


ZSTD
Easysearch ZSTD 基准测试:高压缩率下实现近 5 倍查询吞吐
Easysearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 5004 次浏览 • 2026-03-17 12:41
在搜索引擎领域,压缩算法的选择一直是一个经典的权衡难题:
- 选择高压缩率(如
best_compression/ DEFLATE),磁盘省了,但查询解压慢; - 选择高速编码(如默认 LZ4),查询快了,但磁盘占用大。
Easysearch 引入了基于 JDK 21 FFM(Foreign Function & Memory API) 直连本地 ZSTD 动态库的加速方案,试图打破这一困局。为了验证效果,我们在完全对等的环境下,对 Easysearch(ZSTD)和 Elasticsearch 7.10.2(best_compression)进行了一次严格的查询吞吐对比测试。
结果令人振奋——即使在系统明显背景负载下,Easysearch 也没有因为高压缩而变慢,反而在查询吞吐上实现了近 5 倍提升。
测试环境
为确保对比公平,两套集群的硬件资源、JVM 配置、数据规模、索引结构完全对齐:
| 配置项 | Easysearch | Elasticsearch 7.10.2 |
|---|---|---|
| 节点数 | 3 | 3 |
| JVM 堆内存 | 12GB × 3 | 12GB × 3 |
| node.processors | 16 × 3 | 16 × 3 |
| 文档数 | 10,000,000 | 10,000,000 |
| 主分片 / 副本 | 3 / 0 | 3 / 0 |
| 数据类型 | nginx 访问日志 | nginx 访问日志 |
| 字段数 | 17 | 17 |
| mapping | 完全一致(MD5 校验) | 完全一致(MD5 校验) |
| Stored fields 压缩模式 | ZSTD (JDK21 FFM/native, level=3) | best_compression (DEFLATE) |
压缩机制对比:
best_compression映射到 LuceneBEST_COMPRESSION;在 stored fields 路径上,压缩实现为DeflateWithPresetDictCompressionMode,内部使用java.util.zip.Deflater/Inflater(即 DEFLATE)。 Easysearch ZSTD 当前走 JDK 21 FFM 绑定本地 zstd 库(java.lang.foreign);index.compression.zstd.jni=true为当前这套实现的启用方式。
查询模型:JMeter 随机 match 查询,随机命中 service_name、method、error_code、url 四个字段,每次返回 10 条文档。
压测起始负载(_cat/nodes 快照):
| 负载项 | Easysearch run | Elasticsearch run |
|---|---|---|
| load_1m | 29.74 | 25.27 |
| load_5m | 27.10 | 28.15 |
| load_15m | 26.09 | 36.96 |
| ram.percent | 99 | 99 |
说明:压测并非在空闲机上进行,而是在已有明显背景负载的生产式环境下完成。
核心结果
1. 查询吞吐量(QPS):在高背景负载下,Easysearch 仍领先 372%
稳态阶段(3 轮平均),Easysearch 的查询吞吐是 Elasticsearch 的 4.7 倍:
| 指标 | Elasticsearch (DEFLATE) | Easysearch (ZSTD) | 差异 |
|---|---|---|---|
| 稳态 QPS | 532.8 | 2,518.0 | +372.6% |
| 平均响应时间 | 779.0 ms | 164.3 ms | -78.9% |
| 稳态 CPU 占用(系统总占用) | 92.43% | 89.59% | 仅作背景参考 |
注:压测期间服务器存在明显背景负载(其他进程占用较高),该 CPU 指标是系统总占用,不等价于“仅搜索进程”的纯业务 CPU 对比。
在系统总 CPU 均接近 90% 的背景下,Easysearch 仍达到接近 5 倍吞吐。
查询吞吐量 QPS 对比(稳态均值)
2. 响应时间:从近 1 秒降到 164 毫秒
平均响应时间对比(ms,越低越好)
用户体感上,这意味着:同样一个搜索请求,Elasticsearch 还在等解压,Easysearch 已经把结果送到了客户端。
3. 各轮次详细数据
各轮次 QPS 趋势
各轮次平均响应时间趋势(ms)
4. CPU 使用效率:每 1% CPU 产出的 QPS 差距惊人
单看 CPU 占用率,两者似乎差不多(89.59% vs 92.43%)。但如果换一个视角——每消耗 1% CPU 能产出多少 QPS,差距就一目了然了:
| 指标 | Elasticsearch (DEFLATE) | Easysearch (ZSTD) | 倍数 |
|---|---|---|---|
| 稳态 QPS | 532.8 | 2,518.0 | — |
| 稳态 CPU | 92.43% | 89.59% | — |
| QPS / 1% CPU | 5.76 | 28.10 | 4.88× |
CPU 使用效率:每 1% CPU 产出的 QPS
这意味着什么?
- ES 使用 DEFLATE(best_compression)时,解压路径更可能成为 CPU 热点;结合 ES 的高 CPU(92.43%)与较低 QPS,说明单位 CPU 产出偏低;
- Easysearch 使用 ZSTD(JDK21 FFM/native)时,解压开销更小;在相近 CPU 水位(89.59%)下获得更高 QPS,单位 CPU 产出明显更高。
换句话说,当前这组实测更支持“ZSTD 在该查询模型下单位 CPU 产出更高”。
5. 存储空间:ZSTD 并未膨胀
| 索引 | 压缩算法 | 磁盘占用 |
|---|---|---|
| nginx_best_10m (ES) | best_compression (DEFLATE) | 1.8 GB |
| nginx_zstd3 (Easysearch) | ZSTD (level=3, JDK21 FFM/native) | 1.9 GB |
两者存储空间接近。若按 _cat/indices 的 1 位小数展示是 1.8GB vs 1.9GB;若按 _stats/store 字节值计算,差异约 2.5%。因此可以认为 ZSTD 在 level=3 下与 DEFLATE best_compression 压缩率接近。
磁盘占用对比(GB)
为什么 ZSTD 能做到"又小又快"?
传统认知中,压缩率和解压速度是一对矛盾。但 ZSTD 算法天然具备非对称压缩的特性:
压缩算法特性对比
在搜索引擎场景中,查询会触发存储字段(_source)读取与解压路径,命中文件系统页缓存时,可能不发生实际磁盘 I/O,但仍需进行 _source 解压。
当查询涉及较多 _source 读取时:
- DEFLATE 的解压开销成为 CPU 瓶颈,拖慢了整体吞吐;
- ZSTD(JDK21 FFM/native) 的解压速度在该场景下明显更优,单次请求的解压 CPU 成本更低,从而释放出更多 CPU 资源用于并发查询处理。
这就是为什么 Easysearch 在 CPU 占用更低(89.59% vs 92.43%)的情况下,反而能处理近 5 倍的查询量。
一张图总结
Easysearch ZSTD vs Elasticsearch DEFLATE — 全维度对比
结论
Easysearch 的 ZSTD 压缩方案证明了一个事实:即使在高背景负载下,高压缩率和高查询性能依然可以兼得。
在 1000 万条 nginx 日志、且系统存在明显背景负载的实测中:
- 查询吞吐提升 372%,从 533 QPS 跃升至 2518 QPS
- 平均响应时间下降 79%,从 779ms 降至 164ms
- CPU 使用效率提升 388%,每 1% CPU 产出 28.10 QPS vs 5.76 QPS
- CPU 占用绝对值下降 2.84 个百分点(相对下降约 3.07%)
- 磁盘占用与 DEFLATE best_compression 接近(按字节口径约 +2.5%)
对于日志分析、可观测性、安全审计等需要兼顾存储成本和查询性能的场景,Easysearch ZSTD 是一个不需要妥协的选择。
ZSTD 使用方法
1) 新建索引时启用 ZSTD
curl -k -u 'admin:<password>' -X PUT 'https://127.0.0.1:9200/<index-name>' \
-H 'Content-Type: application/json' -d '{
"settings": {
"index.codec": "ZSTD",
"index.compression.zstd.jni": true
}
}'可选参数:
index.compression.zstd.level(默认3)
说明:
index.compression.zstd.dict固定为true,无需单独配置index.compression.zstd.dict不作为独立开关来调整
2) 老索引切换到 ZSTD(推荐 reindex)
index.codec 是静态设置(打开状态不可动态改;可在关闭索引后调整)。
index.compression.zstd.jni 是 final 设置(关闭索引后也不可修改)。
如果老索引要启用 index.compression.zstd.jni=true,建议新建目标索引后 reindex 迁移:
如果对已有索引执行 PUT /<index-name>/_settings 直接修改,会报错:final <index-name> setting [index.compression.zstd.jni], not updateable。
# 先创建目标索引(启用 ZSTD)
curl -k -u 'admin:<password>' -X PUT 'https://127.0.0.1:9200/<target-index>' \
-H 'Content-Type: application/json' -d '{
"settings": {
"index.codec": "ZSTD",
"index.compression.zstd.jni": true
}
}'
# 再迁移数据
curl -k -u 'admin:<password>' -X POST 'https://127.0.0.1:9200/_reindex' \
-H 'Content-Type: application/json' -d '{
"source": { "index": "<source-index>" },
"dest": { "index": "<target-index>" }
}'3) 校验是否生效
curl -k -u 'admin:<password>' \
'https://127.0.0.1:9200/<index-name>/_settings?include_defaults=true&pretty'重点确认:
index.codec = ZSTDindex.compression.zstd.jni = true
关于 Easysearch

INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。
官网文档:https://docs.infinilabs.com/easysearch
作者:张磊,极限科技(INFINI Labs)搜索引擎研发负责人,对 Elasticsearch 和 Lucene 源码比较熟悉,目前主要负责公司的 Easysearch 产品的研发以及客户服务工作。
相关文章:
Easysearch 字段'隐身'之谜:source_reuse 与 ignore_above 的陷阱解析
Easysearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 12097 次浏览 • 2025-09-30 16:08
背景问题
前阵子,社区有小伙伴在使用 Easysearch 的数据压缩功能时发现,在开启 source_reuse 和 ZSTD 后,一个字段的内容看不到了。
索引的设置如下:
{
......
