

【搜索客社区日报】第2231期 (2026-05-15)
https://mp.weixin.qq.com/s/7Tn6CI899BZ1mPqCacNvUQ
2、留给内容平台搜索架构转型的时间不多了:从123RF图库放弃OpenSearch聊起
https://mp.weixin.qq.com/s/v3UW0cl_Ga8wfSGgynpSdw
3、如何衡量和提升 Elasticsearch 搜索召回率:通过 混合搜索 从 0.43 提升到 0.75
https://my.oschina.net/u/3343882/blog/19658268
4、不用 Logstash,如何实现 Elasticsearch 的增量数据同步?
https://my.oschina.net/u/5170379/blog/19577824
5、Easysearch analysis-ik 多词典性能优化:从性能回退到分词性能提升 25%~30%
https://mp.weixin.qq.com/s/C5EsDLsF0J0xh-0XX7-L5w
编辑:Fred
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/7Tn6CI899BZ1mPqCacNvUQ
2、留给内容平台搜索架构转型的时间不多了:从123RF图库放弃OpenSearch聊起
https://mp.weixin.qq.com/s/v3UW0cl_Ga8wfSGgynpSdw
3、如何衡量和提升 Elasticsearch 搜索召回率:通过 混合搜索 从 0.43 提升到 0.75
https://my.oschina.net/u/3343882/blog/19658268
4、不用 Logstash,如何实现 Elasticsearch 的增量数据同步?
https://my.oschina.net/u/5170379/blog/19577824
5、Easysearch analysis-ik 多词典性能优化:从性能回退到分词性能提升 25%~30%
https://mp.weixin.qq.com/s/C5EsDLsF0J0xh-0XX7-L5w
编辑:Fred
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2230期 (2026-05-13)
https://mp.weixin.qq.com/s/TI8wqs94Uzp7szQlsFj32Q
2.一个索引,所有媒体:介绍 jina-embeddings-v5-omni
https://blog.csdn.net/UbuntuTo ... 02005
3.AI Agent 记忆:使用 Elasticsearch 管理记忆,打造智能 Agent
https://cloud.tencent.com/deve ... 67232
编辑:kin122
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/TI8wqs94Uzp7szQlsFj32Q
2.一个索引,所有媒体:介绍 jina-embeddings-v5-omni
https://blog.csdn.net/UbuntuTo ... 02005
3.AI Agent 记忆:使用 Elasticsearch 管理记忆,打造智能 Agent
https://cloud.tencent.com/deve ... 67232
编辑:kin122
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2229期 (2026-05-12)
https://medium.com/%40linjifan ... 969e2
2. Elasticsearch 从入门到精通系列—后面还好多连载的不贴了(需要梯子)
https://dogukanngumus.medium.c ... 42f72
https://dogukanngumus.medium.c ... ba02e
https://dogukanngumus.medium.c ... 1d620
https://dogukanngumus.medium.c ... a527f
3. 不阻断PHP的前提下把TPS提高到1000你敢信?(需要梯子)
https://awstip.com/scaling-tel ... 70521
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
https://medium.com/%40linjifan ... 969e2
2. Elasticsearch 从入门到精通系列—后面还好多连载的不贴了(需要梯子)
https://dogukanngumus.medium.c ... 42f72
https://dogukanngumus.medium.c ... ba02e
https://dogukanngumus.medium.c ... 1d620
https://dogukanngumus.medium.c ... a527f
3. 不阻断PHP的前提下把TPS提高到1000你敢信?(需要梯子)
https://awstip.com/scaling-tel ... 70521
编辑:斯蒂文
更多资讯:http://news.searchkit.cn 收起阅读 »
Easysearch analysis-ik 多词典性能优化:从性能回退到分词性能提升 25%~30%
Easysearch 版 analysis-ik 相比开源 IK 有一个重要的增强:支持多词典。简单说就是不同字段可以挂不同词库,可以叠加默认词典,也可以只用自定义词典。这是开源单词典 IK 做不到的。
功能实现初期,主要精力放在把能力跑通上。但在后来的一次写入压测中,我们发现 Easysearch 的写入吞吐和 Elasticsearch 有明显差距,最终定位到问题出在多词典的实现方式上——字段最终该用哪套词典,本来应该在分词前就算好,结果代码里把这个选择丢进了分词的热路径,每次分词都要反复切词典、重复扫同一段文本。
这篇文章记录的就是我们怎么一步步把性能拉回来、最终反超基线的过程。
问题怎么冒出来的
4 月 20 号,我们跑了一轮系统级写入压测。数据、mapping、settings、并发和 bulk 参数都一样,Elasticsearch 8.19.5 和 Easysearch 2.1.2 的写入吞吐差距大得有点不对劲:
| 时间 | 场景 | Elasticsearch | Easysearch | 说明 |
|---|---|---|---|---|
| 2026-04-20 第 2 次有效重跑 | 29900 docs / bulk=250 / concurrency=3 端到端写入压测 |
129.44 docs/s |
31.21 docs/s |
这是整条写入链路的 docs/s,不是单独分词吞吐 |
| 2026-04-20 诊断样本 | 5000 docs / bulk=250 / concurrency=3 |
156.25 docs/s |
30.67 docs/s |
Easysearch 的累计索引耗时约为 Elasticsearch 的 8.0x |

