

极限科技(INFINI Labs)招聘搜索运维工程师(Elasticsearch/Easysearch)

极限科技诚招全职搜索运维工程师(Elasticsearch/Easysearch)!
欢迎搜索技术热爱者加入我们,共同打造高效、智能的搜索解决方案!
在招岗位介绍
岗位名称
搜索运维工程师(Elasticsearch/Easysearch)
Base:北京/西安
薪资待遇:10-15K,五险一金,双休等
岗位职责
- 负责客户现场的 Elasticsearch/Easysearch/OpenSearch 搜索引擎集群的日常维护、监控和优化,确保集群的高可用性和性能稳定;
- 协助客户进行搜索引擎集群的部署、配置及版本升级;
- 排查和解决 Elasticsearch/Easysearch/OpenSearch 集群中的各种技术问题,及时响应并处理集群异常;
- 根据业务需求设计和实施搜索索引的调优、数据迁移和扩展方案;
- 负责与客户沟通,提供技术支持及相关培训,确保客户需求得到有效满足;
- 制定并实施搜索引擎的备份、恢复和安全策略,保障数据安全;
- 与内部研发团队和外部客户进行协作,推动集群性能改进和功能优化。
岗位要求
- 全日制本科及以上学历,2 年以上运维工作经验;
- 拥有 Elasticsearch/Easysearch/OpenSearch 使用经验,熟悉搜索引擎的原理、架构和相关生态工具(如 Logstash、Kibana 等);
- 熟悉 Linux 操作系统的使用及常见性能调优方法;
- 熟练掌握 Shell 或 Python 等至少一种脚本语言,能够编写自动化运维脚本;
- 具有优秀的问题分析与解决能力,能够快速应对突发情况;
- 具备良好的沟通能力和团队合作精神,能够接受客户驻场工作;
- 提供 五险一金,享有带薪年假及法定节假日。
加分项
- 计算机科学、信息技术或相关专业;
- 具备丰富的大规模分布式系统运维经验;
- 熟悉 Elasticsearch/Easysearch/OpenSearch 分片、路由、查询优化等高级功能;
- 拥有 Elastic Certified Engineer 认证;
- 具备大规模搜索引擎集群设计、扩展和调优经验;
- 熟悉其他搜索引擎技术(如 Solr、Lucene)者优先;
- 熟悉大数据处理相关技术(比如: Kafka 、Flink 等)者优先。
简历投递
- 邮件:hello@infini.ltd(邮件标题请备注姓名+求职岗位)
- 微信:INFINI-Labs (加微请备注求职岗位)

关于极限科技(INFINI Labs)

极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
我们在做什么
极限科技(INFINI Labs)正在致力于以下几个核心方向:
1、开发近实时搜索引擎 INFINI Easysearch
INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。详情参见:https://infinilabs.cn
2、打造下一代实时搜索引擎 INFINI Pizza
INFINI Pizza 是一个分布式混合搜索数据库系统。我们的使命是充分利用现代硬件和人工智能的潜力,为企业提供量身定制的实时智能搜索体验。我们致力于满足具有挑战性的环境中高并发和高吞吐量的需求,同时提供无缝高效的搜索功能。详情参见:https://pizza.rs
3、为现代团队打造的统一搜索与 AI 智能助手 Coco AI
Coco AI 是一款完全开源的统一搜索与 AI 助手平台,它通过统一搜索入口,连接企业内外部的异构数据源,融合大模型能力,帮助团队高效访问知识,智能决策协作。详情参见:https://coco.rs
4、积极参与全球开源生态建设
通过开源 Coco AI、Console、Gateway、Agent、Loadgen 等搜索领域产品和社区贡献,推动全球开源技术的发展,提升中国在全球开源领域的影响力。INFINI Labs Github 主页:https://github.com/infinilabs
5、提供专业服务
为客户提供包括搜索技术支持、迁移服务、定制解决方案和培训在内的全方位服务。
6、提供国产化搜索解决方案
针对中国市场的特殊需求,提供符合国产化标准的搜索产品和解决方案,帮助客户解决使用 Elasticsearch 时遇到的挑战。
极限科技(INFINI Labs)通过这些努力,旨在成为全球领先的实时搜索和数据分析解决方案提供商。
极限科技诚招全职搜索运维工程师(Elasticsearch/Easysearch)!
欢迎搜索技术热爱者加入我们,共同打造高效、智能的搜索解决方案!
在招岗位介绍
岗位名称
搜索运维工程师(Elasticsearch/Easysearch)
Base:北京/西安
薪资待遇:10-15K,五险一金,双休等
岗位职责
- 负责客户现场的 Elasticsearch/Easysearch/OpenSearch 搜索引擎集群的日常维护、监控和优化,确保集群的高可用性和性能稳定;
- 协助客户进行搜索引擎集群的部署、配置及版本升级;
- 排查和解决 Elasticsearch/Easysearch/OpenSearch 集群中的各种技术问题,及时响应并处理集群异常;
- 根据业务需求设计和实施搜索索引的调优、数据迁移和扩展方案;
- 负责与客户沟通,提供技术支持及相关培训,确保客户需求得到有效满足;
- 制定并实施搜索引擎的备份、恢复和安全策略,保障数据安全;
- 与内部研发团队和外部客户进行协作,推动集群性能改进和功能优化。
岗位要求
- 全日制本科及以上学历,2 年以上运维工作经验;
- 拥有 Elasticsearch/Easysearch/OpenSearch 使用经验,熟悉搜索引擎的原理、架构和相关生态工具(如 Logstash、Kibana 等);
- 熟悉 Linux 操作系统的使用及常见性能调优方法;
- 熟练掌握 Shell 或 Python 等至少一种脚本语言,能够编写自动化运维脚本;
- 具有优秀的问题分析与解决能力,能够快速应对突发情况;
- 具备良好的沟通能力和团队合作精神,能够接受客户驻场工作;
- 提供 五险一金,享有带薪年假及法定节假日。
加分项
- 计算机科学、信息技术或相关专业;
- 具备丰富的大规模分布式系统运维经验;
- 熟悉 Elasticsearch/Easysearch/OpenSearch 分片、路由、查询优化等高级功能;
- 拥有 Elastic Certified Engineer 认证;
- 具备大规模搜索引擎集群设计、扩展和调优经验;
- 熟悉其他搜索引擎技术(如 Solr、Lucene)者优先;
- 熟悉大数据处理相关技术(比如: Kafka 、Flink 等)者优先。
简历投递
- 邮件:hello@infini.ltd(邮件标题请备注姓名+求职岗位)
- 微信:INFINI-Labs (加微请备注求职岗位)
关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
我们在做什么
极限科技(INFINI Labs)正在致力于以下几个核心方向:
1、开发近实时搜索引擎 INFINI Easysearch
INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。详情参见:https://infinilabs.cn
2、打造下一代实时搜索引擎 INFINI Pizza
INFINI Pizza 是一个分布式混合搜索数据库系统。我们的使命是充分利用现代硬件和人工智能的潜力,为企业提供量身定制的实时智能搜索体验。我们致力于满足具有挑战性的环境中高并发和高吞吐量的需求,同时提供无缝高效的搜索功能。详情参见:https://pizza.rs
3、为现代团队打造的统一搜索与 AI 智能助手 Coco AI
Coco AI 是一款完全开源的统一搜索与 AI 助手平台,它通过统一搜索入口,连接企业内外部的异构数据源,融合大模型能力,帮助团队高效访问知识,智能决策协作。详情参见:https://coco.rs
4、积极参与全球开源生态建设
通过开源 Coco AI、Console、Gateway、Agent、Loadgen 等搜索领域产品和社区贡献,推动全球开源技术的发展,提升中国在全球开源领域的影响力。INFINI Labs Github 主页:https://github.com/infinilabs
5、提供专业服务
为客户提供包括搜索技术支持、迁移服务、定制解决方案和培训在内的全方位服务。
6、提供国产化搜索解决方案
针对中国市场的特殊需求,提供符合国产化标准的搜索产品和解决方案,帮助客户解决使用 Elasticsearch 时遇到的挑战。
极限科技(INFINI Labs)通过这些努力,旨在成为全球领先的实时搜索和数据分析解决方案提供商。
收起阅读 »【搜索客社区日报】第2093期 (2025-08-12)
https://medium.com/%40CyberRay ... 95361
2. 让老司机教你怎么优雅的处理实时流式数据(需要梯子)
https://blog.dataengineerthing ... 575be
3. 多字段检索会是版本答案吗?(需要梯子)
https://medium.com/%40shekdivy ... 6c0b5
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
https://medium.com/%40CyberRay ... 95361
2. 让老司机教你怎么优雅的处理实时流式数据(需要梯子)
https://blog.dataengineerthing ... 575be
3. 多字段检索会是版本答案吗?(需要梯子)
https://medium.com/%40shekdivy ... 6c0b5
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
收起阅读 »
【搜索客社区日报】第2092期 (2025-08-11)
https://elasticstack.blog.csdn ... 46713
2、什么是 Model Context Protocol ( MCP )?
https://elasticstack.blog.csdn ... 48028
3、利用 Elastic API 实现自定义 AI 驱动的 SOAR
https://elasticstack.blog.csdn ... 57262
4、如何显示一个 Elasticsearch 索引的字段
https://elasticstack.blog.csdn ... 98378
5、无服务器日志分析由 Elasticsearch 提供支持,推出新的低价层
https://elasticstack.blog.csdn ... 52057
编辑:Muse
更多资讯:http://news.searchkit.cn
https://elasticstack.blog.csdn ... 46713
2、什么是 Model Context Protocol ( MCP )?
https://elasticstack.blog.csdn ... 48028
3、利用 Elastic API 实现自定义 AI 驱动的 SOAR
https://elasticstack.blog.csdn ... 57262
4、如何显示一个 Elasticsearch 索引的字段
https://elasticstack.blog.csdn ... 98378
5、无服务器日志分析由 Elasticsearch 提供支持,推出新的低价层
https://elasticstack.blog.csdn ... 52057
编辑:Muse
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2091期 (2025-08-08)
https://www.oschina.net/news/364960/openai-gpt-5
2、Easysearch 集成阿里云与 Ollama Embedding API,构建端到端的语义搜索系统
https://searchkit.cn/article/15520
3、ES 调优帖:Gateway 批量写入性能优化实践
https://infinilabs.cn/blog/202 ... tion/
4、Context Engineering: 基于 OceanBase 的代码文档检索引擎
https://mp.weixin.qq.com/s/GPK_U7rc1PHUhcx5Ipnx6A
5、得物向量数据库落地实践
https://my.oschina.net/u/5783135/blog/18686778
编辑:Fred
更多资讯:http://news.searchkit.cn
https://www.oschina.net/news/364960/openai-gpt-5
2、Easysearch 集成阿里云与 Ollama Embedding API,构建端到端的语义搜索系统
https://searchkit.cn/article/15520
3、ES 调优帖:Gateway 批量写入性能优化实践
https://infinilabs.cn/blog/202 ... tion/
4、Context Engineering: 基于 OceanBase 的代码文档检索引擎
https://mp.weixin.qq.com/s/GPK_U7rc1PHUhcx5Ipnx6A
5、得物向量数据库落地实践
https://my.oschina.net/u/5783135/blog/18686778
编辑:Fred
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2090期 (2025-08-07)
https://mp.weixin.qq.com/s/7n8OYNrCC_I9SJaybHA_-Q
2.告别文字乱码!全新文生图模型Qwen-Image来咯
https://mp.weixin.qq.com/s/CdLk_CwFk5Ui-JAvHV9-8Q
3.理解 AI on K8S
https://mp.weixin.qq.com/s/PHVfC3hPgTz6nUR7OUic_g
4.AIBrix v0.4.0 版本发布:支持 P/D 分离与专家并行、KVCache v1 连接器、KV 事件同步及多引擎支持
https://aibrix.github.io/posts ... ease/
编辑:Se7en
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/7n8OYNrCC_I9SJaybHA_-Q
2.告别文字乱码!全新文生图模型Qwen-Image来咯
https://mp.weixin.qq.com/s/CdLk_CwFk5Ui-JAvHV9-8Q
3.理解 AI on K8S
https://mp.weixin.qq.com/s/PHVfC3hPgTz6nUR7OUic_g
4.AIBrix v0.4.0 版本发布:支持 P/D 分离与专家并行、KVCache v1 连接器、KV 事件同步及多引擎支持
https://aibrix.github.io/posts ... ease/
编辑:Se7en
更多资讯:http://news.searchkit.cn 收起阅读 »
喜报!极限科技 Coco AI 荣获 2025 首届人工智能应用创新大赛全国一等奖
由中国技术经济学会主办的 2025 首届全国人工智能应用创新大赛 总决赛于 6 月 22 日在湖南大学圆满落幕。该赛事以“场景驱动・创新创业”为主题,旨在考察参赛选手设计 AI 智能体(AI Agent)、应用人工智能大模型技术解决实际问题的能力。本届大赛吸引了全国 632 所高校及 210 家企业的 4913 支团队参赛,经过层层选拔,最终 689 支团队晋级全国总决赛。

在激烈的竞争中,极限数据(北京)科技有限公司 Coco AI 团队凭借作品《Coco AI - 为现代团队打造的统一搜索与 AI 智能助手》,一路过关斩将,成功晋级全国总决赛,并在总决赛中脱颖而出,荣获一等奖。这一成绩的取得,不仅是对极限科技技术实力和创新能力的高度认可,更是对 Coco AI 产品价值的有力证明。

Coco AI 产品以“让搜索更简单”为使命,通过先进的 AI 技术,为现代团队提供高效、智能的统一搜索解决方案。在大赛中,Coco AI 团队凭借其扎实的技术功底、创新的解决方案以及出色的现场表现,赢得了评委和观众的一致好评。

此次获奖,是极限科技在人工智能领域取得的又一重要成果。我们将以此为契机,在人工智能快速发展的大背景下,持续优化 Coco AI 产品,不断提升其性能和用户体验。未来,极限科技将继续加大在人工智能领域的研发投入,助力企业释放数据价值,推动智能化搜索迈向新的未来。
关于 Coco AI
Coco AI 是一款完全开源的统一搜索与 AI 助手平台,专为现代企业设计。它通过统一搜索入口,连接企业内外部的异构数据源,融合大模型能力,帮助团队高效访问知识,智能决策协作。
针对企业数据“分散、敏感、难利用”的三大痛点,Coco AI 提供了全面解决方案:
-
统一搜索入口,连接所有数据源
支持集成 S3、Notion、Google Workspace、语雀、GitHub 等,实现跨平台聚合搜索,打破信息孤岛。
-
开源可私有部署,保障数据安全
平台完全开源,支持本地部署与离线运行,数据不出企业,满足高安全与合规要求。
-
融合大模型能力,激活沉睡数据
支持接入多种主流大模型,实现自然语言问答、语义理解与智能推荐,为个人和组织构建个性化知识图谱。
-
模块化扩展,灵活接入外部工具
通过 MCP 架构,模型可动态调用外部能力,无需修改平台代码,轻松适配多样业务场景。
Coco AI,助力企业构建智能知识中枢,释放数据价值,优化决策与协作流程。
官网:https://coco.rs
GitHub:https://github.com/infinilabs/coco-app
关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
由中国技术经济学会主办的 2025 首届全国人工智能应用创新大赛 总决赛于 6 月 22 日在湖南大学圆满落幕。该赛事以“场景驱动・创新创业”为主题,旨在考察参赛选手设计 AI 智能体(AI Agent)、应用人工智能大模型技术解决实际问题的能力。本届大赛吸引了全国 632 所高校及 210 家企业的 4913 支团队参赛,经过层层选拔,最终 689 支团队晋级全国总决赛。
在激烈的竞争中,极限数据(北京)科技有限公司 Coco AI 团队凭借作品《Coco AI - 为现代团队打造的统一搜索与 AI 智能助手》,一路过关斩将,成功晋级全国总决赛,并在总决赛中脱颖而出,荣获一等奖。这一成绩的取得,不仅是对极限科技技术实力和创新能力的高度认可,更是对 Coco AI 产品价值的有力证明。
Coco AI 产品以“让搜索更简单”为使命,通过先进的 AI 技术,为现代团队提供高效、智能的统一搜索解决方案。在大赛中,Coco AI 团队凭借其扎实的技术功底、创新的解决方案以及出色的现场表现,赢得了评委和观众的一致好评。
此次获奖,是极限科技在人工智能领域取得的又一重要成果。我们将以此为契机,在人工智能快速发展的大背景下,持续优化 Coco AI 产品,不断提升其性能和用户体验。未来,极限科技将继续加大在人工智能领域的研发投入,助力企业释放数据价值,推动智能化搜索迈向新的未来。
关于 Coco AI
Coco AI 是一款完全开源的统一搜索与 AI 助手平台,专为现代企业设计。它通过统一搜索入口,连接企业内外部的异构数据源,融合大模型能力,帮助团队高效访问知识,智能决策协作。
针对企业数据“分散、敏感、难利用”的三大痛点,Coco AI 提供了全面解决方案:
-
统一搜索入口,连接所有数据源
支持集成 S3、Notion、Google Workspace、语雀、GitHub 等,实现跨平台聚合搜索,打破信息孤岛。
-
开源可私有部署,保障数据安全
平台完全开源,支持本地部署与离线运行,数据不出企业,满足高安全与合规要求。
-
融合大模型能力,激活沉睡数据
支持接入多种主流大模型,实现自然语言问答、语义理解与智能推荐,为个人和组织构建个性化知识图谱。
-
模块化扩展,灵活接入外部工具
通过 MCP 架构,模型可动态调用外部能力,无需修改平台代码,轻松适配多样业务场景。
Coco AI,助力企业构建智能知识中枢,释放数据价值,优化决策与协作流程。
官网:https://coco.rs
GitHub:https://github.com/infinilabs/coco-app
关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
收起阅读 »ES 调优帖:Gateway 批量写入性能优化实践
背景:bulk 优化的应用
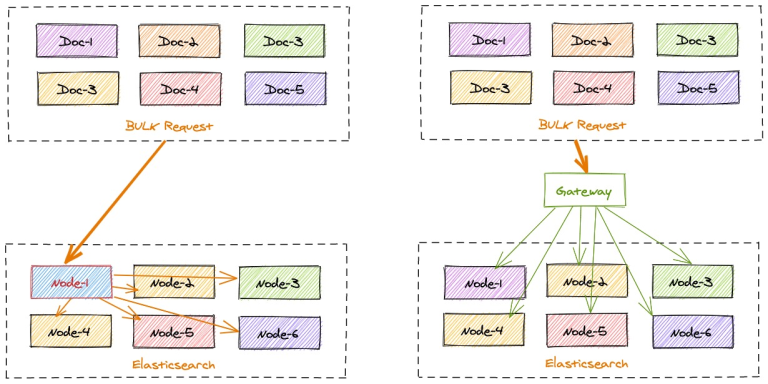
在 ES 的写入优化里,bulk 操作被广泛地用于批量处理数据。bulk 操作允许用户一次提交多个数据操作,如索引、更新、删除等,从而提高数据处理效率。bulk 操作的实现原理是,将数据操作请求打包成 HTTP 请求,并批量提交给 Elasticsearch 服务器。这样,Elasticsearch 服务器就可以一次处理多个数据操作,从而提高处理效率。
这种优化的核心价值在于减少了网络往返的次数和连接建立的开销。每一次单独的写入操作都需要经历完整的请求-响应周期,而批量写入则是将多个操作打包在一起,用一次通信完成原本需要多次交互的工作。这不仅仅节省了时间,更重要的是释放了系统资源,让服务器能够专注于真正的数据处理,而不是频繁的协议握手和状态维护。
这样的批量请求的确是可以优化写入请求的效率,让 ES 集群获得更多的资源去做写入请求的集中处理。但是除了客户端与 ES 集群的通讯效率优化,还有其他中间过程能优化么?
