


k8s
极限网关助力好未来 Elasticsearch 容器化升级
Elasticsearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 5411 次浏览 • 2024-06-12 15:01
极限网关在好未来的最佳实践案例,轻松扛住日增百 TB 数据的流量,助力 ES 从物理机到云原生架构的改造,实现了流控、请求分析、安全管理、无缝迁移等场景。一次完美的客户体验~
背景
物理机架构时代
2022 年,好未来整个日志 Elasticsearch 拥有数十套服务集群,几百台物理机。这么多台机器耗费成本非常高,而且还要花费很大精力去维护。在人力资源有限情况下,存在非常多的弊端,运行成本高,不仅是机器折旧还有机柜等费用。
流量特征
这是来自某个业务线,如下图 1,真实流量,潮汐性非常明显。好未来有很多条业务线,几乎跟这个趋势都一致的,除了个别业务有“续报”、“开课”等活动特殊情况。潮汐性带来的问题就是高峰期 CPU、内存资源是可以消耗很高;低峰期资源使用量非常低,由于是物理架构,这些资源无法给其他业务线共享。
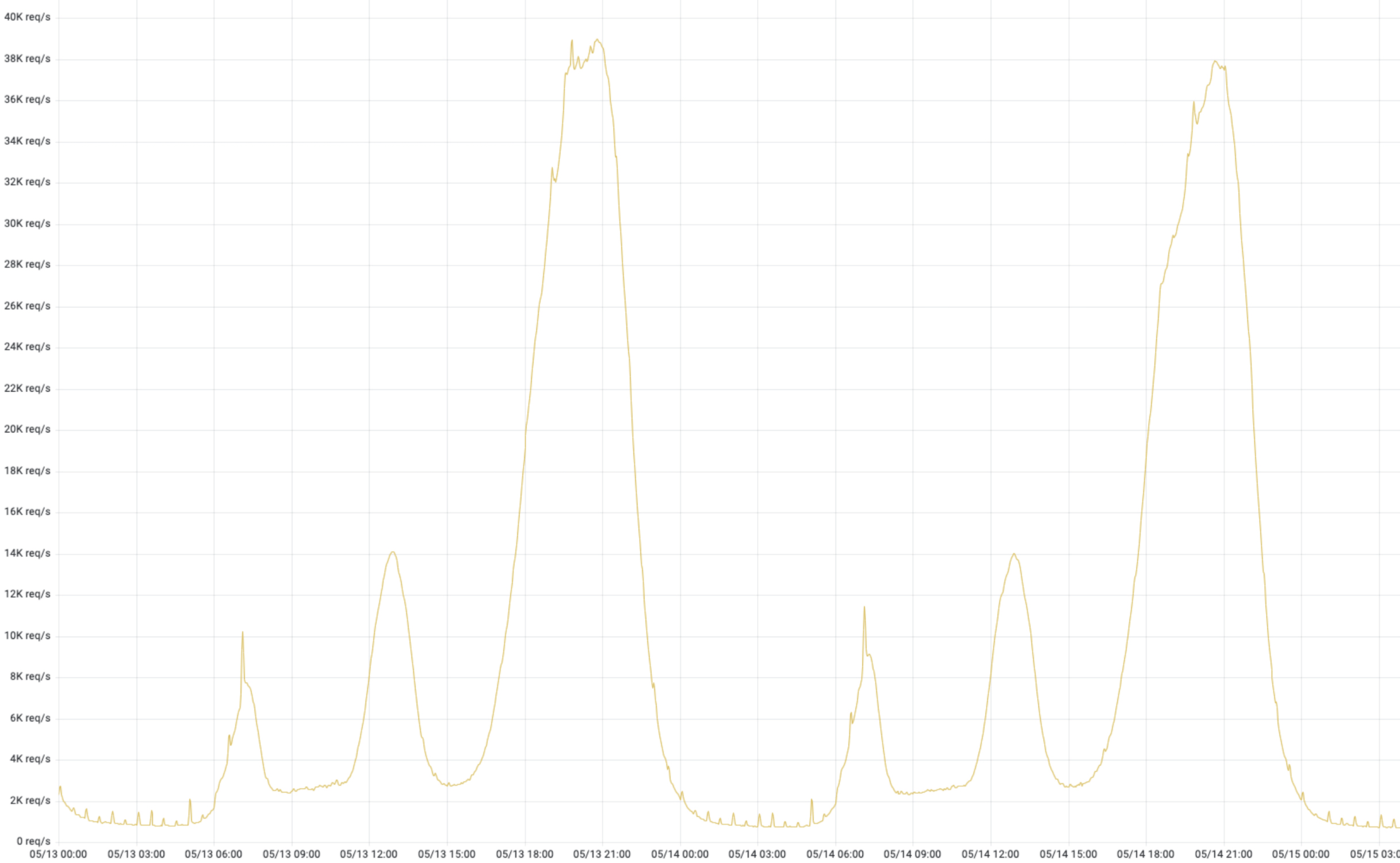
降本增效-容器化改造原动力
日志服务对成本的空前的压力促使我们推进 Elasticsearch 进行架构改造;如何改造,改造成什么样子,这两个问题一直是推进改造原动力。业界能够同时对水平扩展和垂直扩展就是 K8S,我们开始对 Elasticsearch 改造成能在 K8S 上运行进行探索,从而提升 CPU、内存利用率。
物理机时代,没办法把资源动态的扩缩,动态调配,资源隔离,单靠人力操作调度成本太高,几乎无法完成;集群对内存资源需求要比 CPU 资源大很多,由于机器型号配置是固定的,无法“定制”,这也会导致成本居高不下。所以,无论从那个方面来讲,容器化优势非常明显,既能够优化成本,也能够降低运维复杂度。
ES 容器化改造
进行架构升级重点难点- API 服务
改造过程,我们遇到了很多问题,比如容器 ES 版本和物理机 ES 版本不一致,如何让 ES API 能够兼容不同的 ES 版本,由于版本的不兼容,导致无法直接使用原有的 tribenode 进行服务,怎么提供一个高可用的 Elasticsearch API 服务。我们考虑到多个方面,比如使用官方推荐的 proxy 模式、第三方服务等进行选择,经过多方面对比,选择了极限网关 进行 tribenode 替换。
原始 ES API 服务痛点
- API 访问没有流量控制
- 可观测性差,而且稳定性一般
- 版本兼容性差
物理机时代 API 架构
在物理机时代 ES 集群,API 架构如图 2,可以明显看到 tribe node 对所有 ES 集群的“侵入性”是非常大的,这就带来了很多问题,比较严重的就是单个集群对 ES tribenode 的影响和版本升级带来的不兼容问题。