当时服务器上跑的就是早期多词典版本。后面修性能,追的就是这个版本和开源单词典 IK 基线之间的差距。
这一步还不能直接确定问题就在分词器。但差距摆在这儿了,得继续往下排。我们先排除了几个常见干扰因素:
refresh_interval- 动态同义词 HTTP 服务
- mapping / settings 不一致
- 网络层和 bulk 客户端本身
采样结果很快把范围收窄了。Elasticsearch 那边热点比较分散,Easysearch 这边呢,分词链路里出现了异常集中的开销——分词过程中反复做词典选择和字典查找。
瓶颈不在 Lucene 写入链路本身,就在 analysis-ik 的多词典实现上。
根因分析
第一类问题出在实现模型上。多词典想表达的是”这个字段最终用哪套词典”,这件事完全可以在分词前算好。但早期代码里,硬是把它变成了运行时的事:
- “字段用哪个词典”变成了”运行时多轮扫描”——同一段文本对着多套词典各来一遍。
- 全局字典切换的动作放进了每字符的热路径。
- 结果就是同一段文本的扫描和查找成本翻了好几倍。
所以问题不是多词典天然慢,是实现把本该提前算好的东西塞进了热路径反复做。
第二类问题是后续优化过程中留下的额外开销。后面加的跨边界、停用词、长文本等测试本身不是性能问题的来源,它们的作用是把正确性边界补齐,确保每次优化不会改变分词结果。
最后通过性能分析确认,残留开销主要来自两处:缓存命中前还在做不必要的数据复制;诊断逻辑在生产热路径上产生了额外开销。修完之后这两处热点都从火焰图上消失了,说明性能回退确实来自真实的代码路径成本,不是测试抖动。
修复过程
整个修复分四个阶段。
第一阶段:把多词典从”运行时分发”收敛为”最终有效词典视图”
多词典能力保留,但不再让分词器在热路径里反复切词典、重复扫文本。改成在分词前就把字段最终生效的词典算好,分词过程只面对一个已经收敛好的词典视图。
说白了就是把模型拉回正确方向——多词典管表达能力,热路径只管分词。
第二阶段:逐步打掉热路径上的常数开销
留下来的每一项优化,都经过正式性能测试和采样分析验证。原则就一条:不改分词语义,只减少热路径上反复发生的查找、分配和判断。
第三阶段:补齐正确性护栏
正确性测试必须先到位,不然吞吐提升没有意义——万一分词结果变了,跑得再快也白搭。
这一轮重点覆盖了这些容易出问题的场景:
- 真跨边界场景
- 数字和量词合并,如
1号 - 自定义词典里的含符号词
- 补充平面字符跨边界稳定性
- 停用词过滤后的偏移量
- 长文本样本的稳定性
- 正式性能测试数据集的分词结果对齐
后面所有的吞吐数字,前提都是分词结果一致,避免把分词行为的变化误当成性能提升。
第四阶段:清理最后的残留开销
到 4 月 28 号,最后一轮修复集中处理两个地方:
- 词典视图命中缓存时直接返回,不再多做一次数据复制
- 诊断逻辑默认关掉,不让线上请求为调试能力买单
这两处修完,Easysearch 版 IK 就不只是恢复到单词典版本附近了,在正式测试里已经明显领先。
用数据看恢复过程
为了不把系统级写入压测和分词器性能测试混在一起,下面只看几个关键节点。2026-04-20 的 docs/s 是系统级写入吞吐,后面的 tok/s 是单独的分词器吞吐。
这里说的”开源 IK 基线”就是开源 IK 的单词典实现对照版本。所有正式吞吐结论都建立在同一数据集、同一测试方法、分词结果一致的前提上。
| 时间 | 口径 | 关键结果 | 说明 |
|---|---|---|---|
| 2026-04-23 17:02 CST | 初期本地复现 | 服务器多词典版本 61.39 万 tok/s,单词典版本 114.48 万 tok/s |
单词典版本快 86.49%,性能差距被明确复现 |
| 2026-04-24 09:51:12~09:55:15 CST | 第一次正式追平 | smart 相对开源单词典基线 +7.26% |
从明显落后追到略微领先 |
| 2026-04-25 04:14~04:16 CST | 双模式阶段复核 | smart +16.88%,max_word +20.09% |
领先优势开始扩大 |
| 2026-04-28 12:30:56 CST | 最新正式复核 | smart +30.96%,max_word +21.31% |
当前最新结果 |
整个过程就是:
- 先暴露出明显的性能退化
- 逐步缩小差距
- 追平,然后开始领先
- 最终在分词结果完全一致的前提下,正式反超
最早的本地复现数据很关键:服务器当时跑的多词典版本只有 613896.67 tok/s,单词典版本 1144843.77 tok/s。后面所有修复就是冲着这个差距去的。


三张图分别对应问题暴露、分词复现和修复结果:第一张展示服务器 bulk 写入吞吐的系统级差距;第二张展示多词典版本和单词典版本的本地分词差距;第三张展示分词结果对齐后,Easysearch 版 IK 怎么一步步追上来,最终实现 25%~30% 的分词性能提升。
为什么说 Easysearch 版 IK 现在更好
这次修复的价值不只是消灭了几个热点,更重要的是把多词典能力、分词正确性和性能测试体系一起补齐了。
1. 功能更强,性能代价可控
开源单词典 IK 模型简单,但表达能力也弱。Easysearch 的多词典能力要解决的是字段级词库隔离、自定义词典叠加这些实际需求。
关键问题是:能不能把这些能力的性能开销压到足够低。修复后的结果证明,可以。
2. 正确性护栏更完整
这轮补上的测试不只是几个短样例,覆盖了更容易翻车的边界条件:
- 真跨边界场景
- 长文本稳定性
- 自定义词典和符号词
- 数字量词合并
- 停用词过滤后的偏移量
这意味着以后再做性能优化,必须同时保证分词结果不变。想靠改分词行为换吞吐,测试会先拦住。
3. 性能测试体系更严格
这轮之后,Easysearch 对 analysis-ik 的正式性能结论统一按一套标准出:
- 同一数据集
- 同一测试方法
smart和max_word双模式- 分词结果一致
- 有性能分析结果支撑
这套体系能避免两个常见坑:只看单轮吞吐波动就下结论,或者分词结果已经变了还在比性能。
小结
多词典能力在实现初期,主要精力放在功能补齐上——先把字段级词库隔离、自定义词典叠加这些能力跑通,性能优化是后面分阶段来的事,没办法一蹴而就。
这轮优化下来,核心思路其实就一条:把词典选择从分词热路径里挪出去,提前收敛好,让分词过程只面对最终的词典视图。再配合热点清理和正确性护栏,增强功能和更高性能完全可以兼得。
截至 2026 年 4 月 28 日,在本地 Mac 笔记本上的多轮 benchmark 中,Easysearch 版 IK 在 smart 模式大约领先开源单词典 IK 基线 25%~30%,max_word 模式大约领先 20% 左右,分词结果完全一致。具体数字每次跑会有波动,但趋势是稳定的。
这也是 Easysearch 版 IK 相对开源版更有价值的地方:不是多了几个配置项,而是在多词典能力、分词正确性和分词性能三个方面都给出了可验证的结果。
关于 Easysearch

INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。
作者:张磊,极限科技(INFINI Labs)搜索引擎研发负责人,对 Elasticsearch 和 Lucene 源码比较熟悉,目前主要负责公司的 Easysearch 产品的研发以及客户服务工作。
相关文章:
Easysearch 版 analysis-ik 相比开源 IK 有一个重要的增强:支持多词典。简单说就是不同字段可以挂不同词库,可以叠加默认词典,也可以只用自定义词典。这是开源单词典 IK 做不到的。
功能实现初期,主要精力放在把能力跑通上。但在后来的一次写入压测中,我们发现 Easysearch 的写入吞吐和 Elasticsearch 有明显差距,最终定位到问题出在多词典的实现方式上——字段最终该用哪套词典,本来应该在分词前就算好,结果代码里把这个选择丢进了分词的热路径,每次分词都要反复切词典、重复扫同一段文本。
这篇文章记录的就是我们怎么一步步把性能拉回来、最终反超基线的过程。
问题怎么冒出来的
4 月 20 号,我们跑了一轮系统级写入压测。数据、mapping、settings、并发和 bulk 参数都一样,Elasticsearch 8.19.5 和 Easysearch 2.1.2 的写入吞吐差距大得有点不对劲:
| 时间 | 场景 | Elasticsearch | Easysearch | 说明 |
|---|---|---|---|---|
| 2026-04-20 第 2 次有效重跑 | 29900 docs / bulk=250 / concurrency=3 端到端写入压测 |
129.44 docs/s |
31.21 docs/s |
这是整条写入链路的 docs/s,不是单独分词吞吐 |
| 2026-04-20 诊断样本 | 5000 docs / bulk=250 / concurrency=3 |
156.25 docs/s |
30.67 docs/s |
Easysearch 的累计索引耗时约为 Elasticsearch 的 8.0x |
当时服务器上跑的就是早期多词典版本。后面修性能,追的就是这个版本和开源单词典 IK 基线之间的差距。
这一步还不能直接确定问题就在分词器。但差距摆在这儿了,得继续往下排。我们先排除了几个常见干扰因素:
refresh_interval- 动态同义词 HTTP 服务
- mapping / settings 不一致
- 网络层和 bulk 客户端本身
采样结果很快把范围收窄了。Elasticsearch 那边热点比较分散,Easysearch 这边呢,分词链路里出现了异常集中的开销——分词过程中反复做词典选择和字典查找。
瓶颈不在 Lucene 写入链路本身,就在 analysis-ik 的多词典实现上。
根因分析
第一类问题出在实现模型上。多词典想表达的是”这个字段最终用哪套词典”,这件事完全可以在分词前算好。但早期代码里,硬是把它变成了运行时的事:
- “字段用哪个词典”变成了”运行时多轮扫描”——同一段文本对着多套词典各来一遍。
- 全局字典切换的动作放进了每字符的热路径。
- 结果就是同一段文本的扫描和查找成本翻了好几倍。
所以问题不是多词典天然慢,是实现把本该提前算好的东西塞进了热路径反复做。
第二类问题是后续优化过程中留下的额外开销。后面加的跨边界、停用词、长文本等测试本身不是性能问题的来源,它们的作用是把正确性边界补齐,确保每次优化不会改变分词结果。
最后通过性能分析确认,残留开销主要来自两处:缓存命中前还在做不必要的数据复制;诊断逻辑在生产热路径上产生了额外开销。修完之后这两处热点都从火焰图上消失了,说明性能回退确实来自真实的代码路径成本,不是测试抖动。
修复过程
整个修复分四个阶段。
第一阶段:把多词典从”运行时分发”收敛为”最终有效词典视图”
多词典能力保留,但不再让分词器在热路径里反复切词典、重复扫文本。改成在分词前就把字段最终生效的词典算好,分词过程只面对一个已经收敛好的词典视图。
说白了就是把模型拉回正确方向——多词典管表达能力,热路径只管分词。
第二阶段:逐步打掉热路径上的常数开销
留下来的每一项优化,都经过正式性能测试和采样分析验证。原则就一条:不改分词语义,只减少热路径上反复发生的查找、分配和判断。
第三阶段:补齐正确性护栏
正确性测试必须先到位,不然吞吐提升没有意义——万一分词结果变了,跑得再快也白搭。
这一轮重点覆盖了这些容易出问题的场景:
- 真跨边界场景
- 数字和量词合并,如
1号 - 自定义词典里的含符号词
- 补充平面字符跨边界稳定性
- 停用词过滤后的偏移量
- 长文本样本的稳定性
- 正式性能测试数据集的分词结果对齐
后面所有的吞吐数字,前提都是分词结果一致,避免把分词行为的变化误当成性能提升。
第四阶段:清理最后的残留开销
到 4 月 28 号,最后一轮修复集中处理两个地方:
- 词典视图命中缓存时直接返回,不再多做一次数据复制
- 诊断逻辑默认关掉,不让线上请求为调试能力买单
这两处修完,Easysearch 版 IK 就不只是恢复到单词典版本附近了,在正式测试里已经明显领先。
