


advent
Day24 - Predator捕捉病毒样本
Advent • swordsmanli 发表了文章 • 0 个评论 • 4592 次浏览 • 2018-12-21 16:18

对,你一定看过一个电影,情节是这样的,他们拿着长矛去狩猎异形怪物,它们比人类强健,它们的脸部的器官布置得出奇丑陋。它们的身上总是带了一堆很先进的狩猎武器,它们喜欢在杀死猎物后将尸体剥皮,还会将猎物头骨加工成工艺品,当成战利品收藏。对,这部电影系列就叫Predator。好了,言归正传,我们今天讲的故事其实非常简单,讲述的是elasticsearch引擎在安全领域的简单应用,如何通过elasticsearch来搜索一个病毒,我们开发了一个小小的工具来帮我做跨集群查询,以及SQL-DSL转换接口,我们把这个小工具叫做predator。
背景
我司主要是做病毒相关工作的,近年来,数据爆炸,病毒软件也成几何级数倍数增长,大数据病毒出现自然需要对应的大数据工具来处理它们,简单来讲,就是我们可以把病毒样本的一些属性剥离到elasticsearch中,就和日志来描述一个用户的行为一样,本质来说,它们都是数据,然后,我们研究病毒的一些特征属性,通过简单的搜索,就可以快速分析出一堆可能的病毒样本,再然后,通过一系列的测试,过滤,我们就可以真正的找到我们想要的病毒样本,并且通过这些规则持续的追踪它们,是不是很简单?
问题
事情是那么简单,但是在使用elasticsearch作为特征库的过程中,我们也有这样的问题:
1,多种维度特征
由于存在多种维度特征的病毒,不通模块剥离出不通病毒属性,所以存在多张表来存属性,那么在query的时候就需要跨表,甚至跨集群查询。
2,DSL的复杂度
由于内部研究员们对elasticStack并不熟悉,加上DSL语言相对复杂,我们需要使用更加接近hunman特性的SQL来转换DSL语言。
数据处理架构
我们有一个类似的数据处理架构

Predator和它的Spear
因此,我们开发了一个小工具,其实,这个小工具非常简单,只是简单的解决了上述2个问题:
使用Elasticsearch-SQL插件来包装一个restful的DSL转换SQL接口,当然,目前ES6已经完全支持SQL接口了,哈哈,早点出来我们就不用做那么工作了:) :):)。
简单的写个跨集群的查下聚合器就可以实现跨表查下,其实,这个功能只是简单的查下封装,只是针对特殊的业务场景,没啥参考价值。
至于Spear,它其实就是个predator service的客户端,哈哈,像不像铁血战士拿着长矛开着非常去狩猎的样子:) 。

这是一个规则:

这是规则的查询结果:

长矛的sample code:
# cross cluster search by dsls
import json
from spear import Spear
sp = Spear()
dsl_1 = {}
dsl_2 = {}
query_dict = {
json.dumps(dsl_1): {
"cluster": "es_cluster_1",
"type":"xxx"
},
json.dumps(dsl_2): {
"cluster": "es_cluster_2",
"type": "yyy"
}
}
sp.cross_count_by_dsl(query_dict, is_show_help=False)当然长矛也支持SQL接口
总结
其实,这个只是一个user case的工程实践,可以看到的是,伟大的ElasticStack在各行各业,各种大数据领域,如果抛开领域的概念,一切都是数据,那么理论上来说我们可以使用elasticsearch处理任何类型的数据,当然目前业界典型的应用场景还是搜索,日志,甚至于APM,总之,紧跟社区可以学到很多东西啦。
Day 17 - 关于日志型数据管理策略的思考
Elasticsearch • kennywu76 发表了文章 • 7 个评论 • 7950 次浏览 • 2018-12-17 11:19
近两年随着Elastic Stack的愈发火热,其近乎成为构建实时日志应用的工业标准。在小型数据应用场景,最新的6.5版本已经可以做到开箱即用,无需过多考虑架构上的设计工作。 然而一旦应用规模扩大到数百TB甚至PB的数据量级,整个系统的架构和后期维护工作则显得非常重要。借着2018 Elastic Advent写文的机会,结合过去几年架构和运维公司日志集群的实践经验,对于大规模日志型数据的管理策略,在此做一个总结性的思考。 文中抛出的观点,有些已经在我们的集群中有所应用并取得比较好的效果,有些则还待实践的检验。抛砖引玉,不尽成熟的地方,还请社区各位专家指正。
对于日志系统,最终用户通常有以下几个基本要求:
- 数据从产生到可检索的实时性要求高,可接受的延迟通常要求控制在数秒,至多不超过数十秒
- 新鲜数据(当天至过去几天)的查询和统计频率高,返回速度要快(毫秒级,至多几秒)
- 历史数据保留得越久越好。
针对这些需求,加上对成本控制的必要性,大家通常想到的第一个架构设计就是冷热数据分离。
冷热数据分离
冷热分离的概念比较好理解,热结点做数据的写入,保存近期热数据,冷数据定期迁移到冷数据结点,就这么简单。不过实际操作起来可能还是碰到一些具体需要考虑的细节问题。
- 冷热结点集群配置的JVM heap配置要差异化。热结点无需存放太多数据,对于heap的要求通常不是太高,在够用的情况下尽量配置小一点。可以配置在26GB左右甚至更小,而不是大多数人知道的经验值31GB。原因在于这个size的heap,可以启用
zero basedCompressed Oops,JVM运行效率是最高的, 参考: heap-size。而冷结点存在的目的是尽量放更多的数据,性能不是首要的,因此heap可以配置在31GB。 - 数据迁移过程有一定资源消耗,为避免对数据写入产生显著影响,通常定时在业务低峰期,日志产出量比较低的时候进行,比如半夜。
- 索引是否应该启用压缩,如何启用?最初我们对于热结点上的索引是不启用压缩的,为了节省CPU消耗。只在冷结点配置里,增加了索引压缩选项。这样索引迁移到冷结点后,执行force merge操作的时候,ES会自动将结点上配置的索引压缩属性套用到merge过后新生成的segment,这样就实现了热结点不压缩,冷结点merge过后压缩的功能。极大节省了冷结点的磁盘空间。后来随着硬件的升级,我们发现服务器的cpu基本都是过剩的,磁盘IO通常先到瓶颈。 因此尝试在热结点上一开始创建索引的时候,就启用压缩选项。实际对比测试并没有发现显著的索引吞吐量下降,并且因为索引压缩后磁盘文件size的大幅减少,每天夜间的数据迁移工作可以节省大量的时间。至此我们的日志集群索引默认就是压缩的。
- 冷结点上留做系统缓存的内存一般不多,加上数据量非常巨大。索引默认的mmapfs读取方式,很容易因为系统缓存不够,导致数据在内存和磁盘之间频繁换入换出。严重的情况下,整个结点甚至会因为io持续在100%无法响应。 实践中我们发现对冷结点使用niofs效果会更好。
实现了冷热结点分离以后,集群的资源利用率提升了不少,可管理性也要好很多了. 但是随着接入日志的类型越来越多(我们生产上有差不多400种类型的日志),各种日志的速率差异又很大,让ES自己管理shard的分布很容易产生写入热点问题。 针对这个问题,可以采用对集群结点进行分组管理的策略来解决。
热结点分组管理
所谓分组管理,就是通过在结点的配置文件中增加自定义的标签属性,将服务器区分到不同的组别中。然后通过设置索引的index.routing.allocation.include属性,控制改索引分布在哪个组别。同时配合设置index.routing.allocation.total_shards_per_node,可以做到某个索引的shard在某个group的结点之间绝对均匀分布。
比如一个分组有10台机器,对一个5 primary ,1 replica的索引,让该索引分布在该分组的同时,设置total_shards_per_node为1,让每个节点上只能有一个分片,这样就避免了写入热点问题。 该方案的缺陷也显而易见,一旦有结点挂掉,不会自动recovery,某个shard将一直处于unassigned状态,集群状态变成yellow。 但我认为,热数据的恢复开销是非常高的,与其立即在其他结点开始复制,之后再重新rebalance,不如就让集群暂时处于yellow状态。 通过监控报警的手段,及时通知运维人员解决结点故障。 待故障解决之后,直接从恢复后的结点开始数据复制,开销要低得多。
在我们的生产环境主要有两种类型的结点分组,分别是10台机器一个分组,和2台机器一个分组。10台机器的分组用于应对速率非常高,shard划分比较多的索引,2台机器的分组用于速率很低,一个shard(加一个复制片)就可以应对的索引。
这种分组策略在我们的生产环境中经过验证,非常好的解决了写入热点问题。那么冷数据怎么管理? 冷数据不做写入,不存在写入热点问题,查询频率也比较低,业务需求方面对查询响应要求也不那么严苛,所以查询热点问题也不是那么突出。因此为了简化管理,冷结点我们是不做shard分布的精细控制,所有数据迁移到冷数据结点之后,由ES默认的shard分布则略去控制数据的分布。
不过如果想进一步提高冷数据结点服务器资源的利用率,还是可以有进一步挖掘的的空间。我们知道ES默认的shard分布策略,只是保证一个索引的shard尽量分布在不同的结点,同时保证每个节点上shard数量差不多。但是如果采用默认按天创建索引的策略,由于索引速率差异很大,不同索引之间shard的大小差异可能是1-2个数量级的。如果每个shard的size差异不大就好了,那么默认的分布策略,基本上可以保证冷结点之间数据量分布的大致均匀。 能实现类似功能的是ES的rollover特性。
索引的Rollover
Rollover api可以让索引根据预先定义的时间跨度,或者索引大小来自动切分出新索引,从而将索引的大小控制在计划的范围内。合理的应用rollver api可以保证集群shard大小差别不会太大。 只是集群索引类别比较多的时候,rollover全部手动管理负担比较大,需要借助额外的管理工具和监控工具。我们出于管理简便的考虑,暂时没有应用到这个特性。
索引的Rollup
我们发现生产有些用户写入的“日志”,实际上是多维的metrcis数据,使用的时候不是为了查询日志的详情,仅仅是为了做各种维度组合的过滤和聚合。对于这种类型的数据,保留历史数据过多一来浪费存储空间,二来每次聚合都要在裸数据上跑,非常浪费资源。 ES从6.3开始,在x-pack里推出了rollup api,通过定期对裸数据做预先聚合,大大缩减了保存在磁盘上的数据量。对于不需要查询裸日志的应用场景,合理应用该特性,可以将历史数据的磁盘消耗降低几个数量级,同时rollup search也可以大大提升聚合速度。不过rollup也有其局限性,即他的实现是通过定期任务,对间隔期数据跑聚合完成的,有一定的计算开销。 如果数据写入速率非常高,集群压力很大,rollup可能无法跟上写入速率,而不具有实用性。 所以实际环境中,还是需要根据应用场景和资源使用情况,进行灵活的取舍。
多集群的便利性
数据量大到一定程度以后,单集群由于master node单点的限制,会遇到各种集群状态数据更新时得性能问题。 由此现在一些大规模的应用已经开始利用到多集群互联和cross cluster search的特性。 这种结构除了解决单集群数据容量限制问题以外,我们还发现在做容量均衡方面还有比较好的便利性。应用日志写入量通常随着业务变化也会剧烈变化,好不容易规划好的容量,不久就被业务的增长给打破,数倍或者数10倍的流量增长很可能就让一组结点过载出现写入延迟。 如果只有一个集群,在结点之间重新平衡shard比较费力,涉及到数据的迁移,可能非常缓慢,还会影响写入。 但如果有多集群互联,切换就可以做到非常的快速和简单。 原理上只需要在新集群中加入对应的索引配置模版,然后更新写入程序的配置,写入目标指向新集群,重启写入程序即可。并且,可以进一步将整个流程工具化,在GUI上完成一键切换。
Day 7 - Elasticsearch中数据是如何存储的
Advent • weizijun 发表了文章 • 7 个评论 • 78995 次浏览 • 2018-12-07 13:55
前言
很多使用Elasticsearch的同学会关心数据存储在ES中的存储容量,会有这样的疑问:xxTB的数据入到ES会使用多少存储空间。这个问题其实很难直接回答的,只有数据写入ES后,才能观察到实际的存储空间。比如同样是1TB的数据,写入ES的存储空间可能差距会非常大,可能小到只有300~400GB,也可能多到6-7TB,为什么会造成这么大的差距呢?究其原因,我们来探究下Elasticsearch中的数据是如何存储。文章中我以Elasticsearch 2.3版本为示例,对应的lucene版本是5.5,Elasticsearch现在已经来到了6.5版本,数字类型、列存等存储结构有些变化,但基本的概念变化不多,文章中的内容依然适用。
Elasticsearch索引结构
Elasticsearch对外提供的是index的概念,可以类比为DB,用户查询是在index上完成的,每个index由若干个shard组成,以此来达到分布式可扩展的能力。比如下图是一个由10个shard组成的index。