"settings": {
"index": {
"codec": "ZSTD",
"source_reuse": "true"
}
},
"mappings": {
"dynamic_templates": [
{
"message_field": {
"path_match": "message",
"mapping": {
"norms": false,
"type": "text"
},
"match_mapping_type": "string"
}
},
{
"string_fields": {
"mapping": {
"norms": false,
"type": "text",
"fields": {
"keyword": {
"ignore_above": 256,
"type": "keyword"
}
}
},
"match_mapping_type": "string",
"match": "*"
}
}
]
......
}然后产生的一个多字段内容能被搜索到,但是不可见。
类似于下面的这个情况:
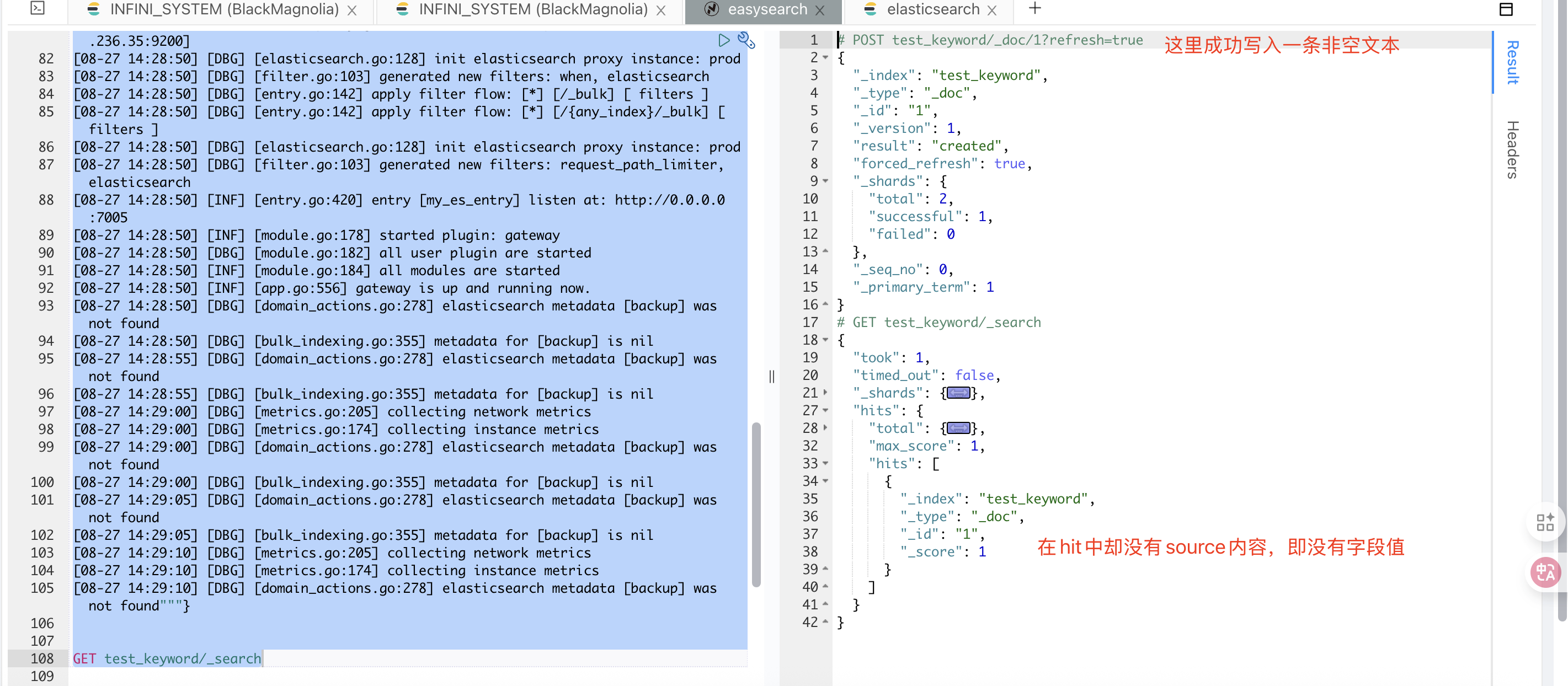
原因分析
我们先来看看整个字段展示经历的环节:
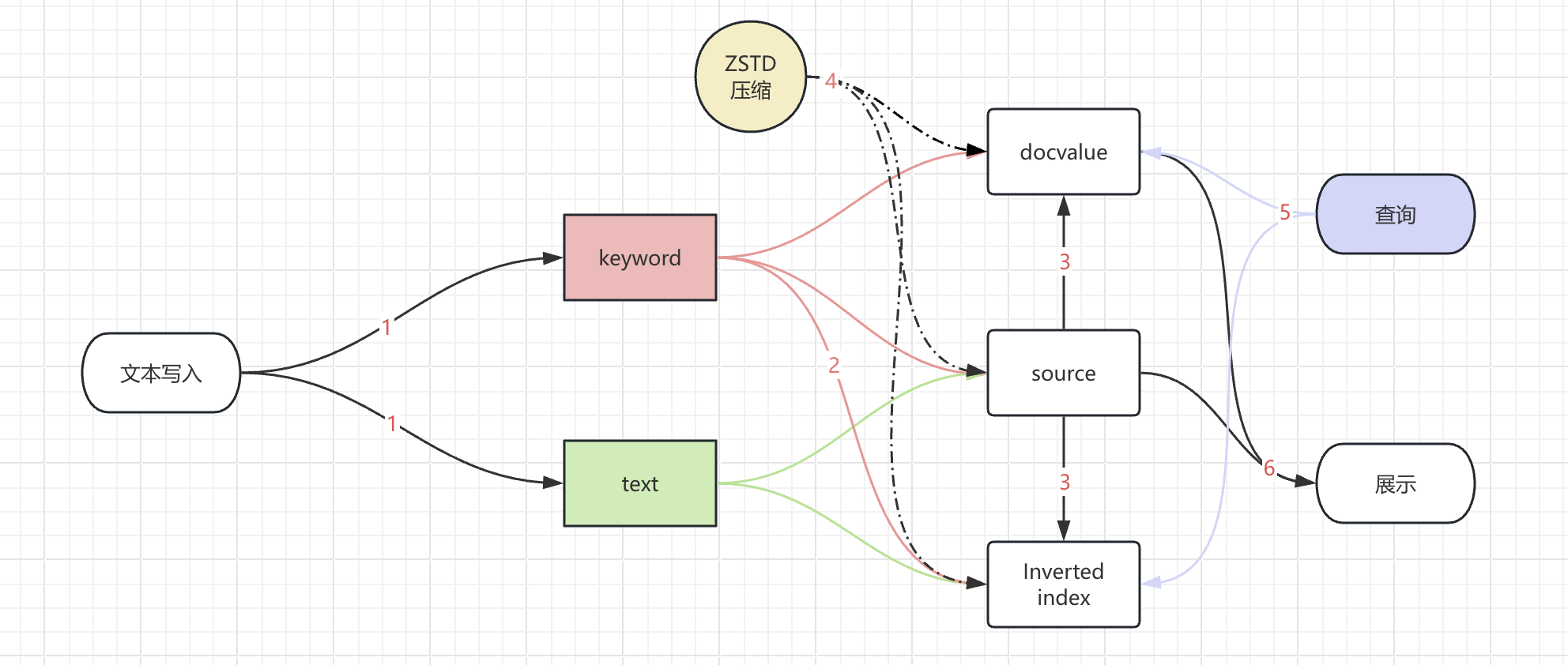
- 字段写入索引的时候,不仅写了 text 字段也写了 keyword 字段。
- keyword 字段产生倒排索引的时候,会忽略掉长度超过 ignore_above 的内容。
- 因为开启了 source_reuse,_source 字段中与 doc_values 或倒排索引重复的部分会被去除。
- 产生的数据文件进行了 ZSTD 压缩,进一步提高了数据的压缩效率。
- 索引进行倒排或者 docvalue 的查询,检索到这个文档进行展示。
- 展示的时候通过文档 id 获取
_source或者docvalues_fields的内容来展示文本,但是文本内容是空的。
其中步骤 4 中的 ZSTD 压缩,是作用于数据文件的,并不对数据内容进行修改。因此,我们来专注于其他环节。
问题复现
首先,这个字段索引的配置也是一个 es 常见的设置,并不会带来内容显示缺失的问题。
"mapping": {
"type": "text",
"fields": {
"keyword": {
"ignore_above": 256,
"type": "keyword"
}
}
},那么,source_reuse 就成了我们可以重点排查的环节。
source 发生了什么
source_reuse 的作用描述如下:
source_reuse: 启用 source_reuse 配置项能够去除 _source 字段中与 doc_values 或倒排索引重复的部分,从而有效减小索引总体大小,这个功能对日志类索引效果尤其明显。
source_reuse 支持对以下数据类型进行压缩:keyword,integer,long,short,boolean,float,half_float,double,geo_point,ip, 如果是 text 类型,需要默认启用 keyword 类型的 multi-field 映射。 以上类型必须启用 doc_values 映射(默认启用)才能压缩。这是一个对 _source 字段进行产品化的功能实现。为了减少索引的存储体量,简单粗暴的操作是直接将_source字段进行关闭,利用其他数据格式去存储,在查询的时候对应的利用 docvalue 或者 indexed 去展示文本内容。
那么 _source关闭后,会不会也有这样的问题呢?
测试的步骤如下:
# 1. 创建不带source的双字段索引
PUT test_source
{
"mappings": {
"_source": {
"enabled": false
},
"properties": {
"msg": {
"type": "text",
"fields": {
"keyword": {
"ignore_above": 256,
"type": "keyword"
}
}
}
}
}
}
# 2. 写入测试数据
POST test_source/_doc/1
{"msg":"""[08-27 14:28:45] [DBG] [config.go:273] config contain variables, try to parse with environments
[08-27 14:28:45] [DBG] [config.go:214] load config files: []
[08-27 14:28:45] [INF] [pipeline.go:419] creating pipeline: pipeline_logging_merge
[08-27 14:28:45] [INF] [pipeline.go:419] creating pipeline: ingest_pipeline_logging
[08-27 14:28:45] [INF] [pipeline.go:419] creating pipeline: async_messages_merge
[08-27 14:28:45] [INF] [pipeline.go:419] creating pipeline: metrics_merge
[08-27 14:28:45] [INF] [pipeline.go:419] creating pipeline: request_logging_merge
[08-27 14:28:45] [INF] [pipeline.go:419] creating pipeline: ingest_merged_requests
[08-27 14:28:45] [INF] [pipeline.go:419] creating pipeline: async_ingest_bulk_requests
[08-27 14:28:45] [INF] [module.go:159] started module: pipeline
[08-27 14:28:45] [DBG] [module.go:163] all system module are started
[08-27 14:28:45] [DBG] [floating_ip.go:348] setup floating_ip, root privilege are required
[08-27 14:28:45] [DBG] [queue_config.go:121] init new queue config:e60457c6eae50a4eabbb62fc1001dccc,bulk_requests
[08-27 14:28:45] [DBG] [queue_config.go:121] init new queue config:e60457c6eae50a4eabbb62fc1001dccc,bulk_requests
[08-27 14:28:45] [DBG] [queue_config.go:121] init new queue config:e60457c6eae50a4eabbb62fc1001dccc,bulk_requests
