

【搜索客社区日报】第1903期 (2024-09-20)
https://opensearch.org/blog/Ho ... arch/
2、一网打尽!处理 Elasticsearch 中未分配的分片问题(附完整 DSL 示例)
https://mp.weixin.qq.com/s/NUyQk_2LUITJG19YXf1WoQ
3、【老杨玩搜索】2. Easysearch 增删改查 | 从零开始实现页面搜索功能
https://www.bilibili.com/video/BV12M4m1S7H4/
4、RankRAG指令微调框架:让LLM在检索增强任务中更高效
https://mp.weixin.qq.com/s/FqUNHygaCIuQmeLxYRqyHw
5、编程语言之争:Rust 社区活跃开发者 Ed Page 谈 Rust 与 C++ 的未来
https://blog.csdn.net/GOSIM202 ... 36175
编辑:Fred
更多资讯:http://news.searchkit.cn
https://opensearch.org/blog/Ho ... arch/
2、一网打尽!处理 Elasticsearch 中未分配的分片问题(附完整 DSL 示例)
https://mp.weixin.qq.com/s/NUyQk_2LUITJG19YXf1WoQ
3、【老杨玩搜索】2. Easysearch 增删改查 | 从零开始实现页面搜索功能
https://www.bilibili.com/video/BV12M4m1S7H4/
4、RankRAG指令微调框架:让LLM在检索增强任务中更高效
https://mp.weixin.qq.com/s/FqUNHygaCIuQmeLxYRqyHw
5、编程语言之争:Rust 社区活跃开发者 Ed Page 谈 Rust 与 C++ 的未来
https://blog.csdn.net/GOSIM202 ... 36175
编辑:Fred
更多资讯:http://news.searchkit.cn 收起阅读 »
【第4期】搜索客 Meetup | INFINI Pizza 网站 SVG 动画这么炫,我教你啊!
本次 Meetup 活动由 搜索客社区、极限科技(INFINI Labs)联合举办,活动主题将从设计师的角度出发,探讨如何在零编程基础下,借助 ChatGPT 和 SVG,搞定 INFINI Pizza 首页动效,从设计到实现,探索 AI 的更多玩法。欢迎大家预约报名参加和交流。
活动主题:INFINI Pizza 网站 SVG 动画这么炫,我教你啊!
活动时间:2024 年 9 月 25 日 19:00-20:00(周三)
活动形式:微信视频号(极限实验室)直播
报名方式:关注或扫码海报中的二维码进行预约

嘉宾介绍
邹稳安,拥有多年 UI/UE 设计经验。现任极限科技设计团队负责人,负责公司产品、UI 设计,致力于通过设计提升用户体验。
主题摘要
什么?一个设计师,让我干前端的活?
当前端工程师无法及时接手项目时,设计师能否独立完成网页动效?本次 Meetup 将分享设计师如何在零编程基础下,借助 ChatGPT 和 SVG,搞定 INFINI Pizza 首页动效。从设计到实现,探索 AI 的更多玩法。

图:Pizza 官网(https://pizza.rs)首页动画效果
参与有奖
本次直播活动将设有福袋抽奖环节,参与就有机会获得 INFINI Labs 周边纪念品,包括 T 恤、鸭舌帽、咖啡杯、指甲刀套件等等(图片仅供参考,款式、颜色与尺码随机)。

活动交流
本活动设有 Meetup 技术交流群,可添加小助手微信拉群,与更多小伙伴一起学习交流。

Meetup 讲师招募

搜索客社区 Meetup 的成功举办,离不开社区小伙伴的热情参与。目前社区讲师招募计划也在持续进行中,我们诚挚邀请各位技术大咖、行业精英踊跃提交演讲议题,与大家分享您的经验。
讲师报名链接:http://cfp.searchkit.cn
或扫描下方二维码,立刻报名成为讲师!

Meetup 活动聚焦 AI 与搜索领域的最新动态,以及数据实时搜索分析、向量检索、技术实践与案例分析、日志分析、安全等领域的深度探讨。
我们热切期待您的精彩分享!
往期回顾
- 【第 3 期】搜索客 Meetup | Elasticsearch 的代码结构和写入查询流程的解读 - 下篇
- 【第 2 期】搜索客 Meetup | Elasticsearch 的代码结构和写入查询流程的解读 - 上篇
- 【第 1 期】搜索客 Meetup | Easysearch 结合大模型实现 RAG
关于 搜索客(SearchKit)社区
搜索客社区由 Elasticsearch 中文社区进行全新的品牌升级,以新的 Slogan:“搜索人自己的社区” 为宣言。汇集搜索领域最新动态、精选干货文章、精华讨论、文档资料、翻译与版本发布等,为广大搜索领域从业者提供更为丰富便捷的学习和交流平台。
社区官网:https://searchkit.cn 。
本次 Meetup 活动由 搜索客社区、极限科技(INFINI Labs)联合举办,活动主题将从设计师的角度出发,探讨如何在零编程基础下,借助 ChatGPT 和 SVG,搞定 INFINI Pizza 首页动效,从设计到实现,探索 AI 的更多玩法。欢迎大家预约报名参加和交流。
活动主题:INFINI Pizza 网站 SVG 动画这么炫,我教你啊!
活动时间:2024 年 9 月 25 日 19:00-20:00(周三)
活动形式:微信视频号(极限实验室)直播
报名方式:关注或扫码海报中的二维码进行预约
嘉宾介绍
邹稳安,拥有多年 UI/UE 设计经验。现任极限科技设计团队负责人,负责公司产品、UI 设计,致力于通过设计提升用户体验。
主题摘要
什么?一个设计师,让我干前端的活?
当前端工程师无法及时接手项目时,设计师能否独立完成网页动效?本次 Meetup 将分享设计师如何在零编程基础下,借助 ChatGPT 和 SVG,搞定 INFINI Pizza 首页动效。从设计到实现,探索 AI 的更多玩法。
图:Pizza 官网(https://pizza.rs)首页动画效果
参与有奖
本次直播活动将设有福袋抽奖环节,参与就有机会获得 INFINI Labs 周边纪念品,包括 T 恤、鸭舌帽、咖啡杯、指甲刀套件等等(图片仅供参考,款式、颜色与尺码随机)。
活动交流
本活动设有 Meetup 技术交流群,可添加小助手微信拉群,与更多小伙伴一起学习交流。
Meetup 讲师招募
搜索客社区 Meetup 的成功举办,离不开社区小伙伴的热情参与。目前社区讲师招募计划也在持续进行中,我们诚挚邀请各位技术大咖、行业精英踊跃提交演讲议题,与大家分享您的经验。
讲师报名链接:http://cfp.searchkit.cn
或扫描下方二维码,立刻报名成为讲师!
Meetup 活动聚焦 AI 与搜索领域的最新动态,以及数据实时搜索分析、向量检索、技术实践与案例分析、日志分析、安全等领域的深度探讨。
我们热切期待您的精彩分享!
往期回顾
- 【第 3 期】搜索客 Meetup | Elasticsearch 的代码结构和写入查询流程的解读 - 下篇
- 【第 2 期】搜索客 Meetup | Elasticsearch 的代码结构和写入查询流程的解读 - 上篇
- 【第 1 期】搜索客 Meetup | Easysearch 结合大模型实现 RAG
关于 搜索客(SearchKit)社区
搜索客社区由 Elasticsearch 中文社区进行全新的品牌升级,以新的 Slogan:“搜索人自己的社区” 为宣言。汇集搜索领域最新动态、精选干货文章、精华讨论、文档资料、翻译与版本发布等,为广大搜索领域从业者提供更为丰富便捷的学习和交流平台。
社区官网:https://searchkit.cn 。
收起阅读 »【搜索客社区日报】第1902期 (2024-09-19)
https://learn.deeplearning.ai/ ... ideos
2.Qwen2.5感觉成了,热泪眼眶
https://mp.weixin.qq.com/s/nGhkIyelt5OdwSUGx7FQcg
3.SiliconCloud上线Flux.1:文生图比肩MJ v6,免费尝鲜
https://mp.weixin.qq.com/s/zyg3wDPMaLPwac_UYjB6uQ
4.如何在MindSearch中集成新的搜索API,全面提升智能搜索能力!https://mp.weixin.qq.com/s/jCe5ii1TO88tEtsYDOYo9w
编辑:Se7en
更多资讯:http://news.searchkit.cn
https://learn.deeplearning.ai/ ... ideos
2.Qwen2.5感觉成了,热泪眼眶
https://mp.weixin.qq.com/s/nGhkIyelt5OdwSUGx7FQcg
3.SiliconCloud上线Flux.1:文生图比肩MJ v6,免费尝鲜
https://mp.weixin.qq.com/s/zyg3wDPMaLPwac_UYjB6uQ
4.如何在MindSearch中集成新的搜索API,全面提升智能搜索能力!https://mp.weixin.qq.com/s/jCe5ii1TO88tEtsYDOYo9w
编辑:Se7en
更多资讯:http://news.searchkit.cn 收起阅读 »
【第3期】INFINI Easysearch 免费认证培训开放报名

探索 Easysearch 的无限可能,与 INFINI Labs 共赴搜索技术前沿!
随着数字化转型的加速,搜索技术已成为企业数据洞察的核心。INFINI Labs 作为搜索创新技术的引领者,诚邀所有对 Easysearch 搜索引擎感兴趣的开发者、技术爱好者及合作伙伴,参加我们即将于 2024 年 10 月 19 日至 20 日举办的第 3 期 Easysearch 线上免费培训活动。这不仅是一场知识的盛宴,更是技能提升的加速器,将助您在职业道路上迈出坚实的一步!
活动亮点
- 系统课程,全面深入:从 Easysearch 的基本概念到环境搭建,再到高级功能的实战应用,INFINI Labs 的技术专家将为您带来全面而深入的讲解,确保每位参与者都能收获满满。
- 实战导向,解决痛点:课程设计紧贴实际需求,旨在帮助学员掌握 Easysearch 的核心技术,有效解决工作中的搜索需求和技术难题,让理论知识迅速转化为实践能力。
- 认证证书,助力进阶:后期 INFINI Labs 将推出 Easysearch 认证考试。通过考试的学员将获得官方认证的 Easysearch 证书,为您的职业发展增添强力背书,开启职业生涯的新篇章。
培训时间
2024 年 10 月 19 日至 20 日(周六、周日)共两天,每天具体培训时间:
- 上午 09:30 ~ 11:30
- 下午 14:00 ~ 16:00
培训内容概览
第一阶段:初识 Easysearch
- Easysearch 环境搭建与对比,了解其与 Elasticsearch 的差异;
- 功能初探:身份验证、数据脱敏、权限控制等,全面掌握 Easysearch 的基础功能;
- 容灾技术:兼容性验证、跨集群复制等,确保您的搜索服务稳定可靠;
第二阶段:Easysearch 高阶使用
- 深度探析:性能压测、数据迁移、请求管理等,提升 Easysearch 的使用效率;
- 高级功能:快照管理、可视化看板、告警功能等,让您的搜索服务更加智能;
- 生态集成:Filebeat、Logstash、LangChain 等,轻松实现 Easysearch 与其他工具的集成;
参与方式
本次活动完全免费,名额有限,请尽快报名,同时微信扫码添加小助手进群(培训会议地址将在微信群公布),锁定您的学习席位!
扫码或点击 我要报名

👉 立即行动:不要错过这次提升自我、与行业精英共成长的宝贵机会。让我们相聚云端,共同探索 Easysearch 的无限可能,开启技术进阶的新篇章!
参会提示
- 培训内容涉及动手实践,请务必自备电脑(Windows 系统环境请提前安装好 Linux 虚拟机);
- 请提前在 INFINI Labs 官网下载对应平台最新安装包(INFINI Easysearch、INFINI Gateway、INFINI Console);
- 下载地址:https://infinilabs.cn/download
联系我们
如有任何疑问,欢迎通过微信添加 [小助手:INFINI-Labs] 与我们联系。
INFINI Labs 期待与您相约,共赴这场技术盛宴!
关于 Easysearch

Easysearch 是一个分布式的近实时搜索与分析引擎,基于开源的 Apache Lucene 构建。它旨在提供一个自主可控、轻量级的 Elasticsearch 可替代版本,并不断完善和支持更多的企业级功能。与 Elasticsearch 相比,Easysearch 更注重搜索业务场景的优化,同时保持其产品的简洁与易用性。
详情参见:Easysearch 介绍
关于极限科技(INFINI Labs)

极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
探索 Easysearch 的无限可能,与 INFINI Labs 共赴搜索技术前沿!
随着数字化转型的加速,搜索技术已成为企业数据洞察的核心。INFINI Labs 作为搜索创新技术的引领者,诚邀所有对 Easysearch 搜索引擎感兴趣的开发者、技术爱好者及合作伙伴,参加我们即将于 2024 年 10 月 19 日至 20 日举办的第 3 期 Easysearch 线上免费培训活动。这不仅是一场知识的盛宴,更是技能提升的加速器,将助您在职业道路上迈出坚实的一步!
活动亮点
- 系统课程,全面深入:从 Easysearch 的基本概念到环境搭建,再到高级功能的实战应用,INFINI Labs 的技术专家将为您带来全面而深入的讲解,确保每位参与者都能收获满满。
- 实战导向,解决痛点:课程设计紧贴实际需求,旨在帮助学员掌握 Easysearch 的核心技术,有效解决工作中的搜索需求和技术难题,让理论知识迅速转化为实践能力。
- 认证证书,助力进阶:后期 INFINI Labs 将推出 Easysearch 认证考试。通过考试的学员将获得官方认证的 Easysearch 证书,为您的职业发展增添强力背书,开启职业生涯的新篇章。
培训时间
2024 年 10 月 19 日至 20 日(周六、周日)共两天,每天具体培训时间:
- 上午 09:30 ~ 11:30
- 下午 14:00 ~ 16:00
培训内容概览
第一阶段:初识 Easysearch
- Easysearch 环境搭建与对比,了解其与 Elasticsearch 的差异;
- 功能初探:身份验证、数据脱敏、权限控制等,全面掌握 Easysearch 的基础功能;
- 容灾技术:兼容性验证、跨集群复制等,确保您的搜索服务稳定可靠;
第二阶段:Easysearch 高阶使用
- 深度探析:性能压测、数据迁移、请求管理等,提升 Easysearch 的使用效率;
- 高级功能:快照管理、可视化看板、告警功能等,让您的搜索服务更加智能;
- 生态集成:Filebeat、Logstash、LangChain 等,轻松实现 Easysearch 与其他工具的集成;
参与方式
本次活动完全免费,名额有限,请尽快报名,同时微信扫码添加小助手进群(培训会议地址将在微信群公布),锁定您的学习席位!
扫码或点击 我要报名
👉 立即行动:不要错过这次提升自我、与行业精英共成长的宝贵机会。让我们相聚云端,共同探索 Easysearch 的无限可能,开启技术进阶的新篇章!
参会提示
- 培训内容涉及动手实践,请务必自备电脑(Windows 系统环境请提前安装好 Linux 虚拟机);
- 请提前在 INFINI Labs 官网下载对应平台最新安装包(INFINI Easysearch、INFINI Gateway、INFINI Console);
- 下载地址:https://infinilabs.cn/download
联系我们
如有任何疑问,欢迎通过微信添加 [小助手:INFINI-Labs] 与我们联系。
INFINI Labs 期待与您相约,共赴这场技术盛宴!
关于 Easysearch
Easysearch 是一个分布式的近实时搜索与分析引擎,基于开源的 Apache Lucene 构建。它旨在提供一个自主可控、轻量级的 Elasticsearch 可替代版本,并不断完善和支持更多的企业级功能。与 Elasticsearch 相比,Easysearch 更注重搜索业务场景的优化,同时保持其产品的简洁与易用性。
详情参见:Easysearch 介绍
关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
收起阅读 »【搜索客社区日报】第1901期 (2024-09-13)
https://mp.weixin.qq.com/s/O7JjH182dyIP7bgSaYomBg
2、RankRAG 指令微调框架:让 LLM 在检索增强任务中更高效
https://mp.weixin.qq.com/s/FqUNHygaCIuQmeLxYRqyHw
3、如何用 Scrapy 爬取网站数据并在 Easysearch 中进行存储检索分析
https://mp.weixin.qq.com/s/8M0a3NbLvRJNyAepp1N_hA
4、【老杨玩搜索】1.Easysearch 安装 | 从零开始实现页面搜索功能
https://mp.weixin.qq.com/s/utLpCdaonOjpMucQ-k7CgA
编辑:Fred
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/O7JjH182dyIP7bgSaYomBg
2、RankRAG 指令微调框架:让 LLM 在检索增强任务中更高效
https://mp.weixin.qq.com/s/FqUNHygaCIuQmeLxYRqyHw
3、如何用 Scrapy 爬取网站数据并在 Easysearch 中进行存储检索分析
https://mp.weixin.qq.com/s/8M0a3NbLvRJNyAepp1N_hA
4、【老杨玩搜索】1.Easysearch 安装 | 从零开始实现页面搜索功能
https://mp.weixin.qq.com/s/utLpCdaonOjpMucQ-k7CgA
编辑:Fred
更多资讯:http://news.searchkit.cn 收起阅读 »
如何用 Scrapy 爬取网站数据并在 Easysearch 中进行存储检索分析

做过数据分析和爬虫程序的小伙伴想必对 Scrapy 这个爬虫框架已经很熟悉了。今天给大家介绍下,如何基于 Scrapy 快速编写一个爬虫程序并利用 Easysearch 储存、检索、分析爬取的数据。我们以极限科技的官网 Blog 为数据源(https://infinilabs.cn/blog) ,做下实操演示。
1、安装 scrapy
使用 Scrapy 可以快速构建一个爬虫项目,从目标网站中获取所需的数据,并进行后续的处理和分析。
pip install scrapy
# 新建项目 infini_spiders
scrapy startproject infini_spiders
# 初始化爬虫
cd infini_spiders/spiders
scrapy genspider blog infinilabs.cn2、爬虫编写
编写一个爬虫文件 blog.py ,它会首先访问 start_urls 指定的地址,将结果发给 parse 函数解析。通过这一步解析,我们得到了每一篇博客的地址。然后我们对每个博客的地址发送请求,将结果发给 parse_blog 函数进行解析,在这里才会真正提取每篇博客的 title、tag、url、date、content 内容。
from typing import Any, Iterable
import scrapy
from bs4 import BeautifulSoup
from scrapy.http import Response
class BlogSpider(scrapy.Spider):
name = "blog"
allowed_domains = ["infinilabs.cn"]
start_urls = ["https://infinilabs.cn/blog/"]
def parse(self, response):
links = response.css("div.blogs a")
yield from response.follow_all(links, self.parse_blog)
def parse_blog(self, response):
title = response.xpath('//div[@class="title"]/text()').extract_first()
tags = response.xpath('//div[@class="tags"]/div[@class="tag"]/text()').extract()
url = response.url
author = response.xpath('//div[@class="logo"]/div[@class="name"]//text()').extract_first()
date = response.xpath('//div[@class="date"]/text()').extract_first()
all_text = response.xpath('//p//text() | //h3/text() | //h2/text() | //h4/text() | //ol/li//text()').extract()
content = '\n'.join(all_text)
yield {
'title': title,
'tags': tags,
'url': url,
'author': author,
'date': date,
'content': content
}提取完我们想要的内容后,接下来就要考虑存储了。考虑到要对内容进行检索、分析,接下来我们将内容直接存放到 Easysearch 当中。
3、安装插件
通过安装 ScrapyElasticsearch pipeline 可将 scrapy 爬取的内容存入到 Easysearch 中。
pip install ScrapyElasticSearch修改 scrapy 自带的配置文件 settings.py ,添加以下内容。
ITEM_PIPELINES = {
'scrapyelasticsearch.scrapyelasticsearch.ElasticSearchPipeline': 10
}
ELASTICSEARCH_SERVERS = ['http://192.168.56.3:9210']
ELASTICSEARCH_INDEX = 'scrapy'
ELASTICSEARCH_INDEX_DATE_FORMAT = '%Y-%m-%d'
ELASTICSEARCH_TYPE = '_doc'
ELASTICSEARCH_USERNAME = 'admin'
ELASTICSEARCH_PASSWORD = '9423d1d5345ed6d0db19'ScrapyElasticSearch 会以 bulk 方式写入 Easysearch,每次批量的大小由 scrapyelasticsearch.scrapyelasticsearch.ElasticSearchPipeline 参数控制,大家可自行修改。
在上述配置中,我们会将爬到的数据存放到 scrapy-yyyy-mm-dd 索引中。
4、启动爬虫
在 infini_spiders/spiders 目录下,使用命令启动爬虫。
scrapy crawl blogblog 就是爬虫的名字,对应到 blog.py 里面的 name 变量。运行完成后,就可以去 Easysearch 里查看数据了,当然我们还是使用 Console 进行查看。
5、查看数据
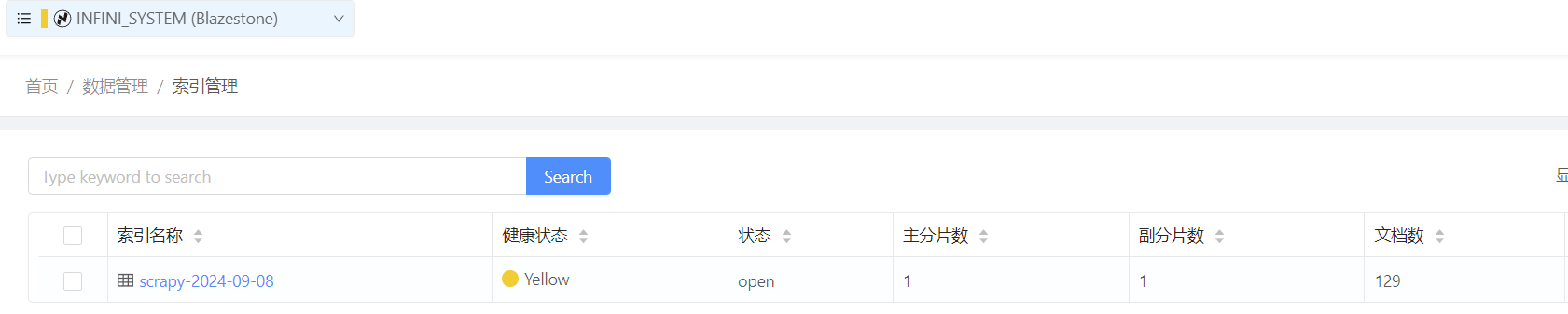
先查看下索引情况,scrapy 索引已经生成,里面有 129 篇博客。
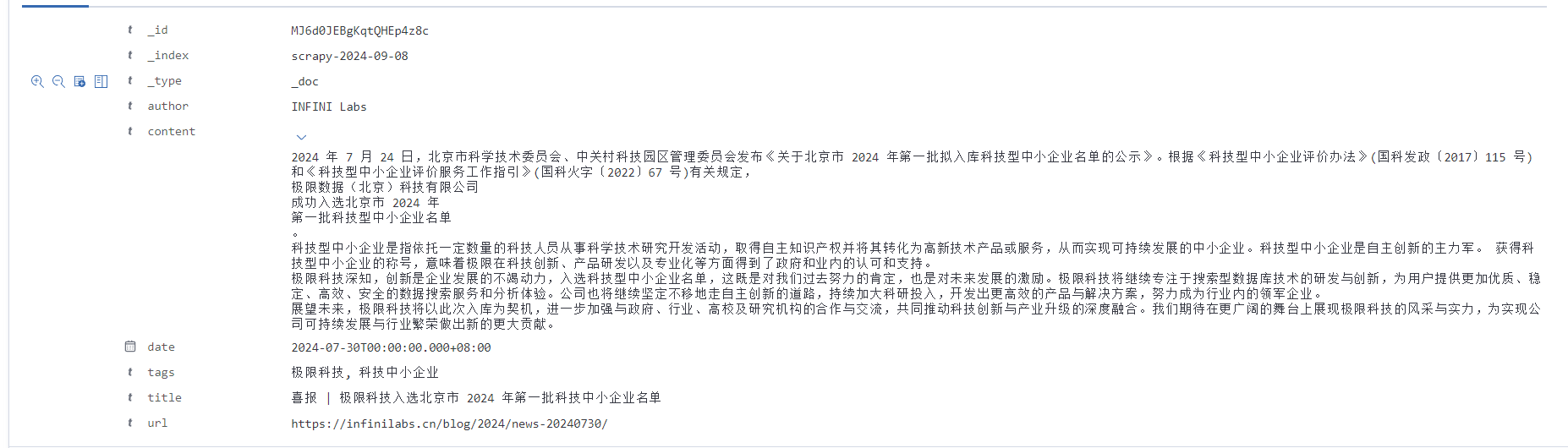
查看详细内容,确保博客正文已经保存。
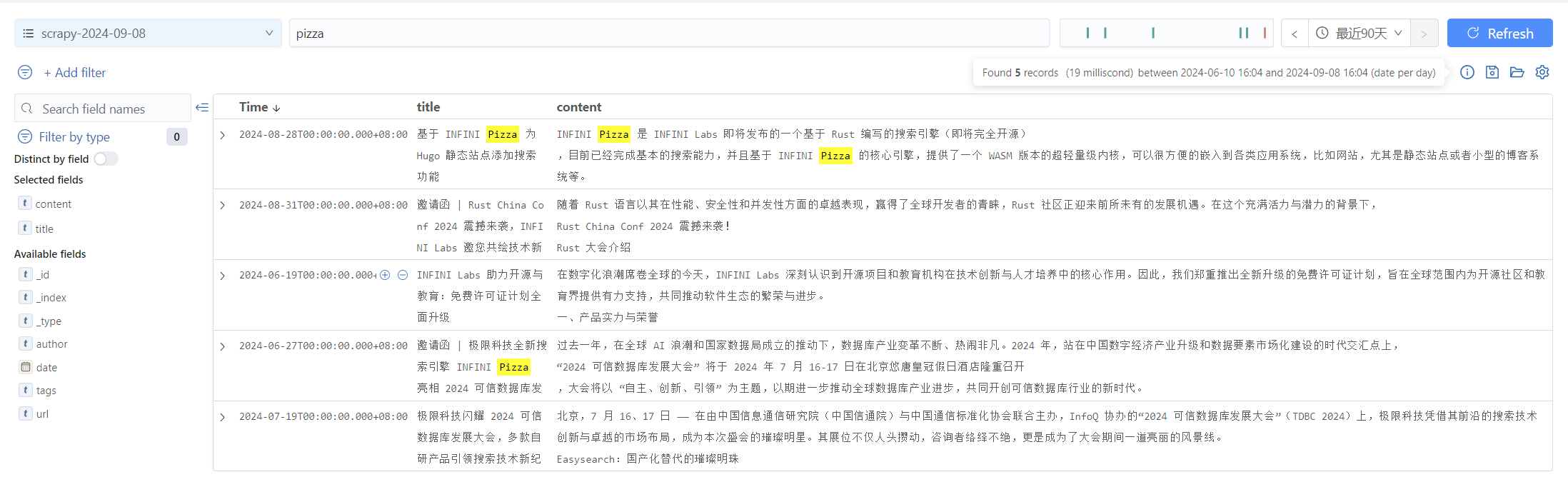
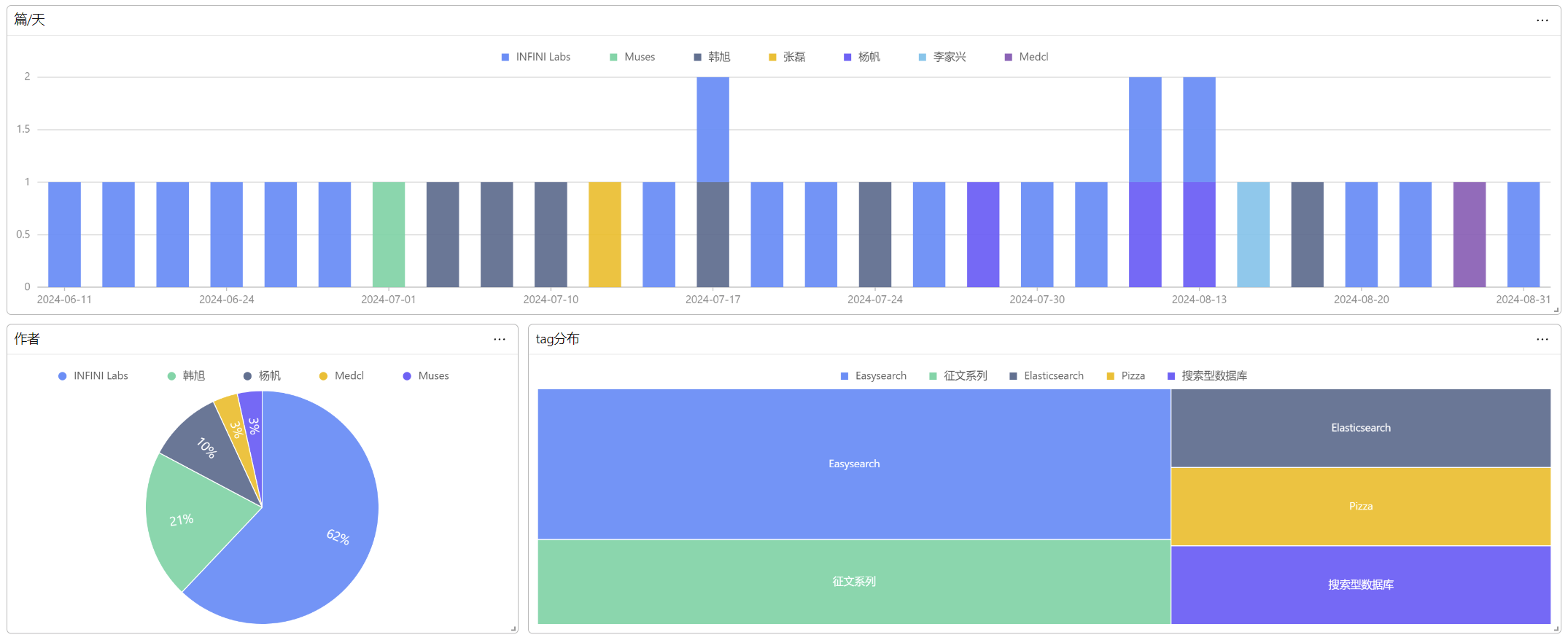
到了这一步,我们就能使用 Console 对博客进行搜索、分析了。
6、结语
这次的分享就到这里了。欢迎与我一起交流 ES 的各种问题和解决方案。

