


Embedding
Easysearch 集成阿里云与 Ollama Embedding API,构建端到端的语义搜索系统
Easysearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 5802 次浏览 • 2025-07-28 17:48
背景
在当前 AI 与搜索深度融合的时代,语义搜索已成为企业级应用的核心能力之一。作为 Elasticsearch 的国产化替代方案,Easysearch 不仅具备高性能、高可用、弹性伸缩等企业级特性,更通过灵活的插件化架构,支持多种主流 Embedding 模型服务,包括 阿里云通义千问(DashScope) 和 本地化 Ollama 服务,实现对 OpenAI 接口规范的完美兼容。
本文将详细介绍如何在 Easysearch 中集成阿里云和 Ollama 的 Embedding API,构建端到端的语义搜索系统,并提供完整的配置示例与流程图解析。
一、为什么选择 Easysearch?
Easysearch 是由极限科技(INFINI Labs)自主研发的分布式近实时搜索型数据库,具备以下核心优势:
- ✅ 完全兼容 Elasticsearch 7.x API 及 8.x 常用操作
- ✅ 原生支持向量检索(kNN)、语义搜索、混合检索
- ✅ 内置数据摄入管道与搜索管道,支持 AI 模型集成
- ✅ 支持国产化部署、数据安全可控
- ✅ 高性能、低延迟、可扩展性强
尤其在 AI 增强搜索场景中,Easysearch 提供了强大的 text_embedding 和 semantic_query_enricher 处理器,允许无缝接入外部 Embedding 模型服务。
二、支持的 Embedding 服务
Easysearch 通过标准 OpenAI 兼容接口无缝集成各类第三方 Embedding 模型服务,理论上支持所有符合 OpenAI Embedding API 规范的模型。以下是已验证的典型服务示例:
| 服务类型 | 模型示例 | 接口协议 | 部署方式 | 特点 |
|---|---|---|---|---|
| 云端 SaaS | 阿里云 DashScope | OpenAI 兼容 | 云端 | 开箱即用,高可用性 |
OpenAI text-embedding-3 |
OpenAI 原生 | 云端 | ||
| 其他兼容 OpenAI 的云服务 | OpenAI 兼容 | 云端 | ||
| 本地部署 | Ollama (nomic-embed-text等) |
自定义 API | 本地/私有化 | 数据隐私可控 |
| 自建开源模型(如 BGE、M3E) | OpenAI 兼容 | 本地/私有化 | 灵活定制 |
核心优势:
-
广泛兼容性
支持任意实现 OpenAI Embedding API 格式(/v1/embeddings)的服务,包括:- 请求格式:
{ "input": "text", "model": "model_name" } - 响应格式:
{ "data": [{ "embedding": [...] }] }
- 请求格式:
-
即插即用
仅需配置服务端点的base_url和api_key即可快速接入新模型。 - 混合部署
可同时配置多个云端或本地模型,根据业务需求灵活切换。
三、结合 AI 服务流程图
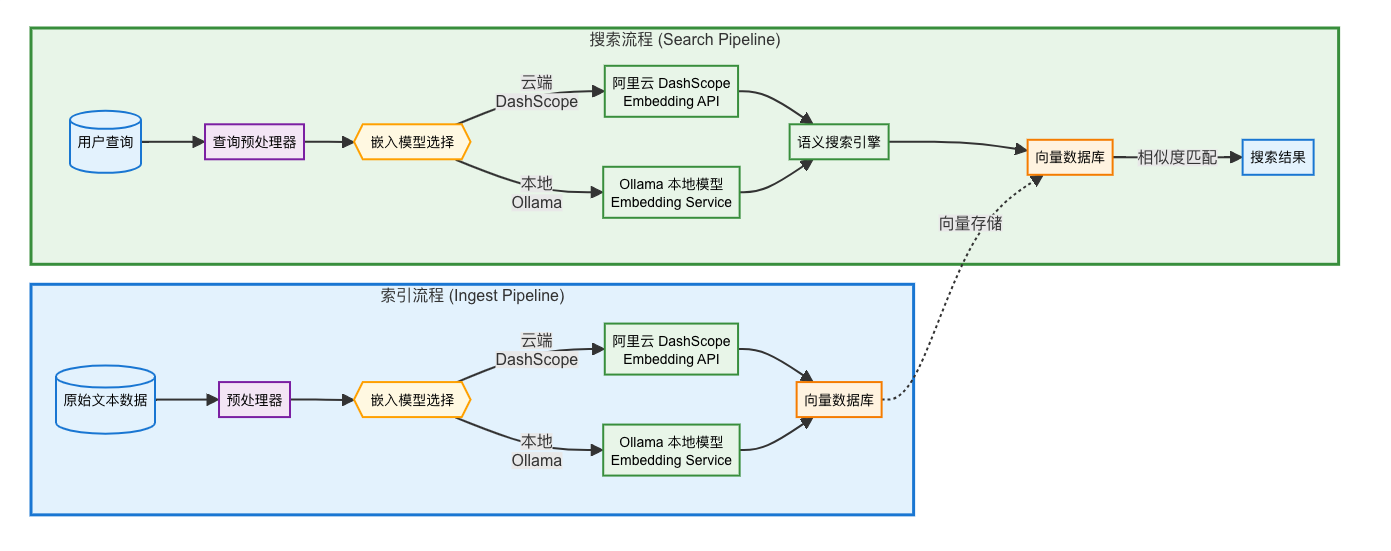
说明:
- 索引阶段:通过 Ingest Pipeline 调用 Embedding API,将文本转为向量并存储。
- 搜索阶段:通过 Search Pipeline 动态生成查询向量,执行语义相似度匹配。
- 所有 API 调用均兼容 OpenAI 接口格式,降低集成成本。
四、集成阿里云 DashScope(通义千问)
阿里云 DashScope 提供高性能文本嵌入模型 text-embedding-v4,支持 256 维向量输出,适用于中文语义理解任务。
1. 创建 Ingest Pipeline(索引时生成向量)
PUT _ingest/pipeline/text-embedding-aliyun
{