[08-27 14:28:45] [DBG] [processor.go:139] generated new processors: indexing_merge
[08-27 14:28:45] [DBG] [pipeline.go:466] processing pipeline_v2: metrics_merge
[08-27 14:28:45] [DBG] [processor.go:139] generated new processors: when
[08-27 14:28:45] [DBG] [pipeline.go:466] processing pipeline_v2: ingest_merged_requests
[08-27 14:28:45] [DBG] [processor.go:139] generated new processors: indexing_merge
[08-27 14:28:45] [DBG] [pipeline.go:466] processing pipeline_v2: request_logging_merge
[08-27 14:28:45] [DBG] [processor.go:139] generated new processors: indexing_merge
[08-27 14:28:45] [DBG] [pipeline.go:466] processing pipeline_v2: async_messages_merge
[08-27 14:28:45] [DBG] [processor.go:139] generated new processors: bulk_indexing
[08-27 14:28:45] [DBG] [pipeline.go:466] processing pipeline_v2: ingest_pipeline_logging
[08-27 14:28:45] [DBG] [queue_config.go:121] init new queue config:1216c96eb876eee5b177d45436d0a362,gateway-pipeline-logs
[08-27 14:28:45] [DBG] [processor.go:139] generated new processors: bulk_indexing
[08-27 14:28:45] [DBG] [processor.go:139] generated new processors: indexing_merge
[08-27 14:28:45] [DBG] [pipeline.go:466] processing pipeline_v2: pipeline_logging_merge
[08-27 14:28:45] [DBG] [pipeline.go:466] processing pipeline_v2: async_ingest_bulk_requests
[08-27 14:28:45] [DBG] [badger.go:110] init badger database [queue_consumer_commit_offset]
[08-27 14:28:45] [INF] [floating_ip.go:290] floating_ip entering standby mode
[08-27 14:28:45] [DBG] [badger.go:110] init badger database [dis_locker]
[08-27 14:28:45] [DBG] [time.go:208] refresh low precision time in background
[08-27 14:28:45] [DBG] [domain_actions.go:278] elasticsearch metadata [backup] was not found
[08-27 14:28:45] [DBG] [bulk_indexing.go:355] metadata for [backup] is nil
[08-27 14:28:50] [INF] [module.go:178] started plugin: floating_ip
[08-27 14:28:50] [INF] [module.go:178] started plugin: force_merge
[08-27 14:28:50] [DBG] [network.go:78] network io stats will be included for map[]
[08-27 14:28:50] [INF] [module.go:178] started plugin: metrics
[08-27 14:28:50] [INF] [module.go:178] started plugin: statsd
[08-27 14:28:50] [DBG] [entry.go:100] reuse port 0.0.0.0:7005
[08-27 14:28:50] [DBG] [metrics.go:205] collecting network metrics
[08-27 14:28:50] [DBG] [metrics.go:174] collecting instance metrics
[08-27 14:28:50] [DBG] [elasticsearch.go:128] init elasticsearch proxy instance: prod
[08-27 14:28:50] [DBG] [filter.go:103] generated new filters: when, elasticsearch
[08-27 14:28:50] [DBG] [entry.go:142] apply filter flow: [*] [/_bulk] [ filters ]
[08-27 14:28:50] [DBG] [entry.go:142] apply filter flow: [*] [/{any_index}/_bulk] [ filters ]
[08-27 14:28:50] [DBG] [elasticsearch.go:128] init elasticsearch proxy instance: prod
[08-27 14:28:50] [DBG] [filter.go:103] generated new filters: request_path_limiter, elasticsearch
[08-27 14:28:50] [INF] [module.go:178] started plugin: gateway
[08-27 14:28:50] [DBG] [module.go:182] all user plugin are started
[08-27 14:28:50] [INF] [module.go:184] all modules are started
[08-27 14:28:50] [INF] [app.go:556] gateway is up and running now.
