


routing
kibana里的Search Profiler怎么指定routing?
回复Kibana • dotNetDR_ 发起了问题 • 1 人关注 • 0 个回复 • 3272 次浏览 • 2020-12-30 14:19
玩转Elasticsearch routing功能
Elasticsearch • mushao999 发表了文章 • 5 个评论 • 8258 次浏览 • 2019-12-01 19:24
Elasticsearch是一个搭建在Lucene搜索引擎库基础之上的搜索服务平台。它在单机的Lucene搜索引擎库基础之上增加了分布式设计,translog等特性,增强了搜索引擎的性能,高可用性,高可扩性等。
Elasticsearch分布式设计的基本思想是Elasticsearch集群由多个服务器节点组成,集群中的一个索引分为多个分片,每个分片可以分配在不同的节点上。其中每个分片都是一个单独的功能完成的Lucene实例,可以独立地进行写入和查询服务,ES中存储的数据分布在集群分片的一个或多个上,其结构简单描述为下图。
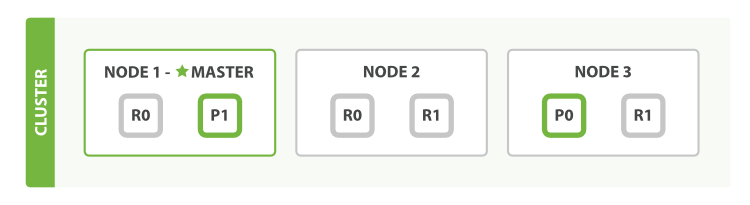
在上面的架构图中,集群由三个节点组成,每个节点上有两个分片,想要读写文档就必须知道文档被分配在哪个分片上,这也正是本文要讲的routing功能的作用。
1. 工作原理
1.1 routing参数
routing参数是一个可选参数,默认使用文档的_id值,可以用在INDEX, UPDATE,GET, SEARCH, DELETE等各种操作中。在写入(包括更新)时,用于计算文档所属分片,在查询(GET请求或指定了routing的查询)中用于限制查询范围,提高查询速度。
1.2 计算方法
ES中shardId的计算公式如下:
shardId = hash(_routing) % num_primary_shards通过该公式可以保证使用相同routing的文档被分配到同一个shard上,当然在默认情况下使用_id作为routing起到将文档均匀分布到多个分片上防止数据倾斜的作用。
1.3 routing_partition_size参数
使用了routing参数可以让routing值相同的文档分配到同一个分片上,从而减少查询时需要查询的shard数,提高查询效率。但是使用该参数容易导致数据倾斜。为此,ES还提供了一个index.routing_partition_size参数(仅当使用routing参数时可用),用于将routing相同的文档映射到集群分片的一个子集上,这样一方面可以减少查询的分片数,另一方面又可以在一定程度上防止数据倾斜。引入该参数后计算公式如下
shard_num = (hash(_routing) + hash(_id) % routing_partition_size) % num_primary_shards1.4 源码解读
如下为计算文档归属分片的源码,从源码中我们可以看到ES的哈希算法使用的是Murmur3,取模使用的是java的floorMod
version: 6.5
path: org\elasticsearch\cluster\routing\OperationRouting.java
public static int generateShardId(IndexMetaData indexMetaData, @Nullable String id, @Nullable String routing) {
final String effectiveRouting;
final int partitionOffset;
if (routing == null) {
assert(indexMetaData.isRoutingPartitionedIndex() == false) : "A routing value is required for gets from a partitioned index";
effectiveRouting = id; //默认使用id
} else {
effectiveRouting = routing;
}
if (indexMetaData.isRoutingPartitionedIndex()) {//使用了routing_partition_size参数
partitionOffset = Math.floorMod(Murmur3HashFunction.hash(id), indexMetaData.getRoutingPartitionSize());
} else {
// we would have still got 0 above but this check just saves us an unnecessary hash calculation
partitionOffset = 0;
}
return calculateScaledShardId(indexMetaData, effectiveRouting, partitionOffset);
}