Gateway 的优化点
bulk 的优化理念是将日常零散的写入需求做集中化的处理,尽量减低日常请求的损耗,完成资源最大化的利用。简而言之就是“好钢用在刀刃上”。
但是 ES 在收到 bulk 写入请求后,也是需要协调节点根据文档的 id 计算所属的分片来将数据分发到对应的数据节点的。这个过程也是有一定损耗的,如果 bulk 请求中数据分布的很散,每个分片都需要进行写入,原本 bulk 集中写入的需求优势则还是没有得到最理想化的提升。
gateway 的写入加速则对 bulk 的优化理念的最大化补全。
gateway 可以本地计算每个索引文档对应后端 Elasticsearch 集群的目标存放位置,从而能够精准的进行写入请求定位。
在一批 bulk 请求中,可能存在多个后端节点的数据,bulk_reshuffle 过滤器用来将正常的 bulk 请求打散,按照目标节点或者分片进行拆分重新组装,避免 Elasticsearch 节点收到请求之后再次进行请求分发, 从而降低 Elasticsearch 集群间的流量和负载,也能避免单个节点成为热点瓶颈,确保各个数据节点的处理均衡,从而提升集群总体的索引吞吐能力。
整理的优化思路如下图:
优化实践
那我们来实践一下,看看 gateway 能提升多少的写入。
这里我们分 2 个测试场景:
- 基础集中写入测试,不带文档 id,直接批量写入。这个场景更像是日志或者监控数据采集的场景。
- 带文档 id 的写入测试,更偏向搜索场景或者大数据批同步的场景。
2 个场景都进行直接写入 ES 和 gateway 转发 ES 的效率比对。
测试材料除了需要备一个网关和一套 es 外,其余的内容如下:
测试索引 mapping 一致,名称区分:
PUT gateway_bulk_test
{
"settings": {
"number_of_shards": 6,
"number_of_replicas": 0
},
"mappings": {
"properties": {
"timestamp": {
"type": "date",
"format": "strict_date_optional_time"
},
"field1": {
"type": "keyword"
},
"field2": {
"type": "keyword"
},
"field3": {
"type": "keyword"
},
"field4": {
"type": "integer"
},
"field5": {
"type": "keyword"
},
"field6": {
"type": "float"
}
}
}
}
PUT bulk_test
{
"settings": {
"number_of_shards": 6,
"number_of_replicas": 0
},
"mappings": {
"properties": {
"timestamp": {
"type": "date",
"format": "strict_date_optional_time"
},
"field1": {
"type": "keyword"
},
"field2": {
"type": "keyword"
},
"field3": {
"type": "keyword"
},
"field4": {
"type": "integer"
},
"field5": {
"type": "keyword"
},
"field6": {
"type": "float"
}
}
}
}gateway 的配置文件如下:
path.data: data
path.logs: log
entry:
- name: my_es_entry
enabled: true
router: my_router
max_concurrency: 200000
network:
binding: 0.0.0.0:8000
flow:
- name: async_bulk
filter:
- bulk_reshuffle:
when:
contains:
_ctx.request.path: /_bulk
elasticsearch: prod
level: node
partition_size: 1
fix_null_id: true
- elasticsearch:
elasticsearch: prod #elasticsearch configure reference name
max_connection_per_node: 1000 #max tcp connection to upstream, default for all nodes
max_response_size: -1 #default for all nodes
balancer: weight
refresh: # refresh upstream nodes list, need to enable this feature to use elasticsearch nodes auto discovery
enabled: true
interval: 60s
filter:
roles:
exclude:
- master
router:
- name: my_router
default_flow: async_bulk
elasticsearch:
- name: prod
enabled: true
endpoints:
- https://127.0.0.1:9221
- https://127.0.0.1:9222
- https://127.0.0.1:9223
basic_auth:
username: admin
password: admin
pipeline:
- name: bulk_request_ingest
auto_start: true
keep_running: true
retry_delay_in_ms: 1000
processor:
- bulk_indexing:
max_connection_per_node: 100
num_of_slices: 3
max_worker_size: 30
idle_timeout_in_seconds: 10
bulk:
compress: false
batch_size_in_mb: 10
batch_size_in_docs: 10000
consumer:
fetch_max_messages: 100
queue_selector:
labels:
type: bulk_reshuffle测试脚本如下:
#!/usr/bin/env python3
"""
ES Bulk写入性能测试脚本
"""
import hashlib
import json
import random
import string
import time
from typing import List, Dict, Any
import requests
from concurrent.futures import ThreadPoolExecutor
from datetime import datetime
import urllib3
# 禁用SSL警告
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
class ESBulkTester:
def __init__(self):
# 配置变量 - 可修改
self.es_configs = [
{
"name": "ES直连",
"url": "https://127.0.0.1:9221",
"index": "bulk_test",
"username": "admin", # 修改为实际用户名
"password": "admin", # 修改为实际密码
"verify_ssl": False # HTTPS需要SSL验证
},
{
"name": "Gateway代理",
"url": "http://localhost:8000",
"index": "gateway_bulk_test",
"username": None, # 无需认证
"password": None,
"verify_ssl": False
}
]
self.batch_size = 10000 # 每次bulk写入条数
self.log_interval = 100000 # 每多少次bulk写入输出日志
# ID生成规则配置 - 前2位后5位
self.id_prefix_start = 1
self.id_prefix_end = 999 # 前3位: 01-999
self.id_suffix_start = 1
self.id_suffix_end = 9999 # 后4位: 0001-9999
# 当前ID计数器
self.current_prefix = self.id_prefix_start
self.current_suffix = self.id_suffix_start
def generate_id(self) -> str:
"""生成固定规则的ID - 前2位后5位"""
id_str = f"{self.current_prefix:02d}{self.current_suffix:05d}"
# 更新计数器
self.current_suffix += 1
if self.current_suffix > self.id_suffix_end:
self.current_suffix = self.id_suffix_start
self.current_prefix += 1
if self.current_prefix > self.id_prefix_end:
self.current_prefix = self.id_prefix_start
return id_str
def generate_random_hash(self, length: int = 32) -> str:
"""生成随机hash值"""
random_string = ''.join(random.choices(string.ascii_letters + string.digits, k=length))
return hashlib.md5(random_string.encode()).hexdigest()
def generate_document(self) -> Dict[str, Any]:
"""生成随机文档内容"""
return {
"timestamp": datetime.now().isoformat(),
"field1": self.generate_random_hash(),
"field2": self.generate_random_hash(),
"field3": self.generate_random_hash(),
"field4": random.randint(1, 1000),
"field5": random.choice(["A", "B", "C", "D"]),
"field6": random.uniform(0.1, 100.0)
}
def create_bulk_payload(self, index_name: str) -> str:
"""创建bulk写入payload"""
bulk_data = []
for _ in range(self.batch_size):
#doc_id = self.generate_id()
doc = self.generate_document()
# 添加index操作
bulk_data.append(json.dumps({
"index": {
"_index": index_name,
# "_id": doc_id
}
}))
bulk_data.append(json.dumps(doc))
return "\n".join(bulk_data) + "\n"
def bulk_index(self, config: Dict[str, Any], payload: str) -> bool:
"""执行bulk写入"""
url = f"{config['url']}/_bulk"
headers = {
"Content-Type": "application/x-ndjson"
}
# 设置认证信息
auth = None
if config.get('username') and config.get('password'):
auth = (config['username'], config['password'])
try:
response = requests.post(
url,
data=payload,
headers=headers,
auth=auth,
verify=config.get('verify_ssl', True),
timeout=30
)
return response.status_code == 200
except Exception as e:
print(f"Bulk写入失败: {e}")
return False
def refresh_index(self, config: Dict[str, Any]) -> bool:
"""刷新索引"""
url = f"{config['url']}/{config['index']}/_refresh"
# 设置认证信息
auth = None
if config.get('username') and config.get('password'):
auth = (config['username'], config['password'])
try:
response = requests.post(
url,
auth=auth,
verify=config.get('verify_ssl', True),
timeout=10
)
success = response.status_code == 200
print(f"索引刷新{'成功' if success else '失败'}: {config['index']}")
return success
except Exception as e:
print(f"索引刷新失败: {e}")
return False
def run_test(self, config: Dict[str, Any], round_num: int, total_iterations: int = 100000):
"""运行性能测试"""
test_name = f"{config['name']}-第{round_num}轮"
print(f"\n开始测试: {test_name}")
print(f"ES地址: {config['url']}")
print(f"索引名称: {config['index']}")
print(f"认证: {'是' if config.get('username') else '否'}")
print(f"每次bulk写入: {self.batch_size}条")
print(f"总计划写入: {total_iterations * self.batch_size}条")
print("-" * 50)
start_time = time.time()
success_count = 0
error_count = 0
for i in range(1, total_iterations + 1):
payload = self.create_bulk_payload(config['index'])
if self.bulk_index(config, payload):
success_count += 1
else:
error_count += 1
# 每N次输出日志
if i % self.log_interval == 0:
elapsed_time = time.time() - start_time
rate = i / elapsed_time if elapsed_time > 0 else 0
print(f"已完成 {i:,} 次bulk写入, 耗时: {elapsed_time:.2f}秒, 速率: {rate:.2f} bulk/秒")
end_time = time.time()
total_time = end_time - start_time
total_docs = total_iterations * self.batch_size
print(f"\n{test_name} 测试完成!")
print(f"总耗时: {total_time:.2f}秒")
print(f"成功bulk写入: {success_count:,}次")
print(f"失败bulk写入: {error_count:,}次")
print(f"总文档数: {total_docs:,}条")
print(f"平均速率: {success_count/total_time:.2f} bulk/秒")
print(f"文档写入速率: {total_docs/total_time:.2f} docs/秒")
print("=" * 60)
return {
"test_name": test_name,
"config_name": config['name'],
"round": round_num,
"es_url": config['url'],
"index": config['index'],
"total_time": total_time,
"success_count": success_count,
"error_count": error_count,
"total_docs": total_docs,
"bulk_rate": success_count/total_time,
"doc_rate": total_docs/total_time
}
def run_comparison_test(self, total_iterations: int = 10000):
"""运行双地址对比测试"""
print("ES Bulk写入性能测试开始")
print(f"测试时间: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}")
print("=" * 60)
results = []
rounds = 2 # 每个地址测试2轮
# 循环测试所有配置
for config in self.es_configs:
print(f"\n开始测试配置: {config['name']}")
print("*" * 40)
for round_num in range(1, rounds + 1):
# 运行测试
result = self.run_test(config, round_num, total_iterations)
results.append(result)
# 每轮结束后刷新索引
print(f"\n第{round_num}轮测试完成,执行索引刷新...")
self.refresh_index(config)
# 重置ID计数器
if round_num == 1:
# 第1轮:使用初始ID范围(新增数据)
print("第1轮:新增数据模式")
else:
# 第2轮:重复使用相同ID(更新数据模式)
print("第2轮:数据更新模式,复用第1轮ID")
self.current_prefix = self.id_prefix_start
self.current_suffix = self.id_suffix_start
print(f"{config['name']} 第{round_num}轮测试结束\n")
# 输出对比结果
print("\n性能对比结果:")
print("=" * 80)
# 按配置分组显示结果
config_results = {}
for result in results:
config_name = result['config_name']
if config_name not in config_results:
config_results[config_name] = []
config_results[config_name].append(result)
for config_name, rounds_data in config_results.items():
print(f"\n{config_name}:")
total_time = 0
total_bulk_rate = 0
total_doc_rate = 0
for round_data in rounds_data:
print(f" 第{round_data['round']}轮:")
print(f" 耗时: {round_data['total_time']:.2f}秒")
print(f" Bulk速率: {round_data['bulk_rate']:.2f} bulk/秒")
print(f" 文档速率: {round_data['doc_rate']:.2f} docs/秒")
print(f" 成功率: {round_data['success_count']/(round_data['success_count']+round_data['error_count'])*100:.2f}%")
total_time += round_data['total_time']
total_bulk_rate += round_data['bulk_rate']
total_doc_rate += round_data['doc_rate']
avg_bulk_rate = total_bulk_rate / len(rounds_data)
avg_doc_rate = total_doc_rate / len(rounds_data)
print(f" 平均性能:")
print(f" 总耗时: {total_time:.2f}秒")
print(f" 平均Bulk速率: {avg_bulk_rate:.2f} bulk/秒")
print(f" 平均文档速率: {avg_doc_rate:.2f} docs/秒")
# 整体对比
if len(config_results) >= 2:
config_names = list(config_results.keys())
config1_avg = sum([r['bulk_rate'] for r in config_results[config_names[0]]]) / len(config_results[config_names[0]])
config2_avg = sum([r['bulk_rate'] for r in config_results[config_names[1]]]) / len(config_results[config_names[1]])
if config1_avg > config2_avg:
faster = config_names[0]
rate_diff = config1_avg - config2_avg
else:
faster = config_names[1]
rate_diff = config2_avg - config1_avg
print(f"\n整体性能对比:")
print(f"{faster} 平均性能更好,bulk速率高 {rate_diff:.2f} bulk/秒")
print(f"性能提升: {(rate_diff/min(config1_avg, config2_avg)*100):.1f}%")
def main():
"""主函数"""
tester = ESBulkTester()
# 运行测试(每次bulk 1万条,300次bulk = 300万条文档)
tester.run_comparison_test(total_iterations=300)
if __name__ == "__main__":
main()1. 日志场景:不带 id 写入
测试条件:
- bulk 写入数据不带文档 id
- 每批次 bulk 10000 条数据,总共写入 30w 数据
这里把
反馈结果:
性能对比结果:
================================================================================
ES直连:
第1轮:
耗时: 152.29秒
Bulk速率: 1.97 bulk/秒
文档速率: 19699.59 docs/秒
成功率: 100.00%
平均性能:
总耗时: 152.29秒
平均Bulk速率: 1.97 bulk/秒
平均文档速率: 19699.59 docs/秒
Gateway代理:
第1轮:
耗时: 115.63秒
Bulk速率: 2.59 bulk/秒
文档速率: 25944.35 docs/秒
成功率: 100.00%
平均性能:
总耗时: 115.63秒
平均Bulk速率: 2.59 bulk/秒
平均文档速率: 25944.35 docs/秒
整体性能对比:
Gateway代理 平均性能更好,bulk速率高 0.62 bulk/秒
性能提升: 31.7%2. 业务场景:带文档 id 的写入
测试条件:
- bulk 写入数据带有文档 id,两次测试写入的文档 id 生成规则一致且重复。
- 每批次 bulk 10000 条数据,总共写入 30w 数据
这里把 py 脚本中 第 99 行 和 第 107 行的注释打开。
反馈结果:
性能对比结果:
================================================================================
ES直连:
第1轮:
耗时: 155.30秒
Bulk速率: 1.93 bulk/秒
文档速率: 19317.39 docs/秒
成功率: 100.00%
平均性能:
总耗时: 155.30秒
平均Bulk速率: 1.93 bulk/秒
平均文档速率: 19317.39 docs/秒
Gateway代理:
第1轮:
耗时: 116.73秒
Bulk速率: 2.57 bulk/秒
文档速率: 25700.06 docs/秒
成功率: 100.00%
平均性能:
总耗时: 116.73秒
平均Bulk速率: 2.57 bulk/秒
平均文档速率: 25700.06 docs/秒
整体性能对比:
Gateway代理 平均性能更好,bulk速率高 0.64 bulk/秒
性能提升: 33.0%小结
不管是日志场景还是业务价值更重要的大数据或者搜索数据同步场景, gateway 的写入加速都能平稳的节省 25%-30% 的写入耗时。
关于极限网关(INFINI Gateway)

INFINI Gateway 是一个开源的面向搜索场景的高性能数据网关,所有请求都经过网关处理后再转发到后端的搜索业务集群。基于 INFINI Gateway,可以实现索引级别的限速限流、常见查询的缓存加速、查询请求的审计、查询结果的动态修改等等。
官网文档:https://docs.infinilabs.com/gateway
开源地址:https://github.com/infinilabs/gateway
作者:金多安,极限科技(INFINI Labs)搜索运维专家,Elastic 认证专家,搜索客社区日报责任编辑。一直从事与搜索运维相关的工作,日常会去挖掘 ES / Lucene 方向的搜索技术原理,保持搜索相关技术发展的关注。
原文:https://infinilabs.cn/blog/2025/gateway-bulk-write-performance-optimization/
背景:bulk 优化的应用
在 ES 的写入优化里,bulk 操作被广泛地用于批量处理数据。bulk 操作允许用户一次提交多个数据操作,如索引、更新、删除等,从而提高数据处理效率。bulk 操作的实现原理是,将数据操作请求打包成 HTTP 请求,并批量提交给 Elasticsearch 服务器。这样,Elasticsearch 服务器就可以一次处理多个数据操作,从而提高处理效率。
这种优化的核心价值在于减少了网络往返的次数和连接建立的开销。每一次单独的写入操作都需要经历完整的请求-响应周期,而批量写入则是将多个操作打包在一起,用一次通信完成原本需要多次交互的工作。这不仅仅节省了时间,更重要的是释放了系统资源,让服务器能够专注于真正的数据处理,而不是频繁的协议握手和状态维护。
这样的批量请求的确是可以优化写入请求的效率,让 ES 集群获得更多的资源去做写入请求的集中处理。但是除了客户端与 ES 集群的通讯效率优化,还有其他中间过程能优化么?
