

【搜索客社区日报】 第1959期 (2024-12-25)
https://mp.weixin.qq.com/s/crvAiHdbkDMFySS9x8tydQ
2.GraphRAG:用知识图增强RAG(搭梯)
https://medium.com/%40zilliz_l ... f99e1
3.如何在 Elasticsearch 中高效索引超过 1000 万条记录(搭梯)
https://medium.com/%40icreon/h ... ca87b
4.深入探讨高质量重排器及其性能优化:Elastic Rerank模型的实战评估
https://cloud.tencent.com/deve ... 77172
5.超越传统模型:从零开始构建高效的日志分析平台——基于Elasticsearch的实战指南
https://developer.aliyun.com/article/1625901
编辑:kin122
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/crvAiHdbkDMFySS9x8tydQ
2.GraphRAG:用知识图增强RAG(搭梯)
https://medium.com/%40zilliz_l ... f99e1
3.如何在 Elasticsearch 中高效索引超过 1000 万条记录(搭梯)
https://medium.com/%40icreon/h ... ca87b
4.深入探讨高质量重排器及其性能优化:Elastic Rerank模型的实战评估
https://cloud.tencent.com/deve ... 77172
5.超越传统模型:从零开始构建高效的日志分析平台——基于Elasticsearch的实战指南
https://developer.aliyun.com/article/1625901
编辑:kin122
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第1958期 (2024-12-24)
平安夜咯铁子们,hohoho
1. Logstash面试题(需要梯子)
https://medium.com/%40romantic ... a1432
2. 用ES来提升RAG的效果,顶不顶(需要梯子)
https://medium.com/%40raphy.26 ... 26c63
3. 别说我没教你啊,全干工程师们会用Nodejs连接Elasticsearch了(需要梯子)
https://medium.com/%40arnabgol ... 5270b
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
平安夜咯铁子们,hohoho
1. Logstash面试题(需要梯子)
https://medium.com/%40romantic ... a1432
2. 用ES来提升RAG的效果,顶不顶(需要梯子)
https://medium.com/%40raphy.26 ... 26c63
3. 别说我没教你啊,全干工程师们会用Nodejs连接Elasticsearch了(需要梯子)
https://medium.com/%40arnabgol ... 5270b
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
收起阅读 »
【搜索客社区日报】第1957期 (2024-12-23)
https://infinilabs.cn/blog/2024/release-20241213/
2. Easysearch Chart Admin 密码自定义
https://infinilabs.cn/blog/202 ... stom/
3. Elasticsearch VS Easysearch 性能测试
https://infinilabs.cn/blog/202 ... ting/
4. Easysearch Java SDK 2.0.x 使用指南(三)
https://infinilabs.cn/blog/202 ... nt-3/
5. RAG效果不好怎么办?试试这八大解决方案(含代码)
https://mp.weixin.qq.com/s/XiHXa6Jwak_Ps2QTABdQ2w
编辑:Muse
更多资讯:http://news.searchkit.cn
https://infinilabs.cn/blog/2024/release-20241213/
2. Easysearch Chart Admin 密码自定义
https://infinilabs.cn/blog/202 ... stom/
3. Elasticsearch VS Easysearch 性能测试
https://infinilabs.cn/blog/202 ... ting/
4. Easysearch Java SDK 2.0.x 使用指南(三)
https://infinilabs.cn/blog/202 ... nt-3/
5. RAG效果不好怎么办?试试这八大解决方案(含代码)
https://mp.weixin.qq.com/s/XiHXa6Jwak_Ps2QTABdQ2w
编辑:Muse
更多资讯:http://news.searchkit.cn 收起阅读 »
Elasticseach Ingest 模块&&漏洞分析
本文基于Elasticsearch7.10.2分析
0.Ingest 节点 概述
在实际进行文档index之前,使用采集节点(默认情况下,每个es节点都是ingest)对文档进行预处理。采集节点会拦截bulk和index请求,进行转换,然后将文档传回index或bulk API。
每个索引都有index.default_pipeline 和 index.final_pipeline 两个配置。
他们都是用于指定 Elasticsearch index 或者bulk 文档时要执行的预处理逻辑。
- index.default_pipeline 定义了默认管道,它会在索引文档时首先执行。但如果索引请求中指定了 pipeline 参数,则该参数指定的管道会覆盖默认管道。如果设置了 index.default_pipeline 但对应的管道不存在,索引请求会失败。特殊值 _none 表示不运行任何摄取管道。
- index.final_pipeline 定义了最终管道,它总是在请求管道(如果指定)和默认管道(如果存在)之后执行。如果设置了 index.final_pipeline 但对应的管道不存在,索引请求会失败。特殊值 _none 表示不运行最终管道。
简而言之,default_pipeline 先执行,可被覆盖;final_pipeline 后执行,不可被覆盖。两者都可设为 _none 以禁用。
一个Pipeline可以有多个Processor组成,每个Processor有着各自的不同功能,官方支持的Processor可参考:https://www.elastic.co/guide/en/elasticsearch/reference/7.10/ingest-processors.html
一个简单的例子,利用Set Processor 对新增的文档中加入新的字段和值:
PUT _ingest/pipeline/set_os
{
"description": "sets the value of host.os.name from the field os",
"processors": [
{
"set": {
"field": "host.os.name", // 增加的属性
"value": "{{os}}" // 这里引用了文档原先的os属性, 这里可以直接填写其他值
}
}
]
}
POST _ingest/pipeline/set_os/_simulate
{
"docs": [
{
"_source": {
"os": "Ubuntu"
}
}
]
}这样转换之后,文档内容就变成了:
{
"host" : {
"os" : {
"name" : "Ubuntu"
}
},
"os" : "Ubuntu"
}写单个文档的流程概述

当请求,或者索引本身配置有pipline的时候,协调节点就会转发到ingest节点
PSOT source_index/_doc?pipeline=set_os
{
"os": "xxxx"
}
【注】 并不是一定会发生内部rpc的请求转发,如果本地节点能接受当前的请求则不会转发到其他节点。
1. 模块总体概述
本小节关注IngestService中重要的相关类,对这些类有一个整体的了解有助于理解该模块。
- ClusterService
- IngestService 实现了 ClusterStateApplier 接口, 这样就能监听和响应集群的状态变化,当集群状态更新时,IngestService可以调整其内部 pipelines完成CRUD。
- 另外IngestService还有List<Consumer
>用来对提供给对集群状态变更之后需要最新状态的插件。
- ScriptService
- 某些Processor需要其用于管理和执行脚本,比如Script Processor。
- AnalysisRegistry
- 某些需要对文档内容进行分词处理的Processor。
- ThreadPool
- Processor都是异步执行的,实际执行线程池取决于调用上下文(如 write 或 management)
- bulk API 时发生的pipeline 处理使用的是write线程池。
- pipeline/_simulate API 使用的是management线程池,模拟执行通常是短时间的、低频的任务,不需要高并发支持而且为了不影响实际的文档处理或其他重要任务。
- 另外为了避免Grok Processor运行时间过长,使用了Generic线程做定时调度检查执行时间
- Processor都是异步执行的,实际执行线程池取决于调用上下文(如 write 或 management)
- IngestMetric
- 通过实现ReportingService接口来做到展示ingest内部的执行情况。
- GET _nodes/stats?filter_path=nodes.*.ingest 可以查看到ingest 中的每个Pipeline中的执行的次数、失败次数以及总耗时
- IngestPlugin
- Ingest支持加载自定义的Processor插件,系统内置的所有Processor以及自定义的都通过IngestService 中的Map<String, Processor.Factory> processorFactories来进行管理。
- IngestDocument
- 其包含文档的源数据,提供了修改和查询文档的字段的能力,为Processor灵活操作文档数据提供基础,在后续pipeline的执行中,也是由其的executePipeline方法驱动的。
2. Processor 实现机制
抽象工厂设计模式的应用
Processor接口设计
每个Processor都有核心方法execute,使得处理器能够以统一的方式操作 IngestDocument,并通过多态实现不同处理逻辑。
Processor.Factory的设计
Processor.Factory 是 Processor 的抽象工厂,负责动态创建处理器实例。其主要职责包括:
- 动态实例化:
- Processor create() 方法接收处理器配置并创建具体的处理器。
- 支持递归创建,例如ConditionalProcessor可以嵌套其他处理器。
- 依赖注入:
- Processor.Parameters 提供了一组服务和工具(如 ScriptService),工厂可以利用这些依赖创建复杂的Processor。
Processor.Factory的集中管理
在 IngestService 中,通过 Map<String, Processor.Factory> processorFactories 集中管理所有处理器工厂。这种管理方式提供了以下优势:
动态扩展:
- 插件可以注册自定义Processor工厂。
- 新处理器类型的注册仅需添加到 processorFactories。
组合以及装饰器设计模式的应用
Processor经典的几个类的关系如下:

CompoundProcessor是经典的组合设计模式,Pipeline这个类可以像使用单个 Processor 一样调用 CompoundProcessor,无需关注其内部具体细节。
而ConditionalProcessor 以及TrackingResultProcessor则体现了装饰器模式,在不改变原有对象的情况下扩展功能:
- ConditionalProcessor 在执行Processor前会调用evaluate方法判断是否需要执行。
- TrackingResultProcessor中decorate是为 CompoundProcessor 及其内部的 Processor 添加跟踪功能。
如何自定义Processor 插件
自定义 Processor 插件的注册方式为实现 IngestPlugin (Elasticsearch 提供不同的插件接口用来扩展不同类型的功能)的 getProcessors 方法,该方法返回一个工厂列表,IngestService 会将这些工厂注入到 processorFactories 中。
分析完代码之后,我们回到实战中来,简单起见,我们实现类似Append的Processor,但是我们这个更简单,输入的是字符串,然后我们用,分割一下将其作为数组设为值。
import org.elasticsearch.ingest.Processor;
import org.elasticsearch.plugins.IngestPlugin;
import org.elasticsearch.plugins.Plugin;
import java.util.HashMap;
import java.util.Map;
public class AddArrayProcessorPlugin extends Plugin implements IngestPlugin {
@Override
public Map<String, Processor.Factory> getProcessors(Processor.Parameters parameters) {
Map<String, Processor.Factory> processors = new HashMap<>();
processors.put(AddArrayProcessor.TYPE, new AddArrayProcessor.Factory());
return processors;
}
}import org.elasticsearch.ingest.AbstractProcessor;
import org.elasticsearch.ingest.ConfigurationUtils;
import org.elasticsearch.ingest.IngestDocument;
import org.elasticsearch.ingest.Processor;
import java.util.*;
public class AddArrayProcessor extends AbstractProcessor {
public static final String TYPE = "add_array";
public String field;
public String value;
protected AddArrayProcessor(String tag, String description, String field, String value) {
super(tag, description);
this.field = field;
this.value = value;
}
@Override
public IngestDocument execute(IngestDocument ingestDocument) throws Exception {
List valueList = new ArrayList<>(Arrays.asList(value.split(",")));
ingestDocument.setFieldValue(field, valueList);
return ingestDocument;
}
@Override
public String getType() {
return TYPE;
}
public static final class Factory implements Processor.Factory {
@Override
public Processor create(Map<String, Processor.Factory> processorFactories, String tag,
String description, Map<String, Object> config) throws Exception {
String field = ConfigurationUtils.readStringProperty(TYPE, tag, config, "field");
String value = ConfigurationUtils.readStringProperty(TYPE, tag, config, "value");
return new AddArrayProcessor(tag, description, field, value);
}
}
}打包之后,我们去install我们的Processor插件:
bin/elasticsearch-plugin install file:///home/hcb/data/data/es/data_standalone/elasticsearch-7.10.2-SNAPSHOT/AddArrayProcessor-1.0-SNAPSHOT.zip
warning: no-jdk distributions that do not bundle a JDK are deprecated and will be removed in a future release
-> Installing file:///home/hcb/data/data/es/data_standalone/elasticsearch-7.10.2-SNAPSHOT/AddArrayProcessor-1.0-SNAPSHOT.zip
-> Downloading file:///home/hcb/data/data/es/data_standalone/elasticsearch-7.10.2-SNAPSHOT/AddArrayProcessor-1.0-SNAPSHOT.zip
[=================================================] 100%
-> Installed AddArrayProcess测试一下:
POST /_ingest/pipeline/_simulate
{
"pipeline": {
"processors": [
{
"add_array": {
"field": "test_arr",
"value": "a,b,c,d,e,f"
}
}
]
},
"docs": [
{
"_index": "test",
"_id": "1",
"_source": {
"field": "value"
}
}
]
}
docs结果:
"_source" : {
"field" : "value",
"test_arr" : [
"a",
"b",
"c",
"d",
"e",
"f"
]
}3. Pipeline设计
如何管理Pipeline
在IngestServcie中有一个Map存储所有的Pipeline实例,private volatile Map<String, PipelineHolder> pipelines = Collections.emptyMap();
这里并没有将Pipeline实例存储在IngestMetadata,这样做的原因有2个:
- 在 Elasticsearch 的启动过程中,插件和节点服务的初始化发生在 ClusterState 加载之后, 只有等所有插件完成加载后,所有的Processor工厂才会被注册到系统中,这意味着在集群状态初始化之前,Processor工厂并不可用。
- ClusterState 中的元数据结构是静态注册的,即在类加载时已经确定,如果要将运行时示例存储进去,必须改变 ClusterState 的元数据结构存储格式,这个很不方便维护,而且这在集群状态同步的时候也会带来不必要的序列化以及反序列化。
所以Pipeline的管理逻辑是:
- ClusterState 中的IngestMetadata 只存储 JSON 格式的管道定义,描述 Pipeline 的配置(例如,包含哪些 Processor,它们的参数等)。
- IngestService 中维护的运行时实例,将 JSON 配置解析为完整的 Pipeline 对象,包括处理器链
在集群变更时, pipeline的CRUD的实现在innerUpdatePipelines方法中 。
责任链设计模式的应用
管道的执行通过IngestDocument的org.elasticsearch.ingest.IngestDocument#executePipeline 去驱动,每个文档的每个Pipeline都会进入到这个函数, 而每个Pipeline有组装好的CompoundProcessor,实际的链式调用是在CompoundProcessor中。
简图大致如下:

