

请教一下关于ES reindex后新的索引size比旧的索引size多了十分之一的大小问题
Elasticsearch | 作者 LZY_lee | 发布于2019年08月28日 | 阅读数:6956
我用的ES版本是7.3,节点有三个,所有的索引都是动态映射,没动过,而且我看了下他们两个自动生成的mapping是一样。
旧索引"ukraine"的配置为2个分片没有副本,setting为以下
"ukraine" : {
"settings" : {
"index" : {
"refresh_interval" : "20s",
"number_of_shards" : "2",
"provided_name" : "ukraine",
"merge" : {
"scheduler" : {
"max_thread_count" : "1"
}
},
"creation_date" : "1565748461617",
"unassigned" : {
"node_left" : {
"delayed_timeout" : "12h"
}
},
"number_of_replicas" : "0",
"uuid" : "4at3-BWcQYyOCzyOVUsiyQ",
"version" : {
"created" : "7030099"
}
}
}
},
新索引"ukraine_1"的数据配置为三个分片没有副本,setting为以下
"ukraine_1" : {
"settings" : {
"index" : {
"refresh_interval" : "20s",
"number_of_shards" : "3",
"provided_name" : "ukraine_1",
"creation_date" : "1566913563202",
"number_of_replicas" : "0",
"uuid" : "4Gl_efE-SOKmb7Wi9e19vw",
"version" : {
"created" : "7030099"
}
}
}
},
然后使用的reindex命令是
POST _reindex?wait_for_completion=false&refresh
{
"source": {
"index": "ukraine"
},
"dest": {
"index": "ukraine_1",
"type": "bill"
}
}
图片是插件看到的一个信息,索引现在的一个问题就是为什么配置差不多的情况下,大小差了几个G呢?
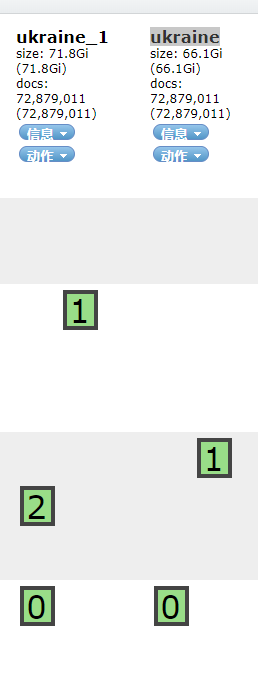
旧索引"ukraine"的配置为2个分片没有副本,setting为以下
"ukraine" : {
"settings" : {
"index" : {
"refresh_interval" : "20s",
"number_of_shards" : "2",
"provided_name" : "ukraine",
"merge" : {
"scheduler" : {
"max_thread_count" : "1"
}
},
"creation_date" : "1565748461617",
"unassigned" : {
"node_left" : {
"delayed_timeout" : "12h"
}
},
"number_of_replicas" : "0",
"uuid" : "4at3-BWcQYyOCzyOVUsiyQ",
"version" : {
"created" : "7030099"
}
}
}
},
新索引"ukraine_1"的数据配置为三个分片没有副本,setting为以下
"ukraine_1" : {
"settings" : {
"index" : {
"refresh_interval" : "20s",
"number_of_shards" : "3",
"provided_name" : "ukraine_1",
"creation_date" : "1566913563202",
"number_of_replicas" : "0",
"uuid" : "4Gl_efE-SOKmb7Wi9e19vw",
"version" : {
"created" : "7030099"
}
}
}
},
然后使用的reindex命令是
POST _reindex?wait_for_completion=false&refresh
{
"source": {
"index": "ukraine"
},
"dest": {
"index": "ukraine_1",
"type": "bill"
}
}
图片是插件看到的一个信息,索引现在的一个问题就是为什么配置差不多的情况下,大小差了几个G呢?

7 个回复
Goun
赞同来自: LZY_lee
原因2:ID变了,导致hash到不同的shard中,shard中的倒排索引规则不一定,导致磁盘中存的大小也不一样
God_lockin
赞同来自:
laoyang360 - 《一本书讲透Elasticsearch》作者,Elastic认证工程师 [死磕Elasitcsearch]知识星球地址:http://t.cn/RmwM3N9;微信公众号:铭毅天下; 博客:https://elastic.blog.csdn.net
赞同来自:
LZY_lee
赞同来自:
LZY_lee
赞同来自:
zhengguo
赞同来自:
举个例子,当然底层应该是远远没有这么简单:
假设一个索引有三个文档,doc1、doc2、doc3 都含有hello这个词
那么如果两个分片
三个分片就是
zqc0512 - andy zhou
赞同来自:
这玩意 数据条目对就行。还在乎这点资源?一般晚上一起操作