混合时代 API 架构
通过图 3,我们可以看到,极限网关对于版本兼容性很好,能够适配不同的版本。因此,最终选择极限网关作为下一代 ES API 服务方。

里程碑:全部 ES 集群容器化
在 2023 年 3 月份,通过 Elastic 官方 ECK 模式,完成全部日志 ES 集群容器化改造,拥有数百节点,1PB+ 数据存储,每日新增数据 100T 左右。紧接着,除了日志服务外,同时支持了好未来多条业务线。

极限网关实践
下面主要讲述了,为什么选择极限网关,以及极限网关在好未来落地、应用这些内容。
为什么选择极限网关?
学习成本低
我们可以从文档中看到极限网关,其架构简洁,语法简单,直观易懂。学习成本比较低,上手非常快,对新手友好。
性能强悍
经过压测,发现极限网关速度非常快,且针对 Elasticsearch 做了非常细致的优化,能成倍提升写入和查询的速度。
安全性高
支持多种认证方式,最简单的账号密码认证,可以给自定义多个账户密码,大大简化了 Elasticsearch 的安全设置,同时,还可以支持 LDAP 安全验证。
跨版本支持
我们容器化改造过程需要兼容不同版本的 Elasticsrearch,极限网关针对不同的 Elasticsearch 版本做了兼容和针对性处理,能够让业务代码无缝的进行适配,后端 Elasticsearch 集群版本升级能够做到无缝过渡,降低版本升级和数据迁移的复杂度,非常匹配我们的业务场景。
灵活可扩展
可灵活对每个请求进行干预和路由,支持路由的智能学习,内置丰富的过滤器,通过配置动态修改每个请求的处理逻辑,也支持通过插件来进行扩展,满足我们对流量的控制,尤其是限流、用户、IP 等这些功能非常实用。
启用安全策略-为 API 服务保驾护航
痛点
在升级之前使用 tribe 作为 API 服务提供后端,几乎相当于裸奔,没有任何认证策略;另外,tribe 本身的稳定性也有问题,官方在新版本逐渐废弃这种 CCS(跨集群搜索),期间出现多次服务崩溃。
极限网关解决问题
极限网关通过,“basic_auth” 插件,提供最基本的安全校验,使用起来非常方便;同时,极限网关提供 LDAP 插件,可以接入公共的 LDAP 服务,对所有的访问用户进行校验,安全策略对所有的用户生效,不用担心因为 IP 问题泄漏数据等。
强大的过滤功能
在使用 ES 集群过程中,许多场景,需要对请求进行控制、限制等操作。在这方便,感受到了极限网关强大的产品力。比如下面的两个场景
对异常流量进行限流
- 支持对 IP 限流
- 支持对 hostname 限流
- 支持 header 限流
对异常用户进行封禁
当 Elasticsearch 是通过 Basic Auth 或者 LDAP 方式来进行身份认证的时候,request_user_filter 过滤器可用来按请求的用户名信息来进行过滤。操作起来也非常简单,只需要 request_user_filter 这一个过滤器。
- request_user_filter:
include:
- "elastic"
exclude:
- "Ryan"总结来讲,主要有这些方面的功能:

优秀的可观测性
痛点
改造前经常为看不到直观的数据指标感到头疼,查看指标需要多个地方同时打开,去筛选,查找,非常繁琐,付出的成本非常大。为此,大家都再考虑如何优化这种情况,无奈优先级比较低,一直没有真正的投入时间去优化这块。
完美解决
使用了极限网关,通过收集请求日志,非常清晰的收集到想要的数据,具体如下:
- 总体方面:
- 流量曲线
- 状态码占比
- 缓存统计
- 每台网关请求流量
- 细节方面:
- 打印每次请求语句
- 可以查看请求到具体 ES 节点流量
- 可以查看过滤器的列表
通过下图,我们可以从管理视角直观的看到各种信息,这对于管理员来讲,省时省力,方便快捷。

