] [badger.go:110] init badger database [dis_locker]
[08-27 14:28:45] [DBG] [time.go:208] refresh low precision time in background
[08-27 14:28:45] [DBG] [domain_actions.go:278] elasticsearch metadata [backup] was not found
[08-27 14:28:45] [DBG] [bulk_indexing.go:355] metadata for [backup] is nil
[08-27 14:28:50] [INF] [module.go:178] started plugin: floating_ip
[08-27 14:28:50] [INF] [module.go:178] started plugin: force_merge
[08-27 14:28:50] [DBG] [network.go:78] network io stats will be included for map[]
[08-27 14:28:50] [INF] [module.go:178] started plugin: metrics
[08-27 14:28:50] [INF] [module.go:178] started plugin: statsd
[08-27 14:28:50] [DBG] [entry.go:100] reuse port 0.0.0.0:7005
[08-27 14:28:50] [DBG] [metrics.go:205] collecting network metrics
[08-27 14:28:50] [DBG] [metrics.go:174] collecting instance metrics
[08-27 14:28:50] [DBG] [elasticsearch.go:128] init elasticsearch proxy instance: prod
[08-27 14:28:50] [DBG] [filter.go:103] generated new filters: when, elasticsearch
[08-27 14:28:50] [DBG] [entry.go:142] apply filter flow: [*] [/_bulk] [ filters ]
[08-27 14:28:50] [DBG] [entry.go:142] apply filter flow: [*] [/{any_index}/_bulk] [ filters ]
[08-27 14:28:50] [DBG] [elasticsearch.go:128] init elasticsearch proxy instance: prod
[08-27 14:28:50] [DBG] [filter.go:103] generated new filters: request_path_limiter, elasticsearch
[08-27 14:28:50] [INF] [module.go:178] started plugin: gateway
[08-27 14:28:50] [DBG] [module.go:182] all user plugin are started
[08-27 14:28:50] [INF] [module.go:184] all modules are started
[08-27 14:28:50] [INF] [app.go:556] gateway is up and running now.
[08-27 14:28:50] [DBG] [domain_actions.go:278] elasticsearch metadata [backup] was not found
[08-27 14:28:50] [DBG] [bulk_indexing.go:355] metadata for [backup] is nil
[08-27 14:28:55] [DBG] [domain_actions.go:278] elasticsearch metadata [backup] was not found
[08-27 14:28:55] [DBG] [bulk_indexing.go:355] metadata for [backup] is nil
[08-27 14:29:00] [DBG] [metrics.go:205] collecting network metrics
[08-27 14:29:00] [DBG] [metrics.go:174] collecting instance metrics
[08-27 14:29:00] [DBG] [domain_actions.go:278] elasticsearch metadata [backup] was not found
[08-27 14:29:00] [DBG] [bulk_indexing.go:355] metadata for [backup] is nil
[08-27 14:29:05] [DBG] [domain_actions.go:278] elasticsearch metadata [backup] was not found
[08-27 14:29:05] [DBG] [bulk_indexing.go:355] metadata for [backup] is nil
[08-27 14:29:10] [DBG] [metrics.go:205] collecting network metrics
[08-27 14:29:10] [DBG] [metrics.go:174] collecting instance metrics
[08-27 14:29:10] [DBG] [domain_actions.go:278] elasticsearch metadata [backup] was not found"""}
# 3. 查询数据
GET test_source/_search此时,可以看到,存入的文档检索出来是空的
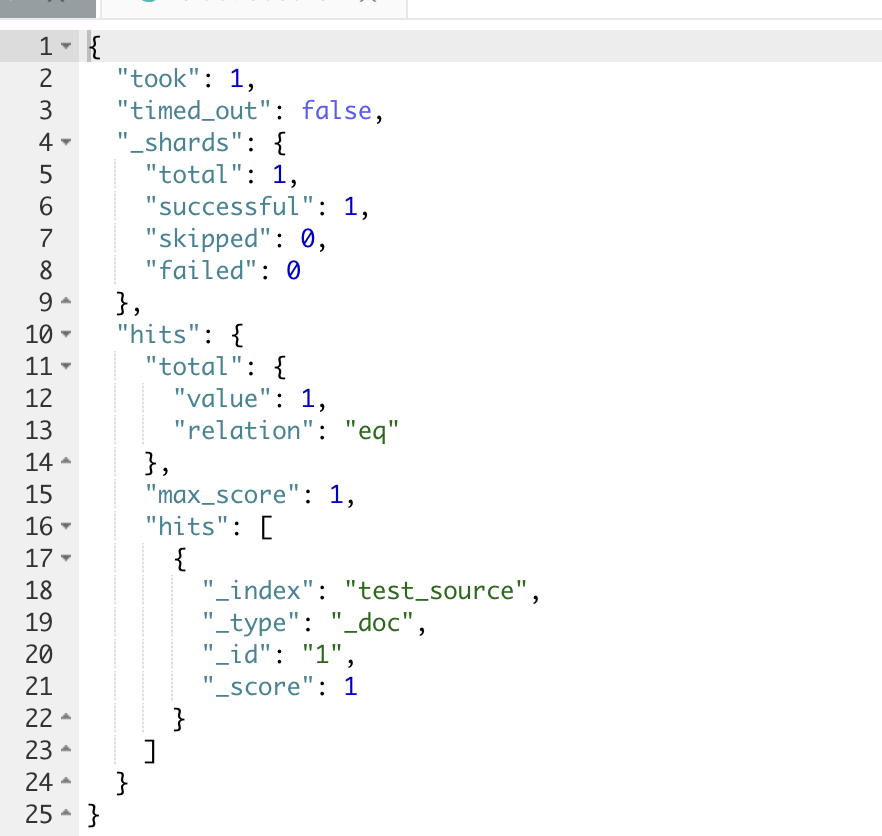
_source 字段是用于索引时传递的原始 JSON 文档主体。它本身未被索引成倒排(因此不作用于 query 阶段),只是在执行查询时用于 fetch 文档内容。
对于 text 类型,关闭_source,则字段内容自然不可被查看。
而对于 keyword 字段,查看_source也是不行的。可是 keyword 不仅存储source,还存储了 doc_values。因此,对于 keyword 字段类型,可以考虑关闭_source,使用 docvalue_fields 来查看字段内容。
测试如下:
# 1. 创建测试条件的索引
PUT test_source2
{