Gateway 的优化点
bulk 的优化理念是将日常零散的写入需求做集中化的处理,尽量减低日常请求的损耗,完成资源最大化的利用。简而言之就是“好钢用在刀刃上”。
但是 ES 在收到 bulk 写入请求后,也是需要协调节点根据文档的 id 计算所属的分片来将数据分发到对应的数据节点的。这个过程也是有一定损耗的,如果 bulk 请求中数据分布的很散,每个分片都需要进行写入,原本 bulk 集中写入的需求优势则还是没有得到最理想化的提升。
gateway 的写入加速则对 bulk 的优化理念的最大化补全。
gateway 可以本地计算每个索引文档对应后端 Elasticsearch 集群的目标存放位置,从而能够精准的进行写入请求定位。
在一批 bulk 请求中,可能存在多个后端节点的数据,bulk_reshuffle 过滤器用来将正常的 bulk 请求打散,按照目标节点或者分片进行拆分重新组装,避免 Elasticsearch 节点收到请求之后再次进行请求分发, 从而降低 Elasticsearch 集群间的流量和负载,也能避免单个节点成为热点瓶颈,确保各个数据节点的处理均衡,从而提升集群总体的索引吞吐能力。
整理的优化思路如下图:
优化实践
那我们来实践一下,看看 gateway 能提升多少的写入。
这里我们分 2 个测试场景:
- 基础集中写入测试,不带文档 id,直接批量写入。这个场景更像是日志或者监控数据采集的场景。
- 带文档 id 的写入测试,更偏向搜索场景或者大数据批同步的场景。
2 个场景都进行直接写入 ES 和 gateway 转发 ES 的效率比对。
测试材料除了需要备一个网关和一套 es 外,其余的内容如下:
测试索引 mapping 一致,名称区分:
PUT gateway_bulk_test
{
"settings": {
"number_of_shards": 6,
"number_of_replicas": 0
},
"mappings": {
"properties": {
"timestamp": {
"type": "date",
"format": "strict_date_optional_time"
},
"field1": {
"type": "keyword"
},
"field2": {
"type": "keyword"
},
"field3": {
"type": "keyword"
},
"field4": {
"type": "integer"
},
"field5": {
"type": "keyword"
},
"field6": {
"type": "float"
}
}
}
}
PUT bulk_test
{
"settings": {
"number_of_shards": 6,
"number_of_replicas": 0
},
"mappings": {
"properties": {
"timestamp": {
"type": "date",
"format": "strict_date_optional_time"
},
"field1": {
"type": "keyword"
},
"field2": {
"type": "keyword"
},
"field3": {
"type": "keyword"
},
"field4": {
"type": "integer"
},
"field5": {
"type": "keyword"
},
"field6": {
"type": "float"
}
}
}
}gateway 的配置文件如下:
path.data: data
path.logs: log
entry:
- name: my_es_entry
enabled: true
router: my_router
max_concurrency: 200000
network:
binding: 0.0.0.0:8000
flow:
- name: async_bulk
filter:
- bulk_reshuffle:
when:
contains:
_ctx.request.path: /_bulk
elasticsearch: prod
level: node
partition_size: 1
fix_null_id: true
- elasticsearch:
elasticsearch: prod #elasticsearch configure reference name
max_connection_per_node: 1000 #max tcp connection to upstream, default for all nodes
max_response_size: -1 #default for all nodes
balancer: weight
refresh: # refresh upstream nodes list, need to enable this feature to use elasticsearch nodes auto discovery
enabled: true
interval: 60s
filter:
roles:
exclude:
- master
router:
- name: my_router
default_flow: async_bulk
elasticsearch:
- name: prod
enabled: true
endpoints:
- https://127.0.0.1:9221
- https://127.0.0.1:9222
- https://127.0.0.1:9223
basic_auth:
username: admin
password: admin
pipeline:
- name: bulk_request_ingest
auto_start: true
keep_running: true
retry_delay_in_ms: 1000
processor:
- bulk_indexing:
max_connection_per_node: 100
num_of_slices: 3
max_worker_size: 30
idle_timeout_in_seconds: 10
bulk:
compress: false
batch_size_in_mb: 10
batch_size_in_docs: 10000
consumer:
fetch_max_messages: 100
queue_selector:
labels:
type: bulk_reshuffle测试脚本如下:
#!/usr/bin/env python3
"""
ES Bulk写入性能测试脚本
"""
import hashlib
import json
import random
import string
import time
from typing import List, Dict, Any
import requests
from concurrent.futures import ThreadPoolExecutor
from datetime import datetime
import urllib3
# 禁用SSL警告
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
class ESBulkTester:
def __init__(self):
# 配置变量 - 可修改
self.es_configs = [
{
"name": "ES直连",
"url": "https://127.0.0.1:9221",
"index": "bulk_test",
"username": "admin", # 修改为实际用户名
"password": "admin", # 修改为实际密码
"verify_ssl": False # HTTPS需要SSL验证
},
{
"name": "Gateway代理",
"url": "http://localhost:8000",
"index": "gateway_bulk_test",
"username": None, # 无需认证
"password": None,
"verify_ssl": False
}
]
self.batch_size = 10000 # 每次bulk写入条数
self.log_interval = 100000 # 每多少次bulk写入输出日志
# ID生成规则配置 - 前2位后5位
self.id_prefix_start = 1
self.id_prefix_end = 999 # 前3位: 01-999
self.id_suffix_start = 1
self.id_suffix_end = 9999 # 后4位: 0001-9999
# 当前ID计数器
self.current_prefix = self.id_prefix_start
self.current_suffix = self.id_suffix_start
def generate_id(self) -> str:
"""生成固定规则的ID - 前2位后5位"""
id_str = f"{self.current_prefix:02d}{self.current_suffix:05d}"
# 更新计数器
self.current_suffix += 1
if self.current_suffix > self.id_suffix_end:
self.current_suffix = self.id_suffix_start
self.current_prefix += 1
if self.current_prefix > self.id_prefix_end:
self.current_prefix = self.id_prefix_start
return id_str
def generate_random_hash(self, length: int = 32) -> str:
"""生成随机hash值"""
random_string = ''.join(random.choices(string.ascii_letters + string.digits, k=length))
return hashlib.md5(random_string.encode()).hexdigest()
def generate_document(self) -> Dict[str, Any]:
"""生成随机文档内容"""
return {
"timestamp": datetime.now().isoformat(),
"field1": self.generate_random_hash(),
"field2": self.generate_random_hash(),
"field3": self.generate_random_hash(),
"field4": random.randint(1, 1000),
"field5": random.choice(["A", "B", "C", "D"]),
"field6": random.uniform(0.1, 100.0)
}
def create_bulk_payload(self, index_name: str) -> str:
"""创建bulk写入payload"""
bulk_data = []
for _ in range(self.batch_size):
#doc_id = self.generate_id()
doc = self.generate_document()
# 添加index操作
bulk_data.append(json.dumps({
"index": {
"_index": index_name,
# "_id": doc_id
}
}))
bulk_data.append(json.dumps(doc))
return "\n".join(bulk_data) + "\n"
def bulk_index(self, config: Dict[str, Any], payload: str) -> bool:
"""执行bulk写入"""
url = f"{config['url']}/_bulk"
headers = {
"Content-Type": "application/x-ndjson"
}
# 设置认证信息
auth = None
if config.get('username') and config.get('password'):
auth = (config['username'], config['password'])
try:
response = requests.post(
url,
data=payload,
headers=headers,
auth=auth,
verify=config.get('verify_ssl', True),
timeout=30
)
return response.status_code == 200
except Exception as e:
print(f"Bulk写入失败: {e}")
return False
def refresh_index(self, config: Dict[str, Any]) -> bool:
"""刷新索引"""
url = f"{config['url']}/{config['index']}/_refresh"
# 设置认证信息
auth = None
if config.get('username') and config.get('password'):
auth = (config['username'], config['password'])
try:
response = requests.post(
url,
auth=auth,
verify=config.get('verify_ssl', True),
timeout=10
)
success = response.status_code == 200
print(f"索引刷新{'成功' if success else '失败'}: {config['index']}")
return success
except Exception as e:
print(f"索引刷新失败: {e}")
return False
def run_test(self, config: Dict[str, Any], round_num: int, total_iterations: int = 100000):
"""运行性能测试"""
test_name = f"{config['name']}-第{round_num}轮"
print(f"\n开始测试: {test_name}")
print(f"ES地址: {config['url']}")
print(f"索引名称: {config['index']}")
print(f"认证: {'是' if config.get('username') else '否'}")
print(f"每次bulk写入: {self.batch_size}条")
print(f"总计划写入: {total_iterations * self.batch_size}条")
print("-" * 50)
start_time = time.time()
success_count = 0
error_count = 0
for i in range(1, total_iterations + 1):
payload = self.create_bulk_payload(config['index'])
if self.bulk_index(config, payload):
success_count += 1
else:
error_count += 1
# 每N次输出日志
if i % self.log_interval == 0:
elapsed_time = time.time() - start_time
rate = i / elapsed_time if elapsed_time > 0 else 0
print(f"已完成 {i:,} 次bulk写入, 耗时: {elapsed_time:.2f}秒, 速率: {rate:.2f} bulk/秒")
end_time = time.time()
total_time = end_time - start_time
total_docs = total_iterations * self.batch_size
print(f"\n{test_name} 测试完成!")
print(f"总耗时: {total_time:.2f}秒")
print(f"成功bulk写入: {success_count:,}次")
print(f"失败bulk写入: {error_count:,}次")
print(f"总文档数: {total_docs:,}条")
print(f"平均速率: {success_count/total_time:.2f} bulk/秒")
print(f"文档写入速率: {total_docs/total_time:.2f} docs/秒")
print("=" * 60)
return {
"test_name": test_name,
"config_name": config['name'],
"round": round_num,
"es_url": config['url'],
"index": config['index'],
"total_time": total_time,
"success_count": success_count,
"error_count": error_count,
"total_docs": total_docs,
"bulk_rate": success_count/total_time,
"doc_rate": total_docs/total_time
}
def run_comparison_test(self, total_iterations: int = 10000):
"""运行双地址对比测试"""
print("ES Bulk写入性能测试开始")
print(f"测试时间: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}")
print("=" * 60)
results = []
rounds = 2 # 每个地址测试2轮
# 循环测试所有配置
for config in self.es_configs:
print(f"\n开始测试配置: {config['name']}")
print("*" * 40)
for round_num in range(1, rounds + 1):
# 运行测试
result = self.run_test(config, round_num, total_iterations)
results.append(result)
# 每轮结束后刷新索引
print(f"\n第{round_num}轮测试完成,执行索引刷新...")
self.refresh_index(config)
# 重置ID计数器
if round_num == 1:
# 第1轮:使用初始ID范围(新增数据)
print("第1轮:新增数据模式")
else:
# 第2轮:重复使用相同ID(更新数据模式)
print("第2轮:数据更新模式,复用第1轮ID")
self.current_prefix = self.id_prefix_start
self.current_suffix = self.id_suffix_start
print(f"{config['name']} 第{round_num}轮测试结束\n")
# 输出对比结果
print("\n性能对比结果:")
print("=" * 80)
# 按配置分组显示结果
config_results = {}
for result in results:
config_name = result['config_name']
if config_name not in config_results:
config_results[config_name] = []
config_results[config_name].append(result)
for config_name, rounds_data in config_results.items():
print(f"\n{config_name}:")
total_time = 0
total_bulk_rate = 0
total_doc_rate = 0
for round_data in rounds_data:
print(f" 第{round_data['round']}轮:")
print(f" 耗时: {round_data['total_time']:.2f}秒")
print(f" Bulk速率: {round_data['bulk_rate']:.2f} bulk/秒")
print(f" 文档速率: {round_data['doc_rate']:.2f} docs/秒")
print(f" 成功率: {round_data['success_count']/(round_data['success_count']+round_data['error_count'])*100:.2f}%")
total_time += round_data['total_time']
total_bulk_rate += round_data['bulk_rate']
total_doc_rate += round_data['doc_rate']
avg_bulk_rate = total_bulk_rate / len(rounds_data)
avg_doc_rate = total_doc_rate / len(rounds_data)
print(f" 平均性能:")
print(f" 总耗时: {total_time:.2f}秒")
print(f" 平均Bulk速率: {avg_bulk_rate:.2f} bulk/秒")
print(f" 平均文档速率: {avg_doc_rate:.2f} docs/秒")
# 整体对比
if len(config_results) >= 2:
config_names = list(config_results.keys())
config1_avg = sum([r['bulk_rate'] for r in config_results[config_names[0]]]) / len(config_results[config_names[0]])
config2_avg = sum([r['bulk_rate'] for r in config_results[config_names[1]]]) / len(config_results[config_names[1]])
if config1_avg > config2_avg:
faster = config_names[0]
rate_diff = config1_avg - config2_avg
else:
faster = config_names[1]
rate_diff = config2_avg - config1_avg
print(f"\n整体性能对比:")
print(f"{faster} 平均性能更好,bulk速率高 {rate_diff:.2f} bulk/秒")
print(f"性能提升: {(rate_diff/min(config1_avg, config2_avg)*100):.1f}%")
def main():
"""主函数"""
tester = ESBulkTester()
# 运行测试(每次bulk 1万条,300次bulk = 300万条文档)
tester.run_comparison_test(total_iterations=300)
if __name__ == "__main__":
main()1. 日志场景:不带 id 写入
测试条件:
- bulk 写入数据不带文档 id
- 每批次 bulk 10000 条数据,总共写入 30w 数据
这里把
反馈结果:
性能对比结果:
================================================================================
ES直连:
第1轮:
耗时: 152.29秒
Bulk速率: 1.97 bulk/秒
文档速率: 19699.59 docs/秒
成功率: 100.00%
平均性能:
总耗时: 152.29秒
平均Bulk速率: 1.97 bulk/秒
平均文档速率: 19699.59 docs/秒
Gateway代理:
第1轮:
耗时: 115.63秒
Bulk速率: 2.59 bulk/秒
文档速率: 25944.35 docs/秒
成功率: 100.00%
平均性能:
总耗时: 115.63秒
平均Bulk速率: 2.59 bulk/秒
平均文档速率: 25944.35 docs/秒
整体性能对比:
Gateway代理 平均性能更好,bulk速率高 0.62 bulk/秒
性能提升: 31.7%2. 业务场景:带文档 id 的写入
测试条件:
- bulk 写入数据带有文档 id,两次测试写入的文档 id 生成规则一致且重复。
- 每批次 bulk 10000 条数据,总共写入 30w 数据
这里把 py 脚本中 第 99 行 和 第 107 行的注释打开。
反馈结果:
性能对比结果:
================================================================================
ES直连:
第1轮:
耗时: 155.30秒
Bulk速率: 1.93 bulk/秒
文档速率: 19317.39 docs/秒
成功率: 100.00%
平均性能:
总耗时: 155.30秒
平均Bulk速率: 1.93 bulk/秒
平均文档速率: 19317.39 docs/秒
Gateway代理:
第1轮:
耗时: 116.73秒
Bulk速率: 2.57 bulk/秒
文档速率: 25700.06 docs/秒
成功率: 100.00%
平均性能:
总耗时: 116.73秒
平均Bulk速率: 2.57 bulk/秒
平均文档速率: 25700.06 docs/秒
整体性能对比:
Gateway代理 平均性能更好,bulk速率高 0.64 bulk/秒
性能提升: 33.0%小结
不管是日志场景还是业务价值更重要的大数据或者搜索数据同步场景, gateway 的写入加速都能平稳的节省 25%-30% 的写入耗时。
关于极限网关(INFINI Gateway)
INFINI Gateway 是一个开源的面向搜索场景的高性能数据网关,所有请求都经过网关处理后再转发到后端的搜索业务集群。基于 INFINI Gateway,可以实现索引级别的限速限流、常见查询的缓存加速、查询请求的审计、查询结果的动态修改等等。
官网文档:https://docs.infinilabs.com/gateway
开源地址:https://github.com/infinilabs/gateway
收起阅读 »作者:金多安,极限科技(INFINI Labs)搜索运维专家,Elastic 认证专家,搜索客社区日报责任编辑。一直从事与搜索运维相关的工作,日常会去挖掘 ES / Lucene 方向的搜索技术原理,保持搜索相关技术发展的关注。
原文:https://infinilabs.cn/blog/2025/gateway-bulk-write-performance-optimization/