[08-27 14:28:50] [DBG] [domain_actions.go:278] elasticsearch metadata [backup] was not found
[08-27 14:28:50] [DBG] [bulk_indexing.go:355] metadata for [backup] is nil
[08-27 14:28:55] [DBG] [domain_actions.go:278] elasticsearch metadata [backup] was not found
[08-27 14:28:55] [DBG] [bulk_indexing.go:355] metadata for [backup] is nil
[08-27 14:29:00] [DBG] [metrics.go:205] collecting network metrics
[08-27 14:29:00] [DBG] [metrics.go:174] collecting instance metrics
[08-27 14:29:00] [DBG] [domain_actions.go:278] elasticsearch metadata [backup] was not found
[08-27 14:29:00] [DBG] [bulk_indexing.go:355] metadata for [backup] is nil
[08-27 14:29:05] [DBG] [domain_actions.go:278] elasticsearch metadata [backup] was not found
[08-27 14:29:05] [DBG] [bulk_indexing.go:355] metadata for [backup] is nil
[08-27 14:29:10] [DBG] [metrics.go:205] collecting network metrics
[08-27 14:29:10] [DBG] [metrics.go:174] collecting instance metrics
[08-27 14:29:10] [DBG] [domain_actions.go:278] elasticsearch metadata [backup] was not found"""}
# 3. 查询数据
GET test_source/_search此时,可以看到,存入的文档检索出来是空的
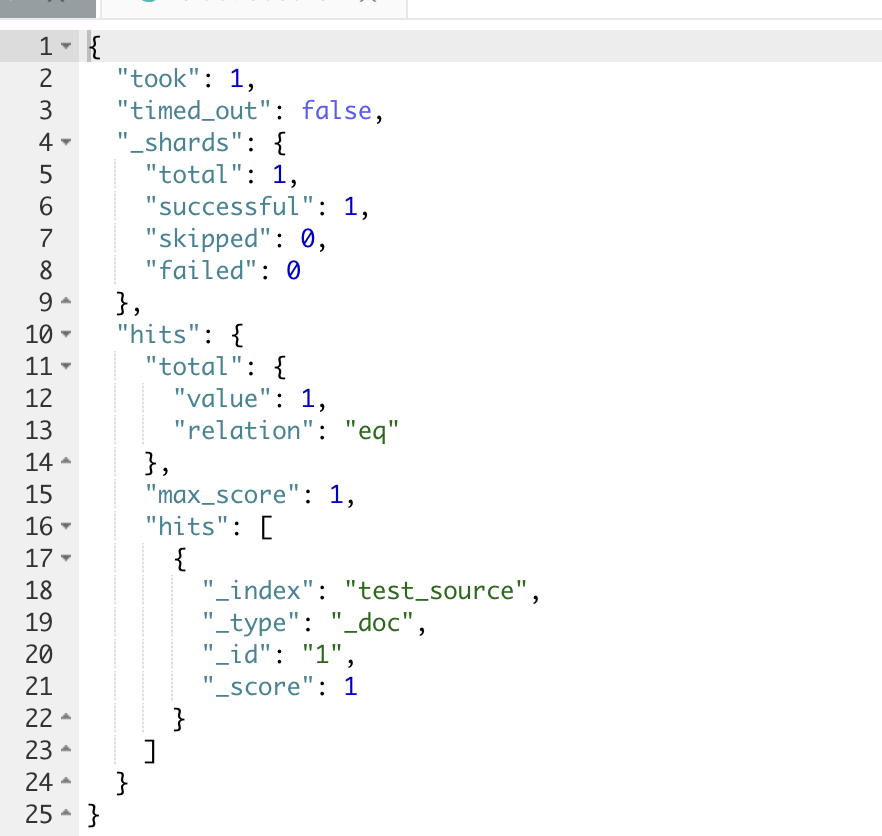
_source 字段是用于索引时传递的原始 JSON 文档主体。它本身未被索引成倒排(因此不作用于 query 阶段),只是在执行查询时用于 fetch 文档内容。
对于 text 类型,关闭_source,则字段内容自然不可被查看。
而对于 keyword 字段,查看_source也是不行的。可是 keyword 不仅存储source,还存储了 doc_values。因此,对于 keyword 字段类型,可以考虑关闭_source,使用 docvalue_fields 来查看字段内容。
测试如下:
# 1. 创建测试条件的索引
PUT test_source2
{
"mappings": {
"_source": {
"enabled": false
},
"properties": {
"msg": {
"type": "keyword"
}
}
}
}
# 2. 写入数据
POST test_source2/_doc
{"msg":"1111111"}
# 3. 使用 docvalue_fields 查询数据
POST test_source2/_search
{"docvalue_fields": ["msg"]}
# 返回结果
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "test_source2",
"_type": "_doc",
"_id": "yBvTj5kBvrlGDwP29avf",
"_score": 1,
"fields": {
"msg": [
"1111111"
]
}
}
]
}
}在如果是 text 类型,需要默认启用 keyword 类型的 multi-field 映射。 以上类型必须启用 doc_values 映射(默认启用)才能压缩。这句介绍里,也可以看到 source_reuse 的正常使用需要 doc_values。_那是不是一样使用 doc_values 进行内容展示呢?既然用于 docvalue_fields 内容展示,为什么还是内容看不了(不可见)呢?_
keyword 的 ignore_above
仔细看问题场景里 keyword 的配置,它使用了 ignore_above。那么,会不会是这里的问题?
我们将 ignore_above 配置带入上面的测试,这里为了简化测试,ignore_above 配置为 3。为区分问题现象,这里两条长度不同的文本进去,一条为 11,一条为1111111,可以作为参数作用效果的对比。
# 1. 创建测试条件的索引,ignore_above 设置为3
PUT test_source3
{
"mappings": {
"_source": {
"enabled": false
},
"properties": {
"msg": {
"type": "keyword",
"ignore_above": 3
}
}
}
}
# 2. 写入数据,
POST test_source3/_doc
{"msg":"1111111"}
POST test_source3/_doc
{"msg":"11"}
# 3. 使用 docvalue_fields 查询数据
POST test_source3/_search
{"docvalue_fields": ["msg"]}
# 返回内容
{
"took": 363,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "test_source3",
"_type": "_doc",
"_id": "yhvjj5kBvrlGDwP22KsG",
"_score": 1
},
{
"_index": "test_source3",
"_type": "_doc",
"_id": "yxvzj5kBvrlGDwP2Nav6",
"_score": 1,
"fields": {
"msg": [
"11"
]
}
}
]
}
}OK! 问题终于复现了。我们再来看看作为关键因素的 ignore_above 参数是用来干嘛的。
ignore_above:任何长度超过此整数值的字符串都不应被索引。默认值为 2147483647。默认动态映射会创建一个 ignore_above 设置为 256 的 keyword 子字段。也就是说,ignore_above 在(倒排)索引时会截取内容,防止产生的索引内容过长。
但是从测试的两个文本来看,面对在参数范围内的文档,docvalues 会正常创建,而超出参数范围的文本而忽略创建(至于这个问题背后的源码细节我们可以另外开坑再鸽,此处省略)。
那么,在 source_reuse 下,keyword 的 ignore_above 是不是起到了相同的作用呢?