"mappings": {
"_source": {
"enabled": false
},
"properties": {
"msg": {
"type": "keyword"
}
}
}
}
# 2. 写入数据
POST test_source2/_doc
{"msg":"1111111"}
# 3. 使用 docvalue_fields 查询数据
POST test_source2/_search
{"docvalue_fields": ["msg"]}
# 返回结果
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "test_source2",
"_type": "_doc",
"_id": "yBvTj5kBvrlGDwP29avf",
"_score": 1,
"fields": {
"msg": [
"1111111"
]
}
}
]
}
}在如果是 text 类型,需要默认启用 keyword 类型的 multi-field 映射。 以上类型必须启用 doc_values 映射(默认启用)才能压缩。这句介绍里,也可以看到 source_reuse 的正常使用需要 doc_values。_那是不是一样使用 doc_values 进行内容展示呢?既然用于 docvalue_fields 内容展示,为什么还是内容看不了(不可见)呢?_
keyword 的 ignore_above
仔细看问题场景里 keyword 的配置,它使用了 ignore_above。那么,会不会是这里的问题?
我们将 ignore_above 配置带入上面的测试,这里为了简化测试,ignore_above 配置为 3。为区分问题现象,这里两条长度不同的文本进去,一条为 11,一条为1111111,可以作为参数作用效果的对比。
# 1. 创建测试条件的索引,ignore_above 设置为3
PUT test_source3
{
"mappings": {
"_source": {
"enabled": false
},
"properties": {
"msg": {
"type": "keyword",
"ignore_above": 3
}
}
}
}
# 2. 写入数据,
POST test_source3/_doc
{"msg":"1111111"}
POST test_source3/_doc
{"msg":"11"}
# 3. 使用 docvalue_fields 查询数据
POST test_source3/_search
{"docvalue_fields": ["msg"]}
# 返回内容
{
"took": 363,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "test_source3",
"_type": "_doc",
"_id": "yhvjj5kBvrlGDwP22KsG",
"_score": 1
},
{
"_index": "test_source3",
"_type": "_doc",
"_id": "yxvzj5kBvrlGDwP2Nav6",
"_score": 1,
"fields": {
"msg": [
"11"
]
}
}
]
}
}OK! 问题终于复现了。我们再来看看作为关键因素的 ignore_above 参数是用来干嘛的。
ignore_above:任何长度超过此整数值的字符串都不应被索引。默认值为 2147483647。默认动态映射会创建一个 ignore_above 设置为 256 的 keyword 子字段。也就是说,ignore_above 在(倒排)索引时会截取内容,防止产生的索引内容过长。
但是从测试的两个文本来看,面对在参数范围内的文档,docvalues 会正常创建,而超出参数范围的文本而忽略创建(至于这个问题背后的源码细节我们可以另外开坑再鸽,此处省略)。
那么,在 source_reuse 下,keyword 的 ignore_above 是不是起到了相同的作用呢?
我们可以在问题场景上去除 ignore_above,参数试试,来看下面的测试:
# 1. 创建测试条件的索引,使用 source_reuse,设置 ignore_above 为3
PUT test_source4
{
"settings": {
"index": {
"source_reuse": "true"
}
},
"mappings": {
"properties": {
"msg": {
"type": "text",
"fields": {
"keyword": {
"ignore_above": 3,
"type": "keyword"
}
}
}
}
}
}
# 2. 写入数据
POST test_source4/_doc
{"msg":"1111111"}
POST test_source4/_doc
{"msg":"11"}
# 3. 使用 docvalue_fields 查询数据
POST test_source4/_search
# 返回内容
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "test_source4",
"_type": "_doc",
"_id": "",
"_score": 1,
"_source": {}
},
{
"_index": "test_source4",
"_type": "_doc",
"_id": "zRv2j5kBvrlGDwP2_qsO",
"_score": 1,
"_source": {
"msg": "11"
}
}
]
}
}可以看到,数据“不可见”的问题被完整的复现了。
小结
从上面一系列针对数据“不可见”问题的测试,我们可以总结以下几点:
- 在 source_reuse 的压缩使用中,keyword 字段的 ignore_ablve 参数尽量使用默认值,不要进行过短的设置(这个 tip 已补充在 Easysearch 文档中)。
- 在 source_reuse 是对数据压缩常见方法-关闭 source 字段的产品化处理,在日志压缩场景中有效且便捷,可以考虑多加利用。
- keyword 的 ignore_above 参数,不仅超出长度范围不进行倒排索引,也不会写入 docvalues。
特别感谢:社区@牛牪犇群
更多 Easysearch 资料请查看 官网文档。
作者:金多安,极限科技(INFINI Labs)搜索运维专家,Elastic 认证专家,搜索客社区日报责任编辑。一直从事与搜索运维相关的工作,日常会去挖掘 ES / Lucene 方向的搜索技术原理,保持搜索相关技术发展的关注。
原文:https://infinilabs.cn/blog/2025/invisibility-in-easysearch-field/
背景问题
前阵子,社区有小伙伴在使用 Easysearch 的数据压缩功能时发现,在开启 source_reuse 和 ZSTD 后,一个字段的内容看不到了。
索引的设置如下:
{
......