【搜索客社区日报】第2089期 (2025-08-06)
https://seanfalconer.medium.co ... 85b72
2.Text-to-SQL的自动优化:性能分析阶段(搭梯)
https://medium.com/%40DaveLumA ... f6b43
3.Elasticsearch 插件用于 UBI:分析用户搜索行为
https://cloud.tencent.com/deve ... 51491
编辑:kin122
更多资讯:http://news.searchkit.cn
https://seanfalconer.medium.co ... 85b72
2.Text-to-SQL的自动优化:性能分析阶段(搭梯)
https://medium.com/%40DaveLumA ... f6b43
3.Elasticsearch 插件用于 UBI:分析用户搜索行为
https://cloud.tencent.com/deve ... 51491
编辑:kin122
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2088期 (2025-08-05)
https://blog.devgenius.io/buil ... 0d79c
2. mongodb和ES的左右互搏之术(需要梯子)
https://medium.com/%40kumarjai ... 5284e
3. opensearch 里的性能瓶颈?不能忍(需要梯子)
https://medium.com/collaborne- ... 71ace
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
https://blog.devgenius.io/buil ... 0d79c
2. mongodb和ES的左右互搏之术(需要梯子)
https://medium.com/%40kumarjai ... 5284e
3. opensearch 里的性能瓶颈?不能忍(需要梯子)
https://medium.com/collaborne- ... 71ace
编辑:斯蒂文
更多资讯:http://news.searchkit.cn
收起阅读 »
【搜索客社区日报】第2087期 (2025-08-04)
https://infinilabs.cn/blog/202 ... ys-2/
2、IK 字段级别词典的升级之路
https://infinilabs.cn/blog/202 ... ys-3/
3、使用 Elasticsearch 和 AI 构建智能重复项检测
https://elasticstack.blog.csdn ... 96938
4、上下文工程(Context Engineering)综述:大模型的下一个前沿
https://mp.weixin.qq.com/s/hsalUdlx0KMtQh8U2gvnnw
5、Elasticsearch:在 Elastic 中玩转 DeepSeek R1 来实现 RAG 应用
https://elasticstack.blog.csdn ... 32862
编辑:Muse
更多资讯:http://news.searchkit.cn
https://infinilabs.cn/blog/202 ... ys-2/
2、IK 字段级别词典的升级之路
https://infinilabs.cn/blog/202 ... ys-3/
3、使用 Elasticsearch 和 AI 构建智能重复项检测
https://elasticstack.blog.csdn ... 96938
4、上下文工程(Context Engineering)综述:大模型的下一个前沿
https://mp.weixin.qq.com/s/hsalUdlx0KMtQh8U2gvnnw
5、Elasticsearch:在 Elastic 中玩转 DeepSeek R1 来实现 RAG 应用
https://elasticstack.blog.csdn ... 32862
编辑:Muse
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2086期 (2025-07-31)
https://mp.weixin.qq.com/s/8AVx8hWltAeOBh1iSwo4IA
2.李沐“沐神”B站更新了!教你手搓语音大模型,代码全开源还能在线试玩
https://mp.weixin.qq.com/s/58w4JDG7OSbZhRKSX9Cm8Q
3.从DeepSeek-V3到Kimi K2:八种现代 LLM 架构大比较
https://mp.weixin.qq.com/s/YgVuQnXBoltaFY64cStA-A
编辑:Se7en
更多资讯:http://news.searchkit.cn
https://mp.weixin.qq.com/s/8AVx8hWltAeOBh1iSwo4IA
2.李沐“沐神”B站更新了!教你手搓语音大模型,代码全开源还能在线试玩
https://mp.weixin.qq.com/s/58w4JDG7OSbZhRKSX9Cm8Q
3.从DeepSeek-V3到Kimi K2:八种现代 LLM 架构大比较
https://mp.weixin.qq.com/s/YgVuQnXBoltaFY64cStA-A
编辑:Se7en
更多资讯:http://news.searchkit.cn 收起阅读 »
【搜索客社区日报】第2085期 (2025-07-30)
https://medium.com/data-scienc ... 8b3a0
2.TF-IDF:辨别你的词汇是否特别的方法(搭梯)
https://medium.com/%40DaveLumA ... f6b43
3.TF-IDF:教机器哪些词真正重要(搭梯)
https://liorgd.medium.com/tf-i ... 56ac7
4.循环神经网络(RNNs)& TF-IDF — 从序列训练到文本权重(搭梯)
https://medium.com/%40animagun ... d0402
编辑:kin122
更多资讯:http://news.searchkit.cn
https://medium.com/data-scienc ... 8b3a0
2.TF-IDF:辨别你的词汇是否特别的方法(搭梯)
https://medium.com/%40DaveLumA ... f6b43
3.TF-IDF:教机器哪些词真正重要(搭梯)
https://liorgd.medium.com/tf-i ... 56ac7
4.循环神经网络(RNNs)& TF-IDF — 从序列训练到文本权重(搭梯)
https://medium.com/%40animagun ... d0402
编辑:kin122
更多资讯:http://news.searchkit.cn 收起阅读 »
IK 字段级别词典的升级之路
背景知识:词库的作用
IK 分词器是一款基于词典匹配的中文分词器,其准确性和召回率与 IK 使用的词库也有不小的关系。
这里我们先了解一下词典匹配法的作用流程:
- 预先准备一个大规模的词典,用算法在文本中寻找词典里的最长匹配项。这种方法实现简单且速度快。
- 但面临歧义切分和未登录词挑战:同一序列可能有不同切分方式(例如“北京大学生”可以切成“北京大学/生”或“北京/大学生”),需要规则或算法消除歧义;
- 而词典中没有的新词(如网络流行语、人名等)无法正确切分。
可以看到词库是词元产生的比对基础,一个完善的中文词库能大大提高分词器的准确性和召回率。
IK 使用的词库是中文中常见词汇的合集,完善且丰富,ik_smart 和 ik_max_word 也能满足大部分中文分词的场景需求。但是针对一些专业的场景,比如医药这样的行业词库、电商搜索词、新闻热点词等,IK 是很难覆盖到的。这时候就需要使用者自己去维护自定义的词库了。
IK 的自定义词库加载方式
IK 本身也支持自定义词库的加载和更新的,但是只支持一个集群使用一个词库。
这里主要的制约因素是,词库对象与 ik 的中文分词器执行对象是一一对应的关系。
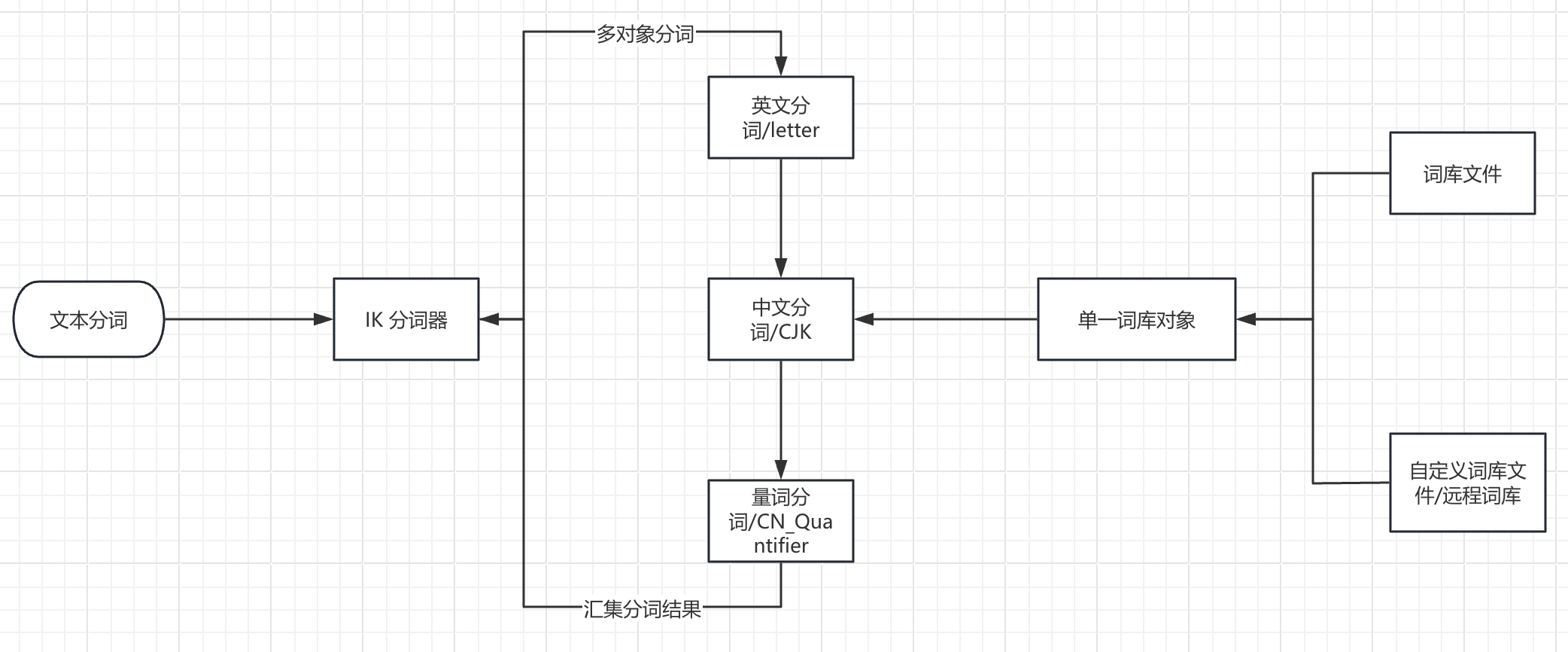
这导致了 IK 的词库面对不同中文分词场景时较低的灵活性,使用者并不能做到字段级别的词库加载。并且基于文件或者 http 协议的词库加载方式也需要不小的维护成本。
字段级别词库的加载
鉴于上述的背景问题,INFINI lab 加强了 IK 的词库加载逻辑,做到了字段级别的词库加载。同时将自定义词库的加载方式由外部文件/远程访问改成了内部索引查询。
主要逻辑如图:
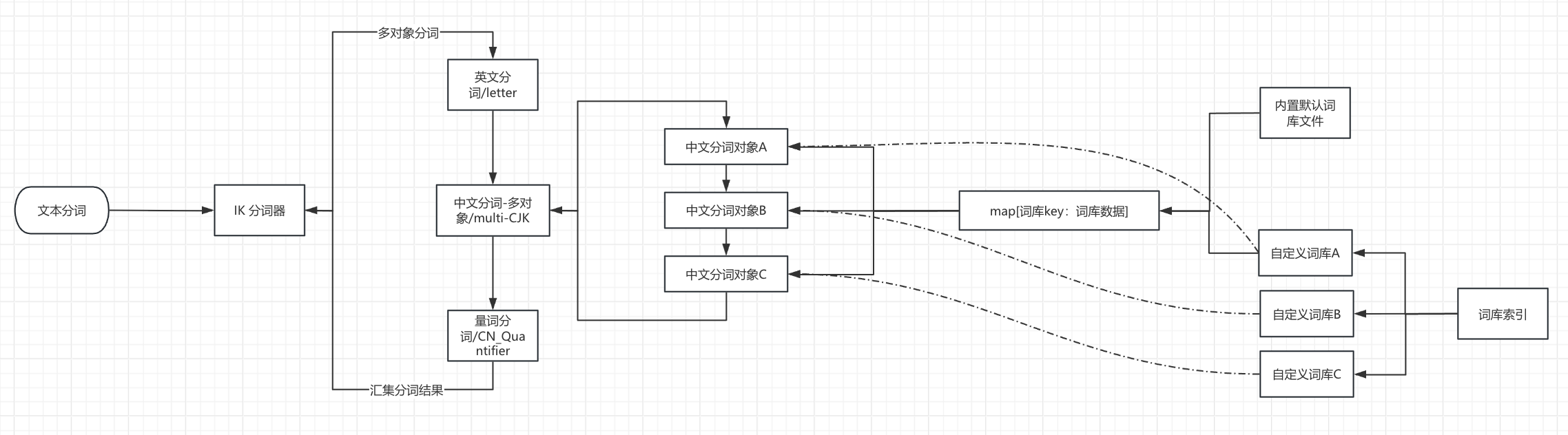
这里 IK 多中文词库的加载优化主要基于 IK 可以加载多词类对象(即下面这段代码)的灵活性,将原来遍历一个 CJK 词类对象修改成遍历多个 CJK 词类对象,各个自定义词库可以附着在 CJK 词库对象上实现不同词库的分词。
do{
//遍历子分词器
for(ISegmenter segmenter : segmenters){
segmenter.analyze(context);
}
//字符缓冲区接近读完,需要读入新的字符
if(context.needRefillBuffer()){
break;
}
}对默认词库的新增支持
对于默认词库的修改,新版 IK 也可以通过写入词库索引方式支持,只要将 dict_key 设置为 default 即可。
POST .analysis_ik/_doc
{
"dict_key": "default",
"dict_type": "main_dicts",
"dict_content":"杨树林"
}效率测试
测试方案 1:单条测试
测试方法:写入一条数据到默认 ik_max_word 和自定义词库,查看是否有明显的效率差距
- 创建测试索引,自定义一个包括默认词库的 IK 分词器
PUT my-index-000001
{
"settings": {
"number_of_shards": 3,
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "my_tokenizer"
}
},
"tokenizer": {
"my_tokenizer": {
"type": "ik_max_word",
"custom_dict_enable": true,
"load_default_dicts":true,
"lowcase_enable": true,
"dict_key": "test_dic"
}
}
}
},
"mappings": {
"properties": {
"test_ik": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
}
}- 将该词库重复默认词库的内容
POST .analysis_ik/_doc
{
"dict_key": "test_dic",
"dict_type": "main_dicts",
"dict_content":"""xxxx #词库内容
"""
}
# debug 日志
[2025-07-09T16:37:43,112][INFO ][o.w.a.d.Dictionary ] [ik-1] Loaded 275909 words from main_dicts dictionary for dict_key: test_dic- 测试默认词库和自定义词库的分词效率
GET my-index-000001/_analyze
{
"analyzer": "my_custom_analyzer",
"text":"自强不息,杨树林"
}
GET my-index-000001/_analyze
{
"analyzer": "ik_max_word",
"text":"自强不息,杨树林"
}
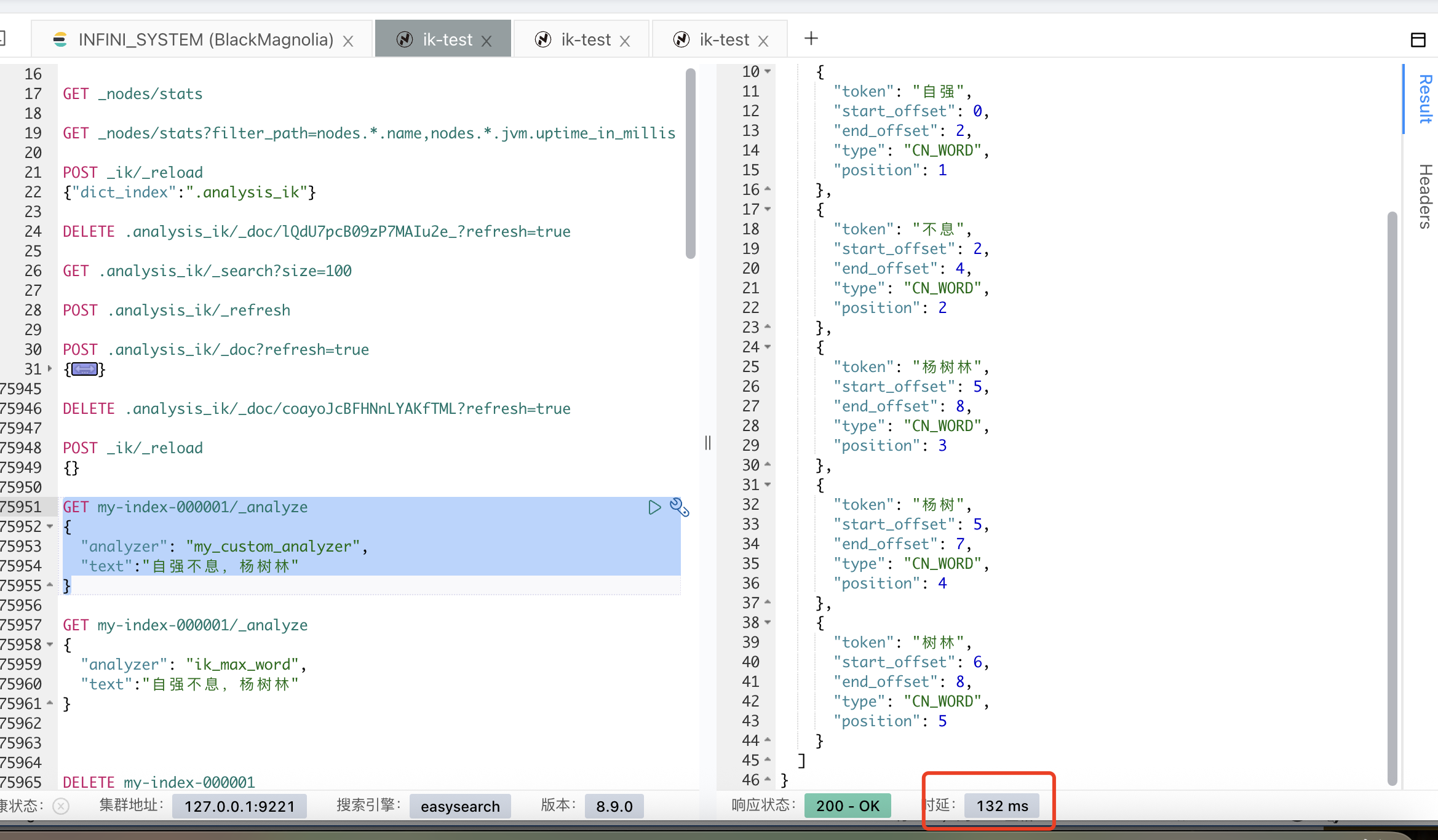
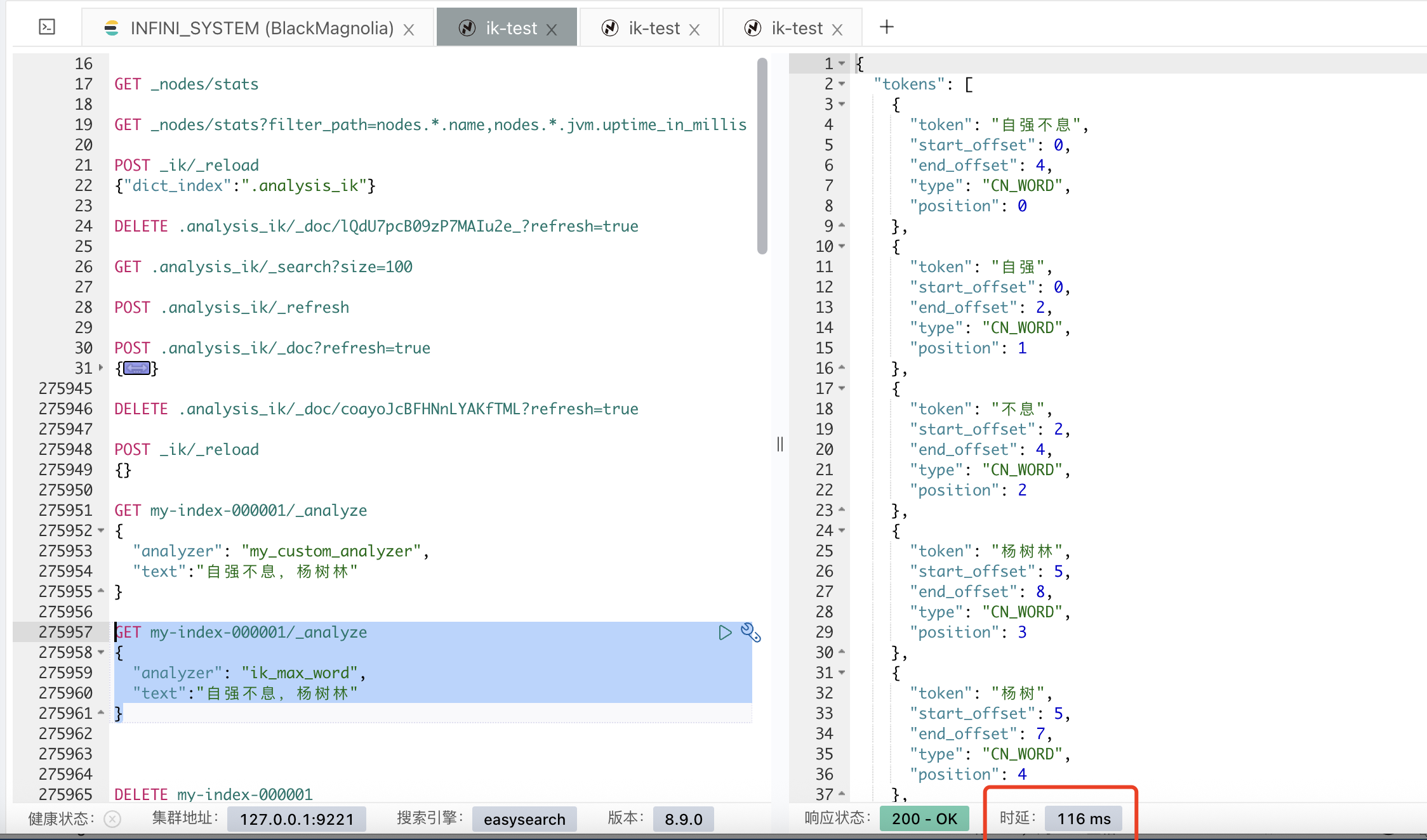
打开 debug 日志,可以看到自定义分词器在不同的词库找到了 2 次“自强不息”
...
[2025-07-09T16:52:22,937][INFO ][o.w.a.c.CN_QuantifierSegmenter] [ik-1] 当前扫描词元[息]不需要启动量词扫描
[2025-07-09T16:52:22,937][INFO ][o.w.a.c.CJKSegmenter ] [ik-1] >>> WORD FOUND [自强不息] from dict [default]
[2025-07-09T16:52:22,937][INFO ][o.w.a.c.CJKSegmenter ] [ik-1] >>> WORD FOUND [不息] from dict [default]
[2025-07-09T16:52:22,937][INFO ][o.w.a.c.CJKSegmenter ] [ik-1] >>> WORD FOUND [自强不息] from dict [test_dic]
[2025-07-09T16:52:22,937][INFO ][o.w.a.c.CJKSegmenter ] [ik-1] >>> WORD FOUND [不息] from dict [test_dic]
[2025-07-09T16:52:22,937][INFO ][o.w.a.c.CN_QuantifierSegmenter] [ik-1] 当前扫描词元[,]不需要启动量词扫描
...而默认词库只有一次
...
[2025-07-09T16:54:22,618][INFO ][o.w.a.c.CN_QuantifierSegmenter] [ik-1] 当前扫描词元[息]不需要启动量词扫描
[2025-07-09T16:54:22,618][INFO ][o.w.a.c.CJKSegmenter ] [ik-1] >>> WORD FOUND [自强不息] from dict [default]
[2025-07-09T16:54:22,618][INFO ][o.w.a.c.CJKSegmenter ] [ik-1] >>> WORD FOUND [不息] from dict [default]
[2025-07-09T16:54:22,618][INFO ][o.w.a.c.CN_QuantifierSegmenter] [ik-1] 当前扫描词元[,]不需要启动量词扫描
...测试方案 2:持续写入测试
测试方法:在 ik_max_word 和自定义词库的索引里,分别持续 bulk 写入,查看总体写入延迟。
测试索引:
# ik_max_word索引
PUT ik_max_test
{
"mappings": {
"properties": {
"chapter": {
"type": "keyword"
},
"content": {
"type": "text",
"analyzer": "ik_max_word"
},
"paragraph_id": {
"type": "keyword"
},
"random_field": {
"type": "text"
},
"timestamp": {
"type": "keyword"
},
"word_count": {
"type": "integer"
}
}
},
"settings": {
"index": {
"number_of_shards": "1",
"number_of_replicas": "0"
}
}
}
# 自定义词库索引
PUT ik_custom_test
{
"mappings": {
"properties": {
"chapter": {
"type": "keyword"
},
"content": {
"type": "text",
"analyzer": "my_custom_analyzer"
},
"paragraph_id": {
"type": "keyword"
},
"random_field": {
"type": "text"
},
"timestamp": {
"type": "keyword"
},
"word_count": {
"type": "integer"
}
}
},
"settings": {
"index": {
"number_of_shards": "1",
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "my_tokenizer"
}
},
"tokenizer": {
"my_tokenizer": {
"load_default_dicts": "true",
"type": "ik_max_word",
"dict_key": "test_dic",
"lowcase_enable": "true",
"custom_dict_enable": "true"
}
}
},
"number_of_replicas": "0"
}
}
}
这里利用脚本循环写入了一段《四世同堂》的文本,比较相同次数下,两次写入的总体延迟。
测试脚本内容如下:
#!/usr/bin/env python3
# -_- coding: utf-8 -_-
"""
四世同堂中文内容随机循环写入 Elasticsearch 脚本
目标:生成指定 bulk 次数的索引内容
"""
import random
import time
import json
from datetime import datetime
import requests
import logging
import os
import argparse
import urllib3
# 配置日志
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(**name**)
class ESDataGenerator:
def **init**(self, es_host='localhost', es_port=9200, index_name='sisitontang_content',
target_bulk_count=10000, batch_size=1000, use_https=False, username=None, password=None, verify_ssl=True):
"""
初始化 ES 连接和配置
"""
protocol = 'https' if use_https else 'http'
self.es_url = f'{protocol}://{es_host}:{es_port}'
self.index_name = index_name
self.target_bulk_count = target_bulk_count # 目标 bulk 次数
self.batch_size = batch_size
self.check_interval = 1000 # 每 1000 次 bulk 检查一次进度
# 设置认证信息
self.auth = None
if username and password:
self.auth = (username, password)
logger.info(f"使用用户名认证: {username}")
# 设置请求会话
self.session = requests.Session()
if self.auth:
self.session.auth = self.auth
# 处理HTTPS和SSL证书验证
if use_https:
self.session.verify = False # 始终禁用SSL验证以避免证书问题
logger.info("警告:已禁用SSL证书验证(适合开发测试环境)")
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
# 设置SSL适配器以处理连接问题
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
# 配置重试策略
retry_strategy = Retry(
total=3,
backoff_factor=1,
status_forcelist=[429, 500, 502, 503, 504],
)
adapter = HTTPAdapter(max_retries=retry_strategy)
self.session.mount("https://", adapter)
# 设置更宽松的SSL上下文
self.session.verify = False
logger.info(f"ES连接地址: {self.es_url}")
# 创建索引映射
self.create_index()
def create_index(self):
"""创建索引和映射"""
mapping = {
"mappings": {
"properties": {
"chapter": {"type": "keyword"},
"content": {"type": "text", "analyzer": "ik_max_word"},
"timestamp": {"type": "date"},
"word_count": {"type": "integer"},
"paragraph_id": {"type": "keyword"},
"random_field": {"type": "text"}
}
}
}
try:
# 检查索引是否存在
response = self.session.head(f"{self.es_url}/{self.index_name}")
if response.status_code == 200:
logger.info(f"索引 {self.index_name} 已存在")
else:
# 创建索引
response = self.session.put(
f"{self.es_url}/{self.index_name}",
headers={'Content-Type': 'application/json'},
json=mapping
)
if response.status_code in [200, 201]:
logger.info(f"创建索引 {self.index_name} 成功")
else:
logger.error(f"创建索引失败: {response.status_code} - {response.text}")
except Exception as e:
logger.error(f"创建索引失败: {e}")
def load_text_content(self, file_path='sisitontang.txt'):
"""
从文件加载《四世同堂》的完整文本内容
如果文件不存在,则返回扩展的示例内容
"""
if os.path.exists(file_path):
try:
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
logger.info(f"从文件 {file_path} 加载了 {len(content)} 个字符的文本内容")
return content
except Exception as e:
logger.error(f"读取文件失败: {e}")
# 如果文件不存在,返回扩展的示例内容
logger.info("使用内置的扩展示例内容")
return self.get_extended_sample_content()
def get_extended_sample_content(self):
"""
获取扩展的《四世同堂》示例内容
"""
content = """
小羊圈胡同是北平城里的一个小胡同。它不宽,可是很长,从东到西有一里多路。在这条胡同里,从东边数起,有个小茶馆,几个小门脸,和一群小房屋。小茶馆的斜对面是个较大的四合院,院子里有几棵大槐树。这个院子就是祁家的住所,四世同堂的大家庭就在这里度过了最困难的岁月。
祁老人是个善良的老头儿,虽然年纪大了,可是还很有精神。他的一生见证了太多的变迁,从清朝的衰落到民国的建立,再到现在的战乱,他都以一种达观的态度面对着。他的儿子祁天佑是个教书先生,为人正直,在胡同里很有威望。祁家的儿媳妇韵梅是个贤惠的女人,把家里打理得井井有条,即使在最困难的时候,也要维持着家庭的尊严。
钱默吟先生是个有学问的人,他的诗写得很好,可是性格有些古怪。他住在胡同深处的一个小院子里,平时很少出门,只是偶尔到祁家坐坐,和祁天佑聊聊古今。他对时局有着自己独特的见解,但更多的时候,他选择在自己的小天地里寻找精神的慰藉。战争的残酷现实让这个文人感到深深的无力,但他依然坚持着自己的文人气节。
小顺子是个活泼的孩子,他每天都在胡同里跑来跑去,和其他的孩子们一起玩耍。他的笑声总是能感染到周围的人,让这个古老的胡同充满了生机。即使在战争的阴霾下,孩子们依然保持着他们的天真和快乐,这或许就是生活的希望所在。小顺子不懂得大人们的烦恼,他只是简单地享受着童年的快乐。
李四大爷是个老实人,他在胡同里开了个小杂货铺。虽然生意不大,但是童叟无欺,街坊邻居们都愿意到他这里买东西。他的妻子是个能干的女人,把小铺子管理得很好。在那个物资匮乏的年代,能够维持一个小铺子的经营已经很不容易了。李四大爷经常帮助邻居们,即使自己的生活也不宽裕。
胡同里的生活是平静的,每天清晨,人们就开始忙碌起来。有的人挑着水桶去井边打水,有的人牵着羊去街上卖奶,有的人挑着菜担子去菜市场。这种平静的生活在战争来临之前是那么的珍贵,人们都珍惜着这样的日子。邻里之间相互照顾,孩子们在院子里玩耍,老人们在门口晒太阳聊天。
冠晓荷是个复杂的人物,他有文化,也有野心。在日本人占领北平的时候,他选择了与敌人合作,这让胡同里的人们都看不起他。但是他的妻子还是个好人,只是被丈夫连累了。冠晓荷的选择代表了那个时代一部分知识分子的软弱和妥协,他们在民族大义和个人利益之间选择了后者。
春天来了,胡同里的槐树发芽了,小鸟们在枝头歌唱。孩子们在院子里玩耍,老人们在门口晒太阳。这样的日子让人感到温暖和希望。即使在最黑暗的时期,生活依然要继续,人们依然要保持对美好未来的希望。春天的到来总是能够给人们带来新的希望和力量。
战争的阴云笼罩着整个城市,胡同里的人们也感受到了压力。有的人选择了抗争,有的人选择了妥协,有的人选择了逃避。每个人都在用自己的方式应对这个艰难的时代。祁瑞宣面临着痛苦的选择,他既不愿意与日本人合作,也不敢公开反抗,这种内心的煎熬让他备受折磨。
老舍先生用他细腻的笔触描绘了胡同里的众生相,每个人物都有自己的特点和命运。他们的喜怒哀乐构成了这部伟大作品的丰富内涵。从祁老爷子的达观,到祁瑞宣的痛苦,从韵梅的坚强,到冠晓荷的堕落,每个人物都是那个时代的缩影。
在那个动荡的年代,普通人的生活是不容易的。他们要面对战争的威胁,要面对生活的困难,要面对道德的选择。但是他们依然坚强地活着,为了家人,为了希望。即使在最困难的时候,人们依然保持着对美好生活的向往。
胡同里的邻里关系是复杂的,有友好的,也有矛盾的。但是在大的困难面前,大家还是会相互帮助。这种邻里之间的温情是中华民族传统文化的重要组成部分。在那个特殊的年代,这种人与人之间的温情显得更加珍贵。
祁瑞宣是个有理想的青年,他受过良好的教育,有自己的抱负。但是在日本人占领期间,他的理想和现实之间产生了尖锐的矛盾。他不愿意做汉奸,但是也不能完全抵抗。这种内心的矛盾和痛苦是那个时代很多知识分子的真实写照。
小妞子是个可爱的孩子,她的天真无邪给这个沉重的故事增添了一丝亮色。她不懂得大人们的复杂心理,只是简单地生活着,快乐着。孩子们的天真和快乐在那个黑暗的年代显得格外珍贵,它们代表着生活的希望和未来。