"description": "阿里云用于生成文本嵌入向量的管道",
"processors": [
{
"text_embedding": {
"url": "https://dashscope.aliyuncs.com/compatible-mode/v1/embeddings",
"vendor": "openai",
"api_key": "sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx",
"text_field": "input_text",
"vector_field": "text_vector",
"model_id": "text-embedding-v4",
"dims": 256,
"batch_size": 5
}
}
]
}2. 创建索引并定义向量字段
PUT /my-index
{
"mappings": {
"properties": {
"input_text": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"text_vector": {
"type": "knn_dense_float_vector",
"knn": {
"dims": 256,
"model": "lsh",
"similarity": "cosine",
"L": 99,
"k": 1
}
}
}
}
}3. 使用 Pipeline 批量写入数据
POST /_bulk?pipeline=text-embedding-aliyun&refresh=wait_for
{ "index": { "_index": "my-index", "_id": "1" } }
{ "input_text": "风急天高猿啸哀,渚清沙白鸟飞回..." }
{ "index": { "_index": "my-index", "_id": "2" } }
{ "input_text": "月落乌啼霜满天,江枫渔火对愁眠..." }
...4. 配置 Search Pipeline(搜索时动态生成向量)
PUT /_search/pipeline/search_model_aliyun
{
"request_processors": [
{
"semantic_query_enricher": {
"tag": "tag1",
"description": "阿里云 search embedding model",
"url": "https://dashscope.aliyuncs.com/compatible-mode/v1/embeddings",
"vendor": "openai",
"api_key": "sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx",
"default_model_id": "text-embedding-v4",
"vector_field_model_id": {
"text_vector": "text-embedding-v4"
}
}
}
]
}5. 设置索引默认搜索管道
PUT /my-index/_settings
{
"index.search.default_pipeline": "search_model_aliyun"
}6. 执行语义搜索
GET /my-index/_search
{
"_source": "input_text",
"query": {
"semantic": {
"text_vector": {
"query_text": "风急天高猿啸哀,渚清沙白鸟飞回...",
"candidates": 10,
"query_strategy": "LSH_COSINE"
}
}
}
}搜索结果示例:
"hits": [
{
"_id": "1",
"_score": 2.0,
"_source": { "input_text": "风急天高猿啸哀..." }
},
{
"_id": "4",
"_score": 1.75,
"_source": { "input_text": "白日依山尽..." }
},
...
]结果显示:相同诗句匹配得分最高,其他古诗按语义相似度排序,效果理想。
五、集成本地 Ollama 服务
Ollama 支持在本地运行开源 Embedding 模型(如 nomic-embed-text),适合对数据隐私要求高的场景。
1. 启动 Ollama 服务
ollama serve
ollama pull nomic-embed-text:latest2. 创建 Ingest Pipeline(使用 Ollama)
PUT _ingest/pipeline/ollama-embedding-pipeline
{
"description": "Ollama embedding 示例",
"processors": [
{
"text_embedding": {
"url": "http://localhost:11434/api/embed",
"vendor": "ollama",
"text_field": "input_text",
"vector_field": "text_vector",
"model_id": "nomic-embed-text:latest"
}
}
]
}3. 创建 Search Pipeline(搜索时使用 Ollama)
PUT /_search/pipeline/ollama_model_pipeline
{
"request_processors": [
{
"semantic_query_enricher": {
"tag": "tag1",
"description": "Sets the ollama model",
"url": "http://localhost:11434/api/embed",
"vendor": "ollama",
"default_model_id": "nomic-embed-text:latest",
"vector_field_model_id": {
"text_vector": "nomic-embed-text:latest"
}
}
}
]
}后续步骤与阿里云一致:创建索引 → 写入数据 → 搜索查询。
六、安全性说明
Easysearch 在处理 API Key 时采取以下安全措施:
- 🔐 所有
api_key在返回时自动加密脱敏(如TfUmLjPg...infinilabs) - 🔒 支持密钥管理插件(如 Hashicorp Vault 集成)
- 🛡️ 支持 HTTPS、RBAC、审计日志等企业级安全功能
确保敏感信息不被泄露,满足合规要求。
七、总结
通过 Easysearch 的 Ingest Pipeline 与 Search Pipeline,我们可以轻松集成:
- ✅ 阿里云 DashScope(云端高性能)
- ✅ Ollama(本地私有化部署)
- ✅ 其他支持 OpenAI 接口的 Embedding 服务
无论是追求性能还是数据安全,Easysearch 都能提供灵活、高效的语义搜索解决方案。
八、下一步建议
- 尝试混合检索:结合关键词匹配与语义搜索
- 使用 Rerank 模型提升排序精度
- 部署多节点集群提升吞吐量
- 接入 INFINI Gateway 实现统一 API 网关管理
参考链接
关于 Easysearch

INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。
官网文档:https://docs.infinilabs.com/easysearch
作者:张磊,极限科技(INFINI Labs)搜索引擎研发负责人,对 Elasticsearch 和 Lucene 源码比较熟悉,目前主要负责公司的 Easysearch 产品的研发以及客户服务工作。
原文:https://infinilabs.cn/blog/2025/Easysearch-Integration-with-Alibaba-CloudOllama-Embedding-API/
Easysearch 集成阿里云与 Ollama Embedding API,构建端到端的语义搜索系统
Easysearch • INFINI Labs 小助手 发表了文章 • 0 个评论 • 5802 次浏览 • 2025-07-28 17:48
背景
在当前 AI 与搜索深度融合的时代,语义搜索已成为企业级应用的核心能力之一。作为 Elasticsearch 的国产化替代方案,Easysearch 不仅具备高性能、高可用、弹性伸缩等企业级特性,更通过灵活的插件化架构,支持多种主流 Embedding 模型服务,包括 阿里云通义千问(DashScope) 和 本地化 Ollama 服务,实现对 OpenAI 接口规范的完美兼容。
本文将详细介绍如何在 Easysearch 中集成阿里云和 Ollama 的 Embedding API,构建端到端的语义搜索系统,并提供完整的配置示例与流程图解析。
一、为什么选择 Easysearch?
