

目前ES 查询很慢。
index 按月建立,index 大小不统一,最大的有200G,最少的20M,所有index联合查询。查询并聚合,20多秒。 单个节点的配置在下图。各位大佬有什么建议吗
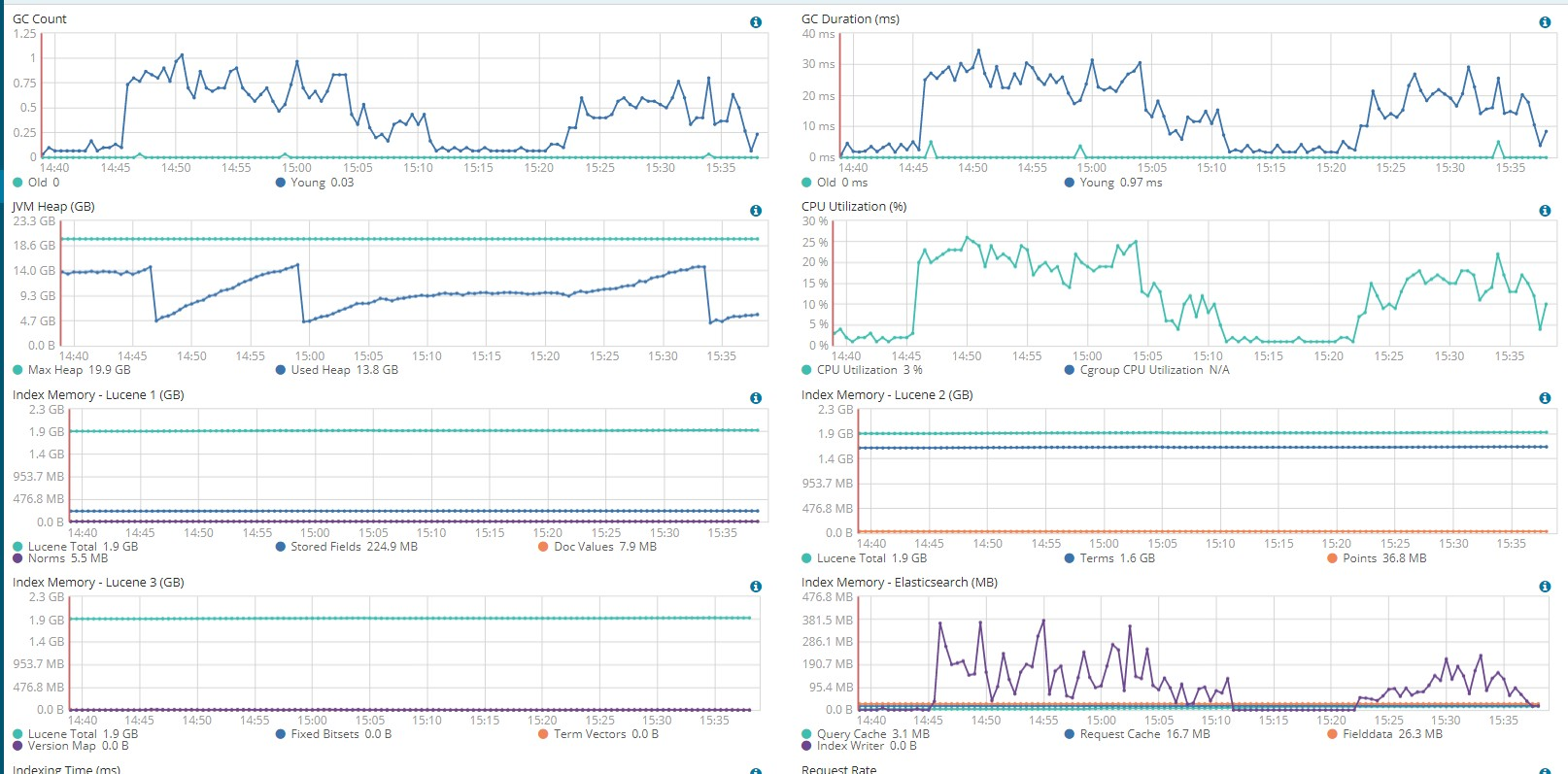
index 按月建立,index 大小不统一,最大的有200G,最少的20M,所有index联合查询。查询并聚合,20多秒。 单个节点的配置在下图。各位大佬有什么建议吗

2 个回复
rochy - rochy_he
赞同来自:
否则不清楚是查询慢还是聚合慢
其次,是全部查询都很慢,还是部分查询慢;
如果是部分查询慢,也有可能是查询语句的问题
Vbeifeng
赞同来自:
如果根据市或者省份去查询 的话返回的document 会有1千万条数据。返回document 条数多的话查询会变慢,不同的查询条件下做聚合也是时间长短不一致。
这个是语句:
{"size": 0,
"query": {
"term": {
"province.keyword": {
"value": "北京"
}
}
},,"aggs": {
"al": {
"sum": {
"field": "sell"
}
},"sales":{
"sum": {
"field": "sales"
}
}
}
}