shard是Elasticsearch数据存储的最小单位,index的存储容量为所有shard的存储容量之和。Elasticsearch集群的存储容量则为所有index存储容量之和。
一个shard就对应了一个lucene的library。对于一个shard,Elasticsearch增加了translog的功能,类似于HBase WAL,是数据写入过程中的中间数据,其余的数据都在lucene库中管理的。
所以Elasticsearch索引使用的存储内容主要取决于lucene中的数据存储。
lucene数据存储
下面我们主要看下lucene的文件内容,在了解lucene文件内容前,大家先了解些lucene的基本概念。
lucene基本概念
- segment : lucene内部的数据是由一个个segment组成的,写入lucene的数据并不直接落盘,而是先写在内存中,经过了refresh间隔,lucene才将该时间段写入的全部数据refresh成一个segment,segment多了之后会进行merge成更大的segment。lucene查询时会遍历每个segment完成。由于lucene* 写入的数据是在内存中完成,所以写入效率非常高。但是也存在丢失数据的风险,所以Elasticsearch基于此现象实现了translog,只有在segment数据落盘后,Elasticsearch才会删除对应的translog。
- doc : doc表示lucene中的一条记录
- field :field表示记录中的字段概念,一个doc由若干个field组成。
- term :term是lucene中索引的最小单位,某个field对应的内容如果是全文检索类型,会将内容进行分词,分词的结果就是由term组成的。如果是不分词的字段,那么该字段的内容就是一个term。
- 倒排索引(inverted index): lucene索引的通用叫法,即实现了term到doc list的映射。
- 正排数据:搜索引擎的通用叫法,即原始数据,可以理解为一个doc list。
- docvalues :Elasticsearch中的列式存储的名称,Elasticsearch除了存储原始存储、倒排索引,还存储了一份docvalues,用作分析和排序。
lucene文件内容
lucene包的文件是由很多segment文件组成的,segments_xxx文件记录了lucene包下面的segment文件数量。每个segment会包含如下的文件。
| Name | Extension | Brief Description |
|---|---|---|
| Segment Info | .si | segment的元数据文件 |
| Compound File | .cfs, .cfe | 一个segment包含了如下表的各个文件,为减少打开文件的数量,在segment小的时候,segment的所有文件内容都保存在cfs文件中,cfe文件保存了lucene各文件在cfs文件的位置信息 |
| Fields | .fnm | 保存了fields的相关信息 |
| Field Index | .fdx | 正排存储文件的元数据信息 |
| Field Data | .fdt | 存储了正排存储数据,写入的原文存储在这 |
| Term Dictionary | .tim | 倒排索引的元数据信息 |
| Term Index | .tip | 倒排索引文件,存储了所有的倒排索引数据 |
| Frequencies | .doc | 保存了每个term的doc id列表和term在doc中的词频 |
| Positions | .pos | Stores position information about where a term occurs in the index 全文索引的字段,会有该文件,保存了term在doc中的位置 |
| Payloads | .pay | Stores additional per-position metadata information such as character offsets and user payloads 全文索引的字段,使用了一些像payloads的高级特性会有该文件,保存了term在doc中的一些高级特性 |
| Norms | .nvd, .nvm | 文件保存索引字段加权数据 |
| Per-Document Values | .dvd, .dvm | lucene的docvalues文件,即数据的列式存储,用作聚合和排序 |
| Term Vector Data | .tvx, .tvd, .tvf | Stores offset into the document data file 保存索引字段的矢量信息,用在对term进行高亮,计算文本相关性中使用 |
| Live Documents | .liv | 记录了segment中删除的doc |
测试数据示例
下面我们以真实的数据作为示例,看看lucene中各类型数据的容量占比。
写100w数据,有一个uuid字段,写入的是长度为36位的uuid,字符串总为3600w字节,约为35M。
数据使用一个shard,不带副本,使用默认的压缩算法,写入完成后merge成一个segment方便观察。
使用线上默认的配置,uuid存为不分词的字符串类型。创建如下索引:
PUT test_field
{
"settings": {
"index": {
"number_of_shards": "1",
"number_of_replicas": "0",
"refresh_interval": "30s"
}
},
"mappings": {
"type": {
"_all": {
"enabled": false
},
"properties": {
"uuid": {
"type": "string",
"index": "not_analyzed"
}
}
}
}
}首先写入100w不同的uuid,使用磁盘容量细节如下:
health status index pri rep docs.count docs.deleted store.size pri.store.size
green open test_field 1 0 1000000 0 122.7mb 122.7mb
-rw-r--r-- 1 weizijun staff 41M Aug 19 21:23 _8.fdt
-rw-r--r-- 1 weizijun staff 17K Aug 19 21:23 _8.fdx
-rw-r--r-- 1 weizijun staff 688B Aug 19 21:23 _8.fnm
-rw-r--r-- 1 weizijun staff 494B Aug 19 21:23 _8.si
-rw-r--r-- 1 weizijun staff 265K Aug 19 21:23 _8_Lucene50_0.doc
-rw-r--r-- 1 weizijun staff 44M Aug 19 21:23 _8_Lucene50_0.tim
-rw-r--r-- 1 weizijun staff 340K Aug 19 21:23 _8_Lucene50_0.tip
-rw-r--r-- 1 weizijun staff 37M Aug 19 21:23 _8_Lucene54_0.dvd
-rw-r--r-- 1 weizijun staff 254B Aug 19 21:23 _8_Lucene54_0.dvm
-rw-r--r-- 1 weizijun staff 195B Aug 19 21:23 segments_2
-rw-r--r-- 1 weizijun staff 0B Aug 19 21:20 write.lock可以看到正排数据、倒排索引数据,列存数据容量占比几乎相同,正排数据和倒排数据还会存储Elasticsearch的唯一id字段,所以容量会比列存多一些。
35M的uuid存入Elasticsearch后,数据膨胀了3倍,达到了122.7mb。Elasticsearch竟然这么消耗资源,不要着急下结论,接下来看另一个测试结果。
我们写入100w一样的uuid,然后看看Elasticsearch使用的容量。
health status index pri rep docs.count docs.deleted store.size pri.store.size
green open test_field 1 0 1000000 0 13.2mb 13.2mb
-rw-r--r-- 1 weizijun staff 5.5M Aug 19 21:29 _6.fdt
-rw-r--r-- 1 weizijun staff 15K Aug 19 21:29 _6.fdx
-rw-r--r-- 1 weizijun staff 688B Aug 19 21:29 _6.fnm
-rw-r--r-- 1 weizijun staff 494B Aug 19 21:29 _6.si
-rw-r--r-- 1 weizijun staff 309K Aug 19 21:29 _6_Lucene50_0.doc
-rw-r--r-- 1 weizijun staff 7.0M Aug 19 21:29 _6_Lucene50_0.tim
-rw-r--r-- 1 weizijun staff 195K Aug 19 21:29 _6_Lucene50_0.tip
-rw-r--r-- 1 weizijun staff 244K Aug 19 21:29 _6_Lucene54_0.dvd
-rw-r--r-- 1 weizijun staff 252B Aug 19 21:29 _6_Lucene54_0.dvm
-rw-r--r-- 1 weizijun staff 195B Aug 19 21:29 segments_2
-rw-r--r-- 1 weizijun staff 0B Aug 19 21:26 write.lock这回35M的数据Elasticsearch容量只有13.2mb,其中还有主要的占比还是Elasticsearch的唯一id,100w的uuid几乎不占存储容积。
所以在Elasticsearch中建立索引的字段如果基数越大(count distinct),越占用磁盘空间。
我们再看看存100w个不一样的整型会是如何。
health status index pri rep docs.count docs.deleted store.size pri.store.size
green open test_field 1 0 1000000 0 13.6mb 13.6mb
-rw-r--r-- 1 weizijun staff 6.1M Aug 28 10:19 _42.fdt
-rw-r--r-- 1 weizijun staff 22K Aug 28 10:19 _42.fdx
-rw-r--r-- 1 weizijun staff 688B Aug 28 10:19 _42.fnm
-rw-r--r-- 1 weizijun staff 503B Aug 28 10:19 _42.si
-rw-r--r-- 1 weizijun staff 2.8M Aug 28 10:19 _42_Lucene50_0.doc
-rw-r--r-- 1 weizijun staff 2.2M Aug 28 10:19 _42_Lucene50_0.tim
-rw-r--r-- 1 weizijun staff 83K Aug 28 10:19 _42_Lucene50_0.tip
-rw-r--r-- 1 weizijun staff 2.5M Aug 28 10:19 _42_Lucene54_0.dvd
-rw-r--r-- 1 weizijun staff 228B Aug 28 10:19 _42_Lucene54_0.dvm
-rw-r--r-- 1 weizijun staff 196B Aug 28 10:19 segments_2
-rw-r--r-- 1 weizijun staff 0B Aug 28 10:16 write.lock从结果可以看到,100w整型数据,Elasticsearch的存储开销为13.6mb。如果以int型计算100w数据的长度的话,为400w字节,大概是3.8mb数据。忽略Elasticsearch唯一id字段的影响,Elasticsearch实际存储容量跟整型数据长度差不多。
我们再看一下开启最佳压缩参数对存储空间的影响:
health status index pri rep docs.count docs.deleted store.size pri.store.size
green open test_field 1 0 1000000 0 107.2mb 107.2mb
-rw-r--r-- 1 weizijun staff 25M Aug 20 12:30 _5.fdt
-rw-r--r-- 1 weizijun staff 6.0K Aug 20 12:30 _5.fdx
-rw-r--r-- 1 weizijun staff 688B Aug 20 12:31 _5.fnm
-rw-r--r-- 1 weizijun staff 500B Aug 20 12:31 _5.si
-rw-r--r-- 1 weizijun staff 265K Aug 20 12:31 _5_Lucene50_0.doc
-rw-r--r-- 1 weizijun staff 44M Aug 20 12:31 _5_Lucene50_0.tim
-rw-r--r-- 1 weizijun staff 322K Aug 20 12:31 _5_Lucene50_0.tip
-rw-r--r-- 1 weizijun staff 37M Aug 20 12:31 _5_Lucene54_0.dvd
-rw-r--r-- 1 weizijun staff 254B Aug 20 12:31 _5_Lucene54_0.dvm
-rw-r--r-- 1 weizijun staff 224B Aug 20 12:31 segments_4
-rw-r--r-- 1 weizijun staff 0B Aug 20 12:00 write.lock结果中可以发现,只有正排数据会启动压缩,压缩能力确实强劲,不考虑唯一id字段,存储容量大概压缩到接近50%。
我们还做了一些实验,Elasticsearch默认是开启_all参数的,_all可以让用户传入的整体json数据作为全文检索的字段,可以更方便的检索,但在现实场景中已经使用的不多,相反会增加很多存储容量的开销,可以看下开启_all的磁盘空间使用情况:
health status index pri rep docs.count docs.deleted store.size pri.store.size
green open test_field 1 0 1000000 0 162.4mb 162.4mb
-rw-r--r-- 1 weizijun staff 41M Aug 18 22:59 _20.fdt
-rw-r--r-- 1 weizijun staff 18K Aug 18 22:59 _20.fdx
-rw-r--r-- 1 weizijun staff 777B Aug 18 22:59 _20.fnm
-rw-r--r-- 1 weizijun staff 59B Aug 18 22:59 _20.nvd
-rw-r--r-- 1 weizijun staff 78B Aug 18 22:59 _20.nvm
-rw-r--r-- 1 weizijun staff 539B Aug 18 22:59 _20.si
-rw-r--r-- 1 weizijun staff 7.2M Aug 18 22:59 _20_Lucene50_0.doc
-rw-r--r-- 1 weizijun staff 4.2M Aug 18 22:59 _20_Lucene50_0.pos
-rw-r--r-- 1 weizijun staff 73M Aug 18 22:59 _20_Lucene50_0.tim
-rw-r--r-- 1 weizijun staff 832K Aug 18 22:59 _20_Lucene50_0.tip
-rw-r--r-- 1 weizijun staff 37M Aug 18 22:59 _20_Lucene54_0.dvd
-rw-r--r-- 1 weizijun staff 254B Aug 18 22:59 _20_Lucene54_0.dvm
-rw-r--r-- 1 weizijun staff 196B Aug 18 22:59 segments_2
-rw-r--r-- 1 weizijun staff 0B Aug 18 22:53 write.lock
开启_all比不开启多了40mb的存储空间,多的数据都在倒排索引上,大约会增加30%多的存储开销。所以线上都直接禁用。
然后我还做了其他几个尝试,为了验证存储容量是否和数据量成正比,写入1000w数据的uuid,发现存储容量基本为100w数据的10倍。我还验证了数据长度是否和数据量成正比,发现把uuid增长2倍、4倍,存储容量也响应的增加了2倍和4倍。在此就不一一列出数据了。
lucene各文件具体内容和实现
lucene数据元信息文件
文件名为:segments_xxx
该文件为lucene数据文件的元信息文件,记录所有segment的元数据信息。
该文件主要记录了目前有多少segment,每个segment有一些基本信息,更新这些信息定位到每个segment的元信息文件。
lucene元信息文件还支持记录userData,Elasticsearch可以在此记录translog的一些相关信息。
文件示例

具体实现类
public final class SegmentInfos implements Cloneable, Iterable<SegmentCommitInfo> {
// generation是segment的版本的概念,从文件名中提取出来,实例中为:2t/101
private long generation; // generation of the "segments_N" for the next commit
private long lastGeneration; // generation of the "segments_N" file we last successfully read
// or wrote; this is normally the same as generation except if
// there was an IOException that had interrupted a commit
/** Id for this commit; only written starting with Lucene 5.0 */
private byte[] id;
/** Which Lucene version wrote this commit, or null if this commit is pre-5.3. */
private Version luceneVersion;
/** Counts how often the index has been changed. */
public long version;
/** Used to name new segments. */
// TODO: should this be a long ...?
public int counter;
/** Version of the oldest segment in the index, or null if there are no segments. */
private Version minSegmentLuceneVersion;
private List<SegmentCommitInfo> segments = new ArrayList<>();
/** Opaque Map<String, String> that user can specify during IndexWriter.commit */
public Map<String,String> userData = Collections.emptyMap();
}
/** Embeds a [read-only] SegmentInfo and adds per-commit
* fields.
*
* @lucene.experimental */
public class SegmentCommitInfo {
/** The {@link SegmentInfo} that we wrap. */
public final SegmentInfo info;
// How many deleted docs in the segment:
private int delCount;
// Generation number of the live docs file (-1 if there
// are no deletes yet):
private long delGen;
// Normally 1+delGen, unless an exception was hit on last
// attempt to write:
private long nextWriteDelGen;
// Generation number of the FieldInfos (-1 if there are no updates)
private long fieldInfosGen;
// Normally 1+fieldInfosGen, unless an exception was hit on last attempt to
// write
private long nextWriteFieldInfosGen; //fieldInfosGen == -1 ? 1 : fieldInfosGen + 1;
// Generation number of the DocValues (-1 if there are no updates)
private long docValuesGen;
// Normally 1+dvGen, unless an exception was hit on last attempt to
// write
private long nextWriteDocValuesGen; //docValuesGen == -1 ? 1 : docValuesGen + 1;
// TODO should we add .files() to FieldInfosFormat, like we have on
// LiveDocsFormat?
// track the fieldInfos update files
private final Set<String> fieldInfosFiles = new HashSet<>();
// Track the per-field DocValues update files
private final Map<Integer,Set<String>> dvUpdatesFiles = new HashMap<>();
// Track the per-generation updates files
@Deprecated
private final Map<Long,Set<String>> genUpdatesFiles = new HashMap<>();
private volatile long sizeInBytes = -1;
}
segment的元信息文件
文件后缀:.si
每个segment都有一个.si文件,记录了该segment的元信息。
segment元信息文件中记录了segment的文档数量,segment对应的文件列表等信息。
文件示例

具体实现类
/**
* Information about a segment such as its name, directory, and files related
* to the segment.
*
* @lucene.experimental
*/
public final class SegmentInfo {
// _bl
public final String name;
/** Where this segment resides. */
public final Directory dir;
/** Id that uniquely identifies this segment. */
private final byte[] id;
private Codec codec;
// Tracks the Lucene version this segment was created with, since 3.1. Null
// indicates an older than 3.0 index, and it's used to detect a too old index.
// The format expected is "x.y" - "2.x" for pre-3.0 indexes (or null), and
// specific versions afterwards ("3.0.0", "3.1.0" etc.).
// see o.a.l.util.Version.
private Version version;
private int maxDoc; // number of docs in seg
private boolean isCompoundFile;
private Map<String,String> diagnostics;
private Set<String> setFiles;
private final Map<String,String> attributes;
}fields信息文件
文件后缀:.fnm
该文件存储了fields的基本信息。
fields信息中包括field的数量,field的类型,以及IndexOpetions,包括是否存储、是否索引,是否分词,是否需要列存等等。
文件示例

具体实现类
/**
* Access to the Field Info file that describes document fields and whether or
* not they are indexed. Each segment has a separate Field Info file. Objects
* of this class are thread-safe for multiple readers, but only one thread can
* be adding documents at a time, with no other reader or writer threads
* accessing this object.
**/
public final class FieldInfo {
/** Field's name */
public final String name;
/** Internal field number */
//field在内部的编号
public final int number;
//field docvalues的类型
private DocValuesType docValuesType = DocValuesType.NONE;
// True if any document indexed term vectors
private boolean storeTermVector;
private boolean omitNorms; // omit norms associated with indexed fields
//index的配置项
private IndexOptions indexOptions = IndexOptions.NONE;
private boolean storePayloads; // whether this field stores payloads together with term positions
private final Map<String,String> attributes;
// docvalues的generation
private long dvGen;
}数据存储文件
文件后缀:.fdx, .fdt
索引文件为.fdx,数据文件为.fdt,数据存储文件功能为根据自动的文档id,得到文档的内容,搜索引擎的术语习惯称之为正排数据,即doc_id -> content,es的_source数据就存在这
索引文件记录了快速定位文档数据的索引信息,数据文件记录了所有文档id的具体内容。
文件示例

具体实现类
/**
* Random-access reader for {@link CompressingStoredFieldsIndexWriter}.
* @lucene.internal
*/
public final class CompressingStoredFieldsIndexReader implements Cloneable, Accountable {
private static final long BASE_RAM_BYTES_USED = RamUsageEstimator.shallowSizeOfInstance(CompressingStoredFieldsIndexReader.class);
final int maxDoc;
//docid索引,快速定位某个docid的数组坐标
final int[] docBases;
//快速定位某个docid所在的文件offset的startPointer
final long[] startPointers;
//平均一个chunk的文档数
final int[] avgChunkDocs;
//平均一个chunk的size
final long[] avgChunkSizes;
final PackedInts.Reader[] docBasesDeltas; // delta from the avg
final PackedInts.Reader[] startPointersDeltas; // delta from the avg
}
/**
* {@link StoredFieldsReader} impl for {@link CompressingStoredFieldsFormat}.
* @lucene.experimental
*/
public final class CompressingStoredFieldsReader extends StoredFieldsReader {
//从fdt正排索引文件中获得
private final int version;
// field的基本信息
private final FieldInfos fieldInfos;
//fdt正排索引文件reader
private final CompressingStoredFieldsIndexReader indexReader;
//从fdt正排索引文件中获得,用于指向fdx数据文件的末端,指向numChunks地址4
private final long maxPointer;
//fdx正排数据文件句柄
private final IndexInput fieldsStream;
//块大小
private final int chunkSize;
private final int packedIntsVersion;
//压缩类型
private final CompressionMode compressionMode;
//解压缩处理对象
private final Decompressor decompressor;
//文档数量,从segment元数据中获得
private final int numDocs;
//是否正在merge,默认为false
private final boolean merging;
//初始化时new了一个BlockState,BlockState记录下当前正排文件读取的状态信息
private final BlockState state;
//chunk的数量
private final long numChunks; // number of compressed blocks written
//dirty chunk的数量
private final long numDirtyChunks; // number of incomplete compressed blocks written
//是否close,默认为false
private boolean closed;
}倒排索引文件
索引后缀:.tip,.tim
倒排索引也包含索引文件和数据文件,.tip为索引文件,.tim为数据文件,索引文件包含了每个字段的索引元信息,数据文件有具体的索引内容。
5.5.0版本的倒排索引实现为FST tree,FST tree的最大优势就是内存空间占用非常低 ,具体可以参看下这篇文章:http://www.cnblogs.com/bonelee/p/6226185.html
http://examples.mikemccandless.com/fst.py?terms=&cmd=Build+it 为FST图实例,可以根据输入的数据构造出FST图
输入到 FST 中的数据为:
String inputValues[] = {"mop","moth","pop","star","stop","top"};
long outputValues[] = {0,1,2,3,4,5};生成的 FST 图为:


文件示例

具体实现类
public final class BlockTreeTermsReader extends FieldsProducer {
// Open input to the main terms dict file (_X.tib)
final IndexInput termsIn;
// Reads the terms dict entries, to gather state to
// produce DocsEnum on demand
final PostingsReaderBase postingsReader;
private final TreeMap<String,FieldReader> fields = new TreeMap<>();
/** File offset where the directory starts in the terms file. */
/索引数据文件tim的数据的尾部的元数据的地址
private long dirOffset;
/** File offset where the directory starts in the index file. */
//索引文件tip的数据的尾部的元数据的地址
private long indexDirOffset;
//semgent的名称
final String segment;
//版本号
final int version;
//5.3.x index, we record up front if we may have written any auto-prefix terms,示例中记录的是false
final boolean anyAutoPrefixTerms;
}
/**
* BlockTree's implementation of {@link Terms}.
* @lucene.internal
*/
public final class FieldReader extends Terms implements Accountable {
//term的数量
final long numTerms;
//field信息
final FieldInfo fieldInfo;
final long sumTotalTermFreq;
//总的文档频率
final long sumDocFreq;
//文档数量
final int docCount;
//字段在索引文件tip中的起始位置
final long indexStartFP;
final long rootBlockFP;
final BytesRef rootCode;
final BytesRef minTerm;
final BytesRef maxTerm;
//longs:metadata buffer, holding monotonic values
final int longsSize;
final BlockTreeTermsReader parent;
final FST<BytesRef> index;
}倒排链文件
文件后缀:.doc, .pos, .pay
.doc保存了每个term的doc id列表和term在doc中的词频
全文索引的字段,会有.pos文件,保存了term在doc中的位置
全文索引的字段,使用了一些像payloads的高级特性才会有.pay文件,保存了term在doc中的一些高级特性
文件示例

具体实现类
/**
* Concrete class that reads docId(maybe frq,pos,offset,payloads) list
* with postings format.
*
* @lucene.experimental
*/
public final class Lucene50PostingsReader extends PostingsReaderBase {
private static final long BASE_RAM_BYTES_USED = RamUsageEstimator.shallowSizeOfInstance(Lucene50PostingsReader.class);
private final IndexInput docIn;
private final IndexInput posIn;
private final IndexInput payIn;
final ForUtil forUtil;
private int version;
//不分词的字段使用的是该对象,基于skiplist实现了倒排链
final class BlockDocsEnum extends PostingsEnum {
}
//全文检索字段使用的是该对象
final class BlockPostingsEnum extends PostingsEnum {
}
//包含高级特性的字段使用的是该对象
final class EverythingEnum extends PostingsEnum {
}
}列存文件(docvalues)
文件后缀:.dvm, .dvd
索引文件为.dvm,数据文件为.dvd。
lucene实现的docvalues有如下类型:
- 1、NONE 不开启docvalue时的状态
- 2、NUMERIC 单个数值类型的docvalue主要包括(int,long,float,double)
- 3、BINARY 二进制类型值对应不同的codes最大值可能超过32766字节,
- 4、SORTED 有序增量字节存储,仅仅存储不同部分的值和偏移量指针,值必须小于等于32766字节
- 5、SORTED_NUMERIC 存储数值类型的有序数组列表
- 6、SORTED_SET 可以存储多值域的docvalue值,但返回时,仅仅只能返回多值域的第一个docvalue
- 7、对应not_anaylized的string字段,使用的是SORTED_SET类型,number的类型是SORTED_NUMERIC类型
其中SORTED_SET 的 SORTED_SINGLE_VALUED类型包括了两类数据 : binary + numeric, binary是按ord排序的term的列表,numeric是doc到ord的映射。
文件示例