这里拿其和Zookeeper(3.6.3)中RequestProcessor 做一些对比:
| 特点 | ES中的CompoundProcessor | Zookeeper中RequestProcessor |
|---|---|---|
| 链的存储定义 | 由两条列表组成,分别保存正常流程以及失败流程的Processor列表。 | 固定的链式结构。 |
| 异步执行 | 支持异步回调,可以异步执行链中的处理器。 | 同步执行 。 |
| 失败处理 | 提供专门的 onFailureProcessors 作为失败处理链。如果不忽略异常并且onFailureProcessors 不为空则会执行失败处理链逻辑。 | 没有专门的失败处理链,异常直接交由上层捕获。 |
| 可配置性 | 可动态调整处理器链和配置(如 ignoreFailure)。 | 代码中写死,无法配置 |
这里并没有说Zookeeper的设计就差于Elasticsearch, 只是设计目标有所不同,RequestProcessor就是适合集中式的强一致、其中Processor并不需要灵活变化,而CompoundProcessor就是适合高并发而Procesor灵活变化场景。
4. Ingest实战建议
回到实战中来,这里结合目前所分析的内容给出相应的实战建议。
- 建立监控
- 对于关键的Piepline,我们需要通过GET _nodes/stats?filter_path=nodes.*.ingest 获取其运行状况,识别延迟或失败的 Processor。
- 文档写入的时候使用的是write线程池,我们也需要监控GET _nodes/stats?filter_path=nodes.*.thread_pool.write 的queue和write_rejections 判断需要扩展线程池。
- 优化Processor
- 减少高开销操作,优先使用内置 Processor,比如script Processor 可适时替换set, append,避免过度复杂的正则表达式或嵌套逻辑。
- 自定义的Processor尽量优化,比如如果涉及查询外部系统可考虑引入缓存。
- 建立单独的Ingest节点
- 如果有大量的Pipeline需要执行,则可以考虑增加专用 Ingest 节点,避免与数据节点争夺资源。
5. 漏洞&&修复分析
这里分析7.10.2版本Ingest模块存在的漏洞以及官方是如何修复的。
CVE-2021-22144
https://discuss.elastic.co/t/elasticsearch-7-13-3-and-6-8-17-security-update/278100
Elasticsearch Grok 解析器中发现了一个不受控制的递归漏洞,该漏洞可能导致拒绝服务攻击。能够向 Elasticsearch 提交任意查询的用户可能会创建恶意 Grok 查询,从而导致 Elasticsearch 节点崩溃。
漏洞复现
发起这个请求:
- patterns: 处理字段时使用的 Grok 模式,这里设置为 %{INT}。
- pattern_definitions: 定义自定义 Grok 模式,这里故意让 INT 模式递归引用自身,导致循环引用问题。
POST /_ingest/pipeline/_simulate
{
"pipeline": {
"processors": [
{
"grok": {
"field": "message",
"patterns": [
"%{INT}"
],
"pattern_definitions": {
"INT": "%{INT}"
}
}
}
]
},
"docs": [
{
"_source": {
"message": "test"
}
}
]
}
当执行之后会使得节点直接StackOverflow中止进程。
修复逻辑
这个问题的关键在于原先的逻辑中,只会对间接的递归引用(pattern1 => pattern2 => pattern3 => pattern1)做了检测,但是没有对直接的自引用(pattern1 => pattern1 )做检测。
private void forbidCircularReferences() {
// 这个是增加的逻辑,检测直接的自引用
for (Map.Entry<String, String> entry : patternBank.entrySet()) {
if (patternReferencesItself(entry.getValue(), entry.getKey())) {
throw new IllegalArgumentException("circular reference in pattern [" + entry.getKey() + "][" + entry.getValue() + "]");
}
}
// 间接递归引用检测(这个是原先的逻辑)
for (Map.Entry<String, String> entry : patternBank.entrySet()) {
String name = entry.getKey();
String pattern = entry.getValue();
innerForbidCircularReferences(name, new ArrayList<>(), pattern);
}
}CVE-2023-46673
https://discuss.elastic.co/t/elasticsearch-7-17-14-8-10-3-security-update-esa-2023-24/347708
漏洞复现
尝试了很多已有的Processor都没有复现,我们这使用自定义的Processor来复现,将之前的自定义AddArrayProcessor加一行代码:
@Override
public IngestDocument execute(IngestDocument ingestDocument) throws Exception {
List valueList = new ArrayList<>(Arrays.asList(value.split(",")));
valueList.add(valueList); // 增加的代码
ingestDocument.setFieldValue(field, valueList);
return ingestDocument;
}重新编译再安装插件之后,执行改Processor 将会StackOverflow。
修复逻辑
这个问题的关键在于在IngestDocument的deepCopyMap的方法之前没有判断这样的无限引用的情况:

那么在此之前做一个检测就好了,这个方法在原本的ES代码中就存在:org.elasticsearch.common.util.CollectionUtils#ensureNoSelfReferences(java.lang.Object, java.lang.String) ,其利用 IdentityHashMap 记录已访问对象的引用,检测并防止对象间的循环引用。
CVE-2024-23450
https://discuss.elastic.co/t/elasticsearch-8-13-0-7-17-19-security-update-esa-2024-06/356314
漏洞复现
虽然我们的索引只有2个Pipeline的配置,但是由于Pipeline Processor的存在,所以实际上一个文档其实能被很多Pipeline处理,当需要执行足够多个的pipline个数时,则会发生StackOverflow。
修复逻辑
这个问题的关键在于对Pipeline的个数并没有限制,添加一个配置项,当超出该个数则直接抛出异常。
public static final int MAX_PIPELINES = Integer.parseInt(System.getProperty("es.ingest.max_pipelines", "100"));IngestDocument的org.elasticsearch.ingest.IngestDocument#executePipeline 添加逻辑:
public void executePipeline(Pipeline pipeline, BiConsumer<IngestDocument, Exception> handler) {
if (executedPipelines.size() >= MAX_PIPELINES) {
handler.accept(
null,
new IllegalStateException(PIPELINE_TOO_MANY_ERROR_MESSAGE + MAX_PIPELINES + " nested pipelines")
);
} 思考: 这里判断pipeline是否超出100个限制是用已经执行的pipeline个数来计算的。 假设已经超出100个pipeline,那这100个pipeline是会白跑的, 如果能在真正执行之前分析需要执行的Pipeline个数会更好。
6. 总结
Ingest 模块作为 Elasticsearch 数据处理流程的重要组成部分,提供了灵活的管道化能力,使得用户能够在数据写入前进行丰富的预处理操作。然而,在实际场景中,Ingest 模块也面临性能瓶颈、资源竞争等挑战,需要结合业务需求和系统现状进行精细化调优,通过优化 Processor 执行效率、合理规划集群架构以及增强监控与诊断手段,我们可以充分释放 Ingest 模块的能力,提升 Elasticsearch 的整体数据处理能力。
本文基于Elasticsearch7.10.2分析
0.Ingest 节点 概述
在实际进行文档index之前,使用采集节点(默认情况下,每个es节点都是ingest)对文档进行预处理。采集节点会拦截bulk和index请求,进行转换,然后将文档传回index或bulk API。
每个索引都有index.default_pipeline 和 index.final_pipeline 两个配置。
他们都是用于指定 Elasticsearch index 或者bulk 文档时要执行的预处理逻辑。
- index.default_pipeline 定义了默认管道,它会在索引文档时首先执行。但如果索引请求中指定了 pipeline 参数,则该参数指定的管道会覆盖默认管道。如果设置了 index.default_pipeline 但对应的管道不存在,索引请求会失败。特殊值 _none 表示不运行任何摄取管道。
- index.final_pipeline 定义了最终管道,它总是在请求管道(如果指定)和默认管道(如果存在)之后执行。如果设置了 index.final_pipeline 但对应的管道不存在,索引请求会失败。特殊值 _none 表示不运行最终管道。
简而言之,default_pipeline 先执行,可被覆盖;final_pipeline 后执行,不可被覆盖。两者都可设为 _none 以禁用。
一个Pipeline可以有多个Processor组成,每个Processor有着各自的不同功能,官方支持的Processor可参考:https://www.elastic.co/guide/en/elasticsearch/reference/7.10/ingest-processors.html
一个简单的例子,利用Set Processor 对新增的文档中加入新的字段和值:
PUT _ingest/pipeline/set_os
{
"description": "sets the value of host.os.name from the field os",
"processors": [
{
"set": {
"field": "host.os.name", // 增加的属性
"value": "{{os}}" // 这里引用了文档原先的os属性, 这里可以直接填写其他值
}
}
]
}
POST _ingest/pipeline/set_os/_simulate
{
"docs": [
{
"_source": {
"os": "Ubuntu"
}
}
]
}这样转换之后,文档内容就变成了:
{
"host" : {
"os" : {
"name" : "Ubuntu"
}
},
"os" : "Ubuntu"
}写单个文档的流程概述
当请求,或者索引本身配置有pipline的时候,协调节点就会转发到ingest节点
PSOT source_index/_doc?pipeline=set_os
{
"os": "xxxx"
}【注】 并不是一定会发生内部rpc的请求转发,如果本地节点能接受当前的请求则不会转发到其他节点。
1. 模块总体概述
本小节关注IngestService中重要的相关类,对这些类有一个整体的了解有助于理解该模块。
- ClusterService
- IngestService 实现了 ClusterStateApplier 接口, 这样就能监听和响应集群的状态变化,当集群状态更新时,IngestService可以调整其内部 pipelines完成CRUD。
- 另外IngestService还有List<Consumer
>用来对提供给对集群状态变更之后需要最新状态的插件。
- ScriptService
- 某些Processor需要其用于管理和执行脚本,比如Script Processor。
- AnalysisRegistry
- 某些需要对文档内容进行分词处理的Processor。
- ThreadPool
- Processor都是异步执行的,实际执行线程池取决于调用上下文(如 write 或 management)
- bulk API 时发生的pipeline 处理使用的是write线程池。
- pipeline/_simulate API 使用的是management线程池,模拟执行通常是短时间的、低频的任务,不需要高并发支持而且为了不影响实际的文档处理或其他重要任务。
- 另外为了避免Grok Processor运行时间过长,使用了Generic线程做定时调度检查执行时间
- Processor都是异步执行的,实际执行线程池取决于调用上下文(如 write 或 management)
- IngestMetric
- 通过实现ReportingService接口来做到展示ingest内部的执行情况。
- GET _nodes/stats?filter_path=nodes.*.ingest 可以查看到ingest 中的每个Pipeline中的执行的次数、失败次数以及总耗时
- IngestPlugin
- Ingest支持加载自定义的Processor插件,系统内置的所有Processor以及自定义的都通过IngestService 中的Map<String, Processor.Factory> processorFactories来进行管理。
- IngestDocument
- 其包含文档的源数据,提供了修改和查询文档的字段的能力,为Processor灵活操作文档数据提供基础,在后续pipeline的执行中,也是由其的executePipeline方法驱动的。
2. Processor 实现机制
抽象工厂设计模式的应用
Processor接口设计
每个Processor都有核心方法execute,使得处理器能够以统一的方式操作 IngestDocument,并通过多态实现不同处理逻辑。
Processor.Factory的设计
Processor.Factory 是 Processor 的抽象工厂,负责动态创建处理器实例。其主要职责包括:
- 动态实例化:
- Processor create() 方法接收处理器配置并创建具体的处理器。
- 支持递归创建,例如ConditionalProcessor可以嵌套其他处理器。
- 依赖注入:
- Processor.Parameters 提供了一组服务和工具(如 ScriptService),工厂可以利用这些依赖创建复杂的Processor。
Processor.Factory的集中管理
在 IngestService 中,通过 Map<String, Processor.Factory> processorFactories 集中管理所有处理器工厂。这种管理方式提供了以下优势:
动态扩展:
- 插件可以注册自定义Processor工厂。
- 新处理器类型的注册仅需添加到 processorFactories。
组合以及装饰器设计模式的应用
Processor经典的几个类的关系如下:
CompoundProcessor是经典的组合设计模式,Pipeline这个类可以像使用单个 Processor 一样调用 CompoundProcessor,无需关注其内部具体细节。
而ConditionalProcessor 以及TrackingResultProcessor则体现了装饰器模式,在不改变原有对象的情况下扩展功能:
- ConditionalProcessor 在执行Processor前会调用evaluate方法判断是否需要执行。
- TrackingResultProcessor中decorate是为 CompoundProcessor 及其内部的 Processor 添加跟踪功能。
如何自定义Processor 插件
自定义 Processor 插件的注册方式为实现 IngestPlugin (Elasticsearch 提供不同的插件接口用来扩展不同类型的功能)的 getProcessors 方法,该方法返回一个工厂列表,IngestService 会将这些工厂注入到 processorFactories 中。
分析完代码之后,我们回到实战中来,简单起见,我们实现类似Append的Processor,但是我们这个更简单,输入的是字符串,然后我们用,分割一下将其作为数组设为值。
import org.elasticsearch.ingest.Processor;
import org.elasticsearch.plugins.IngestPlugin;
import org.elasticsearch.plugins.Plugin;
import java.util.HashMap;
import java.util.Map;
public class AddArrayProcessorPlugin extends Plugin implements IngestPlugin {
@Override
public Map<String, Processor.Factory> getProcessors(Processor.Parameters parameters) {
Map<String, Processor.Factory> processors = new HashMap<>();
processors.put(AddArrayProcessor.TYPE, new AddArrayProcessor.Factory());
return processors;
}
}import org.elasticsearch.ingest.AbstractProcessor;
import org.elasticsearch.ingest.ConfigurationUtils;
import org.elasticsearch.ingest.IngestDocument;
import org.elasticsearch.ingest.Processor;
import java.util.*;
public class AddArrayProcessor extends AbstractProcessor {
public static final String TYPE = "add_array";
public String field;
public String value;
protected AddArrayProcessor(String tag, String description, String field, String value) {
super(tag, description);
this.field = field;
this.value = value;
}
@Override
public IngestDocument execute(IngestDocument ingestDocument) throws Exception {
List valueList = new ArrayList<>(Arrays.asList(value.split(",")));
ingestDocument.setFieldValue(field, valueList);
return ingestDocument;
}
@Override
public String getType() {
return TYPE;
}
public static final class Factory implements Processor.Factory {
@Override
public Processor create(Map<String, Processor.Factory> processorFactories, String tag,
String description, Map<String, Object> config) throws Exception {
String field = ConfigurationUtils.readStringProperty(TYPE, tag, config, "field");
String value = ConfigurationUtils.readStringProperty(TYPE, tag, config, "value");
return new AddArrayProcessor(tag, description, field, value);
}
}
}打包之后,我们去install我们的Processor插件:
bin/elasticsearch-plugin install file:///home/hcb/data/data/es/data_standalone/elasticsearch-7.10.2-SNAPSHOT/AddArrayProcessor-1.0-SNAPSHOT.zip
warning: no-jdk distributions that do not bundle a JDK are deprecated and will be removed in a future release
-> Installing file:///home/hcb/data/data/es/data_standalone/elasticsearch-7.10.2-SNAPSHOT/AddArrayProcessor-1.0-SNAPSHOT.zip
-> Downloading file:///home/hcb/data/data/es/data_standalone/elasticsearch-7.10.2-SNAPSHOT/AddArrayProcessor-1.0-SNAPSHOT.zip
[=================================================] 100%
-> Installed AddArrayProcess测试一下:
POST /_ingest/pipeline/_simulate
{
"pipeline": {
"processors": [
{
"add_array": {
"field": "test_arr",
"value": "a,b,c,d,e,f"
}
}
]
},
"docs": [
{
"_index": "test",
"_id": "1",
"_source": {
"field": "value"
}
}
]
}
docs结果:
"_source" : {
"field" : "value",
"test_arr" : [
"a",
"b",
"c",
"d",
"e",
"f"
]
}3. Pipeline设计
如何管理Pipeline
在IngestServcie中有一个Map存储所有的Pipeline实例,private volatile Map<String, PipelineHolder> pipelines = Collections.emptyMap();
这里并没有将Pipeline实例存储在IngestMetadata,这样做的原因有2个:
- 在 Elasticsearch 的启动过程中,插件和节点服务的初始化发生在 ClusterState 加载之后, 只有等所有插件完成加载后,所有的Processor工厂才会被注册到系统中,这意味着在集群状态初始化之前,Processor工厂并不可用。
- ClusterState 中的元数据结构是静态注册的,即在类加载时已经确定,如果要将运行时示例存储进去,必须改变 ClusterState 的元数据结构存储格式,这个很不方便维护,而且这在集群状态同步的时候也会带来不必要的序列化以及反序列化。
所以Pipeline的管理逻辑是:
- ClusterState 中的IngestMetadata 只存储 JSON 格式的管道定义,描述 Pipeline 的配置(例如,包含哪些 Processor,它们的参数等)。
- IngestService 中维护的运行时实例,将 JSON 配置解析为完整的 Pipeline 对象,包括处理器链
在集群变更时, pipeline的CRUD的实现在innerUpdatePipelines方法中 。
责任链设计模式的应用
管道的执行通过IngestDocument的org.elasticsearch.ingest.IngestDocument#executePipeline 去驱动,每个文档的每个Pipeline都会进入到这个函数, 而每个Pipeline有组装好的CompoundProcessor,实际的链式调用是在CompoundProcessor中。
简图大致如下:
这里拿其和Zookeeper(3.6.3)中RequestProcessor 做一些对比:
| 特点 | ES中的CompoundProcessor | Zookeeper中RequestProcessor |
|---|---|---|
| 链的存储定义 | 由两条列表组成,分别保存正常流程以及失败流程的Processor列表。 | 固定的链式结构。 |
| 异步执行 | 支持异步回调,可以异步执行链中的处理器。 | 同步执行 。 |
| 失败处理 | 提供专门的 onFailureProcessors 作为失败处理链。如果不忽略异常并且onFailureProcessors 不为空则会执行失败处理链逻辑。 | 没有专门的失败处理链,异常直接交由上层捕获。 |
| 可配置性 | 可动态调整处理器链和配置(如 ignoreFailure)。 | 代码中写死,无法配置 |
这里并没有说Zookeeper的设计就差于Elasticsearch, 只是设计目标有所不同,RequestProcessor就是适合集中式的强一致、其中Processor并不需要灵活变化,而CompoundProcessor就是适合高并发而Procesor灵活变化场景。
4. Ingest实战建议
回到实战中来,这里结合目前所分析的内容给出相应的实战建议。
- 建立监控
- 对于关键的Piepline,我们需要通过GET _nodes/stats?filter_path=nodes.*.ingest 获取其运行状况,识别延迟或失败的 Processor。
- 文档写入的时候使用的是write线程池,我们也需要监控GET _nodes/stats?filter_path=nodes.*.thread_pool.write 的queue和write_rejections 判断需要扩展线程池。
- 优化Processor
- 减少高开销操作,优先使用内置 Processor,比如script Processor 可适时替换set, append,避免过度复杂的正则表达式或嵌套逻辑。
- 自定义的Processor尽量优化,比如如果涉及查询外部系统可考虑引入缓存。
- 建立单独的Ingest节点
- 如果有大量的Pipeline需要执行,则可以考虑增加专用 Ingest 节点,避免与数据节点争夺资源。
5. 漏洞&&修复分析
这里分析7.10.2版本Ingest模块存在的漏洞以及官方是如何修复的。
CVE-2021-22144
https://discuss.elastic.co/t/elasticsearch-7-13-3-and-6-8-17-security-update/278100
Elasticsearch Grok 解析器中发现了一个不受控制的递归漏洞,该漏洞可能导致拒绝服务攻击。能够向 Elasticsearch 提交任意查询的用户可能会创建恶意 Grok 查询,从而导致 Elasticsearch 节点崩溃。
漏洞复现
发起这个请求:
- patterns: 处理字段时使用的 Grok 模式,这里设置为 %{INT}。
- pattern_definitions: 定义自定义 Grok 模式,这里故意让 INT 模式递归引用自身,导致循环引用问题。
POST /_ingest/pipeline/_simulate
{
"pipeline": {
"processors": [
{
"grok": {
"field": "message",
"patterns": [
"%{INT}"
],
"pattern_definitions": {
"INT": "%{INT}"
}
}
}
]
},
"docs": [
{
"_source": {
"message": "test"
}
}
]
}
当执行之后会使得节点直接StackOverflow中止进程。
修复逻辑
这个问题的关键在于原先的逻辑中,只会对间接的递归引用(pattern1 => pattern2 => pattern3 => pattern1)做了检测,但是没有对直接的自引用(pattern1 => pattern1 )做检测。
private void forbidCircularReferences() {
// 这个是增加的逻辑,检测直接的自引用
for (Map.Entry<String, String> entry : patternBank.entrySet()) {
if (patternReferencesItself(entry.getValue(), entry.getKey())) {
throw new IllegalArgumentException("circular reference in pattern [" + entry.getKey() + "][" + entry.getValue() + "]");
}
}
// 间接递归引用检测(这个是原先的逻辑)
for (Map.Entry<String, String> entry : patternBank.entrySet()) {
String name = entry.getKey();
String pattern = entry.getValue();
innerForbidCircularReferences(name, new ArrayList<>(), pattern);
}
}CVE-2023-46673
https://discuss.elastic.co/t/elasticsearch-7-17-14-8-10-3-security-update-esa-2023-24/347708
漏洞复现
尝试了很多已有的Processor都没有复现,我们这使用自定义的Processor来复现,将之前的自定义AddArrayProcessor加一行代码:
@Override
public IngestDocument execute(IngestDocument ingestDocument) throws Exception {
List valueList = new ArrayList<>(Arrays.asList(value.split(",")));
valueList.add(valueList); // 增加的代码
ingestDocument.setFieldValue(field, valueList);
return ingestDocument;
}重新编译再安装插件之后,执行改Processor 将会StackOverflow。
修复逻辑
这个问题的关键在于在IngestDocument的deepCopyMap的方法之前没有判断这样的无限引用的情况:
那么在此之前做一个检测就好了,这个方法在原本的ES代码中就存在:org.elasticsearch.common.util.CollectionUtils#ensureNoSelfReferences(java.lang.Object, java.lang.String) ,其利用 IdentityHashMap 记录已访问对象的引用,检测并防止对象间的循环引用。
CVE-2024-23450
https://discuss.elastic.co/t/elasticsearch-8-13-0-7-17-19-security-update-esa-2024-06/356314
漏洞复现
虽然我们的索引只有2个Pipeline的配置,但是由于Pipeline Processor的存在,所以实际上一个文档其实能被很多Pipeline处理,当需要执行足够多个的pipline个数时,则会发生StackOverflow。
修复逻辑
这个问题的关键在于对Pipeline的个数并没有限制,添加一个配置项,当超出该个数则直接抛出异常。
public static final int MAX_PIPELINES = Integer.parseInt(System.getProperty("es.ingest.max_pipelines", "100"));IngestDocument的org.elasticsearch.ingest.IngestDocument#executePipeline 添加逻辑:
public void executePipeline(Pipeline pipeline, BiConsumer<IngestDocument, Exception> handler) {
if (executedPipelines.size() >= MAX_PIPELINES) {
handler.accept(
null,
new IllegalStateException(PIPELINE_TOO_MANY_ERROR_MESSAGE + MAX_PIPELINES + " nested pipelines")
);
} 思考: 这里判断pipeline是否超出100个限制是用已经执行的pipeline个数来计算的。 假设已经超出100个pipeline,那这100个pipeline是会白跑的, 如果能在真正执行之前分析需要执行的Pipeline个数会更好。
6. 总结
Ingest 模块作为 Elasticsearch 数据处理流程的重要组成部分,提供了灵活的管道化能力,使得用户能够在数据写入前进行丰富的预处理操作。然而,在实际场景中,Ingest 模块也面临性能瓶颈、资源竞争等挑战,需要结合业务需求和系统现状进行精细化调优,通过优化 Processor 执行效率、合理规划集群架构以及增强监控与诊断手段,我们可以充分释放 Ingest 模块的能力,提升 Elasticsearch 的整体数据处理能力。
收起阅读 »【第5期】搜索客 Meetup | 最强开源 Elasticsearch 多集群管理工具 INFINI Console - 动手实战
本次活动由 搜索客社区、极限科技(INFINI Labs)联合举办,最近 INFINI Labs 重磅宣布旗下的产品 Console/Gateway/Agent/Framework 等在 Github 上开源了,其中 INFINI Console 作为 一款非常轻量级的多集群、跨版本的搜索基础设施统一管控工具,受到广大用户喜爱。借此开源机会,我们邀请到 INFINI Labs 的技术专家罗厚付老师跟大家分享介绍 Console 并动手实战,手把手教你从源码编译 -> 安装部署 -> 上手体验全攻略,欢迎预约直播观看~
活动主题:最强开源 Elasticsearch 多集群管理工具 INFINI Console - 动手实战
活动时间:2024 年 12 月 20 日 19:00-20:00(周三)
活动形式:微信视频号(极限实验室)直播
报名方式:关注或扫码海报中的二维码进行预约

嘉宾介绍
罗厚付,极限科技技术专家,拥有多年安全风控及大数据系统架构经验。现任极限科技云上产品设计与研发负责人,主导过多个核心产品的设计与落地。日常负责运维超大规模 ES 集群(800+节点/1PB+数据)。
主题摘要
INFINI Labs Console/Gateway/Agent/Framework 开源后,如何在本地搭建开发环境,并运行起来,使用 INFINI Easysearch 进行指标存储,使用 INFINI Console/Agent 对 Ealsticsearch 进行指标采集。
参与有奖
本次直播活动将设有福袋抽奖环节,参与就有机会获得 INFINI Labs 周边纪念品,包括 T 恤、鸭舌帽、咖啡杯、指甲刀套件等等(图片仅供参考,款式、颜色与尺码随机)。

活动交流
本活动设有 Meetup 技术交流群,可添加小助手微信拉群,与更多小伙伴一起学习交流。

Meetup 讲师招募

搜索客社区 Meetup 的成功举办,离不开社区小伙伴的热情参与。目前社区讲师招募计划也在持续进行中,我们诚挚邀请各位技术大咖、行业精英踊跃提交演讲议题,与大家分享您的经验。
讲师报名链接:http://cfp.searchkit.cn
或扫描下方二维码,立刻报名成为讲师!

Meetup 活动聚焦 AI 与搜索领域的最新动态,以及数据实时搜索分析、向量检索、技术实践与案例分析、日志分析、安全等领域的深度探讨。
我们热切期待您的精彩分享!
往期回顾
- 【第 4 期】搜索客 Meetup | INFINI Pizza 网站 SVG 动画这么炫,我教你啊!
- 【第 3 期】搜索客 Meetup | Elasticsearch 的代码结构和写入查询流程的解读 - 下篇
- 【第 2 期】搜索客 Meetup | Elasticsearch 的代码结构和写入查询流程的解读 - 上篇
- 【第 1 期】搜索客 Meetup | Easysearch 结合大模型实现 RAG
关于极限科技(INFINI Labs)

极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
本次活动由 搜索客社区、极限科技(INFINI Labs)联合举办,最近 INFINI Labs 重磅宣布旗下的产品 Console/Gateway/Agent/Framework 等在 Github 上开源了,其中 INFINI Console 作为 一款非常轻量级的多集群、跨版本的搜索基础设施统一管控工具,受到广大用户喜爱。借此开源机会,我们邀请到 INFINI Labs 的技术专家罗厚付老师跟大家分享介绍 Console 并动手实战,手把手教你从源码编译 -> 安装部署 -> 上手体验全攻略,欢迎预约直播观看~
活动主题:最强开源 Elasticsearch 多集群管理工具 INFINI Console - 动手实战
活动时间:2024 年 12 月 20 日 19:00-20:00(周三)
活动形式:微信视频号(极限实验室)直播
报名方式:关注或扫码海报中的二维码进行预约
嘉宾介绍
罗厚付,极限科技技术专家,拥有多年安全风控及大数据系统架构经验。现任极限科技云上产品设计与研发负责人,主导过多个核心产品的设计与落地。日常负责运维超大规模 ES 集群(800+节点/1PB+数据)。
主题摘要
INFINI Labs Console/Gateway/Agent/Framework 开源后,如何在本地搭建开发环境,并运行起来,使用 INFINI Easysearch 进行指标存储,使用 INFINI Console/Agent 对 Ealsticsearch 进行指标采集。
参与有奖
本次直播活动将设有福袋抽奖环节,参与就有机会获得 INFINI Labs 周边纪念品,包括 T 恤、鸭舌帽、咖啡杯、指甲刀套件等等(图片仅供参考,款式、颜色与尺码随机)。
活动交流
本活动设有 Meetup 技术交流群,可添加小助手微信拉群,与更多小伙伴一起学习交流。
Meetup 讲师招募
搜索客社区 Meetup 的成功举办,离不开社区小伙伴的热情参与。目前社区讲师招募计划也在持续进行中,我们诚挚邀请各位技术大咖、行业精英踊跃提交演讲议题,与大家分享您的经验。
讲师报名链接:http://cfp.searchkit.cn
或扫描下方二维码,立刻报名成为讲师!
Meetup 活动聚焦 AI 与搜索领域的最新动态,以及数据实时搜索分析、向量检索、技术实践与案例分析、日志分析、安全等领域的深度探讨。
我们热切期待您的精彩分享!
往期回顾
- 【第 4 期】搜索客 Meetup | INFINI Pizza 网站 SVG 动画这么炫,我教你啊!
- 【第 3 期】搜索客 Meetup | Elasticsearch 的代码结构和写入查询流程的解读 - 下篇
- 【第 2 期】搜索客 Meetup | Elasticsearch 的代码结构和写入查询流程的解读 - 上篇
- 【第 1 期】搜索客 Meetup | Easysearch 结合大模型实现 RAG
关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
收起阅读 »【搜索客社区日报】第1956期 (2024-12-20)
https://infinilabs.cn/blog/202 ... nt-2/
2. 从 Elastic 迁移到 Easysearch 指引
https://infinilabs.cn/blog/202 ... arch/
3. Elasticsearch filter context 的使用原理
https://infinilabs.cn/blog/202 ... text/
4. Elasticsearch filter context 的实践案例
https://infinilabs.cn/blog/202 ... tice/
5. 百度:AIAPI 的检索架构演进 - 转向 AI 原生检索
https://my.oschina.net/u/4939618/blog/16744627
编辑:Fred
更多资讯:http://news.searchkit.cn
https://infinilabs.cn/blog/202 ... nt-2/
2. 从 Elastic 迁移到 Easysearch 指引
https://infinilabs.cn/blog/202 ... arch/
3. Elasticsearch filter context 的使用原理
https://infinilabs.cn/blog/202 ... text/
4. Elasticsearch filter context 的实践案例
https://infinilabs.cn/blog/202 ... tice/
5. 百度:AIAPI 的检索架构演进 - 转向 AI 原生检索
https://my.oschina.net/u/4939618/blog/16744627
编辑:Fred
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第1952期 (2024-12-16)
https://infinilabs.cn/blog/202 ... nt-1/
2、如何让 localStorage 数据实现实时响应
https://infinilabs.cn/blog/2024/localStorage/
3、如何实现一个充满科技感的官网(一)
https://infinilabs.cn/blog/202 ... e-en/
4、「AI学习三步法:实践」用Coze免费打造自己的微信AI机器人
https://tinyurl.com/bp5kwjbf
5、Elasticsearch的未来:向量搜索与AI驱动解决方案的融合
https://mp.weixin.qq.com/s/V_6aBIc6b551GEDptwV_8g
编辑:Muse
更多资讯:http://news.searchkit.cn
https://infinilabs.cn/blog/202 ... nt-1/
2、如何让 localStorage 数据实现实时响应
https://infinilabs.cn/blog/2024/localStorage/
3、如何实现一个充满科技感的官网(一)
https://infinilabs.cn/blog/202 ... e-en/
4、「AI学习三步法:实践」用Coze免费打造自己的微信AI机器人
https://tinyurl.com/bp5kwjbf
5、Elasticsearch的未来:向量搜索与AI驱动解决方案的融合
https://mp.weixin.qq.com/s/V_6aBIc6b551GEDptwV_8g
编辑:Muse
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第1955期 (2024-12-19)
https://mp.weixin.qq.com/s/2H89vOHXWyF0n8G0N8kiiA
2.开源大模型服务平台 - GPUStack,助力企业级私有部署
https://mp.weixin.qq.com/s/FcDswFWzdn8fBdJEx_f8kA
3.使用 AutoOps 排查高 CPU 使用率问题
https://www.elastic.co/search- ... -high
编辑:Se7en
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/2H89vOHXWyF0n8G0N8kiiA
2.开源大模型服务平台 - GPUStack,助力企业级私有部署
https://mp.weixin.qq.com/s/FcDswFWzdn8fBdJEx_f8kA
3.使用 AutoOps 排查高 CPU 使用率问题
https://www.elastic.co/search- ... -high
编辑:Se7en
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第1953期 (2024-12-17)
1. 我们在zendesk是怎么做语义检索的(需要梯子)
https://zendesk.engineering/se ... aa7d3
2. 构建一个简单的“或许你想找”?(需要梯子)
https://medium.com/%40andre.lu ... 0a1b5
3. 官方ES+kibana 视频教程(需要梯子)
https://www.youtube.com/watch% ... MMBta
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
1. 我们在zendesk是怎么做语义检索的(需要梯子)
https://zendesk.engineering/se ... aa7d3
2. 构建一个简单的“或许你想找”?(需要梯子)
https://medium.com/%40andre.lu ... 0a1b5
3. 官方ES+kibana 视频教程(需要梯子)
https://www.youtube.com/watch% ... MMBta
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
收起阅读 »
《ClickHouse:强大的数据分析引擎》
列式存储
列式存储是一种数据存储结构,也称为列存储或列式数据库。它将数据按列存储而非传统的按行存储。每一列的数据类型相同或者相似。
采用行式存储时,数据在磁盘上的组织结构为:
采用列式存储时,数据在磁盘上的组织结构为:
列存储在写入效率、保证数据完整性上都不如行存储,它的优势是在读取过程,不会产生冗余数据,这对数据完整性要求不高的大数据处理领域,比如互联网,犹为重要。
ClickHouse 的主要特点
高性能
快速的查询响应:能够在秒级甚至亚秒级时间内处理大规模数据的查询请求。
高效的数据压缩:采用了多种数据压缩算法,大大减少了数据存储占用的空间,同时提高了数据读取的速度。
向量化执行引擎:可以并行处理大量数据,充分利用现代硬件的优势,提高执行效率。
可扩展性
分布式架构:支持水平扩展,可以轻松地添加更多的服务器节点来处理不断增长的数据量和查询负载。
数据分片:将数据分散存储在不同的节点上,提高数据的可用性和可靠性。
丰富的数据分析功能
支持多种数据类型:包括数值、字符串、日期时间等常见数据类型,以及数组、嵌套结构等复杂数据类型。
强大的聚合函数:提供了丰富的聚合函数,如求和、平均值、最大值、最小值等,方便进行数据分析和统计。
支持 SQL 语言:用户可以使用熟悉的 SQL 语句进行数据查询和分析,降低了学习成本。
场景支持
ClickHouse的数据处理速度非常快,尤其适合于包含复杂分析查询的场景
适合场景
日志和事件数据:由于ClickHouse的处理速度,它可以作为实时数据分析的工具。
监控和报警系统:ClickHouse可以用于快速查询和显示监控数据。
交互式查询:由于其快速的查询速度,ClickHouse可以作为数据科学家进行交互式探索的工具。
数据仓库:ClickHouse可以作为数据仓库的一种替代方法,用于快速查询和分析。
不适合场景
事务处理:ClickHouse不支持事务处理。
强一致性:ClickHouse不保证数据的强一致性。
低延迟的更新:ClickHouse不适合于需要实时或近实时更新数据的场景。
高度模式化的数据:ClickHouse对模式的灵活性不如关系型数据库。
小结
总之,ClickHouse 是一款功能强大的数据库管理系统,适用于大规模数据分析和处理场景。通过了解其特点和基础知识,用户可以更好地利用 ClickHouse 来满足自己的数据分析需求
列式存储
列式存储是一种数据存储结构,也称为列存储或列式数据库。它将数据按列存储而非传统的按行存储。每一列的数据类型相同或者相似。
采用行式存储时,数据在磁盘上的组织结构为:
采用列式存储时,数据在磁盘上的组织结构为:
列存储在写入效率、保证数据完整性上都不如行存储,它的优势是在读取过程,不会产生冗余数据,这对数据完整性要求不高的大数据处理领域,比如互联网,犹为重要。
ClickHouse 的主要特点
高性能
快速的查询响应:能够在秒级甚至亚秒级时间内处理大规模数据的查询请求。
高效的数据压缩:采用了多种数据压缩算法,大大减少了数据存储占用的空间,同时提高了数据读取的速度。
向量化执行引擎:可以并行处理大量数据,充分利用现代硬件的优势,提高执行效率。
可扩展性
分布式架构:支持水平扩展,可以轻松地添加更多的服务器节点来处理不断增长的数据量和查询负载。
数据分片:将数据分散存储在不同的节点上,提高数据的可用性和可靠性。
丰富的数据分析功能
支持多种数据类型:包括数值、字符串、日期时间等常见数据类型,以及数组、嵌套结构等复杂数据类型。
强大的聚合函数:提供了丰富的聚合函数,如求和、平均值、最大值、最小值等,方便进行数据分析和统计。
支持 SQL 语言:用户可以使用熟悉的 SQL 语句进行数据查询和分析,降低了学习成本。
场景支持
ClickHouse的数据处理速度非常快,尤其适合于包含复杂分析查询的场景
适合场景
日志和事件数据:由于ClickHouse的处理速度,它可以作为实时数据分析的工具。
监控和报警系统:ClickHouse可以用于快速查询和显示监控数据。
交互式查询:由于其快速的查询速度,ClickHouse可以作为数据科学家进行交互式探索的工具。
数据仓库:ClickHouse可以作为数据仓库的一种替代方法,用于快速查询和分析。
不适合场景
事务处理:ClickHouse不支持事务处理。
强一致性:ClickHouse不保证数据的强一致性。
低延迟的更新:ClickHouse不适合于需要实时或近实时更新数据的场景。
高度模式化的数据:ClickHouse对模式的灵活性不如关系型数据库。
小结
总之,ClickHouse 是一款功能强大的数据库管理系统,适用于大规模数据分析和处理场景。通过了解其特点和基础知识,用户可以更好地利用 ClickHouse 来满足自己的数据分析需求 收起阅读 »
【搜索客社区日报】第1954期 (2024-12-18)
https://towardsdatascience.com ... ebfff
2.日志分析大比拼:Elasticsearch VS Apache Doris
https://blog.devgenius.io/log- ... bd2a1
3.什么是语义重排(semantic rerank)?如何使用它?
https://cloud.tencent.com/deve ... 76629
4.介绍 Elastic Rerank:Elastic 的新语义重排模型
https://cloud.tencent.com/deve ... 76632
5.深入探讨高质量重排器及其性能优化:Elastic Rerank模型的实战评估
https://cloud.tencent.com/deve ... 77172
编辑:kin122
更多资讯:http://news.searchkit.cn
https://towardsdatascience.com ... ebfff
2.日志分析大比拼:Elasticsearch VS Apache Doris
https://blog.devgenius.io/log- ... bd2a1
3.什么是语义重排(semantic rerank)?如何使用它?
https://cloud.tencent.com/deve ... 76629
4.介绍 Elastic Rerank:Elastic 的新语义重排模型
https://cloud.tencent.com/deve ... 76632
5.深入探讨高质量重排器及其性能优化:Elastic Rerank模型的实战评估
https://cloud.tencent.com/deve ... 77172
编辑:kin122
更多资讯:http://news.searchkit.cn 收起阅读 »
Easysearch Java SDK 2.0.x 使用指南(一)

各位 Easysearch 的小伙伴们,我们前一阵刚把 easysearch-client 更新到了 2.0.2 版本!借此详细介绍下新版客户端的使用。
新版客户端和 1.0 版本相比,完全重构,抛弃了旧版客户端的一些历史包袱,从里到外都焕然一新!不管是刚入门的小白还是经验丰富的老司机,2.0.x 客户端都能让你开发效率蹭蹭往上涨!
到底有啥新东西?
- 更轻更快: 以前的版本依赖了一堆乱七八糟的东西,现在好了,我们把那些没用的都砍掉了,客户端变得更苗条,性能也杠杠的!
- 类型安全,告别迷糊: 常用的 Easysearch API 现在都配上了强类型的请求和响应对象,再也不用担心写错参数类型了,代码也更好看了,维护起来也更省心!
- 同步异步,想咋用咋用: 所有 API 都支持同步和异步两种调用方式,不管是啥场景,都能轻松应对!
- 构建查询,跟搭积木一样简单: 我们用了流式构建器和函数式编程,构建复杂查询的时候,代码写起来那叫一个流畅,看着也舒服!
- 和 Jackson 无缝对接: 可以轻松地把你的 Java 类和客户端 API 关联起来,数据转换嗖嗖的快!
快速上手
废话不多说,咱们直接上干货!这部分教你怎么快速安装和使用 easysearch-client 2.0.2 客户端,还会演示一些基本操作。
安装
easysearch-client 2.0.2 已经上传到 Maven 中央仓库了,加到你的项目里超级方便。
最低要求: JDK 8 或者更高版本
依赖管理: 客户端内部用 Jackson 来处理对象映射。
Maven 项目
在你的 pom.xml 文件的 <dependencies> 里面加上这段:
<dependencies>
<dependency>
<groupId>com.infinilabs</groupId>
<artifactId>easysearch-client</artifactId>
<version>2.0.2</version>
</dependency>
</dependencies>Gradle 项目
在你的 build.gradle 文件的 dependencies 里面加上这段:
dependencies {
implementation 'com.infinilabs:easysearch-client:2.0.2'
}初始化客户端
下面这段代码演示了怎么初始化一个启用了安全通信加密和 security 的 Easysearch 客户端,看起来有点长,别慌,我们一步一步解释!
public static EasysearchClient create() throws NoSuchAlgorithmException, KeyStoreException,
KeyManagementException {
final HttpHost[] hosts = new HttpHost[]{new HttpHost("localhost", 9200, "https")};
final SSLContext sslContext = SSLContextBuilder.create()
.loadTrustMaterial(null, (chains, authType) -> true).build();
SSLIOSessionStrategy sessionStrategy = new SSLIOSessionStrategy(sslContext, NoopHostnameVerifier.INSTANCE);
final CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
credentialsProvider.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials("username", "passwowd"));
RestClient restClient = RestClient.builder(hosts)
.setHttpClientConfigCallback(httpClientBuilder ->
httpClientBuilder.setDefaultCredentialsProvider(credentialsProvider)
.setSSLStrategy(sessionStrategy)
.disableAuthCaching()
).setRequestConfigCallback(requestConfigCallback ->
requestConfigCallback.setConnectTimeout(30000).setSocketTimeout(300000))
.build();
EasysearchTransport transport = new RestClientTransport(
restClient, new JacksonJsonpMapper());
return new EasysearchClient(transport);
}这段代码,简单来说,就是:
- 连上 Easysearch: 我们要用 HTTPS 连接到本地的 9200 端口。
- 搞定证书: 这里为了方便,我们信任了所有证书(注意!生产环境一定要配置好你们自己的证书)。
- 填上用户名密码: 这里需要填上你的用户名和密码。
- 设置连接参数: 设置了连接超时时间(30 秒)和读取超时时间(300 秒)。
- 创建客户端: 最后,我们就创建好了一个
EasysearchClient实例,可以开始干活了!
举个栗子:批量操作
下面的例子演示了怎么用 bulk API 来批量索引数据:
public static void bulk() throws Exception {
String json2 = "{"
+ " \"@timestamp\": \"2023-01-08T22:50:13.059Z\","
+ " \"agent\": {"
+ " \"version\": \"7.3.2\","
+ " \"type\": \"filebeat\","
+ " \"ephemeral_id\": \"3ff1f2c8-1f7f-48c2-b560-4272591b8578\","
+ " \"hostname\": \"ba-0226-msa-fbl-747db69c8d-ngff6\""
+ " }"
+ "}";
EasysearchClient client = create();
BulkRequest.Builder br = new BulkRequest.Builder();
br.index("test1");
for (int i = 0; i < 10; i++) {
BulkOperation.Builder builder = new BulkOperation.Builder();
IndexOperation.Builder indexBuilder = new IndexOperation.Builder();
builder.index(indexBuilder.document(JsonData.fromJson(json2)).build());
br.operations(builder.build());
}
for (int i = 0; i < 10; i++) {
BulkOperation.Builder builder = new BulkOperation.Builder();
IndexOperation.Builder indexBuilder = new IndexOperation.Builder();
indexBuilder.document(JsonData.fromJson(json2)).index("test2");
builder.index(indexBuilder.build());
br.operations(builder.build());
}
for (int i = 0; i < 10; i++) {
Map<String, Object> map = new HashMap<>();
map.put("@timestamp", "2023-01-08T22:50:13.059Z");
map.put("field1", "value1");
IndexOperation.Builder indexBuilder = new IndexOperation.Builder();
indexBuilder.document(map).index("test3");
br.operations(new BulkOperation(indexBuilder.build()));
}
BulkResponse bulkResponse = client.bulk(br.build());
if (bulkResponse.errors()) {
for (BulkResponseItem item : bulkResponse.items()) {
System.out.println(item.toString());
}
}
client._transport().close();
}这个例子里,我们一口气把数据批量索引到了 test1、test2 和 test3 这三个索引里,
并且展示了三种在 bulk API 中构建 IndexOperation 的方式,虽然它们最终都能实现将文档索引到 Easysearch,但在使用场景和灵活性上还是有一些区别的:
这段代码的核心是利用 BulkRequest.Builder 来构建一个批量请求,并通过 br.operations(...) 方法添加多个操作。而每个操作,在这个例子里,都是一个 IndexOperation,也就是索引一个文档。IndexOperation 可以通过 IndexOperation.Builder 来创建。
三种方式的区别主要体现在如何构建 IndexOperation 里的 document 部分,也就是要索引的文档内容。
第一种方式:使用 JsonData.fromJson(json2) 且不指定索引。
特点:
使用 JsonData.fromJson(json2) 将一个 JSON 字符串直接转换成 JsonData 对象作为文档内容。
这里没有在 IndexOperation.Builder 上调用 index() 方法来指定索引名称。由于没有在每个 IndexOperation 中指定索引,这个索引名称将回退到 BulkRequest.Builder 上设置的索引,即 br.index("test1"),所以这 10 个文档都会被索引到 test1。
当你需要将一批相同结构的 JSON 文档索引到同一个索引时,这种方式比较简洁。
第二种方式:使用 JsonData.fromJson(json2) 并指定索引
特点:
同样使用 JsonData.fromJson(json2) 将 JSON 字符串转换成 JsonData 对象。
关键区别在于,这里在 IndexOperation.Builder 上调用了 index("test2"),为每个操作单独指定了索引名称。
这 10 个文档会被索引到 test2,即使 BulkRequest.Builder 上设置了 index("test1") 也没用,因为 IndexOperation 里的设置优先级更高。
当你需要将一批相同结构的 JSON 文档索引到不同的索引时,就需要使用这种方式来分别指定索引。
第三种方式:使用 Map<String, Object> 并指定索引
特点:
使用 Map<String, Object> 来构建文档内容,这种方式更加灵活,可以构建任意结构的文档。
同样在 IndexOperation.Builder 上调用了 index("test3") 指定了索引名称。
使用 new BulkOperation(indexBuilder.build()) 代替之前的 builder.index(indexBuilder.build()), 这是等价的。
这 10 个文档会被索引到 test3。
当你需要索引的文档结构不固定,或者你需要动态构建文档内容时,使用 Map 是最佳选择。例如,你可以根据不同的业务逻辑,往 Map 里添加不同的字段。
总结
这次 easysearch-client 2.0.x Java 客户端的更新真的很给力,强烈建议大家升级体验!相信我,用了新版客户端,你的开发效率绝对会提升一大截!
想要了解更多?
-
客户端 Maven 地址: https://mvnrepository.com/artifact/com.infinilabs/easysearch-client/2.0.2
- 更详细的文档和示例代码在 官网 持续更新中,请随时关注!
大家有啥问题或者建议,也欢迎随时反馈!
作者:张磊,极限科技(INFINI Labs)搜索引擎研发负责人,对 Elasticsearch 和 Lucene 源码比较熟悉,目前主要负责公司的 Easysearch 产品的研发以及客户服务工作。
各位 Easysearch 的小伙伴们,我们前一阵刚把 easysearch-client 更新到了 2.0.2 版本!借此详细介绍下新版客户端的使用。
新版客户端和 1.0 版本相比,完全重构,抛弃了旧版客户端的一些历史包袱,从里到外都焕然一新!不管是刚入门的小白还是经验丰富的老司机,2.0.x 客户端都能让你开发效率蹭蹭往上涨!
到底有啥新东西?
- 更轻更快: 以前的版本依赖了一堆乱七八糟的东西,现在好了,我们把那些没用的都砍掉了,客户端变得更苗条,性能也杠杠的!
- 类型安全,告别迷糊: 常用的 Easysearch API 现在都配上了强类型的请求和响应对象,再也不用担心写错参数类型了,代码也更好看了,维护起来也更省心!
- 同步异步,想咋用咋用: 所有 API 都支持同步和异步两种调用方式,不管是啥场景,都能轻松应对!
- 构建查询,跟搭积木一样简单: 我们用了流式构建器和函数式编程,构建复杂查询的时候,代码写起来那叫一个流畅,看着也舒服!
- 和 Jackson 无缝对接: 可以轻松地把你的 Java 类和客户端 API 关联起来,数据转换嗖嗖的快!
快速上手
废话不多说,咱们直接上干货!这部分教你怎么快速安装和使用 easysearch-client 2.0.2 客户端,还会演示一些基本操作。
安装
easysearch-client 2.0.2 已经上传到 Maven 中央仓库了,加到你的项目里超级方便。
最低要求: JDK 8 或者更高版本
依赖管理: 客户端内部用 Jackson 来处理对象映射。
Maven 项目
在你的 pom.xml 文件的 <dependencies> 里面加上这段:
<dependencies>
<dependency>
<groupId>com.infinilabs</groupId>
<artifactId>easysearch-client</artifactId>
<version>2.0.2</version>
</dependency>
</dependencies>Gradle 项目
在你的 build.gradle 文件的 dependencies 里面加上这段:
dependencies {
implementation 'com.infinilabs:easysearch-client:2.0.2'
}初始化客户端
下面这段代码演示了怎么初始化一个启用了安全通信加密和 security 的 Easysearch 客户端,看起来有点长,别慌,我们一步一步解释!
public static EasysearchClient create() throws NoSuchAlgorithmException, KeyStoreException,
KeyManagementException {
final HttpHost[] hosts = new HttpHost[]{new HttpHost("localhost", 9200, "https")};
final SSLContext sslContext = SSLContextBuilder.create()
.loadTrustMaterial(null, (chains, authType) -> true).build();
SSLIOSessionStrategy sessionStrategy = new SSLIOSessionStrategy(sslContext, NoopHostnameVerifier.INSTANCE);
final CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
credentialsProvider.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials("username", "passwowd"));
RestClient restClient = RestClient.builder(hosts)
.setHttpClientConfigCallback(httpClientBuilder ->
httpClientBuilder.setDefaultCredentialsProvider(credentialsProvider)
.setSSLStrategy(sessionStrategy)
.disableAuthCaching()
).setRequestConfigCallback(requestConfigCallback ->
requestConfigCallback.setConnectTimeout(30000).setSocketTimeout(300000))
.build();
EasysearchTransport transport = new RestClientTransport(
restClient, new JacksonJsonpMapper());
return new EasysearchClient(transport);
}这段代码,简单来说,就是:
- 连上 Easysearch: 我们要用 HTTPS 连接到本地的 9200 端口。
- 搞定证书: 这里为了方便,我们信任了所有证书(注意!生产环境一定要配置好你们自己的证书)。
- 填上用户名密码: 这里需要填上你的用户名和密码。
- 设置连接参数: 设置了连接超时时间(30 秒)和读取超时时间(300 秒)。
- 创建客户端: 最后,我们就创建好了一个
EasysearchClient实例,可以开始干活了!
举个栗子:批量操作
下面的例子演示了怎么用 bulk API 来批量索引数据:
public static void bulk() throws Exception {
String json2 = "{"
+ " \"@timestamp\": \"2023-01-08T22:50:13.059Z\","
+ " \"agent\": {"
+ " \"version\": \"7.3.2\","
+ " \"type\": \"filebeat\","
+ " \"ephemeral_id\": \"3ff1f2c8-1f7f-48c2-b560-4272591b8578\","
+ " \"hostname\": \"ba-0226-msa-fbl-747db69c8d-ngff6\""
+ " }"
+ "}";
EasysearchClient client = create();
BulkRequest.Builder br = new BulkRequest.Builder();
br.index("test1");
for (int i = 0; i < 10; i++) {
BulkOperation.Builder builder = new BulkOperation.Builder();
IndexOperation.Builder indexBuilder = new IndexOperation.Builder();
builder.index(indexBuilder.document(JsonData.fromJson(json2)).build());
br.operations(builder.build());
}
for (int i = 0; i < 10; i++) {
BulkOperation.Builder builder = new BulkOperation.Builder();
IndexOperation.Builder indexBuilder = new IndexOperation.Builder();
indexBuilder.document(JsonData.fromJson(json2)).index("test2");
builder.index(indexBuilder.build());
br.operations(builder.build());
}
for (int i = 0; i < 10; i++) {
Map<String, Object> map = new HashMap<>();
map.put("@timestamp", "2023-01-08T22:50:13.059Z");
map.put("field1", "value1");
IndexOperation.Builder indexBuilder = new IndexOperation.Builder();
indexBuilder.document(map).index("test3");
br.operations(new BulkOperation(indexBuilder.build()));
}
BulkResponse bulkResponse = client.bulk(br.build());
if (bulkResponse.errors()) {
for (BulkResponseItem item : bulkResponse.items()) {
System.out.println(item.toString());
}
}
client._transport().close();
}这个例子里,我们一口气把数据批量索引到了 test1、test2 和 test3 这三个索引里,
并且展示了三种在 bulk API 中构建 IndexOperation 的方式,虽然它们最终都能实现将文档索引到 Easysearch,但在使用场景和灵活性上还是有一些区别的:
这段代码的核心是利用 BulkRequest.Builder 来构建一个批量请求,并通过 br.operations(...) 方法添加多个操作。而每个操作,在这个例子里,都是一个 IndexOperation,也就是索引一个文档。IndexOperation 可以通过 IndexOperation.Builder 来创建。
三种方式的区别主要体现在如何构建 IndexOperation 里的 document 部分,也就是要索引的文档内容。
第一种方式:使用 JsonData.fromJson(json2) 且不指定索引。
特点:
使用 JsonData.fromJson(json2) 将一个 JSON 字符串直接转换成 JsonData 对象作为文档内容。
这里没有在 IndexOperation.Builder 上调用 index() 方法来指定索引名称。由于没有在每个 IndexOperation 中指定索引,这个索引名称将回退到 BulkRequest.Builder 上设置的索引,即 br.index("test1"),所以这 10 个文档都会被索引到 test1。
当你需要将一批相同结构的 JSON 文档索引到同一个索引时,这种方式比较简洁。
第二种方式:使用 JsonData.fromJson(json2) 并指定索引
特点:
同样使用 JsonData.fromJson(json2) 将 JSON 字符串转换成 JsonData 对象。
关键区别在于,这里在 IndexOperation.Builder 上调用了 index("test2"),为每个操作单独指定了索引名称。
这 10 个文档会被索引到 test2,即使 BulkRequest.Builder 上设置了 index("test1") 也没用,因为 IndexOperation 里的设置优先级更高。
当你需要将一批相同结构的 JSON 文档索引到不同的索引时,就需要使用这种方式来分别指定索引。
第三种方式:使用 Map<String, Object> 并指定索引
特点:
使用 Map<String, Object> 来构建文档内容,这种方式更加灵活,可以构建任意结构的文档。
同样在 IndexOperation.Builder 上调用了 index("test3") 指定了索引名称。
使用 new BulkOperation(indexBuilder.build()) 代替之前的 builder.index(indexBuilder.build()), 这是等价的。
这 10 个文档会被索引到 test3。
当你需要索引的文档结构不固定,或者你需要动态构建文档内容时,使用 Map 是最佳选择。例如,你可以根据不同的业务逻辑,往 Map 里添加不同的字段。
总结
这次 easysearch-client 2.0.x Java 客户端的更新真的很给力,强烈建议大家升级体验!相信我,用了新版客户端,你的开发效率绝对会提升一大截!
想要了解更多?
-
客户端 Maven 地址: https://mvnrepository.com/artifact/com.infinilabs/easysearch-client/2.0.2
- 更详细的文档和示例代码在 官网 持续更新中,请随时关注!
大家有啥问题或者建议,也欢迎随时反馈!
收起阅读 »作者:张磊,极限科技(INFINI Labs)搜索引擎研发负责人,对 Elasticsearch 和 Lucene 源码比较熟悉,目前主要负责公司的 Easysearch 产品的研发以及客户服务工作。
【搜索客社区日报】第1951期 (2024-12-13)
https://mp.weixin.qq.com/s/9voA_HVAnp3DO4RKkr85qQ
2、如何平衡向量检索速度和精度?深度解读 HNSW 算法
https://mp.weixin.qq.com/s/JECoGeO27L1IHdseDBHmow
3、Elasticsearch 进阶篇(三):ik 分词器的使用与项目应用
https://blog.csdn.net/Tingfeng ... 15124
4、【老杨玩搜索】12. Easysearch 页面-multi_match | 从零开始实现页面搜索功能
https://www.bilibili.com/video/BV12E2JYsEUS
编辑:Fred
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/9voA_HVAnp3DO4RKkr85qQ
2、如何平衡向量检索速度和精度?深度解读 HNSW 算法
https://mp.weixin.qq.com/s/JECoGeO27L1IHdseDBHmow
3、Elasticsearch 进阶篇(三):ik 分词器的使用与项目应用
https://blog.csdn.net/Tingfeng ... 15124
4、【老杨玩搜索】12. Easysearch 页面-multi_match | 从零开始实现页面搜索功能
https://www.bilibili.com/video/BV12E2JYsEUS
编辑:Fred
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第1950期 (2024-12-12)
https://mp.weixin.qq.com/s/-Jmc2So_fxsryvW_rTa2Qw
2.得物新一代可观测性架构:海量数据下的存算分离设计与实践
https://mp.weixin.qq.com/s/VwGEq-sbEToew3M_F_LvyQ
3.使用 present 工具轻松生成演示文稿
https://charly3pins.dev/blog/l ... th-go
4.京东十亿级订单系统的数据库查询性能优化之路
https://elasticsearch.cn/article/15319
编辑:Se7en
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/-Jmc2So_fxsryvW_rTa2Qw
2.得物新一代可观测性架构:海量数据下的存算分离设计与实践
https://mp.weixin.qq.com/s/VwGEq-sbEToew3M_F_LvyQ
3.使用 present 工具轻松生成演示文稿
https://charly3pins.dev/blog/l ... th-go
4.京东十亿级订单系统的数据库查询性能优化之路
https://elasticsearch.cn/article/15319
编辑:Se7en
更多资讯:http://news.searchkit.cn 收起阅读 »
十亿级订单系统的数据库查询性能优化之路
作者:京东零售 崔健
0.前言
-
系统概要:BIP采购系统用于京东采销部门向供应商采购商品,并且提供了多种创建采购单的方式以及采购单审批、回告、下传回传等业务功能
- 系统价值:向供应商采购商品增加库存,满足库存周转及客户订单的销售,供应链最重要的第一环节
1.背景
采购系统在经历了多年的迭代后,在数据库查询层面面临巨大的性能挑战。核心根因主要有以下几方面:
-
复杂查询多,历史上通过MySQL和JED承载了过多的检索过滤条件,时至今日很难推动接口使用方改变调用方式
-
数据量大,随着业务的持续发展,带来了海量的数据增长(日均150万单左右,订单主表/子表/渠道表/扩展表分别都是:6.5亿行,订单明细表/分配表:9.2亿行,日志表:60亿行)
- 数据模型复杂,订单完整数据分布在20+张表,经常需要多表join
引入的主要问题有:
-
业务层面:
-
订单列表页查询/导出体验差,性能非常依赖输入条件,尤其是在面对订单数据倾斜的时候,部分用户无法查询/导出超过半个月以上的订单
- 查询条件不合理,1.归档筛选条件,技术词汇透传到业务,导致相同周期的单子无法一键查询/导出,需要切换“是否归档”查询全部;2.无法区分“需要仓库收货”类的单子,大部分业务同事主要关注这类单子的履约情况
-
-
技术层面:
-
慢SQL多,各种多表关联复杂条件查询导致,索引、SQL已经优化道了瓶颈,经常出现数据库负载被拉高
-
大表多,难在数据库上做DDL,可能会引起核心写库负载升高、主从延迟等问题
- 模型复杂,开发、迭代成本高,查询索引字段散落在多个表中,导致查询性能下降
-
2.目标
业务层面:提升核心查询/导出体验,加强查询性能,优化不合理的查询条件
技术层面:1.减少慢SQL,降低数据库负载,提高系统稳定性;2.降低单表数据量级;3.简化数据模型
3.挑战
提升海量数据、复杂场景下的查询性能!
- 采购订单系统 VS C端销售订单系统复杂度对比:
| 对比项 | 采购订单系统 | C端订单销售系统 |
|---|---|---|
| 分库逻辑 | 使用采购单号分库 | 按用户pin分库分表 |
| 查询场景 | 面向采销、接口人、供应商、仓储运营提供包括采销员、单号、SKU、供应商、部门、配送中心、库房等多场景复杂查询 | 主要是按用户pin进行订单查询 |
| 单据所属人 | 采购单生成后,采销可以进行单据转移 | 订单生成后订单所属人不变 |
| 数据倾斜 | 单一采销或供应商存在大量采购单,并且自动补货会自动创建采购单 | C端一个用户pin下订单数量有限 |
4.方案
思路
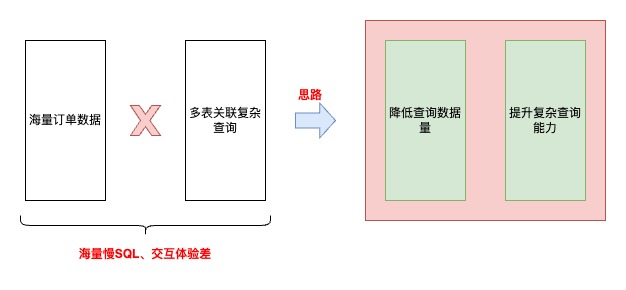
优化前
优化后

4.1 降低查询数据量
4.1.1 前期调研
基于历史数据、业务调研分析,采购订单只有8%的订单属于“需要实际送货至京东库房”的范围,也就是拥有完整订单履约流程、业务核心关注时效的。其余订单属于通过客户订单驱动,在采购系统的生命周期只有创建记录

基于以上结论,在与产品达成共识后,提出新的业务领域概念:“入库订单” ,在查询时单独异构这部分订单数据(前期也曾考虑过,直接从写入层面拆分入库订单,但是因为开发成本、改动范围被pass了)。异构这部分数据实际也参考了操作系统、中间件的核心优化思路,缓存访问频次高的热数据
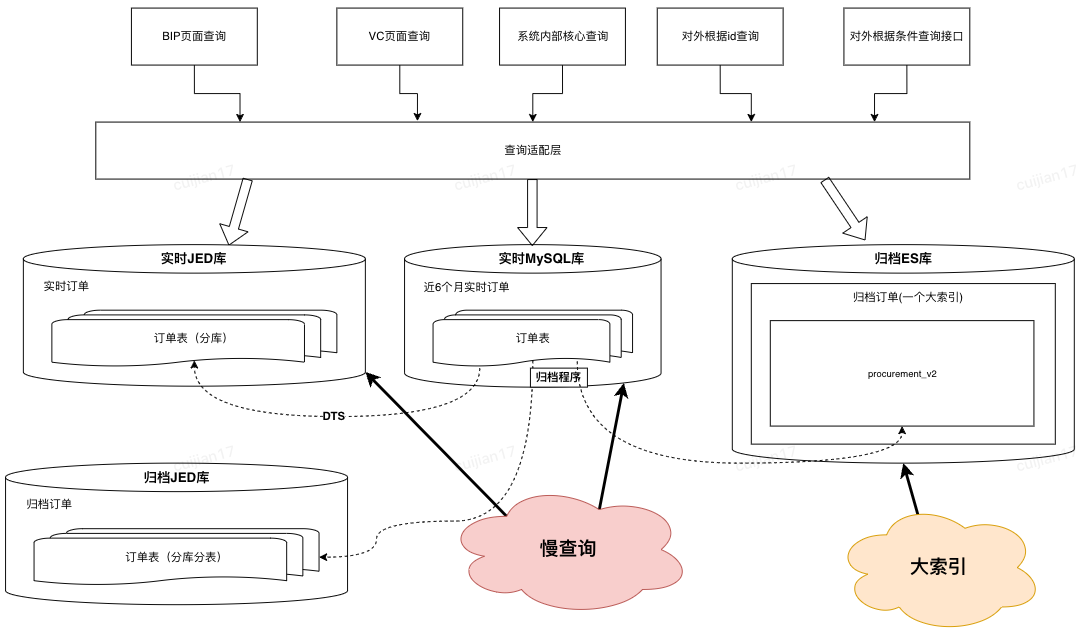
4.1.2 入库订单异构
执行流程
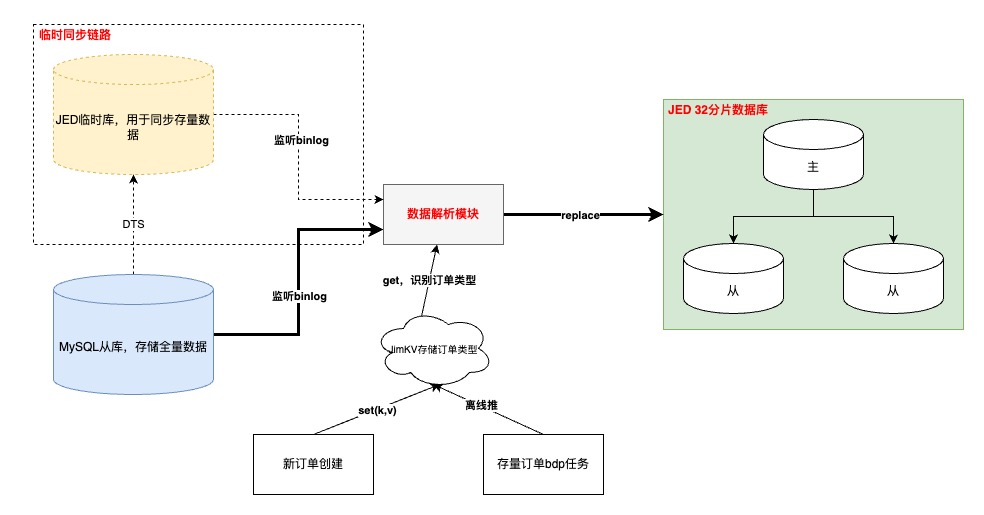
-
“入库”订单数据打标
-
增量订单在创建订单完成时写入;存量订单通过离线表推数
-
需要订单创建模块先完成改造上线,再同步历史,保证数据不丢
- 如果在【数据解析模块】处理binlog时无法及时从JimKV获取到订单标识,会补偿反查数据库并回写JimKV,提升其他表的binlog处理效率
-
-
binlog监听
-
基于公司的【数据订阅】任务,通过消费JMQ实现。其中订阅任务基于订单号进行MQ数据分区,并且在消费端配置不允许消息重试,防止消息时序错乱
- 其中,根据订单号进行各个表的MQ数据分区,第一版设计可能会引起热分区,导致消费速率变慢,基于这个问题识别到热分区主要是由于频繁更新订单明细数据导致(订单(1)->明细(N)),于是将明细相关表基于自身id进行分区,其他订单纬度表还是基于订单号。这样既不影响订单数据更新的先后顺序,也不会造成热分区、还可以保证明细数据的准确性
-
-
数据同步
-
增量数据同步可以采用源库的增量binlog进行解析即可,存量数据通过申请新库/表,进行DTS的存量+增量同步写入,完成binlog生产
- 以上是在上线前的临时链路,上线后需要切换到源库同步binlog的增量订阅任务,此时依赖“位点回拨”+“数据可重入”。位点回拨基于订阅任务的binlog时间戳,数据可重入依赖上文提到的MQ消费有序以及SQL覆盖写
-
-
数据校对
-
以表为纬度,优先统计总数,再随机抽样明细进行比对
- 目前入库订单量为稳定在5000万,全部实时订单量级6.5亿,降低92%
-
4.2 提升复杂查询能力
4.2.1 数据准备
-
考虑到异构“入库”订单到JED,虽然数据查询时效性可以有一定保障,但是在复杂查询能力以及识别“非入库”订单还没有支持
-
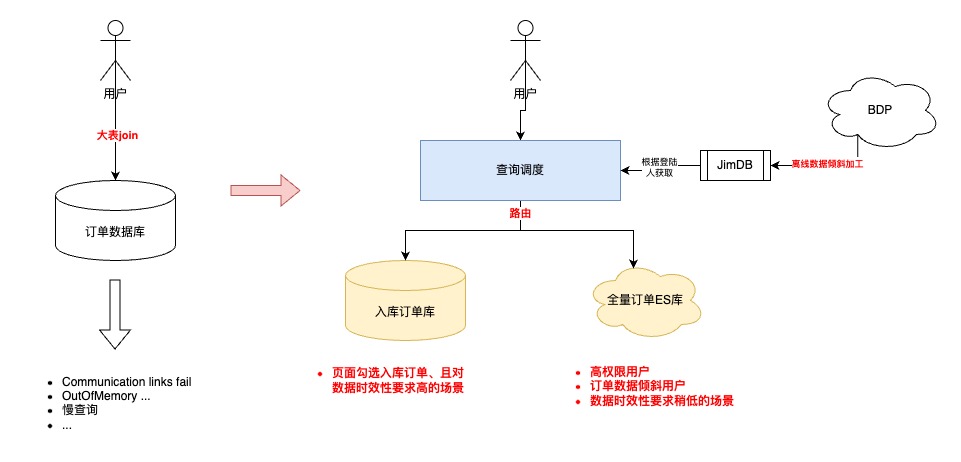
其中,“非入库”订单业务对于订单数据时效性要求并不高(1.订单创建源于客户订单;2.没有履约流程;3.无需手动操作订单关键节点)
- 所以,考虑将这部分查询能力转移到ES上
ES数据异构过程
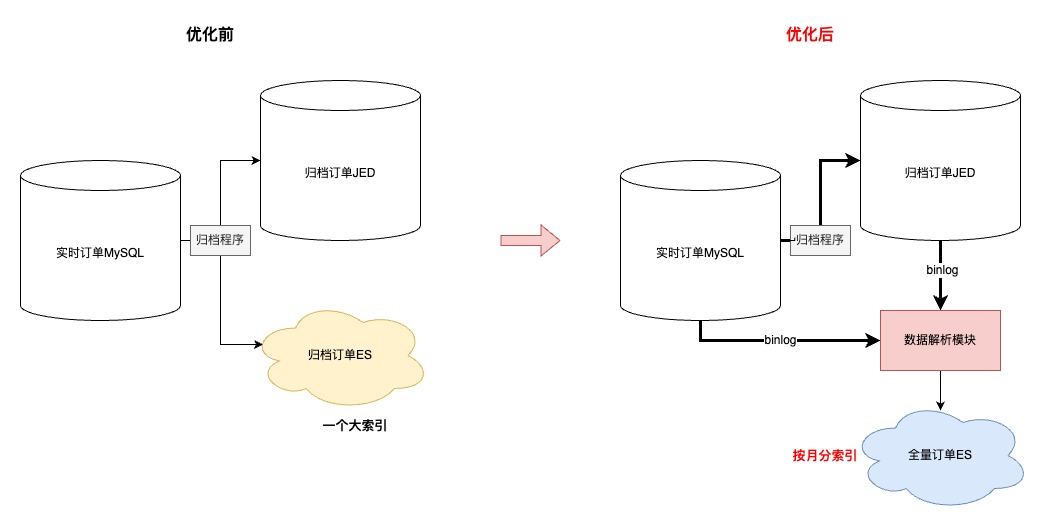
-
首先,同步到ES的数据的由“实时+归档”订单组成,其中合计20亿订单,顺带优化了先前归档ES大索引(所有订单放在同一个索引)的问题,改成基于“月份”存储订单,之所以改成月份是因为根据条件查询分两种:1.一定会有查询时间范围(最多3个月);2.指定单号查询,这种会优先检索单号对应的订单创建时间,再路由到指定索引
-
其次,简化了归档程序流程,历史方案是程序中直接写入【归档JED+归档ES】,现在优化成只写入JED,ES数据通过【数据解析模块】完成,简化归档程序的同时,提高了归档能力的时效性
-
再次,因为ES是存储全量订单,需要支持复杂条件的查询,所以在订单没有物理删除的前提下,【数据解析模块】会过滤所有delete语句,保证全量订单数据的完整性
-
接着,为了提升同步到ES数据的吞吐,在MQ消费端,主要做了两方面优化:1.会根据表和具体操作进行binlog的请求合并;2.降低对于ES内部refresh机制的依赖,将2分钟内更新到ES的数据缓存到JimKV,更新前从缓存中获取
- 最后,上文提到,同步到入库JED,有的表是根据订单号,有的表是根据自身id。那么ES这里,因为NoSQL的设计,和线程并发的问题,为了防止数据错误,只能将所有表数据根据单号路由到相同的MQ分区
4.2.2 查询调度策略设计
优化前,所有的查询请求都会直接落到数据库进行查询,可以高效查询完全取决于用户的筛选条件是否可以精准缩小数据查询范围
优化后,新增动态路由层
-
离线计算T-1的采销/供应商的订单数据倾斜,将数据倾斜情况推送到JimDB集群
- 根据登陆用户、数据延迟要求、查询数据范围,自动调度查询的数据集群,实现高性能的查询请求
查询调度
5.ES主备机制&数据监控
1.主/备ES可以通过DUCC开关,实现动态切换,提升数据可靠性
2.结合公司的业务监控,完成订单数据延迟监控(数据同步模块写入时间-订单创建时间)
3.开启消息队列积压告警
5.1 ES集群主/备机制
1:1ES集群进行互备,应急预案快速切换,保证高可用