意外收获:无缝迁移业务 Elasticsearch 上云
由于前期日志业务上云,受到非常好的反馈,多个业务线期望能够上云上服务,达到降本增效的目的。
支持双写
数据可以通过极限网关同时写入两个 ES 集群,能够保障数据完全一致,安全可靠。
无缝切换
切换很丝滑,影响非常小,能够让外界几乎感受不到服务波动。

通过使用极限网关,自建 ES 集群可以无缝的迁移上云,在整个迁移的过程中,两套集群通过网关进行了解耦,在迁移的过程中还能实现版本的无缝升级,极大降低了迁移成本,提高迁移效率,多次验证服务稳定可靠。
极限网关流量概览
这是其中一套极限网关的流量统计。用这部分数据进行巡检,一目了然,做到全局的掌控,提高感知力度。


极限网关使用总结
极限网关提供一系列高性能和高可靠性的网关服务。使用这样的服务给我们带来以下好处:
- 可观测性好:极限网关可以动态的对 Elasticsearch 运行过程中请求进行拦截和分析,通过指标和日志来了解集群运行状态,这些指标可以用于提升性能和业务优化。
- 增强安全性:包含先进的安全机制,如 basicauth、LDAP 等支持,保护用户数据不受未授权访问和各种网络威胁的侵害。
- 高稳定性:通过冗余设计和故障转移机制,极限网关能够确保网络服务的高可用性,即使在某些组件发生故障时也能保持服务不中断,单版本最长服务超过 15 个月。
- 易于管理:通过提供 INFINI Console 简洁直观的管理界面,让用户能够轻松配置和监控网络状态,提升管理效率。
- 客户支持:良好的客户服务支持可以帮助用户快速解决使用过程中遇到的问题,提供专业的技术指导。
综上所述,极限网关为用户提供了一个高速、安全、稳定且易于管理的 ES 网关,适合对网络性能有较高要求的个人和企业用户。
未来规划
第一阶段,完成了日志 ES 集群,所有集群的容器化改造,合并,成功的把成本降低了 60%以上。这期间积累了丰富容器化经验,为业务 ES 集群上容器做了良好的铺垫;成本优势和运维优势吸引越来越多的业务接入到容器化 ES 集群。
提升 ES 集群效能--新技术应用&&版本升级
- 极限科技官方推荐的 Easysearch 在压缩率,查询速度等等方面有很多的优势,通过长时间的测试稳定性,新特性,对比云原生的 ES 集群,根据测试结果,给“客户”提供多种选择,这也是工作重点之一。
- 我们当前使用的 ES 版本是 6.8,已经远远落后于官方版本,今年我们计划在选择合适的集群升级 ES 版本,拥抱更多官方提供的特性。
混合(多)云架构支持
随着越来越多的 ES 集群在机房的 K8S 集群部署,这里资源出现了紧张局面。 我们尝试在云上部署自建 ES 集群,弥补机房资源有限,无法大规模扩容,同时能够支持多活场景,满足更多客户的不同需求。混合云主要实现以下几种能力:
1、扩缩容:满足不同业务灵活适配
混合(多)云部署,可以让负载内部私有云 ES,同时部署到公有云,提升扩展 IT 基础设施不仅局限于 CPU、内存,还有存储。比如某一个业务要做活动,预估流量“大爆发”,需要提前准备大规模资源,在机房内根本来不及采购扩容支持,然而在公有云上就能很方便扩容、缩容。在云上搭建 ES 集群,设置满足需求的数量、容量、配置,配合极限网关路由策略,精准的把控流量流向。

2、灾备:紧急情况快速部署,恢复 ES 集群读写
当机房级别大规模故障,部分业务实现了多活,单一的机房故障不会影响其服务能力,而此时比如日志查看等仍有需求,为了满足这部分“客户”需求,可以在云上 K8S 集群,快速搭建 ES 集群,恢复日志读写功能。

参考文档:
- https://infinilabs.cn/docs/latest/gateway
- https://www.elastic.co/guide/en/cloud-on-K8S/current/K8S-overview.html
作者:张华勋,前新浪 CDN 研发,工作主要涉及 Mysql、MongoDB、Redis、Elasticsearch、流量调度等组件和系统,以及运维自动化、平台化等工作。现就职于好未来。
关于好未来
好未来(NYSE:TAL)是一家以内容能力与科技能力为基础,以科教、科创、科普为战略方向,助力人的终身成长,并持续探索创新的科技公司。 好未来的前身学而思成立于 2003 年,2010 年在美国纽交所正式挂牌交易。好未来以“爱与科技助力终身成长”为使命,致力成为持续创新的组织。更多参见:https://www.100tal.com/
关于极限科技(INFINI Labs)

极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。

通过 Helm Chart 部署 Easysearch
经验分享 • liaosy 发表了文章 • 0 个评论 • 3303 次浏览 • 2023-09-25 14:39