"settings": {
"index": {
"codec": "ZSTD",
"source_reuse": "true"
}
},
"mappings": {
"dynamic_templates": [
{
"message_field": {
"path_match": "message",
"mapping": {
"norms": false,
"type": "text"
},
"match_mapping_type": "string"
}
},
{
"string_fields": {
"mapping": {
"norms": false,
"type": "text",
"fields": {
"keyword": {
"ignore_above": 256,
"type": "keyword"
}
}
},
"match_mapping_type": "string",
"match": "*"
}
}
]
......
}然后产生的一个多字段内容能被搜索到,但是不可见。
类似于下面的这个情况:
原因分析
我们先来看看整个字段展示经历的环节:
- 字段写入索引的时候,不仅写了 text 字段也写了 keyword 字段。
- keyword 字段产生倒排索引的时候,会忽略掉长度超过 ignore_above 的内容。
- 因为开启了 source_reuse,_source 字段中与 doc_values 或倒排索引重复的部分会被去除。
- 产生的数据文件进行了 ZSTD 压缩,进一步提高了数据的压缩效率。
- 索引进行倒排或者 docvalue 的查询,检索到这个文档进行展示。
- 展示的时候通过文档 id 获取
_source或者docvalues_fields的内容来展示文本,但是文本内容是空的。
其中步骤 4 中的 ZSTD 压缩,是作用于数据文件的,并不对数据内容进行修改。因此,我们来专注于其他环节。
问题复现
首先,这个字段索引的配置也是一个 es 常见的设置,并不会带来内容显示缺失的问题。
"mapping": {
"type": "text",
"fields": {
"keyword": {
"ignore_above": 256,
"type": "keyword"
}
}
},那么,source_reuse 就成了我们可以重点排查的环节。
source 发生了什么
source_reuse 的作用描述如下:
source_reuse: 启用 source_reuse 配置项能够去除 _source 字段中与 doc_values 或倒排索引重复的部分,从而有效减小索引总体大小,这个功能对日志类索引效果尤其明显。
source_reuse 支持对以下数据类型进行压缩:keyword,integer,long,short,boolean,float,half_float,double,geo_point,ip, 如果是 text 类型,需要默认启用 keyword 类型的 multi-field 映射。 以上类型必须启用 doc_values 映射(默认启用)才能压缩。这是一个对 _source 字段进行产品化的功能实现。为了减少索引的存储体量,简单粗暴的操作是直接将_source字段进行关闭,利用其他数据格式去存储,在查询的时候对应的利用 docvalue 或者 indexed 去展示文本内容。
那么 _source关闭后,会不会也有这样的问题呢?
测试的步骤如下:
# 1. 创建不带source的双字段索引
PUT test_source
{
"mappings": {
"_source": {
"enabled": false
},
"properties": {
"msg": {
"type": "text",
"fields": {
"keyword": {
"ignore_above": 256,
"type": "keyword"
}
}
}
}
}
}
# 2. 写入测试数据
POST test_source/_doc/1
{"msg":"""[08-27 14:28:45] [DBG] [config.go:273] config contain variables, try to parse with environments
[08-27 14:28:45] [DBG] [config.go:214] load config files: []
[08-27 14:28:45] [INF] [pipeline.go:419] creating pipeline: pipeline_logging_merge
[08-27 14:28:45] [INF] [pipeline.go:419] creating pipeline: ingest_pipeline_logging
[08-27 14:28:45] [INF] [pipeline.go:419] creating pipeline: async_messages_merge
[08-27 14:28:45] [INF] [pipeline.go:419] creating pipeline: metrics_merge
[08-27 14:28:45] [INF] [pipeline.go:419] creating pipeline: request_logging_merge
[08-27 14:28:45] [INF] [pipeline.go:419] creating pipeline: ingest_merged_requests
[08-27 14:28:45] [INF] [pipeline.go:419] creating pipeline: async_ingest_bulk_requests
[08-27 14:28:45] [INF] [module.go:159] started module: pipeline
[08-27 14:28:45] [DBG] [module.go:163] all system module are started
[08-27 14:28:45] [DBG] [floating_ip.go:348] setup floating_ip, root privilege are required
[08-27 14:28:45] [DBG] [queue_config.go:121] init new queue config:e60457c6eae50a4eabbb62fc1001dccc,bulk_requests
[08-27 14:28:45] [DBG] [queue_config.go:121] init new queue config:e60457c6eae50a4eabbb62fc1001dccc,bulk_requests
[08-27 14:28:45] [DBG] [queue_config.go:121] init new queue config:e60457c6eae50a4eabbb62fc1001dccc,bulk_requests
[08-27 14:28:45] [DBG] [processor.go:139] generated new processors: indexing_merge
[08-27 14:28:45] [DBG] [pipeline.go:466] processing pipeline_v2: metrics_merge
[08-27 14:28:45] [DBG] [processor.go:139] generated new processors: when
[08-27 14:28:45] [DBG] [pipeline.go:466] processing pipeline_v2: ingest_merged_requests
[08-27 14:28:45] [DBG] [processor.go:139] generated new processors: indexing_merge
[08-27 14:28:45] [DBG] [pipeline.go:466] processing pipeline_v2: request_logging_merge
[08-27 14:28:45] [DBG] [processor.go:139] generated new processors: indexing_merge
[08-27 14:28:45] [DBG] [pipeline.go:466] processing pipeline_v2: async_messages_merge
[08-27 14:28:45] [DBG] [processor.go:139] generated new processors: bulk_indexing
[08-27 14:28:45] [DBG] [pipeline.go:466] processing pipeline_v2: ingest_pipeline_logging
[08-27 14:28:45] [DBG] [queue_config.go:121] init new queue config:1216c96eb876eee5b177d45436d0a362,gateway-pipeline-logs
[08-27 14:28:45] [DBG] [processor.go:139] generated new processors: bulk_indexing
