

社区日报 第97期 (2017-11-11)
-
sense为什么不能用了,看看ES官方怎么说? http://t.cn/RlB3B62
-
使用allocation API快速定位分片分配问题 http://t.cn/RlrzTsD
-
ES6.0有关防止硬盘被填满的改进 http://t.cn/RlrU3Nr
-
喜大普奔,ES社区支持Markdown编辑器了 https://elasticsearch.cn/article/366
-
Elastic 收购网站搜索 SaaS 服务领导者 Swiftype http://t.cn/Rl3a4P2
- 只等你来 | Elastic Meetup 广州交流会 https://elasticsearch.cn/article/364
-
sense为什么不能用了,看看ES官方怎么说? http://t.cn/RlB3B62
-
使用allocation API快速定位分片分配问题 http://t.cn/RlrzTsD
-
ES6.0有关防止硬盘被填满的改进 http://t.cn/RlrU3Nr
-
喜大普奔,ES社区支持Markdown编辑器了 https://elasticsearch.cn/article/366
-
Elastic 收购网站搜索 SaaS 服务领导者 Swiftype http://t.cn/Rl3a4P2
- 只等你来 | Elastic Meetup 广州交流会 https://elasticsearch.cn/article/364
Elastic 招聘技术支持工程师,坐标北京

Support Engineer - Mandarin Speaking
Location: Beijing, China
Department: Support
Responsibilities
- Ensuring customer issues are resolved within our committed service level agreements.
- Maintain strong relationships with our customers for the delivery of support.
- Have a mindset of continuous improvement, in terms of efficiency of support processes and customer satisfaction.
Experience
- Demonstrable experience in of support in technology businesses
- Experience working across multi-cultural and geographically distributed teams
Key Skills
- Strong verbal and written communication skills in both Mandarin and English.
- Customer orientated focus.
- Team player, ability to work in a fast pace environment with a positive and adaptable approach.
- Knowledge of databases or search technologies a plus.
- Demonstrated strong technical understanding of software products.
Additional Information
- Competitive pay and benefits
- Stock options
- Catered lunches, snacks, and beverages in most offices
- An environment in which you can balance great work with a great life
- Passionate people building great products
- Employees with a wide variety of interests
- Distributed-first company with employees in over 30 countries, spread across 18 time zones, and speaking over 30 languages!
Elastic is an Equal Employment employer committed to the principles of equal employment opportunity and affirmative action for all applicants and employees. Qualified applicants will receive consideration for employment without regard to race, color, religion, sex, sexual orientation, gender perception or identity, national origin, age, marital status, protected veteran status, or disability status or any other basis protected by federal, state or local law, ordinance or regulation. Elastic also makes reasonable accommodations for disabled employees consistent with applicable law.
About Elastic
Elastic is the world's leading software provider for making structured and unstructured data usable in real time for search, logging, security, and analytics use cases. Founded in 2012 by the people behind the Elasticsearch, Kibana, Beats, and Logstash open source projects, Elastic's global community has more than 80,000 members across 45 countries, and since its initial release. Elastic's products have achieved more than 100 million cumulative downloads. Today thousands of organizations, including Cisco, eBay, Dell, Goldman Sachs, Groupon, HP, Microsoft, Netflix, The New York Times, Uber, Verizon, Yelp, and Wikipedia, use the Elastic Stack, X-Pack, and Elastic Cloud to power mission-critical systems that drive new revenue opportunities and massive cost savings. Elastic is backed by more than $104 million in funding from Benchmark Capital, Index Ventures, and NEA; has headquarters in Amsterdam, the Netherlands, and Mountain View, California; and has over 500 employees in more than 30 countries around the world.
Our Philosophy
We’re always on the search for amazing people, people who have deep passion for technology and are masters at their craft. We build highly sophisticated distributed systems and we don’t take our technology lightly. In Elasticsearch, you’ll have the opportunity to work in a vibrant young company next to some of the smartest and highly skilled technologists the industry has to offer. We’re looking for great team players, yet we also promote independence and ownership. We’re hackers… but of the good kind. The kind that innovates and creates cutting edge products that eventually translates to a lot of happy, smiling faces.
LifeAtElastic









Support Engineer - Mandarin Speaking
Location: Beijing, China
Department: Support
Responsibilities
- Ensuring customer issues are resolved within our committed service level agreements.
- Maintain strong relationships with our customers for the delivery of support.
- Have a mindset of continuous improvement, in terms of efficiency of support processes and customer satisfaction.
Experience
- Demonstrable experience in of support in technology businesses
- Experience working across multi-cultural and geographically distributed teams
Key Skills
- Strong verbal and written communication skills in both Mandarin and English.
- Customer orientated focus.
- Team player, ability to work in a fast pace environment with a positive and adaptable approach.
- Knowledge of databases or search technologies a plus.
- Demonstrated strong technical understanding of software products.
Additional Information
- Competitive pay and benefits
- Stock options
- Catered lunches, snacks, and beverages in most offices
- An environment in which you can balance great work with a great life
- Passionate people building great products
- Employees with a wide variety of interests
- Distributed-first company with employees in over 30 countries, spread across 18 time zones, and speaking over 30 languages!
Elastic is an Equal Employment employer committed to the principles of equal employment opportunity and affirmative action for all applicants and employees. Qualified applicants will receive consideration for employment without regard to race, color, religion, sex, sexual orientation, gender perception or identity, national origin, age, marital status, protected veteran status, or disability status or any other basis protected by federal, state or local law, ordinance or regulation. Elastic also makes reasonable accommodations for disabled employees consistent with applicable law.
About Elastic
Elastic is the world's leading software provider for making structured and unstructured data usable in real time for search, logging, security, and analytics use cases. Founded in 2012 by the people behind the Elasticsearch, Kibana, Beats, and Logstash open source projects, Elastic's global community has more than 80,000 members across 45 countries, and since its initial release. Elastic's products have achieved more than 100 million cumulative downloads. Today thousands of organizations, including Cisco, eBay, Dell, Goldman Sachs, Groupon, HP, Microsoft, Netflix, The New York Times, Uber, Verizon, Yelp, and Wikipedia, use the Elastic Stack, X-Pack, and Elastic Cloud to power mission-critical systems that drive new revenue opportunities and massive cost savings. Elastic is backed by more than $104 million in funding from Benchmark Capital, Index Ventures, and NEA; has headquarters in Amsterdam, the Netherlands, and Mountain View, California; and has over 500 employees in more than 30 countries around the world.
Our Philosophy
We’re always on the search for amazing people, people who have deep passion for technology and are masters at their craft. We build highly sophisticated distributed systems and we don’t take our technology lightly. In Elasticsearch, you’ll have the opportunity to work in a vibrant young company next to some of the smartest and highly skilled technologists the industry has to offer. We’re looking for great team players, yet we also promote independence and ownership. We’re hackers… but of the good kind. The kind that innovates and creates cutting edge products that eventually translates to a lot of happy, smiling faces.
LifeAtElastic
社区支持 Markdown 编辑器
为了改善大家的创作体验,提高大家的写作和分享热情!?,经过两天的不懈奋斗,终于把 Markdown 编辑器搬上来了。 目前只支持文章的发布,可以通过切换编辑器来选择 Markdown 编辑模式。 希望不要再以编辑器作为理由发只有链接的文章了。 ???????????
- 支持 Github 风格的 Markdown 格式
- 支持本站附件功能
- 支持 emoj 符号
- 支持自动的页面导航
- 以前的文章可再次编辑,切换 Markdown 模式然后修改保存
如何使用?
- 点击【发起】,选择文章
- 切换绿色按钮,将编辑器切换到 Markdown,然后在文本框内输入 Markdown 格式的内容即可。
在线 Markdown 脚本编辑预览工具:https://elasticsearch.cn/static/js/editor/markdown/
以下为样式测试参考,忽略其意义。

----------- 常用格式-----------------
# 标题1
## 标题2
### 标题3
#### 标题4
##### 标题5
###### 标题6
超大标题 //等于号写于文字下方
===
标题 //同超大标题
---
`短代码`
_ 注:长代码块,用三个: ` _
> This is the first level of quoting.
>
> > This is nested blockquote.
>
> Back to the first level.
* Red
* Green
* Blue
- Red
- Green
- Blue
+ Red
+ Green
+ Blue
1. 这是第一个
1. 这是第二个
1. 这是第三个
* * *
***
*****
- - -
---
[markdown-syntax](http://daringfireball.net/projects/markdown/syntax)
[id]: http://example.com/ "Optional Title Here"
This is [an example][id] reference-style link.
*内容*
**内容**
_内容_
__内容__

<http://elastic.co/>
<info@elastic.o>
四个空格
一个tab
----------- 样式预览-----------------
标题1
标题2
标题3
标题4
标题5
标题6
超大标题 //等于号写于文字下方
标题 //同超大标题
短代码
This is the first level of quoting.
This is nested blockquote.
Back to the first level.
- Red
- Green
-
Blue
- Red
- Green
-
Blue
- Red
- Green
- Blue
- 这是第一个
- 这是第二个
- 这是第三个
This is an example reference-style link.
内容 内容 内容 内容

四个空格
一个tabhttps://github.com/infinitbyte/gopa 的 README 内容
GOPA, A Spider Written in Go.

![]()

Goal
- Light weight, low footprint, memory requirement should < 100MB
- Easy to deploy, no runtime or dependency required
- Easy to use, no programming or scripts ability needed, out of box features
Screenshoot

How to use
Setup
First of all, get it, two opinions: download the pre-built package or compile it yourself.
Download Pre Built Package
Go to Release or Snapshot page, download the right package for your platform.
Note: Darwin is for Mac
Compile The Package Manually
- Mac/Linux: Run
make buildto build the Gopa. - Windows: Checkout this wiki page - How to build GOPA on windows.
So far, we have:
gopa, the main program, a single binary.
config/, elasticsearch related scripts etc.
gopa.yml, main configuration for gopa.
Optional Config
By default, Gopa works well except indexing, if you want to use elasticsearch as indexing, follow these steps:
- Create a index in elasticsearch with script
config/gopa-index-mapping.shExample
curl -XPUT "http://localhost:9200/gopa-index" -H 'Content-Type: application/json' -d' { "mappings": { "doc": { "properties": { "host": { "type": "keyword", "ignore_above": 256 }, "snapshot": { "properties": { "bold": { "type": "text" }, "url": { "type": "keyword", "ignore_above": 256 }, "content_type": { "type": "keyword", "ignore_above": 256 }, "file": { "type": "keyword", "ignore_above": 256 }, "h1": { "type": "text" }, "h2": { "type": "text" }, "h3": { "type": "text" }, "h4": { "type": "text" }, "hash": { "type": "keyword", "ignore_above": 256 }, "id": { "type": "keyword", "ignore_above": 256 }, "images": { "properties": { "external": { "properties": { "label": { "type": "text" }, "url": { "type": "keyword", "ignore_above": 256 } } }, "internal": { "properties": { "label": { "type": "text" }, "url": { "type": "keyword", "ignore_above": 256 } } } } }, "italic": { "type": "text" }, "links": { "properties": { "external": { "properties": { "label": { "type": "text" }, "url": { "type": "keyword", "ignore_above": 256 } } }, "internal": { "properties": { "label": { "type": "text" }, "url": { "type": "keyword", "ignore_above": 256 } } } } }, "path": { "type": "keyword", "ignore_above": 256 }, "sim_hash": { "type": "keyword", "ignore_above": 256 }, "lang": { "type": "keyword", "ignore_above": 256 }, "size": { "type": "long" }, "text": { "type": "text" }, "title": { "type": "text", "fields": { "keyword": { "type": "keyword" } } }, "version": { "type": "long" } } }, "task": { "properties": { "breadth": { "type": "long" }, "created": { "type": "date" }, "depth": { "type": "long" }, "id": { "type": "keyword", "ignore_above": 256 }, "original_url": { "type": "keyword", "ignore_above": 256 }, "reference_url": { "type": "keyword", "ignore_above": 256 }, "schema": { "type": "keyword", "ignore_above": 256 }, "status": { "type": "integer" }, "updated": { "type": "date" }, "url": { "type": "keyword", "ignore_above": 256 } } } } } } }'
Note: Elasticsearch version should > v5.0
- Enable index module in
gopa.yml, update the elasticsearch's setting:- module: index enabled: true ui: enabled: true elasticsearch: endpoint: http://dev:9200 index_prefix: gopa- username: elastic password: changeme
Start
Gopa doesn't require any dependencies, simply run ./gopa to start the program.
Gopa can be run as daemon(Note: Only available on Linux and Mac):
Example
➜ gopa git:(master) ✗ ./bin/gopa --daemon
________ ________ __________ _____
/ _____/ \_____ \\______ \/ _ \
/ \ ___ / | \| ___/ /_\ \
\ \_\ \/ | \ | / | \
\______ /\_______ /____| \____|__ /
\/ \/ \/
[gopa] 0.10.0_SNAPSHOT
///last commit: 99616a2, Fri Oct 20 14:04:54 2017 +0200, medcl, update version to 0.10.0 ///
[10-21 16:01:09] [INF] [instance.go:23] workspace: data/gopa/nodes/0
[gopa] started.
Also run ./gopa -h to get the full list of command line options.
Example
➜ gopa git:(master) ✗ ./bin/gopa -h
________ ________ __________ _____
/ _____/ \_____ \\______ \/ _ \
/ \ ___ / | \| ___/ /_\ \
\ \_\ \/ | \ | / | \
\______ /\_______ /____| \____|__ /
\/ \/ \/
[gopa] 0.10.0_SNAPSHOT
///last commit: 99616a2, Fri Oct 20 14:04:54 2017 +0200, medcl, update version to 0.10.0 ///
Usage of ./bin/gopa:
-config string
the location of config file (default "gopa.yml")
-cpuprofile string
write cpu profile to this file
-daemon
run in background as daemon
-debug
run in debug mode, wi
-log string
the log level,options:trace,debug,info,warn,error (default "info")
-log_path string
the log path (default "log")
-memprofile string
write memory profile to this file
-pidfile string
pidfile path (only for daemon)
-pprof string
enable and setup pprof/expvar service, eg: localhost:6060 , the endpoint will be: http://localhost:6060/debug/pprof/ and http://localhost:6060/debug/vars
Stop
It's safety to press ctrl+c stop the current running Gopa, Gopa will handle the rest,saving the checkpoint,
you may restore the job later,the world is still in your hand.
If you are running Gopa as daemon, you may stop it like this:
kill -QUIT `pgrep gopa`Configuration
UI
- Search Console
http://127.0.0.1:9001/ - Admin Console
http://127.0.0.1:9001/admin/
API
- TBD
Contributing
You are sincerely and warmly welcomed to play with this project, from UI style to core features, or just a piece of document, welcome! let's make it better.
License
Released under the Apache License, Version 2.0 .
Also XSS Test
alert('XSS test');
为了改善大家的创作体验,提高大家的写作和分享热情!?,经过两天的不懈奋斗,终于把 Markdown 编辑器搬上来了。 目前只支持文章的发布,可以通过切换编辑器来选择 Markdown 编辑模式。 希望不要再以编辑器作为理由发只有链接的文章了。 ???????????
- 支持 Github 风格的 Markdown 格式
- 支持本站附件功能
- 支持 emoj 符号
- 支持自动的页面导航
- 以前的文章可再次编辑,切换 Markdown 模式然后修改保存
如何使用?
- 点击【发起】,选择文章
- 切换绿色按钮,将编辑器切换到 Markdown,然后在文本框内输入 Markdown 格式的内容即可。
在线 Markdown 脚本编辑预览工具:https://elasticsearch.cn/static/js/editor/markdown/
以下为样式测试参考,忽略其意义。
----------- 常用格式-----------------
# 标题1
## 标题2
### 标题3
#### 标题4
##### 标题5
###### 标题6
超大标题 //等于号写于文字下方
===
标题 //同超大标题
---
`短代码`
_ 注:长代码块,用三个: ` _
> This is the first level of quoting.
>
> > This is nested blockquote.
>
> Back to the first level.
* Red
* Green
* Blue
- Red
- Green
- Blue
+ Red
+ Green
+ Blue
1. 这是第一个
1. 这是第二个
1. 这是第三个
* * *
***
*****
- - -
---
[markdown-syntax](http://daringfireball.net/projects/markdown/syntax)
[id]: http://example.com/ "Optional Title Here"
This is [an example][id] reference-style link.
*内容*
**内容**
_内容_
__内容__

<http://elastic.co/>
<info@elastic.o>
四个空格
一个tab
----------- 样式预览-----------------
标题1
标题2
标题3
标题4
标题5
标题6
超大标题 //等于号写于文字下方
标题 //同超大标题
短代码
This is the first level of quoting.
This is nested blockquote.
Back to the first level.
- Red
- Green
-
Blue
- Red
- Green
-
Blue
- Red
- Green
- Blue
- 这是第一个
- 这是第二个
- 这是第三个
This is an example reference-style link.
内容 内容 内容 内容
四个空格
一个tabhttps://github.com/infinitbyte/gopa 的 README 内容
GOPA, A Spider Written in Go.
![]()
Goal
- Light weight, low footprint, memory requirement should < 100MB
- Easy to deploy, no runtime or dependency required
- Easy to use, no programming or scripts ability needed, out of box features
Screenshoot
How to use
Setup
First of all, get it, two opinions: download the pre-built package or compile it yourself.
Download Pre Built Package
Go to Release or Snapshot page, download the right package for your platform.
Note: Darwin is for Mac
Compile The Package Manually
- Mac/Linux: Run
make buildto build the Gopa. - Windows: Checkout this wiki page - How to build GOPA on windows.
So far, we have:
gopa, the main program, a single binary.
config/, elasticsearch related scripts etc.
gopa.yml, main configuration for gopa.
Optional Config
By default, Gopa works well except indexing, if you want to use elasticsearch as indexing, follow these steps:
- Create a index in elasticsearch with script
config/gopa-index-mapping.shExample
curl -XPUT "http://localhost:9200/gopa-index" -H 'Content-Type: application/json' -d' { "mappings": { "doc": { "properties": { "host": { "type": "keyword", "ignore_above": 256 }, "snapshot": { "properties": { "bold": { "type": "text" }, "url": { "type": "keyword", "ignore_above": 256 }, "content_type": { "type": "keyword", "ignore_above": 256 }, "file": { "type": "keyword", "ignore_above": 256 }, "h1": { "type": "text" }, "h2": { "type": "text" }, "h3": { "type": "text" }, "h4": { "type": "text" }, "hash": { "type": "keyword", "ignore_above": 256 }, "id": { "type": "keyword", "ignore_above": 256 }, "images": { "properties": { "external": { "properties": { "label": { "type": "text" }, "url": { "type": "keyword", "ignore_above": 256 } } }, "internal": { "properties": { "label": { "type": "text" }, "url": { "type": "keyword", "ignore_above": 256 } } } } }, "italic": { "type": "text" }, "links": { "properties": { "external": { "properties": { "label": { "type": "text" }, "url": { "type": "keyword", "ignore_above": 256 } } }, "internal": { "properties": { "label": { "type": "text" }, "url": { "type": "keyword", "ignore_above": 256 } } } } }, "path": { "type": "keyword", "ignore_above": 256 }, "sim_hash": { "type": "keyword", "ignore_above": 256 }, "lang": { "type": "keyword", "ignore_above": 256 }, "size": { "type": "long" }, "text": { "type": "text" }, "title": { "type": "text", "fields": { "keyword": { "type": "keyword" } } }, "version": { "type": "long" } } }, "task": { "properties": { "breadth": { "type": "long" }, "created": { "type": "date" }, "depth": { "type": "long" }, "id": { "type": "keyword", "ignore_above": 256 }, "original_url": { "type": "keyword", "ignore_above": 256 }, "reference_url": { "type": "keyword", "ignore_above": 256 }, "schema": { "type": "keyword", "ignore_above": 256 }, "status": { "type": "integer" }, "updated": { "type": "date" }, "url": { "type": "keyword", "ignore_above": 256 } } } } } } }'
Note: Elasticsearch version should > v5.0
- Enable index module in
gopa.yml, update the elasticsearch's setting:- module: index enabled: true ui: enabled: true elasticsearch: endpoint: http://dev:9200 index_prefix: gopa- username: elastic password: changeme
Start
Gopa doesn't require any dependencies, simply run ./gopa to start the program.
Gopa can be run as daemon(Note: Only available on Linux and Mac):
Example
➜ gopa git:(master) ✗ ./bin/gopa --daemon
________ ________ __________ _____
/ _____/ \_____ \\______ \/ _ \
/ \ ___ / | \| ___/ /_\ \
\ \_\ \/ | \ | / | \
\______ /\_______ /____| \____|__ /
\/ \/ \/
[gopa] 0.10.0_SNAPSHOT
///last commit: 99616a2, Fri Oct 20 14:04:54 2017 +0200, medcl, update version to 0.10.0 ///
[10-21 16:01:09] [INF] [instance.go:23] workspace: data/gopa/nodes/0
[gopa] started.
Also run ./gopa -h to get the full list of command line options.
Example
➜ gopa git:(master) ✗ ./bin/gopa -h
________ ________ __________ _____
/ _____/ \_____ \\______ \/ _ \
/ \ ___ / | \| ___/ /_\ \
\ \_\ \/ | \ | / | \
\______ /\_______ /____| \____|__ /
\/ \/ \/
[gopa] 0.10.0_SNAPSHOT
///last commit: 99616a2, Fri Oct 20 14:04:54 2017 +0200, medcl, update version to 0.10.0 ///
Usage of ./bin/gopa:
-config string
the location of config file (default "gopa.yml")
-cpuprofile string
write cpu profile to this file
-daemon
run in background as daemon
-debug
run in debug mode, wi
-log string
the log level,options:trace,debug,info,warn,error (default "info")
-log_path string
the log path (default "log")
-memprofile string
write memory profile to this file
-pidfile string
pidfile path (only for daemon)
-pprof string
enable and setup pprof/expvar service, eg: localhost:6060 , the endpoint will be: http://localhost:6060/debug/pprof/ and http://localhost:6060/debug/vars
Stop
It's safety to press ctrl+c stop the current running Gopa, Gopa will handle the rest,saving the checkpoint,
you may restore the job later,the world is still in your hand.
If you are running Gopa as daemon, you may stop it like this:
kill -QUIT `pgrep gopa`Configuration
UI
- Search Console
http://127.0.0.1:9001/ - Admin Console
http://127.0.0.1:9001/admin/
API
- TBD
Contributing
You are sincerely and warmly welcomed to play with this project, from UI style to core features, or just a piece of document, welcome! let's make it better.
License
Released under the Apache License, Version 2.0 .
Also XSS Test
alert('XSS test');
收起阅读 »社区日报 第96期 (2017-11-10)
http://t.cn/RlHuOKx
2、业界良心 | 《Elasticsearch5.6.3 Java API 中文手册》
https://elasticsearch.cn/article/362
3、PPT | 基于 Mesos/Docker 的 Elasticsearch 容器化私有云
http://t.cn/RlHuTQR
4、只等你来 | Elastic Meetup 广州交流会
https://elasticsearch.cn/article/364
编辑:laoyang360
归档:https://elasticsearch.cn/article/365
订阅:https://tinyletter.com/elastic-daily
http://t.cn/RlHuOKx
2、业界良心 | 《Elasticsearch5.6.3 Java API 中文手册》
https://elasticsearch.cn/article/362
3、PPT | 基于 Mesos/Docker 的 Elasticsearch 容器化私有云
http://t.cn/RlHuTQR
4、只等你来 | Elastic Meetup 广州交流会
https://elasticsearch.cn/article/364
编辑:laoyang360
归档:https://elasticsearch.cn/article/365
订阅:https://tinyletter.com/elastic-daily
收起阅读 »
Elastic Meetup 广州交流会
Elastic Meetup 线下交流活动再次来到羊城广州,算是社区在广州的第二次线下聚会了,广州的小伙伴们,快快报名吧! 回顾去年的线下活动,可以点击这里:https://elasticsearch.cn/article/71

主办:
本次活动由 Elastic 与 网易游戏运维与基础架构部 联合举办。
媒体:
本次活动由 IT大咖说 独家提供现场直播。
时间:
2017.11.25 下午2:00-5:00(1点半开始签到)
地点:
广州市天河区科韵路16号广州信息港E栋网易大厦 一楼博学堂
主题:
- 网易 - 杜鑫 - ELK在藏宝阁中的应用
- 酷狗 - 钟旺 - 基于ES的音乐搜索引擎
- 阿里云 - 赵弘扬 - Elasticsearch在阿里云的实践分享
- 网易 - 林邦骏 - 网易ELK 系统综述
- 数说故事 - 吴文杰 - Data Warehouse with ElasticSearch in Datastory
- 闪电分享(5-10分钟,可现场报名)
参会报名:
http://elasticsearch.mikecrm.com/O6o0yq3
现场直播:
直播连接:http://www.itdks.com/eventlist/detail/1673

主题介绍:
ELK在藏宝阁中的应用
内容介绍:
1. 藏宝阁项目介绍 主要介绍一下藏宝阁项目,让不熟悉藏宝阁的听众有一个基本的了解,熟悉应用的背景。
-
ELK在藏宝阁中的应用(概述) 大致简要的阐述一下ELK在藏宝阁中哪些地方发挥了什么样的作用。
- ELK在藏宝阁推荐系统中的应用(重点) 较为详细的剖析一下ELK在推荐系统中的发挥的作用,具备的优势。
分享嘉宾:

杜鑫,网易藏宝阁工作室资深开发工程师,目前主要从事藏宝阁推荐业务相关的研发工作。
网易ELK 系统综述
内容介绍:
从架构以及功能两个角度去阐述网易的 ELK 平台,介绍系统内部各个组件及其管理方式。进而以用户的视角介绍平台中包含的自动化服务等功能,从管理员的视角去讨论组件的配置管理、资源调度回收等问题。
分享嘉宾:

林邦骏,网易 GDC产品组资深运维工程师,主要负责内部 ELK 产品的运维、功能开发等工作。
基于ES的音乐搜索引擎
内容介绍:
1、酷狗音乐搜索引擎架构变迁
2、构建音乐搜索引擎经验之谈
分享嘉宾:

钟旺,酷狗后台开发工程师,从事JAVA、ES相关的开发工作。
Data Warehouse with ElasticSearch in Datastory
内容介绍:
ES最多使用的场景是搜索和日志分析,然而ES强大的实时索引查询、全文检索和聚合能力也能成为数据仓库与OLAP场景的强力支持。
本次分享将为大家带来数说故事如何借助ES和Hadoop生态在不同的数据场景下构建起数据仓库能力。
分享嘉宾:

吴文杰 ,数说故事平台架构团队 高级工程师,负责数说故事百亿级数据的存储查询及内部基础平台建设。
Elasticsearch在阿里云的实践分享
内容介绍
介绍阿里云Elastiserach服务的技术架构和Xpack相关功能,并分享在云上环境搭建ELK的实践案例。
分享嘉宾

赵弘扬,阿里巴巴搜索产品专家,负责阿里云搜索产品规划和开发。
深圳也在筹备中,可以提前报名!:https://elasticsearch.cn/article/261
关于 Elastic Meetup
Elastic Meetup 由 Elastic 中文社区定期举办的线下交流活动,主要围绕 Elastic 的开源产品(Elasticsearch、Logstash、Kibana 和 Beats)及周边技术,探讨在搜索、数据实时分析、日志分析、安全等领域的实践与应用。
关于 Elastic

Elastic 通过构建软件,让用户能够实时地、大规模地将数据用于搜索、日志和分析场景。Elastic 创立于 2012 年,相继开发了开源的 Elastic Stack(Elasticsearch、Kibana、Beats 和 Logstash)、X-Pack(商业功能)和 Elastic Cloud(托管服务)。截至目前,累计下载量超过 1.5 亿。Benchmark Capital、Index Ventures 和 NEA 为 Elastic 提供了超过 1 亿美元资金作为支持,Elastic 共有 600 多名员工,分布在 30 个国家/地区。有关更多信息,请访问 http://elastic.co/cn 。
关于网易游戏运维与基础架构部
.png")
网易游戏运维与基础架构部, 主要负责网易游戏产品的可靠性保障以及基础设施的开发和部署,旨在:
- 专注为产品全生命周期提供可靠性保障服务,依托于大数据为运维提供决策
- 通过智能监控提高问题发现和解决能力,以自动化驱动低成本的业务管理
- 打造混合云方案,站在游戏业务角度驱动的TCO优化和运维智能化
关于IT大咖说
.jpg")
IT大咖说,IT垂直领域的大咖知识分享平台,践行“开源是一种态度”,通过线上线下开放模式分享行业TOP大咖干货,技术大会在线直播点播,在线活动直播平台。http://www.itdks.com 。
再次感谢网易游戏运维与基础架构部和IT大咖说的大力支持!
Elastic Meetup 线下交流活动再次来到羊城广州,算是社区在广州的第二次线下聚会了,广州的小伙伴们,快快报名吧! 回顾去年的线下活动,可以点击这里:https://elasticsearch.cn/article/71
主办:
本次活动由 Elastic 与 网易游戏运维与基础架构部 联合举办。
媒体:
本次活动由 IT大咖说 独家提供现场直播。
时间:
2017.11.25 下午2:00-5:00(1点半开始签到)
地点:
广州市天河区科韵路16号广州信息港E栋网易大厦 一楼博学堂
主题:
- 网易 - 杜鑫 - ELK在藏宝阁中的应用
- 酷狗 - 钟旺 - 基于ES的音乐搜索引擎
- 阿里云 - 赵弘扬 - Elasticsearch在阿里云的实践分享
- 网易 - 林邦骏 - 网易ELK 系统综述
- 数说故事 - 吴文杰 - Data Warehouse with ElasticSearch in Datastory
- 闪电分享(5-10分钟,可现场报名)
参会报名:
http://elasticsearch.mikecrm.com/O6o0yq3
现场直播:
直播连接:http://www.itdks.com/eventlist/detail/1673
主题介绍:
ELK在藏宝阁中的应用
内容介绍:
1. 藏宝阁项目介绍 主要介绍一下藏宝阁项目,让不熟悉藏宝阁的听众有一个基本的了解,熟悉应用的背景。
-
ELK在藏宝阁中的应用(概述) 大致简要的阐述一下ELK在藏宝阁中哪些地方发挥了什么样的作用。
- ELK在藏宝阁推荐系统中的应用(重点) 较为详细的剖析一下ELK在推荐系统中的发挥的作用,具备的优势。
分享嘉宾:
杜鑫,网易藏宝阁工作室资深开发工程师,目前主要从事藏宝阁推荐业务相关的研发工作。
网易ELK 系统综述
内容介绍:
从架构以及功能两个角度去阐述网易的 ELK 平台,介绍系统内部各个组件及其管理方式。进而以用户的视角介绍平台中包含的自动化服务等功能,从管理员的视角去讨论组件的配置管理、资源调度回收等问题。
分享嘉宾:
林邦骏,网易 GDC产品组资深运维工程师,主要负责内部 ELK 产品的运维、功能开发等工作。
基于ES的音乐搜索引擎
内容介绍:
1、酷狗音乐搜索引擎架构变迁
2、构建音乐搜索引擎经验之谈
分享嘉宾:
钟旺,酷狗后台开发工程师,从事JAVA、ES相关的开发工作。
Data Warehouse with ElasticSearch in Datastory
内容介绍:
ES最多使用的场景是搜索和日志分析,然而ES强大的实时索引查询、全文检索和聚合能力也能成为数据仓库与OLAP场景的强力支持。
本次分享将为大家带来数说故事如何借助ES和Hadoop生态在不同的数据场景下构建起数据仓库能力。
分享嘉宾:
吴文杰 ,数说故事平台架构团队 高级工程师,负责数说故事百亿级数据的存储查询及内部基础平台建设。
Elasticsearch在阿里云的实践分享
内容介绍
介绍阿里云Elastiserach服务的技术架构和Xpack相关功能,并分享在云上环境搭建ELK的实践案例。
分享嘉宾
赵弘扬,阿里巴巴搜索产品专家,负责阿里云搜索产品规划和开发。
深圳也在筹备中,可以提前报名!:https://elasticsearch.cn/article/261
关于 Elastic Meetup
Elastic Meetup 由 Elastic 中文社区定期举办的线下交流活动,主要围绕 Elastic 的开源产品(Elasticsearch、Logstash、Kibana 和 Beats)及周边技术,探讨在搜索、数据实时分析、日志分析、安全等领域的实践与应用。
关于 Elastic
Elastic 通过构建软件,让用户能够实时地、大规模地将数据用于搜索、日志和分析场景。Elastic 创立于 2012 年,相继开发了开源的 Elastic Stack(Elasticsearch、Kibana、Beats 和 Logstash)、X-Pack(商业功能)和 Elastic Cloud(托管服务)。截至目前,累计下载量超过 1.5 亿。Benchmark Capital、Index Ventures 和 NEA 为 Elastic 提供了超过 1 亿美元资金作为支持,Elastic 共有 600 多名员工,分布在 30 个国家/地区。有关更多信息,请访问 http://elastic.co/cn 。
关于网易游戏运维与基础架构部
网易游戏运维与基础架构部, 主要负责网易游戏产品的可靠性保障以及基础设施的开发和部署,旨在:
- 专注为产品全生命周期提供可靠性保障服务,依托于大数据为运维提供决策
- 通过智能监控提高问题发现和解决能力,以自动化驱动低成本的业务管理
- 打造混合云方案,站在游戏业务角度驱动的TCO优化和运维智能化
关于IT大咖说
IT大咖说,IT垂直领域的大咖知识分享平台,践行“开源是一种态度”,通过线上线下开放模式分享行业TOP大咖干货,技术大会在线直播点播,在线活动直播平台。http://www.itdks.com 。
再次感谢网易游戏运维与基础架构部和IT大咖说的大力支持!
收起阅读 »社区日报 第95期 (2017-11-09)
http://t.cn/RlY7tMh
2.Spring Boot 中使用 Java API 调用 Elasticsearch
http://t.cn/RljQNFJ
3.一个实时查看,搜索尾部日志事件的kibana插件
http://t.cn/RcXglR2
招聘:京东北京招聘ES高级工程师
https://elasticsearch.cn/article/358
编辑:金桥
归档:https://elasticsearch.cn/article/363
订阅:https://tinyletter.com/elastic-daily
http://t.cn/RlY7tMh
2.Spring Boot 中使用 Java API 调用 Elasticsearch
http://t.cn/RljQNFJ
3.一个实时查看,搜索尾部日志事件的kibana插件
http://t.cn/RcXglR2
招聘:京东北京招聘ES高级工程师
https://elasticsearch.cn/article/358
编辑:金桥
归档:https://elasticsearch.cn/article/363
订阅:https://tinyletter.com/elastic-daily 收起阅读 »
Elasticsearch 5.6 Java API 中文手册

[Elasticsearch 5.6 Java API 中文手册]
本手册由 全科 翻译,并且整理成电子书,支持PDF,ePub,Mobi格式,方便大家下载阅读。
不只是官方文档的翻译,还包含使用实例,包含我们使用踩过的坑
阅读地址:https://es.quanke.name
下载地址:https://www.gitbook.com/book/q ... -java
github地址:https://github.com/quanke/elasticsearch-java
编辑:http://quanke.name
编辑整理辛苦,还望大神们点一下star ,抚平我虚荣的心
[全科的公众号]

[Elasticsearch 5.6 Java API 中文手册]
本手册由 全科 翻译,并且整理成电子书,支持PDF,ePub,Mobi格式,方便大家下载阅读。
不只是官方文档的翻译,还包含使用实例,包含我们使用踩过的坑
阅读地址:https://es.quanke.name
下载地址:https://www.gitbook.com/book/q ... -java
github地址:https://github.com/quanke/elasticsearch-java
编辑:http://quanke.name
编辑整理辛苦,还望大神们点一下star ,抚平我虚荣的心
[全科的公众号]
收起阅读 »
Bulk异常引发的Elasticsearch内存泄漏
2018年8月24日更新: 今天放出的6.4版修复了这个问题。
原文链接: http://www.jianshu.com/p/d4f7a6d58008
前天公司度假部门一个线上ElasticSearch集群发出报警,有Data Node的Heap使用量持续超过80%警戒线。 收到报警邮件后,不敢怠慢,立即登陆监控系统查看集群状态。还好,所有的结点都在正常服务,只是有2个结点的Heap使用率非常高。此时,Old GC一直在持续的触发,却无法回收内存。

初步排查
问题结点的Heap分配了30GB,80%的使用率约等于24GB。 但集群的数据总量并不大,5个结点所有索引文件加起来占用的磁盘空间还不到10GB。
GET /_cat/allocation?v&h=shards,disk.indices,disk.used,disk.avail
shards disk.indices disk.used disk.avail
3 1.9gb 38.3gb 89.7gb
4 2.2gb 13.4gb 114.6gb
4 2.5gb 20.3gb 107.7gb
4 2.3gb 33.9gb 94.1gb
3 1.7gb 12.8gb 115.2gb查看各结点的segment memory和cache占用量也都非常小,是MB级别的。
GET /_cat/nodes?v&h=id,port,v,m,fdp,mc,mcs,sc,sm,qcm,fm,im,siwm,svmm
id port v m fdp mc mcs sc sm qcm fm siwm svmm
e1LV 9300 5.3.2 - 1 0 0b 68 69mb 1.5mb 1.9mb 0b 499b
5VnU 9300 5.3.2 - 1 0 0b 75 79mb 1.5mb 1.9mb 0b 622b
_Iob 9300 5.3.2 - 1 0 0b 56 55.7mb 1.3mb 914.1kb 0b 499b
4Kyl 9300 5.3.2 * 1 1 330.1mb 81 84.4mb 1.2mb 1.9mb 0b 622b
XEP_ 9300 5.3.2 - 1 0 0b 45 50.4mb 748.5kb 1mb 0b 622b集群的QPS只有30上下,CPU消耗10%都不到,各类thread pool的活动线程数量也都非常低。

非常费解是什么东西占着20多GB的内存不释放?
出现问题的集群ES版本是5.3.2,而这个版本的稳定性在公司内部已经经过长时间的考验,做为稳定版本在线上进行了大规模部署。 其他一些读写负载非常高的集群也未曾出现过类似的状况,看来是遇到新问题了。
查看问题结点ES的日志,除了看到一些Bulk异常以外,未见特别明显的其他和资源相关的错误:
[2017-11-06T16:33:15,668][DEBUG][o.e.a.b.TransportShardBulkAction] [] [suggest-3][0] failed to execute bulk item (update) BulkShardRequest [[suggest-3][0]] containing [44204
] requests
org.elasticsearch.index.engine.DocumentMissingException: [type][纳格尔果德_1198]: document missing
at org.elasticsearch.action.update.UpdateHelper.prepare(UpdateHelper.java:92) ~[elasticsearch-5.3.2.jar:5.3.2]
at org.elasticsearch.action.update.UpdateHelper.prepare(UpdateHelper.java:81) ~[elasticsearch-5.3.2.jar:5.3.2]和用户确认这些异常的原因,是因为写入程序会从数据源拿到数据后,根据doc_id对ES里的数据做update。会有部分doc_id在ES里不存在的情况,但并不影响业务逻辑,因而ES记录的document missing异常应该可以忽略。
至此别无他法,只能对JVM做Dump分析了。
Heap Dump分析
用的工具是Eclipse MAT,从这里下载的Mac版:Downloads 。 使用这个工具需要经过以下2个步骤:
- 获取二进制的head dump文件
jmap -dump:format=b,file=/tmp/es_heap.bin <pid>其中pid是ES JAVA进程的进程号。 - 将生成的dump文件下载到本地开发机器,启动MAT,从其GUI打开文件。
要注意,MAT本身也是JAVA应用,需要有JDK运行环境的支持。
MAT第一次打dump文件的时候,需要对其解析,生成多个索引。这个过程比较消耗CPU和内存,但一旦完成,之后再打开dump文件就很快,消耗很低。 对于这种20多GB的大文件,第一次解析的过程会非常缓慢,并且很可能因为开发机内存的较少而内存溢出。因此,我找了台大内存的服务器来做第一次的解析工作:
-
将linux版的MAT拷贝上去,解压缩后,修改配置文件MemoryAnalyzer.ini,将内存设置为20GB左右:
$ cat MemoryAnalyzer.ini -startup plugins/org.eclipse.equinox.launcher_1.3.100.v20150511-1540.jar --launcher.library plugins/org.eclipse.equinox.launcher.gtk.linux.x86_64_1.1.300.v20150602-1417 -vmargs -Xmx20240m这样能保证解析的过程中不会内存溢出。
- 将dump文件拷贝上去,执行下面几个命令生成索引及3个分析报告:
mat/ParseHeapDump.sh es_heap.bin org.eclipse.mat.api:suspectsmat/ParseHeapDump.sh es_heap.bin org.eclipse.mat.api:overviewmat/ParseHeapDump.sh es_heap.bin org.eclipse.mat.api:top_components
分析成功以后,会生成如下一堆索引文件(.index)和分析报告(.zip)
-rw-r--r--@ 1 xgwu staff 62M Nov 6 16:18 es_heap.a2s.index
-rw-r--r--@ 1 xgwu staff 25G Nov 6 14:59 es_heap.bin
-rw-r--r--@ 1 xgwu staff 90M Nov 6 16:21 es_heap.domIn.index
-rw-r--r--@ 1 xgwu staff 271M Nov 6 16:21 es_heap.domOut.index
-rw-r--r-- 1 xgwu staff 144K Nov 7 18:38 es_heap.i2sv2.index
-rw-r--r--@ 1 xgwu staff 220M Nov 6 16:18 es_heap.idx.index
-rw-r--r--@ 1 xgwu staff 356M Nov 6 16:20 es_heap.inbound.index
-rw-r--r--@ 1 xgwu staff 6.8M Nov 6 16:20 es_heap.index
-rw-r--r--@ 1 xgwu staff 76M Nov 6 16:18 es_heap.o2c.index
-rw-r--r--@ 1 xgwu staff 231M Nov 6 16:20 es_heap.o2hprof.index
-rw-r--r--@ 1 xgwu staff 206M Nov 6 16:21 es_heap.o2ret.index
-rw-r--r--@ 1 xgwu staff 353M Nov 6 16:20 es_heap.outbound.index
-rw-r--r--@ 1 xgwu staff 399K Nov 6 16:16 es_heap.threads
-rw-r--r--@ 1 xgwu staff 89K Nov 7 17:40 es_heap_Leak_Suspects.zip
-rw-r--r--@ 1 xgwu staff 78K Nov 6 19:22 es_heap_System_Overview.zip
-rw-r--r--@ 1 xgwu staff 205K Nov 6 19:22 es_heap_Top_Components.zip
drwxr-xr-x@ 3 xgwu staff 96B Nov 6 16:15 workspace将这些文件打包下载到本地机器上,用MAT GUI打开就可以分析了。
在MAT里打开dump文件的时候,可以选择打开已经生成好的报告,比如Leak suspects:

通过Leak Suspects,一眼看到这20多GB内存主要是被一堆bulk线程实例占用了,每个实例则占用了接近1.5GB的内存。

进入"dominator_tree"面板,按照"Retained Heap"排序,可以看到多个bulk线程的内存占用都非常高。

将其中一个thread的引用链条展开,看看这些线程是如何Retain这么多内存的,特别注意红圈部分:

这个引用关系解读如下:
- 这个bulk线程的thread local map里保存了一个log4j的
MultableLogEvent对象。 MutablelogEvent对象引用了log4j的ParameterizedMessage对象。ParameterizedMessage引用了bulkShardRequest对象。bulkShardRequest引用了4万多个BulkitemRequest对象。
这样看下来,似乎是log4j的logevent对一个大的bulk请求对象有强引用而导致其无法被垃圾回收掉,产生内存泄漏。
联想到ES日志里,有记录一些document missing的bulk异常,猜测是否在记录这些异常的时候产生的泄漏。
问题复现
为了验证猜测,我在本地开发机上,启动了一个单结点的5.3.2测试集群,用bulk api做批量的update,并且有意为其中1个update请求设置不存在的doc_id。为了便于测试,我在ES的配置文件elasticsearch.yml里添加了配置项processors: 1。 这个配置项影响集群thread_pool的配置,bulk thread pool的大小将减少为1个,这样可以更快速和便捷的做各类验证。
启动集群,发送完bulk请求后,立即做一个dump,重复之前的分析过程,问题得到了复现。 这时候想,是否其他bulk异常也会引起同样的问题,比如写入的数据和mapping不匹配? 测试了一下,问题果然还是会产生。再用不同的bulk size进行测试,发现无法回收的这段内存大小,取决于最后一次抛过异常的bulk size大小。至此,基本可以确定内存泄漏与log4j记录异常消息的逻辑有关系。
为了搞清楚这个问题是否5.3.2独有,后续版本是否有修复,在最新的5.6.3上做了同样的测试,问题依旧,因此这应该是一个还未发现的深层Bug.
读源码查根源
大致搞清楚问题查找的方向了,但根源还未找到,也就不知道如何修复和避免,只有去扒源码了。
在TransportShardBulkAction 第209行,找到了ES日志里抛异常的代码片段。
if (isConflictException(failure)) {
logger.trace((Supplier<?>) () -> new ParameterizedMessage("{} failed to execute bulk item ({}) {}",
request.shardId(), docWriteRequest.opType().getLowercase(), request), failure);
} else {
logger.debug((Supplier<?>) () -> new ParameterizedMessage("{} failed to execute bulk item ({}) {}",
request.shardId(), docWriteRequest.opType().getLowercase(), request), failure);
}这里看到了ParameterizedMessage实例化过程中,request做为一个参数传入了。这里的request是一个BulkShardRequest对象,保存的是要写入到一个shard的一批bulk item request。 这样以来,一个批次写入的请求数量越多,这个对象retain的内存就越多。 可问题是,为什么logger.debug()调用完毕以后,这个引用不会被释放?
通过和之前MAT上的dominator tree仔细对比,可以看到ParameterizedMessage之所以无法释放,是因为被一个MutableLogEvent在引用,而这个MutableLogEvent被做为一个thread local存放起来了。 由于ES的Bulk thread pool是fix size的,也就是预先创建好,不会销毁和再创建。 那么这些MutableLogEvent对象由于是thread local的,只要线程没有销毁,就会对该线程实例一直全局存在,并且其还会一直引用最后一次处理过的ParameterizedMessage。 所以在ES记录bulk exception这种比较大的请求情况下, 整个request对象会被thread local变量一直强引用无法释放,产生大量的内存泄漏。
再继续挖一下log4j的源码,发现MutableLogEvent是在org.apache.logging.log4j.core.impl.ReusableLogEventFactory里做为thread local创建的。
public class ReusableLogEventFactory implements LogEventFactory {
private static final ThreadNameCachingStrategy THREAD_NAME_CACHING_STRATEGY = ThreadNameCachingStrategy.create();
private static final Clock CLOCK = ClockFactory.getClock();
private static ThreadLocal<MutableLogEvent> mutableLogEventThreadLocal = new ThreadLocal<>();而org.apache.logging.log4j.core.config.LoggerConfig则根据一个常数ENABLE_THREADLOCALS的值来决定用哪个LogEventFactory。
if (LOG_EVENT_FACTORY == null) {
LOG_EVENT_FACTORY = Constants.ENABLE_THREADLOCALS
? new ReusableLogEventFactory()
: new DefaultLogEventFactory();
}继续深挖,在org.apache.logging.log4j.util.Constants里看到,log4j会根据运行环境判断是否是WEB应用,如果不是,就从系统参数log4j2.enable.threadlocals读取这个常量,如果没有设置,则默认值是true。
public static final boolean ENABLE_THREADLOCALS = !IS_WEB_APP && PropertiesUtil.getProperties().getBooleanProperty(
"log4j2.enable.threadlocals", true);由于ES不是一个web应用,导致log4j选择使用了ReusableLogEventFactory,因而使用了thread_local来创建MutableLogEvent对象,最终在ES记录bulk exception这个特殊场景下产生非常显著的内存泄漏。
再问一个问题,为何log4j要将logevent做为thread local创建? 跑到log4j的官网去扒了一下文档,在这里 Garbage-free Steady State Logging 找到了合理的解释。 原来为了减少记录日志过程中的反复创建的对象数量,减轻GC压力从而提高性能,log4j有很多地方使用了thread_local来重用变量。 但使用thread local字段装载非JDK类,可能会产生内存泄漏问题,特别是对于web应用。 因此才会在启动的时候判断运行环境,对于web应用会禁用thread local类型的变量。
ThreadLocal fields holding non-JDK classes can cause memory leaks in web applications when the application server's thread pool continues to reference these fields after the web application is undeployed. To avoid causing memory leaks, Log4j will not use these ThreadLocals when it detects that it is used in a web application (when the javax.servlet.Servlet class is in the classpath, or when system property log4j2.is.webapp is set to "true").
参考上面的文档后,也为ES找到了规避这个问题的措施: 在ES的JVM配置文件jvm.options里,添加一个log4j的系统变量-Dlog4j2.enable.threadlocals=false,禁用掉thread local即可。 经过测试,该选项可以有效避开这个内存泄漏问题。
这个问题Github上也提交了Issue,对应的链接是: Memory leak upon partial TransportShardBulkAction failure
写在最后
ES的确是非常复杂的一个系统,包含非常多的模块和第三方组件,可以支持很多想象不到的用例场景,但一些边缘场景可能会引发一些难以排查的问题。完备的监控体系和一个经验丰富的支撑团队对于提升业务开发人员使用ES开发的效率、提升业务的稳定性是非常重要的!
2018年8月24日更新: 今天放出的6.4版修复了这个问题。
原文链接: http://www.jianshu.com/p/d4f7a6d58008
前天公司度假部门一个线上ElasticSearch集群发出报警,有Data Node的Heap使用量持续超过80%警戒线。 收到报警邮件后,不敢怠慢,立即登陆监控系统查看集群状态。还好,所有的结点都在正常服务,只是有2个结点的Heap使用率非常高。此时,Old GC一直在持续的触发,却无法回收内存。
初步排查
问题结点的Heap分配了30GB,80%的使用率约等于24GB。 但集群的数据总量并不大,5个结点所有索引文件加起来占用的磁盘空间还不到10GB。
GET /_cat/allocation?v&h=shards,disk.indices,disk.used,disk.avail
shards disk.indices disk.used disk.avail
3 1.9gb 38.3gb 89.7gb
4 2.2gb 13.4gb 114.6gb
4 2.5gb 20.3gb 107.7gb
4 2.3gb 33.9gb 94.1gb
3 1.7gb 12.8gb 115.2gb查看各结点的segment memory和cache占用量也都非常小,是MB级别的。
GET /_cat/nodes?v&h=id,port,v,m,fdp,mc,mcs,sc,sm,qcm,fm,im,siwm,svmm
id port v m fdp mc mcs sc sm qcm fm siwm svmm
e1LV 9300 5.3.2 - 1 0 0b 68 69mb 1.5mb 1.9mb 0b 499b
5VnU 9300 5.3.2 - 1 0 0b 75 79mb 1.5mb 1.9mb 0b 622b
_Iob 9300 5.3.2 - 1 0 0b 56 55.7mb 1.3mb 914.1kb 0b 499b
4Kyl 9300 5.3.2 * 1 1 330.1mb 81 84.4mb 1.2mb 1.9mb 0b 622b
XEP_ 9300 5.3.2 - 1 0 0b 45 50.4mb 748.5kb 1mb 0b 622b集群的QPS只有30上下,CPU消耗10%都不到,各类thread pool的活动线程数量也都非常低。
非常费解是什么东西占着20多GB的内存不释放?
出现问题的集群ES版本是5.3.2,而这个版本的稳定性在公司内部已经经过长时间的考验,做为稳定版本在线上进行了大规模部署。 其他一些读写负载非常高的集群也未曾出现过类似的状况,看来是遇到新问题了。
查看问题结点ES的日志,除了看到一些Bulk异常以外,未见特别明显的其他和资源相关的错误:
[2017-11-06T16:33:15,668][DEBUG][o.e.a.b.TransportShardBulkAction] [] [suggest-3][0] failed to execute bulk item (update) BulkShardRequest [[suggest-3][0]] containing [44204
] requests
org.elasticsearch.index.engine.DocumentMissingException: [type][纳格尔果德_1198]: document missing
at org.elasticsearch.action.update.UpdateHelper.prepare(UpdateHelper.java:92) ~[elasticsearch-5.3.2.jar:5.3.2]
at org.elasticsearch.action.update.UpdateHelper.prepare(UpdateHelper.java:81) ~[elasticsearch-5.3.2.jar:5.3.2]和用户确认这些异常的原因,是因为写入程序会从数据源拿到数据后,根据doc_id对ES里的数据做update。会有部分doc_id在ES里不存在的情况,但并不影响业务逻辑,因而ES记录的document missing异常应该可以忽略。
至此别无他法,只能对JVM做Dump分析了。
Heap Dump分析
用的工具是Eclipse MAT,从这里下载的Mac版:Downloads 。 使用这个工具需要经过以下2个步骤:
- 获取二进制的head dump文件
jmap -dump:format=b,file=/tmp/es_heap.bin <pid>其中pid是ES JAVA进程的进程号。 - 将生成的dump文件下载到本地开发机器,启动MAT,从其GUI打开文件。
要注意,MAT本身也是JAVA应用,需要有JDK运行环境的支持。
MAT第一次打dump文件的时候,需要对其解析,生成多个索引。这个过程比较消耗CPU和内存,但一旦完成,之后再打开dump文件就很快,消耗很低。 对于这种20多GB的大文件,第一次解析的过程会非常缓慢,并且很可能因为开发机内存的较少而内存溢出。因此,我找了台大内存的服务器来做第一次的解析工作:
-
将linux版的MAT拷贝上去,解压缩后,修改配置文件MemoryAnalyzer.ini,将内存设置为20GB左右:
$ cat MemoryAnalyzer.ini -startup plugins/org.eclipse.equinox.launcher_1.3.100.v20150511-1540.jar --launcher.library plugins/org.eclipse.equinox.launcher.gtk.linux.x86_64_1.1.300.v20150602-1417 -vmargs -Xmx20240m这样能保证解析的过程中不会内存溢出。
- 将dump文件拷贝上去,执行下面几个命令生成索引及3个分析报告:
mat/ParseHeapDump.sh es_heap.bin org.eclipse.mat.api:suspectsmat/ParseHeapDump.sh es_heap.bin org.eclipse.mat.api:overviewmat/ParseHeapDump.sh es_heap.bin org.eclipse.mat.api:top_components
分析成功以后,会生成如下一堆索引文件(.index)和分析报告(.zip)
-rw-r--r--@ 1 xgwu staff 62M Nov 6 16:18 es_heap.a2s.index
-rw-r--r--@ 1 xgwu staff 25G Nov 6 14:59 es_heap.bin
-rw-r--r--@ 1 xgwu staff 90M Nov 6 16:21 es_heap.domIn.index
-rw-r--r--@ 1 xgwu staff 271M Nov 6 16:21 es_heap.domOut.index
-rw-r--r-- 1 xgwu staff 144K Nov 7 18:38 es_heap.i2sv2.index
-rw-r--r--@ 1 xgwu staff 220M Nov 6 16:18 es_heap.idx.index
-rw-r--r--@ 1 xgwu staff 356M Nov 6 16:20 es_heap.inbound.index
-rw-r--r--@ 1 xgwu staff 6.8M Nov 6 16:20 es_heap.index
-rw-r--r--@ 1 xgwu staff 76M Nov 6 16:18 es_heap.o2c.index
-rw-r--r--@ 1 xgwu staff 231M Nov 6 16:20 es_heap.o2hprof.index
-rw-r--r--@ 1 xgwu staff 206M Nov 6 16:21 es_heap.o2ret.index
-rw-r--r--@ 1 xgwu staff 353M Nov 6 16:20 es_heap.outbound.index
-rw-r--r--@ 1 xgwu staff 399K Nov 6 16:16 es_heap.threads
-rw-r--r--@ 1 xgwu staff 89K Nov 7 17:40 es_heap_Leak_Suspects.zip
-rw-r--r--@ 1 xgwu staff 78K Nov 6 19:22 es_heap_System_Overview.zip
-rw-r--r--@ 1 xgwu staff 205K Nov 6 19:22 es_heap_Top_Components.zip
drwxr-xr-x@ 3 xgwu staff 96B Nov 6 16:15 workspace将这些文件打包下载到本地机器上,用MAT GUI打开就可以分析了。
在MAT里打开dump文件的时候,可以选择打开已经生成好的报告,比如Leak suspects:
通过Leak Suspects,一眼看到这20多GB内存主要是被一堆bulk线程实例占用了,每个实例则占用了接近1.5GB的内存。
进入"dominator_tree"面板,按照"Retained Heap"排序,可以看到多个bulk线程的内存占用都非常高。
将其中一个thread的引用链条展开,看看这些线程是如何Retain这么多内存的,特别注意红圈部分:
这个引用关系解读如下:
- 这个bulk线程的thread local map里保存了一个log4j的
MultableLogEvent对象。 MutablelogEvent对象引用了log4j的ParameterizedMessage对象。ParameterizedMessage引用了bulkShardRequest对象。bulkShardRequest引用了4万多个BulkitemRequest对象。
这样看下来,似乎是log4j的logevent对一个大的bulk请求对象有强引用而导致其无法被垃圾回收掉,产生内存泄漏。
联想到ES日志里,有记录一些document missing的bulk异常,猜测是否在记录这些异常的时候产生的泄漏。
问题复现
为了验证猜测,我在本地开发机上,启动了一个单结点的5.3.2测试集群,用bulk api做批量的update,并且有意为其中1个update请求设置不存在的doc_id。为了便于测试,我在ES的配置文件elasticsearch.yml里添加了配置项processors: 1。 这个配置项影响集群thread_pool的配置,bulk thread pool的大小将减少为1个,这样可以更快速和便捷的做各类验证。
启动集群,发送完bulk请求后,立即做一个dump,重复之前的分析过程,问题得到了复现。 这时候想,是否其他bulk异常也会引起同样的问题,比如写入的数据和mapping不匹配? 测试了一下,问题果然还是会产生。再用不同的bulk size进行测试,发现无法回收的这段内存大小,取决于最后一次抛过异常的bulk size大小。至此,基本可以确定内存泄漏与log4j记录异常消息的逻辑有关系。
为了搞清楚这个问题是否5.3.2独有,后续版本是否有修复,在最新的5.6.3上做了同样的测试,问题依旧,因此这应该是一个还未发现的深层Bug.
读源码查根源
大致搞清楚问题查找的方向了,但根源还未找到,也就不知道如何修复和避免,只有去扒源码了。
在TransportShardBulkAction 第209行,找到了ES日志里抛异常的代码片段。
if (isConflictException(failure)) {
logger.trace((Supplier<?>) () -> new ParameterizedMessage("{} failed to execute bulk item ({}) {}",
request.shardId(), docWriteRequest.opType().getLowercase(), request), failure);
} else {
logger.debug((Supplier<?>) () -> new ParameterizedMessage("{} failed to execute bulk item ({}) {}",
request.shardId(), docWriteRequest.opType().getLowercase(), request), failure);
}这里看到了ParameterizedMessage实例化过程中,request做为一个参数传入了。这里的request是一个BulkShardRequest对象,保存的是要写入到一个shard的一批bulk item request。 这样以来,一个批次写入的请求数量越多,这个对象retain的内存就越多。 可问题是,为什么logger.debug()调用完毕以后,这个引用不会被释放?
通过和之前MAT上的dominator tree仔细对比,可以看到ParameterizedMessage之所以无法释放,是因为被一个MutableLogEvent在引用,而这个MutableLogEvent被做为一个thread local存放起来了。 由于ES的Bulk thread pool是fix size的,也就是预先创建好,不会销毁和再创建。 那么这些MutableLogEvent对象由于是thread local的,只要线程没有销毁,就会对该线程实例一直全局存在,并且其还会一直引用最后一次处理过的ParameterizedMessage。 所以在ES记录bulk exception这种比较大的请求情况下, 整个request对象会被thread local变量一直强引用无法释放,产生大量的内存泄漏。
再继续挖一下log4j的源码,发现MutableLogEvent是在org.apache.logging.log4j.core.impl.ReusableLogEventFactory里做为thread local创建的。
public class ReusableLogEventFactory implements LogEventFactory {
private static final ThreadNameCachingStrategy THREAD_NAME_CACHING_STRATEGY = ThreadNameCachingStrategy.create();
private static final Clock CLOCK = ClockFactory.getClock();
private static ThreadLocal<MutableLogEvent> mutableLogEventThreadLocal = new ThreadLocal<>();而org.apache.logging.log4j.core.config.LoggerConfig则根据一个常数ENABLE_THREADLOCALS的值来决定用哪个LogEventFactory。
if (LOG_EVENT_FACTORY == null) {
LOG_EVENT_FACTORY = Constants.ENABLE_THREADLOCALS
? new ReusableLogEventFactory()
: new DefaultLogEventFactory();
}继续深挖,在org.apache.logging.log4j.util.Constants里看到,log4j会根据运行环境判断是否是WEB应用,如果不是,就从系统参数log4j2.enable.threadlocals读取这个常量,如果没有设置,则默认值是true。
public static final boolean ENABLE_THREADLOCALS = !IS_WEB_APP && PropertiesUtil.getProperties().getBooleanProperty(
"log4j2.enable.threadlocals", true);由于ES不是一个web应用,导致log4j选择使用了ReusableLogEventFactory,因而使用了thread_local来创建MutableLogEvent对象,最终在ES记录bulk exception这个特殊场景下产生非常显著的内存泄漏。
再问一个问题,为何log4j要将logevent做为thread local创建? 跑到log4j的官网去扒了一下文档,在这里 Garbage-free Steady State Logging 找到了合理的解释。 原来为了减少记录日志过程中的反复创建的对象数量,减轻GC压力从而提高性能,log4j有很多地方使用了thread_local来重用变量。 但使用thread local字段装载非JDK类,可能会产生内存泄漏问题,特别是对于web应用。 因此才会在启动的时候判断运行环境,对于web应用会禁用thread local类型的变量。
ThreadLocal fields holding non-JDK classes can cause memory leaks in web applications when the application server's thread pool continues to reference these fields after the web application is undeployed. To avoid causing memory leaks, Log4j will not use these ThreadLocals when it detects that it is used in a web application (when the javax.servlet.Servlet class is in the classpath, or when system property log4j2.is.webapp is set to "true").
参考上面的文档后,也为ES找到了规避这个问题的措施: 在ES的JVM配置文件jvm.options里,添加一个log4j的系统变量-Dlog4j2.enable.threadlocals=false,禁用掉thread local即可。 经过测试,该选项可以有效避开这个内存泄漏问题。
这个问题Github上也提交了Issue,对应的链接是: Memory leak upon partial TransportShardBulkAction failure
写在最后
ES的确是非常复杂的一个系统,包含非常多的模块和第三方组件,可以支持很多想象不到的用例场景,但一些边缘场景可能会引发一些难以排查的问题。完备的监控体系和一个经验丰富的支撑团队对于提升业务开发人员使用ES开发的效率、提升业务的稳定性是非常重要的!
收起阅读 »社区日报 第94期 (2017-11-08)
Part1 http://t.cn/R5eAIJz
Part2 http://t.cn/RtCo3Sw
Part3 http://t.cn/Rt0avHj
2. Siddontang 大神的 Elasticsearch学习笔记(在 github 上,版本不是很新,仅供参考)
http://t.cn/Rl0kKfd
3. Elasticsearch 数据备份,恢复,及迁移(2015年文章)
http://t.cn/RL3YX6g
编辑:江水
归档:https://elasticsearch.cn/article/360
订阅:https://tinyletter.com/elastic-daily
Part1 http://t.cn/R5eAIJz
Part2 http://t.cn/RtCo3Sw
Part3 http://t.cn/Rt0avHj
2. Siddontang 大神的 Elasticsearch学习笔记(在 github 上,版本不是很新,仅供参考)
http://t.cn/Rl0kKfd
3. Elasticsearch 数据备份,恢复,及迁移(2015年文章)
http://t.cn/RL3YX6g
编辑:江水
归档:https://elasticsearch.cn/article/360
订阅:https://tinyletter.com/elastic-daily 收起阅读 »
Elastic XPack 对初创公司开放优惠申请啦!
如果你是创业公司的员工,并且你们在使用 elastic 的产品解决自己的业务问题,比如 elasticsearch、kibana、logstash 等,又对 X-Pack 很感兴趣,现在可以申请初创公司优惠价格了,真的很优惠,走过路过不要错过!
初创公司定义为:
1. 公司人数50人以内
2. 年销售额500万以内
3. 注册资金2500万以内。
申请方式为:
访问 http://elastictech.cn ,点击右上角的【创业公司优惠申请】链接填写相关信息即可!
如果你是创业公司的员工,并且你们在使用 elastic 的产品解决自己的业务问题,比如 elasticsearch、kibana、logstash 等,又对 X-Pack 很感兴趣,现在可以申请初创公司优惠价格了,真的很优惠,走过路过不要错过!
初创公司定义为:
1. 公司人数50人以内
2. 年销售额500万以内
3. 注册资金2500万以内。
申请方式为:
访问 http://elastictech.cn ,点击右上角的【创业公司优惠申请】链接填写相关信息即可! 收起阅读 »
【京东商城】ES高级工程师
薪资待遇:25k ~ 40k
工作内容:
1、开发、维护ES及相应管理后台
2、ElasticSearch集群的配置管理及优化
3、个性化功能及插件开发。
职位要求:
1、本科以上学历,4年以上工作经验。
2、精通Java,熟悉各种中间件技术及常用框架。
3、熟悉Elasticsearch,有相应开发维护经验者优先。
京东正大力推进Elasticsearch的使用场景,目前已有数千个实例,每日新增数据百T,日查询量千亿级别,技术氛围好,发展潜力大。欢迎您的加入~
欢迎投递简历至:wanghanghang@jd.com
薪资待遇:25k ~ 40k
工作内容:
1、开发、维护ES及相应管理后台
2、ElasticSearch集群的配置管理及优化
3、个性化功能及插件开发。
职位要求:
1、本科以上学历,4年以上工作经验。
2、精通Java,熟悉各种中间件技术及常用框架。
3、熟悉Elasticsearch,有相应开发维护经验者优先。
京东正大力推进Elasticsearch的使用场景,目前已有数千个实例,每日新增数据百T,日查询量千亿级别,技术氛围好,发展潜力大。欢迎您的加入~
欢迎投递简历至:wanghanghang@jd.com
收起阅读 »
社区日报 第93期 (2017-11-07)
http://t.cn/RloiI8o
2.用elastic stack来分析下你的redis slowlog
http://t.cn/Rlo6dQu
3.ES分片recovery 流程分析与速度优化
http://t.cn/RloJr8Q
编辑:叮咚光军
归档:https://elasticsearch.cn/article/357
订阅:https://tinyletter.com/elastic-daily
http://t.cn/RloiI8o
2.用elastic stack来分析下你的redis slowlog
http://t.cn/Rlo6dQu
3.ES分片recovery 流程分析与速度优化
http://t.cn/RloJr8Q
编辑:叮咚光军
归档:https://elasticsearch.cn/article/357
订阅:https://tinyletter.com/elastic-daily
收起阅读 »
ElasticSearch 集群监控
原文地址:http://www.54tianzhisheng.cn/2017/10/15/ElasticSearch-cluster-health-metrics/

最近在做 ElasticSearch 的信息(集群和节点)监控,特此稍微整理下学到的东西。这篇文章主要介绍集群的监控。
要监控哪些 ElasticSearch metrics
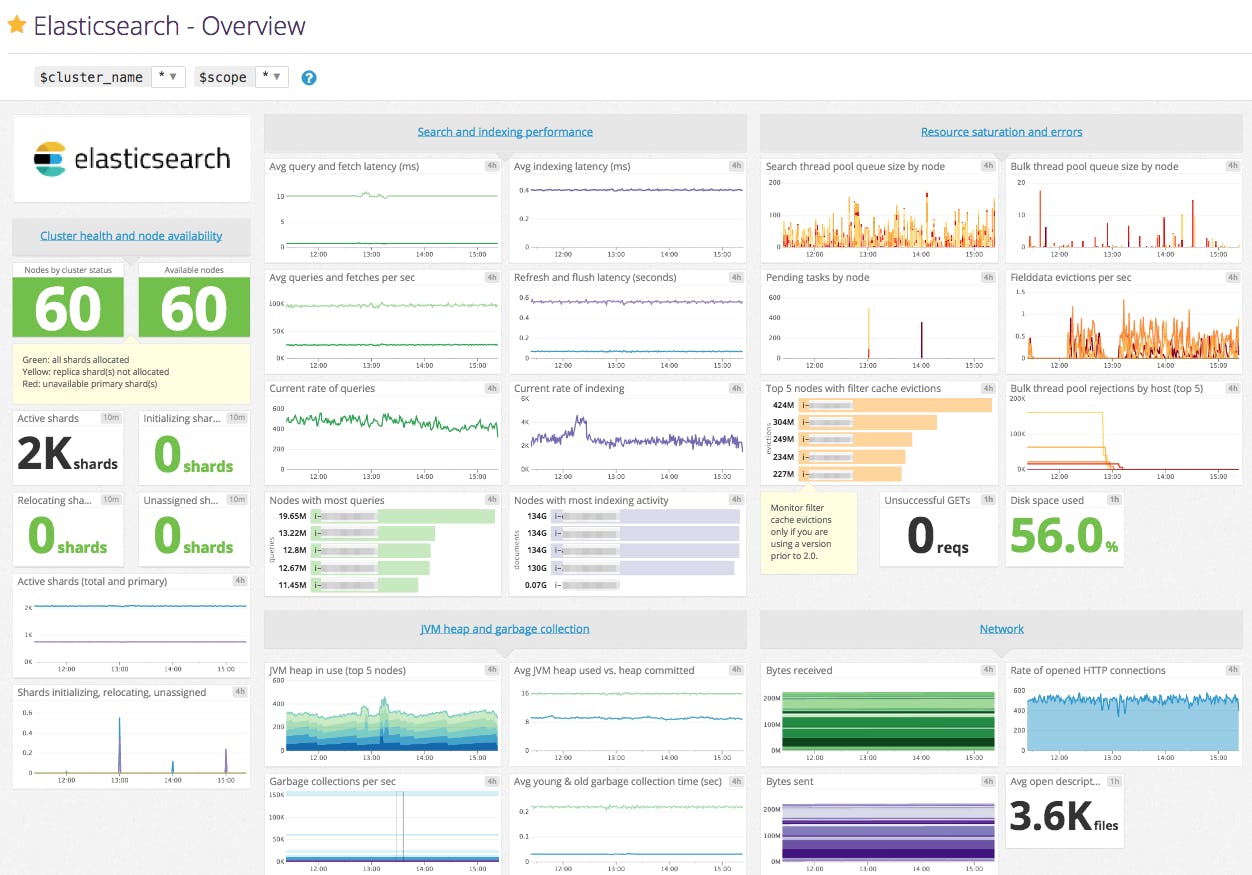
Elasticsearch 提供了大量的 Metric,可以帮助您检测到问题的迹象,在遇到节点不可用、out-of-memory、long garbage collection times 的时候采取相应措施。但是指标太多了,有时我们并不需要这么多,这就需要我们进行筛选。
集群健康
一个 Elasticsearch 集群至少包括一个节点和一个索引。或者它 可能有一百个数据节点、三个单独的主节点,以及一小打客户端节点——这些共同操作一千个索引(以及上万个分片)。
不管集群扩展到多大规模,你都会想要一个快速获取集群状态的途径。Cluster Health API 充当的就是这个角色。你可以把它想象成是在一万英尺的高度鸟瞰集群。它可以告诉你安心吧一切都好,或者警告你集群某个地方有问题。
让我们执行一下 cluster-health API 然后看看响应体是什么样子的:
GET _cluster/health和 Elasticsearch 里其他 API 一样,cluster-health 会返回一个 JSON 响应。这对自动化和告警系统来说,非常便于解析。响应中包含了和你集群有关的一些关键信息:
{
"cluster_name": "elasticsearch_zach",
"status": "green",
"timed_out": false,
"number_of_nodes": 1,
"number_of_data_nodes": 1,
"active_primary_shards": 10,
"active_shards": 10,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 0
}响应信息中最重要的一块就是 status 字段。状态可能是下列三个值之一 :
| status | 含义 |
|---|---|
| green | 所有的主分片和副本分片都已分配。你的集群是 100% 可用的。 |
| yellow | 所有的主分片已经分片了,但至少还有一个副本是缺失的。不会有数据丢失,所以搜索结果依然是完整的。不过,你的高可用性在某种程度上被弱化。如果 更多的 分片消失,你就会丢数据了。把 yellow 想象成一个需要及时调查的警告。 |
| red | 至少一个主分片(以及它的全部副本)都在缺失中。这意味着你在缺少数据:搜索只能返回部分数据,而分配到这个分片上的写入请求会返回一个异常。 |
number_of_nodes和number_of_data_nodes这个命名完全是自描述的。active_primary_shards指出你集群中的主分片数量。这是涵盖了所有索引的汇总值。active_shards是涵盖了所有索引的所有分片的汇总值,即包括副本分片。relocating_shards显示当前正在从一个节点迁往其他节点的分片的数量。通常来说应该是 0,不过在 Elasticsearch 发现集群不太均衡时,该值会上涨。比如说:添加了一个新节点,或者下线了一个节点。initializing_shards是刚刚创建的分片的个数。比如,当你刚创建第一个索引,分片都会短暂的处于initializing状态。这通常会是一个临时事件,分片不应该长期停留在initializing状态。你还可能在节点刚重启的时候看到initializing分片:当分片从磁盘上加载后,它们会从initializing状态开始。unassigned_shards是已经在集群状态中存在的分片,但是实际在集群里又找不着。通常未分配分片的来源是未分配的副本。比如,一个有 5 分片和 1 副本的索引,在单节点集群上,就会有 5 个未分配副本分片。如果你的集群是red状态,也会长期保有未分配分片(因为缺少主分片)。
集群统计
集群统计信息包含 集群的分片数,文档数,存储空间,缓存信息,内存作用率,插件内容,文件系统内容,JVM 作用状况,系统 CPU,OS 信息,段信息。
查看全部统计信息命令:
curl -XGET 'http://localhost:9200/_cluster/stats?human&pretty'返回 JSON 结果:
{
"timestamp": 1459427693515,
"cluster_name": "elasticsearch",
"status": "green",
"indices": {
"count": 2,
"shards": {
"total": 10,
"primaries": 10,
"replication": 0,
"index": {
"shards": {
"min": 5,
"max": 5,
"avg": 5
},
"primaries": {
"min": 5,
"max": 5,
"avg": 5
},
"replication": {
"min": 0,
"max": 0,
"avg": 0
}
}
},
"docs": {
"count": 10,
"deleted": 0
},
"store": {
"size": "16.2kb",
"size_in_bytes": 16684,
"throttle_time": "0s",
"throttle_time_in_millis": 0
},
"fielddata": {
"memory_size": "0b",
"memory_size_in_bytes": 0,
"evictions": 0
},
"query_cache": {
"memory_size": "0b",
"memory_size_in_bytes": 0,
"total_count": 0,
"hit_count": 0,
"miss_count": 0,
"cache_size": 0,
"cache_count": 0,
"evictions": 0
},
"completion": {
"size": "0b",
"size_in_bytes": 0
},
"segments": {
"count": 4,
"memory": "8.6kb",
"memory_in_bytes": 8898,
"terms_memory": "6.3kb",
"terms_memory_in_bytes": 6522,
"stored_fields_memory": "1.2kb",
"stored_fields_memory_in_bytes": 1248,
"term_vectors_memory": "0b",
"term_vectors_memory_in_bytes": 0,
"norms_memory": "384b",
"norms_memory_in_bytes": 384,
"doc_values_memory": "744b",
"doc_values_memory_in_bytes": 744,
"index_writer_memory": "0b",
"index_writer_memory_in_bytes": 0,
"version_map_memory": "0b",
"version_map_memory_in_bytes": 0,
"fixed_bit_set": "0b",
"fixed_bit_set_memory_in_bytes": 0,
"file_sizes": {}
},
"percolator": {
"num_queries": 0
}
},
"nodes": {
"count": {
"total": 1,
"data": 1,
"coordinating_only": 0,
"master": 1,
"ingest": 1
},
"versions": [
"5.6.3"
],
"os": {
"available_processors": 8,
"allocated_processors": 8,
"names": [
{
"name": "Mac OS X",
"count": 1
}
],
"mem" : {
"total" : "16gb",
"total_in_bytes" : 17179869184,
"free" : "78.1mb",
"free_in_bytes" : 81960960,
"used" : "15.9gb",
"used_in_bytes" : 17097908224,
"free_percent" : 0,
"used_percent" : 100
}
},
"process": {
"cpu": {
"percent": 9
},
"open_file_descriptors": {
"min": 268,
"max": 268,
"avg": 268
}
},
"jvm": {
"max_uptime": "13.7s",
"max_uptime_in_millis": 13737,
"versions": [
{
"version": "1.8.0_74",
"vm_name": "Java HotSpot(TM) 64-Bit Server VM",
"vm_version": "25.74-b02",
"vm_vendor": "Oracle Corporation",
"count": 1
}
],
"mem": {
"heap_used": "57.5mb",
"heap_used_in_bytes": 60312664,
"heap_max": "989.8mb",
"heap_max_in_bytes": 1037959168
},
"threads": 90
},
"fs": {
"total": "200.6gb",
"total_in_bytes": 215429193728,
"free": "32.6gb",
"free_in_bytes": 35064553472,
"available": "32.4gb",
"available_in_bytes": 34802409472
},
"plugins": [
{
"name": "analysis-icu",
"version": "5.6.3",
"description": "The ICU Analysis plugin integrates Lucene ICU module into elasticsearch, adding ICU relates analysis components.",
"classname": "org.elasticsearch.plugin.analysis.icu.AnalysisICUPlugin",
"has_native_controller": false
},
{
"name": "ingest-geoip",
"version": "5.6.3",
"description": "Ingest processor that uses looksup geo data based on ip adresses using the Maxmind geo database",
"classname": "org.elasticsearch.ingest.geoip.IngestGeoIpPlugin",
"has_native_controller": false
},
{
"name": "ingest-user-agent",
"version": "5.6.3",
"description": "Ingest processor that extracts information from a user agent",
"classname": "org.elasticsearch.ingest.useragent.IngestUserAgentPlugin",
"has_native_controller": false
}
]
}
}内存使用和 GC 指标
在运行 Elasticsearch 时,内存是您要密切监控的关键资源之一。 Elasticsearch 和 Lucene 以两种方式利用节点上的所有可用 RAM:JVM heap 和文件系统缓存。 Elasticsearch 运行在Java虚拟机(JVM)中,这意味着JVM垃圾回收的持续时间和频率将成为其他重要的监控领域。
上面返回的 JSON监控的指标有我个人觉得有这些:
- nodes.successful
- nodes.failed
- nodes.total
- nodes.mem.used_percent
- nodes.process.cpu.percent
- nodes.jvm.mem.heap_used
可以看到 JSON 文件是很复杂的,如果从这复杂的 JSON 中获取到对应的指标(key)的值呢,这里请看文章 :JsonPath —— JSON 解析神器
最后
这里主要讲下 ES 集群的一些监控信息,有些监控指标是个人觉得需要监控的,但是具体情况还是得看需求了。下篇文章主要讲节点的监控信息。转载请注明地址:http://www.54tianzhisheng.cn/2017/10/15/ElasticSearch-cluster-health-metrics/
参考资料
1、How to monitor Elasticsearch performance
相关阅读
原文地址:http://www.54tianzhisheng.cn/2017/10/15/ElasticSearch-cluster-health-metrics/
最近在做 ElasticSearch 的信息(集群和节点)监控,特此稍微整理下学到的东西。这篇文章主要介绍集群的监控。
要监控哪些 ElasticSearch metrics
Elasticsearch 提供了大量的 Metric,可以帮助您检测到问题的迹象,在遇到节点不可用、out-of-memory、long garbage collection times 的时候采取相应措施。但是指标太多了,有时我们并不需要这么多,这就需要我们进行筛选。
集群健康
一个 Elasticsearch 集群至少包括一个节点和一个索引。或者它 可能有一百个数据节点、三个单独的主节点,以及一小打客户端节点——这些共同操作一千个索引(以及上万个分片)。
不管集群扩展到多大规模,你都会想要一个快速获取集群状态的途径。Cluster Health API 充当的就是这个角色。你可以把它想象成是在一万英尺的高度鸟瞰集群。它可以告诉你安心吧一切都好,或者警告你集群某个地方有问题。
让我们执行一下 cluster-health API 然后看看响应体是什么样子的:
GET _cluster/health和 Elasticsearch 里其他 API 一样,cluster-health 会返回一个 JSON 响应。这对自动化和告警系统来说,非常便于解析。响应中包含了和你集群有关的一些关键信息:
{
"cluster_name": "elasticsearch_zach",
"status": "green",
"timed_out": false,
"number_of_nodes": 1,
"number_of_data_nodes": 1,
"active_primary_shards": 10,
"active_shards": 10,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 0
}响应信息中最重要的一块就是 status 字段。状态可能是下列三个值之一 :
| status | 含义 |
|---|---|
| green | 所有的主分片和副本分片都已分配。你的集群是 100% 可用的。 |
| yellow | 所有的主分片已经分片了,但至少还有一个副本是缺失的。不会有数据丢失,所以搜索结果依然是完整的。不过,你的高可用性在某种程度上被弱化。如果 更多的 分片消失,你就会丢数据了。把 yellow 想象成一个需要及时调查的警告。 |
| red | 至少一个主分片(以及它的全部副本)都在缺失中。这意味着你在缺少数据:搜索只能返回部分数据,而分配到这个分片上的写入请求会返回一个异常。 |
number_of_nodes和number_of_data_nodes这个命名完全是自描述的。active_primary_shards指出你集群中的主分片数量。这是涵盖了所有索引的汇总值。active_shards是涵盖了所有索引的所有分片的汇总值,即包括副本分片。relocating_shards显示当前正在从一个节点迁往其他节点的分片的数量。通常来说应该是 0,不过在 Elasticsearch 发现集群不太均衡时,该值会上涨。比如说:添加了一个新节点,或者下线了一个节点。initializing_shards是刚刚创建的分片的个数。比如,当你刚创建第一个索引,分片都会短暂的处于initializing状态。这通常会是一个临时事件,分片不应该长期停留在initializing状态。你还可能在节点刚重启的时候看到initializing分片:当分片从磁盘上加载后,它们会从initializing状态开始。unassigned_shards是已经在集群状态中存在的分片,但是实际在集群里又找不着。通常未分配分片的来源是未分配的副本。比如,一个有 5 分片和 1 副本的索引,在单节点集群上,就会有 5 个未分配副本分片。如果你的集群是red状态,也会长期保有未分配分片(因为缺少主分片)。
集群统计
集群统计信息包含 集群的分片数,文档数,存储空间,缓存信息,内存作用率,插件内容,文件系统内容,JVM 作用状况,系统 CPU,OS 信息,段信息。
查看全部统计信息命令:
curl -XGET 'http://localhost:9200/_cluster/stats?human&pretty'返回 JSON 结果:
{
"timestamp": 1459427693515,
"cluster_name": "elasticsearch",
"status": "green",
"indices": {
"count": 2,
"shards": {
"total": 10,
"primaries": 10,
"replication": 0,
"index": {
"shards": {
"min": 5,
"max": 5,
"avg": 5
},
"primaries": {
"min": 5,
"max": 5,
"avg": 5
},
"replication": {
"min": 0,
"max": 0,
"avg": 0
}
}
},
"docs": {
"count": 10,
"deleted": 0
},
"store": {
"size": "16.2kb",
"size_in_bytes": 16684,
"throttle_time": "0s",
"throttle_time_in_millis": 0
},
"fielddata": {
"memory_size": "0b",
"memory_size_in_bytes": 0,
"evictions": 0
},
"query_cache": {
"memory_size": "0b",
"memory_size_in_bytes": 0,
"total_count": 0,
"hit_count": 0,
"miss_count": 0,
"cache_size": 0,
"cache_count": 0,
"evictions": 0
},
"completion": {
"size": "0b",
"size_in_bytes": 0
},
"segments": {
"count": 4,
"memory": "8.6kb",
"memory_in_bytes": 8898,
"terms_memory": "6.3kb",
"terms_memory_in_bytes": 6522,
"stored_fields_memory": "1.2kb",
"stored_fields_memory_in_bytes": 1248,
"term_vectors_memory": "0b",
"term_vectors_memory_in_bytes": 0,
"norms_memory": "384b",
"norms_memory_in_bytes": 384,
"doc_values_memory": "744b",
"doc_values_memory_in_bytes": 744,
"index_writer_memory": "0b",
"index_writer_memory_in_bytes": 0,
"version_map_memory": "0b",
"version_map_memory_in_bytes": 0,
"fixed_bit_set": "0b",
"fixed_bit_set_memory_in_bytes": 0,
"file_sizes": {}
},
"percolator": {
"num_queries": 0
}
},
"nodes": {
"count": {
"total": 1,
"data": 1,
"coordinating_only": 0,
"master": 1,
"ingest": 1
},
"versions": [
"5.6.3"
],
"os": {
"available_processors": 8,
"allocated_processors": 8,
"names": [
{
"name": "Mac OS X",
"count": 1
}
],
"mem" : {
"total" : "16gb",
"total_in_bytes" : 17179869184,
"free" : "78.1mb",
"free_in_bytes" : 81960960,
"used" : "15.9gb",
"used_in_bytes" : 17097908224,
"free_percent" : 0,
"used_percent" : 100
}
},
"process": {
"cpu": {
"percent": 9
},
"open_file_descriptors": {
"min": 268,
"max": 268,
"avg": 268
}
},
"jvm": {
"max_uptime": "13.7s",
"max_uptime_in_millis": 13737,
"versions": [
{
"version": "1.8.0_74",
"vm_name": "Java HotSpot(TM) 64-Bit Server VM",
"vm_version": "25.74-b02",
"vm_vendor": "Oracle Corporation",
"count": 1
}
],
"mem": {
"heap_used": "57.5mb",
"heap_used_in_bytes": 60312664,
"heap_max": "989.8mb",
"heap_max_in_bytes": 1037959168
},
"threads": 90
},
"fs": {
"total": "200.6gb",
"total_in_bytes": 215429193728,
"free": "32.6gb",
"free_in_bytes": 35064553472,
"available": "32.4gb",
"available_in_bytes": 34802409472
},
"plugins": [
{
"name": "analysis-icu",
"version": "5.6.3",
"description": "The ICU Analysis plugin integrates Lucene ICU module into elasticsearch, adding ICU relates analysis components.",
"classname": "org.elasticsearch.plugin.analysis.icu.AnalysisICUPlugin",
"has_native_controller": false
},
{
"name": "ingest-geoip",
"version": "5.6.3",
"description": "Ingest processor that uses looksup geo data based on ip adresses using the Maxmind geo database",
"classname": "org.elasticsearch.ingest.geoip.IngestGeoIpPlugin",
"has_native_controller": false
},
{
"name": "ingest-user-agent",
"version": "5.6.3",
"description": "Ingest processor that extracts information from a user agent",
"classname": "org.elasticsearch.ingest.useragent.IngestUserAgentPlugin",
"has_native_controller": false
}
]
}
}内存使用和 GC 指标
在运行 Elasticsearch 时,内存是您要密切监控的关键资源之一。 Elasticsearch 和 Lucene 以两种方式利用节点上的所有可用 RAM:JVM heap 和文件系统缓存。 Elasticsearch 运行在Java虚拟机(JVM)中,这意味着JVM垃圾回收的持续时间和频率将成为其他重要的监控领域。
上面返回的 JSON监控的指标有我个人觉得有这些:
- nodes.successful
- nodes.failed
- nodes.total
- nodes.mem.used_percent
- nodes.process.cpu.percent
- nodes.jvm.mem.heap_used
可以看到 JSON 文件是很复杂的,如果从这复杂的 JSON 中获取到对应的指标(key)的值呢,这里请看文章 :JsonPath —— JSON 解析神器
最后
这里主要讲下 ES 集群的一些监控信息,有些监控指标是个人觉得需要监控的,但是具体情况还是得看需求了。下篇文章主要讲节点的监控信息。转载请注明地址:http://www.54tianzhisheng.cn/2017/10/15/ElasticSearch-cluster-health-metrics/
参考资料
1、How to monitor Elasticsearch performance
相关阅读
1、Elasticsearch 默认分词器和中分分词器之间的比较及使用方法
2、全文搜索引擎 Elasticsearch 集群搭建入门教程
收起阅读 »ElasticSearch 单个节点监控
原文地址:http://www.54tianzhisheng.cn/2017/10/18/ElasticSearch-nodes-metrics/

集群健康监控是对集群信息进行高度的概括,节点统计值 API 提供了集群中每个节点的统计值。节点统计值很多,在监控的时候仍需要我们清楚哪些指标是最值得关注的。
集群健康监控可以参考这篇文章:ElasticSearch 集群监控
节点信息 Node Info :
curl -XGET 'http://localhost:9200/_nodes'执行上述命令可以获取所有 node 的信息
_nodes: {
total: 2,
successful: 2,
failed: 0
},
cluster_name: "elasticsearch",
nodes: {
MSQ_CZ7mTNyOSlYIfrvHag: {
name: "node0",
transport_address: "192.168.180.110:9300",
host: "192.168.180.110",
ip: "192.168.180.110",
version: "5.5.0",
build_hash: "260387d",
total_indexing_buffer: 103887667,
roles:{...},
settings: {...},
os: {
refresh_interval_in_millis: 1000,
name: "Linux",
arch: "amd64",
version: "3.10.0-229.el7.x86_64",
available_processors: 4,
allocated_processors: 4
},
process: {
refresh_interval_in_millis: 1000,
id: 3022,
mlockall: false
},
jvm: {
pid: 3022,
version: "1.8.0_121",
vm_name: "Java HotSpot(TM) 64-Bit Server VM",
vm_version: "25.121-b13",
vm_vendor: "Oracle Corporation",
start_time_in_millis: 1507515225302,
mem: {
heap_init_in_bytes: 1073741824,
heap_max_in_bytes: 1038876672,
non_heap_init_in_bytes: 2555904,
non_heap_max_in_bytes: 0,
direct_max_in_bytes: 1038876672
},
gc_collectors: [],
memory_pools: [],
using_compressed_ordinary_object_pointers: "true",
input_arguments:{}
}
thread_pool:{
force_merge: {},
fetch_shard_started: {},
listener: {},
index: {},
refresh: {},
generic: {},
warmer: {},
search: {},
flush: {},
fetch_shard_store: {},
management: {},
get: {},
bulk: {},
snapshot: {}
}
transport: {...},
http: {...},
plugins: [],
modules: [],
ingest: {...}
}上面是我已经简写了很多数据之后的返回值,但是指标还是很多,有些是一些常规的指标,对于监控来说,没必要拿取。从上面我们可以主要关注以下这些指标:
os, process, jvm, thread_pool, transport, http, ingest and indices节点统计 nodes-statistics
节点统计值 API 可通过如下命令获取:
GET /_nodes/stats得到:
_nodes: {
total: 2,
successful: 2,
failed: 0
},
cluster_name: "elasticsearch",
nodes: {
MSQ_CZ7mTNyOSlYI0yvHag: {
timestamp: 1508312932354,
name: "node0",
transport_address: "192.168.180.110:9300",
host: "192.168.180.110",
ip: "192.168.180.110:9300",
roles: [],
indices: {
docs: {
count: 6163666,
deleted: 0
},
store: {
size_in_bytes: 2301398179,
throttle_time_in_millis: 122850
},
indexing: {},
get: {},
search: {},
merges: {},
refresh: {},
flush: {},
warmer: {},
query_cache: {},
fielddata: {},
completion: {},
segments: {},
translog: {},
request_cache: {},
recovery: {}
},
os: {
timestamp: 1508312932369,
cpu: {
percent: 0,
load_average: {
1m: 0.09,
5m: 0.12,
15m: 0.08
}
},
mem: {
total_in_bytes: 8358301696,
free_in_bytes: 1381613568,
used_in_bytes: 6976688128,
free_percent: 17,
used_percent: 83
},
swap: {
total_in_bytes: 8455712768,
free_in_bytes: 8455299072,
used_in_bytes: 413696
},
cgroup: {
cpuacct: {},
cpu: {
control_group: "/user.slice",
cfs_period_micros: 100000,
cfs_quota_micros: -1,
stat: {}
}
}
},
process: {
timestamp: 1508312932369,
open_file_descriptors: 228,
max_file_descriptors: 65536,
cpu: {
percent: 0,
total_in_millis: 2495040
},
mem: {
total_virtual_in_bytes: 5002465280
}
},
jvm: {
timestamp: 1508312932369,
uptime_in_millis: 797735804,
mem: {
heap_used_in_bytes: 318233768,
heap_used_percent: 30,
heap_committed_in_bytes: 1038876672,
heap_max_in_bytes: 1038876672,
non_heap_used_in_bytes: 102379784,
non_heap_committed_in_bytes: 108773376,
pools: {
young: {
used_in_bytes: 62375176,
max_in_bytes: 279183360,
peak_used_in_bytes: 279183360,
peak_max_in_bytes: 279183360
},
survivor: {
used_in_bytes: 175384,
max_in_bytes: 34865152,
peak_used_in_bytes: 34865152,
peak_max_in_bytes: 34865152
},
old: {
used_in_bytes: 255683208,
max_in_bytes: 724828160,
peak_used_in_bytes: 255683208,
peak_max_in_bytes: 724828160
}
}
},
threads: {},
gc: {},
buffer_pools: {},
classes: {}
},
thread_pool: {
bulk: {},
fetch_shard_started: {},
fetch_shard_store: {},
flush: {},
force_merge: {},
generic: {},
get: {},
index: {
threads: 1,
queue: 0,
active: 0,
rejected: 0,
largest: 1,
completed: 1
}
listener: {},
management: {},
refresh: {},
search: {},
snapshot: {},
warmer: {}
},
fs: {},
transport: {
server_open: 13,
rx_count: 11696,
rx_size_in_bytes: 1525774,
tx_count: 10282,
tx_size_in_bytes: 1440101928
},
http: {
current_open: 4,
total_opened: 23
},
breakers: {},
script: {},
discovery: {},
ingest: {}
}节点名是一个 UUID,上面列举了很多指标,下面讲解下:
索引部分 indices
这部分列出了这个节点上所有索引的聚合过的统计值 :
-
docs展示节点内存有多少文档,包括还没有从段里清除的已删除文档数量。 -
store部分显示节点耗用了多少物理存储。这个指标包括主分片和副本分片在内。如果限流时间很大,那可能表明你的磁盘限流设置得过低。 indexing显示已经索引了多少文档。这个值是一个累加计数器。在文档被删除的时候,数值不会下降。还要注意的是,在发生内部 索引操作的时候,这个值也会增加,比如说文档更新。
还列出了索引操作耗费的时间,正在索引的文档数量,以及删除操作的类似统计值。
-
get显示通过 ID 获取文档的接口相关的统计值。包括对单个文档的GET和HEAD请求。 search描述在活跃中的搜索(open_contexts)数量、查询的总数量、以及自节点启动以来在查询上消耗的总时间。用query_time_in_millis / query_total计算的比值,可以用来粗略的评价你的查询有多高效。比值越大,每个查询花费的时间越多,你应该要考虑调优了。
fetch 统计值展示了查询处理的后一半流程(query-then-fetch 里的 fetch )。如果 fetch 耗时比 query 还多,说明磁盘较慢,或者获取了太多文档,或者可能搜索请求设置了太大的分页(比如, size: 10000 )。
-
merges包括了 Lucene 段合并相关的信息。它会告诉你目前在运行几个合并,合并涉及的文档数量,正在合并的段的总大小,以及在合并操作上消耗的总时间。 filter_cache展示了已缓存的过滤器位集合所用的内存数量,以及过滤器被驱逐出内存的次数。过多的驱逐数 可能 说明你需要加大过滤器缓存的大小,或者你的过滤器不太适合缓存(比如它们因为高基数而在大量产生,就像是缓存一个now时间表达式)。
不过,驱逐数是一个很难评定的指标。过滤器是在每个段的基础上缓存的,而从一个小的段里驱逐过滤器,代价比从一个大的段里要廉价的多。有可能你有很大的驱逐数,但是它们都发生在小段上,也就意味着这些对查询性能只有很小的影响。
把驱逐数指标作为一个粗略的参考。如果你看到数字很大,检查一下你的过滤器,确保他们都是正常缓存的。不断驱逐着的过滤器,哪怕都发生在很小的段上,效果也比正确缓存住了的过滤器差很多。
-
field_data显示 fielddata 使用的内存, 用以聚合、排序等等。这里也有一个驱逐计数。和filter_cache不同的是,这里的驱逐计数是很有用的:这个数应该或者至少是接近于 0。因为 fielddata 不是缓存,任何驱逐都消耗巨大,应该避免掉。如果你在这里看到驱逐数,你需要重新评估你的内存情况,fielddata 限制,请求语句,或者这三者。 segments会展示这个节点目前正在服务中的 Lucene 段的数量。 这是一个重要的数字。大多数索引会有大概 50–150 个段,哪怕它们存有 TB 级别的数十亿条文档。段数量过大表明合并出现了问题(比如,合并速度跟不上段的创建)。注意这个统计值是节点上所有索引的汇聚总数。记住这点。
memory 统计值展示了 Lucene 段自己用掉的内存大小。 这里包括底层数据结构,比如倒排表,字典,和布隆过滤器等。太大的段数量会增加这些数据结构带来的开销,这个内存使用量就是一个方便用来衡量开销的度量值。
操作系统和进程部分
OS 和 Process 部分基本是自描述的,不会在细节中展开讲解。它们列出来基础的资源统计值,比如 CPU 和负载。OS 部分描述了整个操作系统,而 Process 部分只显示 Elasticsearch 的 JVM 进程使用的资源情况。
这些都是非常有用的指标,不过通常在你的监控技术栈里已经都测量好了。统计值包括下面这些:
- CPU
- 负载
- 内存使用率 (mem.used_percent)
- Swap 使用率
- 打开的文件描述符 (open_file_descriptors)
JVM 部分
jvm 部分包括了运行 Elasticsearch 的 JVM 进程一些很关键的信息。 最重要的,它包括了垃圾回收的细节,这对你的 Elasticsearch 集群的稳定性有着重大影响。
jvm: {
timestamp: 1508312932369,
uptime_in_millis: 797735804,
mem: {
heap_used_in_bytes: 318233768,
heap_used_percent: 30,
heap_committed_in_bytes: 1038876672,
heap_max_in_bytes: 1038876672,
non_heap_used_in_bytes: 102379784,
non_heap_committed_in_bytes: 108773376,
}
}jvm 部分首先列出一些和 heap 内存使用有关的常见统计值。你可以看到有多少 heap 被使用了,多少被指派了(当前被分配给进程的),以及 heap 被允许分配的最大值。理想情况下,heap_committed_in_bytes 应该等于 heap_max_in_bytes 。如果指派的大小更小,JVM 最终会被迫调整 heap 大小——这是一个非常昂贵的操作。如果你的数字不相等,阅读 堆内存:大小和交换 学习如何正确的配置它。
heap_used_percent 指标是值得关注的一个数字。Elasticsearch 被配置为当 heap 达到 75% 的时候开始 GC。如果你的节点一直 >= 75%,你的节点正处于 内存压力 状态。这是个危险信号,不远的未来可能就有慢 GC 要出现了。
如果 heap 使用率一直 >=85%,你就麻烦了。Heap 在 90–95% 之间,则面临可怕的性能风险,此时最好的情况是长达 10–30s 的 GC,最差的情况就是内存溢出(OOM)异常。
线程池部分
Elasticsearch 在内部维护了线程池。 这些线程池相互协作完成任务,有必要的话相互间还会传递任务。通常来说,你不需要配置或者调优线程池,不过查看它们的统计值有时候还是有用的,可以洞察你的集群表现如何。
每个线程池会列出已配置的线程数量( threads ),当前在处理任务的线程数量( active ),以及在队列中等待处理的任务单元数量( queue )。
如果队列中任务单元数达到了极限,新的任务单元会开始被拒绝,你会在 rejected 统计值上看到它反映出来。这通常是你的集群在某些资源上碰到瓶颈的信号。因为队列满意味着你的节点或集群在用最高速度运行,但依然跟不上工作的蜂拥而入。
这里的一系列的线程池,大多数你可以忽略,但是有一小部分还是值得关注的:
indexing普通的索引请求的线程池bulk批量请求,和单条的索引请求不同的线程池getGet-by-ID 操作search所有的搜索和查询请求merging专用于管理 Lucene 合并的线程池
网络部分
transport显示和 传输地址 相关的一些基础统计值。包括节点间的通信(通常是 9300 端口)以及任意传输客户端或者节点客户端的连接。如果看到这里有很多连接数不要担心;Elasticsearch 在节点之间维护了大量的连接。http显示 HTTP 端口(通常是 9200)的统计值。如果你看到total_opened数很大而且还在一直上涨,这是一个明确信号,说明你的 HTTP 客户端里有没启用 keep-alive 长连接的。持续的 keep-alive 长连接对性能很重要,因为连接、断开套接字是很昂贵的(而且浪费文件描述符)。请确认你的客户端都配置正确。
参考资料
3、ES监控指标
最后:
转载请注明地址:http://www.54tianzhisheng.cn/2017/10/18/ElasticSearch-nodes-metrics/
原文地址:http://www.54tianzhisheng.cn/2017/10/18/ElasticSearch-nodes-metrics/
集群健康监控是对集群信息进行高度的概括,节点统计值 API 提供了集群中每个节点的统计值。节点统计值很多,在监控的时候仍需要我们清楚哪些指标是最值得关注的。
集群健康监控可以参考这篇文章:ElasticSearch 集群监控
节点信息 Node Info :
curl -XGET 'http://localhost:9200/_nodes'执行上述命令可以获取所有 node 的信息