具体实现类
/** reader for {@link Lucene54DocValuesFormat} */
final class Lucene54DocValuesProducer extends DocValuesProducer implements Closeable {
//number类型的field的列存列表
private final Map<String,NumericEntry> numerics = new HashMap<>();
//字符串类型的field的列存列表
private final Map<String,BinaryEntry> binaries = new HashMap<>();
//有序字符串类型的field的列存列表
private final Map<String,SortedSetEntry> sortedSets = new HashMap<>();
//有序number类型的field的列存列表
private final Map<String,SortedSetEntry> sortedNumerics = new HashMap<>();
//字符串类型的field的ords列表
private final Map<String,NumericEntry> ords = new HashMap<>();
//docId -> address -> ord 中field的ords列表
private final Map<String,NumericEntry> ordIndexes = new HashMap<>();
//field的数量
private final int numFields;
//内存使用量
private final AtomicLong ramBytesUsed;
//数据源的文件句柄
private final IndexInput data;
//文档数
private final int maxDoc;
// memory-resident structures
private final Map<String,MonotonicBlockPackedReader> addressInstances = new HashMap<>();
private final Map<String,ReverseTermsIndex> reverseIndexInstances = new HashMap<>();
private final Map<String,DirectMonotonicReader.Meta> directAddressesMeta = new HashMap<>();
//是否正在merge
private final boolean merging;
}
/** metadata entry for a numeric docvalues field */
static class NumericEntry {
private NumericEntry() {}
/** offset to the bitset representing docsWithField, or -1 if no documents have missing values */
long missingOffset;
/** offset to the actual numeric values */
//field的在数据文件中的起始地址
public long offset;
/** end offset to the actual numeric values */
//field的在数据文件中的结尾地址
public long endOffset;
/** bits per value used to pack the numeric values */
public int bitsPerValue;
//format类型
int format;
/** count of values written */
public long count;
/** monotonic meta */
public DirectMonotonicReader.Meta monotonicMeta;
//最小的value
long minValue;
//Compressed by computing the GCD
long gcd;
//Compressed by giving IDs to unique values.
long table[];
/** for sparse compression */
long numDocsWithValue;
NumericEntry nonMissingValues;
NumberType numberType;
}
/** metadata entry for a binary docvalues field */
static class BinaryEntry {
private BinaryEntry() {}
/** offset to the bitset representing docsWithField, or -1 if no documents have missing values */
long missingOffset;
/** offset to the actual binary values */
//field的在数据文件中的起始地址
long offset;
int format;
/** count of values written */
public long count;
//最短字符串的长度
int minLength;
//最长字符串的长度
int maxLength;
/** offset to the addressing data that maps a value to its slice of the byte[] */
public long addressesOffset, addressesEndOffset;
/** meta data for addresses */
public DirectMonotonicReader.Meta addressesMeta;
/** offset to the reverse index */
public long reverseIndexOffset;
/** packed ints version used to encode addressing information */
public int packedIntsVersion;
/** packed ints blocksize */
public int blockSize;
}参考资料
Day 6 - Logstash Pipeline-to-Pipeline 尝鲜
Advent • rockybean 发表了文章 • 3 个评论 • 11721 次浏览 • 2018-12-06 23:40
Logstash 在 6.0 推出了 multiple pipeline 的解决方案,即在一个 logstash 实例中可以同时进行多个独立数据流程的处理工作,如下图所示。

而在这之前用户只能通过在单机运行多个 logstash 实例或者在配置文件中增加大量 if-else 条件判断语句来解决。要使用 multiple pipeline 也很简单,只需要将不同的 pipeline 在 config/pipeline.yml中定义好即可,如下所示:
- pipeline.id: apache
pipeline.batch.size: 125
queue.type: persisted
path.config: "/path/to/config/apache.cfg"
- pipeline.id: nginx
path.config: "/path/to/config/nginx.cfg"其中 apache和nginx作为独立的 pipeline 执行,而且配置也可以独立设置,互不干扰。pipeline.yml的引入极大地简化了 logstash 的配置管理工作,使得新手也可以很快完成复杂的 ETL 配置。
在 6.3 版本中,Logstash 又增加了 Pipeline-to-Pipeline的管道机制(beta),即管道和管道之间可以连接在一起组成一个完成的数据处理流。熟悉 linux 的管道命令 |的同学应该可以很快明白这种模式的好处。这无疑使得 Logstash 的配置会更加灵活,今天我们就来了解下这种灵活自由的配置方式。
1. 上手
废话少说,快速上手。修改 config/pipeline.yml文件如下:
- pipeline.id: upstream
config.string: input { stdin {} } output { pipeline { send_to => [test_output] } }
- pipeline.id: downstream
config.string: input { pipeline { address => test_output } } output{ stdout{}}然后运行 logstash,其中 -r 表示配置文件有改动时自动重新加载,方便我们调试。
bin/logstash -r
在终端随意输入字符(比如aaa)后回车,会看到屏幕输出了类似下面的内容,代表运行成功了。
{
"@timestamp" => 2018-12-06T14:43:50.310Z,
"@version" => "1",
"message" => "aaa",
"host" => "rockybean-MacBook-Pro.local"
}我们再回头看下这个配置,upstreamoutput 使用了名为 pipeline 的 plugin,然后 send_to的输出对象test_output是在 downstream的 input pipeline plugin 中定义的。通过这个唯一的address(虚拟地址)就能够把不同的 pipeline 连接在一起组成一个更长的pipeline来处理数据。类似下图所示:

当数据由 upstream传递给 downstream时会进行一个复制操作,这也意味着在这两个 pipeline 中的数据是完全独立的,互不影响。有一点要注意的是:数据的复制会增加额外的性能开销,比如会加大 JVM Heap 的使用。
2. 使用场景
使用方法是不是很简单,接下来我们来看下官方为我们开的几个脑洞。
2.1 Distributor Pattern 分发者模式
该模式执行效果类似下图所示:

在一个 pipeline 处理输入,然后根据不同的数据类型再分发到对应的 Pipeline 去处理。这种模式的好处在于统一输入端口,隔离不同类型的处理配置文件,减少由于配置文件混合在一起带来的维护成本。大家可以想一想如果不用这种Pipeline-to-Pipeline的方式,我们如果轻松做到一个端口处理多个来源的数据呢?
这种模式的参考配置如下所示:
# config/pipelines.yml
- pipeline.id: beats-server
config.string: |
input { beats { port => 5044 } }
output {
if [type] == apache {
pipeline { send_to => weblogs }
} else if [type] == system {
pipeline { send_to => syslog }
} else {
pipeline { send_to => fallback }
}
}
- pipeline.id: weblog-processing
config.string: |
input { pipeline { address => weblogs } }
filter {
# Weblog filter statements here...
}
output {
elasticsearch { hosts => [es_cluster_a_host] }
}
- pipeline.id: syslog-processing
config.string: |
input { pipeline { address => syslog } }
filter {
# Syslog filter statements here...
}
output {
elasticsearch { hosts => [es_cluster_b_host] }
}
- pipeline.id: fallback-processing
config.string: |
input { pipeline { address => fallback } }
output { elasticsearch { hosts => [es_cluster_b_host] } }2.2 Output Isolator Pattern 输出隔离模式
虽然 Logstash 的一个 pipeline 可以配置多个 output,但是这多个 output 会相依为命,一旦某一个 output 出问题,会导致另一个 output 也无法接收新数据。而通过这种模式可以完美解决这个问题。其运行方式如下图所示:

通过输出到两个独立的 pipeline,解除相互之间的影响,比如 http service 出问题的时候,es 依然可以正常接收数据,而且两个 pipeline 可以配置独立的队列来保障数据的完备性,其配置如下所示:
# config/pipelines.yml
- pipeline.id: intake
queue.type: persisted
config.string: |
input { beats { port => 5044 } }
output { pipeline { send_to => [es, http] } }
- pipeline.id: buffered-es
queue.type: persisted
config.string: |
input { pipeline { address => es } }
output { elasticsearch { } }
- pipeline.id: buffered-http
queue.type: persisted
config.string: |
input { pipeline { address => http } }
output { http { } }2.3 Forked Path Pattern 克隆路径模式
这个模式类似 Output Isolator Pattern,只是在不同的 output pipeline 中可以配置不同的 filter 来完成各自输出的数据处理需求,这里就不展开讲了,可以参考如下的配置,其中不同 output pipeline 的 filter 是不同的,比如 partner 这个 pipeline 去掉了一些敏感数据:
# config/pipelines.yml
- pipeline.id: intake
queue.type: persisted
config.string: |
input { beats { port => 5044 } }
output { pipeline { send_to => ["internal-es", "partner-s3"] } }
- pipeline.id: buffered-es
queue.type: persisted
config.string: |
input { pipeline { address => "internal-es" } }
# Index the full event
output { elasticsearch { } }
- pipeline.id: partner
queue.type: persisted
config.string: |
input { pipeline { address => "partner-s3" } }
filter {
# Remove the sensitive data
mutate { remove_field => 'sensitive-data' }
}
output { s3 { } } # Output to partner's bucket2.4 Collector Pattern 收集者模式
从名字可以看出,该模式是将所有 Pipeline 汇集于一处的处理模式,如下图所示:

其配置参考如下:
# config/pipelines.yml
- pipeline.id: beats
config.string: |
input { beats { port => 5044 } }
output { pipeline { send_to => [commonOut] } }
- pipeline.id: kafka
config.string: |
input { kafka { ... } }
output { pipeline { send_to => [commonOut] } }
- pipeline.id: partner
# This common pipeline enforces the same logic whether data comes from Kafka or Beats
config.string: |
input { pipeline { address => commonOut } }
filter {
# Always remove sensitive data from all input sources
mutate { remove_field => 'sensitive-data' }
}
output { elasticsearch { } }3. 总结
本文简单给大家讲解了 Pipeline-to-Pipeline的使用方法及官方推荐的几种模式,希望可以给大家有所帮助。另外这个机制目前还处于 Beta 阶段,尝鲜需谨慎!
Day 5 - Elasticsearch 存储设备全解析
Advent • cyberdak 发表了文章 • 0 个评论 • 6889 次浏览 • 2018-12-05 09:57
day5 - es存储设备全解析
Elastic Search 作为一个分布式系统,它的最小单元(shard)实现基于 lucene , lucene是一个io密集cpu密集的系统。cpu密集可以通过使用更多核,更快的cpu以及优化算法来解决。而io密集部分需要搭配高性能的存储设备以及存储策略来解决。
传统的服务器硬盘分为SATA,SAS硬盘以及现在最高性能的SSD硬盘,其中SSD硬盘又分为 SATA SSD,PCI-E SSD ,M.2 SSD(性能依次提升)。
两者的区别在于 SATA 最高可以提供 7200转的。著名的HADOOP集群中,一半都会选择企业级SATA盘来降低存储成本。而SATA盘容易损坏以及恢复速度的问题,则交给10g高速网卡以及三副本策略来解决。
如果是了解数据库领域的同学就会知道,MySQL 之类的数据库严重推荐使用SSD来做存储。TiDB这种新时代的分布式数据库甚至在安装过程中会见存储是否是高性能设备,当时低速设备时,安装将失败。
如何查看io压力
iostat -x 1 100
可以根据 iowait , ioutil 等值来综合判断. 当iowait长期接近100%基本代表io系统出现瓶颈了。这时候可以用iotop命令来诊断出具体是什么进程在消耗io资源。
如何测试硬盘性能
通过 fio 测试 顺序读/写,随机读/写性能。
顺序读 fio -name iops -rw=read -bs=4k -runtime=60 -iodepth 32 -filename /dev/sda -ioengine libaio -direct=1 随机读 fio -name iops -rw=randread -bs=4k -runtime=60 -iodepth 32 -filename /dev/sda -ioengine libaio -direct=1 顺序写 fio -name iops -rw=write -bs=4k -runtime=60 -iodepth 32 -filename /dev/sda -ioengine libaio -direct=1 随机写 fio -name iops -rw=randwrite -bs=4k -runtime=60 -iodepth 32 -filename /dev/sda -ioengine libaio -direct=1
更具体的测试可以参考磁盘性能指标--IOPS、吞吐量及测试
RAID
RAID 0
将数据分布在N块盘中,速度最快,可以享受磁盘的并行读取和写入;安全性最低,一块盘损坏,将导致所有数据丢失。
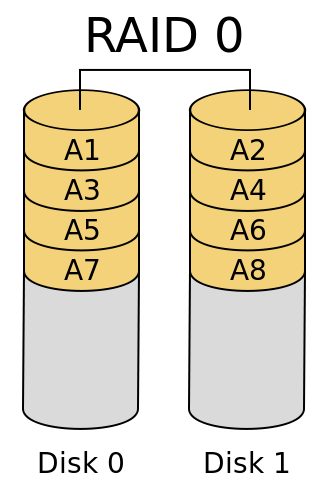
RAID 1
将数据同时保存在N块盘中,写入速度最慢(需要同时写多块盘)。安全性最高。
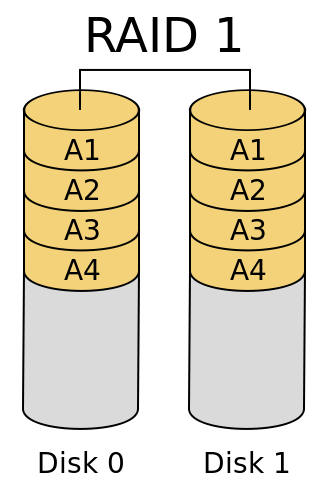
RAID 10 ?
将RAID 1 和 RAID 0 结合起来,获得高安全性和高性能。最常用的RAID策略。同时也是TiDB,MySQL等数据库推荐的RAID策略。
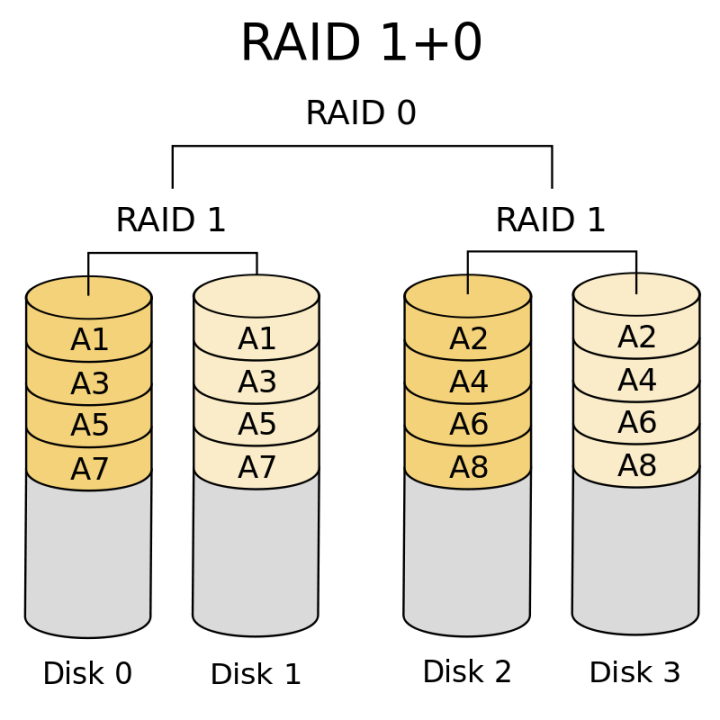
RAID 5
RAID 5 最低三块盘,存储数据的异或编码,在一块盘损坏时,可以提供编码恢复出数据。
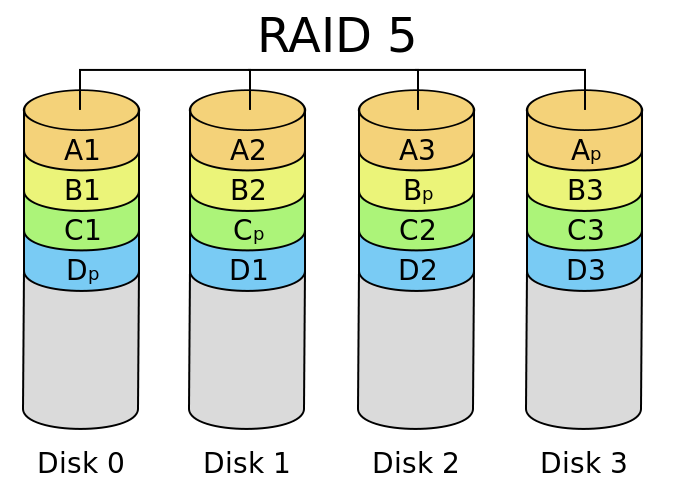
ElasticSearch 使用低速设备的 Tips
修改index.merge.scheduler.max_thread_count参数为1;该参数影响lucene后台的合并线程数量,默认设置只适合SDD。多个合并线程可能导致io压力过大,触发 (linux 120s timeout)[https://cyberdak.github.io/es/2018/07/01/es-force-merge-cause-es-down].
存储策略
- 避免单机存储过多数据,如果单机故障,将导致集群需要大量数据,影响集群的吞吐量,特别是发生在高峰时候更会影响业务。千兆网卡每小时可以同步的数据为463gb,可以参考这个速度结合资深集群网卡以及存储来调节每个节点存储的数据量。
- 存储有条件使用RAID10,增加单节点性能以及避免单节点存储故障
RAID卡策略
根据服务器RAID卡的等级不同,高级的RAID卡可以使用 write-back 写策略,数据写入会直接写入到缓存中,随后刷新到硬盘上。当主机掉电时,由RAID卡带的电池来保证数据成功写入到硬盘中。write back的设置需要电池有电才能支持,而某些场景可以设置为force write-back(即使电池没电了,也要写缓存),从而提高写入性能。
2018 年 Elastic Advent Calendar 分享活动已结束 ??
Advent • medcl 发表了文章 • 44 个评论 • 10344 次浏览 • 2018-11-20 22:33
- Day 1 - ELK 使用小技巧 - @rochy
- Day 2 - ES 6.x拼音分词高亮爬坑记 - @abia
- Day 3 - kibana二次开发tips - @vv
- Day 4 - PB级规模数据的Elasticsearch分库分表实践 - @ouyangchucai
- Day 5 - es存储设备全解析 - @cyberdak
- Day 6 - 上手 Logstash Pipeline to Pipeline 特性 - @rockybean
- Day 7 - Elasticsearch中数据是如何存储的 - @weizijun
- Day 8 - 如何使用Spark快速将数据写入Elasticsearch - @Ricky Huo
- Day 9 - 动手实现一个自定义beat - @Xinglong
- Day 10 - Elasticsearch 分片恢复并发数过大引发的bug分析 - @howardhuang
- Day 11 - Elasticsearch 5.x 6.x父子关系维护检索实战 - @yinbp
- Day 12 - Elasticsearch日志场景最佳实践 - @ginger
- Day 13 - Elasticsearch-Hadoop打通Elasticsearch和Hadoop - @Jasonbian
- Day 14 - 订单中心基于elasticsearch 的解决方案 - @blogsit
- Day 15 - 基于海量公司分词ES中文分词插件 - @novia
- Day 16 - Elasticsearch性能调优 - @白衬衣
- Day 17 - 关于日志型数据管理策略的思考 - @kennywu76
- Day 18 - 记filebeat内存泄漏问题分析及调优 - @点火三周
- Day 19 - 通过点击反馈优化es搜索结果排序 - @laigood
- Day 20 - Elastic性能实战指南 - @laoyang360
- Day 21 - ECE 版本升级扫雷实战 - @Ben_Wu
- Day 22 - 熟练使用ES离做好搜索还差多远 - @nodexy
- Day 23 - 基于 HanLP 的 ES 中文分词插件 - @rochy
- Day 24 - predator捕捉病毒样本 - @swordsmanli
- Day 25 - Elasticsearch Ingest节点数据管道处理器 - @bindiego

Day 14: Elasticsearch 5 入坑指南
Advent • kennywu76 发表了文章 • 33 个评论 • 30222 次浏览 • 2016-12-15 13:16



Day6:《记一次es性能调优》
Elasticsearch • xiaorui 发表了文章 • 5 个评论 • 14906 次浏览 • 2016-12-13 11:49
Day5: 《PacketBeat奇妙的OOM小记》
Advent • kira8565 发表了文章 • 0 个评论 • 7413 次浏览 • 2016-12-05 23:00






Day4: 《将sql转换为es的DSL》
Advent • Xargin 发表了文章 • 6 个评论 • 38600 次浏览 • 2016-12-04 23:23
select * from x_order where userId = 1 order by id desc limit 10,1;
解析之后会变成golang的一个struct,来看看具体的定义:
&sqlparser.Select{
Comments:sqlparser.Comments(nil),
Distinct:"",
SelectExprs:sqlparser.SelectExprs{(*sqlparser.StarExpr)(0xc42000aee0)},
From:sqlparser.TableExprs{(*sqlparser.AliasedTableExpr)(0xc420016930)},
Where:(*sqlparser.Where)(0xc42000afa0),
GroupBy:sqlparser.GroupBy(nil),
Having:(*sqlparser.Where)(nil),
OrderBy:sqlparser.OrderBy{(*sqlparser.Order)(0xc42000af20)},
Limit:(*sqlparser.Limit)(0xc42000af80),
Lock:""
}type Order struct {
Expr ValExpr
Direction string
}\type Limit struct {
Offset, Rowcount ValExpr
}&sqlparser.Where{
Type:"where",
Expr:(*sqlparser.ComparisonExpr)(0xc420016a50)
}select * from users where user_id = 1 and product_id =2
=>
&sqlparser.Where{
Type:"where",
Expr:(*sqlparser.AndExpr)(0xc42000b020)
}
AndExpr有Left和Right两个成员,分别是:
Left:
&sqlparser.ComparisonExpr{
Operator:"=",
Left:(*sqlparser.ColName)(0xc4200709c0),
Right:sqlparser.NumVal{0x31}
}
Right:
&sqlparser.ComparisonExpr{
Operator:"=",
Left:(*sqlparser.ColName)(0xc420070a50),
Right:sqlparser.NumVal{0x32}
}
a and (b and (c or d) and e)
=>
select * from user_history where user_id = 1 and (product_id = 2 and (star_num = 4 or star_num = 5) and banned = 1)

query {
boolmust {
a,
boolmust {
b,
c
}
}
}query {
boolmust {
a,
boolmust {
b,
boolshould {
c,
d
},
e
}
}
}
AndExpr => bool must [{left}, {right}]
OrExpr => bool should [{left}, {right}]
ComparisonExpr => 一般是叶子节点
ParenBoolExpr => 指代括号表达式,其实内部是上述三种节点的某一种,所以直接取出内部节点按上述方法来处理
Day3: 《创建一个你自己的 Beat》
Advent • medcl 发表了文章 • 0 个评论 • 10302 次浏览 • 2016-12-03 22:19
package main
import (
"fmt"
"io/ioutil"
"os"
)
func main() {
//apply run path "." without argument.
if len(os.Args) == 1 {
listDir(".")
} else {
listDir(os.Args[1])
}
}
func listDir(dirFile string) {
files, _ := ioutil.ReadDir(dirFile)
for _, f := range files {
t := f.ModTime()
fmt.Println(f.Name(), dirFile+"/"+f.Name(), f.IsDir(), t, f.Size())
if f.IsDir() {
listDir(dirFile + "/" + f.Name())
}
}
}$ go get github.com/elastic/beats$ cd $GOPATH/src/github.com/{user}
$ cookiecutter $GOPATH/src/github.com/elastic/beats/generate/beatproject_name [Examplebeat]: lsbeat
github_name [your-github-name]: {username}
beat [lsbeat]:
beat_path [github.com/{github id}]:
full_name [Firstname Lastname]: {Full Name}$ cd lsbeat
$ tree
.
├── CONTRIBUTING.md
├── LICENSE
├── Makefile
├── README.md
├── beater
│ └── lsbeat.go
├── config
│ ├── config.go
│ └── config_test.go
├── dev-tools
│ └── packer
│ ├── Makefile
│ ├── beats
│ │ └── lsbeat.yml
│ └── version.yml
├── docs
│ └── index.asciidoc
├── etc
│ ├── beat.yml
│ └── fields.yml
├── glide.yaml
├── lsbeat.template.json
├── main.go
├── main_test.go
└── tests
└── system
├── config
│ └── lsbeat.yml.j2
├── lsbeat.py
├── requirements.txt
└── test_base.py$ make setup
$ git remote add origin git@github.com:{username}/lsbeat.git
$ git push -u origin masterlsbeat.yml
lsbeat:
# Defines how often an event is sent to the output
period: 1slsbeat:
# Defines how often an event is sent to the output
period: 10s
path: "."$ make update
$ cat lsbeat.yml
################### Lsbeat Configuration Example #########################
############################# Lsbeat ######################################
lsbeat:
# Defines how often an event is sent to the output
period: 10s
path: "."
###############################################################################package config
import "time"
type Config struct {
Period time.Duration `config:"period"`
Path string `config:"path"`
}
var DefaultConfig = Config{
Period: 10 * time.Second,
Path: ".",
}type Lsbeat struct {
done chan struct{}
config config.Config
client publisher.Client
lastIndexTime time.Time
...
}func New(b *beat.Beat, cfg *common.Config) (beat.Beater, error) {
config := config.DefaultConfig
if err := cfg.Unpack(&config); err != nil {
return nil, fmt.Errorf("Error reading config file: %v", err)
}
ls := &Lsbeat{
done: make(chan struct{}),
config: config,
}
return ls, nil
}"@timestamp": common.Time(time.Now()),
"type": beatname,
"modtime": common.Time(t),
"filename": f.Name(),
"path": dirFile + "/" + f.Name(),
"directory": f.IsDir(),
"filesize": f.Size(),func (bt *Lsbeat) listDir(dirFile string, beatname string, init bool) {
files, _ := ioutil.ReadDir(dirFile)
for _, f := range files {
t := f.ModTime()
event := common.MapStr{
"@timestamp": common.Time(time.Now()),
"type": beatname,
"modtime": common.Time(t),
"filename": f.Name(),
"path": dirFile + "/" + f.Name(),
"directory": f.IsDir(),
"filesize": f.Size(),
}
if init {
// index all files and directories on init
bt.client.PublishEvent(event)
} else {
// Index only changed files since last run.
if t.After(bt.lastIndexTime) {
bt.client.PublishEvent(event)
}
}
if f.IsDir() {
bt.listDir(dirFile+"/"+f.Name(), beatname, init)
}
}
}import (
"fmt"
"io/ioutil"
"time"
)func (bt *Lsbeat) Run(b *beat.Beat) error {
logp.Info("lsbeat is running! Hit CTRL-C to stop it.")
bt.client = b.Publisher.Connect()
ticker := time.NewTicker(bt.config.Period)
counter := 1
for {
select {
case <-bt.done:
return nil
case <-ticker.C:
}
bt.listDir(bt.config.Path, b.Name, true) // call lsDir
bt.lastIndexTime = time.Now() // mark Timestamp
logp.Info("Event sent")
counter++
}
}func (bt *Lsbeat) Stop() {
bt.client.Close()
close(bt.done)
}- key: lsbeat
title: LS Beat
description:
fields:
- name: counter
type: integer
required: true
description: >
PLEASE UPDATE DOCUMENTATION
#new fiels added lsbeat
- name: modtime
type: date
- name: filename
type: text
- name: path
- name: directory
type: boolean
- name: filesize
type: long
{
"mappings": {
...
},
"order": 0,
"settings": {
"index.refresh_interval": "5s",
"analysis": {
"analyzer": {
"ls_ngram_analyzer": {
"tokenizer": "ls_ngram_tokenizer"
}
},
"tokenizer": {
"ls_ngram_tokenizer": {
"type": "ngram",
"min_gram": "2",
"token_chars": [
"letter",
"digit"
]
}
}
}
},
"template": "lsbeat-*"
}
lsbeat:
# Defines how often an event is sent to the output
period: 10s
path: "/Users/ec2-user/go"


Day2:《Kibana 系漫游指南》
Advent • 三斗室 发表了文章 • 6 个评论 • 12592 次浏览 • 2016-12-02 22:48
- app
- visTypes
- spyModes
- fieldFormatter
 2. vectormap
这是一个 visType 插件,也就是我们在 Kibana3 里曾经用过的 map panel 效果。这个插件不被官方直接采用的一个原因是版权许可问题。不做商用的情况下,这个插件还是可以极大方便我们做行政区域的访问情况统计和展示的。
2. vectormap
这是一个 visType 插件,也就是我们在 Kibana3 里曾经用过的 map panel 效果。这个插件不被官方直接采用的一个原因是版权许可问题。不做商用的情况下,这个插件还是可以极大方便我们做行政区域的访问情况统计和展示的。
 3. kbn_network
这也是一个 visType 插件,酷毙了的网状图效果!通过不同的 aggs 数据展示 node 和 relational。
注意这个跟 Elastic 的 graph 并不是完全一致的东西。该插件要求你本身的数据已经有直接的关联可用。
3. kbn_network
这也是一个 visType 插件,酷毙了的网状图效果!通过不同的 aggs 数据展示 node 和 relational。
注意这个跟 Elastic 的 graph 并不是完全一致的东西。该插件要求你本身的数据已经有直接的关联可用。
 4. sentinl
这是一个同时带有 spyMode 和 app 双插件的项目。其基础思路是参照 Elastic 的 Watcher 接口,但是将监控告警的进程从 ES 挪到 Kibana 里。同时还可以通过 phantomjs 做到截图报表。
4. sentinl
这是一个同时带有 spyMode 和 app 双插件的项目。其基础思路是参照 Elastic 的 Watcher 接口,但是将监控告警的进程从 ES 挪到 Kibana 里。同时还可以通过 phantomjs 做到截图报表。
Day1: 大规模Elasticsearch集群管理心得
Advent • kennywu76 发表了文章 • 83 个评论 • 52553 次浏览 • 2016-12-02 10:07
- 单日索引数据条数600亿,新增索引文件25TB (含一个复制片则为50TB)
- 业务高峰期峰值索引速率维持在百万条/秒
- 历史数据保留时长根据业务需求制定,从10天 - 90天不等
- 集群共3441个索引、17000个分片、数据总量约9300亿, 磁盘总消耗1PB
- Kibana用户600多人, 每日来自Kibana和第三方的API调用共63万次
- 查询响应时间百分位 75%:0.160s 90%:1.640s 95%:6.691s 99%:14.0039s
- 首先很有必要对ES的结点做角色划分和隔离。大家知道ES的data node除了放数据以外,也可以兼任master和client的角色,多数同学会将这些角色混入到data node。然而对于一个规模较大,用户较多的集群,master和client在一些极端使用情况下可能会有性能瓶颈甚至内存溢出,从而使得共存的data node故障。data node的故障恢复涉及到数据的迁移,对集群资源有一定消耗,容易造成数据写入延迟或者查询减慢。如果将master和client独立出来,一旦出现问题,重启后几乎是瞬间就恢复的,对用户几乎没有任何影响。另外将这些角色独立出来的以后,也将对应的计算资源消耗从data node剥离出来,更容易掌握data node资源消耗与写入量和查询量之间的联系,便于做容量管理和规划。
- 避免过高的并发,包括控制shard数量和threadpool的数量。在写入量和查询性能能够满足的前提下,为索引分配尽量少的分片。分片过多会带来诸多负面影响,例如:每次查询后需要汇总排序的数据更多;过多的并发带来的线程切换造成过多的CPU损耗;索引的删除和配置更新更慢Issue#18776; 过多的shard也带来更多小的segment,而过多的小segment会带来非常显著的heap内存消耗,特别是如果查询线程配置得很多的情况下。 配置过大的threadpool更是会产生很多诡异的性能问题Issue#18161里所描述的问题就是我们所经历过的。 默认的Theadpool大小一般来说工作得很不错了。
- 冷热数据最好做分离。对于日志型应用来说,一般是每天建立一个新索引,当天的热索引在写入的同时也会有较多的查询。如果上面还存有比较长时间之前的冷数据,那么当用户做大跨度的历史数据查询的时候,过多的磁盘IO和CPU消耗很容易拖慢写入,造成数据的延迟。所以我们用了一部分机器来做冷数据的存储,利用ES可以给结点配置自定义属性的功能,为冷结点加上"boxtype":"weak"的标识,每晚通过维护脚本更新冷数据的索引路由设置index.routing.allocation.{require|include|exclude},让数据自动向冷结点迁移。 冷数据的特性是不再写入,用户查的频率较低,但量级可能很大。比如我们有个索引每天2TB,并且用户要求保持过去90天数据随时可查。保持这么大量的索引为open状态,并非只消耗磁盘空间。ES为了快速访问磁盘上的索引文件,需要在内存里驻留一些数据(索引文件的索引),也就是所谓的segment memory。稍微熟悉ES的同学知道,JVM heap分配不能超过32GB,对于我们128GB RAM, 48TB磁盘空间的机器而言,如果只跑一个ES实例,只能利用到32GB不到的heap,当heap快用饱和的时候,磁盘上保存的索引文件还不到10TB,这样显然是不经济的。 因此我们决定在冷结点上跑3个ES实例,每个分配31GB heap空间,从而可以在一台物理服务器上存储30多TB的索引数据并保持open状态,供用户随时搜索。 实际使用下来,由于冷数据搜索频率不高,也没有写入,即时只剩余35GB内存给os做文件系统缓存,查询性能还是可以满足需求的。
- 不同数据量级的shard最好隔离到不同组别的结点。 大家知道ES会自己平衡shard在集群的分布,这个自动平衡的逻辑主要考量三个因素。其一同一索引下的shard尽量分散到不同的结点;其二每个结点上的shard数量尽量接近;其三结点的磁盘有足够的剩余空间。这个策略只能保证shard数量分布均匀,而并不能保证数据大小分布均匀。 实际应用中,我们有200多种索引,数据量级差别很大,大的一天几个TB,小的一个月才几个GB,并且每种类型的数据保留时长又千差万别。抛出的问题,就是如何能比较平衡并充分的利用所有节点的资源。 针对这个问题,我们还是通过对结点添加属性标签来做分组,结合index routing控制的方式来做一些精细化的控制。尽量让不同量级的数据使用不同组别的结点,使得每个组内结点上的数据量比较容易自动平衡。
- 定期做索引的force merge,并且最好是每个shard merge成一个segment。前面提到过,heap消耗与segment数量也有关系,force merge可以显著降低这种消耗。 如果merge成一个segment还有一个好处,就是对于terms aggregation,搜索时无需构造Global Ordinals,可以提升聚合速度。
- 结点启动的Bootstrap过程加入了很多关键系统参数设置的核验,比如Max File Descriptors, Memory Lock, Virtual Memory设置等等,如果设置不正确会拒绝启动并抛出异常。 与其带着错误的系统参数启动,并在日后造成性能问题,不如启动失败告知用户问题,是个很好的设计!
- 索引性能提升。升级后在同样索引速率下,我们看到cpu消耗下降非常明显,除了对索引速率提升有帮助,也会一定程度提升搜索速率。
- 新的数值型数据结构,存储空间更小,Range和地理位置计算更快速
- Instant Aggregation对于类似now-7d to now这样的范围查询聚合能够做cache了,实际使用下来,效果明显,用户在Kibana上跑个过去一周数据的聚合,头2次刷新慢点,之后有cache了几乎就瞬间刷出!
- 更多的保护措施保证集群的稳定,比如对一次搜索hit的shard数量做了限制,增强了circuit breaker的特性,更好的防护集群资源被坏查询耗尽。
- 各类Thread pool的使用情况,active/queue/reject可视化出来。 判断集群是否有性能瓶颈了,看看业务高峰期各类queue是不是很高,reject是不是经常发生,基本可以做到心里有数。
- JVM的heap used%以及old GC的频率,如果old GC频率很高,并且多次GC过后heap used%几乎下不来,说明heap压力太大,要考虑扩容了。(也有可能是有问题的查询或者聚合造成的,需要结合用户访问记录来判断)。
- Segment memory大小和Segment的数量。节点上存放的索引较多的时候,这两个指标就值得关注,要知道segment memory是常驻heap不会被GC回收的,因此当heap压力太大的时候,可以结合这个指标判断是否是因为节点上存放的数据过多,需要扩容。Segement的数量也是比较关键的,如果小的segment非常多,比如有几千,即使segment memory本身不多,但是在搜索线程很多的情况下,依然会吃掉相当多的heap,原因是lucene为每个segment会在thread local里记录状态信息,这块的heap内存开销和(segment数量* thread数量)相关。
- 很有必要记录用户的访问记录。我们只开放了http api给用户,前置了一个nginx做http代理,将用户第三方api的访问记录通过access log全部记录下来。通过分析访问记录,可以在集群出现性能问题时,快速找到问题根源,对于问题排查和性能优化都很有帮助。
Elastic Advent Calendar 活动启动咯!
Advent • medcl 发表了文章 • 11 个评论 • 8927 次浏览 • 2016-11-04 13:46
Day24: Elasticsearch添加Shield后TransportClient如何连接?
Advent • medcl 发表了文章 • 6 个评论 • 9693 次浏览 • 2015-12-28 12:13