private static int calculateScaledShardId(IndexMetaData indexMetaData, String effectiveRouting, int partitionOffset) {
final int hash = Murmur3HashFunction.hash(effectiveRouting) + partitionOffset;
// we don't use IMD#getNumberOfShards since the index might have been shrunk such that we need to use the size
// of original index to hash documents
return Math.floorMod(hash, indexMetaData.getRoutingNumShards()) / indexMetaData.getRoutingFactor();
}2. 存在的问题及解决方案
2.1 数据倾斜
如前面所述,用户使用自定义routing可以控制文档的分配位置,从而达到将相似文档放在同一个或同一批分片的目的,减少查询时的分片个数,提高查询速度。然而,这也意味着数据无法像默认情况那么均匀的分配到各分片和各节点上,从而会导致各节点存储和读写压力分布不均,影响系统的性能和稳定性。对此可以从以下两个方面进行优化
- 使用
routing_partition_size参数
如前面所述,该参数可以使routing相同的文档分配到一批分片(集群分片的子集)而不是一个分片上,从而可以从一定程度上减轻数据倾斜的问题。该参数的效果与其值设置的大小有关,当该值等于number_of_shard时,routing将退化为与未指定一样。当然该方法只能减轻数据倾斜,并不能彻底解决。 - 合理划分数据和设置routing值
从前面的分析,我们可以得到文档分片计算的公式,公式中的hash算法和取模算法也已经通过源码获取。因此用户在划分数据时,可以首先明确数据要划分为几类,每一类数据准备划分到哪部分分片上,再结合分片计算公式计算出合理的routing值,当然也可以在routing参数设置之前设置一个自定义hash函数来实现,从而实现数据的均衡分配。 - routing前使用自定义hash函数
很多情况下,用户并不能提前确定数据的分类值,为此可以在分类值和routing值之间设置一个hash函数,保证分类值散列后的值更均匀,使用该值作为routing,从而防止数据倾斜。
2.2 异常行为
ES的id去重是在分片维度进行的,之所以这样做是ES因为默认情况下使用_id作为routing值,这样id相同的文档会被分配到相同的分片上,因此只需要在分片维度做id去重即可保证id的唯一性。
然而当使用了自定义routing后,id相同的文档如果指定了不同的routing是可能被分配到不同的分片上的,从而导致同一个索引中出现两个id一样的文档,这里之所以说“可能”是因为如果不同的routing经过计算后仍然被映射到同一个分片上,去重还是可以生效的。因此这里会出现一个不稳定的情况,即当对id相同routing不同的文档进行写入操作时,有的时候被更新,有的时候会生成两个id相同的文档,具体可以使用下面的操作复现
# 出现两个id一样的情况
POST _bulk
{"index":{"_index":"routing_test","_id":"123","routing":"abc"}}
{"name":"zhangsan","age":18}
{"index":{"_index":"routing_test","_id":"123","routing":"xyz"}}
{"name":"lisi","age":22}
GET routing_test/_search
# 相同id被更新的情况
POST _bulk
{"index":{"_index":"routing_test_2","_id":"123","routing":"123"}}
{"name":"zhangsan","age":18}
{"index":{"_index":"routing_test_2","_id":"123","routing":"123456"}}
{"name":"lisi","age":22}
GET routing_test_2/_search以上测试场景在5.6.4, 6.4.3, 6.8.2集群上均验证会出现,在7.2.1集群上没有出现(可能是id去重逻辑发生了变化,这个后续研究一下后更新)。
对于这种场景,虽然在响应行为不一致,但是由于属于未按正常使用方式使用(id相同的文档应该使用相同的routing),也属于可以理解的情况,官方文档上也有对应描述, 参考地址
3. 常规用法
3.1 文档划分及routing指定
- 明确文档划分
使用routing是为了让查询时有可能出现在相同结果集的文档被分配到一个或一批分片上。因此首先要先明确哪些文档应该被分配在一起,对于这些文档使用相同的routing值,常规的一些自带分类信息的文档,如学生的班级属性,产品的分类等都可以作为文档划分的依据。 - 确定各类别的目标分片
当然这一步不是必须的,但是合理设置各类数据的目标分片,让他们尽量均匀分配,可以防止数据倾斜。因此建议在使用前就明确哪一类数据准备分配在哪一个或一批分片上,然后通过计算给出这类文档的合理routing值 - routing分布均匀
在很多场景下分类有哪些值不确定,因此无法明确划分各类数据的分片归属并计算出routing值,对于这种情况,建议可以在routing之前增加一个hash函数,让不同文档分类的值通过哈希尽量散列得更均匀一些,从而保证数据分布平衡。
3.2 routing的使用
- 写入操作
文档的PUT, POST, BULK操作均支持routing参数,在请求中带上routing=xxx即可。使用了routing值即可保证使用相同routing值的文档被分配到一个或一批分片上。 - GET操作
对于使用了routing写入的文档,在GET时必须指定routing,否则可能导致404,这与GET的实现机制有关,GET请求会先根据routing找到对应的分片再获取文档,如果对写入使用routing的文档GET时没有指定routing,那么会默认使用id进行routing从而大概率无法获得文档。 - 查询操作
查询操作可以在body中指定_routing参数(可以指定多个)来进行查询。当然不指定_routing也是可以查询出结果的,不过是遍历所有的分片,指定了_routing后,查询仅会对routing对应的一个或一批索引进行检索,从而提高查询效率,这也是很多用户使用routing的主要目的,查询操作示例如下:GET my_index/_search { "query": { "terms": { "_routing": [ "user1" ] } } } - UPDATE或DELETE操作
UPDATE或DELETE操作与GET操作类似,也是先根据routing确定分片,再进行更新或删除操作,因此对于写入使用了routing的文档,必须指定routing,否则会报404响应。
3.3 设置routing为必选参数
从3.2的分析可以看出对于使用routing写入的文档,在进行GET,UPDATE或DELETE操作时如果不指定routing参数会出现异常。为此ES提供了一个索引mapping级别的设置,_routing.required, 来强制用户在INDEX,GET, DELETE,UPDATA一个文档时必须使用routing参数。当然查询时不受该参数的限制的。该参数的设置方式如下:
PUT my_index
{
"mappings": {
"_doc": {
"_routing": {
"required": true
}
}
}
}3.4 routing结合别名使用
别名功能支持设置routing, 如下:
POST /_aliases
{
"actions" : [
{
"add" : {
"index" : "test",
"alias" : "alias1",
"routing" : "1"
}
}
]
}还支持查询和写入使用不同的routing,[详情参考] 将routing和别名结合,可以对使用者屏蔽读写时使用routing的细节,降低误操作的风险,提高操作的效率。
routing是ES中相对高阶一些的用法,在用户了解业务数据分布和查询需求的基础之上,可以对查询性能进行优化,然而使用不当会导致数据倾斜,重复ID等问题。本文介绍了routing的原理,问题及使用技巧,希望对大家有帮助,欢迎评论讨论
欢迎关注公众号Elastic慕容,和我一起进入Elastic的奇妙世界吧

elasticsearch5.6.6,java,RestHighLevelClient,使用路由(routing)后更慢了

Elasticsearch • xys2333 回复了问题 • 3 人关注 • 2 个回复 • 7537 次浏览 • 2018-05-21 10:54

es-hadoop routing异常
Elasticsearch • medcl 回复了问题 • 3 人关注 • 1 个回复 • 4018 次浏览 • 2018-02-08 21:46
用routing做的路由 查询结果还会出现别的路由下的数据
回复Elasticsearch • xiaolongzhang 发起了问题 • 1 人关注 • 0 个回复 • 3394 次浏览 • 2017-12-07 10:22

es routing是否能准确控制
Elasticsearch • medcl 回复了问题 • 3 人关注 • 1 个回复 • 6188 次浏览 • 2017-02-23 15:47

使用elasticsearch 游标(routing) 使用

Elasticsearch • nihao 回复了问题 • 4 人关注 • 1 个回复 • 6602 次浏览 • 2016-08-17 14:41

es routing查询问题

Elasticsearch • yyppdd 回复了问题 • 6 人关注 • 4 个回复 • 10622 次浏览 • 2016-06-15 19:51
kibana里的Search Profiler怎么指定routing?
回复Kibana • dotNetDR_ 发起了问题 • 1 人关注 • 0 个回复 • 3272 次浏览 • 2020-12-30 14:19
elasticsearch5.6.6,java,RestHighLevelClient,使用路由(routing)后更慢了
回复Elasticsearch • xys2333 回复了问题 • 3 人关注 • 2 个回复 • 7537 次浏览 • 2018-05-21 10:54
用routing做的路由 查询结果还会出现别的路由下的数据
回复Elasticsearch • xiaolongzhang 发起了问题 • 1 人关注 • 0 个回复 • 3394 次浏览 • 2017-12-07 10:22
使用elasticsearch 游标(routing) 使用
回复Elasticsearch • nihao 回复了问题 • 4 人关注 • 1 个回复 • 6602 次浏览 • 2016-08-17 14:41
玩转Elasticsearch routing功能
Elasticsearch • mushao999 发表了文章 • 5 个评论 • 8258 次浏览 • 2019-12-01 19:24
Elasticsearch是一个搭建在Lucene搜索引擎库基础之上的搜索服务平台。它在单机的Lucene搜索引擎库基础之上增加了分布式设计,translog等特性,增强了搜索引擎的性能,高可用性,高可扩性等。
Elasticsearch分布式设计的基本思想是Elasticsearch集群由多个服务器节点组成,集群中的一个索引分为多个分片,每个分片可以分配在不同的节点上。其中每个分片都是一个单独的功能完成的Lucene实例,可以独立地进行写入和查询服务,ES中存储的数据分布在集群分片的一个或多个上,其结构简单描述为下图。
在上面的架构图中,集群由三个节点组成,每个节点上有两个分片,想要读写文档就必须知道文档被分配在哪个分片上,这也正是本文要讲的routing功能的作用。
1. 工作原理
1.1 routing参数
routing参数是一个可选参数,默认使用文档的_id值,可以用在INDEX, UPDATE,GET, SEARCH, DELETE等各种操作中。在写入(包括更新)时,用于计算文档所属分片,在查询(GET请求或指定了routing的查询)中用于限制查询范围,提高查询速度。
1.2 计算方法
ES中shardId的计算公式如下:
shardId = hash(_routing) % num_primary_shards通过该公式可以保证使用相同routing的文档被分配到同一个shard上,当然在默认情况下使用_id作为routing起到将文档均匀分布到多个分片上防止数据倾斜的作用。
1.3 routing_partition_size参数
使用了routing参数可以让routing值相同的文档分配到同一个分片上,从而减少查询时需要查询的shard数,提高查询效率。但是使用该参数容易导致数据倾斜。为此,ES还提供了一个index.routing_partition_size参数(仅当使用routing参数时可用),用于将routing相同的文档映射到集群分片的一个子集上,这样一方面可以减少查询的分片数,另一方面又可以在一定程度上防止数据倾斜。引入该参数后计算公式如下
shard_num = (hash(_routing) + hash(_id) % routing_partition_size) % num_primary_shards1.4 源码解读
如下为计算文档归属分片的源码,从源码中我们可以看到ES的哈希算法使用的是Murmur3,取模使用的是java的floorMod
version: 6.5
path: org\elasticsearch\cluster\routing\OperationRouting.java
public static int generateShardId(IndexMetaData indexMetaData, @Nullable String id, @Nullable String routing) {
final String effectiveRouting;
final int partitionOffset;
if (routing == null) {
assert(indexMetaData.isRoutingPartitionedIndex() == false) : "A routing value is required for gets from a partitioned index";
effectiveRouting = id; //默认使用id
} else {
effectiveRouting = routing;
}
if (indexMetaData.isRoutingPartitionedIndex()) {//使用了routing_partition_size参数
partitionOffset = Math.floorMod(Murmur3HashFunction.hash(id), indexMetaData.getRoutingPartitionSize());
} else {
// we would have still got 0 above but this check just saves us an unnecessary hash calculation
partitionOffset = 0;
}
return calculateScaledShardId(indexMetaData, effectiveRouting, partitionOffset);
}
private static int calculateScaledShardId(IndexMetaData indexMetaData, String effectiveRouting, int partitionOffset) {
final int hash = Murmur3HashFunction.hash(effectiveRouting) + partitionOffset;
// we don't use IMD#getNumberOfShards since the index might have been shrunk such that we need to use the size
// of original index to hash documents
return Math.floorMod(hash, indexMetaData.getRoutingNumShards()) / indexMetaData.getRoutingFactor();
}2. 存在的问题及解决方案
2.1 数据倾斜
如前面所述,用户使用自定义routing可以控制文档的分配位置,从而达到将相似文档放在同一个或同一批分片的目的,减少查询时的分片个数,提高查询速度。然而,这也意味着数据无法像默认情况那么均匀的分配到各分片和各节点上,从而会导致各节点存储和读写压力分布不均,影响系统的性能和稳定性。对此可以从以下两个方面进行优化
- 使用
routing_partition_size参数
如前面所述,该参数可以使routing相同的文档分配到一批分片(集群分片的子集)而不是一个分片上,从而可以从一定程度上减轻数据倾斜的问题。该参数的效果与其值设置的大小有关,当该值等于number_of_shard时,routing将退化为与未指定一样。当然该方法只能减轻数据倾斜,并不能彻底解决。 - 合理划分数据和设置routing值
从前面的分析,我们可以得到文档分片计算的公式,公式中的hash算法和取模算法也已经通过源码获取。因此用户在划分数据时,可以首先明确数据要划分为几类,每一类数据准备划分到哪部分分片上,再结合分片计算公式计算出合理的routing值,当然也可以在routing参数设置之前设置一个自定义hash函数来实现,从而实现数据的均衡分配。 - routing前使用自定义hash函数
很多情况下,用户并不能提前确定数据的分类值,为此可以在分类值和routing值之间设置一个hash函数,保证分类值散列后的值更均匀,使用该值作为routing,从而防止数据倾斜。
2.2 异常行为
ES的id去重是在分片维度进行的,之所以这样做是ES因为默认情况下使用_id作为routing值,这样id相同的文档会被分配到相同的分片上,因此只需要在分片维度做id去重即可保证id的唯一性。
然而当使用了自定义routing后,id相同的文档如果指定了不同的routing是可能被分配到不同的分片上的,从而导致同一个索引中出现两个id一样的文档,这里之所以说“可能”是因为如果不同的routing经过计算后仍然被映射到同一个分片上,去重还是可以生效的。因此这里会出现一个不稳定的情况,即当对id相同routing不同的文档进行写入操作时,有的时候被更新,有的时候会生成两个id相同的文档,具体可以使用下面的操作复现
# 出现两个id一样的情况
POST _bulk
{"index":{"_index":"routing_test","_id":"123","routing":"abc"}}
{"name":"zhangsan","age":18}
{"index":{"_index":"routing_test","_id":"123","routing":"xyz"}}
{"name":"lisi","age":22}
GET routing_test/_search
# 相同id被更新的情况
POST _bulk
{"index":{"_index":"routing_test_2","_id":"123","routing":"123"}}
{"name":"zhangsan","age":18}
{"index":{"_index":"routing_test_2","_id":"123","routing":"123456"}}
{"name":"lisi","age":22}
GET routing_test_2/_search以上测试场景在5.6.4, 6.4.3, 6.8.2集群上均验证会出现,在7.2.1集群上没有出现(可能是id去重逻辑发生了变化,这个后续研究一下后更新)。
对于这种场景,虽然在响应行为不一致,但是由于属于未按正常使用方式使用(id相同的文档应该使用相同的routing),也属于可以理解的情况,官方文档上也有对应描述, 参考地址
3. 常规用法
3.1 文档划分及routing指定
- 明确文档划分
使用routing是为了让查询时有可能出现在相同结果集的文档被分配到一个或一批分片上。因此首先要先明确哪些文档应该被分配在一起,对于这些文档使用相同的routing值,常规的一些自带分类信息的文档,如学生的班级属性,产品的分类等都可以作为文档划分的依据。 - 确定各类别的目标分片
当然这一步不是必须的,但是合理设置各类数据的目标分片,让他们尽量均匀分配,可以防止数据倾斜。因此建议在使用前就明确哪一类数据准备分配在哪一个或一批分片上,然后通过计算给出这类文档的合理routing值 - routing分布均匀
在很多场景下分类有哪些值不确定,因此无法明确划分各类数据的分片归属并计算出routing值,对于这种情况,建议可以在routing之前增加一个hash函数,让不同文档分类的值通过哈希尽量散列得更均匀一些,从而保证数据分布平衡。
3.2 routing的使用
- 写入操作
文档的PUT, POST, BULK操作均支持routing参数,在请求中带上routing=xxx即可。使用了routing值即可保证使用相同routing值的文档被分配到一个或一批分片上。 - GET操作
对于使用了routing写入的文档,在GET时必须指定routing,否则可能导致404,这与GET的实现机制有关,GET请求会先根据routing找到对应的分片再获取文档,如果对写入使用routing的文档GET时没有指定routing,那么会默认使用id进行routing从而大概率无法获得文档。 - 查询操作
查询操作可以在body中指定_routing参数(可以指定多个)来进行查询。当然不指定_routing也是可以查询出结果的,不过是遍历所有的分片,指定了_routing后,查询仅会对routing对应的一个或一批索引进行检索,从而提高查询效率,这也是很多用户使用routing的主要目的,查询操作示例如下:GET my_index/_search { "query": { "terms": { "_routing": [ "user1" ] } } } - UPDATE或DELETE操作
UPDATE或DELETE操作与GET操作类似,也是先根据routing确定分片,再进行更新或删除操作,因此对于写入使用了routing的文档,必须指定routing,否则会报404响应。
3.3 设置routing为必选参数
从3.2的分析可以看出对于使用routing写入的文档,在进行GET,UPDATE或DELETE操作时如果不指定routing参数会出现异常。为此ES提供了一个索引mapping级别的设置,_routing.required, 来强制用户在INDEX,GET, DELETE,UPDATA一个文档时必须使用routing参数。当然查询时不受该参数的限制的。该参数的设置方式如下:
PUT my_index
{
"mappings": {
"_doc": {
"_routing": {
"required": true
}
}
}
}3.4 routing结合别名使用
别名功能支持设置routing, 如下:
POST /_aliases
{
"actions" : [
{
"add" : {
"index" : "test",
"alias" : "alias1",
"routing" : "1"
}
}
]
}还支持查询和写入使用不同的routing,[详情参考] 将routing和别名结合,可以对使用者屏蔽读写时使用routing的细节,降低误操作的风险,提高操作的效率。
routing是ES中相对高阶一些的用法,在用户了解业务数据分布和查询需求的基础之上,可以对查询性能进行优化,然而使用不当会导致数据倾斜,重复ID等问题。本文介绍了routing的原理,问题及使用技巧,希望对大家有帮助,欢迎评论讨论
欢迎关注公众号Elastic慕容,和我一起进入Elastic的奇妙世界吧