[08-27 14:28:45] [DBG] [processor.go:139] generated new processors: indexing_merge
[08-27 14:28:45] [DBG] [pipeline.go:466] processing pipeline_v2: pipeline_logging_merge
[08-27 14:28:45] [DBG] [pipeline.go:466] processing pipeline_v2: async_ingest_bulk_requests
[08-27 14:28:45] [DBG] [badger.go:110] init badger database [queue_consumer_commit_offset]
[08-27 14:28:45] [INF] [floating_ip.go:290] floating_ip entering standby mode
[08-27 14:28:45] [DBG] [badger.go:110] init badger database [dis_locker]
[08-27 14:28:45] [DBG] [time.go:208] refresh low precision time in background
[08-27 14:28:45] [DBG] [domain_actions.go:278] elasticsearch metadata [backup] was not found
[08-27 14:28:45] [DBG] [bulk_indexing.go:355] metadata for [backup] is nil
[08-27 14:28:50] [INF] [module.go:178] started plugin: floating_ip
[08-27 14:28:50] [INF] [module.go:178] started plugin: force_merge
[08-27 14:28:50] [DBG] [network.go:78] network io stats will be included for map[]
[08-27 14:28:50] [INF] [module.go:178] started plugin: metrics
[08-27 14:28:50] [INF] [module.go:178] started plugin: statsd
[08-27 14:28:50] [DBG] [entry.go:100] reuse port 0.0.0.0:7005
[08-27 14:28:50] [DBG] [metrics.go:205] collecting network metrics
[08-27 14:28:50] [DBG] [metrics.go:174] collecting instance metrics
[08-27 14:28:50] [DBG] [elasticsearch.go:128] init elasticsearch proxy instance: prod
[08-27 14:28:50] [DBG] [filter.go:103] generated new filters: when, elasticsearch
[08-27 14:28:50] [DBG] [entry.go:142] apply filter flow: [*] [/_bulk] [ filters ]
[08-27 14:28:50] [DBG] [entry.go:142] apply filter flow: [*] [/{any_index}/_bulk] [ filters ]
[08-27 14:28:50] [DBG] [elasticsearch.go:128] init elasticsearch proxy instance: prod
[08-27 14:28:50] [DBG] [filter.go:103] generated new filters: request_path_limiter, elasticsearch
[08-27 14:28:50] [INF] [module.go:178] started plugin: gateway
[08-27 14:28:50] [DBG] [module.go:182] all user plugin are started
[08-27 14:28:50] [INF] [module.go:184] all modules are started
[08-27 14:28:50] [INF] [app.go:556] gateway is up and running now.
[08-27 14:28:50] [DBG] [domain_actions.go:278] elasticsearch metadata [backup] was not found
[08-27 14:28:50] [DBG] [bulk_indexing.go:355] metadata for [backup] is nil
[08-27 14:28:55] [DBG] [domain_actions.go:278] elasticsearch metadata [backup] was not found
[08-27 14:28:55] [DBG] [bulk_indexing.go:355] metadata for [backup] is nil
[08-27 14:29:00] [DBG] [metrics.go:205] collecting network metrics
[08-27 14:29:00] [DBG] [metrics.go:174] collecting instance metrics
[08-27 14:29:00] [DBG] [domain_actions.go:278] elasticsearch metadata [backup] was not found
[08-27 14:29:00] [DBG] [bulk_indexing.go:355] metadata for [backup] is nil
[08-27 14:29:05] [DBG] [domain_actions.go:278] elasticsearch metadata [backup] was not found
[08-27 14:29:05] [DBG] [bulk_indexing.go:355] metadata for [backup] is nil
[08-27 14:29:10] [DBG] [metrics.go:205] collecting network metrics
[08-27 14:29:10] [DBG] [metrics.go:174] collecting instance metrics
[08-27 14:29:10] [DBG] [domain_actions.go:278] elasticsearch metadata [backup] was not found"""}
# 3. 查询数据
GET test_source/_search此时,可以看到,存入的文档检索出来是空的
_source 字段是用于索引时传递的原始 JSON 文档主体。它本身未被索引成倒排(因此不作用于 query 阶段),只是在执行查询时用于 fetch 文档内容。
对于 text 类型,关闭_source,则字段内容自然不可被查看。
而对于 keyword 字段,查看_source也是不行的。可是 keyword 不仅存储source,还存储了 doc_values。因此,对于 keyword 字段类型,可以考虑关闭_source,使用 docvalue_fields 来查看字段内容。
测试如下:
# 1. 创建测试条件的索引
PUT test_source2
{
"mappings": {
"_source": {
"enabled": false
},
"properties": {
"msg": {
"type": "keyword"
}
}
}
}
# 2. 写入数据
POST test_source2/_doc
{"msg":"1111111"}
# 3. 使用 docvalue_fields 查询数据
POST test_source2/_search
{"docvalue_fields": ["msg"]}
# 返回结果
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "test_source2",
"_type": "_doc",
"_id": "yBvTj5kBvrlGDwP29avf",
"_score": 1,
"fields": {
"msg": [
"1111111"
]
}
}
]
}
}在如果是 text 类型,需要默认启用 keyword 类型的 multi-field 映射。 以上类型必须启用 doc_values 映射(默认启用)才能压缩。这句介绍里,也可以看到 source_reuse 的正常使用需要 doc_values。_那是不是一样使用 doc_values 进行内容展示呢?既然用于 docvalue_fields 内容展示,为什么还是内容看不了(不可见)呢?_
keyword 的 ignore_above
仔细看问题场景里 keyword 的配置,它使用了 ignore_above。那么,会不会是这里的问题?