Easysearch 可以通过 Helm 快速部署了,快来看看吧!
Easysearch 的 Chart 仓库地址在这里 https://helm.infinilabs.com。
使用 Helm 部署 Easysearch 有两个前提条件:
我们先按照 Chart 仓库的说明来快速部署一下。
~ helm repo add infinilabs https://helm.infinilabs.com
~ cat << EOF | kubectl apply -n test -f -
apiVersion: cert-manager.io/v1
kind: Issuer
metadata:
name: easysearch-ca-issuer
spec:
selfSigned: {}
---
apiVersion: cert-manager.io/v1
kind: Certificate
metadata:
name: easysearch-ca-certificate
spec:
commonName: easysearch-ca-certificate
duration: 87600h0m0s
isCA: true
issuerRef:
kind: Issuer
name: easysearch-ca-issuer
privateKey:
algorithm: ECDSA
size: 256
renewBefore: 2160h0m0s
secretName: easysearch-ca-secret
EOF
~ helm install easysearch infinilabs/easysearch -n test执行上面的两个命令之后,查看一下部署情况
~ kubectl get pod -n test
NAME READY STATUS RESTARTS AGE
easysearch-0 1/1 Running 0 38s
~ kubectl get svc -n test
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
easysearch-svc-headless ClusterIP None <none> 9200/TCP,9300/TCP 67s
~ kubectl exec -n test easysearch-0 -it -- curl -ku'admin:admin' https://localhost:9200
Defaulted container "easysearch" out of: easysearch, init-config (init)
{
"name" : "easysearch-0",
"cluster_name" : "infinilabs",
"cluster_uuid" : "JwhwwWHMQKy8l6_US7rB1A",
"version" : {
"distribution" : "easysearch",
"number" : "1.5.0",
"distributor" : "INFINI Labs",
"build_hash" : "5b5b117bc43e6793e7bb0cd8bd83567a5ef35be0",
"build_date" : "2023-09-07T14:55:21.232870Z",
"build_snapshot" : false,
"lucene_version" : "8.11.2",
"minimum_wire_lucene_version" : "7.7.0",
"minimum_lucene_index_compatibility_version" : "7.7.0"
},
"tagline" : "You Know, For Easy Search!"
}通过上面的验证,我们可以看到 Easysearch 已经部署完成,是不是很方便。
按照 Chart 仓库的指导说明部署的是一个单节点集群,那如果要部署多节点的要怎么办呢?下面让我们来研究一下 Easysearch Chart 包的源码 https://github.com/infinilabs/helm-charts/tree/main/charts/easysearch。
熟悉 Chart 包结构的小伙伴都清楚,Chart 包的变量配置一般都是在 values.yaml 文件中配置的。
我们先来看一下默认的 values.yaml 文件内容(这里只截选了一些可能需要变更的配置,完整内容请查阅源码):
- pod 副本数以及使用资源的配置
replicaCount: 1
resources:
limits:
cpu: 1000m
memory: 2Gi
requests:
cpu: 1000m
memory: 2Gi- 使用存储类型以及容量的配置
storageClassName: local-path
dataVolumeStorage: 100Gi- 集群名、主节点列表以及节点角色配置
clusterName: infinilabs
masterHosts: '"easysearch-0"'
discoverySeedHosts: '"easysearch-0.easysearch-svc-headless"'
nodeRoles: '"master","data","ingest","remote_cluster_client"'根据研究源码的结果,多节点集群的部署只需要我们调整部署的 pod 副本数、集群名、主节点列表以及节点角色这几个配置。下面让我们来实践一下:
1、集群规划
集群名:es-test
规模:3 主节点 + 3 数据节点 + 2 协调节点
2、Chart 的版本名
主节点:es-test-master
数据节点:es-test-data
协调节点:es-test-coordinate
3、根据节点角色创建不同的 values.yaml 文件
- es-test-master.yaml
replicaCount: 3
clusterName: es-test
masterHosts: '"es-test-master-easysearch-0","es-test-master-easysearch-1","es-test-master-easysearch-2"'
discoverySeedHosts: '"es-test-master-easysearch-0.es-test-master-easysearch-svc-headless","es-test-master-easysearch-1.es-test-master-easysearch-svc-headless","es-test-master-easysearch-2.es-test-master-easysearch-svc-headless"'
nodeRoles: '"master","ingest","remote_cluster_client"'- es-test-data.yaml
replicaCount: 3
clusterName: es-test
masterHosts: '"es-test-master-easysearch-0","es-test-master-easysearch-1","es-test-master-easysearch-2"'
discoverySeedHosts: '"es-test-master-easysearch-0.es-test-master-easysearch-svc-headless","es-test-master-easysearch-1.es-test-master-easysearch-svc-headless","es-test-master-easysearch-2.es-test-master-easysearch-svc-headless"'
nodeRoles: '"data","ingest","remote_cluster_client"'- es-test-coordinate.yaml
replicaCount: 2
clusterName: es-test
masterHosts: '"es-test-master-easysearch-0","es-test-master-easysearch-1","es-test-master-easysearch-2"'
discoverySeedHosts: '"es-test-master-easysearch-0.es-test-master-easysearch-svc-headless","es-test-master-easysearch-1.es-test-master-easysearch-svc-headless","es-test-master-easysearch-2.es-test-master-easysearch-svc-headless"'
nodeRoles: ""4、使用各节点角色的配置文件部署
~ helm install es-test-master infinilabs/easysearch -n test -f es-test-master.yaml
~ helm install es-test-data infinilabs/easysearch -n test -f es-test-data.yaml
~ helm install es-test-coordinate infinilabs/easysearch -n test -f es-test-coordinate.yaml5、验证
~ kubectl get pod -n test|grep es-test
es-test-master-easysearch-0 1/1 Running 0 5m57s
es-test-data-easysearch-0 1/1 Running 0 5m29s
es-test-coordinate-easysearch-0 1/1 Running 0 5m10s
es-test-master-easysearch-1 1/1 Running 0 4m57s
es-test-data-easysearch-1 1/1 Running 0 4m29s
es-test-coordinate-easysearch-1 1/1 Running 0 4m10s
es-test-master-easysearch-2 1/1 Running 0 3m56s
es-test-data-easysearch-2 1/1 Running 0 3m29s
~ kubectl exec -n test es-test-master-easysearch-0 -it -- curl -ku'admin:admin' https://localhost:9200/_cat/nodes?v
Defaulted container "easysearch" out of: easysearch, init-config (init)
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
10.42.0.130 12 63 12 1.53 2.67 2.11 - - es-test-coordinate-easysearch-0
10.42.0.136 53 65 52 1.53 2.67 2.11 dir - es-test-data-easysearch-1
10.42.0.139 6 63 14 1.53 2.67 2.11 - - es-test-coordinate-easysearch-1
10.42.0.133 10 63 14 1.53 2.67 2.11 imr - es-test-master-easysearch-1
10.42.0.149 58 65 59 1.53 2.67 2.11 dir - es-test-data-easysearch-2
10.42.0.124 53 68 35 1.53 2.67 2.11 imr * es-test-master-easysearch-0
10.42.0.127 56 65 46 1.53 2.67 2.11 dir - es-test-data-easysearch-0
10.42.0.146 15 63 18 1.53 2.67 2.11 imr - es-test-master-easysearch-2至此,多集群已部署完成。
关于 Easysearch