2018 年 Elastic Advent Calendar 分享活动已结束 ??
Advent • medcl 发表了文章 • 44 个评论 • 10344 次浏览 • 2018-11-20 22:33
- Day 1 - ELK 使用小技巧 - @rochy
- Day 2 - ES 6.x拼音分词高亮爬坑记 - @abia
- Day 3 - kibana二次开发tips - @vv
- Day 4 - PB级规模数据的Elasticsearch分库分表实践 - @ouyangchucai
- Day 5 - es存储设备全解析 - @cyberdak
- Day 6 - 上手 Logstash Pipeline to Pipeline 特性 - @rockybean
- Day 7 - Elasticsearch中数据是如何存储的 - @weizijun
- Day 8 - 如何使用Spark快速将数据写入Elasticsearch - @Ricky Huo
- Day 9 - 动手实现一个自定义beat - @Xinglong
- Day 10 - Elasticsearch 分片恢复并发数过大引发的bug分析 - @howardhuang
- Day 11 - Elasticsearch 5.x 6.x父子关系维护检索实战 - @yinbp
- Day 12 - Elasticsearch日志场景最佳实践 - @ginger
- Day 13 - Elasticsearch-Hadoop打通Elasticsearch和Hadoop - @Jasonbian
- Day 14 - 订单中心基于elasticsearch 的解决方案 - @blogsit
- Day 15 - 基于海量公司分词ES中文分词插件 - @novia
- Day 16 - Elasticsearch性能调优 - @白衬衣
- Day 17 - 关于日志型数据管理策略的思考 - @kennywu76
- Day 18 - 记filebeat内存泄漏问题分析及调优 - @点火三周
- Day 19 - 通过点击反馈优化es搜索结果排序 - @laigood
- Day 20 - Elastic性能实战指南 - @laoyang360
- Day 21 - ECE 版本升级扫雷实战 - @Ben_Wu
- Day 22 - 熟练使用ES离做好搜索还差多远 - @nodexy
- Day 23 - 基于 HanLP 的 ES 中文分词插件 - @rochy
- Day 24 - predator捕捉病毒样本 - @swordsmanli
- Day 25 - Elasticsearch Ingest节点数据管道处理器 - @bindiego
Day 14: Elasticsearch 5 入坑指南
Advent • kennywu76 发表了文章 • 33 个评论 • 30222 次浏览 • 2016-12-15 13:16
Day1: 大规模Elasticsearch集群管理心得
Advent • kennywu76 发表了文章 • 83 个评论 • 52553 次浏览 • 2016-12-02 10:07
- 单日索引数据条数600亿,新增索引文件25TB (含一个复制片则为50TB)
- 业务高峰期峰值索引速率维持在百万条/秒
- 历史数据保留时长根据业务需求制定,从10天 - 90天不等
- 集群共3441个索引、17000个分片、数据总量约9300亿, 磁盘总消耗1PB
- Kibana用户600多人, 每日来自Kibana和第三方的API调用共63万次
- 查询响应时间百分位 75%:0.160s 90%:1.640s 95%:6.691s 99%:14.0039s
- 首先很有必要对ES的结点做角色划分和隔离。大家知道ES的data node除了放数据以外,也可以兼任master和client的角色,多数同学会将这些角色混入到data node。然而对于一个规模较大,用户较多的集群,master和client在一些极端使用情况下可能会有性能瓶颈甚至内存溢出,从而使得共存的data node故障。data node的故障恢复涉及到数据的迁移,对集群资源有一定消耗,容易造成数据写入延迟或者查询减慢。如果将master和client独立出来,一旦出现问题,重启后几乎是瞬间就恢复的,对用户几乎没有任何影响。另外将这些角色独立出来的以后,也将对应的计算资源消耗从data node剥离出来,更容易掌握data node资源消耗与写入量和查询量之间的联系,便于做容量管理和规划。
- 避免过高的并发,包括控制shard数量和threadpool的数量。在写入量和查询性能能够满足的前提下,为索引分配尽量少的分片。分片过多会带来诸多负面影响,例如:每次查询后需要汇总排序的数据更多;过多的并发带来的线程切换造成过多的CPU损耗;索引的删除和配置更新更慢Issue#18776; 过多的shard也带来更多小的segment,而过多的小segment会带来非常显著的heap内存消耗,特别是如果查询线程配置得很多的情况下。 配置过大的threadpool更是会产生很多诡异的性能问题Issue#18161里所描述的问题就是我们所经历过的。 默认的Theadpool大小一般来说工作得很不错了。
- 冷热数据最好做分离。对于日志型应用来说,一般是每天建立一个新索引,当天的热索引在写入的同时也会有较多的查询。如果上面还存有比较长时间之前的冷数据,那么当用户做大跨度的历史数据查询的时候,过多的磁盘IO和CPU消耗很容易拖慢写入,造成数据的延迟。所以我们用了一部分机器来做冷数据的存储,利用ES可以给结点配置自定义属性的功能,为冷结点加上"boxtype":"weak"的标识,每晚通过维护脚本更新冷数据的索引路由设置index.routing.allocation.{require|include|exclude},让数据自动向冷结点迁移。 冷数据的特性是不再写入,用户查的频率较低,但量级可能很大。比如我们有个索引每天2TB,并且用户要求保持过去90天数据随时可查。保持这么大量的索引为open状态,并非只消耗磁盘空间。ES为了快速访问磁盘上的索引文件,需要在内存里驻留一些数据(索引文件的索引),也就是所谓的segment memory。稍微熟悉ES的同学知道,JVM heap分配不能超过32GB,对于我们128GB RAM, 48TB磁盘空间的机器而言,如果只跑一个ES实例,只能利用到32GB不到的heap,当heap快用饱和的时候,磁盘上保存的索引文件还不到10TB,这样显然是不经济的。 因此我们决定在冷结点上跑3个ES实例,每个分配31GB heap空间,从而可以在一台物理服务器上存储30多TB的索引数据并保持open状态,供用户随时搜索。 实际使用下来,由于冷数据搜索频率不高,也没有写入,即时只剩余35GB内存给os做文件系统缓存,查询性能还是可以满足需求的。
- 不同数据量级的shard最好隔离到不同组别的结点。 大家知道ES会自己平衡shard在集群的分布,这个自动平衡的逻辑主要考量三个因素。其一同一索引下的shard尽量分散到不同的结点;其二每个结点上的shard数量尽量接近;其三结点的磁盘有足够的剩余空间。这个策略只能保证shard数量分布均匀,而并不能保证数据大小分布均匀。 实际应用中,我们有200多种索引,数据量级差别很大,大的一天几个TB,小的一个月才几个GB,并且每种类型的数据保留时长又千差万别。抛出的问题,就是如何能比较平衡并充分的利用所有节点的资源。 针对这个问题,我们还是通过对结点添加属性标签来做分组,结合index routing控制的方式来做一些精细化的控制。尽量让不同量级的数据使用不同组别的结点,使得每个组内结点上的数据量比较容易自动平衡。
- 定期做索引的force merge,并且最好是每个shard merge成一个segment。前面提到过,heap消耗与segment数量也有关系,force merge可以显著降低这种消耗。 如果merge成一个segment还有一个好处,就是对于terms aggregation,搜索时无需构造Global Ordinals,可以提升聚合速度。
- 结点启动的Bootstrap过程加入了很多关键系统参数设置的核验,比如Max File Descriptors, Memory Lock, Virtual Memory设置等等,如果设置不正确会拒绝启动并抛出异常。 与其带着错误的系统参数启动,并在日后造成性能问题,不如启动失败告知用户问题,是个很好的设计!
- 索引性能提升。升级后在同样索引速率下,我们看到cpu消耗下降非常明显,除了对索引速率提升有帮助,也会一定程度提升搜索速率。
- 新的数值型数据结构,存储空间更小,Range和地理位置计算更快速
- Instant Aggregation对于类似now-7d to now这样的范围查询聚合能够做cache了,实际使用下来,效果明显,用户在Kibana上跑个过去一周数据的聚合,头2次刷新慢点,之后有cache了几乎就瞬间刷出!
- 更多的保护措施保证集群的稳定,比如对一次搜索hit的shard数量做了限制,增强了circuit breaker的特性,更好的防护集群资源被坏查询耗尽。
- 各类Thread pool的使用情况,active/queue/reject可视化出来。 判断集群是否有性能瓶颈了,看看业务高峰期各类queue是不是很高,reject是不是经常发生,基本可以做到心里有数。
- JVM的heap used%以及old GC的频率,如果old GC频率很高,并且多次GC过后heap used%几乎下不来,说明heap压力太大,要考虑扩容了。(也有可能是有问题的查询或者聚合造成的,需要结合用户访问记录来判断)。
- Segment memory大小和Segment的数量。节点上存放的索引较多的时候,这两个指标就值得关注,要知道segment memory是常驻heap不会被GC回收的,因此当heap压力太大的时候,可以结合这个指标判断是否是因为节点上存放的数据过多,需要扩容。Segement的数量也是比较关键的,如果小的segment非常多,比如有几千,即使segment memory本身不多,但是在搜索线程很多的情况下,依然会吃掉相当多的heap,原因是lucene为每个segment会在thread local里记录状态信息,这块的heap内存开销和(segment数量* thread数量)相关。
- 很有必要记录用户的访问记录。我们只开放了http api给用户,前置了一个nginx做http代理,将用户第三方api的访问记录通过access log全部记录下来。通过分析访问记录,可以在集群出现性能问题时,快速找到问题根源,对于问题排查和性能优化都很有帮助。
Day24 - Predator捕捉病毒样本
Advent • swordsmanli 发表了文章 • 0 个评论 • 4592 次浏览 • 2018-12-21 16:18
对,你一定看过一个电影,情节是这样的,他们拿着长矛去狩猎异形怪物,它们比人类强健,它们的脸部的器官布置得出奇丑陋。它们的身上总是带了一堆很先进的狩猎武器,它们喜欢在杀死猎物后将尸体剥皮,还会将猎物头骨加工成工艺品,当成战利品收藏。对,这部电影系列就叫Predator。好了,言归正传,我们今天讲的故事其实非常简单,讲述的是elasticsearch引擎在安全领域的简单应用,如何通过elasticsearch来搜索一个病毒,我们开发了一个小小的工具来帮我做跨集群查询,以及SQL-DSL转换接口,我们把这个小工具叫做predator。
背景
我司主要是做病毒相关工作的,近年来,数据爆炸,病毒软件也成几何级数倍数增长,大数据病毒出现自然需要对应的大数据工具来处理它们,简单来讲,就是我们可以把病毒样本的一些属性剥离到elasticsearch中,就和日志来描述一个用户的行为一样,本质来说,它们都是数据,然后,我们研究病毒的一些特征属性,通过简单的搜索,就可以快速分析出一堆可能的病毒样本,再然后,通过一系列的测试,过滤,我们就可以真正的找到我们想要的病毒样本,并且通过这些规则持续的追踪它们,是不是很简单?
问题
事情是那么简单,但是在使用elasticsearch作为特征库的过程中,我们也有这样的问题:
1,多种维度特征
由于存在多种维度特征的病毒,不通模块剥离出不通病毒属性,所以存在多张表来存属性,那么在query的时候就需要跨表,甚至跨集群查询。
2,DSL的复杂度
由于内部研究员们对elasticStack并不熟悉,加上DSL语言相对复杂,我们需要使用更加接近hunman特性的SQL来转换DSL语言。
数据处理架构
我们有一个类似的数据处理架构
Predator和它的Spear
因此,我们开发了一个小工具,其实,这个小工具非常简单,只是简单的解决了上述2个问题:
使用Elasticsearch-SQL插件来包装一个restful的DSL转换SQL接口,当然,目前ES6已经完全支持SQL接口了,哈哈,早点出来我们就不用做那么工作了:) :):)。
简单的写个跨集群的查下聚合器就可以实现跨表查下,其实,这个功能只是简单的查下封装,只是针对特殊的业务场景,没啥参考价值。
至于Spear,它其实就是个predator service的客户端,哈哈,像不像铁血战士拿着长矛开着非常去狩猎的样子:) 。
这是一个规则:
这是规则的查询结果:
长矛的sample code:
# cross cluster search by dsls
import json
from spear import Spear
sp = Spear()
dsl_1 = {}
dsl_2 = {}
query_dict = {
json.dumps(dsl_1): {
"cluster": "es_cluster_1",
"type":"xxx"
},
json.dumps(dsl_2): {
"cluster": "es_cluster_2",
"type": "yyy"
}
}
sp.cross_count_by_dsl(query_dict, is_show_help=False)当然长矛也支持SQL接口
总结
其实,这个只是一个user case的工程实践,可以看到的是,伟大的ElasticStack在各行各业,各种大数据领域,如果抛开领域的概念,一切都是数据,那么理论上来说我们可以使用elasticsearch处理任何类型的数据,当然目前业界典型的应用场景还是搜索,日志,甚至于APM,总之,紧跟社区可以学到很多东西啦。
Day 17 - 关于日志型数据管理策略的思考
Elasticsearch • kennywu76 发表了文章 • 7 个评论 • 7950 次浏览 • 2018-12-17 11:19
近两年随着Elastic Stack的愈发火热,其近乎成为构建实时日志应用的工业标准。在小型数据应用场景,最新的6.5版本已经可以做到开箱即用,无需过多考虑架构上的设计工作。 然而一旦应用规模扩大到数百TB甚至PB的数据量级,整个系统的架构和后期维护工作则显得非常重要。借着2018 Elastic Advent写文的机会,结合过去几年架构和运维公司日志集群的实践经验,对于大规模日志型数据的管理策略,在此做一个总结性的思考。 文中抛出的观点,有些已经在我们的集群中有所应用并取得比较好的效果,有些则还待实践的检验。抛砖引玉,不尽成熟的地方,还请社区各位专家指正。
对于日志系统,最终用户通常有以下几个基本要求:
- 数据从产生到可检索的实时性要求高,可接受的延迟通常要求控制在数秒,至多不超过数十秒
- 新鲜数据(当天至过去几天)的查询和统计频率高,返回速度要快(毫秒级,至多几秒)
- 历史数据保留得越久越好。
针对这些需求,加上对成本控制的必要性,大家通常想到的第一个架构设计就是冷热数据分离。
冷热数据分离
冷热分离的概念比较好理解,热结点做数据的写入,保存近期热数据,冷数据定期迁移到冷数据结点,就这么简单。不过实际操作起来可能还是碰到一些具体需要考虑的细节问题。
- 冷热结点集群配置的JVM heap配置要差异化。热结点无需存放太多数据,对于heap的要求通常不是太高,在够用的情况下尽量配置小一点。可以配置在26GB左右甚至更小,而不是大多数人知道的经验值31GB。原因在于这个size的heap,可以启用
zero basedCompressed Oops,JVM运行效率是最高的, 参考: heap-size。而冷结点存在的目的是尽量放更多的数据,性能不是首要的,因此heap可以配置在31GB。 - 数据迁移过程有一定资源消耗,为避免对数据写入产生显著影响,通常定时在业务低峰期,日志产出量比较低的时候进行,比如半夜。
- 索引是否应该启用压缩,如何启用?最初我们对于热结点上的索引是不启用压缩的,为了节省CPU消耗。只在冷结点配置里,增加了索引压缩选项。这样索引迁移到冷结点后,执行force merge操作的时候,ES会自动将结点上配置的索引压缩属性套用到merge过后新生成的segment,这样就实现了热结点不压缩,冷结点merge过后压缩的功能。极大节省了冷结点的磁盘空间。后来随着硬件的升级,我们发现服务器的cpu基本都是过剩的,磁盘IO通常先到瓶颈。 因此尝试在热结点上一开始创建索引的时候,就启用压缩选项。实际对比测试并没有发现显著的索引吞吐量下降,并且因为索引压缩后磁盘文件size的大幅减少,每天夜间的数据迁移工作可以节省大量的时间。至此我们的日志集群索引默认就是压缩的。
- 冷结点上留做系统缓存的内存一般不多,加上数据量非常巨大。索引默认的mmapfs读取方式,很容易因为系统缓存不够,导致数据在内存和磁盘之间频繁换入换出。严重的情况下,整个结点甚至会因为io持续在100%无法响应。 实践中我们发现对冷结点使用niofs效果会更好。
实现了冷热结点分离以后,集群的资源利用率提升了不少,可管理性也要好很多了. 但是随着接入日志的类型越来越多(我们生产上有差不多400种类型的日志),各种日志的速率差异又很大,让ES自己管理shard的分布很容易产生写入热点问题。 针对这个问题,可以采用对集群结点进行分组管理的策略来解决。
热结点分组管理
所谓分组管理,就是通过在结点的配置文件中增加自定义的标签属性,将服务器区分到不同的组别中。然后通过设置索引的index.routing.allocation.include属性,控制改索引分布在哪个组别。同时配合设置index.routing.allocation.total_shards_per_node,可以做到某个索引的shard在某个group的结点之间绝对均匀分布。
比如一个分组有10台机器,对一个5 primary ,1 replica的索引,让该索引分布在该分组的同时,设置total_shards_per_node为1,让每个节点上只能有一个分片,这样就避免了写入热点问题。 该方案的缺陷也显而易见,一旦有结点挂掉,不会自动recovery,某个shard将一直处于unassigned状态,集群状态变成yellow。 但我认为,热数据的恢复开销是非常高的,与其立即在其他结点开始复制,之后再重新rebalance,不如就让集群暂时处于yellow状态。 通过监控报警的手段,及时通知运维人员解决结点故障。 待故障解决之后,直接从恢复后的结点开始数据复制,开销要低得多。
在我们的生产环境主要有两种类型的结点分组,分别是10台机器一个分组,和2台机器一个分组。10台机器的分组用于应对速率非常高,shard划分比较多的索引,2台机器的分组用于速率很低,一个shard(加一个复制片)就可以应对的索引。
这种分组策略在我们的生产环境中经过验证,非常好的解决了写入热点问题。那么冷数据怎么管理? 冷数据不做写入,不存在写入热点问题,查询频率也比较低,业务需求方面对查询响应要求也不那么严苛,所以查询热点问题也不是那么突出。因此为了简化管理,冷结点我们是不做shard分布的精细控制,所有数据迁移到冷数据结点之后,由ES默认的shard分布则略去控制数据的分布。
不过如果想进一步提高冷数据结点服务器资源的利用率,还是可以有进一步挖掘的的空间。我们知道ES默认的shard分布策略,只是保证一个索引的shard尽量分布在不同的结点,同时保证每个节点上shard数量差不多。但是如果采用默认按天创建索引的策略,由于索引速率差异很大,不同索引之间shard的大小差异可能是1-2个数量级的。如果每个shard的size差异不大就好了,那么默认的分布策略,基本上可以保证冷结点之间数据量分布的大致均匀。 能实现类似功能的是ES的rollover特性。
索引的Rollover
Rollover api可以让索引根据预先定义的时间跨度,或者索引大小来自动切分出新索引,从而将索引的大小控制在计划的范围内。合理的应用rollver api可以保证集群shard大小差别不会太大。 只是集群索引类别比较多的时候,rollover全部手动管理负担比较大,需要借助额外的管理工具和监控工具。我们出于管理简便的考虑,暂时没有应用到这个特性。
索引的Rollup
我们发现生产有些用户写入的“日志”,实际上是多维的metrcis数据,使用的时候不是为了查询日志的详情,仅仅是为了做各种维度组合的过滤和聚合。对于这种类型的数据,保留历史数据过多一来浪费存储空间,二来每次聚合都要在裸数据上跑,非常浪费资源。 ES从6.3开始,在x-pack里推出了rollup api,通过定期对裸数据做预先聚合,大大缩减了保存在磁盘上的数据量。对于不需要查询裸日志的应用场景,合理应用该特性,可以将历史数据的磁盘消耗降低几个数量级,同时rollup search也可以大大提升聚合速度。不过rollup也有其局限性,即他的实现是通过定期任务,对间隔期数据跑聚合完成的,有一定的计算开销。 如果数据写入速率非常高,集群压力很大,rollup可能无法跟上写入速率,而不具有实用性。 所以实际环境中,还是需要根据应用场景和资源使用情况,进行灵活的取舍。
多集群的便利性
数据量大到一定程度以后,单集群由于master node单点的限制,会遇到各种集群状态数据更新时得性能问题。 由此现在一些大规模的应用已经开始利用到多集群互联和cross cluster search的特性。 这种结构除了解决单集群数据容量限制问题以外,我们还发现在做容量均衡方面还有比较好的便利性。应用日志写入量通常随着业务变化也会剧烈变化,好不容易规划好的容量,不久就被业务的增长给打破,数倍或者数10倍的流量增长很可能就让一组结点过载出现写入延迟。 如果只有一个集群,在结点之间重新平衡shard比较费力,涉及到数据的迁移,可能非常缓慢,还会影响写入。 但如果有多集群互联,切换就可以做到非常的快速和简单。 原理上只需要在新集群中加入对应的索引配置模版,然后更新写入程序的配置,写入目标指向新集群,重启写入程序即可。并且,可以进一步将整个流程工具化,在GUI上完成一键切换。
Day 7 - Elasticsearch中数据是如何存储的
Advent • weizijun 发表了文章 • 7 个评论 • 78995 次浏览 • 2018-12-07 13:55
前言
很多使用Elasticsearch的同学会关心数据存储在ES中的存储容量,会有这样的疑问:xxTB的数据入到ES会使用多少存储空间。这个问题其实很难直接回答的,只有数据写入ES后,才能观察到实际的存储空间。比如同样是1TB的数据,写入ES的存储空间可能差距会非常大,可能小到只有300~400GB,也可能多到6-7TB,为什么会造成这么大的差距呢?究其原因,我们来探究下Elasticsearch中的数据是如何存储。文章中我以Elasticsearch 2.3版本为示例,对应的lucene版本是5.5,Elasticsearch现在已经来到了6.5版本,数字类型、列存等存储结构有些变化,但基本的概念变化不多,文章中的内容依然适用。
Elasticsearch索引结构
Elasticsearch对外提供的是index的概念,可以类比为DB,用户查询是在index上完成的,每个index由若干个shard组成,以此来达到分布式可扩展的能力。比如下图是一个由10个shard组成的index。
shard是Elasticsearch数据存储的最小单位,index的存储容量为所有shard的存储容量之和。Elasticsearch集群的存储容量则为所有index存储容量之和。
一个shard就对应了一个lucene的library。对于一个shard,Elasticsearch增加了translog的功能,类似于HBase WAL,是数据写入过程中的中间数据,其余的数据都在lucene库中管理的。
所以Elasticsearch索引使用的存储内容主要取决于lucene中的数据存储。
lucene数据存储
下面我们主要看下lucene的文件内容,在了解lucene文件内容前,大家先了解些lucene的基本概念。
lucene基本概念
- segment : lucene内部的数据是由一个个segment组成的,写入lucene的数据并不直接落盘,而是先写在内存中,经过了refresh间隔,lucene才将该时间段写入的全部数据refresh成一个segment,segment多了之后会进行merge成更大的segment。lucene查询时会遍历每个segment完成。由于lucene* 写入的数据是在内存中完成,所以写入效率非常高。但是也存在丢失数据的风险,所以Elasticsearch基于此现象实现了translog,只有在segment数据落盘后,Elasticsearch才会删除对应的translog。
- doc : doc表示lucene中的一条记录
- field :field表示记录中的字段概念,一个doc由若干个field组成。
- term :term是lucene中索引的最小单位,某个field对应的内容如果是全文检索类型,会将内容进行分词,分词的结果就是由term组成的。如果是不分词的字段,那么该字段的内容就是一个term。
- 倒排索引(inverted index): lucene索引的通用叫法,即实现了term到doc list的映射。
- 正排数据:搜索引擎的通用叫法,即原始数据,可以理解为一个doc list。
- docvalues :Elasticsearch中的列式存储的名称,Elasticsearch除了存储原始存储、倒排索引,还存储了一份docvalues,用作分析和排序。
lucene文件内容
lucene包的文件是由很多segment文件组成的,segments_xxx文件记录了lucene包下面的segment文件数量。每个segment会包含如下的文件。
| Name | Extension | Brief Description |
|---|---|---|
| Segment Info | .si | segment的元数据文件 |
| Compound File | .cfs, .cfe | 一个segment包含了如下表的各个文件,为减少打开文件的数量,在segment小的时候,segment的所有文件内容都保存在cfs文件中,cfe文件保存了lucene各文件在cfs文件的位置信息 |
| Fields | .fnm | 保存了fields的相关信息 |
| Field Index | .fdx | 正排存储文件的元数据信息 |
| Field Data | .fdt | 存储了正排存储数据,写入的原文存储在这 |
| Term Dictionary | .tim | 倒排索引的元数据信息 |
| Term Index | .tip | 倒排索引文件,存储了所有的倒排索引数据 |
| Frequencies | .doc | 保存了每个term的doc id列表和term在doc中的词频 |
| Positions | .pos | Stores position information about where a term occurs in the index 全文索引的字段,会有该文件,保存了term在doc中的位置 |
| Payloads | .pay | Stores additional per-position metadata information such as character offsets and user payloads 全文索引的字段,使用了一些像payloads的高级特性会有该文件,保存了term在doc中的一些高级特性 |
| Norms | .nvd, .nvm | 文件保存索引字段加权数据 |
| Per-Document Values | .dvd, .dvm | lucene的docvalues文件,即数据的列式存储,用作聚合和排序 |