程长顺是个朴实的人,他没有什么文化,但是有自己的原则和底线。他不愿意向日本人低头,宁愿过艰苦的生活也要保持自己的尊严。他的坚持代表了中国人民不屈不挠的精神,即使在最困难的时候也不愿意妥协。
胡同里的生活节奏是缓慢的,人们有时间去观察周围的变化,去思考生活的意义。这种慢节奏的生活在今天看来是珍贵的,它让人们有机会去体验生活的细节。在那个年代,即使生活艰难,人们依然能够从平凡的日常中找到乐趣。
老二是个有个性的人,他不愿意受约束,喜欢自由自在的生活。但是在战争年代,这种个性给他带来了麻烦,也给家人带来了担忧。他的反叛精神在某种程度上代表着年轻一代对传统束缚的反抗,但在那个特殊的时代,这种反抗往往会带来意想不到的后果。
胡同里的四合院是北京传统建筑的代表,它们见证了一代又一代人的生活。每个院子里都有自己的故事,每个房间里都有自己的记忆。这些古老的建筑承载着深厚的历史文化底蕴,即使在战争的破坏下,依然坚强地屹立着。
在《四世同堂》这部作品中,老舍先生不仅描绘了个人的命运,也反映了整个民族的命运。小胡同里的故事其实就是大中国的缩影。每个人物的遭遇都代表着那个时代某一类人的命运,他们的选择和结局反映了整个民族在那个特殊历史时期的精神状态。
战争结束了,但是人们心中的创伤需要时间来愈合。胡同里的人们重新开始了正常的生活,但是那段艰难的经历永远不会被忘记。历史的教训提醒着人们珍惜和平,珍惜现在的美好生活。四世同堂的故事将永远流传下去,成为后人了解那个时代的重要窗口。
"""
return content.strip()
def split_text_randomly(self, text, min_length=100, max_length=200):
"""
将文本按100-200字的随机长度进行分割
"""
# 清理文本,移除多余的空白字符
text = ''.join(text.split())
segments = []
start = 0
while start < len(text):
# 随机选择段落长度
segment_length = random.randint(min_length, max_length)
end = min(start + segment_length, len(text))
segment = text[start:end]
if segment.strip(): # 确保段落不为空
segments.append(segment.strip())
start = end
return segments
def generate_random_content(self, base_content):
"""
基于基础内容生成随机变化的内容
"""
# 随机选择一个基础段落
base_paragraph = random.choice(base_content)
# 随机添加一些变化
variations = [
"在那个年代,",
"据说,",
"人们常常说,",
"老一辈人总是提到,",
"历史记录显示,",
"根据回忆,",
"有人说,",
"大家都知道,",
"传说中,",
"众所周知,"
]
endings = [
"这就是当时的情况。",
"这样的事情在那个年代很常见。",
"这个故事至今还在流传。",
"这是一个值得回忆的故事。",
"这样的经历让人难以忘怀。",
"这就是老北京的生活。",
"这种精神值得我们学习。",
"这个时代已经过去了。",
"这样的生活现在已经很难看到了。",
"这是历史的见证。"
]
# 随机组合内容
if random.random() < 0.3:
content = random.choice(variations) + base_paragraph
else:
content = base_paragraph
if random.random() < 0.3:
content += random.choice(endings)
return content
def generate_document(self, text_segments, doc_id):
"""基于文本段落生成一个文档"""
# 随机选择一个文本段落
content = random.choice(text_segments)
# 生成随机的额外字段以增加文档大小
random_field = ''.join(random.choices('abcdefghijklmnopqrstuvwxyz0123456789', k=random.randint(100, 500)))
doc = {
"chapter": f"第{random.randint(1, 100)}章",
"content": content,
"timestamp": datetime.now(),
"word_count": len(content),
"paragraph_id": f"para_{doc_id}",
"random_field": random_field
}
return doc
def get_index_size_gb(self):
"""获取索引大小(GB)"""
try:
response = self.session.get(f"{self.es_url}/_cat/indices/{self.index_name}?bytes=b&h=store.size&format=json")
if response.status_code == 200:
data = response.json()
if data and len(data) > 0:
size_bytes = int(data[0]['store.size'])
size_gb = size_bytes / (1024 * 1024 * 1024)
return size_gb
return 0
except Exception as e:
logger.error(f"获取索引大小失败: {e}")
return 0
def bulk_insert(self, documents):
"""批量插入文档使用HTTP bulk API"""
# 构建bulk请求体
bulk_data = []
for doc in documents:
# 添加action行
action = {"index": {"_index": self.index_name}}
bulk_data.append(json.dumps(action))
# 添加文档行
bulk_data.append(json.dumps(doc, ensure_ascii=False, default=str))
# 每行以换行符结束,最后也要有换行符
bulk_body = '\n'.join(bulk_data) + '\n'
try:
response = self.session.post(
f"{self.es_url}/_bulk",
headers={'Content-Type': 'application/x-ndjson'},
data=bulk_body.encode('utf-8'),
timeout=30 # 添加超时设置
)
if response.status_code == 200:
result = response.json()
# 检查是否有错误
if result.get('errors'):
error_count = 0
error_details = []
for item in result['items']:
if 'error' in item.get('index', {}):
error_count += 1
error_info = item['index']['error']
error_details.append(f"类型: {error_info.get('type')}, 原因: {error_info.get('reason')}")
if error_count > 0:
logger.warning(f"批量插入有 {error_count} 个错误")
# 打印前5个错误的详细信息
for i, error in enumerate(error_details[:5]):
logger.error(f"错误 {i+1}: {error}")
if len(error_details) > 5:
logger.error(f"... 还有 {len(error_details)-5} 个类似错误")
return True
else:
logger.error(f"批量插入失败: HTTP {response.status_code} - {response.text}")
return False
except requests.exceptions.SSLError as e:
logger.error(f"SSL连接错误: {e}")
logger.error("建议检查ES集群的SSL配置或使用 --no-verify-ssl 参数")
return False
except requests.exceptions.ConnectionError as e:
logger.error(f"连接错误: {e}")
logger.error("请检查ES集群地址和端口是否正确")
return False
except requests.exceptions.Timeout as e:
logger.error(f"请求超时: {e}")
logger.error("ES集群响应超时,可能负载过高")
return False
except Exception as e:
logger.error(f"批量插入失败: {e}")
logger.error(f"错误类型: {type(e).__name__}")
return False
def run(self):
"""运行数据生成器"""
start_time = time.time()
start_datetime = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
logger.info(f"开始生成数据,开始时间: {start_datetime},目标bulk次数: {self.target_bulk_count}")
# 加载文本内容
text_content = self.load_text_content()
# 将文本分割成100-200字的段落
text_segments = self.split_text_randomly(text_content, min_length=100, max_length=200)
logger.info(f"分割出 {len(text_segments)} 个文本段落")
doc_count = 0
bulk_count = 0
bulk_times = [] # 记录每次bulk的耗时
while bulk_count < self.target_bulk_count:
# 生成批量文档
documents = []
for i in range(self.batch_size):
doc = self.generate_document(text_segments, doc_count + i)
documents.append(doc)
# 记录单次bulk开始时间
bulk_start = time.time()
# 批量插入
if self.bulk_insert(documents):
bulk_end = time.time()
bulk_duration = bulk_end - bulk_start
bulk_times.append(bulk_duration)
doc_count += self.batch_size
bulk_count += 1
# 定期检查和报告进度
if bulk_count % self.check_interval == 0:
current_size = self.get_index_size_gb()
avg_bulk_time = sum(bulk_times[-self.check_interval:]) / len(bulk_times[-self.check_interval:])
logger.info(f"已完成 {bulk_count} 次bulk操作,插入 {doc_count} 条文档,当前索引大小: {current_size:.2f}GB,最近{self.check_interval}次bulk平均耗时: {avg_bulk_time:.3f}秒")
# 避免过于频繁的插入
#time.sleep(0.01) # 减少延迟,提高测试速度
end_time = time.time()
end_datetime = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
total_duration = end_time - start_time
# 计算统计信息
final_size = self.get_index_size_gb()
avg_bulk_time = sum(bulk_times) / len(bulk_times) if bulk_times else 0
total_docs_per_sec = doc_count / total_duration if total_duration > 0 else 0
bulk_per_sec = bulk_count / total_duration if total_duration > 0 else 0
logger.info(f"数据生成完成!")
logger.info(f"开始时间: {start_datetime}")
logger.info(f"结束时间: {end_datetime}")
logger.info(f"总耗时: {total_duration:.2f}秒 ({total_duration/60:.2f}分钟)")
logger.info(f"总计完成: {bulk_count} 次bulk操作")
logger.info(f"总计插入: {doc_count} 条文档")
logger.info(f"最终索引大小: {final_size:.2f}GB")
logger.info(f"平均每次bulk耗时: {avg_bulk_time:.3f}秒")
logger.info(f"平均bulk速率: {bulk_per_sec:.2f}次/秒")
logger.info(f"平均文档写入速率: {total_docs_per_sec:.0f}条/秒")
def main():
"""主函数"""
parser = argparse.ArgumentParser(description='四世同堂中文内容写入 Elasticsearch 脚本')
parser.add_argument('--host', default='localhost', help='ES 主机地址 (默认: localhost)')
parser.add_argument('--port', type=int, default=9200, help='ES 端口 (默认: 9200)')
parser.add_argument('--index', required=True, help='索引名称 (必填)')
parser.add_argument('--bulk-count', type=int, default=1000, help='目标 bulk 次数 (默认: 10000)')
parser.add_argument('--batch-size', type=int, default=1000, help='每次 bulk 的文档数量 (默认: 1000)')
parser.add_argument('--https', action='store_true', help='使用 HTTPS 协议')
parser.add_argument('--username', help='ES 用户名')
parser.add_argument('--password', help='ES 密码')
parser.add_argument('--no-verify-ssl', action='store_true', help='禁用 SSL 证书验证(默认已禁用)')
args = parser.parse_args()
protocol = "HTTPS" if args.https else "HTTP"
auth_info = f"认证: {args.username}" if args.username else "无认证"
ssl_info = "禁用SSL验证" if args.https else ""
logger.info(f"开始运行脚本,参数: {protocol}://{args.host}:{args.port}, 索引={args.index}, bulk次数={args.bulk_count}, {auth_info} {ssl_info}")
try:
generator = ESDataGenerator(
args.host,
args.port,
args.index,
args.bulk_count,
args.batch_size,
args.https,
args.username,
args.password,
not args.no_verify_ssl # 传入verify_ssl参数,但实际上总是False
)
generator.run()
except KeyboardInterrupt:
logger.info("用户中断了程序")
except Exception as e:
logger.error(f"程序运行出错: {e}")
logger.error(f"错误类型: {type(e).__name__}")
if **name** == "**main**":
main()
根据脚本中的测试文本添加的词库如下:
POST .analysis_ik/\_doc
{
"dict_type": "main_dicts",
"dict_key": "test_dic",
"dict_content": """祁老人
祁天佑
韵梅
祁瑞宣
老二
钱默吟
小顺子
李四大爷
冠晓荷
小妞子
程长顺
老舍
李四大爷
小羊圈胡同
北平城
胡同
小茶馆
小门脸
小房屋
四合院
院子
祁家
小院子
杂货铺
小铺子
井边
街上
菜市场
门口
枝头
城市
房间
北京
清朝
民国
战乱
战争
日本人
抗战
大槐树
槐树
小鸟
羊
门脸
房屋
水桶
菜担子
铺子
老头儿
儿子
教书先生
儿媳妇
女人
大家庭
孩子
孩子们
街坊邻居
妻子
老人
文人
知识分子
青年
汉奸
岁月
一生
变迁
衰落
建立
态度
威望
尊严
学问
诗
性格
时局
见解
小天地
精神
慰藉
现实
无力
气节
笑声
生机
阴霾
天真
快乐
希望
烦恼
童年
生意
生活
物资
年代
经营
日子
邻里
文化
野心
敌人
选择
软弱
妥协
民族大义
个人利益
温暖
时期
未来
力量
压力
抗争
逃避
方式
时代
煎熬
折磨
笔触
众生相
人物
特点
命运
喜怒哀乐
内涵
达观
痛苦
坚强
堕落
缩影
威胁
困难
道德
家人
向往
关系
矛盾
温情
传统文化
组成部分
理想
教育
抱负
占领
写照
亮色
心理
原则
底线
节奏
意义
细节
乐趣
个性
约束
麻烦
担忧
反叛精神
束缚
反抗
后果
建筑
代表
故事
记忆
历史文化底蕴
破坏
作品
创伤
经历
教训
和平
窗口
清晨
春天
内心
玩耍
聊天
晒太阳
歌唱
合作
打水
卖奶
帮助
"""
}进行 2 次集中写入的记录如下:
# ik_max_test
2025-07-13 20:15:33,294 - INFO - 开始时间: 2025-07-13 19:45:07
2025-07-13 20:15:33,294 - INFO - 结束时间: 2025-07-13 20:15:33
2025-07-13 20:15:33,294 - INFO - 总耗时: 1825.31秒 (30.42分钟)
2025-07-13 20:15:33,294 - INFO - 总计完成: 1000 次bulk操作
2025-07-13 20:15:33,294 - INFO - 总计插入: 1000000 条文档
2025-07-13 20:15:33,294 - INFO - 最终索引大小: 0.92GB
2025-07-13 20:15:33,294 - INFO - 平均每次bulk耗时: 1.790秒
2025-07-13 20:15:33,294 - INFO - 平均bulk速率: 0.55次/秒
2025-07-13 20:15:33,294 - INFO - 平均文档写入速率: 548条/秒
# ik_custom_test
2025-07-13 21:17:47,309 - INFO - 开始时间: 2025-07-13 20:44:03
2025-07-13 21:17:47,309 - INFO - 结束时间: 2025-07-13 21:17:47
2025-07-13 21:17:47,309 - INFO - 总耗时: 2023.53秒 (33.73分钟)
2025-07-13 21:17:47,309 - INFO - 总计完成: 1000 次bulk操作
2025-07-13 21:17:47,309 - INFO - 总计插入: 1000000 条文档
2025-07-13 21:17:47,309 - INFO - 最终索引大小: 0.92GB
2025-07-13 21:17:47,309 - INFO - 平均每次bulk耗时: 1.986秒
2025-07-13 21:17:47,309 - INFO - 平均bulk速率: 0.49次/秒
2025-07-13 21:17:47,309 - INFO - 平均文档写入速率: 494条/秒可以看到,有一定损耗,自定义词库词典的效率是之前的 90%。
相关阅读
关于 IK Analysis

IK Analysis 插件集成了 Lucene IK 分析器,并支持自定义词典。它支持 Easysearch\Elasticsearch\OpenSearch 的主要版本。由 INFINI Labs 维护并提供支持。
该插件包含分析器:ik_smart 和 ik_max_word,以及分词器:ik_smart 和 ik_max_word
开源地址:https://github.com/infinilabs/analysis-ik
作者:金多安,极限科技(INFINI Labs)搜索运维专家,Elastic 认证专家,搜索客社区日报责任编辑。一直从事与搜索运维相关的工作,日常会去挖掘 ES / Lucene 方向的搜索技术原理,保持搜索相关技术发展的关注。
原文:https://infinilabs.cn/blog/2025/ik-field-level-dictionarys-3/
背景知识:词库的作用
IK 分词器是一款基于词典匹配的中文分词器,其准确性和召回率与 IK 使用的词库也有不小的关系。
这里我们先了解一下词典匹配法的作用流程:
- 预先准备一个大规模的词典,用算法在文本中寻找词典里的最长匹配项。这种方法实现简单且速度快。
- 但面临歧义切分和未登录词挑战:同一序列可能有不同切分方式(例如“北京大学生”可以切成“北京大学/生”或“北京/大学生”),需要规则或算法消除歧义;
- 而词典中没有的新词(如网络流行语、人名等)无法正确切分。
可以看到词库是词元产生的比对基础,一个完善的中文词库能大大提高分词器的准确性和召回率。
IK 使用的词库是中文中常见词汇的合集,完善且丰富,ik_smart 和 ik_max_word 也能满足大部分中文分词的场景需求。但是针对一些专业的场景,比如医药这样的行业词库、电商搜索词、新闻热点词等,IK 是很难覆盖到的。这时候就需要使用者自己去维护自定义的词库了。
IK 的自定义词库加载方式
IK 本身也支持自定义词库的加载和更新的,但是只支持一个集群使用一个词库。
这里主要的制约因素是,词库对象与 ik 的中文分词器执行对象是一一对应的关系。
这导致了 IK 的词库面对不同中文分词场景时较低的灵活性,使用者并不能做到字段级别的词库加载。并且基于文件或者 http 协议的词库加载方式也需要不小的维护成本。
字段级别词库的加载
鉴于上述的背景问题,INFINI lab 加强了 IK 的词库加载逻辑,做到了字段级别的词库加载。同时将自定义词库的加载方式由外部文件/远程访问改成了内部索引查询。
主要逻辑如图:
这里 IK 多中文词库的加载优化主要基于 IK 可以加载多词类对象(即下面这段代码)的灵活性,将原来遍历一个 CJK 词类对象修改成遍历多个 CJK 词类对象,各个自定义词库可以附着在 CJK 词库对象上实现不同词库的分词。
do{
//遍历子分词器
for(ISegmenter segmenter : segmenters){
segmenter.analyze(context);
}
//字符缓冲区接近读完,需要读入新的字符
if(context.needRefillBuffer()){
break;
}
}对默认词库的新增支持
对于默认词库的修改,新版 IK 也可以通过写入词库索引方式支持,只要将 dict_key 设置为 default 即可。
POST .analysis_ik/_doc
{
"dict_key": "default",
"dict_type": "main_dicts",
"dict_content":"杨树林"
}效率测试
测试方案 1:单条测试
测试方法:写入一条数据到默认 ik_max_word 和自定义词库,查看是否有明显的效率差距
- 创建测试索引,自定义一个包括默认词库的 IK 分词器
PUT my-index-000001
{
"settings": {
"number_of_shards": 3,
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "my_tokenizer"
}
},
"tokenizer": {
"my_tokenizer": {
"type": "ik_max_word",
"custom_dict_enable": true,
"load_default_dicts":true,
"lowcase_enable": true,
"dict_key": "test_dic"
}
}
}
},
"mappings": {
"properties": {
"test_ik": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
}
}- 将该词库重复默认词库的内容
POST .analysis_ik/_doc
{
"dict_key": "test_dic",
"dict_type": "main_dicts",
"dict_content":"""xxxx #词库内容
"""
}
# debug 日志
[2025-07-09T16:37:43,112][INFO ][o.w.a.d.Dictionary ] [ik-1] Loaded 275909 words from main_dicts dictionary for dict_key: test_dic- 测试默认词库和自定义词库的分词效率
GET my-index-000001/_analyze
{
"analyzer": "my_custom_analyzer",
"text":"自强不息,杨树林"
}
GET my-index-000001/_analyze
{
"analyzer": "ik_max_word",
"text":"自强不息,杨树林"
}
打开 debug 日志,可以看到自定义分词器在不同的词库找到了 2 次“自强不息”
...
[2025-07-09T16:52:22,937][INFO ][o.w.a.c.CN_QuantifierSegmenter] [ik-1] 当前扫描词元[息]不需要启动量词扫描
[2025-07-09T16:52:22,937][INFO ][o.w.a.c.CJKSegmenter ] [ik-1] >>> WORD FOUND [自强不息] from dict [default]
[2025-07-09T16:52:22,937][INFO ][o.w.a.c.CJKSegmenter ] [ik-1] >>> WORD FOUND [不息] from dict [default]
[2025-07-09T16:52:22,937][INFO ][o.w.a.c.CJKSegmenter ] [ik-1] >>> WORD FOUND [自强不息] from dict [test_dic]
[2025-07-09T16:52:22,937][INFO ][o.w.a.c.CJKSegmenter ] [ik-1] >>> WORD FOUND [不息] from dict [test_dic]
[2025-07-09T16:52:22,937][INFO ][o.w.a.c.CN_QuantifierSegmenter] [ik-1] 当前扫描词元[,]不需要启动量词扫描
...而默认词库只有一次
...
[2025-07-09T16:54:22,618][INFO ][o.w.a.c.CN_QuantifierSegmenter] [ik-1] 当前扫描词元[息]不需要启动量词扫描
[2025-07-09T16:54:22,618][INFO ][o.w.a.c.CJKSegmenter ] [ik-1] >>> WORD FOUND [自强不息] from dict [default]
[2025-07-09T16:54:22,618][INFO ][o.w.a.c.CJKSegmenter ] [ik-1] >>> WORD FOUND [不息] from dict [default]
[2025-07-09T16:54:22,618][INFO ][o.w.a.c.CN_QuantifierSegmenter] [ik-1] 当前扫描词元[,]不需要启动量词扫描
...测试方案 2:持续写入测试
测试方法:在 ik_max_word 和自定义词库的索引里,分别持续 bulk 写入,查看总体写入延迟。
测试索引:
# ik_max_word索引
PUT ik_max_test
{
"mappings": {
"properties": {
"chapter": {
"type": "keyword"
},
"content": {
"type": "text",
"analyzer": "ik_max_word"
},
"paragraph_id": {
"type": "keyword"
},
"random_field": {
"type": "text"
},
"timestamp": {
"type": "keyword"
},
"word_count": {
"type": "integer"
}
}
},
"settings": {
"index": {
"number_of_shards": "1",
"number_of_replicas": "0"
}
}
}
# 自定义词库索引
PUT ik_custom_test
{
"mappings": {
"properties": {
"chapter": {
"type": "keyword"
},
"content": {
"type": "text",
"analyzer": "my_custom_analyzer"
},
"paragraph_id": {
"type": "keyword"
},
"random_field": {
"type": "text"
},
"timestamp": {
"type": "keyword"
},
"word_count": {
"type": "integer"
}
}
},
"settings": {
"index": {
"number_of_shards": "1",
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "my_tokenizer"
}
},
"tokenizer": {
"my_tokenizer": {
"load_default_dicts": "true",
"type": "ik_max_word",
"dict_key": "test_dic",
"lowcase_enable": "true",
"custom_dict_enable": "true"
}
}
},
"number_of_replicas": "0"
}
}
}
这里利用脚本循环写入了一段《四世同堂》的文本,比较相同次数下,两次写入的总体延迟。
测试脚本内容如下:
#!/usr/bin/env python3
# -_- coding: utf-8 -_-
"""
四世同堂中文内容随机循环写入 Elasticsearch 脚本
目标:生成指定 bulk 次数的索引内容
"""
import random
import time
import json
from datetime import datetime
import requests
import logging
import os
import argparse
import urllib3
# 配置日志
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(**name**)
class ESDataGenerator:
def **init**(self, es_host='localhost', es_port=9200, index_name='sisitontang_content',
target_bulk_count=10000, batch_size=1000, use_https=False, username=None, password=None, verify_ssl=True):
"""
初始化 ES 连接和配置
"""
protocol = 'https' if use_https else 'http'
self.es_url = f'{protocol}://{es_host}:{es_port}'
self.index_name = index_name
self.target_bulk_count = target_bulk_count # 目标 bulk 次数
self.batch_size = batch_size
self.check_interval = 1000 # 每 1000 次 bulk 检查一次进度
# 设置认证信息
self.auth = None
if username and password:
self.auth = (username, password)
logger.info(f"使用用户名认证: {username}")
# 设置请求会话
self.session = requests.Session()
if self.auth:
self.session.auth = self.auth
# 处理HTTPS和SSL证书验证
if use_https:
self.session.verify = False # 始终禁用SSL验证以避免证书问题
logger.info("警告:已禁用SSL证书验证(适合开发测试环境)")
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
# 设置SSL适配器以处理连接问题
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
# 配置重试策略
retry_strategy = Retry(
total=3,
backoff_factor=1,
status_forcelist=[429, 500, 502, 503, 504],
)
adapter = HTTPAdapter(max_retries=retry_strategy)
self.session.mount("https://", adapter)
# 设置更宽松的SSL上下文
self.session.verify = False
logger.info(f"ES连接地址: {self.es_url}")
# 创建索引映射
self.create_index()
def create_index(self):
"""创建索引和映射"""
mapping = {
"mappings": {
"properties": {
"chapter": {"type": "keyword"},
"content": {"type": "text", "analyzer": "ik_max_word"},
"timestamp": {"type": "date"},
"word_count": {"type": "integer"},
"paragraph_id": {"type": "keyword"},
"random_field": {"type": "text"}
}
}
}
try:
# 检查索引是否存在
response = self.session.head(f"{self.es_url}/{self.index_name}")
if response.status_code == 200:
logger.info(f"索引 {self.index_name} 已存在")
else:
# 创建索引
response = self.session.put(
f"{self.es_url}/{self.index_name}",
headers={'Content-Type': 'application/json'},
json=mapping
)
if response.status_code in [200, 201]:
logger.info(f"创建索引 {self.index_name} 成功")
else:
logger.error(f"创建索引失败: {response.status_code} - {response.text}")
except Exception as e:
logger.error(f"创建索引失败: {e}")
def load_text_content(self, file_path='sisitontang.txt'):
"""
从文件加载《四世同堂》的完整文本内容
如果文件不存在,则返回扩展的示例内容
"""
if os.path.exists(file_path):
try:
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
logger.info(f"从文件 {file_path} 加载了 {len(content)} 个字符的文本内容")
return content
except Exception as e:
logger.error(f"读取文件失败: {e}")
# 如果文件不存在,返回扩展的示例内容
logger.info("使用内置的扩展示例内容")
return self.get_extended_sample_content()
def get_extended_sample_content(self):
"""
获取扩展的《四世同堂》示例内容
"""
content = """
小羊圈胡同是北平城里的一个小胡同。它不宽,可是很长,从东到西有一里多路。在这条胡同里,从东边数起,有个小茶馆,几个小门脸,和一群小房屋。小茶馆的斜对面是个较大的四合院,院子里有几棵大槐树。这个院子就是祁家的住所,四世同堂的大家庭就在这里度过了最困难的岁月。
祁老人是个善良的老头儿,虽然年纪大了,可是还很有精神。他的一生见证了太多的变迁,从清朝的衰落到民国的建立,再到现在的战乱,他都以一种达观的态度面对着。他的儿子祁天佑是个教书先生,为人正直,在胡同里很有威望。祁家的儿媳妇韵梅是个贤惠的女人,把家里打理得井井有条,即使在最困难的时候,也要维持着家庭的尊严。
钱默吟先生是个有学问的人,他的诗写得很好,可是性格有些古怪。他住在胡同深处的一个小院子里,平时很少出门,只是偶尔到祁家坐坐,和祁天佑聊聊古今。他对时局有着自己独特的见解,但更多的时候,他选择在自己的小天地里寻找精神的慰藉。战争的残酷现实让这个文人感到深深的无力,但他依然坚持着自己的文人气节。
小顺子是个活泼的孩子,他每天都在胡同里跑来跑去,和其他的孩子们一起玩耍。他的笑声总是能感染到周围的人,让这个古老的胡同充满了生机。即使在战争的阴霾下,孩子们依然保持着他们的天真和快乐,这或许就是生活的希望所在。小顺子不懂得大人们的烦恼,他只是简单地享受着童年的快乐。
李四大爷是个老实人,他在胡同里开了个小杂货铺。虽然生意不大,但是童叟无欺,街坊邻居们都愿意到他这里买东西。他的妻子是个能干的女人,把小铺子管理得很好。在那个物资匮乏的年代,能够维持一个小铺子的经营已经很不容易了。李四大爷经常帮助邻居们,即使自己的生活也不宽裕。
胡同里的生活是平静的,每天清晨,人们就开始忙碌起来。有的人挑着水桶去井边打水,有的人牵着羊去街上卖奶,有的人挑着菜担子去菜市场。这种平静的生活在战争来临之前是那么的珍贵,人们都珍惜着这样的日子。邻里之间相互照顾,孩子们在院子里玩耍,老人们在门口晒太阳聊天。
冠晓荷是个复杂的人物,他有文化,也有野心。在日本人占领北平的时候,他选择了与敌人合作,这让胡同里的人们都看不起他。但是他的妻子还是个好人,只是被丈夫连累了。冠晓荷的选择代表了那个时代一部分知识分子的软弱和妥协,他们在民族大义和个人利益之间选择了后者。
春天来了,胡同里的槐树发芽了,小鸟们在枝头歌唱。孩子们在院子里玩耍,老人们在门口晒太阳。这样的日子让人感到温暖和希望。即使在最黑暗的时期,生活依然要继续,人们依然要保持对美好未来的希望。春天的到来总是能够给人们带来新的希望和力量。
战争的阴云笼罩着整个城市,胡同里的人们也感受到了压力。有的人选择了抗争,有的人选择了妥协,有的人选择了逃避。每个人都在用自己的方式应对这个艰难的时代。祁瑞宣面临着痛苦的选择,他既不愿意与日本人合作,也不敢公开反抗,这种内心的煎熬让他备受折磨。
老舍先生用他细腻的笔触描绘了胡同里的众生相,每个人物都有自己的特点和命运。他们的喜怒哀乐构成了这部伟大作品的丰富内涵。从祁老爷子的达观,到祁瑞宣的痛苦,从韵梅的坚强,到冠晓荷的堕落,每个人物都是那个时代的缩影。
在那个动荡的年代,普通人的生活是不容易的。他们要面对战争的威胁,要面对生活的困难,要面对道德的选择。但是他们依然坚强地活着,为了家人,为了希望。即使在最困难的时候,人们依然保持着对美好生活的向往。
胡同里的邻里关系是复杂的,有友好的,也有矛盾的。但是在大的困难面前,大家还是会相互帮助。这种邻里之间的温情是中华民族传统文化的重要组成部分。在那个特殊的年代,这种人与人之间的温情显得更加珍贵。
祁瑞宣是个有理想的青年,他受过良好的教育,有自己的抱负。但是在日本人占领期间,他的理想和现实之间产生了尖锐的矛盾。他不愿意做汉奸,但是也不能完全抵抗。这种内心的矛盾和痛苦是那个时代很多知识分子的真实写照。
小妞子是个可爱的孩子,她的天真无邪给这个沉重的故事增添了一丝亮色。她不懂得大人们的复杂心理,只是简单地生活着,快乐着。孩子们的天真和快乐在那个黑暗的年代显得格外珍贵,它们代表着生活的希望和未来。
程长顺是个朴实的人,他没有什么文化,但是有自己的原则和底线。他不愿意向日本人低头,宁愿过艰苦的生活也要保持自己的尊严。他的坚持代表了中国人民不屈不挠的精神,即使在最困难的时候也不愿意妥协。
胡同里的生活节奏是缓慢的,人们有时间去观察周围的变化,去思考生活的意义。这种慢节奏的生活在今天看来是珍贵的,它让人们有机会去体验生活的细节。在那个年代,即使生活艰难,人们依然能够从平凡的日常中找到乐趣。
老二是个有个性的人,他不愿意受约束,喜欢自由自在的生活。但是在战争年代,这种个性给他带来了麻烦,也给家人带来了担忧。他的反叛精神在某种程度上代表着年轻一代对传统束缚的反抗,但在那个特殊的时代,这种反抗往往会带来意想不到的后果。
胡同里的四合院是北京传统建筑的代表,它们见证了一代又一代人的生活。每个院子里都有自己的故事,每个房间里都有自己的记忆。这些古老的建筑承载着深厚的历史文化底蕴,即使在战争的破坏下,依然坚强地屹立着。
在《四世同堂》这部作品中,老舍先生不仅描绘了个人的命运,也反映了整个民族的命运。小胡同里的故事其实就是大中国的缩影。每个人物的遭遇都代表着那个时代某一类人的命运,他们的选择和结局反映了整个民族在那个特殊历史时期的精神状态。
战争结束了,但是人们心中的创伤需要时间来愈合。胡同里的人们重新开始了正常的生活,但是那段艰难的经历永远不会被忘记。历史的教训提醒着人们珍惜和平,珍惜现在的美好生活。四世同堂的故事将永远流传下去,成为后人了解那个时代的重要窗口。
"""
return content.strip()
def split_text_randomly(self, text, min_length=100, max_length=200):
"""
将文本按100-200字的随机长度进行分割
"""
# 清理文本,移除多余的空白字符
text = ''.join(text.split())
segments = []
start = 0
while start < len(text):
# 随机选择段落长度
segment_length = random.randint(min_length, max_length)
end = min(start + segment_length, len(text))
segment = text[start:end]
if segment.strip(): # 确保段落不为空
segments.append(segment.strip())
start = end
return segments
def generate_random_content(self, base_content):
"""
基于基础内容生成随机变化的内容
"""
# 随机选择一个基础段落
base_paragraph = random.choice(base_content)
# 随机添加一些变化
variations = [
"在那个年代,",
"据说,",
"人们常常说,",
"老一辈人总是提到,",
"历史记录显示,",
"根据回忆,",
"有人说,",
"大家都知道,",
"传说中,",
"众所周知,"
]
endings = [
"这就是当时的情况。",
"这样的事情在那个年代很常见。",
"这个故事至今还在流传。",
"这是一个值得回忆的故事。",
"这样的经历让人难以忘怀。",
"这就是老北京的生活。",
"这种精神值得我们学习。",
"这个时代已经过去了。",
"这样的生活现在已经很难看到了。",
"这是历史的见证。"
]
# 随机组合内容
if random.random() < 0.3:
content = random.choice(variations) + base_paragraph
else:
content = base_paragraph
if random.random() < 0.3:
content += random.choice(endings)
return content
def generate_document(self, text_segments, doc_id):
"""基于文本段落生成一个文档"""
# 随机选择一个文本段落
content = random.choice(text_segments)
# 生成随机的额外字段以增加文档大小
random_field = ''.join(random.choices('abcdefghijklmnopqrstuvwxyz0123456789', k=random.randint(100, 500)))
doc = {
"chapter": f"第{random.randint(1, 100)}章",
"content": content,
"timestamp": datetime.now(),
"word_count": len(content),
"paragraph_id": f"para_{doc_id}",
"random_field": random_field
}
return doc
def get_index_size_gb(self):
"""获取索引大小(GB)"""
try:
response = self.session.get(f"{self.es_url}/_cat/indices/{self.index_name}?bytes=b&h=store.size&format=json")
if response.status_code == 200:
data = response.json()
if data and len(data) > 0:
size_bytes = int(data[0]['store.size'])
size_gb = size_bytes / (1024 * 1024 * 1024)
return size_gb
return 0
except Exception as e:
logger.error(f"获取索引大小失败: {e}")
return 0
def bulk_insert(self, documents):
"""批量插入文档使用HTTP bulk API"""
# 构建bulk请求体
bulk_data = []
for doc in documents:
# 添加action行
action = {"index": {"_index": self.index_name}}
bulk_data.append(json.dumps(action))
# 添加文档行
bulk_data.append(json.dumps(doc, ensure_ascii=False, default=str))
# 每行以换行符结束,最后也要有换行符
bulk_body = '\n'.join(bulk_data) + '\n'
try:
response = self.session.post(
f"{self.es_url}/_bulk",
headers={'Content-Type': 'application/x-ndjson'},
data=bulk_body.encode('utf-8'),
timeout=30 # 添加超时设置
)
if response.status_code == 200:
result = response.json()
# 检查是否有错误
if result.get('errors'):
error_count = 0
error_details = []
for item in result['items']:
if 'error' in item.get('index', {}):
error_count += 1
error_info = item['index']['error']
error_details.append(f"类型: {error_info.get('type')}, 原因: {error_info.get('reason')}")
if error_count > 0:
logger.warning(f"批量插入有 {error_count} 个错误")
# 打印前5个错误的详细信息
for i, error in enumerate(error_details[:5]):
logger.error(f"错误 {i+1}: {error}")
if len(error_details) > 5:
logger.error(f"... 还有 {len(error_details)-5} 个类似错误")
return True
else:
logger.error(f"批量插入失败: HTTP {response.status_code} - {response.text}")
return False
except requests.exceptions.SSLError as e:
logger.error(f"SSL连接错误: {e}")
logger.error("建议检查ES集群的SSL配置或使用 --no-verify-ssl 参数")
return False
except requests.exceptions.ConnectionError as e:
logger.error(f"连接错误: {e}")
logger.error("请检查ES集群地址和端口是否正确")
return False
except requests.exceptions.Timeout as e:
logger.error(f"请求超时: {e}")
logger.error("ES集群响应超时,可能负载过高")
return False
except Exception as e:
logger.error(f"批量插入失败: {e}")
logger.error(f"错误类型: {type(e).__name__}")
return False
def run(self):
"""运行数据生成器"""
start_time = time.time()
start_datetime = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
logger.info(f"开始生成数据,开始时间: {start_datetime},目标bulk次数: {self.target_bulk_count}")
# 加载文本内容
text_content = self.load_text_content()
# 将文本分割成100-200字的段落
text_segments = self.split_text_randomly(text_content, min_length=100, max_length=200)
logger.info(f"分割出 {len(text_segments)} 个文本段落")
doc_count = 0
bulk_count = 0
bulk_times = [] # 记录每次bulk的耗时
while bulk_count < self.target_bulk_count:
# 生成批量文档
documents = []
for i in range(self.batch_size):
doc = self.generate_document(text_segments, doc_count + i)
documents.append(doc)
# 记录单次bulk开始时间
bulk_start = time.time()
# 批量插入
if self.bulk_insert(documents):
bulk_end = time.time()
bulk_duration = bulk_end - bulk_start
bulk_times.append(bulk_duration)
doc_count += self.batch_size
bulk_count += 1
# 定期检查和报告进度
if bulk_count % self.check_interval == 0:
current_size = self.get_index_size_gb()
avg_bulk_time = sum(bulk_times[-self.check_interval:]) / len(bulk_times[-self.check_interval:])
logger.info(f"已完成 {bulk_count} 次bulk操作,插入 {doc_count} 条文档,当前索引大小: {current_size:.2f}GB,最近{self.check_interval}次bulk平均耗时: {avg_bulk_time:.3f}秒")
# 避免过于频繁的插入
#time.sleep(0.01) # 减少延迟,提高测试速度
end_time = time.time()
end_datetime = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
total_duration = end_time - start_time
# 计算统计信息
final_size = self.get_index_size_gb()
avg_bulk_time = sum(bulk_times) / len(bulk_times) if bulk_times else 0
total_docs_per_sec = doc_count / total_duration if total_duration > 0 else 0
bulk_per_sec = bulk_count / total_duration if total_duration > 0 else 0
logger.info(f"数据生成完成!")
logger.info(f"开始时间: {start_datetime}")
logger.info(f"结束时间: {end_datetime}")
logger.info(f"总耗时: {total_duration:.2f}秒 ({total_duration/60:.2f}分钟)")
logger.info(f"总计完成: {bulk_count} 次bulk操作")
logger.info(f"总计插入: {doc_count} 条文档")
logger.info(f"最终索引大小: {final_size:.2f}GB")
logger.info(f"平均每次bulk耗时: {avg_bulk_time:.3f}秒")
logger.info(f"平均bulk速率: {bulk_per_sec:.2f}次/秒")
logger.info(f"平均文档写入速率: {total_docs_per_sec:.0f}条/秒")
def main():
"""主函数"""
parser = argparse.ArgumentParser(description='四世同堂中文内容写入 Elasticsearch 脚本')
parser.add_argument('--host', default='localhost', help='ES 主机地址 (默认: localhost)')
parser.add_argument('--port', type=int, default=9200, help='ES 端口 (默认: 9200)')
parser.add_argument('--index', required=True, help='索引名称 (必填)')
parser.add_argument('--bulk-count', type=int, default=1000, help='目标 bulk 次数 (默认: 10000)')
parser.add_argument('--batch-size', type=int, default=1000, help='每次 bulk 的文档数量 (默认: 1000)')
parser.add_argument('--https', action='store_true', help='使用 HTTPS 协议')
parser.add_argument('--username', help='ES 用户名')
parser.add_argument('--password', help='ES 密码')
parser.add_argument('--no-verify-ssl', action='store_true', help='禁用 SSL 证书验证(默认已禁用)')
args = parser.parse_args()
protocol = "HTTPS" if args.https else "HTTP"
auth_info = f"认证: {args.username}" if args.username else "无认证"
ssl_info = "禁用SSL验证" if args.https else ""
logger.info(f"开始运行脚本,参数: {protocol}://{args.host}:{args.port}, 索引={args.index}, bulk次数={args.bulk_count}, {auth_info} {ssl_info}")
try:
generator = ESDataGenerator(
args.host,
args.port,
args.index,
args.bulk_count,
args.batch_size,
args.https,
args.username,
args.password,
not args.no_verify_ssl # 传入verify_ssl参数,但实际上总是False
)
generator.run()
except KeyboardInterrupt:
logger.info("用户中断了程序")
except Exception as e:
logger.error(f"程序运行出错: {e}")
logger.error(f"错误类型: {type(e).__name__}")
if **name** == "**main**":
main()
根据脚本中的测试文本添加的词库如下:
POST .analysis_ik/\_doc
{
"dict_type": "main_dicts",
"dict_key": "test_dic",
"dict_content": """祁老人
祁天佑
韵梅
祁瑞宣
老二
钱默吟
小顺子
李四大爷
冠晓荷
小妞子
程长顺
老舍
李四大爷
小羊圈胡同
北平城
胡同
小茶馆
小门脸
小房屋
四合院
院子
祁家
小院子
杂货铺
小铺子
井边
街上
菜市场
门口
枝头
城市
房间
北京
清朝
民国
战乱
战争
日本人
抗战
大槐树
槐树
小鸟
羊
门脸
房屋
水桶
菜担子
铺子
老头儿
儿子
教书先生
儿媳妇
女人
大家庭
孩子
孩子们
街坊邻居
妻子
老人
文人
知识分子
青年
汉奸
岁月
一生
变迁
衰落
建立
态度
威望
尊严
学问
诗
性格
时局
见解
小天地
精神
慰藉
现实
无力
气节
笑声
生机
阴霾
天真
快乐
希望
烦恼
童年
生意
生活
物资
年代
经营
日子
邻里
文化
野心
敌人
选择
软弱
妥协
民族大义
个人利益
温暖
时期
未来
力量
压力
抗争
逃避
方式
时代
煎熬
折磨
笔触
众生相
人物
特点
命运
喜怒哀乐
内涵
达观
痛苦
坚强
堕落
缩影
威胁
困难
道德
家人
向往
关系
矛盾
温情
传统文化
组成部分
理想
教育
抱负
占领
写照
亮色
心理
原则
底线
节奏
意义
细节
乐趣
个性
约束
麻烦
担忧
反叛精神
束缚
反抗
后果
建筑
代表
故事
记忆
历史文化底蕴
破坏
作品
创伤
经历
教训
和平
窗口
清晨
春天
内心
玩耍
聊天
晒太阳
歌唱
合作
打水
卖奶
帮助
"""
}进行 2 次集中写入的记录如下:
# ik_max_test
2025-07-13 20:15:33,294 - INFO - 开始时间: 2025-07-13 19:45:07
2025-07-13 20:15:33,294 - INFO - 结束时间: 2025-07-13 20:15:33
2025-07-13 20:15:33,294 - INFO - 总耗时: 1825.31秒 (30.42分钟)
2025-07-13 20:15:33,294 - INFO - 总计完成: 1000 次bulk操作
2025-07-13 20:15:33,294 - INFO - 总计插入: 1000000 条文档
2025-07-13 20:15:33,294 - INFO - 最终索引大小: 0.92GB
2025-07-13 20:15:33,294 - INFO - 平均每次bulk耗时: 1.790秒
2025-07-13 20:15:33,294 - INFO - 平均bulk速率: 0.55次/秒
2025-07-13 20:15:33,294 - INFO - 平均文档写入速率: 548条/秒
# ik_custom_test
2025-07-13 21:17:47,309 - INFO - 开始时间: 2025-07-13 20:44:03
2025-07-13 21:17:47,309 - INFO - 结束时间: 2025-07-13 21:17:47
2025-07-13 21:17:47,309 - INFO - 总耗时: 2023.53秒 (33.73分钟)
2025-07-13 21:17:47,309 - INFO - 总计完成: 1000 次bulk操作
2025-07-13 21:17:47,309 - INFO - 总计插入: 1000000 条文档
2025-07-13 21:17:47,309 - INFO - 最终索引大小: 0.92GB
2025-07-13 21:17:47,309 - INFO - 平均每次bulk耗时: 1.986秒
2025-07-13 21:17:47,309 - INFO - 平均bulk速率: 0.49次/秒
2025-07-13 21:17:47,309 - INFO - 平均文档写入速率: 494条/秒可以看到,有一定损耗,自定义词库词典的效率是之前的 90%。
相关阅读
关于 IK Analysis
IK Analysis 插件集成了 Lucene IK 分析器,并支持自定义词典。它支持 Easysearch\Elasticsearch\OpenSearch 的主要版本。由 INFINI Labs 维护并提供支持。
该插件包含分析器:ik_smart 和 ik_max_word,以及分词器:ik_smart 和 ik_max_word
开源地址:https://github.com/infinilabs/analysis-ik
收起阅读 »作者:金多安,极限科技(INFINI Labs)搜索运维专家,Elastic 认证专家,搜索客社区日报责任编辑。一直从事与搜索运维相关的工作,日常会去挖掘 ES / Lucene 方向的搜索技术原理,保持搜索相关技术发展的关注。
原文:https://infinilabs.cn/blog/2025/ik-field-level-dictionarys-3/
INFINI Labs 产品更新 | Coco AI v0.7.0 发布 - 全新的文件搜索体验与全屏化的集成功能

INFINI Labs 产品更新发布!此次更新主要包括 Coco AI v0.7.0 新增 macOS Spotlight 和 Windows 文件搜索支持、语音输入功能,以及全屏集成模式;Easysearch v1.14.0 引入完整文本嵌入模型、语义检索 API 和搜索管道功能等,全面提升产品性能和稳定性。
Coco AI v0.7.0
Coco AI 是一款完全开源、跨平台的企业级智能搜索与助手系统,专为现代企业打造。它通过统一搜索入口,连接企业内外部的异构数据源,融合大模型能力,帮助团队高效访问知识,智能决策协作。
Coco AI 本次详细更新记录如下:
Coco AI 客户端 v0.7.0
功能特性 (Features)
- 文件搜索支持 Spotlight(macOS) (#705)
- 语音输入支持(搜索模式 & 聊天模式) (#732)
- 文本转语音现已由 LLM 驱动 (#750)
- Windows 文件搜索支持 (#762)
问题修复 (Bug Fixes)
- 文件搜索:优先应用过滤器后再处理 from/size 参数 (#741)
- 文件搜索:按名称与内容搜索时未匹配文件名问题 (#743)
- 修复 Windows 平台窗口被移动时自动隐藏的问题 (#748)
- 修复删除快捷键时未注销扩展热键的问题 (#770)
- 修复应用索引未遵循搜索范围配置的问题 (#773)
- 修复子页面缺失分类标题的问题 (#772)
- 修复快捷 AI 入口显示错误的问题 (#779)
- 语音播放相关的小问题修复 (#780)
- 修复 Linux 平台任务栏图标显示异常 (#783)
- 修复子页面数据不一致问题 (#784)
- 修复扩展安装状态显示错误 (#789)
- 增加 HTTP 流请求的超时容忍度,提升稳定性 (#798)
- 修复回车键行为异常问题 (#794)
- 修复重命名后选中状态失效的问题 (#800)
- 修复 Windows 右键菜单中快捷键异常问题 (#804)
- 修复因 "state() 在 manage() 之前调用" 引起的 panic (#806)
- 修复多行输入问题 (#808)
- 修复 Ctrl+K 快捷键无效问题 (#815)
- 修复窗口配置同步失败问题 (#818)
- 修复子页面回车键无法使用问题 (#819)
- 修复 Ubuntu (GNOME) 下打开应用时崩溃问题 (#821)
改进优化 (Improvements)
- 文件状态检测优先使用
stat(2)(#737) - 文件搜索扩展类型重命名为 extension (#738)
- 创建聊天记录及发送聊天 API (#739)
- 更多文件类型图标支持 (#740)
- 替换 meval-rs 依赖,清除编译警告 (#745)
- Assistant、数据源、MCP Server 接口参数重构 (#746)
- 扩展代码结构调整 (#747)
- 升级
applications-rs依赖版本 (#751) - QuickLink/quick_link 重命名为 Quicklink/quicklink (#752)
- Assistant 样式与参数微调 (#753)
- 可选字段默认不强制要求填写 (#758)
- 搜索聊天组件新增 formatUrl、think 数据及图标地址支持 (#765)
- Coco App HTTP 请求统一添加请求头 (#744)
- 响应体反序列化前增加状态码判断 (#767)
- 启动页适配手机屏幕宽度 (#768)
- 搜索聊天新增语言参数与格式化 URL 参数 (#775)
- 未登录状态不请求用户接口 (#795)
- Windows 文件搜索清理查询字符串中的非法字符 (#802)
- 崩溃日志中展示 backtrace 信息 (#805)
相关截图
Coco AI 服务端 v0.7.0
功能特性 (Features)
- 重构了映射(mappings)的实现
- 新增了基于 HTTP 流式传输的聊天 API
- 新增了文件上传的配置选项
- 聊天消息中现已支持附件
- 为调试目的,增加记录大语言模型(LLM)请求的日志
- 新增 RSS 连接器
- 支持在初始化时配置模型的默认推理参数
- 新增本地文件系统(Local FS)连接器
- 新增 S3 连接器
问题修复(Bug Fixes)
- 修复了查询参数 "filter" 不生效的问题
- 修复了列表中分页功能不工作的问题
- 修复了在没有网络的情况下本地图标无法显示的问题
- 修复了大语言模型(LLM)提供商列表中状态显示不正确的问题
- 修复了带附件的聊天 API
- 防止了在 LLM 意图解析出错时可能出现的空指针异常
- 修复了删除多个 URL 输入框时功能不正常的问题
- 修复了启用本地模型提供商后状态未及时更新的问题
- 确保在 RAG(检索增强生成)处理过程中正确使用数据源
- 修复了提示词模板选择不正确的问题
- 防止了当用户取消正在进行的回复时可能导致回复消息丢失的问题
- 使第一条聊天消息可以被取消
改进优化 (Improvements)
- 重构了用户 ID 的处理方式
- 跳过空的流式响应数据块
- 重构了查询的实现
- 对更多敏感的搜索结果进行屏蔽处理
- 重构了附件相关的 API
- 为智能助理增加了上传设置
- 重构了 ORM 和安全接口
- 在附件上传 API 中移除了对
session_id的检查 - 为搜索框增加了
formatUrl功能 - 为集成页面增加了全屏模式
- 程序现在会忽略无效的连接器
- 程序现在会跳过无效的 MCP 服务器
- 对于内置的智能助理和提供商,隐藏了删除按钮
- 处理了提示词模板的默认值
- 如果某个集成功能被禁用,其按钮预览将显示为禁用状态
- 手动刷新流式输出的第一行数据,以改善响应体验
Easysearch v1.14.0
重大变更(Breaking Changes)
- AI 模块 从 modules 迁移至 plugins 目录下,方便调用 knn 插件
- 旧的文本向量化接口
_ai/embed已不再支持,将在后续版本删除
功能特性 (Features)
- 插件模块新增完整的文本嵌入模型集成功能,涵盖从数据导入到向量检索的全流程
- 新增语义检索 API,简化向量搜索使用流程
- 新增语义检索处理器配置大模型信息
- 新增搜索管道(Search pipelines),轻松地在 Easysearch 内部处理查询请求和查询结果
- 多模型集成支持
- OpenAI 向量模型:直接调用 OpenAI 的嵌入接口(如 text-embedding-3-small)
- Ollama 本地模型:支持离线环境或私有化部署的向量生成
- IK 分词器提供 reload API,能够对存量自定义词典进行完整更新
- IK 分词器能够通过词库索引对默认词库进行自定义添加
改进优化 (Improvements)
- 增强数据摄取管道(ingest pipeline)
- 在数据索引阶段支持文本向量化,文档可自动生成向量表示
- 导入数据时通过 ingest 管道进行向量化时支持单条和批量模式,适配大模型的请求限制场景
- 更新 Easysearch Docker 初始化文档
- IK 分词器优化自定义词库加载逻辑,减少内存占用
Console v1.29.8
INFINI Console 是一款开源的非常轻量级的多集群、跨版本的搜索基础设施统一管控平台。通过对流行的搜索引擎基础设施进行跨版本、多集群的集中纳管,企业可以快速方便的统一管理企业内部的不同版本的多套搜索集群。
Console 本次详细更新记录如下:
问题修复(Bug Fixes)
- 在获取分片级别的分片状态指标时,shard_id 参数未生效的问题
- 优化了监控图表中坐标轴标签的显示效果
- 在更改指标级别后,统计数据未刷新的问题
- 根据响应中的 key 来进行 rollup 检查
- 因 omitempty JSON 标签导致更新不生效时,改为使用 save 方法
改进优化 (Improvements)
- 为指标请求添加了自定义的超时错误处理
- 优化了动态分区逻辑
- 此版本包含了底层 Framework v1.2.0 的更新,解决了一些常见问题,并增强了整体稳定性和性能。虽然 Console 本身没有直接的变更,但从 Framework 中继承的改进间接地使 Console 受益。
Gateway v1.29.8
INFINI Gateway 是一个开源的面向搜索场景的高性能数据网关,所有请求都经过网关处理后再转发到后端的搜索业务集群。基于 INFINI Gateway 可以实现索引级别的限速限流、常见查询的缓存加速、查询请求的审计、查询结果的动态修改等等。
Gateway 本次更新如下:
改进优化 (Improvements)
- 此版本包含了底层 Framework v1.2.0 的更新,解决了一些常见问题,并增强了整体稳定性和性能。虽然 Gateway 本身没有直接的变更,但从 Framework 中继承的改进间接地使 Gateway 受益。
Agent v1.29.8
INFINI Agent 负责采集和上传 Elasticsearch, Easysearch, Opensearch 集群的日志和指标信息,通过 INFINI Console 管理,支持主流操作系统和平台,安装包轻量且无任何外部依赖,可以快速方便地安装。
Agent 本次更新如下:
功能特性 (Features)
- 在 Kubernetes 环境下通过环境变量
http.port探测 Easysearch 的 HTTP 端口
改进优化 (Improvements)
- 此版本包含了底层 Framework v1.2.0 的更新,解决了一些常见问题,并增强了整体稳定性和性能。虽然 Agent 本身没有直接的变更,但从 Framework 中继承的改进间接地使 Agent 受益。
Loadgen v1.29.8
INFINI Loadgen 是一款开源的专为 Easysearch、Elasticsearch、OpenSearch 设计的轻量级性能测试工具。
Loadgen 本次更新如下:
改进优化 (Improvements)
- 此版本包含了底层 Framework v1.2.0 的更新,解决了一些常见问题,并增强了整体稳定性和性能。虽然 Loadgen 本身没有直接的变更,但从 Framework 中继承的改进间接地使 Loadgen 受益。
Framework 1.2.0
INFINI Framework 是 INFINI Labs 基于 Golang 的产品的核心基础,已开源。该框架以开发者为中心设计,简化了构建高性能、可扩展且可靠的应用程序的过程。
Framework 本次更新如下:
功能特性 (Features)
- ORM 操作钩子 (Hooks):为 ORM(数据访问层)的数据操作新增了钩子(Hooks),允许进行更灵活的二次开发。
- 新增 Create API:新增了用于创建文档的
_createAPI 接口,确保文档 ID 的唯一性。 - URL
terms查询:现在 URL 的查询参数也支持terms类型的查询了,可以一次匹配多个值。
问题修复 (Bug Fixes)
- 修复了通过 HTTP 插件设置的自定义 HTTP 头部信息未被正确应用的问题。
- 修复了 JSON 解析器的一个问题,现在可以正确处理带引号的、且包含下划线
_的 JSON 键(key)。
改进 (Improvements)
- 查询过滤器优化: 系统现在会自动将多个针对同一字段的
term过滤器合并为一个更高效的terms过滤器,以提升查询性能。 - 查询接口重构: 对核心的查询接口进行了重构,使其结构更清晰,为未来的功能扩展打下基础。
更多详情请查看以下各产品的 Release Notes 或联系我们的技术支持团队!
- Coco AI App
- Coco AI Server
- INFINI Easysearch
- INFINI Console
- INFINI Gateway
- INFINI Agent
- INFINI Loadgen
- INFINI Framework
期待反馈
欢迎下载体验使用,如果您在使用过程中遇到如何疑问或者问题,欢迎前往 INFINI Labs Github(https://github.com/infinilabs) 中的对应项目中提交 Feature Request 或提交 Bug。
下载地址: https://infinilabs.cn/download
邮件:hello@infini.ltd
电话:(+86) 400-139-9200
Discord:https://discord.gg/4tKTMkkvVX
也欢迎大家微信扫码添加小助手(INFINI-Labs),加入用户群一起讨论交流。

关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
INFINI Labs 产品更新发布!此次更新主要包括 Coco AI v0.7.0 新增 macOS Spotlight 和 Windows 文件搜索支持、语音输入功能,以及全屏集成模式;Easysearch v1.14.0 引入完整文本嵌入模型、语义检索 API 和搜索管道功能等,全面提升产品性能和稳定性。
Coco AI v0.7.0
Coco AI 是一款完全开源、跨平台的企业级智能搜索与助手系统,专为现代企业打造。它通过统一搜索入口,连接企业内外部的异构数据源,融合大模型能力,帮助团队高效访问知识,智能决策协作。
Coco AI 本次详细更新记录如下:
Coco AI 客户端 v0.7.0
功能特性 (Features)
- 文件搜索支持 Spotlight(macOS) (#705)
- 语音输入支持(搜索模式 & 聊天模式) (#732)
- 文本转语音现已由 LLM 驱动 (#750)
- Windows 文件搜索支持 (#762)
问题修复 (Bug Fixes)
- 文件搜索:优先应用过滤器后再处理 from/size 参数 (#741)
- 文件搜索:按名称与内容搜索时未匹配文件名问题 (#743)
- 修复 Windows 平台窗口被移动时自动隐藏的问题 (#748)
- 修复删除快捷键时未注销扩展热键的问题 (#770)
- 修复应用索引未遵循搜索范围配置的问题 (#773)
- 修复子页面缺失分类标题的问题 (#772)
- 修复快捷 AI 入口显示错误的问题 (#779)
- 语音播放相关的小问题修复 (#780)
- 修复 Linux 平台任务栏图标显示异常 (#783)
- 修复子页面数据不一致问题 (#784)
- 修复扩展安装状态显示错误 (#789)
- 增加 HTTP 流请求的超时容忍度,提升稳定性 (#798)
- 修复回车键行为异常问题 (#794)
- 修复重命名后选中状态失效的问题 (#800)
- 修复 Windows 右键菜单中快捷键异常问题 (#804)
- 修复因 "state() 在 manage() 之前调用" 引起的 panic (#806)
- 修复多行输入问题 (#808)
- 修复 Ctrl+K 快捷键无效问题 (#815)
- 修复窗口配置同步失败问题 (#818)
- 修复子页面回车键无法使用问题 (#819)
- 修复 Ubuntu (GNOME) 下打开应用时崩溃问题 (#821)
改进优化 (Improvements)
- 文件状态检测优先使用
stat(2)(#737) - 文件搜索扩展类型重命名为 extension (#738)
- 创建聊天记录及发送聊天 API (#739)
- 更多文件类型图标支持 (#740)
- 替换 meval-rs 依赖,清除编译警告 (#745)
- Assistant、数据源、MCP Server 接口参数重构 (#746)
- 扩展代码结构调整 (#747)
- 升级
applications-rs依赖版本 (#751) - QuickLink/quick_link 重命名为 Quicklink/quicklink (#752)
- Assistant 样式与参数微调 (#753)
- 可选字段默认不强制要求填写 (#758)
- 搜索聊天组件新增 formatUrl、think 数据及图标地址支持 (#765)
- Coco App HTTP 请求统一添加请求头 (#744)
- 响应体反序列化前增加状态码判断 (#767)
- 启动页适配手机屏幕宽度 (#768)
- 搜索聊天新增语言参数与格式化 URL 参数 (#775)
- 未登录状态不请求用户接口 (#795)
- Windows 文件搜索清理查询字符串中的非法字符 (#802)
- 崩溃日志中展示 backtrace 信息 (#805)
相关截图
Coco AI 服务端 v0.7.0
功能特性 (Features)
- 重构了映射(mappings)的实现
- 新增了基于 HTTP 流式传输的聊天 API
- 新增了文件上传的配置选项
- 聊天消息中现已支持附件
- 为调试目的,增加记录大语言模型(LLM)请求的日志
- 新增 RSS 连接器
- 支持在初始化时配置模型的默认推理参数
- 新增本地文件系统(Local FS)连接器
- 新增 S3 连接器
问题修复(Bug Fixes)
- 修复了查询参数 "filter" 不生效的问题
- 修复了列表中分页功能不工作的问题
- 修复了在没有网络的情况下本地图标无法显示的问题
- 修复了大语言模型(LLM)提供商列表中状态显示不正确的问题
- 修复了带附件的聊天 API
- 防止了在 LLM 意图解析出错时可能出现的空指针异常
- 修复了删除多个 URL 输入框时功能不正常的问题
- 修复了启用本地模型提供商后状态未及时更新的问题
- 确保在 RAG(检索增强生成)处理过程中正确使用数据源
- 修复了提示词模板选择不正确的问题
- 防止了当用户取消正在进行的回复时可能导致回复消息丢失的问题
- 使第一条聊天消息可以被取消
改进优化 (Improvements)
- 重构了用户 ID 的处理方式
- 跳过空的流式响应数据块
- 重构了查询的实现
- 对更多敏感的搜索结果进行屏蔽处理
- 重构了附件相关的 API
- 为智能助理增加了上传设置
- 重构了 ORM 和安全接口
- 在附件上传 API 中移除了对
session_id的检查 - 为搜索框增加了
formatUrl功能 - 为集成页面增加了全屏模式
- 程序现在会忽略无效的连接器
- 程序现在会跳过无效的 MCP 服务器
- 对于内置的智能助理和提供商,隐藏了删除按钮
- 处理了提示词模板的默认值
- 如果某个集成功能被禁用,其按钮预览将显示为禁用状态
- 手动刷新流式输出的第一行数据,以改善响应体验
Easysearch v1.14.0
重大变更(Breaking Changes)
- AI 模块 从 modules 迁移至 plugins 目录下,方便调用 knn 插件
- 旧的文本向量化接口
_ai/embed已不再支持,将在后续版本删除
功能特性 (Features)
- 插件模块新增完整的文本嵌入模型集成功能,涵盖从数据导入到向量检索的全流程
- 新增语义检索 API,简化向量搜索使用流程
- 新增语义检索处理器配置大模型信息
- 新增搜索管道(Search pipelines),轻松地在 Easysearch 内部处理查询请求和查询结果
- 多模型集成支持
- OpenAI 向量模型:直接调用 OpenAI 的嵌入接口(如 text-embedding-3-small)
- Ollama 本地模型:支持离线环境或私有化部署的向量生成
- IK 分词器提供 reload API,能够对存量自定义词典进行完整更新
- IK 分词器能够通过词库索引对默认词库进行自定义添加
改进优化 (Improvements)
- 增强数据摄取管道(ingest pipeline)
- 在数据索引阶段支持文本向量化,文档可自动生成向量表示
- 导入数据时通过 ingest 管道进行向量化时支持单条和批量模式,适配大模型的请求限制场景
- 更新 Easysearch Docker 初始化文档
- IK 分词器优化自定义词库加载逻辑,减少内存占用
Console v1.29.8
INFINI Console 是一款开源的非常轻量级的多集群、跨版本的搜索基础设施统一管控平台。通过对流行的搜索引擎基础设施进行跨版本、多集群的集中纳管,企业可以快速方便的统一管理企业内部的不同版本的多套搜索集群。
Console 本次详细更新记录如下:
问题修复(Bug Fixes)
- 在获取分片级别的分片状态指标时,shard_id 参数未生效的问题
- 优化了监控图表中坐标轴标签的显示效果
- 在更改指标级别后,统计数据未刷新的问题
- 根据响应中的 key 来进行 rollup 检查
- 因 omitempty JSON 标签导致更新不生效时,改为使用 save 方法
改进优化 (Improvements)
- 为指标请求添加了自定义的超时错误处理
- 优化了动态分区逻辑
- 此版本包含了底层 Framework v1.2.0 的更新,解决了一些常见问题,并增强了整体稳定性和性能。虽然 Console 本身没有直接的变更,但从 Framework 中继承的改进间接地使 Console 受益。
Gateway v1.29.8
INFINI Gateway 是一个开源的面向搜索场景的高性能数据网关,所有请求都经过网关处理后再转发到后端的搜索业务集群。基于 INFINI Gateway 可以实现索引级别的限速限流、常见查询的缓存加速、查询请求的审计、查询结果的动态修改等等。
Gateway 本次更新如下:
改进优化 (Improvements)
- 此版本包含了底层 Framework v1.2.0 的更新,解决了一些常见问题,并增强了整体稳定性和性能。虽然 Gateway 本身没有直接的变更,但从 Framework 中继承的改进间接地使 Gateway 受益。
Agent v1.29.8
INFINI Agent 负责采集和上传 Elasticsearch, Easysearch, Opensearch 集群的日志和指标信息,通过 INFINI Console 管理,支持主流操作系统和平台,安装包轻量且无任何外部依赖,可以快速方便地安装。
Agent 本次更新如下:
功能特性 (Features)
- 在 Kubernetes 环境下通过环境变量
http.port探测 Easysearch 的 HTTP 端口
改进优化 (Improvements)
- 此版本包含了底层 Framework v1.2.0 的更新,解决了一些常见问题,并增强了整体稳定性和性能。虽然 Agent 本身没有直接的变更,但从 Framework 中继承的改进间接地使 Agent 受益。
Loadgen v1.29.8
INFINI Loadgen 是一款开源的专为 Easysearch、Elasticsearch、OpenSearch 设计的轻量级性能测试工具。
Loadgen 本次更新如下:
改进优化 (Improvements)
- 此版本包含了底层 Framework v1.2.0 的更新,解决了一些常见问题,并增强了整体稳定性和性能。虽然 Loadgen 本身没有直接的变更,但从 Framework 中继承的改进间接地使 Loadgen 受益。
Framework 1.2.0
INFINI Framework 是 INFINI Labs 基于 Golang 的产品的核心基础,已开源。该框架以开发者为中心设计,简化了构建高性能、可扩展且可靠的应用程序的过程。
Framework 本次更新如下:
功能特性 (Features)
- ORM 操作钩子 (Hooks):为 ORM(数据访问层)的数据操作新增了钩子(Hooks),允许进行更灵活的二次开发。
- 新增 Create API:新增了用于创建文档的
_createAPI 接口,确保文档 ID 的唯一性。 - URL
terms查询:现在 URL 的查询参数也支持terms类型的查询了,可以一次匹配多个值。
问题修复 (Bug Fixes)
- 修复了通过 HTTP 插件设置的自定义 HTTP 头部信息未被正确应用的问题。
- 修复了 JSON 解析器的一个问题,现在可以正确处理带引号的、且包含下划线
_的 JSON 键(key)。
改进 (Improvements)
- 查询过滤器优化: 系统现在会自动将多个针对同一字段的
term过滤器合并为一个更高效的terms过滤器,以提升查询性能。 - 查询接口重构: 对核心的查询接口进行了重构,使其结构更清晰,为未来的功能扩展打下基础。
更多详情请查看以下各产品的 Release Notes 或联系我们的技术支持团队!
- Coco AI App
- Coco AI Server
- INFINI Easysearch
- INFINI Console
- INFINI Gateway
- INFINI Agent
- INFINI Loadgen
- INFINI Framework
期待反馈
欢迎下载体验使用,如果您在使用过程中遇到如何疑问或者问题,欢迎前往 INFINI Labs Github(https://github.com/infinilabs) 中的对应项目中提交 Feature Request 或提交 Bug。
下载地址: https://infinilabs.cn/download
邮件:hello@infini.ltd
电话:(+86) 400-139-9200
Discord:https://discord.gg/4tKTMkkvVX
也欢迎大家微信扫码添加小助手(INFINI-Labs),加入用户群一起讨论交流。
关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
收起阅读 »IK 字段级别词典升级:IK reload API
之前介绍 IK 字段级别字典 使用的时候,对于字典的更新只是支持词典库的新增,并不支持对存量词典库的修改或者删除。经过这段时间的开发,已经可以兼容词典库的更新,主要通过 IK reload API 来实现。
IK reload API
IK reload API 通过对词典库的全量重新加载来实现词典库的更新或者删除。用户可以通过下面的命令实现:
# 测试索引准备
PUT my-index-000001
{
"settings": {
"number_of_shards": 3,
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "my_tokenizer"
}
},
"tokenizer": {
"my_tokenizer": {
"type": "ik_smart",
"custom_dict_enable": true,
"load_default_dicts":false, # 这里不包含默认词库
"lowcase_enable": true,
"dict_key": "test_dic"
}
}
}
},
"mappings": {
"properties": {
"test_ik": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
}
}
# 原来词库分词效果,只预置了分词“自强不息”
GET my-index-000001/_analyze
{
"analyzer": "my_custom_analyzer",
"text":"自强不息,杨树林"
}
{
"tokens": [
{
"token": "自强不息",
"start_offset": 0,
"end_offset": 4,
"type": "CN_WORD",
"position": 0
},
{
"token": "杨",
"start_offset": 5,
"end_offset": 6,
"type": "CN_CHAR",
"position": 1
},
{
"token": "树",
"start_offset": 6,
"end_offset": 7,
"type": "CN_CHAR",
"position": 2
},
{
"token": "林",
"start_offset": 7,
"end_offset": 8,
"type": "CN_CHAR",
"position": 3
}
]
}
# 更新词库
POST .analysis_ik/_doc
{
"dict_key": "test_dic",
"dict_type": "main_dicts",
"dict_content":"杨树林"
}
# 删除词库,词库文档的id为coayoJcBFHNnLYAKfTML
DELETE .analysis_ik/_doc/coayoJcBFHNnLYAKfTML?refresh=true
# 重载词库
POST _ik/_reload
{}
# 更新后的词库效果
GET my-index-000001/_analyze
{
"analyzer": "my_custom_analyzer",
"text":"自强不息,杨树林"
}
{
"tokens": [
{
"token": "自",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "强",
"start_offset": 1,
"end_offset": 2,
"type": "CN_CHAR",
"position": 1
},
{
"token": "不",
"start_offset": 2,
"end_offset": 3,
"type": "CN_CHAR",
"position": 2
},
{
"token": "息",
"start_offset": 3,
"end_offset": 4,
"type": "CN_CHAR",
"position": 3
},
{
"token": "杨树林",
"start_offset": 5,
"end_offset": 8,
"type": "CN_WORD",
"position": 4
}
]
}这里是实现索引里全部的词库更新。
也可以实现单独的词典库更新
POST _ik/_reload
{"dict_key":"test_dic”}
# debug 日志
[2025-07-09T15:30:29,439][INFO ][o.e.a.i.ReloadIK ] [ik-1] 收到重载IK词典的请求,将在所有节点上执行。dict_key: test_dic, dict_index: .analysis_ik
[2025-07-09T15:30:29,439][INFO ][o.e.a.i.a.TransportReloadIKDictionaryAction] [ik-1] 在节点 [R6ESV5h1Q8OZMNoosSDEmg] 上执行词典重载操作,dict_key: test_dic, dict_index: .analysis_ik这里传入的 dict_key 对应的词库 id。
对于自定义的词库存储索引,也可以指定词库索引的名称,如果不指定则默认使用 .analysis_ik
POST _ik/_reload
{"dict_index":"ik_index"}
# debug 日志
[2025-07-09T15:32:59,196][INFO ][o.e.a.i.a.TransportReloadIKDictionaryAction] [ik-1] 在节点 [R6ESV5h1Q8OZMNoosSDEmg] 上执行词典重载操作,dict_key: null, dict_index: test_ik
[2025-07-09T15:32:59,196][INFO ][o.w.a.d.ReloadDict ] [ik-1] Reloading all dictionaries注:
- 更新或者删除词库重载后只是对后续写入的文档生效,对已索引的文档无效;
- 因为用户无法直接更改 IK 内置的词库(即默认配置路径下的词库文件),因此 reload API 不会影响内置词库的信息。
相关阅读
关于 IK Analysis
IK Analysis 插件集成了 Lucene IK 分析器,并支持自定义词典。它支持 Easysearch\Elasticsearch\OpenSearch 的主要版本。由 INFINI Labs 维护并提供支持。
该插件包含分析器:ik_smart 和 ik_max_word,以及分词器:ik_smart 和 ik_max_word
开源地址:https://github.com/infinilabs/analysis-ik
作者:金多安,极限科技(INFINI Labs)搜索运维专家,Elastic 认证专家,搜索客社区日报责任编辑。一直从事与搜索运维相关的工作,日常会去挖掘 ES / Lucene 方向的搜索技术原理,保持搜索相关技术发展的关注。
原文:https://infinilabs.cn/blog/2025/ik-field-level-dictionarys-2/
之前介绍 IK 字段级别字典 使用的时候,对于字典的更新只是支持词典库的新增,并不支持对存量词典库的修改或者删除。经过这段时间的开发,已经可以兼容词典库的更新,主要通过 IK reload API 来实现。
IK reload API
IK reload API 通过对词典库的全量重新加载来实现词典库的更新或者删除。用户可以通过下面的命令实现:
# 测试索引准备
PUT my-index-000001
{
"settings": {
"number_of_shards": 3,
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "my_tokenizer"
}
},
"tokenizer": {
"my_tokenizer": {
"type": "ik_smart",
"custom_dict_enable": true,
"load_default_dicts":false, # 这里不包含默认词库
"lowcase_enable": true,
"dict_key": "test_dic"
}
}
}
},
"mappings": {
"properties": {
"test_ik": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
}
}
# 原来词库分词效果,只预置了分词“自强不息”
GET my-index-000001/_analyze
{
"analyzer": "my_custom_analyzer",
"text":"自强不息,杨树林"
}
{
"tokens": [
{
"token": "自强不息",
"start_offset": 0,
"end_offset": 4,
"type": "CN_WORD",
"position": 0
},
{
"token": "杨",
"start_offset": 5,
"end_offset": 6,
"type": "CN_CHAR",
"position": 1
},
{
"token": "树",
"start_offset": 6,
"end_offset": 7,
"type": "CN_CHAR",
"position": 2
},
{
"token": "林",
"start_offset": 7,
"end_offset": 8,
"type": "CN_CHAR",
"position": 3
}
]
}
# 更新词库
POST .analysis_ik/_doc
{
"dict_key": "test_dic",
"dict_type": "main_dicts",
"dict_content":"杨树林"
}
# 删除词库,词库文档的id为coayoJcBFHNnLYAKfTML
DELETE .analysis_ik/_doc/coayoJcBFHNnLYAKfTML?refresh=true
# 重载词库
POST _ik/_reload
{}
# 更新后的词库效果
GET my-index-000001/_analyze
{
"analyzer": "my_custom_analyzer",
"text":"自强不息,杨树林"
}
{
"tokens": [
{
"token": "自",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "强",
"start_offset": 1,
"end_offset": 2,
"type": "CN_CHAR",
"position": 1
},
{
"token": "不",
"start_offset": 2,
"end_offset": 3,
"type": "CN_CHAR",
"position": 2
},
{
"token": "息",
"start_offset": 3,
"end_offset": 4,
"type": "CN_CHAR",
"position": 3
},
{
"token": "杨树林",
"start_offset": 5,
"end_offset": 8,
"type": "CN_WORD",
"position": 4
}
]
}这里是实现索引里全部的词库更新。
也可以实现单独的词典库更新
POST _ik/_reload
{"dict_key":"test_dic”}
# debug 日志
[2025-07-09T15:30:29,439][INFO ][o.e.a.i.ReloadIK ] [ik-1] 收到重载IK词典的请求,将在所有节点上执行。dict_key: test_dic, dict_index: .analysis_ik
[2025-07-09T15:30:29,439][INFO ][o.e.a.i.a.TransportReloadIKDictionaryAction] [ik-1] 在节点 [R6ESV5h1Q8OZMNoosSDEmg] 上执行词典重载操作,dict_key: test_dic, dict_index: .analysis_ik这里传入的 dict_key 对应的词库 id。
对于自定义的词库存储索引,也可以指定词库索引的名称,如果不指定则默认使用 .analysis_ik
POST _ik/_reload
{"dict_index":"ik_index"}
# debug 日志
[2025-07-09T15:32:59,196][INFO ][o.e.a.i.a.TransportReloadIKDictionaryAction] [ik-1] 在节点 [R6ESV5h1Q8OZMNoosSDEmg] 上执行词典重载操作,dict_key: null, dict_index: test_ik
[2025-07-09T15:32:59,196][INFO ][o.w.a.d.ReloadDict ] [ik-1] Reloading all dictionaries注:
- 更新或者删除词库重载后只是对后续写入的文档生效,对已索引的文档无效;
- 因为用户无法直接更改 IK 内置的词库(即默认配置路径下的词库文件),因此 reload API 不会影响内置词库的信息。
相关阅读
关于 IK Analysis
IK Analysis 插件集成了 Lucene IK 分析器,并支持自定义词典。它支持 Easysearch\Elasticsearch\OpenSearch 的主要版本。由 INFINI Labs 维护并提供支持。
该插件包含分析器:ik_smart 和 ik_max_word,以及分词器:ik_smart 和 ik_max_word
开源地址:https://github.com/infinilabs/analysis-ik
收起阅读 »作者:金多安,极限科技(INFINI Labs)搜索运维专家,Elastic 认证专家,搜索客社区日报责任编辑。一直从事与搜索运维相关的工作,日常会去挖掘 ES / Lucene 方向的搜索技术原理,保持搜索相关技术发展的关注。
原文:https://infinilabs.cn/blog/2025/ik-field-level-dictionarys-2/