INFINI Easysearch 是一个分布式的近实时搜索与分析引擎,核心引擎基于开源的 Apache Lucene。Easysearch 的目标是提供一个轻量级的 Elasticsearch 可替代版本,并继续完善和支持更多的企业级功能。 与 Elasticsearch 相比,Easysearch 更关注在搜索业务场景的优化和继续保持其产品的简洁与易用性。

极限网关助力好未来 Elasticsearch 容器化升级
Elasticsearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 5411 次浏览 • 2024-06-12 15:01
极限网关在好未来的最佳实践案例,轻松扛住日增百 TB 数据的流量,助力 ES 从物理机到云原生架构的改造,实现了流控、请求分析、安全管理、无缝迁移等场景。一次完美的客户体验~
背景
物理机架构时代
2022 年,好未来整个日志 Elasticsearch 拥有数十套服务集群,几百台物理机。这么多台机器耗费成本非常高,而且还要花费很大精力去维护。在人力资源有限情况下,存在非常多的弊端,运行成本高,不仅是机器折旧还有机柜等费用。
流量特征
这是来自某个业务线,如下图 1,真实流量,潮汐性非常明显。好未来有很多条业务线,几乎跟这个趋势都一致的,除了个别业务有“续报”、“开课”等活动特殊情况。潮汐性带来的问题就是高峰期 CPU、内存资源是可以消耗很高;低峰期资源使用量非常低,由于是物理架构,这些资源无法给其他业务线共享。
降本增效-容器化改造原动力
日志服务对成本的空前的压力促使我们推进 Elasticsearch 进行架构改造;如何改造,改造成什么样子,这两个问题一直是推进改造原动力。业界能够同时对水平扩展和垂直扩展就是 K8S,我们开始对 Elasticsearch 改造成能在 K8S 上运行进行探索,从而提升 CPU、内存利用率。
物理机时代,没办法把资源动态的扩缩,动态调配,资源隔离,单靠人力操作调度成本太高,几乎无法完成;集群对内存资源需求要比 CPU 资源大很多,由于机器型号配置是固定的,无法“定制”,这也会导致成本居高不下。所以,无论从那个方面来讲,容器化优势非常明显,既能够优化成本,也能够降低运维复杂度。
ES 容器化改造
进行架构升级重点难点- API 服务
改造过程,我们遇到了很多问题,比如容器 ES 版本和物理机 ES 版本不一致,如何让 ES API 能够兼容不同的 ES 版本,由于版本的不兼容,导致无法直接使用原有的 tribenode 进行服务,怎么提供一个高可用的 Elasticsearch API 服务。我们考虑到多个方面,比如使用官方推荐的 proxy 模式、第三方服务等进行选择,经过多方面对比,选择了极限网关 进行 tribenode 替换。
原始 ES API 服务痛点
- API 访问没有流量控制
- 可观测性差,而且稳定性一般
- 版本兼容性差
物理机时代 API 架构
在物理机时代 ES 集群,API 架构如图 2,可以明显看到 tribe node 对所有 ES 集群的“侵入性”是非常大的,这就带来了很多问题,比较严重的就是单个集群对 ES tribenode 的影响和版本升级带来的不兼容问题。
混合时代 API 架构
通过图 3,我们可以看到,极限网关对于版本兼容性很好,能够适配不同的版本。因此,最终选择极限网关作为下一代 ES API 服务方。
里程碑:全部 ES 集群容器化
在 2023 年 3 月份,通过 Elastic 官方 ECK 模式,完成全部日志 ES 集群容器化改造,拥有数百节点,1PB+ 数据存储,每日新增数据 100T 左右。紧接着,除了日志服务外,同时支持了好未来多条业务线。
极限网关实践
下面主要讲述了,为什么选择极限网关,以及极限网关在好未来落地、应用这些内容。
为什么选择极限网关?
学习成本低
我们可以从文档中看到极限网关,其架构简洁,语法简单,直观易懂。学习成本比较低,上手非常快,对新手友好。
性能强悍
经过压测,发现极限网关速度非常快,且针对 Elasticsearch 做了非常细致的优化,能成倍提升写入和查询的速度。
安全性高
支持多种认证方式,最简单的账号密码认证,可以给自定义多个账户密码,大大简化了 Elasticsearch 的安全设置,同时,还可以支持 LDAP 安全验证。
跨版本支持
我们容器化改造过程需要兼容不同版本的 Elasticsrearch,极限网关针对不同的 Elasticsearch 版本做了兼容和针对性处理,能够让业务代码无缝的进行适配,后端 Elasticsearch 集群版本升级能够做到无缝过渡,降低版本升级和数据迁移的复杂度,非常匹配我们的业务场景。
灵活可扩展
可灵活对每个请求进行干预和路由,支持路由的智能学习,内置丰富的过滤器,通过配置动态修改每个请求的处理逻辑,也支持通过插件来进行扩展,满足我们对流量的控制,尤其是限流、用户、IP 等这些功能非常实用。
启用安全策略-为 API 服务保驾护航
痛点
在升级之前使用 tribe 作为 API 服务提供后端,几乎相当于裸奔,没有任何认证策略;另外,tribe 本身的稳定性也有问题,官方在新版本逐渐废弃这种 CCS(跨集群搜索),期间出现多次服务崩溃。
极限网关解决问题
极限网关通过,“basic_auth” 插件,提供最基本的安全校验,使用起来非常方便;同时,极限网关提供 LDAP 插件,可以接入公共的 LDAP 服务,对所有的访问用户进行校验,安全策略对所有的用户生效,不用担心因为 IP 问题泄漏数据等。
强大的过滤功能
在使用 ES 集群过程中,许多场景,需要对请求进行控制、限制等操作。在这方便,感受到了极限网关强大的产品力。比如下面的两个场景
对异常流量进行限流
- 支持对 IP 限流
- 支持对 hostname 限流
- 支持 header 限流
对异常用户进行封禁
当 Elasticsearch 是通过 Basic Auth 或者 LDAP 方式来进行身份认证的时候,request_user_filter 过滤器可用来按请求的用户名信息来进行过滤。操作起来也非常简单,只需要 request_user_filter 这一个过滤器。
- request_user_filter:
include:
- "elastic"
exclude:
- "Ryan"总结来讲,主要有这些方面的功能:
优秀的可观测性
痛点
改造前经常为看不到直观的数据指标感到头疼,查看指标需要多个地方同时打开,去筛选,查找,非常繁琐,付出的成本非常大。为此,大家都再考虑如何优化这种情况,无奈优先级比较低,一直没有真正的投入时间去优化这块。
完美解决
使用了极限网关,通过收集请求日志,非常清晰的收集到想要的数据,具体如下:
- 总体方面:
- 流量曲线
- 状态码占比
- 缓存统计
- 每台网关请求流量
- 细节方面:
- 打印每次请求语句
- 可以查看请求到具体 ES 节点流量
- 可以查看过滤器的列表
通过下图,我们可以从管理视角直观的看到各种信息,这对于管理员来讲,省时省力,方便快捷。
意外收获:无缝迁移业务 Elasticsearch 上云
由于前期日志业务上云,受到非常好的反馈,多个业务线期望能够上云上服务,达到降本增效的目的。
支持双写
数据可以通过极限网关同时写入两个 ES 集群,能够保障数据完全一致,安全可靠。
无缝切换
切换很丝滑,影响非常小,能够让外界几乎感受不到服务波动。
通过使用极限网关,自建 ES 集群可以无缝的迁移上云,在整个迁移的过程中,两套集群通过网关进行了解耦,在迁移的过程中还能实现版本的无缝升级,极大降低了迁移成本,提高迁移效率,多次验证服务稳定可靠。
极限网关流量概览
这是其中一套极限网关的流量统计。用这部分数据进行巡检,一目了然,做到全局的掌控,提高感知力度。
极限网关使用总结
极限网关提供一系列高性能和高可靠性的网关服务。使用这样的服务给我们带来以下好处:
- 可观测性好:极限网关可以动态的对 Elasticsearch 运行过程中请求进行拦截和分析,通过指标和日志来了解集群运行状态,这些指标可以用于提升性能和业务优化。
- 增强安全性:包含先进的安全机制,如 basicauth、LDAP 等支持,保护用户数据不受未授权访问和各种网络威胁的侵害。
- 高稳定性:通过冗余设计和故障转移机制,极限网关能够确保网络服务的高可用性,即使在某些组件发生故障时也能保持服务不中断,单版本最长服务超过 15 个月。
- 易于管理:通过提供 INFINI Console 简洁直观的管理界面,让用户能够轻松配置和监控网络状态,提升管理效率。
- 客户支持:良好的客户服务支持可以帮助用户快速解决使用过程中遇到的问题,提供专业的技术指导。
综上所述,极限网关为用户提供了一个高速、安全、稳定且易于管理的 ES 网关,适合对网络性能有较高要求的个人和企业用户。
未来规划
第一阶段,完成了日志 ES 集群,所有集群的容器化改造,合并,成功的把成本降低了 60%以上。这期间积累了丰富容器化经验,为业务 ES 集群上容器做了良好的铺垫;成本优势和运维优势吸引越来越多的业务接入到容器化 ES 集群。
提升 ES 集群效能--新技术应用&&版本升级
- 极限科技官方推荐的 Easysearch 在压缩率,查询速度等等方面有很多的优势,通过长时间的测试稳定性,新特性,对比云原生的 ES 集群,根据测试结果,给“客户”提供多种选择,这也是工作重点之一。
- 我们当前使用的 ES 版本是 6.8,已经远远落后于官方版本,今年我们计划在选择合适的集群升级 ES 版本,拥抱更多官方提供的特性。
混合(多)云架构支持
随着越来越多的 ES 集群在机房的 K8S 集群部署,这里资源出现了紧张局面。 我们尝试在云上部署自建 ES 集群,弥补机房资源有限,无法大规模扩容,同时能够支持多活场景,满足更多客户的不同需求。混合云主要实现以下几种能力:
1、扩缩容:满足不同业务灵活适配
混合(多)云部署,可以让负载内部私有云 ES,同时部署到公有云,提升扩展 IT 基础设施不仅局限于 CPU、内存,还有存储。比如某一个业务要做活动,预估流量“大爆发”,需要提前准备大规模资源,在机房内根本来不及采购扩容支持,然而在公有云上就能很方便扩容、缩容。在云上搭建 ES 集群,设置满足需求的数量、容量、配置,配合极限网关路由策略,精准的把控流量流向。
2、灾备:紧急情况快速部署,恢复 ES 集群读写
当机房级别大规模故障,部分业务实现了多活,单一的机房故障不会影响其服务能力,而此时比如日志查看等仍有需求,为了满足这部分“客户”需求,可以在云上 K8S 集群,快速搭建 ES 集群,恢复日志读写功能。
参考文档:
- https://infinilabs.cn/docs/latest/gateway
- https://www.elastic.co/guide/en/cloud-on-K8S/current/K8S-overview.html
作者:张华勋,前新浪 CDN 研发,工作主要涉及 Mysql、MongoDB、Redis、Elasticsearch、流量调度等组件和系统,以及运维自动化、平台化等工作。现就职于好未来。
关于好未来
好未来(NYSE:TAL)是一家以内容能力与科技能力为基础,以科教、科创、科普为战略方向,助力人的终身成长,并持续探索创新的科技公司。 好未来的前身学而思成立于 2003 年,2010 年在美国纽交所正式挂牌交易。好未来以“爱与科技助力终身成长”为使命,致力成为持续创新的组织。更多参见:https://www.100tal.com/
关于极限科技(INFINI Labs)
极限科技,全称极限数据(北京)科技有限公司,是一家专注于实时搜索与数据分析的软件公司。旗下品牌极限实验室(INFINI Labs)致力于打造极致易用的数据探索与分析体验。
极限科技是一支年轻的团队,采用天然分布式的方式来进行远程协作,员工分布在全球各地,希望通过努力成为中国乃至全球企业大数据实时搜索分析产品的首选,为中国技术品牌输出添砖加瓦。
通过 Helm Chart 部署 Easysearch
经验分享 • liaosy 发表了文章 • 0 个评论 • 3303 次浏览 • 2023-09-25 14:39
Easysearch 可以通过 Helm 快速部署了,快来看看吧!
Easysearch 的 Chart 仓库地址在这里 https://helm.infinilabs.com。
使用 Helm 部署 Easysearch 有两个前提条件:
我们先按照 Chart 仓库的说明来快速部署一下。
~ helm repo add infinilabs https://helm.infinilabs.com
~ cat << EOF | kubectl apply -n test -f -
apiVersion: cert-manager.io/v1
kind: Issuer
metadata:
name: easysearch-ca-issuer
spec:
selfSigned: {}
---
apiVersion: cert-manager.io/v1
kind: Certificate
metadata:
name: easysearch-ca-certificate
spec:
commonName: easysearch-ca-certificate
duration: 87600h0m0s
isCA: true
issuerRef:
kind: Issuer
name: easysearch-ca-issuer
privateKey:
algorithm: ECDSA
size: 256
renewBefore: 2160h0m0s
secretName: easysearch-ca-secret
EOF
~ helm install easysearch infinilabs/easysearch -n test执行上面的两个命令之后,查看一下部署情况
~ kubectl get pod -n test
NAME READY STATUS RESTARTS AGE
easysearch-0 1/1 Running 0 38s
~ kubectl get svc -n test
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
easysearch-svc-headless ClusterIP None <none> 9200/TCP,9300/TCP 67s
~ kubectl exec -n test easysearch-0 -it -- curl -ku'admin:admin' https://localhost:9200
Defaulted container "easysearch" out of: easysearch, init-config (init)
{
"name" : "easysearch-0",
"cluster_name" : "infinilabs",
"cluster_uuid" : "JwhwwWHMQKy8l6_US7rB1A",
"version" : {
"distribution" : "easysearch",
"number" : "1.5.0",
"distributor" : "INFINI Labs",
"build_hash" : "5b5b117bc43e6793e7bb0cd8bd83567a5ef35be0",
"build_date" : "2023-09-07T14:55:21.232870Z",
"build_snapshot" : false,
"lucene_version" : "8.11.2",
"minimum_wire_lucene_version" : "7.7.0",
"minimum_lucene_index_compatibility_version" : "7.7.0"
},
"tagline" : "You Know, For Easy Search!"
}通过上面的验证,我们可以看到 Easysearch 已经部署完成,是不是很方便。
按照 Chart 仓库的指导说明部署的是一个单节点集群,那如果要部署多节点的要怎么办呢?下面让我们来研究一下 Easysearch Chart 包的源码 https://github.com/infinilabs/helm-charts/tree/main/charts/easysearch。
熟悉 Chart 包结构的小伙伴都清楚,Chart 包的变量配置一般都是在 values.yaml 文件中配置的。
我们先来看一下默认的 values.yaml 文件内容(这里只截选了一些可能需要变更的配置,完整内容请查阅源码):
- pod 副本数以及使用资源的配置
replicaCount: 1
resources:
limits:
cpu: 1000m
memory: 2Gi
requests:
cpu: 1000m
memory: 2Gi- 使用存储类型以及容量的配置
storageClassName: local-path
dataVolumeStorage: 100Gi- 集群名、主节点列表以及节点角色配置
clusterName: infinilabs
masterHosts: '"easysearch-0"'
discoverySeedHosts: '"easysearch-0.easysearch-svc-headless"'
nodeRoles: '"master","data","ingest","remote_cluster_client"'根据研究源码的结果,多节点集群的部署只需要我们调整部署的 pod 副本数、集群名、主节点列表以及节点角色这几个配置。下面让我们来实践一下:
1、集群规划
集群名:es-test
规模:3 主节点 + 3 数据节点 + 2 协调节点
2、Chart 的版本名
主节点:es-test-master
数据节点:es-test-data
协调节点:es-test-coordinate
3、根据节点角色创建不同的 values.yaml 文件
- es-test-master.yaml
replicaCount: 3
clusterName: es-test
masterHosts: '"es-test-master-easysearch-0","es-test-master-easysearch-1","es-test-master-easysearch-2"'
discoverySeedHosts: '"es-test-master-easysearch-0.es-test-master-easysearch-svc-headless","es-test-master-easysearch-1.es-test-master-easysearch-svc-headless","es-test-master-easysearch-2.es-test-master-easysearch-svc-headless"'