| Term Vector Data | .tvx, .tvd, .tvf | Stores offset into the document data file 保存索引字段的矢量信息,用在对term进行高亮,计算文本相关性中使用 |
| Live Documents | .liv | 记录了segment中删除的doc |
测试数据示例
下面我们以真实的数据作为示例,看看lucene中各类型数据的容量占比。
写100w数据,有一个uuid字段,写入的是长度为36位的uuid,字符串总为3600w字节,约为35M。
数据使用一个shard,不带副本,使用默认的压缩算法,写入完成后merge成一个segment方便观察。
使用线上默认的配置,uuid存为不分词的字符串类型。创建如下索引:
PUT test_field
{
"settings": {
"index": {
"number_of_shards": "1",
"number_of_replicas": "0",
"refresh_interval": "30s"
}
},
"mappings": {
"type": {
"_all": {
"enabled": false
},
"properties": {
"uuid": {
"type": "string",
"index": "not_analyzed"
}
}
}
}
}首先写入100w不同的uuid,使用磁盘容量细节如下:
health status index pri rep docs.count docs.deleted store.size pri.store.size
green open test_field 1 0 1000000 0 122.7mb 122.7mb
-rw-r--r-- 1 weizijun staff 41M Aug 19 21:23 _8.fdt
-rw-r--r-- 1 weizijun staff 17K Aug 19 21:23 _8.fdx
-rw-r--r-- 1 weizijun staff 688B Aug 19 21:23 _8.fnm
-rw-r--r-- 1 weizijun staff 494B Aug 19 21:23 _8.si
-rw-r--r-- 1 weizijun staff 265K Aug 19 21:23 _8_Lucene50_0.doc
-rw-r--r-- 1 weizijun staff 44M Aug 19 21:23 _8_Lucene50_0.tim
-rw-r--r-- 1 weizijun staff 340K Aug 19 21:23 _8_Lucene50_0.tip
-rw-r--r-- 1 weizijun staff 37M Aug 19 21:23 _8_Lucene54_0.dvd
-rw-r--r-- 1 weizijun staff 254B Aug 19 21:23 _8_Lucene54_0.dvm
-rw-r--r-- 1 weizijun staff 195B Aug 19 21:23 segments_2
-rw-r--r-- 1 weizijun staff 0B Aug 19 21:20 write.lock可以看到正排数据、倒排索引数据,列存数据容量占比几乎相同,正排数据和倒排数据还会存储Elasticsearch的唯一id字段,所以容量会比列存多一些。
35M的uuid存入Elasticsearch后,数据膨胀了3倍,达到了122.7mb。Elasticsearch竟然这么消耗资源,不要着急下结论,接下来看另一个测试结果。
我们写入100w一样的uuid,然后看看Elasticsearch使用的容量。
health status index pri rep docs.count docs.deleted store.size pri.store.size
green open test_field 1 0 1000000 0 13.2mb 13.2mb
-rw-r--r-- 1 weizijun staff 5.5M Aug 19 21:29 _6.fdt
-rw-r--r-- 1 weizijun staff 15K Aug 19 21:29 _6.fdx
-rw-r--r-- 1 weizijun staff 688B Aug 19 21:29 _6.fnm
-rw-r--r-- 1 weizijun staff 494B Aug 19 21:29 _6.si
-rw-r--r-- 1 weizijun staff 309K Aug 19 21:29 _6_Lucene50_0.doc
-rw-r--r-- 1 weizijun staff 7.0M Aug 19 21:29 _6_Lucene50_0.tim
-rw-r--r-- 1 weizijun staff 195K Aug 19 21:29 _6_Lucene50_0.tip
-rw-r--r-- 1 weizijun staff 244K Aug 19 21:29 _6_Lucene54_0.dvd
-rw-r--r-- 1 weizijun staff 252B Aug 19 21:29 _6_Lucene54_0.dvm
-rw-r--r-- 1 weizijun staff 195B Aug 19 21:29 segments_2
-rw-r--r-- 1 weizijun staff 0B Aug 19 21:26 write.lock这回35M的数据Elasticsearch容量只有13.2mb,其中还有主要的占比还是Elasticsearch的唯一id,100w的uuid几乎不占存储容积。
所以在Elasticsearch中建立索引的字段如果基数越大(count distinct),越占用磁盘空间。
我们再看看存100w个不一样的整型会是如何。
health status index pri rep docs.count docs.deleted store.size pri.store.size
green open test_field 1 0 1000000 0 13.6mb 13.6mb
-rw-r--r-- 1 weizijun staff 6.1M Aug 28 10:19 _42.fdt
-rw-r--r-- 1 weizijun staff 22K Aug 28 10:19 _42.fdx
-rw-r--r-- 1 weizijun staff 688B Aug 28 10:19 _42.fnm
-rw-r--r-- 1 weizijun staff 503B Aug 28 10:19 _42.si
-rw-r--r-- 1 weizijun staff 2.8M Aug 28 10:19 _42_Lucene50_0.doc
-rw-r--r-- 1 weizijun staff 2.2M Aug 28 10:19 _42_Lucene50_0.tim
-rw-r--r-- 1 weizijun staff 83K Aug 28 10:19 _42_Lucene50_0.tip
-rw-r--r-- 1 weizijun staff 2.5M Aug 28 10:19 _42_Lucene54_0.dvd
-rw-r--r-- 1 weizijun staff 228B Aug 28 10:19 _42_Lucene54_0.dvm
-rw-r--r-- 1 weizijun staff 196B Aug 28 10:19 segments_2
-rw-r--r-- 1 weizijun staff 0B Aug 28 10:16 write.lock从结果可以看到,100w整型数据,Elasticsearch的存储开销为13.6mb。如果以int型计算100w数据的长度的话,为400w字节,大概是3.8mb数据。忽略Elasticsearch唯一id字段的影响,Elasticsearch实际存储容量跟整型数据长度差不多。
我们再看一下开启最佳压缩参数对存储空间的影响:
health status index pri rep docs.count docs.deleted store.size pri.store.size
green open test_field 1 0 1000000 0 107.2mb 107.2mb
-rw-r--r-- 1 weizijun staff 25M Aug 20 12:30 _5.fdt
-rw-r--r-- 1 weizijun staff 6.0K Aug 20 12:30 _5.fdx
-rw-r--r-- 1 weizijun staff 688B Aug 20 12:31 _5.fnm
-rw-r--r-- 1 weizijun staff 500B Aug 20 12:31 _5.si
-rw-r--r-- 1 weizijun staff 265K Aug 20 12:31 _5_Lucene50_0.doc
-rw-r--r-- 1 weizijun staff 44M Aug 20 12:31 _5_Lucene50_0.tim
-rw-r--r-- 1 weizijun staff 322K Aug 20 12:31 _5_Lucene50_0.tip
-rw-r--r-- 1 weizijun staff 37M Aug 20 12:31 _5_Lucene54_0.dvd
-rw-r--r-- 1 weizijun staff 254B Aug 20 12:31 _5_Lucene54_0.dvm
-rw-r--r-- 1 weizijun staff 224B Aug 20 12:31 segments_4
-rw-r--r-- 1 weizijun staff 0B Aug 20 12:00 write.lock结果中可以发现,只有正排数据会启动压缩,压缩能力确实强劲,不考虑唯一id字段,存储容量大概压缩到接近50%。
我们还做了一些实验,Elasticsearch默认是开启_all参数的,_all可以让用户传入的整体json数据作为全文检索的字段,可以更方便的检索,但在现实场景中已经使用的不多,相反会增加很多存储容量的开销,可以看下开启_all的磁盘空间使用情况:
health status index pri rep docs.count docs.deleted store.size pri.store.size
green open test_field 1 0 1000000 0 162.4mb 162.4mb
-rw-r--r-- 1 weizijun staff 41M Aug 18 22:59 _20.fdt
-rw-r--r-- 1 weizijun staff 18K Aug 18 22:59 _20.fdx
-rw-r--r-- 1 weizijun staff 777B Aug 18 22:59 _20.fnm
-rw-r--r-- 1 weizijun staff 59B Aug 18 22:59 _20.nvd
-rw-r--r-- 1 weizijun staff 78B Aug 18 22:59 _20.nvm
-rw-r--r-- 1 weizijun staff 539B Aug 18 22:59 _20.si
-rw-r--r-- 1 weizijun staff 7.2M Aug 18 22:59 _20_Lucene50_0.doc
-rw-r--r-- 1 weizijun staff 4.2M Aug 18 22:59 _20_Lucene50_0.pos
-rw-r--r-- 1 weizijun staff 73M Aug 18 22:59 _20_Lucene50_0.tim
-rw-r--r-- 1 weizijun staff 832K Aug 18 22:59 _20_Lucene50_0.tip
-rw-r--r-- 1 weizijun staff 37M Aug 18 22:59 _20_Lucene54_0.dvd
-rw-r--r-- 1 weizijun staff 254B Aug 18 22:59 _20_Lucene54_0.dvm
-rw-r--r-- 1 weizijun staff 196B Aug 18 22:59 segments_2
-rw-r--r-- 1 weizijun staff 0B Aug 18 22:53 write.lock
开启_all比不开启多了40mb的存储空间,多的数据都在倒排索引上,大约会增加30%多的存储开销。所以线上都直接禁用。
然后我还做了其他几个尝试,为了验证存储容量是否和数据量成正比,写入1000w数据的uuid,发现存储容量基本为100w数据的10倍。我还验证了数据长度是否和数据量成正比,发现把uuid增长2倍、4倍,存储容量也响应的增加了2倍和4倍。在此就不一一列出数据了。
lucene各文件具体内容和实现
lucene数据元信息文件
文件名为:segments_xxx
该文件为lucene数据文件的元信息文件,记录所有segment的元数据信息。
该文件主要记录了目前有多少segment,每个segment有一些基本信息,更新这些信息定位到每个segment的元信息文件。
lucene元信息文件还支持记录userData,Elasticsearch可以在此记录translog的一些相关信息。
文件示例
具体实现类
public final class SegmentInfos implements Cloneable, Iterable<SegmentCommitInfo> {
// generation是segment的版本的概念,从文件名中提取出来,实例中为:2t/101
private long generation; // generation of the "segments_N" for the next commit
private long lastGeneration; // generation of the "segments_N" file we last successfully read
// or wrote; this is normally the same as generation except if
// there was an IOException that had interrupted a commit
/** Id for this commit; only written starting with Lucene 5.0 */
private byte[] id;
/** Which Lucene version wrote this commit, or null if this commit is pre-5.3. */
private Version luceneVersion;
/** Counts how often the index has been changed. */
public long version;
/** Used to name new segments. */
// TODO: should this be a long ...?
public int counter;
/** Version of the oldest segment in the index, or null if there are no segments. */
private Version minSegmentLuceneVersion;
private List<SegmentCommitInfo> segments = new ArrayList<>();
/** Opaque Map<String, String> that user can specify during IndexWriter.commit */
public Map<String,String> userData = Collections.emptyMap();
}
/** Embeds a [read-only] SegmentInfo and adds per-commit
* fields.
*
* @lucene.experimental */
public class SegmentCommitInfo {
/** The {@link SegmentInfo} that we wrap. */
public final SegmentInfo info;
// How many deleted docs in the segment:
private int delCount;
// Generation number of the live docs file (-1 if there
// are no deletes yet):
private long delGen;
// Normally 1+delGen, unless an exception was hit on last
// attempt to write:
private long nextWriteDelGen;
// Generation number of the FieldInfos (-1 if there are no updates)
private long fieldInfosGen;
// Normally 1+fieldInfosGen, unless an exception was hit on last attempt to
// write
private long nextWriteFieldInfosGen; //fieldInfosGen == -1 ? 1 : fieldInfosGen + 1;
// Generation number of the DocValues (-1 if there are no updates)
private long docValuesGen;
// Normally 1+dvGen, unless an exception was hit on last attempt to
// write
private long nextWriteDocValuesGen; //docValuesGen == -1 ? 1 : docValuesGen + 1;
// TODO should we add .files() to FieldInfosFormat, like we have on
// LiveDocsFormat?
// track the fieldInfos update files
private final Set<String> fieldInfosFiles = new HashSet<>();
// Track the per-field DocValues update files
private final Map<Integer,Set<String>> dvUpdatesFiles = new HashMap<>();
// Track the per-generation updates files
@Deprecated
private final Map<Long,Set<String>> genUpdatesFiles = new HashMap<>();
private volatile long sizeInBytes = -1;
}
segment的元信息文件
文件后缀:.si
每个segment都有一个.si文件,记录了该segment的元信息。
segment元信息文件中记录了segment的文档数量,segment对应的文件列表等信息。
文件示例
具体实现类
/**
* Information about a segment such as its name, directory, and files related
* to the segment.
*
* @lucene.experimental
*/
public final class SegmentInfo {
// _bl
public final String name;
/** Where this segment resides. */
public final Directory dir;
/** Id that uniquely identifies this segment. */
private final byte[] id;
private Codec codec;
// Tracks the Lucene version this segment was created with, since 3.1. Null
// indicates an older than 3.0 index, and it's used to detect a too old index.
// The format expected is "x.y" - "2.x" for pre-3.0 indexes (or null), and
// specific versions afterwards ("3.0.0", "3.1.0" etc.).
// see o.a.l.util.Version.
private Version version;
private int maxDoc; // number of docs in seg
private boolean isCompoundFile;
private Map<String,String> diagnostics;
private Set<String> setFiles;
private final Map<String,String> attributes;
}fields信息文件
文件后缀:.fnm
该文件存储了fields的基本信息。
fields信息中包括field的数量,field的类型,以及IndexOpetions,包括是否存储、是否索引,是否分词,是否需要列存等等。
文件示例
具体实现类
/**
* Access to the Field Info file that describes document fields and whether or
* not they are indexed. Each segment has a separate Field Info file. Objects
* of this class are thread-safe for multiple readers, but only one thread can
* be adding documents at a time, with no other reader or writer threads
* accessing this object.
**/
public final class FieldInfo {
/** Field's name */
public final String name;
/** Internal field number */
//field在内部的编号
public final int number;
//field docvalues的类型
private DocValuesType docValuesType = DocValuesType.NONE;
// True if any document indexed term vectors
private boolean storeTermVector;
private boolean omitNorms; // omit norms associated with indexed fields
//index的配置项
private IndexOptions indexOptions = IndexOptions.NONE;
private boolean storePayloads; // whether this field stores payloads together with term positions
private final Map<String,String> attributes;
// docvalues的generation
private long dvGen;
}数据存储文件
文件后缀:.fdx, .fdt
索引文件为.fdx,数据文件为.fdt,数据存储文件功能为根据自动的文档id,得到文档的内容,搜索引擎的术语习惯称之为正排数据,即doc_id -> content,es的_source数据就存在这
索引文件记录了快速定位文档数据的索引信息,数据文件记录了所有文档id的具体内容。
文件示例
具体实现类
/**
* Random-access reader for {@link CompressingStoredFieldsIndexWriter}.
* @lucene.internal
*/
public final class CompressingStoredFieldsIndexReader implements Cloneable, Accountable {
private static final long BASE_RAM_BYTES_USED = RamUsageEstimator.shallowSizeOfInstance(CompressingStoredFieldsIndexReader.class);
final int maxDoc;
//docid索引,快速定位某个docid的数组坐标
final int[] docBases;
//快速定位某个docid所在的文件offset的startPointer
final long[] startPointers;
//平均一个chunk的文档数
final int[] avgChunkDocs;
//平均一个chunk的size
final long[] avgChunkSizes;
final PackedInts.Reader[] docBasesDeltas; // delta from the avg
final PackedInts.Reader[] startPointersDeltas; // delta from the avg
}
/**
* {@link StoredFieldsReader} impl for {@link CompressingStoredFieldsFormat}.
* @lucene.experimental
*/
public final class CompressingStoredFieldsReader extends StoredFieldsReader {
//从fdt正排索引文件中获得
private final int version;
// field的基本信息
private final FieldInfos fieldInfos;
//fdt正排索引文件reader
private final CompressingStoredFieldsIndexReader indexReader;
//从fdt正排索引文件中获得,用于指向fdx数据文件的末端,指向numChunks地址4
private final long maxPointer;
//fdx正排数据文件句柄
private final IndexInput fieldsStream;
//块大小
private final int chunkSize;
private final int packedIntsVersion;
//压缩类型
private final CompressionMode compressionMode;
//解压缩处理对象
private final Decompressor decompressor;
//文档数量,从segment元数据中获得
private final int numDocs;
//是否正在merge,默认为false
private final boolean merging;
//初始化时new了一个BlockState,BlockState记录下当前正排文件读取的状态信息
private final BlockState state;
//chunk的数量
private final long numChunks; // number of compressed blocks written
//dirty chunk的数量
private final long numDirtyChunks; // number of incomplete compressed blocks written
//是否close,默认为false
private boolean closed;
}倒排索引文件
索引后缀:.tip,.tim
倒排索引也包含索引文件和数据文件,.tip为索引文件,.tim为数据文件,索引文件包含了每个字段的索引元信息,数据文件有具体的索引内容。
5.5.0版本的倒排索引实现为FST tree,FST tree的最大优势就是内存空间占用非常低 ,具体可以参看下这篇文章:http://www.cnblogs.com/bonelee/p/6226185.html
http://examples.mikemccandless.com/fst.py?terms=&cmd=Build+it 为FST图实例,可以根据输入的数据构造出FST图
输入到 FST 中的数据为:
String inputValues[] = {"mop","moth","pop","star","stop","top"};
long outputValues[] = {0,1,2,3,4,5};生成的 FST 图为:
文件示例
具体实现类
public final class BlockTreeTermsReader extends FieldsProducer {
// Open input to the main terms dict file (_X.tib)
final IndexInput termsIn;
// Reads the terms dict entries, to gather state to
// produce DocsEnum on demand
final PostingsReaderBase postingsReader;
private final TreeMap<String,FieldReader> fields = new TreeMap<>();
/** File offset where the directory starts in the terms file. */
/索引数据文件tim的数据的尾部的元数据的地址
private long dirOffset;
/** File offset where the directory starts in the index file. */
//索引文件tip的数据的尾部的元数据的地址
private long indexDirOffset;
//semgent的名称
final String segment;
//版本号
final int version;
//5.3.x index, we record up front if we may have written any auto-prefix terms,示例中记录的是false
final boolean anyAutoPrefixTerms;
}
/**
* BlockTree's implementation of {@link Terms}.
* @lucene.internal
*/
public final class FieldReader extends Terms implements Accountable {
//term的数量
final long numTerms;
//field信息
final FieldInfo fieldInfo;
final long sumTotalTermFreq;
//总的文档频率
final long sumDocFreq;
//文档数量
final int docCount;
//字段在索引文件tip中的起始位置
final long indexStartFP;
final long rootBlockFP;
final BytesRef rootCode;
final BytesRef minTerm;
final BytesRef maxTerm;
//longs:metadata buffer, holding monotonic values
final int longsSize;
final BlockTreeTermsReader parent;
final FST<BytesRef> index;
}倒排链文件
文件后缀:.doc, .pos, .pay
.doc保存了每个term的doc id列表和term在doc中的词频
全文索引的字段,会有.pos文件,保存了term在doc中的位置
全文索引的字段,使用了一些像payloads的高级特性才会有.pay文件,保存了term在doc中的一些高级特性
文件示例
具体实现类
/**
* Concrete class that reads docId(maybe frq,pos,offset,payloads) list
* with postings format.
*
* @lucene.experimental
*/
public final class Lucene50PostingsReader extends PostingsReaderBase {
private static final long BASE_RAM_BYTES_USED = RamUsageEstimator.shallowSizeOfInstance(Lucene50PostingsReader.class);
private final IndexInput docIn;
private final IndexInput posIn;
private final IndexInput payIn;
final ForUtil forUtil;
private int version;
//不分词的字段使用的是该对象,基于skiplist实现了倒排链
final class BlockDocsEnum extends PostingsEnum {
}
//全文检索字段使用的是该对象
final class BlockPostingsEnum extends PostingsEnum {
}
//包含高级特性的字段使用的是该对象
final class EverythingEnum extends PostingsEnum {
}
}列存文件(docvalues)
文件后缀:.dvm, .dvd
索引文件为.dvm,数据文件为.dvd。
lucene实现的docvalues有如下类型:
- 1、NONE 不开启docvalue时的状态
- 2、NUMERIC 单个数值类型的docvalue主要包括(int,long,float,double)
- 3、BINARY 二进制类型值对应不同的codes最大值可能超过32766字节,
- 4、SORTED 有序增量字节存储,仅仅存储不同部分的值和偏移量指针,值必须小于等于32766字节
- 5、SORTED_NUMERIC 存储数值类型的有序数组列表
- 6、SORTED_SET 可以存储多值域的docvalue值,但返回时,仅仅只能返回多值域的第一个docvalue
- 7、对应not_anaylized的string字段,使用的是SORTED_SET类型,number的类型是SORTED_NUMERIC类型
其中SORTED_SET 的 SORTED_SINGLE_VALUED类型包括了两类数据 : binary + numeric, binary是按ord排序的term的列表,numeric是doc到ord的映射。
文件示例
具体实现类
/** reader for {@link Lucene54DocValuesFormat} */
final class Lucene54DocValuesProducer extends DocValuesProducer implements Closeable {
//number类型的field的列存列表
private final Map<String,NumericEntry> numerics = new HashMap<>();
//字符串类型的field的列存列表
private final Map<String,BinaryEntry> binaries = new HashMap<>();
//有序字符串类型的field的列存列表
private final Map<String,SortedSetEntry> sortedSets = new HashMap<>();
//有序number类型的field的列存列表
private final Map<String,SortedSetEntry> sortedNumerics = new HashMap<>();
//字符串类型的field的ords列表
private final Map<String,NumericEntry> ords = new HashMap<>();
//docId -> address -> ord 中field的ords列表
private final Map<String,NumericEntry> ordIndexes = new HashMap<>();
//field的数量
private final int numFields;
//内存使用量
private final AtomicLong ramBytesUsed;
//数据源的文件句柄
private final IndexInput data;
//文档数
private final int maxDoc;
// memory-resident structures
private final Map<String,MonotonicBlockPackedReader> addressInstances = new HashMap<>();
private final Map<String,ReverseTermsIndex> reverseIndexInstances = new HashMap<>();
private final Map<String,DirectMonotonicReader.Meta> directAddressesMeta = new HashMap<>();
//是否正在merge
private final boolean merging;
}
/** metadata entry for a numeric docvalues field */
static class NumericEntry {
private NumericEntry() {}
/** offset to the bitset representing docsWithField, or -1 if no documents have missing values */
long missingOffset;
/** offset to the actual numeric values */
//field的在数据文件中的起始地址
public long offset;
/** end offset to the actual numeric values */
//field的在数据文件中的结尾地址
public long endOffset;
/** bits per value used to pack the numeric values */
public int bitsPerValue;
//format类型
int format;
/** count of values written */
public long count;
/** monotonic meta */
public DirectMonotonicReader.Meta monotonicMeta;
//最小的value
long minValue;
//Compressed by computing the GCD
long gcd;
//Compressed by giving IDs to unique values.
long table[];
/** for sparse compression */
long numDocsWithValue;
NumericEntry nonMissingValues;
NumberType numberType;
}
/** metadata entry for a binary docvalues field */
static class BinaryEntry {
private BinaryEntry() {}
/** offset to the bitset representing docsWithField, or -1 if no documents have missing values */
long missingOffset;
/** offset to the actual binary values */
//field的在数据文件中的起始地址
long offset;
int format;
/** count of values written */
public long count;
//最短字符串的长度
int minLength;
//最长字符串的长度
int maxLength;
/** offset to the addressing data that maps a value to its slice of the byte[] */
public long addressesOffset, addressesEndOffset;
/** meta data for addresses */
public DirectMonotonicReader.Meta addressesMeta;
/** offset to the reverse index */
public long reverseIndexOffset;
/** packed ints version used to encode addressing information */
public int packedIntsVersion;
/** packed ints blocksize */
public int blockSize;
}参考资料
Day 6 - Logstash Pipeline-to-Pipeline 尝鲜
Advent • rockybean 发表了文章 • 3 个评论 • 11721 次浏览 • 2018-12-06 23:40
Logstash 在 6.0 推出了 multiple pipeline 的解决方案,即在一个 logstash 实例中可以同时进行多个独立数据流程的处理工作,如下图所示。
而在这之前用户只能通过在单机运行多个 logstash 实例或者在配置文件中增加大量 if-else 条件判断语句来解决。要使用 multiple pipeline 也很简单,只需要将不同的 pipeline 在 config/pipeline.yml中定义好即可,如下所示:
- pipeline.id: apache
pipeline.batch.size: 125
queue.type: persisted
path.config: "/path/to/config/apache.cfg"
- pipeline.id: nginx
path.config: "/path/to/config/nginx.cfg"其中 apache和nginx作为独立的 pipeline 执行,而且配置也可以独立设置,互不干扰。pipeline.yml的引入极大地简化了 logstash 的配置管理工作,使得新手也可以很快完成复杂的 ETL 配置。
在 6.3 版本中,Logstash 又增加了 Pipeline-to-Pipeline的管道机制(beta),即管道和管道之间可以连接在一起组成一个完成的数据处理流。熟悉 linux 的管道命令 |的同学应该可以很快明白这种模式的好处。这无疑使得 Logstash 的配置会更加灵活,今天我们就来了解下这种灵活自由的配置方式。
1. 上手
废话少说,快速上手。修改 config/pipeline.yml文件如下:
- pipeline.id: upstream
config.string: input { stdin {} } output { pipeline { send_to => [test_output] } }
- pipeline.id: downstream
config.string: input { pipeline { address => test_output } } output{ stdout{}}然后运行 logstash,其中 -r 表示配置文件有改动时自动重新加载,方便我们调试。
bin/logstash -r
在终端随意输入字符(比如aaa)后回车,会看到屏幕输出了类似下面的内容,代表运行成功了。
{
"@timestamp" => 2018-12-06T14:43:50.310Z,
"@version" => "1",
"message" => "aaa",
"host" => "rockybean-MacBook-Pro.local"
}我们再回头看下这个配置,upstreamoutput 使用了名为 pipeline 的 plugin,然后 send_to的输出对象test_output是在 downstream的 input pipeline plugin 中定义的。通过这个唯一的address(虚拟地址)就能够把不同的 pipeline 连接在一起组成一个更长的pipeline来处理数据。类似下图所示:
当数据由 upstream传递给 downstream时会进行一个复制操作,这也意味着在这两个 pipeline 中的数据是完全独立的,互不影响。有一点要注意的是:数据的复制会增加额外的性能开销,比如会加大 JVM Heap 的使用。
2. 使用场景
使用方法是不是很简单,接下来我们来看下官方为我们开的几个脑洞。
2.1 Distributor Pattern 分发者模式
该模式执行效果类似下图所示:
在一个 pipeline 处理输入,然后根据不同的数据类型再分发到对应的 Pipeline 去处理。这种模式的好处在于统一输入端口,隔离不同类型的处理配置文件,减少由于配置文件混合在一起带来的维护成本。大家可以想一想如果不用这种Pipeline-to-Pipeline的方式,我们如果轻松做到一个端口处理多个来源的数据呢?
这种模式的参考配置如下所示:
# config/pipelines.yml
- pipeline.id: beats-server
config.string: |
input { beats { port => 5044 } }
output {
if [type] == apache {
pipeline { send_to => weblogs }
} else if [type] == system {
pipeline { send_to => syslog }
} else {
pipeline { send_to => fallback }
}
}
- pipeline.id: weblog-processing
config.string: |
input { pipeline { address => weblogs } }
filter {
# Weblog filter statements here...
}
output {
elasticsearch { hosts => [es_cluster_a_host] }
}
- pipeline.id: syslog-processing
config.string: |
input { pipeline { address => syslog } }
filter {
# Syslog filter statements here...
}
output {
elasticsearch { hosts => [es_cluster_b_host] }
}
- pipeline.id: fallback-processing
config.string: |
input { pipeline { address => fallback } }
output { elasticsearch { hosts => [es_cluster_b_host] } }2.2 Output Isolator Pattern 输出隔离模式
虽然 Logstash 的一个 pipeline 可以配置多个 output,但是这多个 output 会相依为命,一旦某一个 output 出问题,会导致另一个 output 也无法接收新数据。而通过这种模式可以完美解决这个问题。其运行方式如下图所示:
通过输出到两个独立的 pipeline,解除相互之间的影响,比如 http service 出问题的时候,es 依然可以正常接收数据,而且两个 pipeline 可以配置独立的队列来保障数据的完备性,其配置如下所示:
# config/pipelines.yml
- pipeline.id: intake
queue.type: persisted
config.string: |
input { beats { port => 5044 } }
output { pipeline { send_to => [es, http] } }
- pipeline.id: buffered-es
queue.type: persisted
config.string: |
input { pipeline { address => es } }
output { elasticsearch { } }
- pipeline.id: buffered-http
queue.type: persisted
config.string: |
input { pipeline { address => http } }
output { http { } }2.3 Forked Path Pattern 克隆路径模式
这个模式类似 Output Isolator Pattern,只是在不同的 output pipeline 中可以配置不同的 filter 来完成各自输出的数据处理需求,这里就不展开讲了,可以参考如下的配置,其中不同 output pipeline 的 filter 是不同的,比如 partner 这个 pipeline 去掉了一些敏感数据:
# config/pipelines.yml
- pipeline.id: intake
queue.type: persisted
config.string: |
input { beats { port => 5044 } }
output { pipeline { send_to => ["internal-es", "partner-s3"] } }
- pipeline.id: buffered-es
queue.type: persisted
config.string: |
input { pipeline { address => "internal-es" } }
# Index the full event
output { elasticsearch { } }
- pipeline.id: partner
queue.type: persisted
config.string: |
input { pipeline { address => "partner-s3" } }
filter {
# Remove the sensitive data
mutate { remove_field => 'sensitive-data' }
}
output { s3 { } } # Output to partner's bucket2.4 Collector Pattern 收集者模式
从名字可以看出,该模式是将所有 Pipeline 汇集于一处的处理模式,如下图所示:
其配置参考如下:
# config/pipelines.yml
- pipeline.id: beats
config.string: |
input { beats { port => 5044 } }
output { pipeline { send_to => [commonOut] } }
- pipeline.id: kafka
config.string: |
input { kafka { ... } }
output { pipeline { send_to => [commonOut] } }
- pipeline.id: partner
# This common pipeline enforces the same logic whether data comes from Kafka or Beats
config.string: |
input { pipeline { address => commonOut } }
filter {
# Always remove sensitive data from all input sources
mutate { remove_field => 'sensitive-data' }
}
output { elasticsearch { } }3. 总结
本文简单给大家讲解了 Pipeline-to-Pipeline的使用方法及官方推荐的几种模式,希望可以给大家有所帮助。另外这个机制目前还处于 Beta 阶段,尝鲜需谨慎!
Day 5 - Elasticsearch 存储设备全解析
Advent • cyberdak 发表了文章 • 0 个评论 • 6889 次浏览 • 2018-12-05 09:57
day5 - es存储设备全解析
Elastic Search 作为一个分布式系统,它的最小单元(shard)实现基于 lucene , lucene是一个io密集cpu密集的系统。cpu密集可以通过使用更多核,更快的cpu以及优化算法来解决。而io密集部分需要搭配高性能的存储设备以及存储策略来解决。
传统的服务器硬盘分为SATA,SAS硬盘以及现在最高性能的SSD硬盘,其中SSD硬盘又分为 SATA SSD,PCI-E SSD ,M.2 SSD(性能依次提升)。
两者的区别在于 SATA 最高可以提供 7200转的。著名的HADOOP集群中,一半都会选择企业级SATA盘来降低存储成本。而SATA盘容易损坏以及恢复速度的问题,则交给10g高速网卡以及三副本策略来解决。
如果是了解数据库领域的同学就会知道,MySQL 之类的数据库严重推荐使用SSD来做存储。TiDB这种新时代的分布式数据库甚至在安装过程中会见存储是否是高性能设备,当时低速设备时,安装将失败。
如何查看io压力
iostat -x 1 100
可以根据 iowait , ioutil 等值来综合判断. 当iowait长期接近100%基本代表io系统出现瓶颈了。这时候可以用iotop命令来诊断出具体是什么进程在消耗io资源。
如何测试硬盘性能
通过 fio 测试 顺序读/写,随机读/写性能。
顺序读 fio -name iops -rw=read -bs=4k -runtime=60 -iodepth 32 -filename /dev/sda -ioengine libaio -direct=1 随机读 fio -name iops -rw=randread -bs=4k -runtime=60 -iodepth 32 -filename /dev/sda -ioengine libaio -direct=1 顺序写 fio -name iops -rw=write -bs=4k -runtime=60 -iodepth 32 -filename /dev/sda -ioengine libaio -direct=1 随机写 fio -name iops -rw=randwrite -bs=4k -runtime=60 -iodepth 32 -filename /dev/sda -ioengine libaio -direct=1
更具体的测试可以参考磁盘性能指标--IOPS、吞吐量及测试
RAID
RAID 0
将数据分布在N块盘中,速度最快,可以享受磁盘的并行读取和写入;安全性最低,一块盘损坏,将导致所有数据丢失。
RAID 1
将数据同时保存在N块盘中,写入速度最慢(需要同时写多块盘)。安全性最高。