我们可以在问题场景上去除 ignore_above,参数试试,来看下面的测试:
# 1. 创建测试条件的索引,使用 source_reuse,设置 ignore_above 为3
PUT test_source4
{
"settings": {
"index": {
"source_reuse": "true"
}
},
"mappings": {
"properties": {
"msg": {
"type": "text",
"fields": {
"keyword": {
"ignore_above": 3,
"type": "keyword"
}
}
}
}
}
}
# 2. 写入数据
POST test_source4/_doc
{"msg":"1111111"}
POST test_source4/_doc
{"msg":"11"}
# 3. 使用 docvalue_fields 查询数据
POST test_source4/_search
# 返回内容
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "test_source4",
"_type": "_doc",
"_id": "",
"_score": 1,
"_source": {}
},
{
"_index": "test_source4",
"_type": "_doc",
"_id": "zRv2j5kBvrlGDwP2_qsO",
"_score": 1,
"_source": {
"msg": "11"
}
}
]
}
}可以看到,数据“不可见”的问题被完整的复现了。
小结
从上面一系列针对数据“不可见”问题的测试,我们可以总结以下几点:
- 在 source_reuse 的压缩使用中,keyword 字段的 ignore_ablve 参数尽量使用默认值,不要进行过短的设置(这个 tip 已补充在 Easysearch 文档中)。
- 在 source_reuse 是对数据压缩常见方法-关闭 source 字段的产品化处理,在日志压缩场景中有效且便捷,可以考虑多加利用。
- keyword 的 ignore_above 参数,不仅超出长度范围不进行倒排索引,也不会写入 docvalues。
特别感谢:社区@牛牪犇群
更多 Easysearch 资料请查看 官网文档。
作者:金多安,极限科技(INFINI Labs)搜索运维专家,Elastic 认证专家,搜索客社区日报责任编辑。一直从事与搜索运维相关的工作,日常会去挖掘 ES / Lucene 方向的搜索技术原理,保持搜索相关技术发展的关注。
原文:https://infinilabs.cn/blog/2025/invisibility-in-easysearch-field/
Easysearch 压缩模式深度比较:ZSTD + source_reuse 的优势分析
Easysearch • liaosy 发表了文章 • 0 个评论 • 3617 次浏览 • 2023-10-09 17:08
引言
在使用 Easysearch 时,如何在存储和查询性能之间找到平衡是一个常见的挑战。Easysearch 具备多种压缩模式,各有千秋。本文将重点探讨一种特别的压缩模式:zstd + source_reuse,我们最近重新优化了 source_reuse,使得它在吞吐量和存储效率方面都表现出色。
测试概览
测试条件选用了 esrally 工具和 geonames 数据集来进行压力测试。数据集包含了 11396503 条记录,往单个 shard 写入,对以下几种压缩模式进行压测对比:
defaultbest_compressionzstd-
zstd + source_reuse
下图是对 CPU 的监控,可以看到各个模式对 CPU 的使用是基本相近的。
default
best_compression
zstd
zstd+reuse
关键数据点
测试结果主要围绕两个指标:
- 中位吞吐量:单位为“每秒操作数”,数值越大表示性能越好。
- 存储大小:单位为 “GB”,数值越小表示存储更加高效。
| 测试数据如下: | 压缩模式 | 中位吞吐量 (docs/s) | 存储大小 (GB) |
|---|---|---|---|
| default | 37834 | 2.7 | |
| best_compression | 37404 | 2.2 | |
| zstd | 38878 | 2.1 | |
| zstd + source_reuse | 38942 | 1.6 |
zstd + source_reuse:压缩原理
该模式采用了 source_reuse 压缩算法,该算法通过对 keyword、long、int、short、boolean 等类型的字段值进行复用,并结合 zstd 压缩算法,大大提高了存储效率。
压缩效率
zstd + source_reuse 在存储大小上的表现尤为出色,针对 geonames 数据集只需 1.6 GB 的存储空间,相比于 best_compression 模式的 2.2 GB,压缩效率显著提高
。
吞吐量表现
高压缩率并没有让 zstd + source_reuse 在吞吐量上做出妥协,因为高压缩率使得其需要持久化的数据大大减小,其中位吞吐量为 38942 docs/s,在 4 种模式中表现最好。
结论
zstd + source_reuse 压缩模式在存储效率和查询性能之间找到了一种极佳的平衡,强烈推荐各位在使用 Easysearch 时,当存储成本比较敏感时,考虑使用 zstd + source_reuse 压缩模式。无论是在存储成本还是写入性能方面,它都能为你带来显著的优势。
关于 Easysearch

INFINI Easysearch 是一个分布式的近实时搜索与分析引擎,核心引擎基于开源的 Apache Lucene。Easysearch 的目标是提供一个轻量级的 Elasticsearch 可替代版本,并继续完善和支持更多的企业级功能。 与 Elasticsearch 相比,Easysearch 更关注在搜索业务场景的优化和继续保持其产品的简洁与易用性。
官网文档:https://www.infinilabs.com/docs/latest/easysearch
下载地址:https://www.infinilabs.com/download
原文:https://www.infinilabs.com/blog/2023/deep-comparison-of-easysearch-compression-modes/
Easysearch ZSTD 基准测试:高压缩率下实现近 5 倍查询吞吐
Easysearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 5004 次浏览 • 2026-03-17 12:41
在搜索引擎领域,压缩算法的选择一直是一个经典的权衡难题:
- 选择高压缩率(如
best_compression/ DEFLATE),磁盘省了,但查询解压慢; - 选择高速编码(如默认 LZ4),查询快了,但磁盘占用大。
Easysearch 引入了基于 JDK 21 FFM(Foreign Function & Memory API) 直连本地 ZSTD 动态库的加速方案,试图打破这一困局。为了验证效果,我们在完全对等的环境下,对 Easysearch(ZSTD)和 Elasticsearch 7.10.2(best_compression)进行了一次严格的查询吞吐对比测试。
结果令人振奋——即使在系统明显背景负载下,Easysearch 也没有因为高压缩而变慢,反而在查询吞吐上实现了近 5 倍提升。
测试环境
为确保对比公平,两套集群的硬件资源、JVM 配置、数据规模、索引结构完全对齐:
| 配置项 | Easysearch | Elasticsearch 7.10.2 |
|---|---|---|
| 节点数 | 3 | 3 |
| JVM 堆内存 | 12GB × 3 | 12GB × 3 |
| node.processors | 16 × 3 | 16 × 3 |
| 文档数 | 10,000,000 | 10,000,000 |
| 主分片 / 副本 | 3 / 0 | 3 / 0 |
| 数据类型 | nginx 访问日志 | nginx 访问日志 |
| 字段数 | 17 | 17 |
| mapping | 完全一致(MD5 校验) | 完全一致(MD5 校验) |
| Stored fields 压缩模式 | ZSTD (JDK21 FFM/native, level=3) | best_compression (DEFLATE) |
压缩机制对比:
best_compression映射到 LuceneBEST_COMPRESSION;在 stored fields 路径上,压缩实现为DeflateWithPresetDictCompressionMode,内部使用java.util.zip.Deflater/Inflater(即 DEFLATE)。 Easysearch ZSTD 当前走 JDK 21 FFM 绑定本地 zstd 库(java.lang.foreign);index.compression.zstd.jni=true为当前这套实现的启用方式。
查询模型:JMeter 随机 match 查询,随机命中 service_name、method、error_code、url 四个字段,每次返回 10 条文档。
压测起始负载(_cat/nodes 快照):
| 负载项 | Easysearch run | Elasticsearch run |
|---|---|---|
| load_1m | 29.74 | 25.27 |
| load_5m | 27.10 | 28.15 |
| load_15m | 26.09 | 36.96 |
| ram.percent | 99 | 99 |
说明:压测并非在空闲机上进行,而是在已有明显背景负载的生产式环境下完成。
核心结果
1. 查询吞吐量(QPS):在高背景负载下,Easysearch 仍领先 372%
稳态阶段(3 轮平均),Easysearch 的查询吞吐是 Elasticsearch 的 4.7 倍:
| 指标 | Elasticsearch (DEFLATE) | Easysearch (ZSTD) | 差异 |
|---|---|---|---|
| 稳态 QPS | 532.8 | 2,518.0 | +372.6% |
| 平均响应时间 | 779.0 ms | 164.3 ms | -78.9% |
| 稳态 CPU 占用(系统总占用) | 92.43% | 89.59% | 仅作背景参考 |
注:压测期间服务器存在明显背景负载(其他进程占用较高),该 CPU 指标是系统总占用,不等价于“仅搜索进程”的纯业务 CPU 对比。
在系统总 CPU 均接近 90% 的背景下,Easysearch 仍达到接近 5 倍吞吐。
查询吞吐量 QPS 对比(稳态均值)
2. 响应时间:从近 1 秒降到 164 毫秒
平均响应时间对比(ms,越低越好)
用户体感上,这意味着:同样一个搜索请求,Elasticsearch 还在等解压,Easysearch 已经把结果送到了客户端。
3. 各轮次详细数据
各轮次 QPS 趋势
各轮次平均响应时间趋势(ms)
4. CPU 使用效率:每 1% CPU 产出的 QPS 差距惊人
单看 CPU 占用率,两者似乎差不多(89.59% vs 92.43%)。但如果换一个视角——每消耗 1% CPU 能产出多少 QPS,差距就一目了然了:
| 指标 | Elasticsearch (DEFLATE) | Easysearch (ZSTD) | 倍数 |
|---|---|---|---|
| 稳态 QPS | 532.8 | 2,518.0 | — |
| 稳态 CPU | 92.43% | 89.59% | — |
| QPS / 1% CPU | 5.76 | 28.10 | 4.88× |
CPU 使用效率:每 1% CPU 产出的 QPS
这意味着什么?
