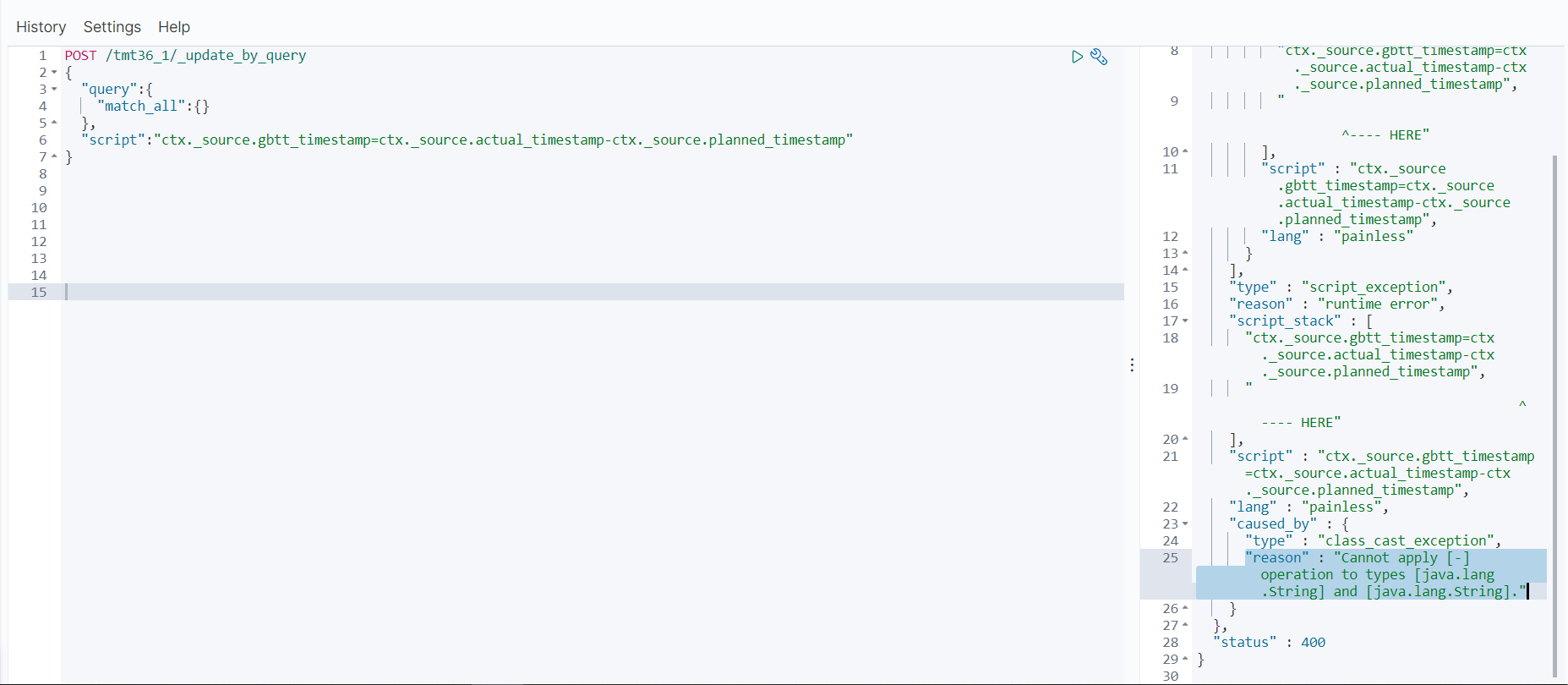
我已经新建了一个索引并将原本为txt格式的字段改为long,然后将原索引的数据导入了新索引,但我想将新索引中的一个数据通过脚本更新时,他依然报错"Cannot apply [-] operation to types [java.lang.String] and [java.lang.String].",在管理中也能看到field已经转为number格式了。我用的kibana和elasticsearch的版本都是目前的版本7.6



本站服务器及带宽由 ![]() 提供赞助 · 网站程序: WeCenter · 湘ICP备17007482号 · 湘公网安备43010402002319号
提供赞助 · 网站程序: WeCenter · 湘ICP备17007482号 · 湘公网安备43010402002319号

4 个回复
liuxg - Elastic
赞同来自:
GET tmt36_1
看看你的index的mapping是啥样的?
你上面修改的是index pattern的mapping。
Ombres
赞同来自:
上面这种的取出来就是String,下面的用起来就没问题了
byx313 - BLOG:https://www.jianshu.com/u/43fd06f9589c
赞同来自:
tacsklet - 公司有用到es
赞同来自: