

最近在做一个全文检索的功能,涉及到的内容还比较多。
主要是不太清楚怎么设计字段,
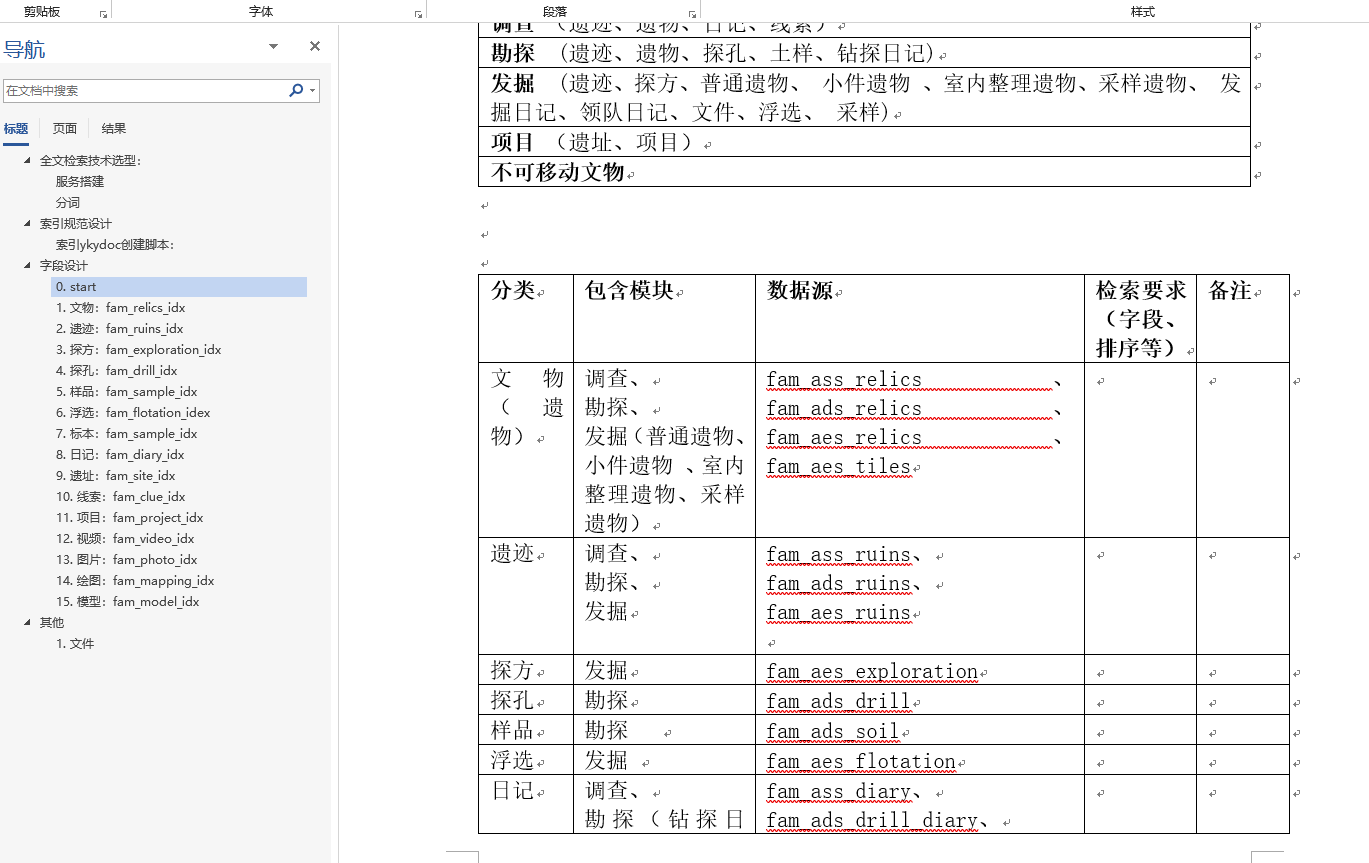
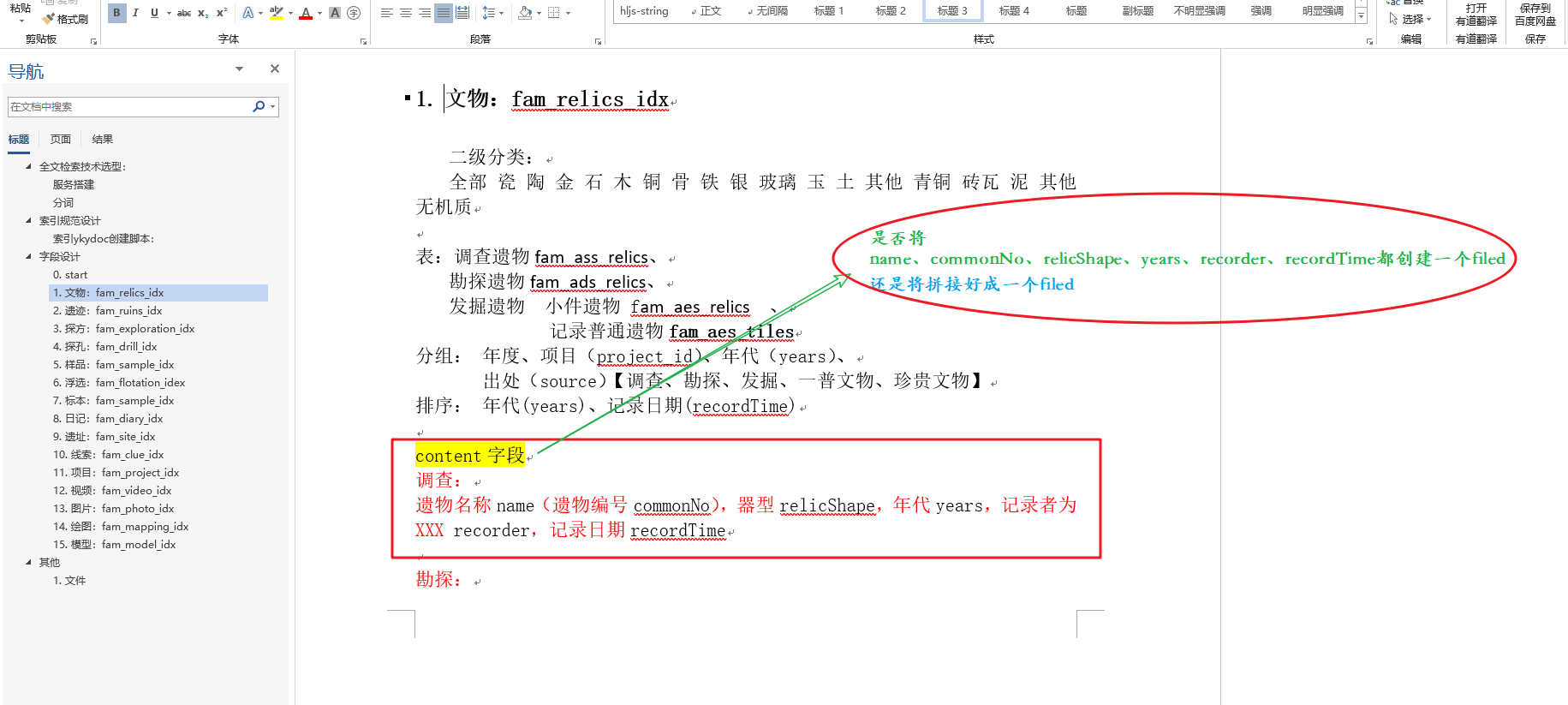
比如field1,field2,field4,field5, 这五个字段都需要参与检索,如下:
如果其中一个字段filed2更新了,这两种情况那种好些。
个人认为,还得请教大家:
主要是
方法一:只会更新filed2字段的分词,并重新创建索引么?
方法二:会更新整个content中的分词,并重新创建索引?
还有考虑后期的可扩展性等!
希望大家帮忙看下,怎么设计好!谢谢
主要是不知道怎么设计,那些字段
主要是不太清楚怎么设计字段,
比如field1,field2,field4,field5, 这五个字段都需要参与检索,如下:
{
"mappings": {
"idx_test": {
"properties": {
"id": {
"type": "keyword"
},
"field1": {
"type": "text",
"analyzer": "ik_max_word",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"field2": {
"type": "text",
"analyzer": "ik_max_word",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"field3": {
"type": "text",
"analyzer": "ik_max_word",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"field4": {
"type": "text",