nodeRoles: '"master","ingest","remote_cluster_client"'- es-test-data.yaml
replicaCount: 3
clusterName: es-test
masterHosts: '"es-test-master-easysearch-0","es-test-master-easysearch-1","es-test-master-easysearch-2"'
discoverySeedHosts: '"es-test-master-easysearch-0.es-test-master-easysearch-svc-headless","es-test-master-easysearch-1.es-test-master-easysearch-svc-headless","es-test-master-easysearch-2.es-test-master-easysearch-svc-headless"'
nodeRoles: '"data","ingest","remote_cluster_client"'- es-test-coordinate.yaml
replicaCount: 2
clusterName: es-test
masterHosts: '"es-test-master-easysearch-0","es-test-master-easysearch-1","es-test-master-easysearch-2"'
discoverySeedHosts: '"es-test-master-easysearch-0.es-test-master-easysearch-svc-headless","es-test-master-easysearch-1.es-test-master-easysearch-svc-headless","es-test-master-easysearch-2.es-test-master-easysearch-svc-headless"'
nodeRoles: ""4、使用各节点角色的配置文件部署
~ helm install es-test-master infinilabs/easysearch -n test -f es-test-master.yaml
~ helm install es-test-data infinilabs/easysearch -n test -f es-test-data.yaml
~ helm install es-test-coordinate infinilabs/easysearch -n test -f es-test-coordinate.yaml5、验证
~ kubectl get pod -n test|grep es-test
es-test-master-easysearch-0 1/1 Running 0 5m57s
es-test-data-easysearch-0 1/1 Running 0 5m29s
es-test-coordinate-easysearch-0 1/1 Running 0 5m10s
es-test-master-easysearch-1 1/1 Running 0 4m57s
es-test-data-easysearch-1 1/1 Running 0 4m29s
es-test-coordinate-easysearch-1 1/1 Running 0 4m10s
es-test-master-easysearch-2 1/1 Running 0 3m56s
es-test-data-easysearch-2 1/1 Running 0 3m29s
~ kubectl exec -n test es-test-master-easysearch-0 -it -- curl -ku'admin:admin' https://localhost:9200/_cat/nodes?v
Defaulted container "easysearch" out of: easysearch, init-config (init)
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
10.42.0.130 12 63 12 1.53 2.67 2.11 - - es-test-coordinate-easysearch-0
10.42.0.136 53 65 52 1.53 2.67 2.11 dir - es-test-data-easysearch-1
10.42.0.139 6 63 14 1.53 2.67 2.11 - - es-test-coordinate-easysearch-1
10.42.0.133 10 63 14 1.53 2.67 2.11 imr - es-test-master-easysearch-1
10.42.0.149 58 65 59 1.53 2.67 2.11 dir - es-test-data-easysearch-2
10.42.0.124 53 68 35 1.53 2.67 2.11 imr * es-test-master-easysearch-0
10.42.0.127 56 65 46 1.53 2.67 2.11 dir - es-test-data-easysearch-0
10.42.0.146 15 63 18 1.53 2.67 2.11 imr - es-test-master-easysearch-2至此,多集群已部署完成。
关于 Easysearch
INFINI Easysearch 是一个分布式的近实时搜索与分析引擎,核心引擎基于开源的 Apache Lucene。Easysearch 的目标是提供一个轻量级的 Elasticsearch 可替代版本,并继续完善和支持更多的企业级功能。 与 Elasticsearch 相比,Easysearch 更关注在搜索业务场景的优化和继续保持其产品的简洁与易用性。