RAID 10 ?
将RAID 1 和 RAID 0 结合起来,获得高安全性和高性能。最常用的RAID策略。同时也是TiDB,MySQL等数据库推荐的RAID策略。
RAID 5
RAID 5 最低三块盘,存储数据的异或编码,在一块盘损坏时,可以提供编码恢复出数据。
ElasticSearch 使用低速设备的 Tips
修改index.merge.scheduler.max_thread_count参数为1;该参数影响lucene后台的合并线程数量,默认设置只适合SDD。多个合并线程可能导致io压力过大,触发 (linux 120s timeout)[https://cyberdak.github.io/es/2018/07/01/es-force-merge-cause-es-down].
存储策略
- 避免单机存储过多数据,如果单机故障,将导致集群需要大量数据,影响集群的吞吐量,特别是发生在高峰时候更会影响业务。千兆网卡每小时可以同步的数据为463gb,可以参考这个速度结合资深集群网卡以及存储来调节每个节点存储的数据量。
- 存储有条件使用RAID10,增加单节点性能以及避免单节点存储故障
RAID卡策略
根据服务器RAID卡的等级不同,高级的RAID卡可以使用 write-back 写策略,数据写入会直接写入到缓存中,随后刷新到硬盘上。当主机掉电时,由RAID卡带的电池来保证数据成功写入到硬盘中。write back的设置需要电池有电才能支持,而某些场景可以设置为force write-back(即使电池没电了,也要写缓存),从而提高写入性能。
2018 年 Elastic Advent Calendar 分享活动已结束 ??
Advent • medcl 发表了文章 • 44 个评论 • 10344 次浏览 • 2018-11-20 22:33
- Day 1 - ELK 使用小技巧 - @rochy
- Day 2 - ES 6.x拼音分词高亮爬坑记 - @abia
- Day 3 - kibana二次开发tips - @vv
- Day 4 - PB级规模数据的Elasticsearch分库分表实践 - @ouyangchucai
- Day 5 - es存储设备全解析 - @cyberdak
- Day 6 - 上手 Logstash Pipeline to Pipeline 特性 - @rockybean
- Day 7 - Elasticsearch中数据是如何存储的 - @weizijun
- Day 8 - 如何使用Spark快速将数据写入Elasticsearch - @Ricky Huo
- Day 9 - 动手实现一个自定义beat - @Xinglong
- Day 10 - Elasticsearch 分片恢复并发数过大引发的bug分析 - @howardhuang
- Day 11 - Elasticsearch 5.x 6.x父子关系维护检索实战 - @yinbp
- Day 12 - Elasticsearch日志场景最佳实践 - @ginger
- Day 13 - Elasticsearch-Hadoop打通Elasticsearch和Hadoop - @Jasonbian
- Day 14 - 订单中心基于elasticsearch 的解决方案 - @blogsit
- Day 15 - 基于海量公司分词ES中文分词插件 - @novia
- Day 16 - Elasticsearch性能调优 - @白衬衣
- Day 17 - 关于日志型数据管理策略的思考 - @kennywu76
- Day 18 - 记filebeat内存泄漏问题分析及调优 - @点火三周
- Day 19 - 通过点击反馈优化es搜索结果排序 - @laigood
- Day 20 - Elastic性能实战指南 - @laoyang360
- Day 21 - ECE 版本升级扫雷实战 - @Ben_Wu
- Day 22 - 熟练使用ES离做好搜索还差多远 - @nodexy
- Day 23 - 基于 HanLP 的 ES 中文分词插件 - @rochy
- Day 24 - predator捕捉病毒样本 - @swordsmanli
- Day 25 - Elasticsearch Ingest节点数据管道处理器 - @bindiego
Day 14: Elasticsearch 5 入坑指南
Advent • kennywu76 发表了文章 • 33 个评论 • 30222 次浏览 • 2016-12-15 13:16
Day6:《记一次es性能调优》
Elasticsearch • xiaorui 发表了文章 • 5 个评论 • 14906 次浏览 • 2016-12-13 11:49
Day5: 《PacketBeat奇妙的OOM小记》
Advent • kira8565 发表了文章 • 0 个评论 • 7413 次浏览 • 2016-12-05 23:00
Day4: 《将sql转换为es的DSL》
Advent • Xargin 发表了文章 • 6 个评论 • 38600 次浏览 • 2016-12-04 23:23
select * from x_order where userId = 1 order by id desc limit 10,1;
解析之后会变成golang的一个struct,来看看具体的定义:
&sqlparser.Select{
Comments:sqlparser.Comments(nil),
Distinct:"",
SelectExprs:sqlparser.SelectExprs{(*sqlparser.StarExpr)(0xc42000aee0)},
From:sqlparser.TableExprs{(*sqlparser.AliasedTableExpr)(0xc420016930)},
Where:(*sqlparser.Where)(0xc42000afa0),
GroupBy:sqlparser.GroupBy(nil),
Having:(*sqlparser.Where)(nil),
OrderBy:sqlparser.OrderBy{(*sqlparser.Order)(0xc42000af20)},
Limit:(*sqlparser.Limit)(0xc42000af80),
Lock:""
}type Order struct {
Expr ValExpr
Direction string
}\type Limit struct {
Offset, Rowcount ValExpr
}&sqlparser.Where{
Type:"where",
Expr:(*sqlparser.ComparisonExpr)(0xc420016a50)
}select * from users where user_id = 1 and product_id =2
=>
&sqlparser.Where{
Type:"where",
Expr:(*sqlparser.AndExpr)(0xc42000b020)
}
AndExpr有Left和Right两个成员,分别是:
Left:
&sqlparser.ComparisonExpr{
Operator:"=",
Left:(*sqlparser.ColName)(0xc4200709c0),
Right:sqlparser.NumVal{0x31}
}
Right:
&sqlparser.ComparisonExpr{
Operator:"=",
Left:(*sqlparser.ColName)(0xc420070a50),
Right:sqlparser.NumVal{0x32}
}a and (b and (c or d) and e)
=>
select * from user_history where user_id = 1 and (product_id = 2 and (star_num = 4 or star_num = 5) and banned = 1)
query {
boolmust {
a,
boolmust {
b,
c
}
}
}query {
boolmust {
a,
boolmust {
b,
boolshould {
c,
d
},
e
}
}
}AndExpr => bool must [{left}, {right}]
OrExpr => bool should [{left}, {right}]
ComparisonExpr => 一般是叶子节点
ParenBoolExpr => 指代括号表达式,其实内部是上述三种节点的某一种,所以直接取出内部节点按上述方法来处理Day3: 《创建一个你自己的 Beat》
Advent • medcl 发表了文章 • 0 个评论 • 10302 次浏览 • 2016-12-03 22:19
package main
import (
"fmt"
"io/ioutil"
"os"
)
func main() {
//apply run path "." without argument.
if len(os.Args) == 1 {
listDir(".")
} else {
listDir(os.Args[1])
}
}
func listDir(dirFile string) {
files, _ := ioutil.ReadDir(dirFile)
for _, f := range files {
t := f.ModTime()
fmt.Println(f.Name(), dirFile+"/"+f.Name(), f.IsDir(), t, f.Size())
if f.IsDir() {
listDir(dirFile + "/" + f.Name())
}
}
}$ go get github.com/elastic/beats$ cd $GOPATH/src/github.com/{user}
$ cookiecutter $GOPATH/src/github.com/elastic/beats/generate/beatproject_name [Examplebeat]: lsbeat
github_name [your-github-name]: {username}
beat [lsbeat]:
beat_path [github.com/{github id}]:
full_name [Firstname Lastname]: {Full Name}$ cd lsbeat
$ tree
.
├── CONTRIBUTING.md
├── LICENSE
├── Makefile
├── README.md
├── beater
│ └── lsbeat.go
├── config
│ ├── config.go
│ └── config_test.go
├── dev-tools
│ └── packer
│ ├── Makefile
│ ├── beats
│ │ └── lsbeat.yml
│ └── version.yml
├── docs
│ └── index.asciidoc
├── etc
│ ├── beat.yml
│ └── fields.yml
├── glide.yaml
├── lsbeat.template.json
├── main.go
├── main_test.go
└── tests
└── system
├── config
│ └── lsbeat.yml.j2
├── lsbeat.py
├── requirements.txt
└── test_base.py$ make setup$ git remote add origin git@github.com:{username}/lsbeat.git
$ git push -u origin masterlsbeat.yml
lsbeat:
# Defines how often an event is sent to the output
period: 1slsbeat:
# Defines how often an event is sent to the output
period: 10s
path: "."$ make update
$ cat lsbeat.yml
################### Lsbeat Configuration Example #########################
############################# Lsbeat ######################################
lsbeat:
# Defines how often an event is sent to the output
period: 10s
path: "."
###############################################################################package config
import "time"
type Config struct {
Period time.Duration `config:"period"`
Path string `config:"path"`
}
var DefaultConfig = Config{
Period: 10 * time.Second,
Path: ".",
}type Lsbeat struct {
done chan struct{}
config config.Config
client publisher.Client
lastIndexTime time.Time
...
}func New(b *beat.Beat, cfg *common.Config) (beat.Beater, error) {
config := config.DefaultConfig
if err := cfg.Unpack(&config); err != nil {
return nil, fmt.Errorf("Error reading config file: %v", err)
}
ls := &Lsbeat{
done: make(chan struct{}),
config: config,
}
return ls, nil
}"@timestamp": common.Time(time.Now()),
"type": beatname,
"modtime": common.Time(t),
"filename": f.Name(),
"path": dirFile + "/" + f.Name(),
"directory": f.IsDir(),
"filesize": f.Size(),func (bt *Lsbeat) listDir(dirFile string, beatname string, init bool) {
files, _ := ioutil.ReadDir(dirFile)
for _, f := range files {
t := f.ModTime()
event := common.MapStr{
"@timestamp": common.Time(time.Now()),
"type": beatname,
"modtime": common.Time(t),
"filename": f.Name(),
"path": dirFile + "/" + f.Name(),
"directory": f.IsDir(),
"filesize": f.Size(),
}
if init {
// index all files and directories on init
bt.client.PublishEvent(event)
} else {
// Index only changed files since last run.
if t.After(bt.lastIndexTime) {
bt.client.PublishEvent(event)
}
}
if f.IsDir() {
bt.listDir(dirFile+"/"+f.Name(), beatname, init)
}
}
}import (
"fmt"
"io/ioutil"
"time"
)func (bt *Lsbeat) Run(b *beat.Beat) error {
logp.Info("lsbeat is running! Hit CTRL-C to stop it.")
bt.client = b.Publisher.Connect()
ticker := time.NewTicker(bt.config.Period)
counter := 1
for {
select {
case <-bt.done:
return nil
case <-ticker.C:
}
bt.listDir(bt.config.Path, b.Name, true) // call lsDir
bt.lastIndexTime = time.Now() // mark Timestamp
logp.Info("Event sent")
counter++
}
}func (bt *Lsbeat) Stop() {
bt.client.Close()
close(bt.done)
}- key: lsbeat
title: LS Beat
description:
fields:
- name: counter
type: integer
required: true
description: >
PLEASE UPDATE DOCUMENTATION
#new fiels added lsbeat
- name: modtime
type: date
- name: filename
type: text
- name: path
- name: directory
type: boolean
- name: filesize
type: long
{
"mappings": {
...
},
"order": 0,
"settings": {
"index.refresh_interval": "5s",
"analysis": {
"analyzer": {
"ls_ngram_analyzer": {
"tokenizer": "ls_ngram_tokenizer"
}
},
"tokenizer": {
"ls_ngram_tokenizer": {
"type": "ngram",
"min_gram": "2",
"token_chars": [
"letter",
"digit"
]
}
}
}
},
"template": "lsbeat-*"
}
lsbeat:
# Defines how often an event is sent to the output
period: 10s
path: "/Users/ec2-user/go"Day2:《Kibana 系漫游指南》
Advent • 三斗室 发表了文章 • 6 个评论 • 12592 次浏览 • 2016-12-02 22:48
- app
- visTypes
- spyModes
- fieldFormatter
2. vectormap
这是一个 visType 插件,也就是我们在 Kibana3 里曾经用过的 map panel 效果。这个插件不被官方直接采用的一个原因是版权许可问题。不做商用的情况下,这个插件还是可以极大方便我们做行政区域的访问情况统计和展示的。
3. kbn_network
这也是一个 visType 插件,酷毙了的网状图效果!通过不同的 aggs 数据展示 node 和 relational。
注意这个跟 Elastic 的 graph 并不是完全一致的东西。该插件要求你本身的数据已经有直接的关联可用。
4. sentinl
这是一个同时带有 spyMode 和 app 双插件的项目。其基础思路是参照 Elastic 的 Watcher 接口,但是将监控告警的进程从 ES 挪到 Kibana 里。同时还可以通过 phantomjs 做到截图报表。
Day1: 大规模Elasticsearch集群管理心得
Advent • kennywu76 发表了文章 • 83 个评论 • 52553 次浏览 • 2016-12-02 10:07
- 单日索引数据条数600亿,新增索引文件25TB (含一个复制片则为50TB)
- 业务高峰期峰值索引速率维持在百万条/秒
- 历史数据保留时长根据业务需求制定,从10天 - 90天不等
- 集群共3441个索引、17000个分片、数据总量约9300亿, 磁盘总消耗1PB
- Kibana用户600多人, 每日来自Kibana和第三方的API调用共63万次
- 查询响应时间百分位 75%:0.160s 90%:1.640s 95%:6.691s 99%:14.0039s
- 首先很有必要对ES的结点做角色划分和隔离。大家知道ES的data node除了放数据以外,也可以兼任master和client的角色,多数同学会将这些角色混入到data node。然而对于一个规模较大,用户较多的集群,master和client在一些极端使用情况下可能会有性能瓶颈甚至内存溢出,从而使得共存的data node故障。data node的故障恢复涉及到数据的迁移,对集群资源有一定消耗,容易造成数据写入延迟或者查询减慢。如果将master和client独立出来,一旦出现问题,重启后几乎是瞬间就恢复的,对用户几乎没有任何影响。另外将这些角色独立出来的以后,也将对应的计算资源消耗从data node剥离出来,更容易掌握data node资源消耗与写入量和查询量之间的联系,便于做容量管理和规划。
- 避免过高的并发,包括控制shard数量和threadpool的数量。在写入量和查询性能能够满足的前提下,为索引分配尽量少的分片。分片过多会带来诸多负面影响,例如:每次查询后需要汇总排序的数据更多;过多的并发带来的线程切换造成过多的CPU损耗;索引的删除和配置更新更慢Issue#18776; 过多的shard也带来更多小的segment,而过多的小segment会带来非常显著的heap内存消耗,特别是如果查询线程配置得很多的情况下。 配置过大的threadpool更是会产生很多诡异的性能问题Issue#18161里所描述的问题就是我们所经历过的。 默认的Theadpool大小一般来说工作得很不错了。
- 冷热数据最好做分离。对于日志型应用来说,一般是每天建立一个新索引,当天的热索引在写入的同时也会有较多的查询。如果上面还存有比较长时间之前的冷数据,那么当用户做大跨度的历史数据查询的时候,过多的磁盘IO和CPU消耗很容易拖慢写入,造成数据的延迟。所以我们用了一部分机器来做冷数据的存储,利用ES可以给结点配置自定义属性的功能,为冷结点加上"boxtype":"weak"的标识,每晚通过维护脚本更新冷数据的索引路由设置index.routing.allocation.{require|include|exclude},让数据自动向冷结点迁移。 冷数据的特性是不再写入,用户查的频率较低,但量级可能很大。比如我们有个索引每天2TB,并且用户要求保持过去90天数据随时可查。保持这么大量的索引为open状态,并非只消耗磁盘空间。ES为了快速访问磁盘上的索引文件,需要在内存里驻留一些数据(索引文件的索引),也就是所谓的segment memory。稍微熟悉ES的同学知道,JVM heap分配不能超过32GB,对于我们128GB RAM, 48TB磁盘空间的机器而言,如果只跑一个ES实例,只能利用到32GB不到的heap,当heap快用饱和的时候,磁盘上保存的索引文件还不到10TB,这样显然是不经济的。 因此我们决定在冷结点上跑3个ES实例,每个分配31GB heap空间,从而可以在一台物理服务器上存储30多TB的索引数据并保持open状态,供用户随时搜索。 实际使用下来,由于冷数据搜索频率不高,也没有写入,即时只剩余35GB内存给os做文件系统缓存,查询性能还是可以满足需求的。
- 不同数据量级的shard最好隔离到不同组别的结点。 大家知道ES会自己平衡shard在集群的分布,这个自动平衡的逻辑主要考量三个因素。其一同一索引下的shard尽量分散到不同的结点;其二每个结点上的shard数量尽量接近;其三结点的磁盘有足够的剩余空间。这个策略只能保证shard数量分布均匀,而并不能保证数据大小分布均匀。 实际应用中,我们有200多种索引,数据量级差别很大,大的一天几个TB,小的一个月才几个GB,并且每种类型的数据保留时长又千差万别。抛出的问题,就是如何能比较平衡并充分的利用所有节点的资源。 针对这个问题,我们还是通过对结点添加属性标签来做分组,结合index routing控制的方式来做一些精细化的控制。尽量让不同量级的数据使用不同组别的结点,使得每个组内结点上的数据量比较容易自动平衡。
- 定期做索引的force merge,并且最好是每个shard merge成一个segment。前面提到过,heap消耗与segment数量也有关系,force merge可以显著降低这种消耗。 如果merge成一个segment还有一个好处,就是对于terms aggregation,搜索时无需构造Global Ordinals,可以提升聚合速度。
- 结点启动的Bootstrap过程加入了很多关键系统参数设置的核验,比如Max File Descriptors, Memory Lock, Virtual Memory设置等等,如果设置不正确会拒绝启动并抛出异常。 与其带着错误的系统参数启动,并在日后造成性能问题,不如启动失败告知用户问题,是个很好的设计!
- 索引性能提升。升级后在同样索引速率下,我们看到cpu消耗下降非常明显,除了对索引速率提升有帮助,也会一定程度提升搜索速率。
- 新的数值型数据结构,存储空间更小,Range和地理位置计算更快速
- Instant Aggregation对于类似now-7d to now这样的范围查询聚合能够做cache了,实际使用下来,效果明显,用户在Kibana上跑个过去一周数据的聚合,头2次刷新慢点,之后有cache了几乎就瞬间刷出!
- 更多的保护措施保证集群的稳定,比如对一次搜索hit的shard数量做了限制,增强了circuit breaker的特性,更好的防护集群资源被坏查询耗尽。
- 各类Thread pool的使用情况,active/queue/reject可视化出来。 判断集群是否有性能瓶颈了,看看业务高峰期各类queue是不是很高,reject是不是经常发生,基本可以做到心里有数。
- JVM的heap used%以及old GC的频率,如果old GC频率很高,并且多次GC过后heap used%几乎下不来,说明heap压力太大,要考虑扩容了。(也有可能是有问题的查询或者聚合造成的,需要结合用户访问记录来判断)。
- Segment memory大小和Segment的数量。节点上存放的索引较多的时候,这两个指标就值得关注,要知道segment memory是常驻heap不会被GC回收的,因此当heap压力太大的时候,可以结合这个指标判断是否是因为节点上存放的数据过多,需要扩容。Segement的数量也是比较关键的,如果小的segment非常多,比如有几千,即使segment memory本身不多,但是在搜索线程很多的情况下,依然会吃掉相当多的heap,原因是lucene为每个segment会在thread local里记录状态信息,这块的heap内存开销和(segment数量* thread数量)相关。
- 很有必要记录用户的访问记录。我们只开放了http api给用户,前置了一个nginx做http代理,将用户第三方api的访问记录通过access log全部记录下来。通过分析访问记录,可以在集群出现性能问题时,快速找到问题根源,对于问题排查和性能优化都很有帮助。
Elastic Advent Calendar 活动启动咯!
Advent • medcl 发表了文章 • 11 个评论 • 8927 次浏览 • 2016-11-04 13:46
Day24: Elasticsearch添加Shield后TransportClient如何连接?
Advent • medcl 发表了文章 • 6 个评论 • 9693 次浏览 • 2015-12-28 12:13