Easysearch 是由极限科技(INFINI Labs)自主研发的分布式近实时搜索型数据库,具备以下核心优势:
- ✅ 完全兼容 Elasticsearch 7.x API 及 8.x 常用操作
- ✅ 原生支持向量检索(kNN)、语义搜索、混合检索
- ✅ 内置数据摄入管道与搜索管道,支持 AI 模型集成
- ✅ 支持国产化部署、数据安全可控
- ✅ 高性能、低延迟、可扩展性强
尤其在 AI 增强搜索场景中,Easysearch 提供了强大的 text_embedding 和 semantic_query_enricher 处理器,允许无缝接入外部 Embedding 模型服务。
二、支持的 Embedding 服务
Easysearch 通过标准 OpenAI 兼容接口无缝集成各类第三方 Embedding 模型服务,理论上支持所有符合 OpenAI Embedding API 规范的模型。以下是已验证的典型服务示例:
| 服务类型 | 模型示例 | 接口协议 | 部署方式 | 特点 |
|---|---|---|---|---|
| 云端 SaaS | 阿里云 DashScope | OpenAI 兼容 | 云端 | 开箱即用,高可用性 |
OpenAI text-embedding-3 |
OpenAI 原生 | 云端 | ||
| 其他兼容 OpenAI 的云服务 | OpenAI 兼容 | 云端 | ||
| 本地部署 | Ollama (nomic-embed-text等) |
自定义 API | 本地/私有化 | 数据隐私可控 |
| 自建开源模型(如 BGE、M3E) | OpenAI 兼容 | 本地/私有化 | 灵活定制 |
核心优势:
-
广泛兼容性
支持任意实现 OpenAI Embedding API 格式(/v1/embeddings)的服务,包括:- 请求格式:
{ "input": "text", "model": "model_name" } - 响应格式:
{ "data": [{ "embedding": [...] }] }
- 请求格式:
-
即插即用
仅需配置服务端点的base_url和api_key即可快速接入新模型。 - 混合部署
可同时配置多个云端或本地模型,根据业务需求灵活切换。
三、结合 AI 服务流程图
说明:
- 索引阶段:通过 Ingest Pipeline 调用 Embedding API,将文本转为向量并存储。
- 搜索阶段:通过 Search Pipeline 动态生成查询向量,执行语义相似度匹配。
- 所有 API 调用均兼容 OpenAI 接口格式,降低集成成本。
四、集成阿里云 DashScope(通义千问)
阿里云 DashScope 提供高性能文本嵌入模型 text-embedding-v4,支持 256 维向量输出,适用于中文语义理解任务。
1. 创建 Ingest Pipeline(索引时生成向量)
PUT _ingest/pipeline/text-embedding-aliyun
{
"description": "阿里云用于生成文本嵌入向量的管道",
"processors": [
{
"text_embedding": {
"url": "https://dashscope.aliyuncs.com/compatible-mode/v1/embeddings",
"vendor": "openai",
"api_key": "sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx",
"text_field": "input_text",
"vector_field": "text_vector",
"model_id": "text-embedding-v4",
"dims": 256,
"batch_size": 5
}
}
]
}2. 创建索引并定义向量字段
PUT /my-index
{
"mappings": {
"properties": {
"input_text": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"text_vector": {
"type": "knn_dense_float_vector",
"knn": {
"dims": 256,
"model": "lsh",
"similarity": "cosine",
"L": 99,
"k": 1
}
}
}
}
}3. 使用 Pipeline 批量写入数据
POST /_bulk?pipeline=text-embedding-aliyun&refresh=wait_for
{ "index": { "_index": "my-index", "_id": "1" } }
{ "input_text": "风急天高猿啸哀,渚清沙白鸟飞回..." }
{ "index": { "_index": "my-index", "_id": "2" } }
{ "input_text": "月落乌啼霜满天,江枫渔火对愁眠..." }
...4. 配置 Search Pipeline(搜索时动态生成向量)
PUT /_search/pipeline/search_model_aliyun
{
"request_processors": [
{
"semantic_query_enricher": {
"tag": "tag1",
"description": "阿里云 search embedding model",
"url": "https://dashscope.aliyuncs.com/compatible-mode/v1/embeddings",
"vendor": "openai",
"api_key": "sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx",
"default_model_id": "text-embedding-v4",
"vector_field_model_id": {
"text_vector": "text-embedding-v4"
}
}
}
]
}5. 设置索引默认搜索管道
PUT /my-index/_settings
{
"index.search.default_pipeline": "search_model_aliyun"
}6. 执行语义搜索
GET /my-index/_search
{
"_source": "input_text",
"query": {
"semantic": {
"text_vector": {
"query_text": "风急天高猿啸哀,渚清沙白鸟飞回...",
"candidates": 10,
"query_strategy": "LSH_COSINE"
}
}
}
}搜索结果示例:
"hits": [
{
"_id": "1",
"_score": 2.0,
"_source": { "input_text": "风急天高猿啸哀..." }
},
{
"_id": "4",
"_score": 1.75,
"_source": { "input_text": "白日依山尽..." }
},
...
]结果显示:相同诗句匹配得分最高,其他古诗按语义相似度排序,效果理想。
五、集成本地 Ollama 服务
Ollama 支持在本地运行开源 Embedding 模型(如 nomic-embed-text),适合对数据隐私要求高的场景。
1. 启动 Ollama 服务
ollama serve
ollama pull nomic-embed-text:latest2. 创建 Ingest Pipeline(使用 Ollama)
PUT _ingest/pipeline/ollama-embedding-pipeline
{
"description": "Ollama embedding 示例",
"processors": [
{
"text_embedding": {
"url": "http://localhost:11434/api/embed",
"vendor": "ollama",
"text_field": "input_text",
"vector_field": "text_vector",
"model_id": "nomic-embed-text:latest"
}
}
]
}3. 创建 Search Pipeline(搜索时使用 Ollama)
PUT /_search/pipeline/ollama_model_pipeline
{
"request_processors": [
{
"semantic_query_enricher": {
"tag": "tag1",
"description": "Sets the ollama model",
"url": "http://localhost:11434/api/embed",
"vendor": "ollama",
"default_model_id": "nomic-embed-text:latest",
"vector_field_model_id": {
"text_vector": "nomic-embed-text:latest"
}
}
}
]
}后续步骤与阿里云一致:创建索引 → 写入数据 → 搜索查询。
六、安全性说明
Easysearch 在处理 API Key 时采取以下安全措施:
- 🔐 所有
api_key在返回时自动加密脱敏(如TfUmLjPg...infinilabs) - 🔒 支持密钥管理插件(如 Hashicorp Vault 集成)
- 🛡️ 支持 HTTPS、RBAC、审计日志等企业级安全功能
确保敏感信息不被泄露,满足合规要求。
七、总结
通过 Easysearch 的 Ingest Pipeline 与 Search Pipeline,我们可以轻松集成:
- ✅ 阿里云 DashScope(云端高性能)
- ✅ Ollama(本地私有化部署)
- ✅ 其他支持 OpenAI 接口的 Embedding 服务
无论是追求性能还是数据安全,Easysearch 都能提供灵活、高效的语义搜索解决方案。
八、下一步建议
- 尝试混合检索:结合关键词匹配与语义搜索
- 使用 Rerank 模型提升排序精度
- 部署多节点集群提升吞吐量
- 接入 INFINI Gateway 实现统一 API 网关管理
参考链接
关于 Easysearch
INFINI Easysearch 是一个分布式的搜索型数据库,实现非结构化数据检索、全文检索、向量检索、地理位置信息查询、组合索引查询、多语种支持、聚合分析等。Easysearch 可以完美替代 Elasticsearch,同时添加和完善多项企业级功能。Easysearch 助您拥有简洁、高效、易用的搜索体验。
官网文档:https://docs.infinilabs.com/easysearch
作者:张磊,极限科技(INFINI Labs)搜索引擎研发负责人,对 Elasticsearch 和 Lucene 源码比较熟悉,目前主要负责公司的 Easysearch 产品的研发以及客户服务工作。
原文:https://infinilabs.cn/blog/2025/Easysearch-Integration-with-Alibaba-CloudOllama-Embedding-API/