我们将 ignore_above 配置带入上面的测试,这里为了简化测试,ignore_above 配置为 3。为区分问题现象,这里两条长度不同的文本进去,一条为 11,一条为1111111,可以作为参数作用效果的对比。
# 1. 创建测试条件的索引,ignore_above 设置为3
PUT test_source3
{
"mappings": {
"_source": {
"enabled": false
},
"properties": {
"msg": {
"type": "keyword",
"ignore_above": 3
}
}
}
}
# 2. 写入数据,
POST test_source3/_doc
{"msg":"1111111"}
POST test_source3/_doc
{"msg":"11"}
# 3. 使用 docvalue_fields 查询数据
POST test_source3/_search
{"docvalue_fields": ["msg"]}
# 返回内容
{
"took": 363,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "test_source3",
"_type": "_doc",
"_id": "yhvjj5kBvrlGDwP22KsG",
"_score": 1
},
{
"_index": "test_source3",
"_type": "_doc",
"_id": "yxvzj5kBvrlGDwP2Nav6",
"_score": 1,
"fields": {
"msg": [
"11"
]
}
}
]
}
}OK! 问题终于复现了。我们再来看看作为关键因素的 ignore_above 参数是用来干嘛的。
ignore_above:任何长度超过此整数值的字符串都不应被索引。默认值为 2147483647。默认动态映射会创建一个 ignore_above 设置为 256 的 keyword 子字段。也就是说,ignore_above 在(倒排)索引时会截取内容,防止产生的索引内容过长。
但是从测试的两个文本来看,面对在参数范围内的文档,docvalues 会正常创建,而超出参数范围的文本而忽略创建(至于这个问题背后的源码细节我们可以另外开坑再鸽,此处省略)。
那么,在 source_reuse 下,keyword 的 ignore_above 是不是起到了相同的作用呢?
我们可以在问题场景上去除 ignore_above,参数试试,来看下面的测试:
# 1. 创建测试条件的索引,使用 source_reuse,设置 ignore_above 为3
PUT test_source4
{
"settings": {
"index": {
"source_reuse": "true"
}
},
"mappings": {
"properties": {
"msg": {
"type": "text",
"fields": {
"keyword": {
"ignore_above": 3,
"type": "keyword"
}
}
}
}
}
}
# 2. 写入数据
POST test_source4/_doc
{"msg":"1111111"}
POST test_source4/_doc
{"msg":"11"}
# 3. 使用 docvalue_fields 查询数据
POST test_source4/_search
# 返回内容
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "test_source4",
"_type": "_doc",
"_id": "",
"_score": 1,
"_source": {}
},
{
"_index": "test_source4",
"_type": "_doc",
"_id": "zRv2j5kBvrlGDwP2_qsO",
"_score": 1,
"_source": {
"msg": "11"
}
}
]
}
}可以看到,数据“不可见”的问题被完整的复现了。
小结
从上面一系列针对数据“不可见”问题的测试,我们可以总结以下几点:
- 在 source_reuse 的压缩使用中,keyword 字段的 ignore_ablve 参数尽量使用默认值,不要进行过短的设置(这个 tip 已补充在 Easysearch 文档中)。
- 在 source_reuse 是对数据压缩常见方法-关闭 source 字段的产品化处理,在日志压缩场景中有效且便捷,可以考虑多加利用。
- keyword 的 ignore_above 参数,不仅超出长度范围不进行倒排索引,也不会写入 docvalues。
特别感谢:社区@牛牪犇群
更多 Easysearch 资料请查看 官网文档。
收起阅读 »作者:金多安,极限科技(INFINI Labs)搜索运维专家,Elastic 认证专家,搜索客社区日报责任编辑。一直从事与搜索运维相关的工作,日常会去挖掘 ES / Lucene 方向的搜索技术原理,保持搜索相关技术发展的关注。
原文:https://infinilabs.cn/blog/2025/invisibility-in-easysearch-field/
INFINI Labs 产品更新 | Coco AI v0.8 与 Easysearch v1.15 全新功能上线,AI 搜索体验再进化!

INFINI Labs 产品更新发布!此次更新主要包括 Coco AI v0.8 新增窗口管理插件,新的插件类型 View,Linux 文件搜索以及更多的连接器;Easysearch v1.15 新增 UI 插件,提供了轻量级界面化管理功能,不再依赖第三方对集群进行管理,真正做到开箱即用,AI 插件正式提供混合搜索能力,结合了关键词搜索和语义搜索,以提升搜索相关性。
以下为详细更新介绍:
Coco AI v0.8
Coco AI 是一款完全开源、跨平台的企业级智能搜索与助手系统,专为现代企业打造。它通过统一搜索入口,连接企业内外部的异构数据源,融合大模型能力,帮助团队高效访问知识,智能决策协作。

Coco AI 本次详细更新记录如下:
Coco AI 客户端 v0.8
功能特性 (Features)
- 改进版本升级,跳过此版本的按钮
- 支持从本地安装插件
- 子插件的 JSON 现在也可以设置 platforms 字段
- 插件设置页面现在可以卸载插件
- 新增插件设置项 'hide_before_open'
- App 搜索索引 app 的名字,现在索引多种语言的 app 名字,英文、中文以及系统语言
- Debug 模式下,支持 context menu
- 为 Linux (GNOME/KDE) 实现文件搜索
- 实现 MacOS 窗口管理插件
- 新增插件类型 View
- 对于文件搜索的结果,现在可以打开文件所在的文件夹
问题修复 (Bug Fixes)
- 修复更新检查失败的问题
- 修复 web 组件,登录状态的问题
- 修复快捷键无法打开插件商店的问题
- 修复设置插件快捷键在 Windows 上崩溃的问题
- 修复无法通过 "coco://" deeplink 登录的问题
- MacOS 文件搜索,确保 mdfind 进程不会成为僵尸进程
- 修复设置窗口打开是空白的问题
- 尽最大努力,确保用户添加的 search path 中的文件会被 indexer 索引
- 修复 MacOS 某些 app 设置空的 CFBundleDisplayName/CFBundleName 导致 app 名字为空的问题
改进优化 (Improvements)
- 将 query_coco_fusion() 函数拆分
- 清理 tauri::AppHandle’s 类型的范型参数 R
- 检查各个安装渠道的 plugin.json 文件,确保合法
- 在 MacOS 上不再为窗口设置 CanJoinAllSpaces 的属性
- 修复 web 组件构建的问题
- 为第三方插件安装的过程上锁
- MacOS/iOS: 支持从 Assets.car 提取 app 图标,从而不再跳过它们
- 放宽 MacOS 文件搜索的条件,避免无法搜到的问题
- 确保 Coco app 在呼出时,不会拿 focus
- 对于 web 组件,跳过登录检查
- 对于 View 插件,处理 HTML 文件,使用 convertFileSrc()处理如下 2 个 tag:"link[href]" and "img[src]"
Coco APP 相关截图
Coco AI 服务端 v0.8
重大变更(Breaking Changes)
- 更新语雀的文档 ID
- 重构数据源同步管理
功能特性 (Features)
- 支持通过路径层次方式访问数据源中的文档
- 处理文档搜索的 path_hierarchy 配置
- Confluence Wiki 连接器
- 为 Notion 连接器提取内容
- 新增网络存储连接器
- 新增 PostgreSQL 连接器
- 新增 MySQL 连接器
- 新增 GitHub 连接器
- 新增 飞书/Lark 连接器
- 新增 GitLab 连接器
- 新增 Salesforce 连接器
- 新增 Gitea 连接器
- 新增 MSSQL 连接器
- 新增 Oracle 连接器
问题修复 (Bug Fixes)
- 修正助手更新逻辑
- 生成唯一图标键以防止意外删除所有图标
- 在 Coco 服务器登录期间修改 access_token URL
- 修复 Web 小部件的权限问题
- 由于在搜索框中导入图标而导致的额外高度
- 全屏模式下页面滚动不工作
- 解决 API 令牌列表分页问题
- MSSQL 分页错误
- 修复 S3 连接器图标
改进优化 (Improvements)
- 移除未使用的 WebSocket API
- 为 Google Drive 添加缺失的根文件夹
- 更新创建/修改连接器页面上的默认连接器设置表单
- 调整数据源详情的标题
- 重构摘要处理器
- 为 Google Drive 添加缺失的文档
- 将 Easysearch 初始管理员密码更新为复杂规则
- 统一许可证头
- 更新默认数据源编辑页面
- 重构 OAuth 连接组件
- 将数据源列表的默认大小设置为 12
- 在设置中添加搜索设置
- 在集成全屏中支持页面模式
- 为列表项添加图标
- 重构非托管模式的 security API
- 支持通过路径层次方式访问 local_fs 连接器中的文档
- 支持通过路径层次方式访问 S3、网络驱动器、GitHub、GitLab 和 Gitee 连接器中的文档
Coco Server 相关截图

Easysearch v1.15
重大变更(Breaking Changes)
- 针对安全模块的角色名称进行规范,废弃不符合规范的角色
- 更新创建搜索管道的 API 的 json 结构和说明文档
功能特性 (Features)
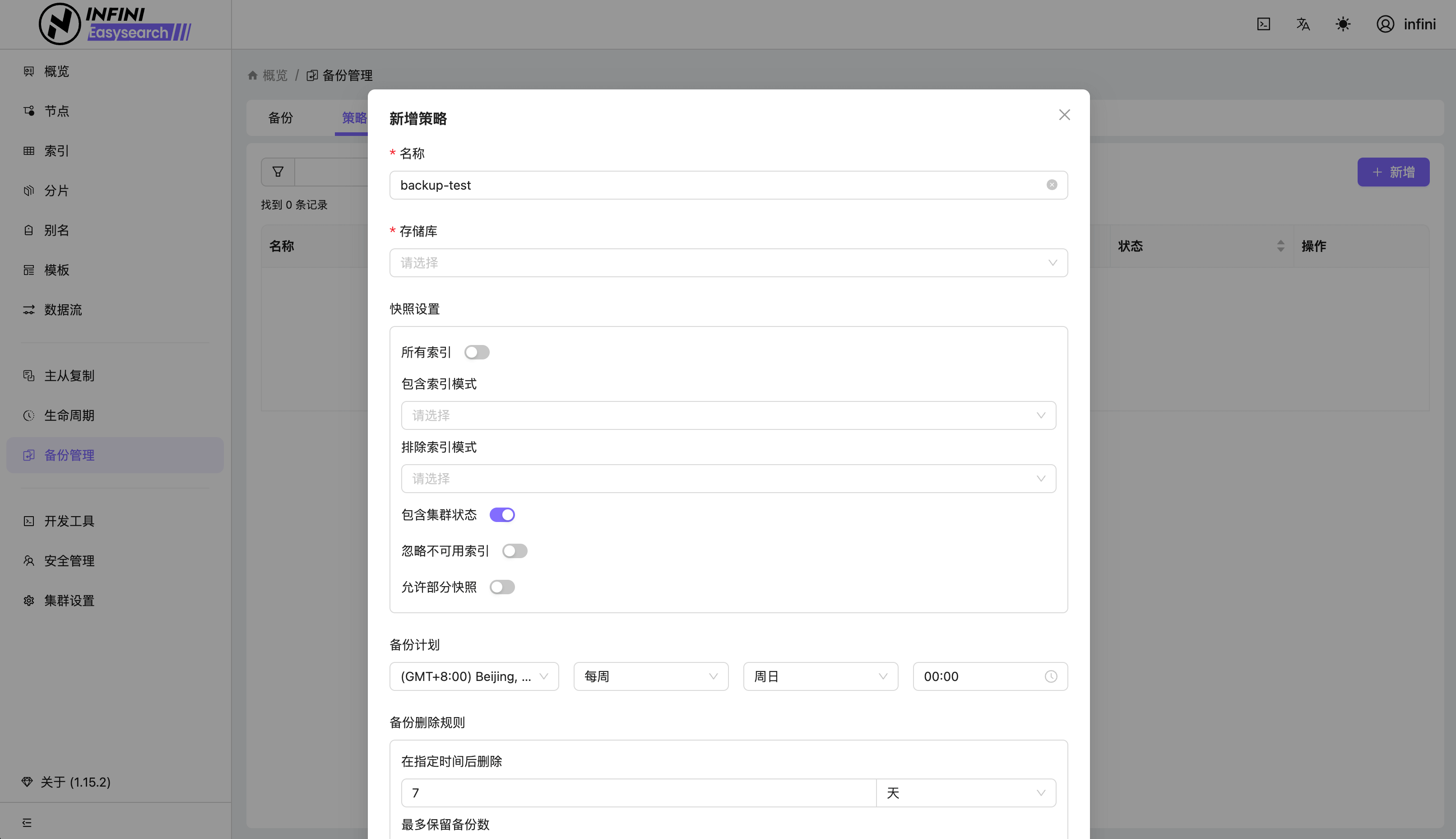
- 新增 ui 插件,涵盖从集群,节点,索引,到分片等不同维度的监控和管理功能以及备份快照、跨集群复制、数据流、热点线程、限流限速配置等管理功能
- ai 插件正式提供混合搜索能力,结合了关键词搜索和语义搜索,以提升搜索相关性
- ai 插件正式提供混合搜索能力
- 允许动态的跨模板重用设置
改进优化 (Improvements)
- index-management 从 plugin 移动到 modules
- 精简证书错误时的日志输出
- 改进 search_pipeline 的统计指标
- 改进角色名称和描述
- 增加 数据流(Data streams)说明文档
- 更新搜索管道相关文档
- 去掉 ILM 配置索引的前缀,并兼容旧索引
Easysearch 新增的 UI 插件为 Easysearch 提供了轻量级界面化管理功能,不再依赖第三方对集群进行管理,真正做到开箱即用。 UI 相关截图如下:

更多详情请查看以下各产品的 Release Notes 或联系我们的技术支持团队!
期待反馈
欢迎下载体验使用,如果您在使用过程中遇到如何疑问或者问题,欢迎前往 INFINI Labs Github(https://github.com/infinilabs) 中的对应项目中提交 Feature Request 或提交 Bug。
下载地址: https://infinilabs.cn/download
邮件:hello@infini.ltd
电话:(+86) 400-139-9200
Discord:https://discord.gg/4tKTMkkvVX
也欢迎大家微信扫码添加小助手(INFINI-Labs),加入用户群一起讨论交流。

关于极限科技(INFINI Labs)

极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
INFINI Labs 产品更新发布!此次更新主要包括 Coco AI v0.8 新增窗口管理插件,新的插件类型 View,Linux 文件搜索以及更多的连接器;Easysearch v1.15 新增 UI 插件,提供了轻量级界面化管理功能,不再依赖第三方对集群进行管理,真正做到开箱即用,AI 插件正式提供混合搜索能力,结合了关键词搜索和语义搜索,以提升搜索相关性。
以下为详细更新介绍:
Coco AI v0.8
Coco AI 是一款完全开源、跨平台的企业级智能搜索与助手系统,专为现代企业打造。它通过统一搜索入口,连接企业内外部的异构数据源,融合大模型能力,帮助团队高效访问知识,智能决策协作。
Coco AI 本次详细更新记录如下:
Coco AI 客户端 v0.8
功能特性 (Features)
- 改进版本升级,跳过此版本的按钮
- 支持从本地安装插件
- 子插件的 JSON 现在也可以设置 platforms 字段
- 插件设置页面现在可以卸载插件
- 新增插件设置项 'hide_before_open'
- App 搜索索引 app 的名字,现在索引多种语言的 app 名字,英文、中文以及系统语言
- Debug 模式下,支持 context menu
- 为 Linux (GNOME/KDE) 实现文件搜索
- 实现 MacOS 窗口管理插件
- 新增插件类型 View
- 对于文件搜索的结果,现在可以打开文件所在的文件夹
问题修复 (Bug Fixes)
- 修复更新检查失败的问题
- 修复 web 组件,登录状态的问题
- 修复快捷键无法打开插件商店的问题
- 修复设置插件快捷键在 Windows 上崩溃的问题
- 修复无法通过 "coco://" deeplink 登录的问题
- MacOS 文件搜索,确保 mdfind 进程不会成为僵尸进程
- 修复设置窗口打开是空白的问题
- 尽最大努力,确保用户添加的 search path 中的文件会被 indexer 索引
- 修复 MacOS 某些 app 设置空的 CFBundleDisplayName/CFBundleName 导致 app 名字为空的问题
改进优化 (Improvements)
- 将 query_coco_fusion() 函数拆分
- 清理 tauri::AppHandle’s 类型的范型参数 R
- 检查各个安装渠道的 plugin.json 文件,确保合法
- 在 MacOS 上不再为窗口设置 CanJoinAllSpaces 的属性
- 修复 web 组件构建的问题
- 为第三方插件安装的过程上锁
- MacOS/iOS: 支持从 Assets.car 提取 app 图标,从而不再跳过它们
- 放宽 MacOS 文件搜索的条件,避免无法搜到的问题
- 确保 Coco app 在呼出时,不会拿 focus
- 对于 web 组件,跳过登录检查
- 对于 View 插件,处理 HTML 文件,使用 convertFileSrc()处理如下 2 个 tag:"link[href]" and "img[src]"
Coco APP 相关截图
Coco AI 服务端 v0.8
重大变更(Breaking Changes)