用数据看恢复过程
为了不把系统级写入压测和分词器性能测试混在一起,下面只看几个关键节点。2026-04-20 的 docs/s 是系统级写入吞吐,后面的 tok/s 是单独的分词器吞吐。
这里说的”开源 IK 基线”就是开源 IK 的单词典实现对照版本。所有正式吞吐结论都建立在同一数据集、同一测试方法、分词结果一致的前提上。
| 时间 | 口径 | 关键结果 | 说明 |
|---|---|---|---|
| 2026-04-23 17:02 CST | 初期本地复现 | 服务器多词典版本 61.39 万 tok/s,单词典版本 114.48 万 tok/s |
单词典版本快 86.49%,性能差距被明确复现 |
| 2026-04-24 09:51:12~09:55:15 CST | 第一次正式追平 | smart 相对开源单词典基线 +7.26% |
从明显落后追到略微领先 |
| 2026-04-25 04:14~04:16 CST | 双模式阶段复核 | smart +16.88%,max_word +20.09% |
领先优势开始扩大 |
| 2026-04-28 12:30:56 CST | 最新正式复核 | smart +30.96%,max_word +21.31% |
当前最新结果 |
整个过程就是:
- 先暴露出明显的性能退化
- 逐步缩小差距
- 追平,然后开始领先
- 最终在分词结果完全一致的前提下,正式反超
最早的本地复现数据很关键:服务器当时跑的多词典版本只有 613896.67 tok/s,单词典版本 1144843.77 tok/s。后面所有修复就是冲着这个差距去的。
三张图分别对应问题暴露、分词复现和修复结果:第一张展示服务器 bulk 写入吞吐的系统级差距;第二张展示多词典版本和单词典版本的本地分词差距;第三张展示分词结果对齐后,Easysearch 版 IK 怎么一步步追上来,最终实现 25%~30% 的分词性能提升。
为什么说 Easysearch 版 IK 现在更好
这次修复的价值不只是消灭了几个热点,更重要的是把多词典能力、分词正确性和性能测试体系一起补齐了。
1. 功能更强,性能代价可控
开源单词典 IK 模型简单,但表达能力也弱。Easysearch 的多词典能力要解决的是字段级词库隔离、自定义词典叠加这些实际需求。
关键问题是:能不能把这些能力的性能开销压到足够低。修复后的结果证明,可以。
2. 正确性护栏更完整
这轮补上的测试不只是几个短样例,覆盖了更容易翻车的边界条件:
- 真跨边界场景
- 长文本稳定性
- 自定义词典和符号词
- 数字量词合并
- 停用词过滤后的偏移量
这意味着以后再做性能优化,必须同时保证分词结果不变。想靠改分词行为换吞吐,测试会先拦住。
3. 性能测试体系更严格
这轮之后,Easysearch 对 analysis-ik 的正式性能结论统一按一套标准出:
- 同一数据集
- 同一测试方法
smart和max_word双模式- 分词结果一致
- 有性能分析结果支撑
这套体系能避免两个常见坑:只看单轮吞吐波动就下结论,或者分词结果已经变了还在比性能。
小结
多词典能力在实现初期,主要精力放在功能补齐上——先把字段级词库隔离、自定义词典叠加这些能力跑通,性能优化是后面分阶段来的事,没办法一蹴而就。
这轮优化下来,核心思路其实就一条:把词典选择从分词热路径里挪出去,提前收敛好,让分词过程只面对最终的词典视图。再配合热点清理和正确性护栏,增强功能和更高性能完全可以兼得。
截至 2026 年 4 月 28 日,在本地 Mac 笔记本上的多轮 benchmark 中,Easysearch 版 IK 在 smart 模式大约领先开源单词典 IK 基线 25%~30%,max_word 模式大约领先 20% 左右,分词结果完全一致。具体数字每次跑会有波动,但趋势是稳定的。
这也是 Easysearch 版 IK 相对开源版更有价值的地方:不是多了几个配置项,而是在多词典能力、分词正确性和分词性能三个方面都给出了可验证的结果。
关于 Easysearch
INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。
作者:张磊,极限科技(INFINI Labs)搜索引擎研发负责人,对 Elasticsearch 和 Lucene 源码比较熟悉,目前主要负责公司的 Easysearch 产品的研发以及客户服务工作。
相关文章:
收起阅读 »【搜索客社区日报】第2227期 (2026-05-08)
https://my.oschina.net/u/4939618/blog/19654121
2、Elasticsearch 实战 | CPU 在摸鱼,查询在搬砖:一行配置性能暴涨 6 倍
https://mp.weixin.qq.com/s/2HNbW22Zyoe8llWcYiy5Uw
3、告别命令行!Easysearch 全新图形化部署体验实战详解
https://mp.weixin.qq.com/s/9i7HrtAq7CphRLvsvcrt4Q
4、如何衡量和提升 Elasticsearch 搜索召回率:通过 混合搜索 从 0.43 提升到 0.75