5.2 数据监控

6.灰度上线
-
第一步,优先上线数据模块,耗费较多时间的原因:1.整体数据量级以及历史数据复杂度的问题;2.数据同步链路比较长,中间环节多
-
第二步,预发环境验证,流量回放并没有做到长周期的完全自动化,根因:1.项目周期相对紧张;2.新老集群的数据还是有一些区别,回放脚本不够完善
-
第三步,用户功能灰度,主要是借助JDOS的负载均衡策略结合用户erp完成
- 第四部,对外接口灰度,通过控制新代码灰度容器个数,逐步放量
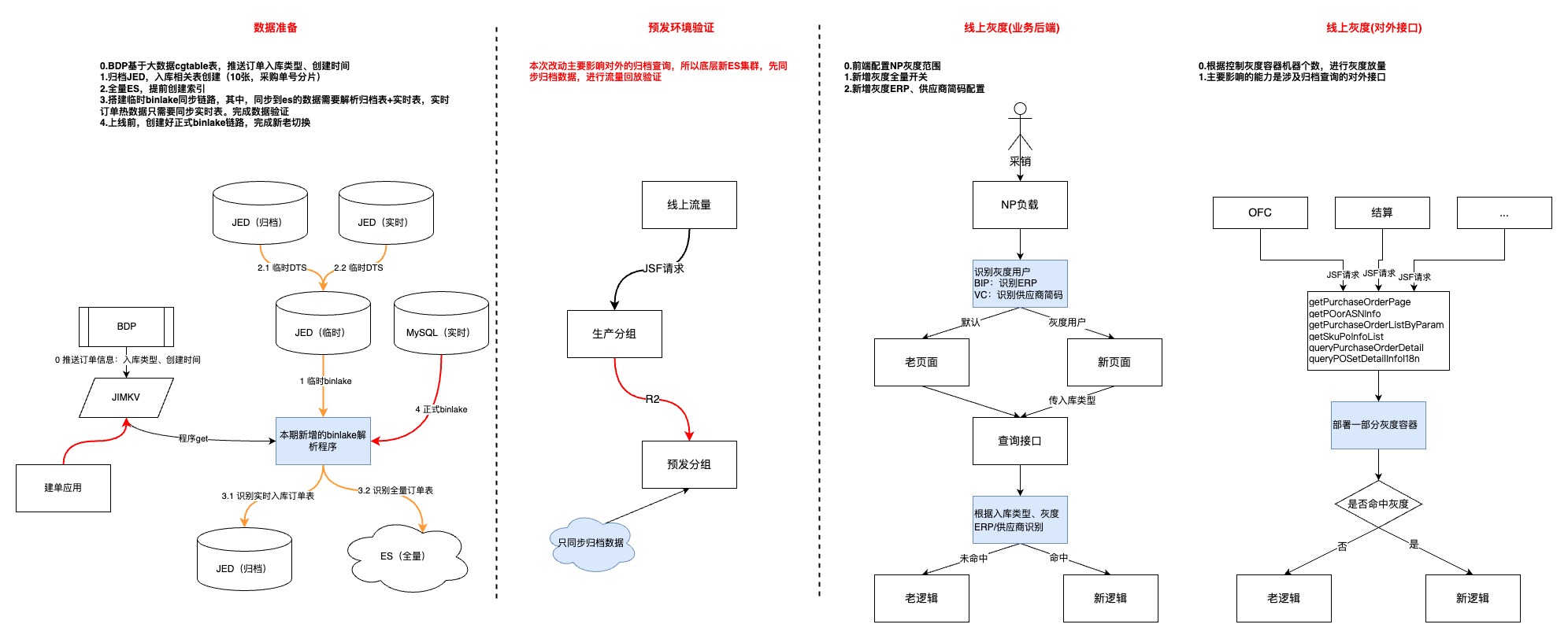
7.成果
平稳切换,无线上问题
| 指标 | 具体提升 |
|---|---|
| 采购列表查询(ms) | 1、TP999:4817 优化到 2872,提升40.37% 2、超管、部门管理员由无法查询超过一周范围的订单,优化为可以在2秒内查询3个月的订单 3、页面删除“是否归档”查询条件,简化业务操作 4、页面新增“是否入库”查询条件,聚焦核心业务数据 |
| 仓储运营列表(ms) | TP999:9009 优化到 6545,提升27.34% |
| 采购统计查询(ms) | TP999:13219 优化到 1546,提升88.3% |
| 慢SQL指标(天纬度) | 1、1s-2s慢SQL数:820->72,降低91% 2、2s-5s慢SQL数:276->26,降低90% 3、5s以上慢SQL数:343->6,降低98% |
8.待办
-
主动监控层面,新增按照天纬度进行数据比对、异常告警的能力,提高问题发现率
-
优化数据模型,对历史无用订单表进行精简,降低开发、运维成本,提升需求迭代效率
-
精简存储集群
-
逐步下线其他非核心业务存储集群,减少外部依赖,提高系统容错度
- 目前全量订单ES集群已经可以支持多场景的外部查询,未来考虑是否可以逐步下线入库订单JED
-
-
识别数据库隐患,基于慢日志监控,重新梳理引入模块,逐步优化,持续降低数据库负载
-
MySQL减负,探索其他优化方案,减少数据量存储,提升数据灵活性。优先从业务层面出发,识别库里进行中的僵尸订单的根因,进行分类,强制结束
- 降级方案,当数据同步或者数据库存在异常时,可以做到秒级无感切换,提升业务可用率
9.写在最后
-
为什么没考虑Doris?因为ES是团队应用相对成熟的中间件,处于学习、开发成本考虑
-
未来入库的JED相关表是否可以下掉,用ES完全替代?目前看可以,当初设计冗余入库JED也是出于对于ES不确定性以及数据延迟的角度考虑,而且历史的一部分查询就落在了异构的全量实时订单JED上。现在,JED官方也不是很推荐非route key的查询。最后,现阶段因为降低了数据量和拆分了业务场景,入库JED的查询性能还是非常不错的
- 因为项目排期、个人能力的因素,在方案设计上会有考虑不周的场景,本期只是优化了最核心的业务、技术痛点,未来还有很大持续优化的空间。中间件的使用并不是可以优化数据库性能的银弹,最核心的还是要结合业务以及系统历史背景,在不断纠结当中寻找balance
作者:京东零售 崔健
0.前言
-
系统概要:BIP采购系统用于京东采销部门向供应商采购商品,并且提供了多种创建采购单的方式以及采购单审批、回告、下传回传等业务功能
- 系统价值:向供应商采购商品增加库存,满足库存周转及客户订单的销售,供应链最重要的第一环节
1.背景
采购系统在经历了多年的迭代后,在数据库查询层面面临巨大的性能挑战。核心根因主要有以下几方面:
-
复杂查询多,历史上通过MySQL和JED承载了过多的检索过滤条件,时至今日很难推动接口使用方改变调用方式
-
数据量大,随着业务的持续发展,带来了海量的数据增长(日均150万单左右,订单主表/子表/渠道表/扩展表分别都是:6.5亿行,订单明细表/分配表:9.2亿行,日志表:60亿行)
- 数据模型复杂,订单完整数据分布在20+张表,经常需要多表join
引入的主要问题有:
-
业务层面:
-
订单列表页查询/导出体验差,性能非常依赖输入条件,尤其是在面对订单数据倾斜的时候,部分用户无法查询/导出超过半个月以上的订单
- 查询条件不合理,1.归档筛选条件,技术词汇透传到业务,导致相同周期的单子无法一键查询/导出,需要切换“是否归档”查询全部;2.无法区分“需要仓库收货”类的单子,大部分业务同事主要关注这类单子的履约情况
-
-
技术层面:
-
慢SQL多,各种多表关联复杂条件查询导致,索引、SQL已经优化道了瓶颈,经常出现数据库负载被拉高
-
大表多,难在数据库上做DDL,可能会引起核心写库负载升高、主从延迟等问题
- 模型复杂,开发、迭代成本高,查询索引字段散落在多个表中,导致查询性能下降
-
2.目标
业务层面:提升核心查询/导出体验,加强查询性能,优化不合理的查询条件
技术层面:1.减少慢SQL,降低数据库负载,提高系统稳定性;2.降低单表数据量级;3.简化数据模型
3.挑战
提升海量数据、复杂场景下的查询性能!
- 采购订单系统 VS C端销售订单系统复杂度对比:
| 对比项 | 采购订单系统 | C端订单销售系统 |
|---|---|---|
| 分库逻辑 | 使用采购单号分库 | 按用户pin分库分表 |
| 查询场景 | 面向采销、接口人、供应商、仓储运营提供包括采销员、单号、SKU、供应商、部门、配送中心、库房等多场景复杂查询 | 主要是按用户pin进行订单查询 |
| 单据所属人 | 采购单生成后,采销可以进行单据转移 | 订单生成后订单所属人不变 |
| 数据倾斜 | 单一采销或供应商存在大量采购单,并且自动补货会自动创建采购单 | C端一个用户pin下订单数量有限 |
4.方案
思路
优化前
优化后
4.1 降低查询数据量
4.1.1 前期调研
基于历史数据、业务调研分析,采购订单只有8%的订单属于“需要实际送货至京东库房”的范围,也就是拥有完整订单履约流程、业务核心关注时效的。其余订单属于通过客户订单驱动,在采购系统的生命周期只有创建记录
基于以上结论,在与产品达成共识后,提出新的业务领域概念:“入库订单” ,在查询时单独异构这部分订单数据(前期也曾考虑过,直接从写入层面拆分入库订单,但是因为开发成本、改动范围被pass了)。异构这部分数据实际也参考了操作系统、中间件的核心优化思路,缓存访问频次高的热数据
4.1.2 入库订单异构
执行流程
-
“入库”订单数据打标
-
增量订单在创建订单完成时写入;存量订单通过离线表推数
-
需要订单创建模块先完成改造上线,再同步历史,保证数据不丢
- 如果在【数据解析模块】处理binlog时无法及时从JimKV获取到订单标识,会补偿反查数据库并回写JimKV,提升其他表的binlog处理效率
-
-
binlog监听
-
基于公司的【数据订阅】任务,通过消费JMQ实现。其中订阅任务基于订单号进行MQ数据分区,并且在消费端配置不允许消息重试,防止消息时序错乱
- 其中,根据订单号进行各个表的MQ数据分区,第一版设计可能会引起热分区,导致消费速率变慢,基于这个问题识别到热分区主要是由于频繁更新订单明细数据导致(订单(1)->明细(N)),于是将明细相关表基于自身id进行分区,其他订单纬度表还是基于订单号。这样既不影响订单数据更新的先后顺序,也不会造成热分区、还可以保证明细数据的准确性
-
-
数据同步
-
增量数据同步可以采用源库的增量binlog进行解析即可,存量数据通过申请新库/表,进行DTS的存量+增量同步写入,完成binlog生产
- 以上是在上线前的临时链路,上线后需要切换到源库同步binlog的增量订阅任务,此时依赖“位点回拨”+“数据可重入”。位点回拨基于订阅任务的binlog时间戳,数据可重入依赖上文提到的MQ消费有序以及SQL覆盖写
-
-
数据校对
-
以表为纬度,优先统计总数,再随机抽样明细进行比对
- 目前入库订单量为稳定在5000万,全部实时订单量级6.5亿,降低92%
-
4.2 提升复杂查询能力
4.2.1 数据准备
-
考虑到异构“入库”订单到JED,虽然数据查询时效性可以有一定保障,但是在复杂查询能力以及识别“非入库”订单还没有支持
-
其中,“非入库”订单业务对于订单数据时效性要求并不高(1.订单创建源于客户订单;2.没有履约流程;3.无需手动操作订单关键节点)
- 所以,考虑将这部分查询能力转移到ES上
ES数据异构过程
-
首先,同步到ES的数据的由“实时+归档”订单组成,其中合计20亿订单,顺带优化了先前归档ES大索引(所有订单放在同一个索引)的问题,改成基于“月份”存储订单,之所以改成月份是因为根据条件查询分两种:1.一定会有查询时间范围(最多3个月);2.指定单号查询,这种会优先检索单号对应的订单创建时间,再路由到指定索引
-
其次,简化了归档程序流程,历史方案是程序中直接写入【归档JED+归档ES】,现在优化成只写入JED,ES数据通过【数据解析模块】完成,简化归档程序的同时,提高了归档能力的时效性
-
再次,因为ES是存储全量订单,需要支持复杂条件的查询,所以在订单没有物理删除的前提下,【数据解析模块】会过滤所有delete语句,保证全量订单数据的完整性
-
接着,为了提升同步到ES数据的吞吐,在MQ消费端,主要做了两方面优化:1.会根据表和具体操作进行binlog的请求合并;2.降低对于ES内部refresh机制的依赖,将2分钟内更新到ES的数据缓存到JimKV,更新前从缓存中获取
- 最后,上文提到,同步到入库JED,有的表是根据订单号,有的表是根据自身id。那么ES这里,因为NoSQL的设计,和线程并发的问题,为了防止数据错误,只能将所有表数据根据单号路由到相同的MQ分区
4.2.2 查询调度策略设计
优化前,所有的查询请求都会直接落到数据库进行查询,可以高效查询完全取决于用户的筛选条件是否可以精准缩小数据查询范围
优化后,新增动态路由层
-
离线计算T-1的采销/供应商的订单数据倾斜,将数据倾斜情况推送到JimDB集群
- 根据登陆用户、数据延迟要求、查询数据范围,自动调度查询的数据集群,实现高性能的查询请求
查询调度
5.ES主备机制&数据监控
1.主/备ES可以通过DUCC开关,实现动态切换,提升数据可靠性
2.结合公司的业务监控,完成订单数据延迟监控(数据同步模块写入时间-订单创建时间)
3.开启消息队列积压告警
5.1 ES集群主/备机制
1:1ES集群进行互备,应急预案快速切换,保证高可用
5.2 数据监控
6.灰度上线
-
第一步,优先上线数据模块,耗费较多时间的原因:1.整体数据量级以及历史数据复杂度的问题;2.数据同步链路比较长,中间环节多
-
第二步,预发环境验证,流量回放并没有做到长周期的完全自动化,根因:1.项目周期相对紧张;2.新老集群的数据还是有一些区别,回放脚本不够完善
-
第三步,用户功能灰度,主要是借助JDOS的负载均衡策略结合用户erp完成
- 第四部,对外接口灰度,通过控制新代码灰度容器个数,逐步放量
7.成果
平稳切换,无线上问题
| 指标 | 具体提升 |
|---|---|
| 采购列表查询(ms) | 1、TP999:4817 优化到 2872,提升40.37% 2、超管、部门管理员由无法查询超过一周范围的订单,优化为可以在2秒内查询3个月的订单 3、页面删除“是否归档”查询条件,简化业务操作 4、页面新增“是否入库”查询条件,聚焦核心业务数据 |
| 仓储运营列表(ms) | TP999:9009 优化到 6545,提升27.34% |
| 采购统计查询(ms) | TP999:13219 优化到 1546,提升88.3% |
| 慢SQL指标(天纬度) | 1、1s-2s慢SQL数:820->72,降低91% 2、2s-5s慢SQL数:276->26,降低90% 3、5s以上慢SQL数:343->6,降低98% |
8.待办
-
主动监控层面,新增按照天纬度进行数据比对、异常告警的能力,提高问题发现率
-
优化数据模型,对历史无用订单表进行精简,降低开发、运维成本,提升需求迭代效率
-
精简存储集群
-
逐步下线其他非核心业务存储集群,减少外部依赖,提高系统容错度
- 目前全量订单ES集群已经可以支持多场景的外部查询,未来考虑是否可以逐步下线入库订单JED
-
-
识别数据库隐患,基于慢日志监控,重新梳理引入模块,逐步优化,持续降低数据库负载
-
MySQL减负,探索其他优化方案,减少数据量存储,提升数据灵活性。优先从业务层面出发,识别库里进行中的僵尸订单的根因,进行分类,强制结束
- 降级方案,当数据同步或者数据库存在异常时,可以做到秒级无感切换,提升业务可用率
9.写在最后
-
为什么没考虑Doris?因为ES是团队应用相对成熟的中间件,处于学习、开发成本考虑
-
未来入库的JED相关表是否可以下掉,用ES完全替代?目前看可以,当初设计冗余入库JED也是出于对于ES不确定性以及数据延迟的角度考虑,而且历史的一部分查询就落在了异构的全量实时订单JED上。现在,JED官方也不是很推荐非route key的查询。最后,现阶段因为降低了数据量和拆分了业务场景,入库JED的查询性能还是非常不错的
- 因为项目排期、个人能力的因素,在方案设计上会有考虑不周的场景,本期只是优化了最核心的业务、技术痛点,未来还有很大持续优化的空间。中间件的使用并不是可以优化数据库性能的银弹,最核心的还是要结合业务以及系统历史背景,在不断纠结当中寻找balance