_nodes: {
total: 2,
successful: 2,
failed: 0
},
cluster_name: "elasticsearch",
nodes: {
MSQ_CZ7mTNyOSlYIfrvHag: {
name: "node0",
transport_address: "192.168.180.110:9300",
host: "192.168.180.110",
ip: "192.168.180.110",
version: "5.5.0",
build_hash: "260387d",
total_indexing_buffer: 103887667,
roles:{...},
settings: {...},
os: {
refresh_interval_in_millis: 1000,
name: "Linux",
arch: "amd64",
version: "3.10.0-229.el7.x86_64",
available_processors: 4,
allocated_processors: 4
},
process: {
refresh_interval_in_millis: 1000,
id: 3022,
mlockall: false
},
jvm: {
pid: 3022,
version: "1.8.0_121",
vm_name: "Java HotSpot(TM) 64-Bit Server VM",
vm_version: "25.121-b13",
vm_vendor: "Oracle Corporation",
start_time_in_millis: 1507515225302,
mem: {
heap_init_in_bytes: 1073741824,
heap_max_in_bytes: 1038876672,
non_heap_init_in_bytes: 2555904,
non_heap_max_in_bytes: 0,
direct_max_in_bytes: 1038876672
},
gc_collectors: [],
memory_pools: [],
using_compressed_ordinary_object_pointers: "true",
input_arguments:{}
}
thread_pool:{
force_merge: {},
fetch_shard_started: {},
listener: {},
index: {},
refresh: {},
generic: {},
warmer: {},
search: {},
flush: {},
fetch_shard_store: {},
management: {},
get: {},
bulk: {},
snapshot: {}
}
transport: {...},
http: {...},
plugins: [],
modules: [],
ingest: {...}
}上面是我已经简写了很多数据之后的返回值,但是指标还是很多,有些是一些常规的指标,对于监控来说,没必要拿取。从上面我们可以主要关注以下这些指标:
os, process, jvm, thread_pool, transport, http, ingest and indices节点统计 nodes-statistics
节点统计值 API 可通过如下命令获取:
GET /_nodes/stats得到:
_nodes: {
total: 2,
successful: 2,
failed: 0
},
cluster_name: "elasticsearch",
nodes: {
MSQ_CZ7mTNyOSlYI0yvHag: {
timestamp: 1508312932354,
name: "node0",
transport_address: "192.168.180.110:9300",
host: "192.168.180.110",
ip: "192.168.180.110:9300",
roles: [],
indices: {
docs: {
count: 6163666,
deleted: 0
},
store: {
size_in_bytes: 2301398179,
throttle_time_in_millis: 122850
},
indexing: {},
get: {},
search: {},
merges: {},
refresh: {},
flush: {},
warmer: {},
query_cache: {},
fielddata: {},
completion: {},
segments: {},
translog: {},
request_cache: {},
recovery: {}
},
os: {
timestamp: 1508312932369,
cpu: {
percent: 0,
load_average: {
1m: 0.09,
5m: 0.12,
15m: 0.08
}
},
mem: {
total_in_bytes: 8358301696,
free_in_bytes: 1381613568,
used_in_bytes: 6976688128,
free_percent: 17,
used_percent: 83
},
swap: {
total_in_bytes: 8455712768,
free_in_bytes: 8455299072,
used_in_bytes: 413696
},
cgroup: {
cpuacct: {},
cpu: {
control_group: "/user.slice",
cfs_period_micros: 100000,
cfs_quota_micros: -1,
stat: {}
}
}
},
process: {
timestamp: 1508312932369,
open_file_descriptors: 228,
max_file_descriptors: 65536,
cpu: {
percent: 0,
total_in_millis: 2495040
},
mem: {
total_virtual_in_bytes: 5002465280
}
},
jvm: {
timestamp: 1508312932369,
uptime_in_millis: 797735804,
mem: {
heap_used_in_bytes: 318233768,
heap_used_percent: 30,
heap_committed_in_bytes: 1038876672,
heap_max_in_bytes: 1038876672,
non_heap_used_in_bytes: 102379784,
non_heap_committed_in_bytes: 108773376,
pools: {
young: {
used_in_bytes: 62375176,
max_in_bytes: 279183360,
peak_used_in_bytes: 279183360,
peak_max_in_bytes: 279183360
},
survivor: {
used_in_bytes: 175384,
max_in_bytes: 34865152,
peak_used_in_bytes: 34865152,
peak_max_in_bytes: 34865152
},
old: {
used_in_bytes: 255683208,
max_in_bytes: 724828160,
peak_used_in_bytes: 255683208,
peak_max_in_bytes: 724828160
}
}
},
threads: {},
gc: {},
buffer_pools: {},
classes: {}
},
thread_pool: {
bulk: {},
fetch_shard_started: {},
fetch_shard_store: {},
flush: {},
force_merge: {},
generic: {},
get: {},
index: {
threads: 1,
queue: 0,
active: 0,
rejected: 0,
largest: 1,
completed: 1
}
listener: {},
management: {},
refresh: {},
search: {},
snapshot: {},
warmer: {}
},
fs: {},
transport: {
server_open: 13,
rx_count: 11696,
rx_size_in_bytes: 1525774,
tx_count: 10282,
tx_size_in_bytes: 1440101928
},
http: {
current_open: 4,
total_opened: 23
},
breakers: {},
script: {},
discovery: {},
ingest: {}
}节点名是一个 UUID,上面列举了很多指标,下面讲解下:
索引部分 indices
这部分列出了这个节点上所有索引的聚合过的统计值 :
-
docs展示节点内存有多少文档,包括还没有从段里清除的已删除文档数量。 -
store部分显示节点耗用了多少物理存储。这个指标包括主分片和副本分片在内。如果限流时间很大,那可能表明你的磁盘限流设置得过低。 indexing显示已经索引了多少文档。这个值是一个累加计数器。在文档被删除的时候,数值不会下降。还要注意的是,在发生内部 索引操作的时候,这个值也会增加,比如说文档更新。
还列出了索引操作耗费的时间,正在索引的文档数量,以及删除操作的类似统计值。
-
get显示通过 ID 获取文档的接口相关的统计值。包括对单个文档的GET和HEAD请求。 search描述在活跃中的搜索(open_contexts)数量、查询的总数量、以及自节点启动以来在查询上消耗的总时间。用query_time_in_millis / query_total计算的比值,可以用来粗略的评价你的查询有多高效。比值越大,每个查询花费的时间越多,你应该要考虑调优了。
fetch 统计值展示了查询处理的后一半流程(query-then-fetch 里的 fetch )。如果 fetch 耗时比 query 还多,说明磁盘较慢,或者获取了太多文档,或者可能搜索请求设置了太大的分页(比如, size: 10000 )。
-
merges包括了 Lucene 段合并相关的信息。它会告诉你目前在运行几个合并,合并涉及的文档数量,正在合并的段的总大小,以及在合并操作上消耗的总时间。 filter_cache展示了已缓存的过滤器位集合所用的内存数量,以及过滤器被驱逐出内存的次数。过多的驱逐数 可能 说明你需要加大过滤器缓存的大小,或者你的过滤器不太适合缓存(比如它们因为高基数而在大量产生,就像是缓存一个now时间表达式)。
不过,驱逐数是一个很难评定的指标。过滤器是在每个段的基础上缓存的,而从一个小的段里驱逐过滤器,代价比从一个大的段里要廉价的多。有可能你有很大的驱逐数,但是它们都发生在小段上,也就意味着这些对查询性能只有很小的影响。
把驱逐数指标作为一个粗略的参考。如果你看到数字很大,检查一下你的过滤器,确保他们都是正常缓存的。不断驱逐着的过滤器,哪怕都发生在很小的段上,效果也比正确缓存住了的过滤器差很多。
-
field_data显示 fielddata 使用的内存, 用以聚合、排序等等。这里也有一个驱逐计数。和filter_cache不同的是,这里的驱逐计数是很有用的:这个数应该或者至少是接近于 0。因为 fielddata 不是缓存,任何驱逐都消耗巨大,应该避免掉。如果你在这里看到驱逐数,你需要重新评估你的内存情况,fielddata 限制,请求语句,或者这三者。 segments会展示这个节点目前正在服务中的 Lucene 段的数量。 这是一个重要的数字。大多数索引会有大概 50–150 个段,哪怕它们存有 TB 级别的数十亿条文档。段数量过大表明合并出现了问题(比如,合并速度跟不上段的创建)。注意这个统计值是节点上所有索引的汇聚总数。记住这点。
memory 统计值展示了 Lucene 段自己用掉的内存大小。 这里包括底层数据结构,比如倒排表,字典,和布隆过滤器等。太大的段数量会增加这些数据结构带来的开销,这个内存使用量就是一个方便用来衡量开销的度量值。
操作系统和进程部分
OS 和 Process 部分基本是自描述的,不会在细节中展开讲解。它们列出来基础的资源统计值,比如 CPU 和负载。OS 部分描述了整个操作系统,而 Process 部分只显示 Elasticsearch 的 JVM 进程使用的资源情况。
这些都是非常有用的指标,不过通常在你的监控技术栈里已经都测量好了。统计值包括下面这些:
- CPU
- 负载
- 内存使用率 (mem.used_percent)
- Swap 使用率
- 打开的文件描述符 (open_file_descriptors)
JVM 部分
jvm 部分包括了运行 Elasticsearch 的 JVM 进程一些很关键的信息。 最重要的,它包括了垃圾回收的细节,这对你的 Elasticsearch 集群的稳定性有着重大影响。
jvm: {
timestamp: 1508312932369,
uptime_in_millis: 797735804,
mem: {
heap_used_in_bytes: 318233768,
heap_used_percent: 30,
heap_committed_in_bytes: 1038876672,
heap_max_in_bytes: 1038876672,
non_heap_used_in_bytes: 102379784,
non_heap_committed_in_bytes: 108773376,
}
}jvm 部分首先列出一些和 heap 内存使用有关的常见统计值。你可以看到有多少 heap 被使用了,多少被指派了(当前被分配给进程的),以及 heap 被允许分配的最大值。理想情况下,heap_committed_in_bytes 应该等于 heap_max_in_bytes 。如果指派的大小更小,JVM 最终会被迫调整 heap 大小——这是一个非常昂贵的操作。如果你的数字不相等,阅读 堆内存:大小和交换 学习如何正确的配置它。
heap_used_percent 指标是值得关注的一个数字。Elasticsearch 被配置为当 heap 达到 75% 的时候开始 GC。如果你的节点一直 >= 75%,你的节点正处于 内存压力 状态。这是个危险信号,不远的未来可能就有慢 GC 要出现了。
如果 heap 使用率一直 >=85%,你就麻烦了。Heap 在 90–95% 之间,则面临可怕的性能风险,此时最好的情况是长达 10–30s 的 GC,最差的情况就是内存溢出(OOM)异常。
线程池部分
Elasticsearch 在内部维护了线程池。 这些线程池相互协作完成任务,有必要的话相互间还会传递任务。通常来说,你不需要配置或者调优线程池,不过查看它们的统计值有时候还是有用的,可以洞察你的集群表现如何。
每个线程池会列出已配置的线程数量( threads ),当前在处理任务的线程数量( active ),以及在队列中等待处理的任务单元数量( queue )。
如果队列中任务单元数达到了极限,新的任务单元会开始被拒绝,你会在 rejected 统计值上看到它反映出来。这通常是你的集群在某些资源上碰到瓶颈的信号。因为队列满意味着你的节点或集群在用最高速度运行,但依然跟不上工作的蜂拥而入。
这里的一系列的线程池,大多数你可以忽略,但是有一小部分还是值得关注的:
indexing普通的索引请求的线程池bulk批量请求,和单条的索引请求不同的线程池getGet-by-ID 操作search所有的搜索和查询请求merging专用于管理 Lucene 合并的线程池
网络部分
transport显示和 传输地址 相关的一些基础统计值。包括节点间的通信(通常是 9300 端口)以及任意传输客户端或者节点客户端的连接。如果看到这里有很多连接数不要担心;Elasticsearch 在节点之间维护了大量的连接。http显示 HTTP 端口(通常是 9200)的统计值。如果你看到total_opened数很大而且还在一直上涨,这是一个明确信号,说明你的 HTTP 客户端里有没启用 keep-alive 长连接的。持续的 keep-alive 长连接对性能很重要,因为连接、断开套接字是很昂贵的(而且浪费文件描述符)。请确认你的客户端都配置正确。
参考资料
3、ES监控指标
最后:
转载请注明地址:http://www.54tianzhisheng.cn/2017/10/18/ElasticSearch-nodes-metrics/
收起阅读 »社区日报 第92期 (2017-11-06)
http://t.cn/Rl6ZoRX
2.在vscode中调试es查询语句。
http://t.cn/Rlio50B
3.全面介绍韩语分词器。
http://t.cn/Rli9inA
编辑:cybredak
归档:https://elasticsearch.cn/article/354
订阅:https://tinyletter.com/elastic-daily
http://t.cn/Rl6ZoRX
2.在vscode中调试es查询语句。
http://t.cn/Rlio50B
3.全面介绍韩语分词器。
http://t.cn/Rli9inA
编辑:cybredak
归档:https://elasticsearch.cn/article/354
订阅:https://tinyletter.com/elastic-daily 收起阅读 »