https://elasticstack.blog.csdn ... 85695
5、Elasticsearch ES|QL 视图:一个查询统领十二个仪表板
https://elasticstack.blog.csdn ... 08168
编辑:Fred
更多资讯:http://news.searchkit.cn
https://my.oschina.net/u/4939618/blog/19654121
2、Elasticsearch 实战 | CPU 在摸鱼,查询在搬砖:一行配置性能暴涨 6 倍
https://mp.weixin.qq.com/s/2HNbW22Zyoe8llWcYiy5Uw
3、告别命令行!Easysearch 全新图形化部署体验实战详解
https://mp.weixin.qq.com/s/9i7HrtAq7CphRLvsvcrt4Q
4、如何衡量和提升 Elasticsearch 搜索召回率:通过 混合搜索 从 0.43 提升到 0.75
https://elasticstack.blog.csdn ... 85695
5、Elasticsearch ES|QL 视图:一个查询统领十二个仪表板
https://elasticstack.blog.csdn ... 08168
编辑:Fred
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2226期 (2026-04-29)
https://blog.csdn.net/UbuntuTo ... 79297
2.手把手教你使 AWS OpenSearch 适用于语义搜索(搭梯)
https://medium.com/%40itsprate ... 73ce5
3.DeepSeek V4:一百万个 token,三种思考模式,以及首批真实上手报告(搭梯)
https://medium.com/ai-advances ... cc096
编辑:kin122
更多资讯:http://news.searchkit.cn
https://blog.csdn.net/UbuntuTo ... 79297
2.手把手教你使 AWS OpenSearch 适用于语义搜索(搭梯)
https://medium.com/%40itsprate ... 73ce5
3.DeepSeek V4:一百万个 token,三种思考模式,以及首批真实上手报告(搭梯)
https://medium.com/ai-advances ... cc096
编辑:kin122
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第 2225 期 (2026-04-28)
https://medium.com/%40huntforw ... 8857a
2. 老司机是怎么在银行系统里把事件检测时间从45分钟缩减到5分钟的(需要梯子)
https://medium.com/%40aliakram ... 0f7fb
3. 稀疏向量的上下文排序可解?可以的可以的老铁!(需要梯子)
https://medium.com/adeo-tech/s ... 3eb69
编辑:斯蒂文
更多资讯:[http://news.searchkit.cn](http://news.searchkit.cn/)
https://medium.com/%40huntforw ... 8857a
2. 老司机是怎么在银行系统里把事件检测时间从45分钟缩减到5分钟的(需要梯子)
https://medium.com/%40aliakram ... 0f7fb
3. 稀疏向量的上下文排序可解?可以的可以的老铁!(需要梯子)
https://medium.com/adeo-tech/s ... 3eb69
编辑:斯蒂文
更多资讯:[http://news.searchkit.cn](http://news.searchkit.cn/) 收起阅读 »
Easysearch 正式支持插件开发:让你的搜索系统真正"为你所用"
从"用搜索"到"造搜索"
搜索系统的需求千差万别。标准功能覆盖不了所有场景——行业特定的分词规则、定制化的业务逻辑、与外部系统的深度集成……
以往,这类定制需求需要依赖厂商支持。从 Easysearch 2.1.2 开始,你可以自己动手了。
随着构建依赖库正式发布到 Maven 中央仓库,Easysearch 的插件开发能力正式对外开放。这意味着 Easysearch 不再是一个黑盒产品,而是一个可扩展、可定制的搜索平台。你可以基于官方接口开发自定义插件,像使用原生功能一样使用它们。
插件能做什么
Easysearch 提供三类核心扩展点,覆盖搜索系统的关键环节:
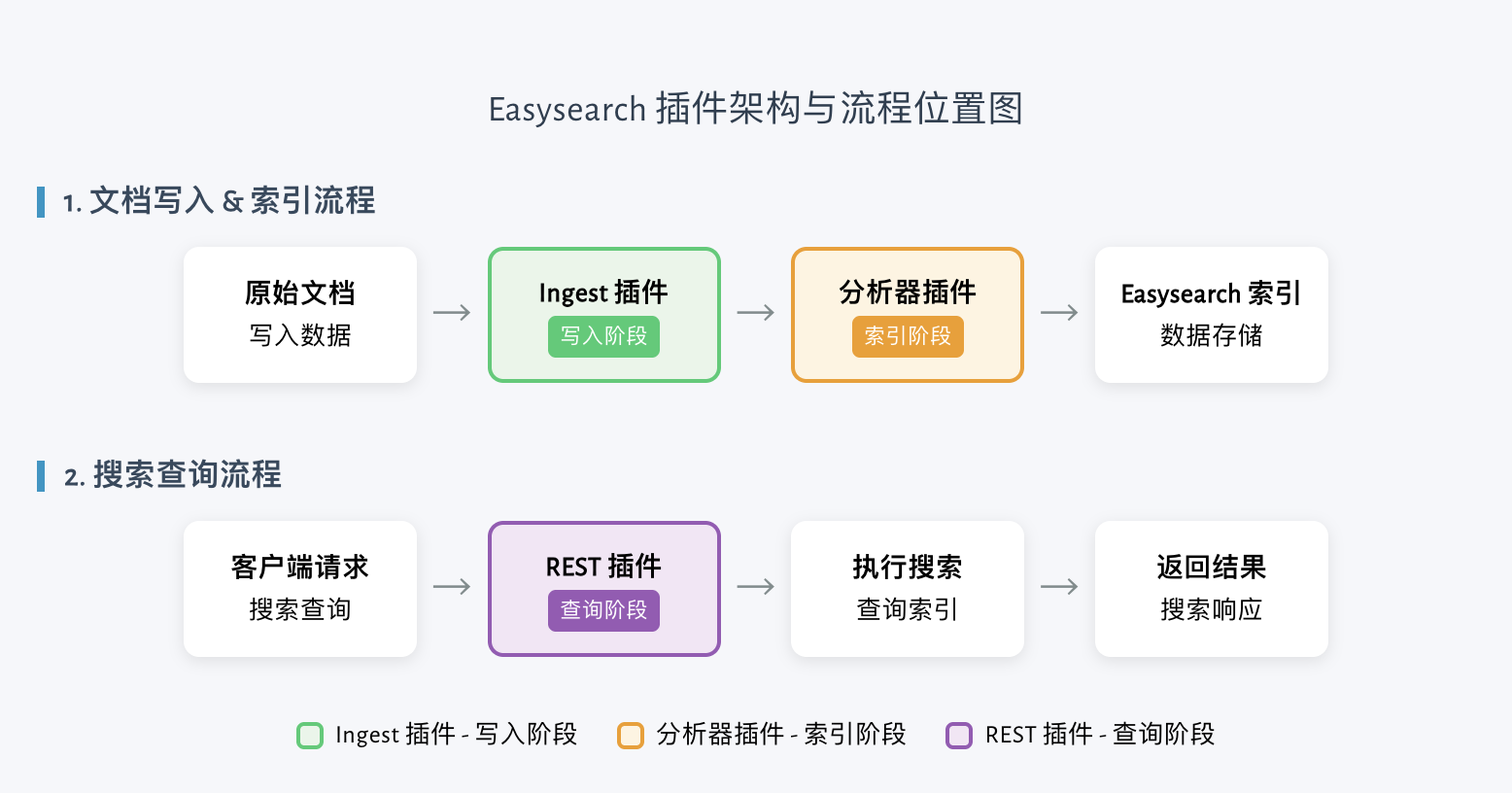
1. 分析器插件(AnalysisPlugin)
自定义分词器、Token 过滤器、字符过滤器。适用于:
- 电商 SKU 的型号规格解析
- 医疗、法律等领域的专业术语分词
- 特殊符号或空格的规范化处理
注册后直接在索引设置中使用,与原生分析器完全等同。

2. REST/API 插件(ActionPlugin)
新增自定义 HTTP 接口。适用于:
- 封装业务查询逻辑,对外暴露简化 API
- 对接企业内部权限中心或监控系统
- 暴露插件自身的管理接口(如状态检查)

3. Ingest 插件(IngestPlugin)
在文档写入前进行字段转换。适用于:
- 自定义业务字段转换(如根据业务规则计算衍生字段)
- 数据标准化(统一日期格式、大小写转换)
- 富文本提取或元数据生成

5 分钟上手
我们准备了官方模板仓库,让你从克隆到运行只需几条命令:
# 克隆模板
git clone https://github.com/infinilabs/easysearch-plugin-template.git my-plugin
cd my-plugin
# 修改包名和类名,编写你的逻辑
# ...方式一:开发调试——直接运行
# 构建插件并运行
./gradlew run
# 验证插件
curl -s "http://localhost:9200/_cat/plugins?v" | grep my-plugin方式二:构建后安装到外部集群
# 构建插件
./gradlew build
# 安装到 Easysearch
bin/easysearch-plugin install file:///$(pwd)/build/distributions/my-plugin-0.1.0.zip
# 启动验证
bin/easysearch
curl -s "http://localhost:9200/_cat/plugins?v" | grep my-plugin完整的开发指南请参考插件开发文档。
设计哲学
Easysearch 插件系统的设计遵循三个原则:
渐进式扩展——从最简单的 Plugin 类开始,按需实现 AnalysisPlugin、ActionPlugin 等接口,不必一次性掌握全部 API。
与原生同等——插件注册的分析器、处理器与系统原生组件在使用方式上完全一致,用户无需关心实现来源。
版本安全——插件加载时校验 easysearch.version,版本不匹配会拒绝加载,避免运行时异常。
从插件到生态
插件开发不只是技术能力的开放,更是产品理念的转变。
你可以将开发的插件发布到 GitHub Releases,通过 URL 直接安装:

bin/easysearch-plugin install https://github.com/yourname/my-plugin/releases/download/v0.1.0/my-plugin-0.1.0.zip我们也欢迎社区贡献。如果你有通用的插件想法,欢迎与我们交流。
结语
搜索系统的最后一公里,只有业务开发者最清楚该怎么走。
Easysearch 2.1.2 的插件开发能力,让你能够自主掌控搜索系统的"最后一公里"。从"用搜索"到"造搜索",现在你可以让你的搜索系统真正"为你所用"。
关于 Easysearch
INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。
从"用搜索"到"造搜索"
搜索系统的需求千差万别。标准功能覆盖不了所有场景——行业特定的分词规则、定制化的业务逻辑、与外部系统的深度集成……
以往,这类定制需求需要依赖厂商支持。从 Easysearch 2.1.2 开始,你可以自己动手了。
随着构建依赖库正式发布到 Maven 中央仓库,Easysearch 的插件开发能力正式对外开放。这意味着 Easysearch 不再是一个黑盒产品,而是一个可扩展、可定制的搜索平台。你可以基于官方接口开发自定义插件,像使用原生功能一样使用它们。
插件能做什么
Easysearch 提供三类核心扩展点,覆盖搜索系统的关键环节:
1. 分析器插件(AnalysisPlugin)
自定义分词器、Token 过滤器、字符过滤器。适用于:
- 电商 SKU 的型号规格解析
- 医疗、法律等领域的专业术语分词
- 特殊符号或空格的规范化处理
注册后直接在索引设置中使用,与原生分析器完全等同。
2. REST/API 插件(ActionPlugin)
新增自定义 HTTP 接口。适用于:
- 封装业务查询逻辑,对外暴露简化 API
- 对接企业内部权限中心或监控系统
- 暴露插件自身的管理接口(如状态检查)
3. Ingest 插件(IngestPlugin)
在文档写入前进行字段转换。适用于:
- 自定义业务字段转换(如根据业务规则计算衍生字段)
- 数据标准化(统一日期格式、大小写转换)
- 富文本提取或元数据生成
5 分钟上手
我们准备了官方模板仓库,让你从克隆到运行只需几条命令:
# 克隆模板
git clone https://github.com/infinilabs/easysearch-plugin-template.git my-plugin
cd my-plugin
# 修改包名和类名,编写你的逻辑
# ...方式一:开发调试——直接运行
# 构建插件并运行
./gradlew run
# 验证插件
curl -s "http://localhost:9200/_cat/plugins?v" | grep my-plugin方式二:构建后安装到外部集群
# 构建插件
./gradlew build
# 安装到 Easysearch
bin/easysearch-plugin install file:///$(pwd)/build/distributions/my-plugin-0.1.0.zip
# 启动验证
bin/easysearch
curl -s "http://localhost:9200/_cat/plugins?v" | grep my-plugin完整的开发指南请参考插件开发文档。
设计哲学
Easysearch 插件系统的设计遵循三个原则:
渐进式扩展——从最简单的 Plugin 类开始,按需实现 AnalysisPlugin、ActionPlugin 等接口,不必一次性掌握全部 API。
与原生同等——插件注册的分析器、处理器与系统原生组件在使用方式上完全一致,用户无需关心实现来源。
版本安全——插件加载时校验 easysearch.version,版本不匹配会拒绝加载,避免运行时异常。
从插件到生态
插件开发不只是技术能力的开放,更是产品理念的转变。
你可以将开发的插件发布到 GitHub Releases,通过 URL 直接安装:
bin/easysearch-plugin install https://github.com/yourname/my-plugin/releases/download/v0.1.0/my-plugin-0.1.0.zip我们也欢迎社区贡献。如果你有通用的插件想法,欢迎与我们交流。
结语
搜索系统的最后一公里,只有业务开发者最清楚该怎么走。
Easysearch 2.1.2 的插件开发能力,让你能够自主掌控搜索系统的"最后一公里"。从"用搜索"到"造搜索",现在你可以让你的搜索系统真正"为你所用"。
关于 Easysearch
INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。
收起阅读 »【搜索客社区日报】第2224期 (2026-04-27)
https://infinilabs.cn/blog/2026/mem0-integration/
2、在 Discover 中探索来自新的时间序列数据流的指标
https://elasticstack.blog.csdn ... 28187
3、来自字节跳动TRAE的Harness Engineering指南
https://mp.weixin.qq.com/s/xBNtHjseMomMA-aOQyOrJg
4、深度解析 Hermes Agent 如何实现“自进化”及其 Prompt / Context / Harness 的设计实践
https://mp.weixin.qq.com/s/2xFei8dMx99lc-iyrZZrww
5、在 Elastic Cloud Serverless 中引入跨项目搜索
https://elasticstack.blog.csdn ... 56142
编辑:Muse
更多资讯:http://news.searchkit.cn
https://infinilabs.cn/blog/2026/mem0-integration/
2、在 Discover 中探索来自新的时间序列数据流的指标
https://elasticstack.blog.csdn ... 28187
3、来自字节跳动TRAE的Harness Engineering指南
https://mp.weixin.qq.com/s/xBNtHjseMomMA-aOQyOrJg
4、深度解析 Hermes Agent 如何实现“自进化”及其 Prompt / Context / Harness 的设计实践
https://mp.weixin.qq.com/s/2xFei8dMx99lc-iyrZZrww
5、在 Elastic Cloud Serverless 中引入跨项目搜索
https://elasticstack.blog.csdn ... 56142
编辑:Muse
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2223期 (2026-04-24)
http://www.jingji.com.cn/zxxx/ ... shtml
2、Elasticsearch 实战 | 别再无脑扩容了!Logstash S3插件的临时文件泄漏,一行代码就能修
https://mp.weixin.qq.com/s/Z-btZI1xUetiAf01jeyoeA
3、CubeGraph:面向时空数据的高效检索增强生成
https://mp.weixin.qq.com/s/55x5m1m007ZDAlyfBRKdHA
编辑:Fred
更多资讯:http://news.searchkit.cn
http://www.jingji.com.cn/zxxx/ ... shtml
2、Elasticsearch 实战 | 别再无脑扩容了!Logstash S3插件的临时文件泄漏,一行代码就能修
https://mp.weixin.qq.com/s/Z-btZI1xUetiAf01jeyoeA
3、CubeGraph:面向时空数据的高效检索增强生成
https://mp.weixin.qq.com/s/55x5m1m007ZDAlyfBRKdHA
编辑:Fred
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2222期 (2026-04-23)
https://mp.weixin.qq.com/s/93SsY__dxtsUPXhAPsjHCA
2.Kimi K2.6 + Hermes 实测!Karpathy同款保姆级教程来了
https://mp.weixin.qq.com/s/2YsgaHJmOsAuq8tDFlEOvg
3.从零开始理解大模型系列教程
https://mp.weixin.qq.com/s/PA35Fmd2CqyDWV__B-BtwA
编辑:Se7en
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/93SsY__dxtsUPXhAPsjHCA
2.Kimi K2.6 + Hermes 实测!Karpathy同款保姆级教程来了
https://mp.weixin.qq.com/s/2YsgaHJmOsAuq8tDFlEOvg
3.从零开始理解大模型系列教程
https://mp.weixin.qq.com/s/PA35Fmd2CqyDWV__B-BtwA
编辑:Se7en
更多资讯:http://news.searchkit.cn 收起阅读 »
INFINI Agent v1.31.0 发布 | 全新 Easysearch 向导:一站式集群拉起与精细化管理