"analyzer": "ik_max_word",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"recordTime": {
"type": "date"
},
"updateTime": {
"type": "date"
},
"fileuploadId": {
"type": "keyword"
},
"flag": {
"type": "keyword"
},
"isDelete": {
"type": "keyword"
}
}
}
}
}{
"mappings": {
"idx_test": {
"properties": {
"id": {
"type": "keyword"
},
"content": {
"type": "text",
"analyzer": "ik_max_word",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"recordTime": {
"type": "date"
},
"updateTime": {
"type": "date"
},
"fileuploadId": {
"type": "keyword"
},
"flag": {
"type": "keyword"
},
"isDelete": {
"type": "keyword"
}
}
}
}
}如果其中一个字段filed2更新了,这两种情况那种好些。
个人认为,还得请教大家:
主要是
方法一:只会更新filed2字段的分词,并重新创建索引么?
方法二:会更新整个content中的分词,并重新创建索引?
还有考虑后期的可扩展性等!
希望大家帮忙看下,怎么设计好!谢谢
主要是不知道怎么设计,那些字段

3 个回复
Fisher - 鱼仔
赞同来自:
把 多个 filed 的字段映射到一个字段里去
每次数据重新写入 底层的分词索引都会重新写入更新的
liuyeye
赞同来自:
pony_maggie - 公众号:犀牛饲养员的技术笔记
赞同来自: