

社区日报 第374期 (2018-08-25)
-
ES6.4发布。 http://t.cn/RkHPfV6
-
在Django项目中使用es。 http://t.cn/RkR2as4
- ElasticHQ: 基于python的es监控管理插件。 http://t.cn/Rk8ioV0
活动预告
1、Elastic 中国开发者大会最后一波早鸟票发售进行中
https://conf.elasticsearch.cn/2018/shenzhen.html
2、Elastic Meetup 9月8日 北京线下沙龙正在报名中
-
ES6.4发布。 http://t.cn/RkHPfV6
-
在Django项目中使用es。 http://t.cn/RkR2as4
- ElasticHQ: 基于python的es监控管理插件。 http://t.cn/Rk8ioV0
活动预告
1、Elastic 中国开发者大会最后一波早鸟票发售进行中
https://conf.elasticsearch.cn/2018/shenzhen.html
2、Elastic Meetup 9月8日 北京线下沙龙正在报名中
https://elasticsearch.cn/article/759
收起阅读 »Elastic Tips 项目
场景:
大家是不是觉得 Elastic 的知识很多,需要学习的很多,常见问题经常问。
目的:
- 汇集 Elastic Stack 的奇巧赢技
- 随手可得的小技巧,温故知新
- 分享和学习,共同进步
- 积少成多,知识库
细节
- 贴士的内容要小且精要,简单,适合阅读和分享(限制为Twitter长度)
- 大家都可以发表贴士,社区一起参与贡献内容
- 贴士需要标识适用的版本号和对应的开源项目,如:Elasticsearch 6.x
- 贴士在得到3个赞之后,表示受到大家的认可,可以提供出现分享功能
- 分享功能要支持外部引用,生成 JS 脚本,随机显示一条贴士,可以挂在个人博客和网站上
- 可以对单条贴士生成一个图片,嵌入二维码,方便微信微博分享,显示贡献者和贡献者的个人签名
- 贴士不单独存储,还是在社区的文章模块,只不过发布的时候,需要选择分类为 “ElasticTips” 目录
- 搞一个微信小程序,方便分享传播贴士内容
开发内容:
- API 模块:Golang 编写,负责读取数据库内容和生成 JS,RSS 订阅
- JS 渲染模块:Golang 编写,负责渲染生成 JS
- 静态图片生成:Golang 编写,基于图片模板,渲染分享用的图片
- 单独的页面来展示贴士,主要要求是要酷炫
- 微信小程序:貌似没得选,再者我也不懂
好了,听起来有点意思,是不是很兴奋,那么问题来了,有没有兴趣一起来弄的呢?
有兴趣的请加入 Slack 讨论组。
场景:
大家是不是觉得 Elastic 的知识很多,需要学习的很多,常见问题经常问。
目的:
- 汇集 Elastic Stack 的奇巧赢技
- 随手可得的小技巧,温故知新
- 分享和学习,共同进步
- 积少成多,知识库
细节
- 贴士的内容要小且精要,简单,适合阅读和分享(限制为Twitter长度)
- 大家都可以发表贴士,社区一起参与贡献内容
- 贴士需要标识适用的版本号和对应的开源项目,如:Elasticsearch 6.x
- 贴士在得到3个赞之后,表示受到大家的认可,可以提供出现分享功能
- 分享功能要支持外部引用,生成 JS 脚本,随机显示一条贴士,可以挂在个人博客和网站上
- 可以对单条贴士生成一个图片,嵌入二维码,方便微信微博分享,显示贡献者和贡献者的个人签名
- 贴士不单独存储,还是在社区的文章模块,只不过发布的时候,需要选择分类为 “ElasticTips” 目录
- 搞一个微信小程序,方便分享传播贴士内容
开发内容:
- API 模块:Golang 编写,负责读取数据库内容和生成 JS,RSS 订阅
- JS 渲染模块:Golang 编写,负责渲染生成 JS
- 静态图片生成:Golang 编写,基于图片模板,渲染分享用的图片
- 单独的页面来展示贴士,主要要求是要酷炫
- 微信小程序:貌似没得选,再者我也不懂
好了,听起来有点意思,是不是很兴奋,那么问题来了,有没有兴趣一起来弄的呢?
有兴趣的请加入 Slack 讨论组。
收起阅读 »
社区日报 第373期 (2018-08-24)
http://t.cn/RklH6TU
2、搜索之路:Elasticsearch的诞生
http://t.cn/Rk6ZPYq
3、教你编译调试Elasticsearch 6.3.2源码
http://t.cn/RklHW8y
活动预告:
1、Elastic Meetup 北京线下沙龙征稿中
https://elasticsearch.cn/article/759
2、Elastic 中国开发者大会 2018 ,开始接受演讲申请和赞助合作
https://conf.elasticsearch.cn/2018/shenzhen.html
编辑:铭毅天下
归档:https://elasticsearch.cn/article/768
订阅:https://tinyletter.com/elastic-daily
http://t.cn/RklH6TU
2、搜索之路:Elasticsearch的诞生
http://t.cn/Rk6ZPYq
3、教你编译调试Elasticsearch 6.3.2源码
http://t.cn/RklHW8y
活动预告:
1、Elastic Meetup 北京线下沙龙征稿中
https://elasticsearch.cn/article/759
2、Elastic 中国开发者大会 2018 ,开始接受演讲申请和赞助合作
https://conf.elasticsearch.cn/2018/shenzhen.html
编辑:铭毅天下
归档:https://elasticsearch.cn/article/768
订阅:https://tinyletter.com/elastic-daily
收起阅读 »
社区日报 第372期 (2018-08-23)
http://t.cn/RkK4iEb
2.你真的理解grok吗?
http://t.cn/RkK4NwF
3.如何在Elasticsearch中使用排名评估API
http://t.cn/RkK4nQx
活动预告:
1、Elastic Meetup 北京线下沙龙征稿中
https://elasticsearch.cn/article/759
2、Elastic 中国开发者大会预热票发售进行中
https://conf.elasticsearch.cn/2018/shenzhen.html
编辑:金桥
归档:https://elasticsearch.cn/article/767
订阅:https://tinyletter.com/elastic-daily
http://t.cn/RkK4iEb
2.你真的理解grok吗?
http://t.cn/RkK4NwF
3.如何在Elasticsearch中使用排名评估API
http://t.cn/RkK4nQx
活动预告:
1、Elastic Meetup 北京线下沙龙征稿中
https://elasticsearch.cn/article/759
2、Elastic 中国开发者大会预热票发售进行中
https://conf.elasticsearch.cn/2018/shenzhen.html
编辑:金桥
归档:https://elasticsearch.cn/article/767
订阅:https://tinyletter.com/elastic-daily
收起阅读 »
社区日报 第371期 (2018-08-22)
http://t.cn/RkKcGWm
2. Elasticsearch之基本查询
http://t.cn/RGtNQV2
3. Elasticsearch之查询过滤
http://t.cn/RGcFE2K
活动预告:
1、Elastic Meetup 北京线下沙龙征稿中
https://elasticsearch.cn/article/759
2、Elastic 中国开发者大会 2018 ,开始接受演讲申请和赞助合作
https://conf.elasticsearch.cn/2018/shenzhen.html
编辑:江水
归档:https://elasticsearch.cn/article/766
订阅:https://tinyletter.com/elastic-daily
http://t.cn/RkKcGWm
2. Elasticsearch之基本查询
http://t.cn/RGtNQV2
3. Elasticsearch之查询过滤
http://t.cn/RGcFE2K
活动预告:
1、Elastic Meetup 北京线下沙龙征稿中
https://elasticsearch.cn/article/759
2、Elastic 中国开发者大会 2018 ,开始接受演讲申请和赞助合作
https://conf.elasticsearch.cn/2018/shenzhen.html
编辑:江水
归档:https://elasticsearch.cn/article/766
订阅:https://tinyletter.com/elastic-daily 收起阅读 »
社区日报 第370期 (2018-08-21)
http://t.cn/Rk6P3lQ
2.(自备翻墙)使用Cloud Dataflow将文档索引到Elasticsearch中。
http://t.cn/Rk6Pev2
3.(自备翻墙)Kubernetes使用Elasticsearch、Fluent Bit和Kibana的最佳实践。
http://t.cn/Rk6hvy0
活动预告:
1、Elastic Meetup 北京线下沙龙征稿中
https://elasticsearch.cn/article/759
2、Elastic 中国开发者大会 2018 ,开始接受演讲申请和赞助合作
https://conf.elasticsearch.cn/2018/shenzhen.html
编辑:叮咚光军
归档:https://elasticsearch.cn/article/765
订阅:https://tinyletter.com/elastic-daily
http://t.cn/Rk6P3lQ
2.(自备翻墙)使用Cloud Dataflow将文档索引到Elasticsearch中。
http://t.cn/Rk6Pev2
3.(自备翻墙)Kubernetes使用Elasticsearch、Fluent Bit和Kibana的最佳实践。
http://t.cn/Rk6hvy0
活动预告:
1、Elastic Meetup 北京线下沙龙征稿中
https://elasticsearch.cn/article/759
2、Elastic 中国开发者大会 2018 ,开始接受演讲申请和赞助合作
https://conf.elasticsearch.cn/2018/shenzhen.html
编辑:叮咚光军
归档:https://elasticsearch.cn/article/765
订阅:https://tinyletter.com/elastic-daily
收起阅读 »
社区日报 第369期 (2018-08-20)
http://t.cn/Rk2LTeO
2、更方便的基于kibana的多数据源导入插件
http://t.cn/REOhwGT
3、马上到来的kibana 6.4 api变更
http://t.cn/RkcPT9Y
活动预告:
1、Elastic Meetup 北京线下沙龙征稿中
https://elasticsearch.cn/article/759
2、Elastic 中国开发者大会 2018 ,开始接受演讲申请和赞助合作
https://conf.elasticsearch.cn/2018/shenzhen.html
编辑:cyberdak
归档:
订阅:https://tinyletter.com/elastic-daily
http://t.cn/Rk2LTeO
2、更方便的基于kibana的多数据源导入插件
http://t.cn/REOhwGT
3、马上到来的kibana 6.4 api变更
http://t.cn/RkcPT9Y
活动预告:
1、Elastic Meetup 北京线下沙龙征稿中
https://elasticsearch.cn/article/759
2、Elastic 中国开发者大会 2018 ,开始接受演讲申请和赞助合作
https://conf.elasticsearch.cn/2018/shenzhen.html
编辑:cyberdak
归档:
订阅:https://tinyletter.com/elastic-daily
收起阅读 »
社区日报 第368期 (2018-08-19)
http://t.cn/RDes1PI
2.如何使用ELK stack管理Nginx日志。
http://t.cn/RkUKe2L
3.(自备梯子)数据科学项目最重要的部分是写博客文章。
http://t.cn/RkU9jJW
活动预告:
1、Elastic Meetup 北京线下沙龙征稿中
https://elasticsearch.cn/article/759
2、Elastic 中国开发者大会预热票今天发售!
https://conf.elasticsearch.cn/2018/shenzhen.html
编辑:至尊宝
归档:https://elasticsearch.cn/article/763
订阅:https://tinyletter.com/elastic-daily
http://t.cn/RDes1PI
2.如何使用ELK stack管理Nginx日志。
http://t.cn/RkUKe2L
3.(自备梯子)数据科学项目最重要的部分是写博客文章。
http://t.cn/RkU9jJW
活动预告:
1、Elastic Meetup 北京线下沙龙征稿中
https://elasticsearch.cn/article/759
2、Elastic 中国开发者大会预热票今天发售!
https://conf.elasticsearch.cn/2018/shenzhen.html
编辑:至尊宝
归档:https://elasticsearch.cn/article/763
订阅:https://tinyletter.com/elastic-daily 收起阅读 »
社区日报 第367期 (2018-08-18)
-
支持弹性化部署的Elastic Cloud。 http://t.cn/Rk2LTeO
-
使用ES处理数据的经验分享(需翻墙)。 http://t.cn/Rk2L13a
- Elassandra:将es和Apache Cassandra结合的工具。 http://t.cn/Rk2DOuf
活动预告
- 活动预告:Elastic 中国开发者大会预热票发售进行中 https://conf.elasticsearch.cn/2018/shenzhen.html
-
支持弹性化部署的Elastic Cloud。 http://t.cn/Rk2LTeO
-
使用ES处理数据的经验分享(需翻墙)。 http://t.cn/Rk2L13a
- Elassandra:将es和Apache Cassandra结合的工具。 http://t.cn/Rk2DOuf
活动预告
- 活动预告:Elastic 中国开发者大会预热票发售进行中 https://conf.elasticsearch.cn/2018/shenzhen.html
阿里云 MVP 第6期招募与 Elastic 社区合作启动
什么是阿里云 MVP?阿里云MVP(Most Valuable Professional,最有价值专家),是专注于帮助他人充分了解和使用阿里云产品和服务的技术实践领袖。截止到2018年6月已经有232位全球各国家和地区的Coder们参加了5期认证。

只要成为MVP,即可享受免费云栖大会门票、最新产品的优先使用权、官方渠道推广等丰厚权益。升级后,还有全球技术留学、高端闭门会议,与顶级技术专家交流学习。与您一同打造《MVP 时间》将您的技术能量传播给更多人,定期邀请阿里技术专家在MVP学院与您共同交流学习提升技术实力。

本期MVP项目与本社区合作推荐技术达人成为候选人,通过认证您还可以在9月到杭州参与一年一度的MVP高端闭门峰会,第6期认证结果将在9月中旬公布结果。
什么样的人可以成为阿里云 MVP?
你交叉使用过阿里云多款产品;
你有丰富的技术沉淀、勇于创新、乐于分享;
你希望能寻找志同道合的资深技术圈,希望建立个人技术影响力。
你可以马上点击Elastic社区专属申请链接提交申请或扫码填写申请:
https://mvp.aliyun.com/mvp/app ... 3D%3D

对于阿里云 MVP申请的一些疑问:
- 多久评选一次MVP?
每个季度会评选一次,并会在每个季度末宣布MVP入围情况,如果遗憾落选,可在公布名单后,重新到MVP平台提交申请。
- MVP代表阿里云吗?
不代表。MVP不是阿里巴巴的员工,他们也不代表阿里云发言。MVP仅是因其在技术社区中的杰出成就,而获得阿里云认可和奖励的第三方个人。
- 阿里云MVP大奖的有效期为多长时间?
MVP大奖的有效期为一年。在此期间,MVP奖获奖者享有阿里云MVP荣誉称号以及大奖所包括的所有特权。
什么是阿里云 MVP?阿里云MVP(Most Valuable Professional,最有价值专家),是专注于帮助他人充分了解和使用阿里云产品和服务的技术实践领袖。截止到2018年6月已经有232位全球各国家和地区的Coder们参加了5期认证。
只要成为MVP,即可享受免费云栖大会门票、最新产品的优先使用权、官方渠道推广等丰厚权益。升级后,还有全球技术留学、高端闭门会议,与顶级技术专家交流学习。与您一同打造《MVP 时间》将您的技术能量传播给更多人,定期邀请阿里技术专家在MVP学院与您共同交流学习提升技术实力。
本期MVP项目与本社区合作推荐技术达人成为候选人,通过认证您还可以在9月到杭州参与一年一度的MVP高端闭门峰会,第6期认证结果将在9月中旬公布结果。
什么样的人可以成为阿里云 MVP?
你交叉使用过阿里云多款产品;
你有丰富的技术沉淀、勇于创新、乐于分享;
你希望能寻找志同道合的资深技术圈,希望建立个人技术影响力。
你可以马上点击Elastic社区专属申请链接提交申请或扫码填写申请:
https://mvp.aliyun.com/mvp/app ... 3D%3D
对于阿里云 MVP申请的一些疑问:
- 多久评选一次MVP?
每个季度会评选一次,并会在每个季度末宣布MVP入围情况,如果遗憾落选,可在公布名单后,重新到MVP平台提交申请。
- MVP代表阿里云吗?
不代表。MVP不是阿里巴巴的员工,他们也不代表阿里云发言。MVP仅是因其在技术社区中的杰出成就,而获得阿里云认可和奖励的第三方个人。
- 阿里云MVP大奖的有效期为多长时间?
MVP大奖的有效期为一年。在此期间,MVP奖获奖者享有阿里云MVP荣誉称号以及大奖所包括的所有特权。 收起阅读 »
社区日报 第366期 (2018-08-17)
http://t.cn/RDdxGyR
2、用PROFILE API 定位 ES 慢查询
http://t.cn/Rk7PYNZ
3、同步Mysql数据到Elasticsearch的工具
https://elasticsearch.cn/article/756
活动预告:
1、Elastic Meetup 北京线下沙龙征稿中
https://elasticsearch.cn/article/759
2、Elastic 中国开发者大会 2018 ,开始接受演讲申请和赞助合作
https://conf.elasticsearch.cn/2018/shenzhen.html
编辑:铭毅天下
归档:https://elasticsearch.cn/article/760
订阅:https://tinyletter.com/elastic-daily
http://t.cn/RDdxGyR
2、用PROFILE API 定位 ES 慢查询
http://t.cn/Rk7PYNZ
3、同步Mysql数据到Elasticsearch的工具
https://elasticsearch.cn/article/756
活动预告:
1、Elastic Meetup 北京线下沙龙征稿中
https://elasticsearch.cn/article/759
2、Elastic 中国开发者大会 2018 ,开始接受演讲申请和赞助合作
https://conf.elasticsearch.cn/2018/shenzhen.html
编辑:铭毅天下
归档:https://elasticsearch.cn/article/760
订阅:https://tinyletter.com/elastic-daily 收起阅读 »
9月8日 Elastic Meetup 北京线下沙龙报名中

时间:9月8日
地点:北京市海淀区上地西路6号,联想研究院圆楼三层报告厅
活动页面:https://meetup.elasticsearch.cn/2018/beijing.html
议题:征集中,等你来投稿
- 58到家搜索服务化实践和演进 -- 邢天宇/五八到家
- Elasticsearch在百度aladdin日志系统的应用 -- 王鹏/百度
- elasticsearch 在58集团信息安全部的应用 -- 亢伟楠/五八集体
- Waterdrop:构建在Spark之上的简单高效数据处理系统 -- 霍晨/新浪网
- 基于 ElasticSearch 构建个性化推荐和高级搜索 -- 周金阳/果壳网/在行
报名地址:http://elasticsearch.mikecrm.com/fUqiv0T
演讲主题介绍
#1 基于 ElasticSearch 构建个性化推荐和高级搜索
[周金阳]周金阳果壳网/在行 算法工程师
使用 ES 来构建一个简易却行之有效的个性化推荐系统,以及一些高级搜索排序的实践。
搜索排序主要是分享一些机器学习工具与 ES 配合的实践心得。
#2 elasticsearch 在58集团信息安全部的应用
[亢伟楠]亢伟楠58集团 资深开发工程师
全面介绍 ELK Stack 在58集团信息安全部的落地,升级,优化以及应用。
包括如下等方面:接入背景,存储选型,性能挑战,master node以及data node优化,安全实践,高吞吐量以及低延迟搜索优化;kibana 的落地,本地化使其更方便产品、运营使用。
#3 58到家搜索服务化实践和演进
[邢天宇]邢天宇北京五八到家信息技术有限公司 java工程师
介绍58到家搜索服务体系的构建和普及,elasticsearch在到家中的各种应用以及优化等等。
#4 Waterdrop:构建在Spark之上的简单高效数据处理系统
[霍晨]霍晨新浪网,大数据研发工程师
大数据时代,随着Spark等工具的出现,数据处理能力在逐渐提升。
但是Spark本身的开发和运维具有一定的成本,为此我们开源了Waterdrop,通过配置文件的形式配置Spark任务,企图降低Spark的使用门槛,减小开发和运维成本
- 什么是waterdrop
- Waterdrop架构介绍
- Waterdrop VS Spark
- Waterdrop VS Logstash
- Waterdrop的优势
- Waterdrop使用场景
- Roadmap
#5 elasticsearch在百度aladdin日志系统的应用
[王鹏]王鹏百度,研发工程师
背景:aladdin建库问题相关的case追查,日志统计分析,问题需要解决。
方案:使用ES(es版本: 6.0.0)做存储和检索系统,日志以json格式,抽取重要字段建索引,每天一个index,index名字包含时间后缀,保存三天内的数据;建库10个模块,每天有100亿条记录,20T左右数据;使用20个容器做集群。
效果:毫秒级返回查询结果,利用kibana实时分析建库情况,同时能方便按需提供数据给业务方。
报名地址:http://elasticsearch.mikecrm.com/fUqiv0T
Elastic 中国开发者大会 2018,阵容强大,正在火热售票中 ?
https://conf.elasticsearch.cn/2018/shenzhen.html
时间:9月8日
地点:北京市海淀区上地西路6号,联想研究院圆楼三层报告厅
活动页面:https://meetup.elasticsearch.cn/2018/beijing.html
议题:征集中,等你来投稿
- 58到家搜索服务化实践和演进 -- 邢天宇/五八到家
- Elasticsearch在百度aladdin日志系统的应用 -- 王鹏/百度
- elasticsearch 在58集团信息安全部的应用 -- 亢伟楠/五八集体
- Waterdrop:构建在Spark之上的简单高效数据处理系统 -- 霍晨/新浪网
- 基于 ElasticSearch 构建个性化推荐和高级搜索 -- 周金阳/果壳网/在行
报名地址:http://elasticsearch.mikecrm.com/fUqiv0T
演讲主题介绍
#1 基于 ElasticSearch 构建个性化推荐和高级搜索
[周金阳]周金阳果壳网/在行 算法工程师
使用 ES 来构建一个简易却行之有效的个性化推荐系统,以及一些高级搜索排序的实践。
搜索排序主要是分享一些机器学习工具与 ES 配合的实践心得。
#2 elasticsearch 在58集团信息安全部的应用
[亢伟楠]亢伟楠58集团 资深开发工程师
全面介绍 ELK Stack 在58集团信息安全部的落地,升级,优化以及应用。
包括如下等方面:接入背景,存储选型,性能挑战,master node以及data node优化,安全实践,高吞吐量以及低延迟搜索优化;kibana 的落地,本地化使其更方便产品、运营使用。
#3 58到家搜索服务化实践和演进
[邢天宇]邢天宇北京五八到家信息技术有限公司 java工程师
介绍58到家搜索服务体系的构建和普及,elasticsearch在到家中的各种应用以及优化等等。
#4 Waterdrop:构建在Spark之上的简单高效数据处理系统
[霍晨]霍晨新浪网,大数据研发工程师
大数据时代,随着Spark等工具的出现,数据处理能力在逐渐提升。
但是Spark本身的开发和运维具有一定的成本,为此我们开源了Waterdrop,通过配置文件的形式配置Spark任务,企图降低Spark的使用门槛,减小开发和运维成本
- 什么是waterdrop
- Waterdrop架构介绍
- Waterdrop VS Spark
- Waterdrop VS Logstash
- Waterdrop的优势
- Waterdrop使用场景
- Roadmap
#5 elasticsearch在百度aladdin日志系统的应用
[王鹏]王鹏百度,研发工程师
背景:aladdin建库问题相关的case追查,日志统计分析,问题需要解决。
方案:使用ES(es版本: 6.0.0)做存储和检索系统,日志以json格式,抽取重要字段建索引,每天一个index,index名字包含时间后缀,保存三天内的数据;建库10个模块,每天有100亿条记录,20T左右数据;使用20个容器做集群。
效果:毫秒级返回查询结果,利用kibana实时分析建库情况,同时能方便按需提供数据给业务方。
报名地址:http://elasticsearch.mikecrm.com/fUqiv0T
Elastic 中国开发者大会 2018,阵容强大,正在火热售票中 ?
