

类似于mysql select * from table where field in ('', '') 只是这个In的有点多,查询前10条数据,就非常慢,field字段类型是keyword.
对mysql 的理解,如果我查到了数据应该就立即返回的;elasticsearch 貌似不是这样处理的,查看了下profile 对于in 查询,每个In的结果都进行了一次termQury,不晓得是不是这个导致了查询速度慢
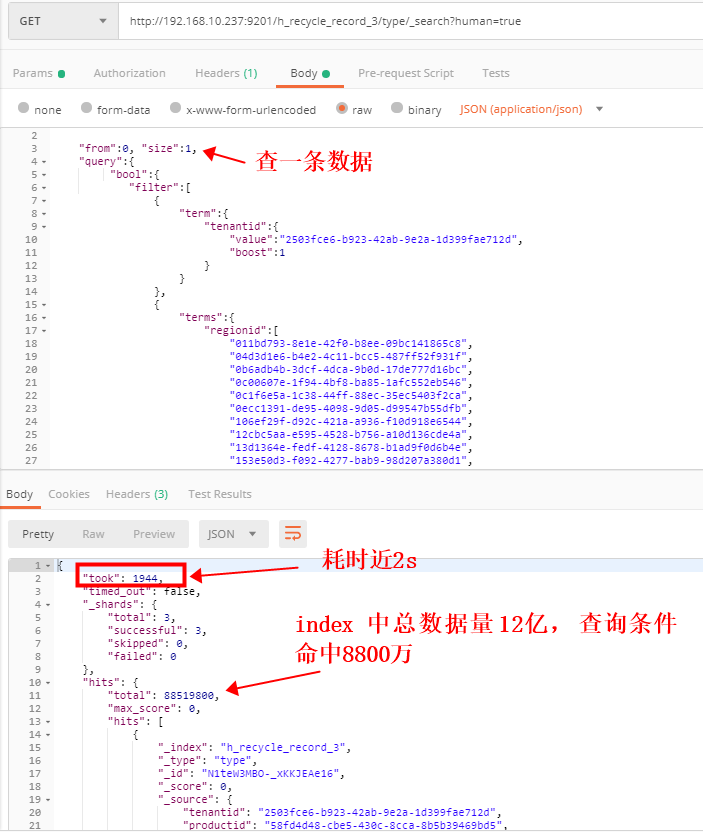
对mysql 的理解,如果我查到了数据应该就立即返回的;elasticsearch 貌似不是这样处理的,查看了下profile 对于in 查询,每个In的结果都进行了一次termQury,不晓得是不是这个导致了查询速度慢

5 个回复
Ombres
赞同来自: kr9226
lucene系基本都存在这个问题,关键词非常多的情况下,查询性能可能会急剧下降,因此在lucene中默认限制子句的长度为1024
acaidemao - 阿菜的猫
赞同来自:
FFFrp
赞同来自:
byx313 - BLOG:https://www.jianshu.com/u/43fd06f9589c
赞同来自:
JiangJibo - 喊我雷锋
赞同来自:
但是es的倒排索引默认是hash结构,也就是根据term的hash值来定位索引,所以默认是没有顺序的,所以理论上是需要命中所有的doc然后做一个筛选,最后排序,排序根据tf-idf原则需要找出那个term的权重最高,也就是出现term频率最低的那个term,如果命中数实在太多那么聚合筛选排序的耗费就越高。但具体要怎么聚合筛选,没看源码,等看了明白了在说说。
这是我对mysql 和 es 的in的机制的理解,说的不对见谅