INFINI Agent v1.31.0 带来了本版本最重要的特性——Easysearch 安装向导。用户无需手动编辑任何配置文件,通过图形界面即可完成 Easysearch 集群的安装、配置和日常管理。
Easysearch 安装向导
一键拉起新集群
向导支持开发模式和生产模式两种方式创建 Easysearch 节点。用户只需填写集群名称、节点名称、监听地址、端口、数据目录等基本信息,向导便会自动完成软件下载、JDK 配置、安全证书生成、参数配置、插件安装、节点启动等全部步骤,并实时展示每一步的进度,支持随时暂停和恢复。

一键加入已有集群
通过粘贴现有集群提供的 Token,向导可自动从目标集群拉取证书、版本、插件等配置信息,完成新节点的安装和接入,全程无需手动复制任何证书文件。


安装前环境预检
向导在开始安装前会对当前机器进行全面检测,帮助用户提前发现潜在问题:
- 操作系统和 CPU 架构是否受支持
- 内存是否满足推荐要求
- 端口是否已被占用
- 数据目录磁盘空间是否充足、路径是否可写
- 系统参数(文件描述符限制、内核
max_map_count等)是否满足 Easysearch 运行需求 - TLS 证书填写后实时校验有效性,包括证书链完整性和过期时间

TLS 安全证书灵活配置
支持三种证书配置方式,满足不同安全需求:
- 自动生成:向导一键生成自签名证书,无需任何证书知识
- 手动上传(共享):为 HTTP 和节点通信层提供同一套证书
- 手动上传(分离):为 HTTP 层和节点通信层分别提供独立证书

完整的服务生命周期管理
集群建好后,向导提供持续的管理能力:
- 启动、停止、重启 Easysearch 节点

- 在线安装和卸载插件

- 在线编辑配置,包括
easysearch.yml、JVM 参数、日志配置、证书配置

- 在线日志排查:内置日志阅读器,支持查看节点日志文件列表,并提供类似 tail -f 的自动滚动功能,无需登录服务器即可快速定位报错。”

网络受限环境支持
针对无法直接访问外网的环境,向导支持配置 HTTP 代理,所有软件包(Easysearch、JDK、插件)均可通过代理下载,并提供连通性测试功能。