- ES 使用 DEFLATE(best_compression)时,解压路径更可能成为 CPU 热点;结合 ES 的高 CPU(92.43%)与较低 QPS,说明单位 CPU 产出偏低;
- Easysearch 使用 ZSTD(JDK21 FFM/native)时,解压开销更小;在相近 CPU 水位(89.59%)下获得更高 QPS,单位 CPU 产出明显更高。
换句话说,当前这组实测更支持“ZSTD 在该查询模型下单位 CPU 产出更高”。
5. 存储空间:ZSTD 并未膨胀
| 索引 | 压缩算法 | 磁盘占用 |
|---|---|---|
| nginx_best_10m (ES) | best_compression (DEFLATE) | 1.8 GB |
| nginx_zstd3 (Easysearch) | ZSTD (level=3, JDK21 FFM/native) | 1.9 GB |
两者存储空间接近。若按 _cat/indices 的 1 位小数展示是 1.8GB vs 1.9GB;若按 _stats/store 字节值计算,差异约 2.5%。因此可以认为 ZSTD 在 level=3 下与 DEFLATE best_compression 压缩率接近。
磁盘占用对比(GB)
为什么 ZSTD 能做到"又小又快"?
传统认知中,压缩率和解压速度是一对矛盾。但 ZSTD 算法天然具备非对称压缩的特性:
压缩算法特性对比
在搜索引擎场景中,查询会触发存储字段(_source)读取与解压路径,命中文件系统页缓存时,可能不发生实际磁盘 I/O,但仍需进行 _source 解压。
当查询涉及较多 _source 读取时:
- DEFLATE 的解压开销成为 CPU 瓶颈,拖慢了整体吞吐;
- ZSTD(JDK21 FFM/native) 的解压速度在该场景下明显更优,单次请求的解压 CPU 成本更低,从而释放出更多 CPU 资源用于并发查询处理。
这就是为什么 Easysearch 在 CPU 占用更低(89.59% vs 92.43%)的情况下,反而能处理近 5 倍的查询量。
一张图总结
Easysearch ZSTD vs Elasticsearch DEFLATE — 全维度对比
结论
Easysearch 的 ZSTD 压缩方案证明了一个事实:即使在高背景负载下,高压缩率和高查询性能依然可以兼得。
在 1000 万条 nginx 日志、且系统存在明显背景负载的实测中:
- 查询吞吐提升 372%,从 533 QPS 跃升至 2518 QPS
- 平均响应时间下降 79%,从 779ms 降至 164ms
- CPU 使用效率提升 388%,每 1% CPU 产出 28.10 QPS vs 5.76 QPS
- CPU 占用绝对值下降 2.84 个百分点(相对下降约 3.07%)
- 磁盘占用与 DEFLATE best_compression 接近(按字节口径约 +2.5%)
对于日志分析、可观测性、安全审计等需要兼顾存储成本和查询性能的场景,Easysearch ZSTD 是一个不需要妥协的选择。
ZSTD 使用方法
1) 新建索引时启用 ZSTD
curl -k -u 'admin:<password>' -X PUT 'https://127.0.0.1:9200/<index-name>' \
-H 'Content-Type: application/json' -d '{
"settings": {
"index.codec": "ZSTD",
"index.compression.zstd.jni": true
}
}'可选参数:
index.compression.zstd.level(默认3)
说明:
index.compression.zstd.dict固定为true,无需单独配置index.compression.zstd.dict不作为独立开关来调整
2) 老索引切换到 ZSTD(推荐 reindex)
index.codec 是静态设置(打开状态不可动态改;可在关闭索引后调整)。
index.compression.zstd.jni 是 final 设置(关闭索引后也不可修改)。
如果老索引要启用 index.compression.zstd.jni=true,建议新建目标索引后 reindex 迁移:
如果对已有索引执行 PUT /<index-name>/_settings 直接修改,会报错:final <index-name> setting [index.compression.zstd.jni], not updateable。
# 先创建目标索引(启用 ZSTD)
curl -k -u 'admin:<password>' -X PUT 'https://127.0.0.1:9200/<target-index>' \
-H 'Content-Type: application/json' -d '{
"settings": {
"index.codec": "ZSTD",
"index.compression.zstd.jni": true
}
}'
# 再迁移数据
curl -k -u 'admin:<password>' -X POST 'https://127.0.0.1:9200/_reindex' \
-H 'Content-Type: application/json' -d '{
"source": { "index": "<source-index>" },
"dest": { "index": "<target-index>" }
}'3) 校验是否生效
curl -k -u 'admin:<password>' \
'https://127.0.0.1:9200/<index-name>/_settings?include_defaults=true&pretty'重点确认:
index.codec = ZSTDindex.compression.zstd.jni = true
关于 Easysearch
INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。
官网文档:https://docs.infinilabs.com/easysearch
作者:张磊,极限科技(INFINI Labs)搜索引擎研发负责人,对 Elasticsearch 和 Lucene 源码比较熟悉,目前主要负责公司的 Easysearch 产品的研发以及客户服务工作。
相关文章:
Easysearch 字段'隐身'之谜:source_reuse 与 ignore_above 的陷阱解析
Easysearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 12097 次浏览 • 2025-09-30 16:08
背景问题
前阵子,社区有小伙伴在使用 Easysearch 的数据压缩功能时发现,在开启 source_reuse 和 ZSTD 后,一个字段的内容看不到了。
索引的设置如下:
{
......
"settings": {
"index": {
"codec": "ZSTD",
"source_reuse": "true"
}
},
"mappings": {
"dynamic_templates": [
{
"message_field": {
"path_match": "message",
"mapping": {
"norms": false,
"type": "text"
},
"match_mapping_type": "string"
}
},
{
"string_fields": {
"mapping": {
"norms": false,
"type": "text",
"fields": {
"keyword": {
"ignore_above": 256,
"type": "keyword"
}
}
},
"match_mapping_type": "string",
"match": "*"
}
}
]
......
}然后产生的一个多字段内容能被搜索到,但是不可见。
类似于下面的这个情况:
原因分析
我们先来看看整个字段展示经历的环节:
- 字段写入索引的时候,不仅写了 text 字段也写了 keyword 字段。
- keyword 字段产生倒排索引的时候,会忽略掉长度超过 ignore_above 的内容。
- 因为开启了 source_reuse,_source 字段中与 doc_values 或倒排索引重复的部分会被去除。
- 产生的数据文件进行了 ZSTD 压缩,进一步提高了数据的压缩效率。
- 索引进行倒排或者 docvalue 的查询,检索到这个文档进行展示。
- 展示的时候通过文档 id 获取
_source或者docvalues_fields的内容来展示文本,但是文本内容是空的。
其中步骤 4 中的 ZSTD 压缩,是作用于数据文件的,并不对数据内容进行修改。因此,我们来专注于其他环节。
问题复现
首先,这个字段索引的配置也是一个 es 常见的设置,并不会带来内容显示缺失的问题。
"mapping": {
"type": "text",
"fields": {
"keyword": {
"ignore_above": 256,
"type": "keyword"
}
}
},那么,source_reuse 就成了我们可以重点排查的环节。
source 发生了什么
source_reuse 的作用描述如下:
source_reuse: 启用 source_reuse 配置项能够去除 _source 字段中与 doc_values 或倒排索引重复的部分,从而有效减小索引总体大小,这个功能对日志类索引效果尤其明显。
source_reuse 支持对以下数据类型进行压缩:keyword,integer,long,short,boolean,float,half_float,double,geo_point,ip, 如果是 text 类型,需要默认启用 keyword 类型的 multi-field 映射。 以上类型必须启用 doc_values 映射(默认启用)才能压缩。这是一个对 _source 字段进行产品化的功能实现。为了减少索引的存储体量,简单粗暴的操作是直接将_source字段进行关闭,利用其他数据格式去存储,在查询的时候对应的利用 docvalue 或者 indexed 去展示文本内容。
那么 _source关闭后,会不会也有这样的问题呢?
测试的步骤如下:
# 1. 创建不带source的双字段索引
PUT test_source
{
"mappings": {
"_source": {
"enabled": false
},
"properties": {
"msg": {
"type": "text",
"fields": {
"keyword": {
"ignore_above": 256,
"type": "keyword"
}
}
}
}
}
}
# 2. 写入测试数据
POST test_source/_doc/1
{"msg":"""[08-27 14:28:45] [DBG] [config.go:273] config contain variables, try to parse with environments
[08-27 14:28:45] [DBG] [config.go:214] load config files: []
[08-27 14:28:45] [INF] [pipeline.go:419] creating pipeline: pipeline_logging_merge
[08-27 14:28:45] [INF] [pipeline.go:419] creating pipeline: ingest_pipeline_logging
[08-27 14:28:45] [INF] [pipeline.go:419] creating pipeline: async_messages_merge
[08-27 14:28:45] [INF] [pipeline.go:419] creating pipeline: metrics_merge
[08-27 14:28:45] [INF] [pipeline.go:419] creating pipeline: request_logging_merge
[08-27 14:28:45] [INF] [pipeline.go:419] creating pipeline: ingest_merged_requests
[08-27 14:28:45] [INF] [pipeline.go:419] creating pipeline: async_ingest_bulk_requests
[08-27 14:28:45] [INF] [module.go:159] started module: pipeline
[08-27 14:28:45] [DBG] [module.go:163] all system module are started
[08-27 14:28:45] [DBG] [floating_ip.go:348] setup floating_ip, root privilege are required
[08-27 14:28:45] [DBG] [queue_config.go:121] init new queue config:e60457c6eae50a4eabbb62fc1001dccc,bulk_requests
[08-27 14:28:45] [DBG] [queue_config.go:121] init new queue config:e60457c6eae50a4eabbb62fc1001dccc,bulk_requests
[08-27 14:28:45] [DBG] [queue_config.go:121] init new queue config:e60457c6eae50a4eabbb62fc1001dccc,bulk_requests
[08-27 14:28:45] [DBG] [processor.go:139] generated new processors: indexing_merge
[08-27 14:28:45] [DBG] [pipeline.go:466] processing pipeline_v2: metrics_merge
[08-27 14:28:45] [DBG] [processor.go:139] generated new processors: when
[08-27 14:28:45] [DBG] [pipeline.go:466] processing pipeline_v2: ingest_merged_requests
[08-27 14:28:45] [DBG] [processor.go:139] generated new processors: indexing_merge
[08-27 14:28:45] [DBG] [pipeline.go:466] processing pipeline_v2: request_logging_merge
[08-27 14:28:45] [DBG] [processor.go:139] generated new processors: indexing_merge
[08-27 14:28:45] [DBG] [pipeline.go:466] processing pipeline_v2: async_messages_merge
[08-27 14:28:45] [DBG] [processor.go:139] generated new processors: bulk_indexing
[08-27 14:28:45] [DBG] [pipeline.go:466] processing pipeline_v2: ingest_pipeline_logging
[08-27 14:28:45] [DBG] [queue_config.go:121] init new queue config:1216c96eb876eee5b177d45436d0a362,gateway-pipeline-logs
[08-27 14:28:45] [DBG] [processor.go:139] generated new processors: bulk_indexing
[08-27 14:28:45] [DBG] [processor.go:139] generated new processors: indexing_merge
[08-27 14:28:45] [DBG] [pipeline.go:466] processing pipeline_v2: pipeline_logging_merge
[08-27 14:28:45] [DBG] [pipeline.go:466] processing pipeline_v2: async_ingest_bulk_requests
[08-27 14:28:45] [DBG] [badger.go:110] init badger database [queue_consumer_commit_offset]
[08-27 14:28:45] [INF] [floating_ip.go:290] floating_ip entering standby mode
[08-27 14:28:45] [DBG] [badger.go:110] init badger database [dis_locker]
[08-27 14:28:45] [DBG] [time.go:208] refresh low precision time in background
[08-27 14:28:45] [DBG] [domain_actions.go:278] elasticsearch metadata [backup] was not found
[08-27 14:28:45] [DBG] [bulk_indexing.go:355] metadata for [backup] is nil
[08-27 14:28:50] [INF] [module.go:178] started plugin: floating_ip
[08-27 14:28:50] [INF] [module.go:178] started plugin: force_merge
[08-27 14:28:50] [DBG] [network.go:78] network io stats will be included for map[]
[08-27 14:28:50] [INF] [module.go:178] started plugin: metrics
[08-27 14:28:50] [INF] [module.go:178] started plugin: statsd
[08-27 14:28:50] [DBG] [entry.go:100] reuse port 0.0.0.0:7005
[08-27 14:28:50] [DBG] [metrics.go:205] collecting network metrics
[08-27 14:28:50] [DBG] [metrics.go:174] collecting instance metrics
[08-27 14:28:50] [DBG] [elasticsearch.go:128] init elasticsearch proxy instance: prod
[08-27 14:28:50] [DBG] [filter.go:103] generated new filters: when, elasticsearch
[08-27 14:28:50] [DBG] [entry.go:142] apply filter flow: [*] [/_bulk] [ filters ]
[08-27 14:28:50] [DBG] [entry.go:142] apply filter flow: [*] [/{any_index}/_bulk] [ filters ]
[08-27 14:28:50] [DBG] [elasticsearch.go:128] init elasticsearch proxy instance: prod
[08-27 14:28:50] [DBG] [filter.go:103] generated new filters: request_path_limiter, elasticsearch
[08-27 14:28:50] [INF] [module.go:178] started plugin: gateway
[08-27 14:28:50] [DBG] [module.go:182] all user plugin are started
[08-27 14:28:50] [INF] [module.go:184] all modules are started
[08-27 14:28:50] [INF] [app.go:556] gateway is up and running now.
[08-27 14:28:50] [DBG] [domain_actions.go:278] elasticsearch metadata [backup] was not found
[08-27 14:28:50] [DBG] [bulk_indexing.go:355] metadata for [backup] is nil
[08-27 14:28:55] [DBG] [domain_actions.go:278] elasticsearch metadata [backup] was not found
[08-27 14:28:55] [DBG] [bulk_indexing.go:355] metadata for [backup] is nil
[08-27 14:29:00] [DBG] [metrics.go:205] collecting network metrics
[08-27 14:29:00] [DBG] [metrics.go:174] collecting instance metrics
[08-27 14:29:00] [DBG] [domain_actions.go:278] elasticsearch metadata [backup] was not found
[08-27 14:29:00] [DBG] [bulk_indexing.go:355] metadata for [backup] is nil
[08-27 14:29:05] [DBG] [domain_actions.go:278] elasticsearch metadata [backup] was not found
[08-27 14:29:05] [DBG] [bulk_indexing.go:355] metadata for [backup] is nil
[08-27 14:29:10] [DBG] [metrics.go:205] collecting network metrics
[08-27 14:29:10] [DBG] [metrics.go:174] collecting instance metrics
[08-27 14:29:10] [DBG] [domain_actions.go:278] elasticsearch metadata [backup] was not found"""}
# 3. 查询数据
GET test_source/_search此时,可以看到,存入的文档检索出来是空的
_source 字段是用于索引时传递的原始 JSON 文档主体。它本身未被索引成倒排(因此不作用于 query 阶段),只是在执行查询时用于 fetch 文档内容。
对于 text 类型,关闭_source,则字段内容自然不可被查看。
而对于 keyword 字段,查看_source也是不行的。可是 keyword 不仅存储source,还存储了 doc_values。因此,对于 keyword 字段类型,可以考虑关闭_source,使用 docvalue_fields 来查看字段内容。
测试如下:
# 1. 创建测试条件的索引
PUT test_source2
{
"mappings": {
"_source": {
"enabled": false
},
"properties": {
"msg": {
"type": "keyword"
}
}
}
}
# 2. 写入数据
POST test_source2/_doc
{"msg":"1111111"}
# 3. 使用 docvalue_fields 查询数据
POST test_source2/_search
{"docvalue_fields": ["msg"]}
# 返回结果
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "test_source2",
"_type": "_doc",
"_id": "yBvTj5kBvrlGDwP29avf",
"_score": 1,
"fields": {
"msg": [
"1111111"
]
}
}
]
}
}在如果是 text 类型,需要默认启用 keyword 类型的 multi-field 映射。 以上类型必须启用 doc_values 映射(默认启用)才能压缩。这句介绍里,也可以看到 source_reuse 的正常使用需要 doc_values。_那是不是一样使用 doc_values 进行内容展示呢?既然用于 docvalue_fields 内容展示,为什么还是内容看不了(不可见)呢?_
keyword 的 ignore_above
仔细看问题场景里 keyword 的配置,它使用了 ignore_above。那么,会不会是这里的问题?
我们将 ignore_above 配置带入上面的测试,这里为了简化测试,ignore_above 配置为 3。为区分问题现象,这里两条长度不同的文本进去,一条为 11,一条为1111111,可以作为参数作用效果的对比。
# 1. 创建测试条件的索引,ignore_above 设置为3
PUT test_source3
{
"mappings": {
"_source": {
"enabled": false
},
"properties": {
"msg": {
"type": "keyword",
"ignore_above": 3
}
}
}
}
# 2. 写入数据,
POST test_source3/_doc
{"msg":"1111111"}
POST test_source3/_doc
{"msg":"11"}
# 3. 使用 docvalue_fields 查询数据
POST test_source3/_search
{"docvalue_fields": ["msg"]}
# 返回内容
{
"took": 363,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "test_source3",
"_type": "_doc",
"_id": "yhvjj5kBvrlGDwP22KsG",
"_score": 1
},
{
"_index": "test_source3",
"_type": "_doc",
"_id": "yxvzj5kBvrlGDwP2Nav6",
"_score": 1,
"fields": {
"msg": [
"11"
]
}
}
]
}
}OK! 问题终于复现了。我们再来看看作为关键因素的 ignore_above 参数是用来干嘛的。
ignore_above:任何长度超过此整数值的字符串都不应被索引。默认值为 2147483647。默认动态映射会创建一个 ignore_above 设置为 256 的 keyword 子字段。也就是说,ignore_above 在(倒排)索引时会截取内容,防止产生的索引内容过长。
但是从测试的两个文本来看,面对在参数范围内的文档,docvalues 会正常创建,而超出参数范围的文本而忽略创建(至于这个问题背后的源码细节我们可以另外开坑再鸽,此处省略)。
那么,在 source_reuse 下,keyword 的 ignore_above 是不是起到了相同的作用呢?
我们可以在问题场景上去除 ignore_above,参数试试,来看下面的测试:
# 1. 创建测试条件的索引,使用 source_reuse,设置 ignore_above 为3
PUT test_source4
{
"settings": {
"index": {
"source_reuse": "true"
}
},
"mappings": {
"properties": {
"msg": {
"type": "text",
"fields": {
"keyword": {
"ignore_above": 3,
"type": "keyword"
}
}
}
}
}
}
# 2. 写入数据
POST test_source4/_doc
{"msg":"1111111"}
POST test_source4/_doc
{"msg":"11"}
# 3. 使用 docvalue_fields 查询数据
POST test_source4/_search
# 返回内容
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "test_source4",
"_type": "_doc",
"_id": "",
"_score": 1,
"_source": {}
},
{
"_index": "test_source4",
"_type": "_doc",
"_id": "zRv2j5kBvrlGDwP2_qsO",
"_score": 1,
"_source": {
"msg": "11"
}
}
]
}
}可以看到,数据“不可见”的问题被完整的复现了。
小结
从上面一系列针对数据“不可见”问题的测试,我们可以总结以下几点:
- 在 source_reuse 的压缩使用中,keyword 字段的 ignore_ablve 参数尽量使用默认值,不要进行过短的设置(这个 tip 已补充在 Easysearch 文档中)。
- 在 source_reuse 是对数据压缩常见方法-关闭 source 字段的产品化处理,在日志压缩场景中有效且便捷,可以考虑多加利用。
- keyword 的 ignore_above 参数,不仅超出长度范围不进行倒排索引,也不会写入 docvalues。
特别感谢:社区@牛牪犇群
更多 Easysearch 资料请查看 官网文档。
作者:金多安,极限科技(INFINI Labs)搜索运维专家,Elastic 认证专家,搜索客社区日报责任编辑。一直从事与搜索运维相关的工作,日常会去挖掘 ES / Lucene 方向的搜索技术原理,保持搜索相关技术发展的关注。
原文:https://infinilabs.cn/blog/2025/invisibility-in-easysearch-field/
Easysearch 压缩模式深度比较:ZSTD + source_reuse 的优势分析
Easysearch • liaosy 发表了文章 • 0 个评论 • 3617 次浏览 • 2023-10-09 17:08
引言
在使用 Easysearch 时,如何在存储和查询性能之间找到平衡是一个常见的挑战。Easysearch 具备多种压缩模式,各有千秋。本文将重点探讨一种特别的压缩模式:zstd + source_reuse,我们最近重新优化了 source_reuse,使得它在吞吐量和存储效率方面都表现出色。
测试概览
测试条件选用了 esrally 工具和 geonames 数据集来进行压力测试。数据集包含了 11396503 条记录,往单个 shard 写入,对以下几种压缩模式进行压测对比:
defaultbest_compressionzstd-
zstd + source_reuse
下图是对 CPU 的监控,可以看到各个模式对 CPU 的使用是基本相近的。
defaultbest_compressionzstdzstd+reuse
关键数据点
测试结果主要围绕两个指标:
- 中位吞吐量:单位为“每秒操作数”,数值越大表示性能越好。
- 存储大小:单位为 “GB”,数值越小表示存储更加高效。
| 测试数据如下: | 压缩模式 | 中位吞吐量 (docs/s) | 存储大小 (GB) |
|---|---|---|---|
| default | 37834 | 2.7 | |
| best_compression | 37404 | 2.2 | |
| zstd | 38878 | 2.1 | |
| zstd + source_reuse | 38942 | 1.6 |
zstd + source_reuse:压缩原理
该模式采用了 source_reuse 压缩算法,该算法通过对 keyword、long、int、short、boolean 等类型的字段值进行复用,并结合 zstd 压缩算法,大大提高了存储效率。
压缩效率
zstd + source_reuse 在存储大小上的表现尤为出色,针对 geonames 数据集只需 1.6 GB 的存储空间,相比于 best_compression 模式的 2.2 GB,压缩效率显著提高
。
吞吐量表现
高压缩率并没有让 zstd + source_reuse 在吞吐量上做出妥协,因为高压缩率使得其需要持久化的数据大大减小,其中位吞吐量为 38942 docs/s,在 4 种模式中表现最好。
结论
zstd + source_reuse 压缩模式在存储效率和查询性能之间找到了一种极佳的平衡,强烈推荐各位在使用 Easysearch 时,当存储成本比较敏感时,考虑使用 zstd + source_reuse 压缩模式。无论是在存储成本还是写入性能方面,它都能为你带来显著的优势。
关于 Easysearch
INFINI Easysearch 是一个分布式的近实时搜索与分析引擎,核心引擎基于开源的 Apache Lucene。Easysearch 的目标是提供一个轻量级的 Elasticsearch 可替代版本,并继续完善和支持更多的企业级功能。 与 Elasticsearch 相比,Easysearch 更关注在搜索业务场景的优化和继续保持其产品的简洁与易用性。
官网文档:https://www.infinilabs.com/docs/latest/easysearch
下载地址:https://www.infinilabs.com/download
原文:https://www.infinilabs.com/blog/2023/deep-comparison-of-easysearch-compression-modes/