https://conf.elasticsearch.cn/2018/shenzhen.html 收起阅读 »
社区日报 第365期 (2018-08-16)
http://t.cn/RDo2OXR
2.搜索引擎 ElasticSearch
http://t.cn/Rrifuz5
3.Grafana与Kibana的主要差异
http://t.cn/RDFwTe0
活动预告:
1. Elastic 中国开发者大会预热票发售进行中
https://conf.elasticsearch.cn/2018/shenzhen.html
编辑:wt
归档:https://elasticsearch.cn/article/758
订阅:https://tinyletter.com/elastic-daily
http://t.cn/RDo2OXR
2.搜索引擎 ElasticSearch
http://t.cn/Rrifuz5
3.Grafana与Kibana的主要差异
http://t.cn/RDFwTe0
活动预告:
1. Elastic 中国开发者大会预热票发售进行中
https://conf.elasticsearch.cn/2018/shenzhen.html
编辑:wt
归档:https://elasticsearch.cn/article/758
订阅:https://tinyletter.com/elastic-daily 收起阅读 »
社区日报 第364期 (2018-08-15)
http://t.cn/Rd3QEfE
2. Elasticsearch SQL
http://t.cn/RDgJ9HQ
3. 日志汇集系统搭建
http://t.cn/RDg9wU2
活动预告:
Elastic 中国开发者大会预热票发售进行中
https://conf.elasticsearch.cn/2018/shenzhen.html
编辑:江水
归档:https://elasticsearch.cn/article/757
订阅:https://tinyletter.com/elastic-daily
http://t.cn/Rd3QEfE
2. Elasticsearch SQL
http://t.cn/RDgJ9HQ
3. 日志汇集系统搭建
http://t.cn/RDg9wU2
活动预告:
Elastic 中国开发者大会预热票发售进行中
https://conf.elasticsearch.cn/2018/shenzhen.html
编辑:江水
归档:https://elasticsearch.cn/article/757
订阅:https://tinyletter.com/elastic-daily 收起阅读 »
推荐一个同步Mysql数据到Elasticsearch的工具
把Mysql的数据同步到Elasticsearch是个很常见的需求,但在Github里找到的同步工具用起来或多或少都有些别扭。
例如:某记录内容为"aaa|bbb|ccc",将其按|分割成数组同步到es,这样的简单任务都难以实现,再加上配置繁琐,文档语焉不详...
所以我写了个同步工具MysqlsMom:力求用最简单的配置完成复杂的同步任务。目前除了我所在的部门,也有越来越多的互联网公司在生产环境中使用该工具了。
欢迎各位大佬进行试用并提出意见,任何建议、鼓励、批评都受到欢迎。
github: https://github.com/m358807551/mysqlsmom
简介:同步 Mysql 数据到 elasticsearch 的工具; QQ、微信:358807551
特点
- 纯 Python 编写;
- 支持基于 sql 语句的全量同步,基于 binlog 的增量同步,基于更新字段的增量同步三种同步方式;
- 全量更新只占用少量内存;支持通过sql语句同步数据;
- 增量更新自动断点续传;
- 取自 Mysql 的数据可经过一系列自定义函数的处理后再同步至 Elasticsearch;
- 能用非常简单的配置完成复杂的同步任务;
环境
- python2.7;
- 增量同步需开启 redis;
- 分析 binlog 的增量同步需要 Mysql 开启 binlog(binlog-format=row);
快速开始
全量同步MySql数据到es
-
clone 项目到本地;
-
安装依赖;
cd mysqlsmom pip install -r requirements.txt默认支持 elasticsearch-2.4版本,支持其它版本请运行(将5.4换成需要的elasticsearch版本)
pip install --upgrade elasticsearch==5.4 -
编辑 ./config/example_init.py,按注释提示修改配置;
# coding=utf-8 STREAM = "INIT" # 修改数据库连接 CONNECTION = { 'host': '127.0.0.1', 'port': 3306, 'user': 'root', 'passwd': '' } # 修改elasticsearch节点 NODES = [{"host": "127.0.0.1", "port": 9200}] TASKS = [ { "stream": { "database": "test_db", # 在此数据库执行sql语句 "sql": "select * from person" # 将该sql语句选中的数据同步到 elasticsearch }, "jobs": [ { "actions": ["insert", "update"], "pipeline": [ {"set_id": {"field": "id"}} # 默认设置 id字段的值 为elasticsearch中的文档id ], "dest": { "es": { "action": "upsert", "index": "test_index", # 设置 index "type": "test", # 设置 type "nodes": NODES } } } ] } ] -
运行
cd mysqlsmom python mysqlsmom.py ./config/example_init.py等待同步完成即可;
分析 binlog 的增量同步
-
确保要增量同步的MySql数据库开启binlog,且开启redis(为了存储最后一次读到的binlog文件名及读到的位置。未来可能支持本地文件存储该信息。)
-
下载项目到本地,且安装好依赖后,编辑 ./config/example_init.py,按注释提示修改配置;
# coding=utf-8 STREAM = "BINLOG" SERVER_ID = 99 # 确保每个用于binlog同步的配置文件的SERVER_ID不同; SLAVE_UUID = __name__ # 配置开启binlog权限的MySql连接 BINLOG_CONNECTION = { 'host': '127.0.0.1', 'port': 3306, 'user': 'root', 'passwd': '' } # 配置es节点 NODES = [{"host": "127.0.0.1", "port": 9200}] TASKS = [ { "stream": { "database": "test_db", # [table]所在的数据库 "table": "person" # 监控该表的binlog }, "jobs": [ { "actions": ["insert", "update"], "pipeline": [ {"only_fields": {"fields": ["id", "name", "age"]}}, # 只同步这些字段到es,注释掉该行则同步全部字段的值到es {"set_id": {"field": "id"}} # 设置es中文档_id的值取自 id(或根据需要更改)字段 ], "dest": { "es": { "action": "upsert", "index": "test_index", # 设置 index "type": "test", # 设置 type "nodes": NODES } } } ] } ] -
运行
cd mysqlsmom python mysqlsmom.py ./config/example_binlog.py该进程会一直运行,实时同步新增和更改后的数据到elasticsearch;
注意:第一次运行该进程时不会同步MySql中已存在的数据,从第二次运行开始,将接着上次同步停止时的位置继续同步;
同步旧数据请看全量同步MySql数据到es;
基于更新时间的增量同步
若 Mysql 表中有类似 update_time 的时间字段,且在每次插入、更新数据后将该字段的值设置为操作时间,则可在不用开启 binlog 的情况下进行增量同步。
-
下载项目到本地,且安装好依赖后,编辑 ./config/example_cron.py,按注释提示修改配置;
# coding=utf-8 STREAM = "CRON" # 修改数据库连接 CONNECTION = { 'host': '127.0.0.1', 'port': 3306, 'user': 'root', 'passwd': '' } # redis存储上次同步时间等信息 REDIS = { "host": "127.0.0.1", "port": 6379, "db": 0, "password": "password", # 不需要密码则注释或删掉该行 } # 一次同步 BULK_SIZE 条数据到elasticsearch,不设置该配置项默认为1 BULK_SIZE = 1 # 修改elasticsearch节点 NODES = [{"host": "127.0.0.1", "port": 9200}] TASKS = [ { "stream": { "database": "test_db", # 在此数据库执行sql语句 "sql": "select id, name from person where update_time >= ?", # 将该sql语句选中的数据同步到 elasticsearch "seconds": 10, # 每隔 seconds 秒同步一次, "init_time": "2018-08-15 18:05:47" # 只有第一次同步会加载 }, "jobs": [ { "pipeline": [ {"set_id": {"field": "id"}} # 默认设置 id字段的值 为 es 中的文档id ], "dest": { "es": { "action": "upsert", "index": "test_index", # 设置 index "type": "test" # 设置 type } } } ] } ] -
运行
cd mysqlsmom python mysqlsmom.py ./config/example_cron.py
组织架构
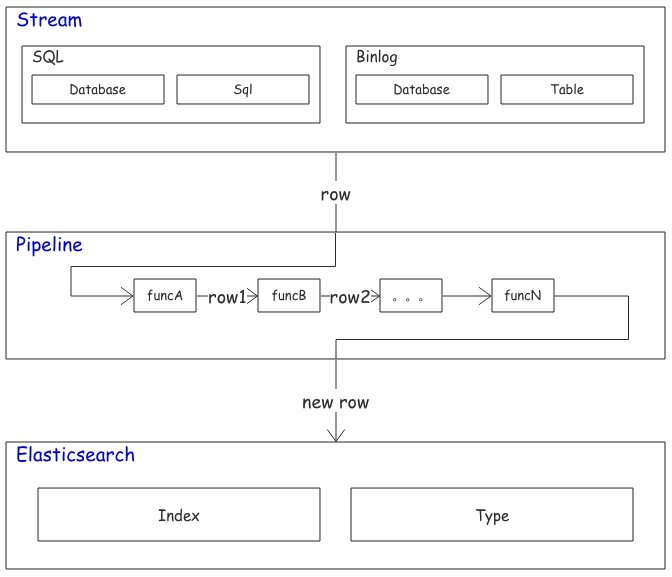
Mysqlsmom 使用实战
Mysqlsmom 的灵活性依赖于:
- 在 row_handlers.py 中添加自定义函数对取自Mysql的数据进行二次加工。
- 在 row_filters.py 中添加自定义函数决定是否要同步某一条数据。
- 在 config/ 目录下的任意配置文件应用上面的函数。
如果不了解 Python 也没关系,上述两个文件中自带的函数足以应付大多数种情况,遇到特殊的同步需求可以在 Github 发起 issue 或通过微信、QQ联系作者。
同步多张表
在一个配置文件中即可完成:
...
TASKS = [
# 同步表1
{
"stream": {
"database": "数据库名1",
"table": "表名1"
},
"jobs": [...]
}
# 同步表2
{
"stream": {
"database": "数据库名2",
"table": "表名2"
},
"jobs": [...]
}
]一个 Mysql Connection 对应一个配置文件。
一张表同步到多个索引
分为两种情况。
一种是把相同的数据同步到不同的索引,配置如下:
...
TASKS = [
{
"stream": {...},
"jobs": [
{
"actions": [...],
"pipeline": [...],
"dest": [
# 同步到索引1
{
"es": {"action": "upsert", "index": "索引1", "type": "类型1", "nodes": NODES},
},
# 同步到索引2
{
"es": {"action": "upsert", "index": "索引2", "type": "类型2", "nodes": NODES},
}
]
}
]
},
...
]另一种是把同一个表产生的数据经过不同的 pipeline 同步到不同的索引:
...
TASKS = [
{
"stream": {...},
"jobs": [
{
"actions": {...},
"pipeline": [...], # 对数据经过一系列处理
"dest": {"es": {"index": "索引1", ...}} # 同步到索引1
},
{
"actions": {...},
"pipeline": [...], # 与上面的pipeline不同
"dest": {"es": {"index": "索引2", ...}} # 同步到索引2
}
]
}
]- TASKS 中的每一项对应一张要同步的表。
- jobs 中的每一项对应对一条记录的一种处理方式。
- dest 中的每一项对应一个es索引类型。
只同步某些字段
对每条来自 Mysql 的 记录的处理都在 pipeline 中进行处理。
"pipeline": [
{"only_fields": {"fields": ["id", "name"]}}, # 只同步 id 和 name字段
{"set_id": {"field": "id"}} # 然后设置 id 字段为es中文档的_id
]字段重命名
对于 Mysql 中的字段名和 elasticsearch 中的域名不一致的情况:
"pipeline": [
# 将name重命名为name1,age 重命名为age1
{"replace_fields": {"name": ["name1"], "age": ["age1"]}},
{"set_id": {"field": "id"}}
]pipeline 会依次执行处理函数,上面的例子等价于:
"pipeline": [
# 先重命名 name 为 name1
{"replace_fields": {"name": ["name1"]}},
# 再重命名 age 为 age1
{"replace_fields": {"age": ["age1"]}},
{"set_id": {"field": "id"}}
]还有一种特殊情形,es 中两个字段存相同的数据,但是分词方式不同。
例如 name_default 的分析器为 default,name_raw 设置为不分词,需要将 name 的值同时同步到这两个域:
"pipeline": [
{"replace_fields": {"name": ["name_default", "name_raw"]}},
{"set_id": {"field": "id"}}
]当然上述问题有一个更好的解决方案,在 es 的 mappings 中配置 name 字段的 fields 属性即可,这超出了本文档的内容。
切分字符串为数组
有时 Mysql 存储字符串类似:"aaa|bbb|ccc",希望转化成数组: ["aaa", "bbb", "ccc"] 再进行同步
"pipeline": [
# tags 存储类似"aaa|bbb|ccc"的字符串,将 tags 字段的值按符号 `|` 切分成数组
{"split": {"field": "tags", "flag": "|"}},
{"set_id": {"field": "id"}}
] 同步删除文档
只有 binlog 同步 能实现删除 elasticsearch 中的文档,配置如下:
TASKS = [
{
"stream": {
"database": "test_db",
"table": "person"
},
"jobs": [
# 插入、更新
{
"actions": ["insert", "update"],
"pipeline": [
{"set_id": {"field": "id"}} # 设置 id 字段的值为 es 中文档 _id
],
"dest": {
"es": {
"action": "upsert",
...
}
}
},
# 重点在这里,配置删除
{
"actions": ["delete"], # 当读取到 binlog 中该表的删除操作时
"pipeline": [{"set_id": {"field": "id"}}], # 要删除的文档 _id
"dest": {
"es": {
"action": "delete", # 在 es 中执行删除操作
... # 与上面的 index 和 type 相同
}
}
}
]
},
...
]更多示例正在更新
常见问题
为什么我的增量同步不及时?
-
连接本地数据库增量同步不及时
该情况暂未收到过反馈,如能复现请联系作者。
-
连接线上数据库发现增量同步不及时
2.1 推荐使用内网IP连接数据库。连接线上数据库(如开启在阿里、腾讯服务器上的Mysql)时,推荐使用内网IP地址,因为外网IP会受到带宽等限制导致获取binlog数据速度受限,最终可能造成同步延时。
待改进
- 据部分用户反馈,全量同步百万级以上的数据性能不佳。
未完待续
文档近期会较频繁更新,任何问题、建议都收到欢迎,请在issues留言,会在24小时内回复;或联系QQ、微信: 358807551;
把Mysql的数据同步到Elasticsearch是个很常见的需求,但在Github里找到的同步工具用起来或多或少都有些别扭。
例如:某记录内容为"aaa|bbb|ccc",将其按|分割成数组同步到es,这样的简单任务都难以实现,再加上配置繁琐,文档语焉不详...
所以我写了个同步工具MysqlsMom:力求用最简单的配置完成复杂的同步任务。目前除了我所在的部门,也有越来越多的互联网公司在生产环境中使用该工具了。
欢迎各位大佬进行试用并提出意见,任何建议、鼓励、批评都受到欢迎。
github: https://github.com/m358807551/mysqlsmom
简介:同步 Mysql 数据到 elasticsearch 的工具; QQ、微信:358807551
特点
- 纯 Python 编写;
- 支持基于 sql 语句的全量同步,基于 binlog 的增量同步,基于更新字段的增量同步三种同步方式;
- 全量更新只占用少量内存;支持通过sql语句同步数据;
- 增量更新自动断点续传;
- 取自 Mysql 的数据可经过一系列自定义函数的处理后再同步至 Elasticsearch;
- 能用非常简单的配置完成复杂的同步任务;
环境
- python2.7;
- 增量同步需开启 redis;
- 分析 binlog 的增量同步需要 Mysql 开启 binlog(binlog-format=row);
快速开始
全量同步MySql数据到es
-
clone 项目到本地;
-
安装依赖;
cd mysqlsmom pip install -r requirements.txt默认支持 elasticsearch-2.4版本,支持其它版本请运行(将5.4换成需要的elasticsearch版本)
pip install --upgrade elasticsearch==5.4 -
编辑 ./config/example_init.py,按注释提示修改配置;
# coding=utf-8 STREAM = "INIT" # 修改数据库连接 CONNECTION = { 'host': '127.0.0.1', 'port': 3306, 'user': 'root', 'passwd': '' } # 修改elasticsearch节点 NODES = [{"host": "127.0.0.1", "port": 9200}] TASKS = [ { "stream": { "database": "test_db", # 在此数据库执行sql语句 "sql": "select * from person" # 将该sql语句选中的数据同步到 elasticsearch }, "jobs": [ { "actions": ["insert", "update"], "pipeline": [ {"set_id": {"field": "id"}} # 默认设置 id字段的值 为elasticsearch中的文档id ], "dest": { "es": { "action": "upsert", "index": "test_index", # 设置 index "type": "test", # 设置 type "nodes": NODES } } } ] } ] -
运行
cd mysqlsmom python mysqlsmom.py ./config/example_init.py等待同步完成即可;
分析 binlog 的增量同步
-
确保要增量同步的MySql数据库开启binlog,且开启redis(为了存储最后一次读到的binlog文件名及读到的位置。未来可能支持本地文件存储该信息。)
-
下载项目到本地,且安装好依赖后,编辑 ./config/example_init.py,按注释提示修改配置;
# coding=utf-8 STREAM = "BINLOG" SERVER_ID = 99 # 确保每个用于binlog同步的配置文件的SERVER_ID不同; SLAVE_UUID = __name__ # 配置开启binlog权限的MySql连接 BINLOG_CONNECTION = { 'host': '127.0.0.1', 'port': 3306, 'user': 'root', 'passwd': '' } # 配置es节点 NODES = [{"host": "127.0.0.1", "port": 9200}] TASKS = [ { "stream": { "database": "test_db", # [table]所在的数据库 "table": "person" # 监控该表的binlog }, "jobs": [ { "actions": ["insert", "update"], "pipeline": [ {"only_fields": {"fields": ["id", "name", "age"]}}, # 只同步这些字段到es,注释掉该行则同步全部字段的值到es {"set_id": {"field": "id"}} # 设置es中文档_id的值取自 id(或根据需要更改)字段 ], "dest": { "es": { "action": "upsert", "index": "test_index", # 设置 index "type": "test", # 设置 type "nodes": NODES } } } ] } ] -
运行
cd mysqlsmom python mysqlsmom.py ./config/example_binlog.py该进程会一直运行,实时同步新增和更改后的数据到elasticsearch;
注意:第一次运行该进程时不会同步MySql中已存在的数据,从第二次运行开始,将接着上次同步停止时的位置继续同步;
同步旧数据请看全量同步MySql数据到es;
基于更新时间的增量同步
若 Mysql 表中有类似 update_time 的时间字段,且在每次插入、更新数据后将该字段的值设置为操作时间,则可在不用开启 binlog 的情况下进行增量同步。
-
下载项目到本地,且安装好依赖后,编辑 ./config/example_cron.py,按注释提示修改配置;
# coding=utf-8 STREAM = "CRON" # 修改数据库连接 CONNECTION = { 'host': '127.0.0.1', 'port': 3306, 'user': 'root', 'passwd': '' } # redis存储上次同步时间等信息 REDIS = { "host": "127.0.0.1", "port": 6379, "db": 0, "password": "password", # 不需要密码则注释或删掉该行 } # 一次同步 BULK_SIZE 条数据到elasticsearch,不设置该配置项默认为1 BULK_SIZE = 1 # 修改elasticsearch节点 NODES = [{"host": "127.0.0.1", "port": 9200}] TASKS = [ { "stream": { "database": "test_db", # 在此数据库执行sql语句 "sql": "select id, name from person where update_time >= ?", # 将该sql语句选中的数据同步到 elasticsearch "seconds": 10, # 每隔 seconds 秒同步一次, "init_time": "2018-08-15 18:05:47" # 只有第一次同步会加载 }, "jobs": [ { "pipeline": [ {"set_id": {"field": "id"}} # 默认设置 id字段的值 为 es 中的文档id ], "dest": { "es": { "action": "upsert", "index": "test_index", # 设置 index "type": "test" # 设置 type } } } ] } ] -
运行
cd mysqlsmom python mysqlsmom.py ./config/example_cron.py
组织架构
Mysqlsmom 使用实战
Mysqlsmom 的灵活性依赖于:
- 在 row_handlers.py 中添加自定义函数对取自Mysql的数据进行二次加工。
- 在 row_filters.py 中添加自定义函数决定是否要同步某一条数据。
- 在 config/ 目录下的任意配置文件应用上面的函数。
如果不了解 Python 也没关系,上述两个文件中自带的函数足以应付大多数种情况,遇到特殊的同步需求可以在 Github 发起 issue 或通过微信、QQ联系作者。
同步多张表
在一个配置文件中即可完成:
...
TASKS = [
# 同步表1
{
"stream": {
"database": "数据库名1",
"table": "表名1"
},
"jobs": [...]
}
# 同步表2
{
"stream": {
"database": "数据库名2",
"table": "表名2"
},
"jobs": [...]
}
]一个 Mysql Connection 对应一个配置文件。
一张表同步到多个索引
分为两种情况。
一种是把相同的数据同步到不同的索引,配置如下:
...
TASKS = [
{
"stream": {...},
"jobs": [
{
"actions": [...],
"pipeline": [...],
"dest": [
# 同步到索引1
{
"es": {"action": "upsert", "index": "索引1", "type": "类型1", "nodes": NODES},
},
# 同步到索引2
{
"es": {"action": "upsert", "index": "索引2", "type": "类型2", "nodes": NODES},
}
]
}
]
},
...
]另一种是把同一个表产生的数据经过不同的 pipeline 同步到不同的索引:
...
TASKS = [
{
"stream": {...},
"jobs": [
{
"actions": {...},
"pipeline": [...], # 对数据经过一系列处理
"dest": {"es": {"index": "索引1", ...}} # 同步到索引1
},
{
"actions": {...},
"pipeline": [...], # 与上面的pipeline不同
"dest": {"es": {"index": "索引2", ...}} # 同步到索引2
}
]
}
]- TASKS 中的每一项对应一张要同步的表。
- jobs 中的每一项对应对一条记录的一种处理方式。
- dest 中的每一项对应一个es索引类型。
只同步某些字段
对每条来自 Mysql 的 记录的处理都在 pipeline 中进行处理。
"pipeline": [
{"only_fields": {"fields": ["id", "name"]}}, # 只同步 id 和 name字段
{"set_id": {"field": "id"}} # 然后设置 id 字段为es中文档的_id
]字段重命名
对于 Mysql 中的字段名和 elasticsearch 中的域名不一致的情况:
"pipeline": [
# 将name重命名为name1,age 重命名为age1
{"replace_fields": {"name": ["name1"], "age": ["age1"]}},
{"set_id": {"field": "id"}}
]pipeline 会依次执行处理函数,上面的例子等价于:
"pipeline": [
# 先重命名 name 为 name1
{"replace_fields": {"name": ["name1"]}},
# 再重命名 age 为 age1
{"replace_fields": {"age": ["age1"]}},
{"set_id": {"field": "id"}}
]还有一种特殊情形,es 中两个字段存相同的数据,但是分词方式不同。
例如 name_default 的分析器为 default,name_raw 设置为不分词,需要将 name 的值同时同步到这两个域:
"pipeline": [
{"replace_fields": {"name": ["name_default", "name_raw"]}},
{"set_id": {"field": "id"}}
]当然上述问题有一个更好的解决方案,在 es 的 mappings 中配置 name 字段的 fields 属性即可,这超出了本文档的内容。
切分字符串为数组
有时 Mysql 存储字符串类似:"aaa|bbb|ccc",希望转化成数组: ["aaa", "bbb", "ccc"] 再进行同步
"pipeline": [
# tags 存储类似"aaa|bbb|ccc"的字符串,将 tags 字段的值按符号 `|` 切分成数组
{"split": {"field": "tags", "flag": "|"}},
{"set_id": {"field": "id"}}
] 同步删除文档
只有 binlog 同步 能实现删除 elasticsearch 中的文档,配置如下:
TASKS = [
{
"stream": {
"database": "test_db",
"table": "person"
},
"jobs": [
# 插入、更新
{
"actions": ["insert", "update"],
"pipeline": [
{"set_id": {"field": "id"}} # 设置 id 字段的值为 es 中文档 _id
],
"dest": {
"es": {
"action": "upsert",
...
}
}
},
# 重点在这里,配置删除
{
"actions": ["delete"], # 当读取到 binlog 中该表的删除操作时
"pipeline": [{"set_id": {"field": "id"}}], # 要删除的文档 _id
"dest": {
"es": {
"action": "delete", # 在 es 中执行删除操作
... # 与上面的 index 和 type 相同
}
}
}
]
},
...
]更多示例正在更新
常见问题
为什么我的增量同步不及时?
-
连接本地数据库增量同步不及时
该情况暂未收到过反馈,如能复现请联系作者。
-
连接线上数据库发现增量同步不及时
2.1 推荐使用内网IP连接数据库。连接线上数据库(如开启在阿里、腾讯服务器上的Mysql)时,推荐使用内网IP地址,因为外网IP会受到带宽等限制导致获取binlog数据速度受限,最终可能造成同步延时。
待改进
- 据部分用户反馈,全量同步百万级以上的数据性能不佳。
未完待续
文档近期会较频繁更新,任何问题、建议都收到欢迎,请在issues留言,会在24小时内回复;或联系QQ、微信: 358807551;
收起阅读 »