获取新版本
INFINI Agent v1.31.0 已正式发布,欢迎升级体验:
INFINI Agent v1.31.0 带来了本版本最重要的特性——Easysearch 安装向导。用户无需手动编辑任何配置文件,通过图形界面即可完成 Easysearch 集群的安装、配置和日常管理。
Easysearch 安装向导
一键拉起新集群
向导支持开发模式和生产模式两种方式创建 Easysearch 节点。用户只需填写集群名称、节点名称、监听地址、端口、数据目录等基本信息,向导便会自动完成软件下载、JDK 配置、安全证书生成、参数配置、插件安装、节点启动等全部步骤,并实时展示每一步的进度,支持随时暂停和恢复。
一键加入已有集群
通过粘贴现有集群提供的 Token,向导可自动从目标集群拉取证书、版本、插件等配置信息,完成新节点的安装和接入,全程无需手动复制任何证书文件。
安装前环境预检
向导在开始安装前会对当前机器进行全面检测,帮助用户提前发现潜在问题:
- 操作系统和 CPU 架构是否受支持
- 内存是否满足推荐要求
- 端口是否已被占用
- 数据目录磁盘空间是否充足、路径是否可写
- 系统参数(文件描述符限制、内核
max_map_count等)是否满足 Easysearch 运行需求 - TLS 证书填写后实时校验有效性,包括证书链完整性和过期时间
TLS 安全证书灵活配置
支持三种证书配置方式,满足不同安全需求:
- 自动生成:向导一键生成自签名证书,无需任何证书知识
- 手动上传(共享):为 HTTP 和节点通信层提供同一套证书
- 手动上传(分离):为 HTTP 层和节点通信层分别提供独立证书
完整的服务生命周期管理
集群建好后,向导提供持续的管理能力:
- 启动、停止、重启 Easysearch 节点
- 在线安装和卸载插件
- 在线编辑配置,包括
easysearch.yml、JVM 参数、日志配置、证书配置
- 在线日志排查:内置日志阅读器,支持查看节点日志文件列表,并提供类似 tail -f 的自动滚动功能,无需登录服务器即可快速定位报错。”
网络受限环境支持
针对无法直接访问外网的环境,向导支持配置 HTTP 代理,所有软件包(Easysearch、JDK、插件)均可通过代理下载,并提供连通性测试功能。
获取新版本
INFINI Agent v1.31.0 已正式发布,欢迎升级体验:
收起阅读 »【搜索客社区日报】第2221期 (2026-04-22)
https://mp.weixin.qq.com/s/k2HHfziaAoQUF_FVWfrRMg
2.斯坦福李飞飞团队实锤:GPT-5、Gemini、Claude根本没在「看图」!拔掉图片照样拿80%高分,30亿小模型吊打所有视觉大模型
https://mp.weixin.qq.com/s/yoOoNDC0DiJ0SgPdTr9n0Q
3.Prometheus Remote Write 在 Elasticsearch 中的摄取原理
https://blog.csdn.net/UbuntuTo ... 71770
编辑:kin122
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/k2HHfziaAoQUF_FVWfrRMg
2.斯坦福李飞飞团队实锤:GPT-5、Gemini、Claude根本没在「看图」!拔掉图片照样拿80%高分,30亿小模型吊打所有视觉大模型
https://mp.weixin.qq.com/s/yoOoNDC0DiJ0SgPdTr9n0Q
3.Prometheus Remote Write 在 Elasticsearch 中的摄取原理
https://blog.csdn.net/UbuntuTo ... 71770
编辑:kin122
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第 2220 期 (2026-04-21)
https://medium.com/%40rosgluk/ ... 29dc0
2. AWS OpenSearch TLS 升级生存指南(需要梯子)
https://aws.plainenglish.io/su ... b5811
3. starrocks在实时分析领域比es强,你同意吗?(需要梯子)
https://medium.com/%40indomita ... e5eae
编辑:斯蒂文
更多资讯:[http://news.searchkit.cn](http://news.searchkit.cn/)
https://medium.com/%40rosgluk/ ... 29dc0
2. AWS OpenSearch TLS 升级生存指南(需要梯子)
https://aws.plainenglish.io/su ... b5811
3. starrocks在实时分析领域比es强,你同意吗?(需要梯子)
https://medium.com/%40indomita ... e5eae
编辑:斯蒂文
更多资讯:[http://news.searchkit.cn](http://news.searchkit.cn/)
收起阅读 »
【搜索客社区日报】第2219期 (2026-04-20)
https://elasticstack.blog.csdn ... 32467
2. Streams 如何在几秒内生成日志管道
https://elasticstack.blog.csdn ... 47967
3. 深度解析 OpenClaw 在 Prompt / Context / Harness 三个维度中的设计哲学与实践
https://mp.weixin.qq.com/s/JycTfNd7EnmWCnJK-QCf0Q
4. 一文搞懂Hermes:新顶流Agent如何从经验中自我进化
https://mp.weixin.qq.com/s/yHva-zLaRTxe8b4HSUr86Q
5. 从 Vibe Coding 到范式编程:用 Spec 打造淘系交易的 AI 领域专家
https://mp.weixin.qq.com/s/s4IVundC5cj61iY8rahA0A
编辑:Muse
更多资讯:http://news.searchkit.cn
https://elasticstack.blog.csdn ... 32467
2. Streams 如何在几秒内生成日志管道
https://elasticstack.blog.csdn ... 47967
3. 深度解析 OpenClaw 在 Prompt / Context / Harness 三个维度中的设计哲学与实践
https://mp.weixin.qq.com/s/JycTfNd7EnmWCnJK-QCf0Q
4. 一文搞懂Hermes:新顶流Agent如何从经验中自我进化
https://mp.weixin.qq.com/s/yHva-zLaRTxe8b4HSUr86Q
5. 从 Vibe Coding 到范式编程:用 Spec 打造淘系交易的 AI 领域专家
https://mp.weixin.qq.com/s/s4IVundC5cj61iY8rahA0A
编辑:Muse
更多资讯:http://news.searchkit.cn 收起阅读 »