关于 Easysearch
INFINI Easysearch 是一个分布式的近实时搜索与分析引擎,核心引擎基于开源的 Apache Lucene。Easysearch 的目标是提供一个轻量级的 Elasticsearch 可替代版本,并继续完善和支持更多的企业级功能。 与 Elasticsearch 相比,Easysearch 更关注在搜索业务场景的优化和继续保持其产品的简洁与易用性。
官网文档:https://infinilabs.cn/docs/latest/easysearch
做过数据分析和爬虫程序的小伙伴想必对 Scrapy 这个爬虫框架已经很熟悉了。今天给大家介绍下,如何基于 Scrapy 快速编写一个爬虫程序并利用 Easysearch 储存、检索、分析爬取的数据。我们以极限科技的官网 Blog 为数据源(https://infinilabs.cn/blog) ,做下实操演示。
1、安装 scrapy
使用 Scrapy 可以快速构建一个爬虫项目,从目标网站中获取所需的数据,并进行后续的处理和分析。
pip install scrapy
# 新建项目 infini_spiders
scrapy startproject infini_spiders
# 初始化爬虫
cd infini_spiders/spiders
scrapy genspider blog infinilabs.cn2、爬虫编写
编写一个爬虫文件 blog.py ,它会首先访问 start_urls 指定的地址,将结果发给 parse 函数解析。通过这一步解析,我们得到了每一篇博客的地址。然后我们对每个博客的地址发送请求,将结果发给 parse_blog 函数进行解析,在这里才会真正提取每篇博客的 title、tag、url、date、content 内容。
from typing import Any, Iterable
import scrapy
from bs4 import BeautifulSoup
from scrapy.http import Response
class BlogSpider(scrapy.Spider):
name = "blog"
allowed_domains = ["infinilabs.cn"]
start_urls = ["https://infinilabs.cn/blog/"]
def parse(self, response):
links = response.css("div.blogs a")
yield from response.follow_all(links, self.parse_blog)
def parse_blog(self, response):
title = response.xpath('//div[@class="title"]/text()').extract_first()
tags = response.xpath('//div[@class="tags"]/div[@class="tag"]/text()').extract()
url = response.url
author = response.xpath('//div[@class="logo"]/div[@class="name"]//text()').extract_first()
date = response.xpath('//div[@class="date"]/text()').extract_first()
all_text = response.xpath('//p//text() | //h3/text() | //h2/text() | //h4/text() | //ol/li//text()').extract()
content = '\n'.join(all_text)
yield {
'title': title,
'tags': tags,
'url': url,
'author': author,
'date': date,
'content': content
}提取完我们想要的内容后,接下来就要考虑存储了。考虑到要对内容进行检索、分析,接下来我们将内容直接存放到 Easysearch 当中。
3、安装插件
通过安装 ScrapyElasticsearch pipeline 可将 scrapy 爬取的内容存入到 Easysearch 中。
pip install ScrapyElasticSearch修改 scrapy 自带的配置文件 settings.py ,添加以下内容。
ITEM_PIPELINES = {
'scrapyelasticsearch.scrapyelasticsearch.ElasticSearchPipeline': 10
}
ELASTICSEARCH_SERVERS = ['http://192.168.56.3:9210']
ELASTICSEARCH_INDEX = 'scrapy'
ELASTICSEARCH_INDEX_DATE_FORMAT = '%Y-%m-%d'
ELASTICSEARCH_TYPE = '_doc'
ELASTICSEARCH_USERNAME = 'admin'
ELASTICSEARCH_PASSWORD = '9423d1d5345ed6d0db19'ScrapyElasticSearch 会以 bulk 方式写入 Easysearch,每次批量的大小由 scrapyelasticsearch.scrapyelasticsearch.ElasticSearchPipeline 参数控制,大家可自行修改。
在上述配置中,我们会将爬到的数据存放到 scrapy-yyyy-mm-dd 索引中。
4、启动爬虫
在 infini_spiders/spiders 目录下,使用命令启动爬虫。
scrapy crawl blogblog 就是爬虫的名字,对应到 blog.py 里面的 name 变量。运行完成后,就可以去 Easysearch 里查看数据了,当然我们还是使用 Console 进行查看。
5、查看数据
先查看下索引情况,scrapy 索引已经生成,里面有 129 篇博客。
查看详细内容,确保博客正文已经保存。
到了这一步,我们就能使用 Console 对博客进行搜索、分析了。
6、结语
这次的分享就到这里了。欢迎与我一起交流 ES 的各种问题和解决方案。
关于 Easysearch
INFINI Easysearch 是一个分布式的近实时搜索与分析引擎,核心引擎基于开源的 Apache Lucene。Easysearch 的目标是提供一个轻量级的 Elasticsearch 可替代版本,并继续完善和支持更多的企业级功能。 与 Elasticsearch 相比,Easysearch 更关注在搜索业务场景的优化和继续保持其产品的简洁与易用性。
官网文档:https://infinilabs.cn/docs/latest/easysearch
收起阅读 »
搜索客社区日报 第1899期 (2024-09-11)
https://mp.weixin.qq.com/s/dGgPK5tKECrF33kziSbKuQ
2.在 Elastic 8.15 中使用最少的代码快速构建 RAG
https://blog.csdn.net/UbuntuTo ... 25165
3.RAG LLM 最佳实践(搭梯)
https://medium.com/israeli-tec ... 1201f
编辑:kin122
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/dGgPK5tKECrF33kziSbKuQ
2.在 Elastic 8.15 中使用最少的代码快速构建 RAG
https://blog.csdn.net/UbuntuTo ... 25165
3.RAG LLM 最佳实践(搭梯)
https://medium.com/israeli-tec ... 1201f
编辑:kin122
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第1898期 (2024-09-10)
1. 用够浪+redis+es搭的实时告警…很强(需要梯子)
https://levelup.gitconnected.c ... c9cef
2. 日志处理里ES是最好的选择吗?(需要梯子)
https://medium.com/%40greptime ... e690e
3. 给你的程序配一个搜索引擎需要多久?最多45分钟!(需要梯子)
https://medium.com/%40danielre ... 45761
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
1. 用够浪+redis+es搭的实时告警…很强(需要梯子)
https://levelup.gitconnected.c ... c9cef
2. 日志处理里ES是最好的选择吗?(需要梯子)
https://medium.com/%40greptime ... e690e
3. 给你的程序配一个搜索引擎需要多久?最多45分钟!(需要梯子)
https://medium.com/%40danielre ... 45761
编辑:斯蒂文
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第1897期 (2024-09-09)
https://mp.weixin.qq.com/s/_j1gpz_rNVO8-V1JPwvOgA
2. 基于 INFINI Pizza 为 Hugo 静态站点添加搜索功能
https://infinilabs.cn/blog/202 ... izza/
3. 搜索引擎原理解析:从0开始实现一个搜索引擎
https://cloud.tencent.com/deve ... 72543
4. 利用MongoDB进行数据治理,防范构建生成式AI应用程序时的潜在安全风险
https://www.modb.pro/db/182607 ... x_hot
5. 一篇文章让你彻底掌握 Shell
https://mp.weixin.qq.com/s/GmSqHJiBToncvcpFAJUZbw
编辑:Muse
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/_j1gpz_rNVO8-V1JPwvOgA
2. 基于 INFINI Pizza 为 Hugo 静态站点添加搜索功能
https://infinilabs.cn/blog/202 ... izza/
3. 搜索引擎原理解析:从0开始实现一个搜索引擎
https://cloud.tencent.com/deve ... 72543
4. 利用MongoDB进行数据治理,防范构建生成式AI应用程序时的潜在安全风险
https://www.modb.pro/db/182607 ... x_hot
5. 一篇文章让你彻底掌握 Shell
https://mp.weixin.qq.com/s/GmSqHJiBToncvcpFAJUZbw
编辑:Muse
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第1896期 (2024-09-06)
https://www.mongodb.com/zh-cn/ ... arch/
2、Elasticsearch 8 让企业更快更好地落地 RAG 应用
https://mp.weixin.qq.com/s/smR2Q_HarUFA4pSCoN8tNA
3、OpenSearch:通过并发段搜索提高矢量搜索性能
https://opensearch.org/blog/bo ... -css/
4、多模态大型语言模型 (LLM) 的工作原理
https://mp.weixin.qq.com/s/1qYuYa-L53M9WwfvHNvl_Q
编辑:Fred
更多资讯:http://news.searchkit.cn
https://www.mongodb.com/zh-cn/ ... arch/
2、Elasticsearch 8 让企业更快更好地落地 RAG 应用
https://mp.weixin.qq.com/s/smR2Q_HarUFA4pSCoN8tNA
3、OpenSearch:通过并发段搜索提高矢量搜索性能
https://opensearch.org/blog/bo ... -css/
4、多模态大型语言模型 (LLM) 的工作原理
https://mp.weixin.qq.com/s/1qYuYa-L53M9WwfvHNvl_Q
编辑:Fred
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第1895期 (2024-09-05)
https://mp.weixin.qq.com/s/qosGdlMJO_w2Ge3i0hdHlA
2.深入体验全新 Cursor AI IDE 后,说杀疯了真不为过!
https://mp.weixin.qq.com/s/CnKMYjpn3YeoHYpoZ7iGIw
3.KubeCon China 回顾|快手的 100% 资源利用率提升:从裸机迁移大规模 Redis 到 Kubernetes
https://mp.weixin.qq.com/s/UGqzq1L2Hu1PjF3Y08XT5Q
编辑:Se7en
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/qosGdlMJO_w2Ge3i0hdHlA
2.深入体验全新 Cursor AI IDE 后,说杀疯了真不为过!
https://mp.weixin.qq.com/s/CnKMYjpn3YeoHYpoZ7iGIw
3.KubeCon China 回顾|快手的 100% 资源利用率提升:从裸机迁移大规模 Redis 到 Kubernetes
https://mp.weixin.qq.com/s/UGqzq1L2Hu1PjF3Y08XT5Q
编辑:Se7en
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第1894期 (2024-09-04)
https://zhuanlan.zhihu.com/p/714675735
2.时隔3年重新开源,这些 ElasticSearch 应用技能运维必会?
https://mp.weixin.qq.com/s/vGbH-rkurt2ydRBPiVrC4w
3.Elasticsearch 回顾:向量搜索创新的时间线
https://blog.csdn.net/UbuntuTo ... 68994
编辑:kin122
更多资讯:http://news.searchkit.cn
https://zhuanlan.zhihu.com/p/714675735
2.时隔3年重新开源,这些 ElasticSearch 应用技能运维必会?
https://mp.weixin.qq.com/s/vGbH-rkurt2ydRBPiVrC4w
3.Elasticsearch 回顾:向量搜索创新的时间线
https://blog.csdn.net/UbuntuTo ... 68994
编辑:kin122
更多资讯:http://news.searchkit.cn
收起阅读 »
【搜索客社区日报】第1893期 (2024-09-03)
https://medium.com/%40imriqwe/ ... f7622
2. ES里的搜索上下文和filter上下文是啥?(需要梯子)
https://mahajanjatin-14.medium ... d31de
3. 来来来,老司机教你几步解决未分配的分片(需要梯子)
https://medium.com/%40yago82/a ... 33d9d
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
https://medium.com/%40imriqwe/ ... f7622
2. ES里的搜索上下文和filter上下文是啥?(需要梯子)
https://mahajanjatin-14.medium ... d31de
3. 来来来,老司机教你几步解决未分配的分片(需要梯子)
https://medium.com/%40yago82/a ... 33d9d
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
收起阅读 »
【搜索客社区日报】第1892期 (2024-09-02)
https://blog.csdn.net/tMb8Z9Vd ... 61894
2. 【2024年8月】盘点国内可用的 Web Search API,仅此一家 —— 博查AI搜索,可平替Bing Search API
https://blog.csdn.net/cxk19980 ... 19049
3. 8月数据库圈值得关注的事 | 2024
https://tech.it168.com/a2024/0 ... shtml
4. 欢迎来到 AI 中心新时代——Arista EOS 系统助力构建强大的 AI 网络
https://www.bytebt.cn/bytebrid ... .html
5. 从RAG到TAG:探索AI与数据库的完美结合
https://mp.weixin.qq.com/s/o8sR4YYx71xh-IW9D00FzA
编辑:Muse
更多资讯:http://news.searchkit.cn
https://blog.csdn.net/tMb8Z9Vd ... 61894
2. 【2024年8月】盘点国内可用的 Web Search API,仅此一家 —— 博查AI搜索,可平替Bing Search API
https://blog.csdn.net/cxk19980 ... 19049
3. 8月数据库圈值得关注的事 | 2024
https://tech.it168.com/a2024/0 ... shtml
4. 欢迎来到 AI 中心新时代——Arista EOS 系统助力构建强大的 AI 网络
https://www.bytebt.cn/bytebrid ... .html
5. 从RAG到TAG:探索AI与数据库的完美结合
https://mp.weixin.qq.com/s/o8sR4YYx71xh-IW9D00FzA
编辑:Muse
更多资讯:http://news.searchkit.cn 收起阅读 »
🔥 Rust China Conf 2024 震撼来袭,INFINI Pizza 搜索引擎重磅亮相!
随着 Rust 语言以其在性能、安全性和并发性方面的卓越表现,赢得了全球开发者的青睐,Rust 社区正迎来前所未有的发展机遇。在这个充满活力与潜力的背景下,Rust China Conf 2024 震撼来袭!
Rust 大会介绍
Rust 大会即将于 9 月 7 日 - 8 日在上海盛大举办。作为年度国内规模最大并唯一的 Rust 线下大型会议,它由 Rust 中文社区发起主办、知名企业和开源组织联合协办,深受开发者与相关企业的喜爱与推崇。自 2020 年起,已连续举办四年,今年预计将吸引超过 400 名一线程序员和企业用户,他们已在个人或公司项目中实践 Rust,期待在此交流心得、共享经验,共同推动 Rust 生态的繁荣与发展。

INFINI Labs 亮相 Rust 大会
作为本次大会的重要赞助商之一,INFINI Labs 将携手蚂蚁集团、字节跳动、JetBrains、亚马逊云科技、华为、Greptime 等知名企业,为与会者带来创新的灵感和实践的洞见。INFINI Labs 的创始人 & CEO 曾勇先生将分享《基于 Rust 编写下一代实时搜索引擎》—— INFINI Pizza 的故事,这款搜索引擎旨在解决海量数据的实时搜索需求,释放现代硬件的潜力,为企业打造高效、准确的搜索解决方案。

大会部分议题亮点抢先看
《人人可用的 Rust》
讲师简介: Rebecca Rumbul,Rust 基金会执行董事兼首席执行官, OpenUK 董事会成员, OpenSSF 管理委员会成员。
议题介绍: 本次分享将介绍 Rust 基金会如何投资于工程和推广工作,以确保 Rust 对所有人来说都是有用、高效且安全的。
《携手共建繁荣的 Rust OS 内核软件生态》
讲师简介: 田洪亮,田洪亮博士是蚂蚁研究院操作系统方向的负责人, 在 Rust 编程和内核开发方面有丰富的经验,荣获 OS2ATC'24 颁发的开源创新先锋奖。他发起的 Occlum 项目,是业界最早的 Rust OS 开源项目, 已发展成可信执行环境中最流行的 library OS,荣登中科协发布的"科创中国"开源创新榜单。曾就职于 Intel Labs China,博士毕业于清华大学。
议题介绍: Rust 语言以其高效、安全和生产力被视为系统编程,尤其是 OS 编程的未来。但在开发 OS 内核时,存在频繁使用 unsafe、缺乏 Cargo 支持、以及可重用的 no_std crates 不足等痛点。星绽开源社区提出了星绽 Framework 和星绽 OSDK,提供强大的 safe API 和开发工具链, 使得 Rust 内核开发更加安全、高效,并促进了 no_std crates 的复用与组合,旨在提升开发者生产力并推动 Rust 生态的繁荣。
《用 Rust 构建高性能的生成式 AI 应用》
讲师简介: 王宇博,现任亚马逊云科技大中华区开发者关系总监、首席布道师,致力于新一代信息技术与创新在开发者中的布道推广,以及开发者生态体系的建设。
议题介绍: 生成式 AI 技术在自然语言处理和图像生成领域快速发展。对于 Rust 开发者来说,利用 Rust 的高性能特性构建高效、可靠的生成式 AI 应用至关重要。本次演讲将深入探讨在 Rust 中开发生成式 AI 应用的实践方法,分析其在数值计算和并发编程中的优势,并分享确保应用可靠性和安全性的最佳实践,帮助开发者掌握构建高性能生成式 AI 应用的技巧。
《字节跳动在 Rust 服务端方向的实践与思考》
讲师简介: 吴迪,字节跳动服务框架 Rust 负责人,负责字节跳动 Rust 生态建设与推广落地。
议题介绍: 字节跳动三年前开始投资 Rust 服务端开发,构建了内部生态并开源核心框架 Volo。现在已在多个业务线成功落地,规模国内最大,收益超预期。本次分享将介绍选择 Rust 的原因、落地心得及未来技术趋势的思考。
《Async Rust 维测&定位的探索和思考》
讲师简介:
陈明煜:毕业于加州大学圣地亚哥分校,现就职于华为,OpenHarmony Ylong Rust 异步框架的开发者,致力于推动 OH 应用的 Rust 异步化。
楼智豪:毕业于浙江大学,现就职于华为,参与过 Rust 与 Cangjie 语言的开源贡献,现从事 Rust 在 OpenHarmony 中的应用。
议题介绍: 本议题将介绍我们在 OpenHarmony 中遇到的一些异步框架使用问题,以及我们在 Rust 异步调测与定位方面的探索。内容包括对业界常见异步框架的维测能力调研,以及对 Rust 无栈协程的推栈处理和跨 FFI 的 C++ exception 问题解决方法,旨在提升 Rust 异步的可商用性。
《Rust HashMap:比看起来更复杂》
讲师简介: 曹瑞秋,蚂蚁集团高级开发工程师,Apache HoraeDB/CeresDB 核心开发者,Apache HoraeDB PPMC member,长期专注于时序数据库领域。
议题介绍: Rust HashMap 看似简单,实际使用中存在诸多"坑点",尤其在 CPU 消耗和内存占用方面。分段 HashMap 设计中的伪共享和内存访问局部性差会影响性能。HashMap 的 capacity 通常远大于指定值,加之内存访问特性,会占据大量物理内存。此外,with_capacity方法和 allocator 内存池的使用不当可能导致内存释放问题。因此,使用 Rust HashMap 需要细心设计。
《Rust 和 C++ 互操作及交叉编译》
讲师简介: 朱树磊,北京大学物理学士,德国 TUM 硕士,现任浙江大华技术股份有限公司高级算法专家。从事人工智能算法研发工作 10 余年,擅长机器学习、深度学习和大数据智能等技术领域,具备丰富的人工智能算法系统设计和开发经验。
议题介绍: Rust 和 C++ 经常需要共存,但 C++ 的交叉编译复杂性是一个挑战。本次分享将介绍如何使用 cxx 让 Rust 和 C++ 代码共存,并通过 LLVM 工具链补齐 C++ 交叉编译的短板,让 C++ 和 Rust 的互操作简单可移植。
《超大规模:抖音直播的 Rust 技术落地实践》
讲师简介: 赵鹏,抖音直播架构师,Rust 技术负责人。
议题介绍: 抖音直播从 2022 年开始引入 Rust 技术栈,用于应对直播业务中的超低延时、超高性能挑战,取得了远超预期巨大的收益。两年时间里我们有 20+ 个头部服务完成了 Rust 重构,吞吐平均提升超 100%,节省了 16w 核 CPU 资源,多个服务 SLA 提升至 6 个 9,目前我们的 Rust 服务在线上承担着超 4000w qps 的请求。Rust 技术在抖音直播研发团队二级部门实现了 100% 覆盖,每个子业务团队都有 Rust 服务在线上运行。我们还成立了专门的 Rust 技术组帮助解决业务公共问题,沉淀了完整的 Rust 研发流水线,基本实现了 Rust 新人两周即可上手开发,两个月完成一个 Rust 服务上线的速度。综合 Rust 服务类型覆盖、数量、资源占用、开发人员、生态、基建完善程度,抖音直播已经是国内规模最大的 Rust 技术生产环境落地团队,本次分享将给大家介绍我们从选型、验证、落地、推广到维护过程中的真实实践经验,希望能够帮助到其他同行朋友。
大会报名
本次大会致力于成为中国 Rustaceans 面对面交流的盛宴,为国内的 Rust 开发者和企业提供一次充分的成果展示、技术分享、能力提升、行业资讯交流、企业人才储备建设的机会。欢迎购票参与现场交流。
🔗 报名链接 / 扫二维码:
https://4292817522623.huodongxing.com/event/5757822319111

关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
随着 Rust 语言以其在性能、安全性和并发性方面的卓越表现,赢得了全球开发者的青睐,Rust 社区正迎来前所未有的发展机遇。在这个充满活力与潜力的背景下,Rust China Conf 2024 震撼来袭!
Rust 大会介绍
Rust 大会即将于 9 月 7 日 - 8 日在上海盛大举办。作为年度国内规模最大并唯一的 Rust 线下大型会议,它由 Rust 中文社区发起主办、知名企业和开源组织联合协办,深受开发者与相关企业的喜爱与推崇。自 2020 年起,已连续举办四年,今年预计将吸引超过 400 名一线程序员和企业用户,他们已在个人或公司项目中实践 Rust,期待在此交流心得、共享经验,共同推动 Rust 生态的繁荣与发展。
INFINI Labs 亮相 Rust 大会
作为本次大会的重要赞助商之一,INFINI Labs 将携手蚂蚁集团、字节跳动、JetBrains、亚马逊云科技、华为、Greptime 等知名企业,为与会者带来创新的灵感和实践的洞见。INFINI Labs 的创始人 & CEO 曾勇先生将分享《基于 Rust 编写下一代实时搜索引擎》—— INFINI Pizza 的故事,这款搜索引擎旨在解决海量数据的实时搜索需求,释放现代硬件的潜力,为企业打造高效、准确的搜索解决方案。
大会部分议题亮点抢先看
《人人可用的 Rust》
讲师简介: Rebecca Rumbul,Rust 基金会执行董事兼首席执行官, OpenUK 董事会成员, OpenSSF 管理委员会成员。
议题介绍: 本次分享将介绍 Rust 基金会如何投资于工程和推广工作,以确保 Rust 对所有人来说都是有用、高效且安全的。
《携手共建繁荣的 Rust OS 内核软件生态》
讲师简介: 田洪亮,田洪亮博士是蚂蚁研究院操作系统方向的负责人, 在 Rust 编程和内核开发方面有丰富的经验,荣获 OS2ATC'24 颁发的开源创新先锋奖。他发起的 Occlum 项目,是业界最早的 Rust OS 开源项目, 已发展成可信执行环境中最流行的 library OS,荣登中科协发布的"科创中国"开源创新榜单。曾就职于 Intel Labs China,博士毕业于清华大学。
议题介绍: Rust 语言以其高效、安全和生产力被视为系统编程,尤其是 OS 编程的未来。但在开发 OS 内核时,存在频繁使用 unsafe、缺乏 Cargo 支持、以及可重用的 no_std crates 不足等痛点。星绽开源社区提出了星绽 Framework 和星绽 OSDK,提供强大的 safe API 和开发工具链, 使得 Rust 内核开发更加安全、高效,并促进了 no_std crates 的复用与组合,旨在提升开发者生产力并推动 Rust 生态的繁荣。
《用 Rust 构建高性能的生成式 AI 应用》
讲师简介: 王宇博,现任亚马逊云科技大中华区开发者关系总监、首席布道师,致力于新一代信息技术与创新在开发者中的布道推广,以及开发者生态体系的建设。
议题介绍: 生成式 AI 技术在自然语言处理和图像生成领域快速发展。对于 Rust 开发者来说,利用 Rust 的高性能特性构建高效、可靠的生成式 AI 应用至关重要。本次演讲将深入探讨在 Rust 中开发生成式 AI 应用的实践方法,分析其在数值计算和并发编程中的优势,并分享确保应用可靠性和安全性的最佳实践,帮助开发者掌握构建高性能生成式 AI 应用的技巧。
《字节跳动在 Rust 服务端方向的实践与思考》
讲师简介: 吴迪,字节跳动服务框架 Rust 负责人,负责字节跳动 Rust 生态建设与推广落地。
议题介绍: 字节跳动三年前开始投资 Rust 服务端开发,构建了内部生态并开源核心框架 Volo。现在已在多个业务线成功落地,规模国内最大,收益超预期。本次分享将介绍选择 Rust 的原因、落地心得及未来技术趋势的思考。
《Async Rust 维测&定位的探索和思考》
讲师简介:
陈明煜:毕业于加州大学圣地亚哥分校,现就职于华为,OpenHarmony Ylong Rust 异步框架的开发者,致力于推动 OH 应用的 Rust 异步化。
楼智豪:毕业于浙江大学,现就职于华为,参与过 Rust 与 Cangjie 语言的开源贡献,现从事 Rust 在 OpenHarmony 中的应用。
议题介绍: 本议题将介绍我们在 OpenHarmony 中遇到的一些异步框架使用问题,以及我们在 Rust 异步调测与定位方面的探索。内容包括对业界常见异步框架的维测能力调研,以及对 Rust 无栈协程的推栈处理和跨 FFI 的 C++ exception 问题解决方法,旨在提升 Rust 异步的可商用性。
《Rust HashMap:比看起来更复杂》
讲师简介: 曹瑞秋,蚂蚁集团高级开发工程师,Apache HoraeDB/CeresDB 核心开发者,Apache HoraeDB PPMC member,长期专注于时序数据库领域。
议题介绍: Rust HashMap 看似简单,实际使用中存在诸多"坑点",尤其在 CPU 消耗和内存占用方面。分段 HashMap 设计中的伪共享和内存访问局部性差会影响性能。HashMap 的 capacity 通常远大于指定值,加之内存访问特性,会占据大量物理内存。此外,with_capacity方法和 allocator 内存池的使用不当可能导致内存释放问题。因此,使用 Rust HashMap 需要细心设计。
《Rust 和 C++ 互操作及交叉编译》
讲师简介: 朱树磊,北京大学物理学士,德国 TUM 硕士,现任浙江大华技术股份有限公司高级算法专家。从事人工智能算法研发工作 10 余年,擅长机器学习、深度学习和大数据智能等技术领域,具备丰富的人工智能算法系统设计和开发经验。
议题介绍: Rust 和 C++ 经常需要共存,但 C++ 的交叉编译复杂性是一个挑战。本次分享将介绍如何使用 cxx 让 Rust 和 C++ 代码共存,并通过 LLVM 工具链补齐 C++ 交叉编译的短板,让 C++ 和 Rust 的互操作简单可移植。
《超大规模:抖音直播的 Rust 技术落地实践》
讲师简介: 赵鹏,抖音直播架构师,Rust 技术负责人。
议题介绍: 抖音直播从 2022 年开始引入 Rust 技术栈,用于应对直播业务中的超低延时、超高性能挑战,取得了远超预期巨大的收益。两年时间里我们有 20+ 个头部服务完成了 Rust 重构,吞吐平均提升超 100%,节省了 16w 核 CPU 资源,多个服务 SLA 提升至 6 个 9,目前我们的 Rust 服务在线上承担着超 4000w qps 的请求。Rust 技术在抖音直播研发团队二级部门实现了 100% 覆盖,每个子业务团队都有 Rust 服务在线上运行。我们还成立了专门的 Rust 技术组帮助解决业务公共问题,沉淀了完整的 Rust 研发流水线,基本实现了 Rust 新人两周即可上手开发,两个月完成一个 Rust 服务上线的速度。综合 Rust 服务类型覆盖、数量、资源占用、开发人员、生态、基建完善程度,抖音直播已经是国内规模最大的 Rust 技术生产环境落地团队,本次分享将给大家介绍我们从选型、验证、落地、推广到维护过程中的真实实践经验,希望能够帮助到其他同行朋友。
大会报名
本次大会致力于成为中国 Rustaceans 面对面交流的盛宴,为国内的 Rust 开发者和企业提供一次充分的成果展示、技术分享、能力提升、行业资讯交流、企业人才储备建设的机会。欢迎购票参与现场交流。
🔗 报名链接 / 扫二维码:
https://4292817522623.huodongxing.com/event/5757822319111
关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
收起阅读 »