- 更新语雀的文档 ID
- 重构数据源同步管理
功能特性 (Features)
- 支持通过路径层次方式访问数据源中的文档
- 处理文档搜索的 path_hierarchy 配置
- Confluence Wiki 连接器
- 为 Notion 连接器提取内容
- 新增网络存储连接器
- 新增 PostgreSQL 连接器
- 新增 MySQL 连接器
- 新增 GitHub 连接器
- 新增 飞书/Lark 连接器
- 新增 GitLab 连接器
- 新增 Salesforce 连接器
- 新增 Gitea 连接器
- 新增 MSSQL 连接器
- 新增 Oracle 连接器
问题修复 (Bug Fixes)
- 修正助手更新逻辑
- 生成唯一图标键以防止意外删除所有图标
- 在 Coco 服务器登录期间修改 access_token URL
- 修复 Web 小部件的权限问题
- 由于在搜索框中导入图标而导致的额外高度
- 全屏模式下页面滚动不工作
- 解决 API 令牌列表分页问题
- MSSQL 分页错误
- 修复 S3 连接器图标
改进优化 (Improvements)
- 移除未使用的 WebSocket API
- 为 Google Drive 添加缺失的根文件夹
- 更新创建/修改连接器页面上的默认连接器设置表单
- 调整数据源详情的标题
- 重构摘要处理器
- 为 Google Drive 添加缺失的文档
- 将 Easysearch 初始管理员密码更新为复杂规则
- 统一许可证头
- 更新默认数据源编辑页面
- 重构 OAuth 连接组件
- 将数据源列表的默认大小设置为 12
- 在设置中添加搜索设置
- 在集成全屏中支持页面模式
- 为列表项添加图标
- 重构非托管模式的 security API
- 支持通过路径层次方式访问 local_fs 连接器中的文档
- 支持通过路径层次方式访问 S3、网络驱动器、GitHub、GitLab 和 Gitee 连接器中的文档
Coco Server 相关截图
Easysearch v1.15
重大变更(Breaking Changes)
- 针对安全模块的角色名称进行规范,废弃不符合规范的角色
- 更新创建搜索管道的 API 的 json 结构和说明文档
功能特性 (Features)
- 新增 ui 插件,涵盖从集群,节点,索引,到分片等不同维度的监控和管理功能以及备份快照、跨集群复制、数据流、热点线程、限流限速配置等管理功能
- ai 插件正式提供混合搜索能力,结合了关键词搜索和语义搜索,以提升搜索相关性
- ai 插件正式提供混合搜索能力
- 允许动态的跨模板重用设置
改进优化 (Improvements)
- index-management 从 plugin 移动到 modules
- 精简证书错误时的日志输出
- 改进 search_pipeline 的统计指标
- 改进角色名称和描述
- 增加 数据流(Data streams)说明文档
- 更新搜索管道相关文档
- 去掉 ILM 配置索引的前缀,并兼容旧索引
Easysearch 新增的 UI 插件为 Easysearch 提供了轻量级界面化管理功能,不再依赖第三方对集群进行管理,真正做到开箱即用。 UI 相关截图如下:
更多详情请查看以下各产品的 Release Notes 或联系我们的技术支持团队!
期待反馈
欢迎下载体验使用,如果您在使用过程中遇到如何疑问或者问题,欢迎前往 INFINI Labs Github(https://github.com/infinilabs) 中的对应项目中提交 Feature Request 或提交 Bug。
下载地址: https://infinilabs.cn/download
邮件:hello@infini.ltd
电话:(+86) 400-139-9200
Discord:https://discord.gg/4tKTMkkvVX
也欢迎大家微信扫码添加小助手(INFINI-Labs),加入用户群一起讨论交流。
关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
收起阅读 »【搜索客社区日报】第2124期 (2025-09-30)
1. 手把手教你做个图片搜索引擎(爬梯)
https://medium.com/%40asirabde ... 6f309
2. 索引刷新的最差实践们(不是(爬梯)
https://blog.palantir.com/defe ... 52ff1
3. ES适合当数据库用吗?(爬梯)
https://www.paradedb.com/blog/ ... abase
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
1. 手把手教你做个图片搜索引擎(爬梯)
https://medium.com/%40asirabde ... 6f309
2. 索引刷新的最差实践们(不是(爬梯)
https://blog.palantir.com/defe ... 52ff1
3. ES适合当数据库用吗?(爬梯)
https://www.paradedb.com/blog/ ... abase
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
收起阅读 »


